注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
FAQ
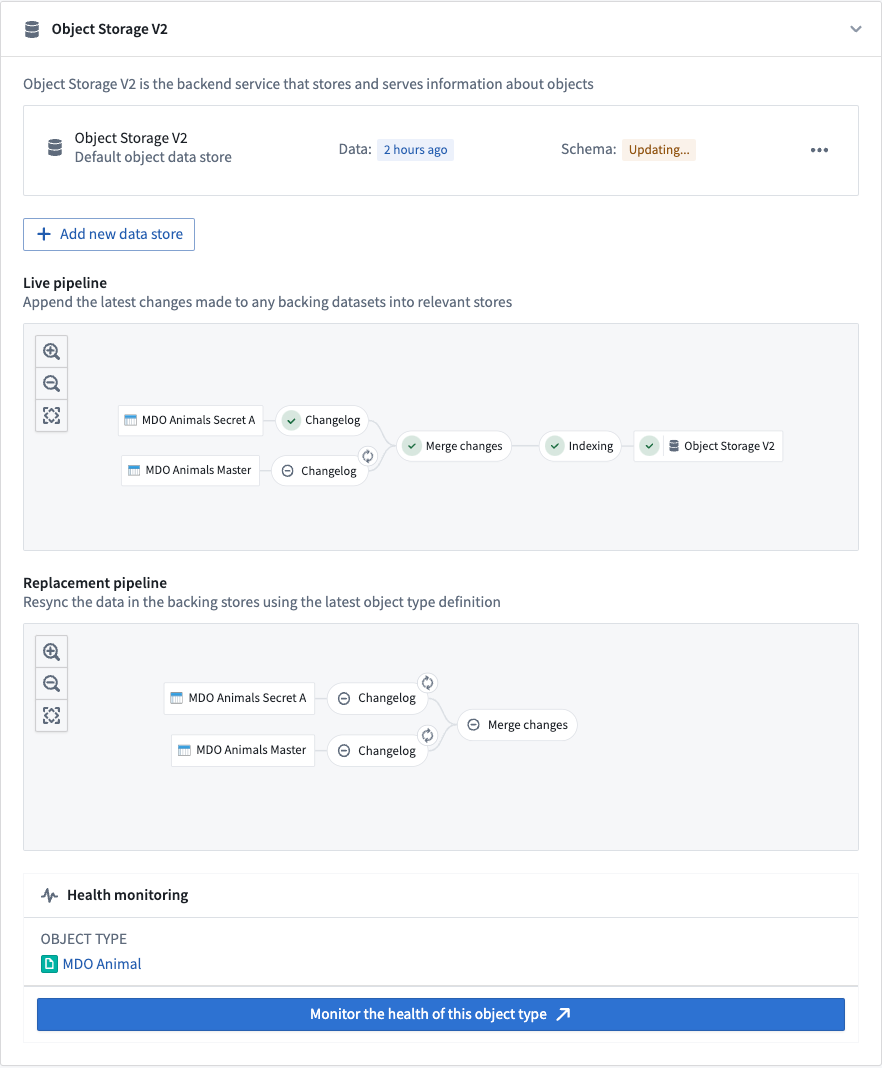
オブジェクトタイプがOSv2にインデックスされたことをどのように知ることができますか?
オントロジーマネージャーアプリケーションには、Funnelパイプライン内のさまざまなジョブの状況を示す専用のパイプライングラフがあります。グラフ内のObject Storage V2ノードに緑色のチェックマークがある場合、インデックス作成が完了し、オブジェクトタイプがOSv2からクエリ可能な状態になっていることを示しています。
インデックス作成ジョブがなぜ失敗する可能性があるのでしょうか、それは以前Object Storage V1 (Phonograph)に成功して登録されていたのに?
OSv1とOSv2では、データの検証が若干異なります。
OSv1の動作は、その下にあるデータストアの動作に大きく影響を受けます。これは、分散ドキュメントストアと検索エンジンに対する密接な結合を持つためです。一方、OSv2には、オントロジーに入力されるデータの品質を保証し、OSv1と比較してシステム全体でより確定的な動作と高い可読性を提供するための厳格な検証があります。
したがって、以前はOSv1で受け入れられていたインデックス作成パイプラインがOSv2を使用するときに検証エラーに遭遇する可能性があります。このような破壊的な変更の詳細なリストについては、OSv1とOSv2の間のオントロジーの破壊的な変更のドキュメンテーションを参照してください。
ジョブの一部が失敗しましたが、再試行すれば成功するかもしれません。再構築をトリガーするにはどうすればよいですか?
OSv2はジョブの全てのアスペクトを管理します。これには、ジョブの再試行も含まれます。ジョブが一時的なエラーにより失敗し、ジョブの再構築で解決される可能性がある場合、OSv2は約5分後に自動的にジョブを再試行します。OSv2がジョブが終了性の失敗(例えば、無効なデータフォーマットによるもの)を検出した場合、新しいデータが利用可能になったときにのみ自動的に再試行します。オブジェクトタイプが制限付きビューデータソースによってバックアップされている場合、データまたはポリシーが変更されたときにジョブがトリガーされます。
インデックスできるデータのサイズには制限がありますか?
インデックスサイズは主に、特定のオブジェクトタイプがインデックスされるオブジェクトデータベースのストレージスペースによって制限されます。例えば、OSv2データストアでは、これは検索ノードのディスクスペースになります。
ディスクスペースが不足している場合、インデックス作成ジョブは成功せず、オントロジーマネージャーアプリケーションのパイプライングラフ内で基本的な問題を報告します。ディスクスペースエラーが発生した場合は、Palantirの担当者に連絡してください。
ストリーミングデータソースを持つオブジェクトタイプの大規模な歴史データをバックフィルできますか?
ストリーミングデータソースをバックアップしているオブジェクトタイプを同期する際には、内部ストリームの作成とインデックス作成の2つのフェーズがあります。ストリーミングインデックス作成ジョブは、Funnelバッチパイプラインと比較して、Sparkを使用して歴史的なストリーミングデータの初期処理を大量に並列化することで、同等のインデックス作成遅延を持ちます。このインデックス作成遅延は、ライブオントロジーデータのユーザー編集と同等です。内部ストリームの作成は通常、制限要因となります。これは、データソースをレコードごとに処理するためのストリーミングインフラを利用します。
オントロジーへのストリーミングの期待される遅延は何ですか?
Funnelストリーミングパイプラインで最も時間がかかる部分は、"exactly once"ストリーミング整合性を可能にするためのFlinkチェックポイントです。デフォルトのチェックポイント頻度は1秒ごとなので、これが入力ストリームにデータが到着し、オントロジーにインデックスされるまでの支配的な遅延となります。頻度を減らし、あるいは完全に取り除くことでコスト/パフォーマンス/遅延のトレードオフを評価するために、我々は継続的な実験を行っています。
必要に応じて、Palantirのサポートに連絡して、動作を設定してください。
オントロジーへのストリーミングの期待されるスループットは何ですか?
インデックス作成のスループットは、Object Storage v2オブジェクトデータベースに対してオブジェクトタイプごとに2 MB/sに制限されています。より高いインデックス作成スループットが必要な場合は、Palantirサポートに連絡してください。
オントロジーでストリームデータソースを使用する際に、オブジェクトが重複削除されるタイムスタンプを指定できますか?
いいえ、Funnelストリーミングパイプラインは、インデックス作成時に入力ストリームの順序を保持します。データはストリームに順序良く書き込まれるべきです。これは、上流のストリーミングパイプラインで、イベントのタイムスタンプでデータをウィンドウ化し、主キーを指定してデータがハッシュ分割されるようにすることで行うことができます。
オントロジーストリーミングは変更データキャプチャ(CDC)ワークフローをサポートしていますか?
Funnelストリーミングパイプラインは、作成、更新、削除ワークフローをサポートしています。削除メタデータの設定方法については、変更データキャプチャのドキュメンテーションを参照してください。
ストリームデータソースを使用してオントロジーに部分的な行を書き込むことはできますか?全体のオブジェクトを提供する代わりに、一度にいくつかのプロパティを更新することはできますか?
現在のところ、いいえです。全体のオブジェクトの解決は上流のパイプラインで行うべきです。スケールの問題で状態保持ストリーミングがこの問題を解決できない場合は、Palantirサポートに連絡してください。
多対多リンクタイプのオントロジーストリーミングを使用できますか?
はい、対応しています。ストリーミングデータソースとオントロジータイプの設定方法については、こちらのドキュメンテーションで詳しく学ぶことができます。
オブジェクトデータベースの他のObject Storage v2(実体化やAutomateなど)に対してストリーミングはサポートされていますか?
オントロジーストリーミングは現在、Object Storage v2オブジェクトデータベースのみがサポートしています。他のオブジェクトデータベースでこの機能が必要な場合は、Palantirサポートに連絡してください。
ストリームデータソースを持つオブジェクトタイプに対して実体化はサポートされていますか?
いいえ。ストリームデータソースを持つオブジェクトタイプに対してユーザーの編集がサポートされていないため、実体化されたデータセットはストリームのアーカイブデータセットと変わりません。現在のアーキテクチャでは、データセット内の重複を排除したビューを提供することはできません。
私のFunnelストリーミングパイプラインは常に実行されています。これをどのようにキャンセルできますか?
Funnelストリーミングパイプラインはユーザーによってキャンセルすることはできません。Funnelは、本番のオブジェクトタイプが高可用性を必要とするため、常にストリームを生きています。この設定は、プロトタイピング時に望ましくないコストを発生させる可能性があります。これがあなたのユースケースで大きな障害となる場合は、Palantirサポートに連絡してください。あるいは、プロトタイピングフェーズ中にオブジェクトタイプをバッチモードに切り替えることを試してみてください。
ダウンタイムなしでストリームデータソースを別のストリームに切り替えるにはどうすればよいですか?
Funnelストリーミングパイプラインには、パイプラインが新しいストリームと"最新の状態"であるかどうかを判断するヒューリスティックがあります。以下の手順で、データソースを別のストリームまたはストリームの別のブランチを指すように変更できます:
- 新しいロジックを別のストリーム(または別のブランチ)で実行します。
- 新しいストリームがリプレイを完了するのを待ちます。つまり、すべての歴史的なレコードが処理されるまでです。
- オブジェクトタイプの入力データソースを新しいストリームに変更します。
- Funnelストリーミングパイプラインは、新しいストリーム上の交換用パイプラインが完全にインデックスされるまで、元のストリーム上のライブパイプラインを保持します。
- Funnelがカットオーバーを完了したら、元のストリームをオフにできます。
意図しない結果をもたらす可能性のある一般的な誤りは何ですか?
- データが予想と異なる場合、入力ストリームが期待通りに順序付けられていることを確認してください。
- Funnelストリーミングパイプラインは、Funnelバッチパイプラインと同じ検証を行います。ただし、ストリーミングパイプラインの場合、ストリーム処理を一時停止できないため、ユーザートランスフォームでエラーをスローするメカニズムはありません。そのため、無効なレコードはドロップされます。
オントロジーストリーミングのコストは何ですか?
Funnelストリーミングパイプラインの計算は、通常のストリーミングリソースと同じ方法で計算されます。ストリーミングリソースコストについての詳細は、ストリーミング計算使用のドキュメンテーションをご覧ください。
保持ウィンドウはどのように動作しますか?
保持ウィンドウは、初めてベータリリースされた際のデータサイズ制限メカニズムとして開発されました。したがって、それは最善の努力としてのみ実装されています。これは、保持ウィンドウ内のオブジェクトインスタンスがクエリ可能であり、保持ウィンドウの外側にあるオブジェクトインスタンスは最終的に削除されることを意味します。例えば、保持ウィンドウが2週間に設定されていて、ストリームデータソースのオブジェクトインスタンスが最後に入力ストリームによって3週間前に更新された場合、そのオブジェクトインスタンスはそのオブジェクトタイプから削除される可能性があります。しかし、そのオブジェクトインスタンスはオントロジーに多くの日数残っている可能性があり、特定の時間枠内に削除されることは決して保証されません。
オントロジーから古いデータを"クリーニングアップ"する現在のメカニズムは、パイプラインの交換を通じて行われます。これは、デフォルトでは2週間ごとに実行されます。交換時に、Funnelストリーミングパイプラインは保持ウィンドウの開始からストリームをリプレイします。これにより、オントロジーから古いオブジェクトインスタンスが削除されます。古いオブジェクトインスタンスをより定期的に削除する必要がある場合は、Palantirサポートに連絡してください。
保持ウィンドウが設定されていない場合、入力ストリームソースからのすべてのデータがオントロジーに取り込まれます。
なぜ私のストリームソースがバッチでインデックスされているか、または重複エラーで失敗しているのですか?
オントロジーマネージャーでは、ストリーミングデータソースと制限付きビューをバックアップとしたストリームの両方について、必ず明示的に入力データソースをストリームとして指定する必要があります。そうしないと、あなたのデータソースは標準のFunnelバッチパイプラインとしてインデックス作成に戻ります。ストリーミングオブジェクトタイプの設定について詳しくは、当社のドキュメンテーションをご覧ください。
ストリーミングデータソースを持つオブジェクトタイプをオントロジー関数を通じてクエリすることはできますか?
はい、オントロジーのクエリは、ストリーミングオブジェクトタイプとバッチオブジェクトタイプの両方に対して同じように動作します。