注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
レガシー REST API プラグイン(magritte-rest-v2)
ここで文書化されているカスタム magritte-rest-v2 ソースタイプを使用したレガシー REST API のオプションは、歴史的な参照のためだけです。この機能は現在、アクティブな開発が行われておらず、オンプレミスシステムに関連する稀な状況を除き、使用しないでください。
- インターネットにアクセス可能なソースへの同期とエクスポートには、外部変換を使用します。
- Webhook、インターネットにアクセス可能なエンドポイントとオンプレミスエンドポイントを含む、REST API ソースを使用します。
- オンプレミスシステムへの同期とエクスポートを行うための ソースコネクタが利用できない場合、レガシー REST API プラグインは引き続き使用されるかもしれません。
カスタムソースタイプ magritte-rest-v2 は、API コールのシーケンスから外部システムと対話することを可能にし、主にエージェントランタイムを使用してオンプレミス REST API に接続するために使用されるべきです。
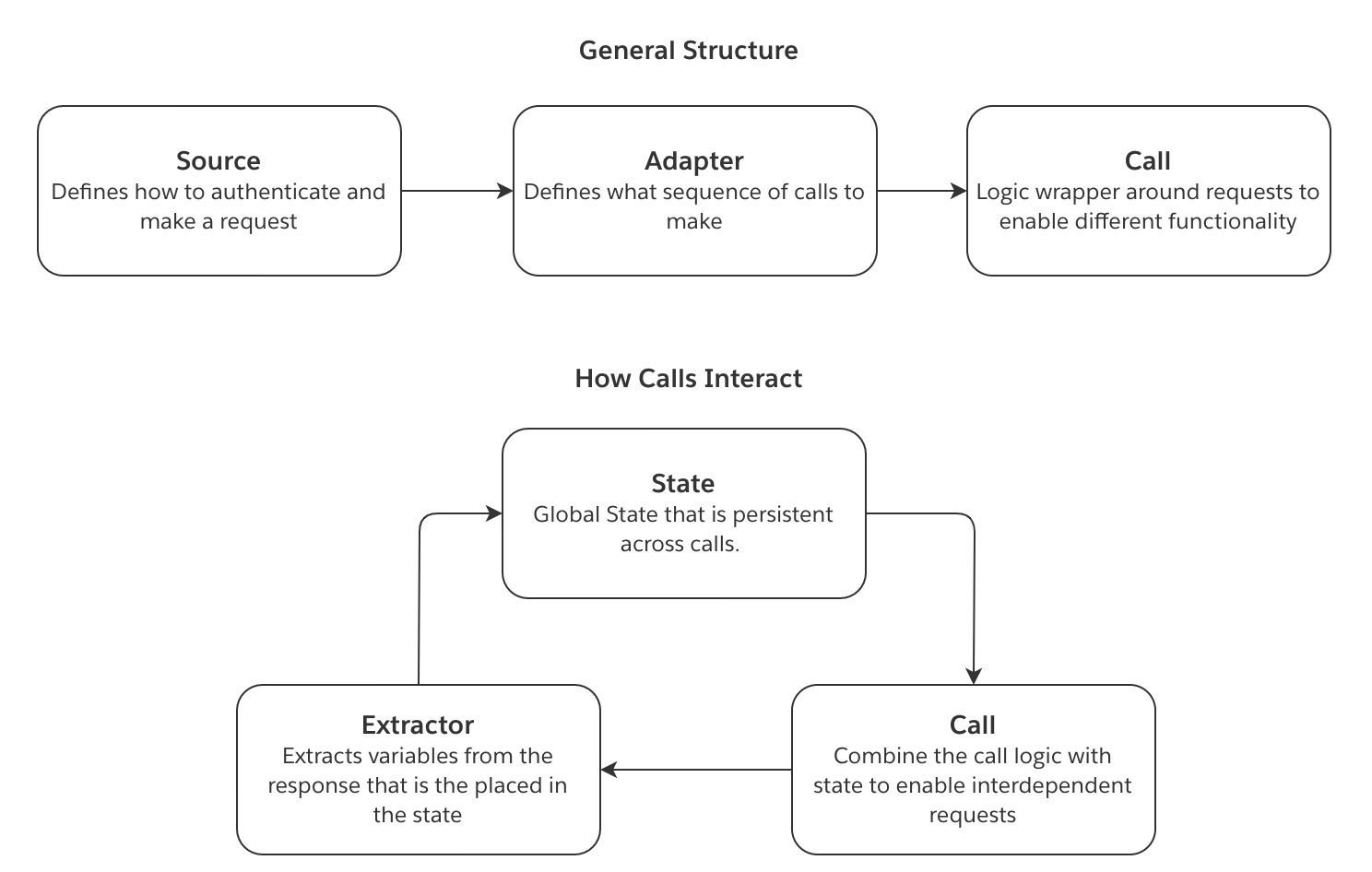
アーキテクチャ
以下の概念は、magritte-rest-v2 ソースを使用する際の情報の流れを説明しています。
- ソース は接続がどのように確立されるかを定義します。これには、リクエストがどのように認証すべきかが含まれます。
- 同期 は コール のリストで構成されます。各コールは、どのようなリクエストを行うべきかを定義し、このリクエストに必要なロジックを実装します。コールは単純な GET リクエストから、ページネーションのためのリクエストループなど、より複雑なものまであります。
- エクストラクタ は、認証コールと同期コールの両方へのレスポンスを解析する方法を定義します。同期コールの場合、レスポンスのフィールドを ステート に保存することができます。
- 結果として得られる ステート は次のコールに渡されます。この
ステートの変数は、次に行うコールに注入することができます。これにより、相互依存的なリクエストが可能になります。
この図は、上記の概念がどのように相互作用するかを示しています:
カスタム magritte-rest-v2 ソースの作成
magritte-rest-v2 ソースを作成するには、Data Connection アプリケーションの ソース タブから 新規ソース を選択します。次に、カスタムソースを追加 のオプションを選択します。magritte-rest-v2 プラグインは主に YAML エディタを通じて設定されます。
以下の例は、異なる認証タイプの設定に必要な YAML コードのスニペットを提供しています:
この文書では、以下のトピックについても追加のガイダンスを提供しています:
認証
ヘッダー
Copied!1 2 3 4 5 6 7type: magritte-rest-v2 sourceMap: my_api: type: magritte-rest headers: Authorization: 'Bearer {{token}}' # 認証のためのトークンを含むヘッダー url: "https://some-api.com/" # APIのエンドポイントURL
ユーザー名とパスワード
Basic 認証としても知られています。
Copied!1 2 3 4 5 6 7 8type: magritte-rest-v2 sourceMap: my_api: type: magritte-rest # 「usernamePassword」は、ユーザ名とパスワードをコロンで結合した形式で指定します usernamePassword: '{{username}}:{{password}}' # 「url」はAPIのエンドポイントを指定します url: "https://some-api.com/"
本文
Copied!1 2 3 4 5 6 7 8 9 10 11 12type: magritte-rest-v2 sourceMap: my_api: type: magritte-rest-auth-call-source # APIのURLを指定します url: "https://some-api.com/" # リクエストのMIMEタイプを指定します requestMimeType: application/json # リクエストのボディ部分です。ユーザー名とパスワードを指定します body: '{"username": "{{username}}", "password": "{{password}}"}' # 認証に関連するAPIのコールを指定します。ここでは空です authCalls: []
URL パラメーター
Copied!1 2 3 4 5 6 7 8 9type: magritte-rest-v2 sourceMap: my_api: # 私のAPI type: magritte-rest-auth-call-source # magritte-rest認証呼び出しソースのタイプ url: "https://some-api.com/" # APIのURL parameters: # パラメータ username: "{{username}}" # ユーザー名 password: "{{password}}" # パスワード authCalls: [] # 認証呼び出しのリスト
コール
次の設定は、URLエンコードされたフォームボディを /auth エンドポイントに送信し、返されたトークンを同期に使用するために使用できます。エンドポイントがフォームタイプを持っている場合にのみ formBody を使用し、それ以外の場合は body を使用してください。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22type: magritte-rest-v2 sourceMap: my_api: type: magritte-rest-auth-call-source url: "https://some-api.com/" headers: Authorization: 'Bearer {%token%}' # 認証呼び出し authCalls: - type: magritte-rest-call path: /auth method: POST # フォームボディにユーザー名とパスワードを入力 formBody: username: '{{username}}' password: '{{password}}' # 抽出器 extractor: - type: magritte-rest-json-extractor assign: # トークンを取得 token: /token
返されたトークンの有効期限が、同期が完了する前に定期的に切れてしまう場合、authExpiration パラメーターを使用して、authCalls の下のコールがどのくらいの頻度でリトライされるべきかを指定してください。authExpiration の値は、/auth エンドポイントで返されるトークンの有効期間を超えないように設定してください。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19type: magritte-rest-v2 sourceMap: my_api: type: magritte-rest-auth-call-source url: "https://some-api.com/" authExpiration: 30m headers: Authorization: 'Bearer {%token%}' authCalls: - type: magritte-rest-call path: /auth method: POST formBody: username: '{{username}}' # ユーザー名 password: '{{password}}' # パスワード extractor: - type: magritte-rest-json-extractor assign: token: /token # トークンを割り当てる
API がログインに成功するために、サブスクリプションキーのようなセキュリティヘッダーを使用する場合、authCalls の下に追加のヘッダーセクションを追加する必要があります。この 2 番目のヘッダーセクションは認証コール専用であり、最初のヘッダーセクションとは完全に別です。認証コールを除くすべての API コールは、最初のヘッダーセクションを使用します。これらのヘッダーセクションが適切に構成されていない場合、401 認証エラーが発生する可能性があります。以下に例を示します。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32type: magritte-rest-v2 sourceMap: my_api: type: magritte-rest-auth-call-source # APIのURLを定義します url: "https://some-api.com/" headers: X-service-identifier: SWN # トークンを使用して認証します Authorization: 'Bearer {%token%}' # サブスクリプションキーを定義します Ocp-Apim-Subscription-Key: '{{subscriptionKey}}' authCalls: - type: magritte-rest-call # 認証のためのパスを定義します path: /auth # メソッドはPOSTを使用します method: POST headers: X-service-identifier: SWN # サブスクリプションキーを定義します Ocp-Apim-Subscription-Key: '{{subscriptionKey}}' body: # ユーザー名を定義します username: '{{username}}' # パスワードを定義します password: '{{password}}' extractor: - type: magritte-rest-json-extractor assign: # トークンを抽出します token: /token
他のドメインへの呼び出し
これにより、あるドメインでの認証を行って、別のドメインでトークンを使用できるようになります。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22type: magritte-rest-v2 sourceMap: auth_api: type: magritte-rest url: "https://auth.api.com" data_api: type: magritte-rest-auth-call-source url: "https://data-api.com/" headers: Authorization: 'Bearer {%token%}' authCalls: - type: magritte-rest-call source: auth_api path: /auth method: POST formBody: username: '{{username}}' # ユーザー名 password: '{{password}}' # パスワード extractor: - type: magritte-rest-json-extractor assign: token: /token # トークンを取得
クライアント証明書
ソースは、認証用に Java KeyStore(JKS)ファイルを提供することができます。
Copied!1 2 3 4 5 6 7 8 9 10 11type: magritte-rest-v2 sourceMap: my_api: type: magritte-rest url: "https://some-api.com/" keystorePath: "/my/keystore/keystore.jks" keystorePassword: "{{password}}" # パスワード # my_api という名前のマジリットRESTソースを定義します。 # URLは "https://some-api.com/" を指定します。 # キーストアのパスは "/my/keystore/keystore.jks" を指定します。 # キーストアのパスワードは "{{password}}" で指定します。
NTLM
次の curl: curl -v http://example.com/do.asmx --ntlm -u DOMAIN\\username:password は次のように翻訳できます:
Copied!1 2 3 4 5 6type: magritte-rest-ntlm-source # ソースのタイプを指定します。ここではmagritte-rest-ntlm-sourceを使用します。 url: http://example.com # データソースへのURLを指定します。 user: "{{username}}" # ユーザー名を指定します。具体的な値は環境変数などから取得します。 password: "{{password}}" # パスワードを指定します。具体的な値は環境変数などから取得します。 domain: DOMAIN (optional) # ドメインを指定します。これはオプションで、必要に応じて設定します。 workstation: (optional) the name of your machine as given by $(hostname) # ワークステーション(マシン名)を指定します。これもオプションで、必要に応じて設定します。具体的な値は$(hostname)コマンドなどで取得します。
プロキシ
Copied!1 2 3 4 5 6type: magritte-rest-v2 sourceMap: my_api: type: magritte-rest url: http://example.com proxy: 'http://my-proxy:8888/' # プロキシとしてIPアドレスも渡すことができます
プロキシ資格情報も設定で渡すことができます:
Copied!1 2 3 4 5 6 7 8 9type: magritte-rest-v2 sourceMap: my_api: type: magritte-rest url: http://example.com proxy: url: 'http://my-proxy:8888/' # IPアドレスも渡すことができます username: 'my-proxy-username' # プロキシのユーザー名 password: 'my-proxy-password' # プロキシのパスワード
サーバー証明書の問題
javax.net.ssl.SSLHandshakeException のようなエラーが表示される場合、サーバーの証明書をエージェントの信頼ストアに追加する必要があるかもしれません。それには、このガイドに従ってください。
デバッグ目的のみに、証明書のチェックを無効にすることもできます。これは、安全でない -k フラグを使用して curl を実行することに相当します(curl -k https://some-domain):
Copied!1 2 3 4 5 6type: magritte-rest-v2 sourceMap: my_api: type: magritte-rest url: https://example.com insecure: true # セキュリティ対策が無効になっていることを意味します
TLSバージョン
デフォルトでは、プラグインは現代のTLSバージョン(TLSv1.2とTLSv1.3)でのみ接続します。
古いバージョンを使用するには、設定でTLSバージョンを指定してください:
Copied!1 2 3 4 5 6type: magritte-rest-v2 sourceMap: my_api: # ここでAPIを定義しています type: magritte-rest # このAPIのタイプは'magritte-rest'です url: https://example.com # このAPIのURLは'https://example.com'です tlsVersion: 'TLSv1.1' # このAPIのTLSバージョンは'TLSv1.1'です
サポートされているバージョン: TLSv1.3, TLSv1.2, TLSv1.1, TLSv1, SSLv3。
シンクを作成する
シンクを作成するには、magritte-rest-v2 ソースの上部から "Create Sync" ボタンをクリックします。基本ビューでは、データを取得するための1つ以上の呼び出しを作成する手順をガイドします。高度なビューでは、YAML 設定を直接編集することができます。これらのビューはページの右上で切り替えることができます。
シンクには少なくとも1つの呼び出しが必要です。基本ビューでは、"Perform calls in sequence" の見出しの下の "Add" ボタンをクリックして新しい呼び出しを作成することができます。
次に、呼び出しが "Single Call" を選択して一度だけ行われるべきか、ループ、時間範囲、日付範囲、リスト、または結果のページングに基づいて複数回行われるべきかを指定できます。
各呼び出しには、クエリ時にソース URL に追加されるパスが必要です。例えば、ソースが URL https://my-ap-source.com を持っていて、パスに /api/v1/get-documents を使用すると、呼び出しは https://my-ap-source.com/api/v1/get-documents をクエリします。
このセクションでは、一般的なシナリオを対象とした YAML 設定のリストを紹介します:
このドキュメントでは、以下のトピックについても追加のガイダンスを提供します:
一般的なシナリオ
DateTimeベースのAPI
/daily_data?date=2020-01-01 で各日付のCSVレポートを提供するAPIを想定します。この例では、これらのレポートが利用可能になると同時に取り込むことを目指しています。これを達成するために、レポートが同期された最後の日付を記憶する毎日の同期をスケジュールすることができます。これにより、今日までの未同期の日付のレポートを自動的に取得します:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26type: rest-source-adapter2 outputFileType: csv incrementalStateVars: incremental_date_to_query: '2020-01-01' initialStateVars: yesterday: type: magritte-rest-datetime-expression offset: '-P1D' # 1日前 timezone: UTC # タイムゾーン formatString: 'yyyy-MM-dd' # フォーマット restCalls: - type: magritte-increasing-date-param-call checkConditionFirst: true paramToIncrease: date_to_query # 増加させるパラメータ increaseBy: P1D # 1日ずつ増加 initValue: '{%incremental_date_to_query%}' # 初期値 stopValue: '{%yesterday%}' # 終了値 format: 'yyyy-MM-dd' # フォーマット method: GET # HTTPメソッド path: '/daily_data' # APIのパス parameters: date: '{%date_to_query%}' # 日付パラメータ extractor: - type: magritte-rest-string-extractor fromStateVar: 'date_to_query' # 状態変数から var: 'incremental_date_to_query' # 変数に代入
上記の設定と等価の Python スニペットを比較すると参考になるかもしれません。あなたの API がインターネット上で利用可能な場合、直接 外部 Python トランスフォーム を使用することができます。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31import requests from datetime import datetime, timedelta # 増分状態をロードする incremental_state = load_incremental_state() # 増分状態がない場合は、'2020-01-01'からクエリを開始する if incremental_state is None: incremental_state = {'incremental_date_to_query': '2020-01-01'} # 昨日の日付を取得 yesterday = datetime.utcnow() - timedelta(days=1) # クエリする日付を増分状態から取得 date_to_query = incremental_state['incremental_date_to_query'] # 文字列から日付形式に変換 date_to_query = datetime.strptime(date_to_query, '%Y-%m-%d') # 昨日の日付がクエリする日付以上の間、以下の操作を行う while yesterday >= date_to_query: # 指定された日付のデータを取得 response = requests.get(source.url + '/daily_data', params={ 'date': date_to_query.strftime('%Y-%m-%d') }) # データをアップロード upload(response) # クエリする日付を1日進める date_to_query += timedelta(days=1) # 増分クエリ日付を更新 incremental_date_to_query = date_to_query # 増分状態を保存 save_incremental_state({'incremental_date_to_query': incremental_date_to_query})
ページベースの API
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29type: rest-source-adapter2 # 出力ファイルのタイプを設定します。ここではjson形式を指定しています。 outputFileType: json restCalls: - type: magritte-paging-inc-param-call # ページ番号を増やすためのパラメータを設定します。 paramToIncrease: page # 初期値を設定します。ここでは0を指定しています。 initValue: 0 # 増加量を設定します。ここでは1を指定しています。 increaseBy: 1 # HTTPメソッドを設定します。ここではGETを指定しています。 method: GET # データを取得するためのパスを設定します。 path: '/data' parameters: # ページ番号を設定します。 page: '{%page%}' # 1ページあたりのエントリ数を設定します。ここでは1000を指定しています。 entries_per_page: 1000 extractor: - type: magritte-rest-json-extractor # データを抽出し、変数に割り当てます。ここでは'/items'を'page_items'に割り当てています。 assign: page_items: '/items' # 条件を設定します。ここでは、'page_items'が空でない場合に処理を続行することを指定しています。 condition: type: magritte-rest-non-empty-condition var: page_items
もし開発者であれば、上記の設定を等価なPythonスニペットと比較することで理解しやすくなるかもしれません:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14import requests page = 0 # ページ番号を初期化 while True: # 無限ループを開始 response = requests.get(source.url + '/data', params={ 'page': page, # 現在のページ番号を指定 'entries_per_page': 1000 # 1ページあたりのエントリ数を1000に指定 }) upload(response) # レスポンスをアップロード page += 1 # ページ番号を1増やす page_items = response.json().get('items') # レスポンスからアイテムを取得 if not page_items: # アイテムがなければループを終了 break
オフセットベースのAPI
以下は、ElasticSearchの基本的な検索APIの例です:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21type: rest-source-adapter2 # RESTソースアダプタタイプ2 outputFileType: json # 出力ファイルのタイプはjson restCalls: - type: magritte-paging-inc-param-call # ページングを増やすパラメータを呼び出すタイプ paramToIncrease: offset # 増加するパラメータはoffset initValue: 0 # 初期値は0 increaseBy: 100 # 100ずつ増加 method: POST # メソッドはPOST path: '/_search' # パスは'_search' body: |- # ボディ部分 { "from": {%offset%}, # 開始地点はoffset "size": 100 # サイズは100 } extractor: # データ抽出部 - type: magritte-rest-json-extractor # JSON抽出タイプ assign: # 割り当て hits: '/hits' # hitsへのパス condition: # 条件 type: magritte-rest-non-empty-condition # 非空の条件タイプ var: hits # 変数はhits
次のページへのリンクベースのAPI
次のページのトークンは、カーソル、継続、またはページネーションのトークンとしてもよく知られています。
以下に、ElasticSearchの検索とスクロールのAPIの例を示します:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28type: rest-source-adapter2 outputFileType: json restCalls: - type: magritte-rest-call method: GET path: /my-es-index/_search?scroll=1m parameters: scroll: 1m extractor: - type: json assign: scroll_id: /_scroll_id # スクロールIDを割り当てる - type: magritte-do-while-call method: GET checkConditionFirst: true # 最初に条件を確認する path: /_search/scroll parameters: scroll: 1m scroll_id: '{%scroll_id%}' # スクロールIDをパラメータとして使用する extractor: - type: json assign: scroll_id: /_scroll_id # スクロールIDを更新する hits: /hits # ヒットを割り当てる timeBetweenCalls: 0s # コール間の時間を0秒に設定する condition: type: magritte-rest-non-empty-condition var: hits # hits変数が空でない場合、繰り返しを続ける
以下は、AWS nextToken ページネーション API の例です:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33type: rest-source-adapter2 outputFileType: json restCalls: - type: magritte-rest-call method: POST path: /findings/list extractor: - type: json assign: nextToken: /nextToken allowNull: false allowMissingField: true requestMimeType: application/json body: '{}' # 日本語: 最初の REST API コール - type: magritte-do-while-call method: POST checkConditionFirst: true path: /findings/list extractor: - type: json assign: findings: /findings nextToken: /nextToken allowNull: false allowMissingField: true condition: type: magritte-rest-available-condition var: nextToken timeBetweenCalls: 0s requestMimeType: appliation/json body: '{"nextToken":"{%nextToken%}"}' # 日本語: 次のトークンが利用可能な間、繰り返し REST API コールを行う
レポートのトリガーとダウンロード
以下の sync は、3つの相互依存するステップが必要なAPIのためのものです。
- 本文がエンドポイントに投稿され、IDを含むレスポンスが返されます。
- この ID を次のエンドポイントで使用してレポートを取得する必要があります。ただし、レポートはすぐには準備できないため、レスポンスにはレポートが完了しているかどうかを定義する
statusというフィールドが含まれています。 - レポートが完了したら、第3のエンドポイントからレポートを取得できます。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33type: rest-source-adapter2 # タイプ:RESTソースアダプター2 outputFileType: json # 出力ファイルタイプ:JSON restCalls: # RESTコール - type: magritte-rest-call # タイプ:マグリットRESTコール path: '/findRelevantId' # パス:/findRelevantId method: POST # メソッド:POST requestMimeType: application/json # リクエストMIMEタイプ:application/json extractor: # 抽出器 - type: json # タイプ:JSON assign: # 割り当て id: /id # ID:/id body: > # 本文: body saveResponse: false # レスポンスを保存:しない - type: magritte-do-while-call # タイプ:マグリットdo-whileコール path: '/reportReady' # パス:/reportReady method: GET # メソッド:GET parameters: # パラメータ: id: '{%id%}' # ID:{%id%} extractor: # 抽出器 - type: magritte-rest-json-extractor # タイプ:マグリットREST JSON抽出器 assign: # 割り当て status: /status # ステータス:/status condition: # 条件 type: "magritte-rest-regex-condition" # タイプ:マグリットREST正規表現条件 var: status # 変数:ステータス matches: "(processing|queued)" # マッチング:"(processing|queued)" timeBetweenCalls: 8s # コール間の時間:8秒 saveResponse: false # レスポンスを保存:しない - type: magritte-rest-call # タイプ:マグリットRESTコール path: '/getReport/{%id%}' # パス:/getReport/{%id%} method: GET # メソッド:GET requestMimeType: application/json # リクエストMIMEタイプ:application/json
Extractor は、状態に保存するフィールドを定義します。これらの変数は、以降のすべての REST コールで利用可能であることに注意してください。保存された変数を注入するには、変数名を {%%} で囲みます。2 番目の do-while コールは、ステータス変数がキューに入れられていないか、処理中でなくなるまでリクエストを送信するループを実装します。
一部の API では、status エンドポイントがなく、代わりに getReport エンドポイントをポーリングし、レポートが準備できるまで空の応答を提供する必要があります。次の設定は、そのようなシナリオに対処する方法を示しています。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20type: rest-source-adapter2 outputFileType: json restCalls: - type: magritte-do-while-call # レポートを取得するパス path: '/getReport/{%id%}' method: GET extractor: - type: magritte-rest-string-extractor # 応答を格納する変数 var: response # 条件を設定 condition: type: magritte-rest-not-condition condition: type: magritte-rest-non-empty-condition # 条件に使用する変数 var: response # コール間の待機時間 timeBetweenCalls: 8s
getReport エンドポイントがレポートが準備できるまで 204 ステータスコードを返す場合、次のように処理できます。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18type: rest-source-adapter2 outputFileType: json restCalls: - type: magritte-do-while-call # '/getReport/{%id%}'というパスでGETメソッドを使用してデータを取得します path: '/getReport/{%id%}' method: GET extractor: - type: magritte-rest-http-status-code-extractor # レスポンスコードをresponseCodeとして割り当てます assign: responseCode condition: type: magritte-rest-regex-condition var: responseCode # レスポンスコードが204と一致するかどうかを確認します matches: 204 # 各呼び出しの間に8秒の待機時間を設定します timeBetweenCalls: 8s
インクリメンタル同期
このプラグインはインクリメンタル同期に対応しています。これを行うには、stateから同期のインクリメンタルstateとして保存する変数を選択し、incrementalStateVarsを指定してください:
Copied!1 2 3type: rest-source-adapter2 incrementalStateVars: var_name: initial_value # インクリメンタルメタデータが見つからない場合に使用される初期値
Copied!1 2 3type: rest-source-adapter2 # タイプ: RESTソースアダプター2 incrementalStateVars: # 増分ステート変数 lastModifiedDate: 20190101 # 最終更新日: 20190101
保存された増分 state は、同期を実行する際の初期 state として使用されます。
より詳細な例:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30type: rest-source-adapter2 outputFileType: json incrementalStateVars: # 'Some initial start time'という初期時間を設定 lastModifiedTime: 'Some initial start time' initialStateVars: # 現在の時間を取得 currentTime: type: magritte-rest-datetime-expression # 'Some timezone, e.g. Europe/Paris'というタイムゾーンを設定 timezone: 'Some timezone, e.g. Europe/Paris' # 日時のフォーマットを指定 'https://docs.oracle.com/javase/8/docs/api/java/time/format/DateTimeFormatter.html' formatString: 'Some format string https://docs.oracle.com/javase/8/docs/api/ \ java/time/format/DateTimeFormatter.html' restCalls: - type: magritte-rest-call # APIのエンドポイントを指定 path: /my/values # HTTPメソッドを指定 method: GET parameters: # 開始時間を設定 from: '{%lastModifiedTime%}' # 終了時間を設定 until: '{%currentTime%}' extractor: # 最終更新時間を現在の時間に更新 - type: magritte-rest-string-extractor var: lastModifiedTime fromStateVar: currentTime
詳細なドキュメンテーション
API ソースを 2 つ以上追加する場合、各 REST コールで使用するソースを source 属性で指定する必要があります。
同期
同期設定には次のフィールドが含まれています。
Copied!1 2 3 4 5 6 7 8 9type: rest-source-adapter2 restCalls: [calls] # Callsについてのドキュメントは下記を参照してください initialStateVars: {variableName}: {variableValue} # 初期状態の変数名とその値 incrementalStateVars: {variableName}: {variableValue} # 逐次的な状態の変数名とその値 outputFileType: json # oneFilePerResponseの場合、必須 cacheToDisk: デフォルトではTrueになっています oneFilePerResponse: デフォルトではTrue; Trueに設定する場合、"outputFileType"が必要です
outputFileType を設定するには、oneFilePerResponse が true である必要があります。そうでない場合、レスポンスはデータセット内の行として保存されます。レスポンスタイプに基づいた推奨オプションについては、以下のレスポンスの保存 を参照してください。
レスポンスの保存
バイナリレスポンスやレスポンスサイズの合計が 100MB を超える場合に推奨されます:
Copied!1 2 3cacheToDisk: true # ディスクにキャッシュする、デフォルトはfalse outputFileType: [任意のファイル形式、例:txt, json, jpg] # 出力ファイルの形式を指定します。 oneFilePerResponse: true # 一つのレスポンスごとに一つのファイルを生成します、デフォルトなので指定する必要はありません
非バイナリレスポンスで数 MB までおよび合計レスポンスサイズが 100 MB 以下の場合、次のことをお勧めします:
Copied!1 2cacheToDisk: false # ディスクにキャッシュ:偽 oneFilePerResponse: false # 応答ごとに一つのファイル:偽
ディスクに収まらない応答を持つ同期で、合計同期時間が短い(3分以内)場合は、以下の方法をお勧めします:
Copied!1 2 3cacheToDisk: false # ディスクへのキャッシュを無効にする oneFilePerResponse: true # 1つのレスポンスごとに1つのファイルを使用する outputFileType: [any file format, e.g. txt, json, jpg] # 任意のファイル形式(例:txt、json、jpg)
コール
コアコールフィールド
すべてのコールはベースとなる RestCall オブジェクトから継承され、以下のフィールドが含まれます:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28type: Restコールタイプ path: エンドポイント method: GET | POST | PUT | PATCH # 以下はすべて任意です source: この呼び出しに使用するAPIソース。 # 複数のAPIソースがある場合、これは必須です。 parameters: リクエストと一緒に渡すパラメータのマップ # デフォルトは空のマップ saveResponse: レスポンスをファウンドリに保存するかどうか # デフォルトはTrue body: 投稿するボディ formBody: # x-www-form-urlencodedの投稿で使用するパラメータのマップ。 # 任意で、x-www-form-urlencodedのエンドポイントをヒットする場合にのみ、ボディの代わりに使用します。 param1: value1 requestMimeType: application/json headers: リクエストヘッダー、これらはソースヘッダーに追加されますが、一致するヘッダーは置き換えられます # validResponseCodes: 任意で、APIコーラーが終了しないHTTPレスポンスコードのセット。 # 設定されていない場合、有効なHTTPレスポンスコードは200、201、204です。 validResponseCodes: - 200 - 201 - 204 # retries: デフォルトは0。リクエストはキャンセル、接続問題、またはタイムアウトのために失敗する可能性があります。 # この呼び出しによって行われるリクエストごとの所望のリトライ回数を設定することができます。 retries: 0 extractor: エクストラクタオブジェクトのリスト、エクストラクタを参照してください # ファイル名テンプレート 例えば 'data_{%page%}', # それ以外の場合、ファイル名は '[sourceName][path][parameters]'になります filename: '<必要でなければ上書きしない>' addTimestampToFilename: デフォルトはtrue、タイムスタンプをファイル名に追加すべきかどうか
上記のフィールドにさらにフィールドを追加することができます。
REST コール
Copied!1 2type: magritte-rest-call # タイプ: マグリット-REST-コール
単一のリクエストを実行します。コアコールと同じYAML設定を使用します。
インクリメンタルなページングコール
条件が満たされる間、増加するパラメーターを持つ同じリクエストを実行します。通常、ページングに使用されます。増加させるパラメーターは、パスまたは parameters: セクションのいずれかに含まれている場合、その値が {%paramToIncrease%} であるべきであることに注意してください。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20type: magritte-paging-inc-param-call # 増加するパラメータへのステートキー。 paramToIncrease: state key to param to increase. # "true"に設定すると、whileループに相当します。"false"(デフォルト)はdo-whileループに相当します。 checkConditionFirst: when set to "true", equivalent to a while loop. When "false" (default) equivalent to do-while loop. # 増加パラメータの初期値。 initValue: Initial value of increasing parameter. # 各イテレーションでパラメータを何だけ増やすか。 increaseBy: How much to increase the parameter by in each iteration. # 各イテレーションで実行する呼び出しのリスト。ネストされた呼び出しを行うために使用され、オプションです。 onEach: List of calls to run in each iteration. Optional and used to do nested calls. # リクエストを続ける条件オブジェクト。条件が真である限り、新しいリクエストが作成されます。 # 条件は最初のリクエストの後にのみ確認されるため、これはdo-whileループのように動作します。 condition: Condition object that keeps requests going. As long as the condition is true, a new request is created. The condition is checked only after the first request, so this acts similarly to a do-while loop. # エラーをスローする前に実行するイテレーションの最大数。 maxIterationsAllowed: How many iterations to run before throwing an error. # リクエスト間で待つ時間(オプション) timeBetweenCalls: (optional) time to wait between requests
日付の増分呼び出し
特定の条件が満たされるまで、増加する日付パラメーターで同じリクエストを実行します。日付を順に処理するために使用されます。これは LocalDate と Period タイプを使用するため、利用可能な最も細かい増分は1日です。これは日付のみのマッチングで機能します。より細かく増分する必要がある場合は、magritte-increasing-time-param-callを参照してください。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16type: magritte-increasing-date-param-call # 増加するパラメータへの状態キー。 paramToIncrease: state key to param to increase. # "true"に設定すると、whileループと同等になります。"false"(デフォルト)の場合はdo-whileループと同等です。 checkConditionFirst: when set to "true", equivalent to a while loop. When "false" (default) equivalent to do-while loop. # 増加パラメータの初期値。 initValue: Initial value of increasing parameter. # 各イテレーションでパラメータを何期間増加させるか、java.time.Periodとして解析可能。 increaseBy: How much to increase the parameter by in each iteration, parseable as a java.time.Period # 使用される最後の日付、該当する場合はこの値を含む。 stopValue: The last date which will be used, including this value if applicable. # 各呼び出しのDateTimeパラメータの形式(java.time.format.DateTimeFormatter)、initValueおよびstopValueと同じ。 format: The format (java.time.format.DateTimeFormatter) for the DateTime parameter in each call, the same as initValue and stopValue. # (オプション)リクエスト間で待つ時間 timeBetweenCalls: (optional) time to wait between requests
インクリメンタルタイムコール
ある条件が満たされるまで、増加するDateTimeパラメーターを用いて同じリクエストを行います。DateTimeを通じて反復するために使用されます。 この機能はOffsetDateTimeとDurationタイプを使用し、magritte-incrementing-date-param-callとは異なります。 OffsetDateTimeは夏時間の変更を考慮に入れません。APIがDateTimeを扱う方法に予期しないギャップが生じないように確認してください。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15type: magritte-increasing-time-param-call # paramToIncrease: 増加させるパラメータへの状態キー。 paramToIncrease: 増加させるべきパラメータへの状態キー。 # checkConditionFirst: "true"に設定した場合、whileループに相当します。"false"(デフォルト)はdo-whileループに相当します。 checkConditionFirst: "true"に設定すると、whileループと同等になります。"false"(デフォルト)はdo-whileループと同等です。 # initValue: 増加パラメータの初期値。 initValue: 増加パラメータの初期値。 # increaseBy: 各反復でパラメータをどれだけ増やすか、java.time.Durationとして解析可能な値 increaseBy: 各イテレーションでパラメータをどれだけ増加させるか、java.time.Durationとして解析可能な値。 # stopValue: 最後に使用されるDateTime、該当する場合はこの値を含む。 stopValue: 最後に使用されるDateTimeで、該当する場合はこの値を含みます。 # format: 各呼び出しのDateTimeパラメータのフォーマット(java.time.format.DateTimeFormatter)、initValueとstopValueと同じ。 format: 各呼び出しのDateTimeパラメータのフォーマット(java.time.format.DateTimeFormatter)、これはinitValueとstopValueと同じです。 # timeBetweenCalls: (オプション)リクエスト間の待機時間 timeBetweenCalls: (任意)リクエスト間の待機時間
Do while
特定の条件が満たされなくなるまでリクエストを実行します。 コアコールフィールドに加えて、2つのフィールドを提供する必要があります。
Copied!1 2 3 4 5type: magritte-do-while-call timeBetweenCalls: リクエスト間の待機時間 # time to wait between requests checkConditionFirst: "true"に設定した場合、whileループと同等。"false"(デフォルト)の場合、do-whileループと同等。 condition: リクエストを続ける条件オブジェクト。条件が真である限り、新しいリクエストが作成されます。 maxIterationsAllowed: エラーをスローする前に実行する反復の最大数。デフォルトは50。
オプションとして、最初の呼び出しをブートストラップするための初期 state を提供できます。
例えば:
Copied!1 2initialState: nextPage: "" # 初期状態:次のページは空("")
初期の state と増分の state が競合する場合、増分の state が初期の State を上書きします。
Iterable state Call
反復可能な state 要素の各要素に対してリクエストを行います。
Copied!1 2 3 4 5 6 7 8 9type: magritte-iterable-state-call timeBetweenCalls: 5s # 各呼び出し間の時間を制限する iterableField: イテレートする状態キー。この変数はイテラブルである必要があります。 iteratorExtractor: イテラブル内の各要素で実行するエクストラクタのリスト。 onEach: 各イテレーションで実行する呼び出しのリスト。オプションで、ネストされた呼び出しを行うために使用されます。 maxIterationsAllowed: エラーをスローする前に実行するイテレーションの最大数。デフォルトは50です。 parallelism: 同期に使用するスレッドの整数数。仮定/制限には、リクエストの副作用がないこと、 呼び出しが行われる順序や状態を更新する応答に関して保証がないこと、呼び出し間に時間がないことが含まれます。 このフィールドはオプションで、デフォルトは1です。
エクストラクター
エクストラクターは、レスポンスまたは state 変数から変数を保存する方法を定義します。URL、URLパラメーター、またはリクエストボディの中で {%var_name_1%} のように state から変数を参照することができます。
エクストラクターのデフォルトの動作は、レスポンスから値を抽出することです。オプションとして、Stateから抽出するための fromStateVar 設定を追加することができます。これにより、異なるエクストラクターを一つずつ順番に実行することができます。例を挙げますと:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15type: rest-source-adapter2 outputFileType: csv restCalls: - type: magritte-rest-call path: /my/path/index.html source: mysource method: GET extractor: - type: magritte-rest-json-extractor assign: full_name: /my/field/full_name - type: magritte-rest-regexp-extractor fromStateVar: full_name assign: names: '\w+'
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15type: rest-source-adapter2 # RESTソースアダプタタイプ2 outputFileType: csv # 出力ファイルタイプはCSV restCalls: - type: magritte-rest-call # Magritte RESTコールタイプ path: /my/path/index.html # パス source: mysource # ソース method: GET # メソッドはGET extractor: - type: magritte-rest-json-extractor # Magritte REST JSON抽出タイプ assign: full_name: /my/field/full_name # full_nameに割り当てるフィールド - type: magritte-rest-regexp-extractor # Magritte REST 正規表現抽出タイプ fromStateVar: full_name # full_nameから抽出 assign: names: '\w+' # namesに割り当てる正規表現
すべてのエクストラクターには、使用可能な条件チェックが組み込まれています:
Copied!1condition: 入力された状態が指定された条件を満たしているか確認します。満たしていない場合、エクストラクターを実行しないでください。
JSONエクストラクター
すべてのJSONエクストラクターは Jackson JsonNode を使用し、同じ表記法に従います。
フィールドの参照についてのクイックガイド:
JSON {"id":1} がある場合:
"/id"を使用すると、1が返されます"/"を使用すると、{"id":1}が返されます
リストがある場合、例えば [1,2,3] や [{"id":1},{"id":2}] など:
""を使用すると、リストが返されます。
ワイルドカードは、リスト内のすべてのアイテムのサブインデックスまたはフィールドを参照するために使用できます。例えば:
ネストしたリストを含むフィールドがある場合、例えば { "result": [[1], [2, 3, 4]] } など:
"/result/*/0"を使用すると、[1,2]が返されます。
オブジェクトのリストを含むフィールドがある場合、例えば { "result": [{ "foo": 1}, {"foo": 2}]} など:
"/result/*/foo"を使用すると、[1,2]が返されます。
JSONエクストラクターの割り当て
レスポンス内のフィールドを単純にステートに配置するエクストラクターです。YAML設定は保存する変数のマップです。 左側の文字列はステート内の変数の名前で、右側の文字列は変数へのパスです。
JSONエクストラクターはワイルドカードをサポートしています - JSON [{"id":1}, {"id":2}] がある場合、/*/id を使用すると [1,2] が返され、"" (空文字列)を使用すると全リストが返されます。
Copied!1 2 3 4type: json assign: var_name_1: /field-name1 # フィールド名1に変数名1を割り当てる var_name_2: /field_name2 # フィールド名2に変数名2を割り当てる
デフォルトでは、抽出されたフィールドが null 値を持っているか存在しない場合、呼び出しは失敗します。
これらの状況で呼び出しを失敗させないための以下のフラグが利用可能です:
- フィールドが存在しないか、フィールドが null 値を持っている場合に失敗しないように、
allowMissingFieldを使用します。 - 存在するフィールドが null 値を持っている場合に失敗しないように、
allowNullを使用します。 - JSON 応答にエスケープされていない制御文字(
\nなど)が含まれている場合に失敗しないように、allowUnescapedControlCharsを使用します。
Copied!1 2 3 4 5type: json allowMissingField: true assign: var_name_1: /field-name1 # フィールド名1へのパス var_name_2: /field_name2 # フィールド名2へのパス
JSONエクストラクターを追加する
Copied!1 2 3 4type: magritte-rest-append-json-extractor appendFrom: /レスポンス内の配列を追加するフィールド appendFromItem: /各配列要素から抽出するフィールド # 任意 appendTo: 要素を追加する状態の変数名。
以下、各行の日本語コメントです。
Copied!1 2 3 4type: magritte-rest-append-json-extractor # magritte-rest-append-json-extractorのタイプ appendFrom: /レスポンス内の配列を追加するフィールド # レスポンス内の配列を追加元とするフィールドを指定 appendFromItem: /各配列要素から抽出するフィールド # 任意 # 各配列要素から抽出するフィールド(任意) appendTo: 要素を追加する状態の変数名。 # 要素を追加する対象となる状態の変数名を指定
応答が以下のようになっている場合:
Copied!1 2 3 4 5 6 7{ "things": [ // ここはオブジェクトのリストです {"name": "dummy", "id": "1"}, // このオブジェクトは"name"と"id"の2つのプロパティを持っています {"name": "dummy2", "id": "2"} // 同様に、このオブジェクトも"name"と"id"の2つのプロパティを持っています ] }
次に、YAML:
Copied!1 2 3 4type: magritte-rest-append-json-extractor # タイプ:MagritteのRESTアペンドJSONエクストラクタ appendFrom: /things # 追加元:/things appendFromItem: /id # 追加元アイテム:/id appendTo: var # 追加先:var
[1,2] を var に追加することになります。
別の方法としては、以下のように使用できます:
Copied!1 2 3 4 5 6# タイプは magritte-rest-append-json-extractor を指定します type: magritte-rest-append-json-extractor # appendFrom: /things は /things からデータを取得することを指定しています appendFrom: /things # appendTo: var は取得したデータを var 変数に追加することを指定しています appendTo: var
結果として、state変数に[{"name": "dummy", "id": "1"}, {"name": "dummy", "id": "2"}]が追加されます。
Max JSONエクストラクター
Copied!1 2 3 4 5 6 7 8 9 10type: magritte-rest-max-json-extractor # typeは、このプログラムがmagritte-rest-max-json-extractorという種類のものであることを示しています list: /field in response that contains an array to max over. # listは、最大値を計算するための配列を含むレスポンス内のフィールドを示しています item: /field per array element to extract # itemは、配列の各要素から抽出するフィールドを示しています var: state variable to save the max value to. # varは、最大値を保存するための状態変数を示しています previousVal: state variable to get the current max value from# Optional # previousValは、現在の最大値を取得するための状態変数を示しています(オプション)
応答が以下のように表示された場合:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13{ // "things"は配列を指します。この配列には複数のオブジェクトが含まれています。 "things": [ // これは最初のオブジェクトです。 // "name"と"value"という2つのフィールドがあります。 // "name"の値は"dummy"で、"value"の値は"1"です。 {"name": "dummy", "value": "1"}, // これは2つ目のオブジェクトです。 // "name"の値は"dummy2"で、"value"の値は"2"です。 {"name": "dummy2", "value": "2"} ] }
次に、YAMLは以下の通りです:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15# タイプ: magritte-rest-max-json-extractor # これは特定のタイプのデータ抽出器を指定します。この場合、Magritte RESTful APIから最大JSON値を抽出します。 type: magritte-rest-max-json-extractor # リスト: /things # これはデータ抽出が行われる特定のリストまたはコレクションを指定します。 list: /things # アイテム: /id # これはリスト内の特定のアイテムまたはエンティティを指定します。この場合、それぞれの 'thing' の 'id' を参照します。 item: /id # 変数: max_value # これは抽出された最大値を保存するための変数を指定します。 var: max_value
2 を max_value に保存することになります。
別の方法として、すでに max_value に値 5 があると仮定すると:
Copied!1 2 3 4 5type: magritte-rest-max-json-extractor # タイプはmagritte-rest-max-json-extractor list: /things # "/things"からリストを取得します item: /id # 各項目から"/id"を取得します var: max_value # 取得した値の最大値を格納する変数名は"max_value" previousVal: max_value # 前回の最大値を格納する変数名も"max_value"
max_value を 5 に等しくします。
Streaming JSON 最終行抽出器
レスポンスが各行にJSONファイルを含むStreaming JSON(NDJSON)形式のための抽出器です。通常、この形式はデータセットを返すために使用され、したがって各行は同じ形式のJSONを持つべきです。
この抽出器は、NDJSONファイルの最終行からパスから変数を抽出することをサポートしています。
Copied!1 2 3 4type: magritte-rest-last-streaming-json-extractor nodePath: /id # jsonが{'value':'somevalue', 'id':1}のように見える場合、これは1を抽出します varName: id # 値を保存するための状態の変数名 saveNulls: false # nullが変数に保存されるべきか、またはスキップされるべきか (デフォルト: false)
ストリーミング JSON 追加エクストラクタ
エクストラクタは、NDJSON ファイルの各行から変数を配列に抽出するだけでなく、最後に遭遇した変数を抽出することもサポートしています。エクストラクタが null(行が欠けている、キーが欠けている、キーの下の値が null である)に遭遇すると、ループを停止します。
Copied!1 2 3 4 5 6type: magritte-rest-last-streaming-json-extractor nodePath: /id # JSONが {'value':'somevalue', 'id':1} のような場合、この設定で 1 を抽出します arrayVarName: ids # 配列を保存する状態の変数名 optional<lastVarName>: lastId # 配列の最後の値を保存する状態の変数名(オプション) optional<limit>: 10 # 解析する行の数を制限します。lastVarName と一緒に使用して、 # iterableStateCall と組み合わせて extract 実行ごとの呼び出し回数を制限できます
XMLエクストラクター
XMLエクストラクターの割り当て
レスポンス内のフィールドを単純に状態に配置するエクストラクター。YAML設定は、保存する変数のマップです。左側の文字列は状態内の変数の名前で、右側の文字列はxpath表記を使用した変数へのパスです。
Copied!1 2 3 4 5 6type: magritte-rest-xml-extractor assign: # 第1階層のタグから第2階層のタグ内のテキストを取得し、変数名「var_name_1」に割り当てる var_name_1: /top_level_tag/second_level_tag/text() # 第1階層のタグ内のテキストを取得し、変数名「var_name_2」に割り当てる var_name_2: /top_level_tag/text()
HTML エクストラクター
CSS セレクターによる HTML の抽出(サポートされているセレクター構文)。抽出する属性を指定できます。空欄の場合、選択した要素のテキストが返されます。first が true の場合、エクストラクターは最初の要素を文字列または数値として返そうとします。このエクストラクターは、形式が正しくない XML にも使用できます。
Copied!1 2 3 4 5type: magritte-rest-html-extractor # magritte-rest-html-extractorというタイプ var: 'links' # 'links'という変数 selector: "a[href$='pdf']" # 'pdf'で終わるhref属性を持つ<a>タグを選択 attribute: href # href属性を取得する(オプション) first: false # 最初の一つだけを取得するかどうか(オプション、デフォルトはfalse)
提供された例では、links 変数に .pdf で終わるすべてのアンカータグハイパーメディア参照を文字列の配列として保存します。
文字列エクストラクター
文字列エクストラクター
文字列を抽出し、この文字列を定義された変数に割り当てた新しい state を返します。
Copied!1 2 3 4 5 6# タイプ:マグリット-レスト-ストリング-エクストラクター # これは、特定の文字列を抽出するための指定です。 type: magritte-rest-string-extractor # var: '変数名' # '変数名'は抽出した文字列を格納するための変数名を指定します。 var: 'variable_name'
サブストリング抽出器
state の変数からサブストリングを抽出し、別の state に保存します。
Copied!1 2 3 4 5 6type: magritte-rest-substr-extractor start: 2 # 開始インデックス length: 5 # オプション、部分文字列の長さ(開始インデックスを含む)。 # 設定されていない場合、部分文字列は開始インデックス以降のすべての文字列になります。 assign: var_to_save_substring_to # var: state_variable_to_substring - 廃止されました、代わりにfromStateVarを使用してください!
正規表現抽出器
文字列から1つ以上の正規表現を抽出する抽出器です。YAML設定は、保存する変数のマップです。左の文字列は、State内の変数の名前であり、右の文字列は一致させる正規表現です。
Copied!1 2 3 4 5 6type: magritte-rest-regexp-extractor assign: # var_name_1には、1と3の間の文字列、またはaとcの間の文字列を取得します var_name_1: (1(.*)3|a(.*)c) # var_name_2には、NotInStringを取得します var_name_2: (NotInString)
入力される文字列が以下の場合:
abcHelloWorld123
# これは単なる文字列です。コードと関連するコメントはありません。
応答は以下のようになります:
Copied!1 2 3 4{ "var_name_1": ["abc", "123"], // 変数1には、"abc"と"123"の要素が含まれています "var_name_2": [] // 変数2は空のリストです }
以下は、HTML から CSV リンクを抽出し、その後 CSV を取得するための使用例です:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26type: rest-source-adapter2 outputFileType: csv restCalls: - type: magritte-rest-call path: /my/path/index.html source: mysource method: GET extractor: - type: magritte-rest-regexp-extractor assign: file_paths: '(?<=https://www\.mysite\.com)(.*filename.*csv)(?=\")' # saveResponse: falseは、このREST呼び出しの応答を保存しないことを指定します。 saveResponse: false - type: magritte-iterable-state-call source: mysource # timeBetweenCalls: 1sは、呼び出し間の時間を1秒に設定します。 timeBetweenCalls: 1s # iterableField: file_pathsは、反復可能なフィールドをfile_pathsに設定します。 iterableField: file_paths method: GET path: '{%path%}' # saveResponse: trueは、このREST呼び出しの応答を保存することを指定します。 saveResponse: true iteratorExtractor: - type: magritte-rest-string-extractor var: 'path'
このコードはREST APIからデータを取得し、そのデータをCSVファイルに保存する機能を持つYAML構成です。REST APIの呼び出しは2種類で、最初の呼び出しは特定のパスのデータを取得し、2番目の呼び出しはそれを反復し、各ファイルパスからデータを取得します。これらの操作は、特定の時間間隔を設けて行われます。この構成は、データエンジニアリングやデータサイエンスの分野でよく使用されます。
Regexp replace extractor
文字列内の1つの正規表現を置換するExtractorで、PySparkの関数 pyspark.sql.functions.regexp_replace に似ています:
Copied!1 2 3 4type: magritte-rest-regexp-replace-extractor var: result # `state` 変数は、結果文字列で作成または上書きされます pattern: "[a]" # 検索する正規表現 replacement: "A" # 正規表現に一致する部分を置き換える新しい文字列
配列の操作
配列に追加または拡張する
Append Array Extractor は state 変数を入力として取り、それを配列の末尾にプッシュします。この Extractor は、イテラブルな state コールに渡すパスを集めるのに便利です。
Copied!1 2 3type: magritte-rest-append-array-extractor appendTo: target # ターゲットが初期化されていない場合、抽出器は空の配列を初期化します。 fromStateVar: args # 単一の引数(追加)またはコレクション(拡張)のどちらかを受け入れます。
こちらが完全な例です:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42type: rest-source-adapter2 restCalls: - type: magritte-paging-inc-param-call method: GET path: category paramToIncrease: page initValue: 0 increaseBy: 100 parameters: start_element: '{%page%}' num_elements: 100 extractor: - type: magritte-rest-json-extractor assign: res: /response/categories - type: magritte-rest-append-array-extractor fromStateVar: res appendTo: categories until: type: magritte-rest-non-empty-condition var: res - type: magritte-iterable-state-call method: GET path: 'category/{%category%}' timeBetweenCalls: 5s iterableField: categories iteratorExtractor: - type: magritte-rest-string-extractor var: category outputFileType: json # 以下、日本語のコメント # RESTソースアダプタ2の設定 # ページングを含むREST API呼び出し # カテゴリの情報取得 # ページごとに100件ずつ取得 # JSON形式のデータを抽出し、変数resに代入 # 配列にデータを追加 # 結果が空になるまで続ける # カテゴリごとにAPI呼び出し # 5秒間隔で呼び出し # イテレータの設定 # 出力ファイル形式はJSON
その他のエクストラクタ
HTTPステータスコードエクストラクタ
レスポンスからHTTPステータスコードを抽出します。
Copied!1 2 3 4# タイプ: マグリット-REST-HTTP-ステータスコード-エクストラクタ type: magritte-rest-http-status-code-extractor # 割り当て: '変数名' assign: 'variable_name'
Set-Cookie 応答ヘッダーエクストラクター
応答中の Set-Cookie ヘッダーからクッキーを抽出します。
Copied!1 2 3 4 5 6 7type: magritte-rest-set-cookie-header-extractor # 'type'はこのコードの種類を指定します。ここでは'magritte-rest-set-cookie-header-extractor'と指定されています。 assign: var_name_1: cookie_name_in_set_cookie_header # 'assign'は変数に値を割り当てるためのフィールドです。 # 'var_name_1'という変数名に'cookie_name_in_set_cookie_header'という値を割り当てています。
配列要素抽出器
指定された配列から要素を抽出します。
Copied!1 2 3 4type: magritte-rest-array-element-extractor fromStateVar: Array var to extract an element from. # 入力配列から要素を抽出するための配列変数 index: The index of the element in the input array to extract. # 抽出する入力配列内の要素のインデックス toStateVar: Name of the variable to extract the element to. # 要素を抽出する変数の名前
与えられたインデックスパラメーターは、配列の末尾から開始するために負の値にすることができます。例えば、-1 は最後の要素を抽出するために使用します。
タイプキャスト抽出器
変数を入力として受け取り、事前に定義されたキャストロジックを使用して変数のタイプをキャストし、結果を宛先変数に保存する抽出器です。
Copied!1 2 3 4 5 6 7type: magritte-rest-typecast-extractor # エクストラクターへの入力変数。 fromStateVar: Input variable to the extractor. # エクストラクターの出力変数。 toStateVar: Output variable of the extractor. # キャスティング後の出力変数のタイプ。 toType: Type of the output variable after casting.
toType パラメーターは、'java.lang.' パッケージ内の有効なJavaタイプでなければなりません。
有効なタイプの例としては、'String'、'Integer'、または 'java.lang' パッケージと名称 'java.lang.Double' などがあります。
型キャスティングが機能するためには、入力変数のタイプを出力タイプにキャストするための事前定義されたメソッドが存在しなければなりません。 つまり、プラグイン内には設定されたタイプから変数を変換するコードが存在しなければなりません。
注:2つの文字列 a と b の java.util.Arrays を文字列にキャストすると、[a, b] が得られます。一方、2つの文字列 a と b の com.fasterxml.jackson.databind.node.ArrayNode を文字列にキャストすると、["a","b"] が得られます。これは、JSON配列の文字列表現です。
条件
条件はElasticSearchの条件と同様に動作します。現在サポートされている条件は以下のとおりです:
正規表現
Copied!1 2 3type: magritte-rest-regex-condition # タイプ: magritte-rest-regex-condition var: a state variable key # 変数: ステート変数のキー matches: a valid regular expression # マッチ: 有効な正規表現
例:
Copied!1 2 3 4 5 6 7type: "magritte-rest-regex-condition" var: my_state_variable matches: '^\d+$' # 以下のコメントを日本語で追加します # type: "magritte-rest-regex-condition" (マグリットREST正規表現条件) # var: my_state_variable (状態変数の定義) # matches: '^\d+$' (数字のみにマッチする正規表現)
利用可能な条件
指定された変数が利用可能であるか(非 null 値が割り当てられているかどうか)を確認します。
Copied!1 2 3 4 5type: magritte-rest-available-condition # type: magritte-rest-available-condition とは、REST APIが利用可能な状態かを判断するための条件タイプを指定します。 var: a state variable key # var: 状態変数のキーを指定します。
例:
Copied!1 2 3 4# タイプ: マグリット-REST使用可能条件 type: magritte-rest-available-condition # 変数: 自分の状態変数 var: my_state_variable
空でない条件
指定された変数が利用可能で、空でないことを確認します。
Copied!1 2type: magritte-rest-non-empty-condition # タイプ: マグリット-レスト-ノンエンプティ-コンディション var: a state variable key # var: 状態変数キー
例:
Copied!1 2 3type: magritte-rest-non-empty-condition var: my_array_state_variable # コメント: my_array_state_variableは非空の配列であることをチェックする条件
Not 条件
与えられたサブ条件を否定します。
Copied!1 2type: magritte-rest-not-condition condition: A condition to negate. # 条件を否定するための条件です。
例:
Copied!1 2 3 4 5 6 7type: magritte-rest-not-condition # 条件タイプ: Magritte REST "not" 条件 condition: type: magritte-rest-available-condition # 条件: Magritte REST "available" 条件 var: my_state_variable # 変数: 私のステート変数
AND 条件
与えられたすべてのサブ条件が真であることを要求します。
Copied!1 2type: magritte-rest-and-condition conditions: ANDで結合する条件のリスト。
例:
Copied!1 2 3 4 5 6type: magritte-rest-and-condition conditions: - type: magritte-rest-available-condition var: my_state_variable # my_state_variableが利用可能な状態であることを確認 - type: magritte-rest-non-empty-condition var: my_array-state_variable # my_array-state_variableが空でないことを確認
バイナリー条件
Copied!1 2 3 4 5type: magritte-rest-binary-condition toCompare: left: 条件の左側で比較するための `state` キー right: 条件の右側で比較するための `state` キー op: 次のうちの一つ "=", "<", ">", "<=", ">="
例:
Copied!1 2 3 4 5type: magritte-rest-binary-condition toCompare: left: a_state_variable # 左の状態変数 right: another_state_variable # 右の状態変数 op: < # 比較演算子
式
式は、Magritte REST同期の任意の場所で特定の値を計算するために使用できます。抽出器とは対照的に、式の結果は同期の state に依存しません。
DateTime 式
特定の日付と/または時間を供給する式。現在の日付/時間を取得し、指定されたオフセットを追加します。
この初期 state 変数のための他のパラメーター(例えば、トップレベルの initialStateVars: ブロックに入れるべき):
Copied!1 2 3 4 5type: magritte-rest-datetime-expression offset: オプション。現在の日付/時刻から加算または減算する時間。マイナスにすることができます。 timezone: オプション。日付/時刻を計算するタイムゾーン。デフォルトはUTCです。 formatString: オプション。計算された日付と時刻の出力形式。 デフォルトはオフセット付きのISO 8601の日付時刻形式です。
有効なオフセットについては、Java 8 Duration documentationを参照してください。
有効なタイムゾーンについては、Java 8 ZoneId documentationを参照してください。
有効な出力形式の文字列については、Java 8 DateTimeFormatterを参照してください。
リテラル式
リテラル値を提供する式です。
リテラルのタイプは自動的に推定され、リテラル式のログを見ることで確認できます。現在、サポートされているタイプは文字列、数字、およびリストです。
Copied!1 2 3 4type: magritte-rest-literal-expression literalValue: Required. # タイプ: マグリット-レスト-リテラル-エクスプレッション # リテラル値: 必須。
例:
Copied!1 2type: magritte-rest-literal-expression # タイプ: マグリット-REST-リテラル-表現 literalValue: 270 # リテラル値: 270
リストの例:
Copied!1 2 3 4 5type: magritte-rest-literal-expression # "type"は式の種類を示す。ここでは"magritte-rest-literal-expression"が指定されています。 # "magritte-rest-literal-expression"は、リテラル値(具体的な値)を表す表現タイプです。 literalValue: ["it's", "a", "kind", "of", "magic"] # "literalValue"はリテラル値を指定します。ここでは文字列のリスト["it's", "a", "kind", "of", "magic"]が指定されています。
Foundry で JSON を処理する
JSON データを取り込む際に:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14{ "response": { "size": 1000, // アイテムリスト "items": [ // アイテム1 { "item id": 1, "status": { "modifiedAt": "2020-02-11" }, "com.palantir.metadata": { ... } }, // アイテム2 { "item id": 2, "status": { "modifiedAt": "2020-02-12" }, "com.palantir.metadata": { ... } }, // アイテム3 { "item id": 3, "status": { "modifiedAt": "2020-02-13" }, "com.palantir.metadata": { ... } } ] } }
magritte-rest-v2 プラグインを使用すると、各 JSON レスポンスがデータセット内の別々のファイルとして保存されます。
このデータを簡単に処理するために、生データセットにスキーマを適用してください:
{
"fieldSchemaList": [
{
"type": "STRING",
"name": "row",
"nullable": null,
"userDefinedTypeClass": null,
// カスタムメタデータ
"customMetadata": {},
"arraySubtype": null,
"precision": null,
"scale": null,
"mapKeyType": null,
"mapValueType": null,
"subSchemas": null
}
],
// データフレームリーダークラス
"dataFrameReaderClass": "com.palantir.foundry.spark.input.DataSourceDataFrameReader",
// カスタムメタデータ
"customMetadata": {
"format": "text",
"options": {}
}
}
このデータセットをクリーンにし、各 item をデータセットの別々の行として、item のフィールドを行として持つために、Pythonトランスフォームリポジトリを作成します。
次のスニペットを新しい utils/read_json.py ファイルに追加してください:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43from pyspark.sql import functions as F import json import re # スキーマのフラット化 def flattenSchema(df, dontFlattenCols=[], jsonCols=[]): new_cols = [] for col in df.schema: _flattenSchema(col, [], new_cols, dontFlattenCols + jsonCols, jsonCols) print(new_cols) return df.select(new_cols) # スキーマのフラット化の補助関数 def _flattenSchema(field, path, cols, dontFlattenCols, jsonCols): curentPath = path + [field.name] currentPathStr = '.'.join(curentPath) if field.dataType.typeName() == 'struct' and currentPathStr not in dontFlattenCols: for field2 in field.dataType.fields: _flattenSchema(field2, curentPath, cols, dontFlattenCols, jsonCols) else: fullPath = '.'.join(['`{0}`'.format(col) for col in curentPath]) newName = '_'.join(curentPath) sanitized = re.sub('[ ,;{}()\n\t\\.]', '_', newName) if currentPathStr in jsonCols: cols.append(F.to_json(fullPath).alias(sanitized)) else: cols.append(F.col(fullPath).alias(sanitized)) # JSON の解析 def parse_json(df, node_path, spark): rdd = df.dataframe().rdd.flatMap(get_json_rows(node_path)) df = spark.read.json(rdd) return df # JSON ノードの取得 def get_json_rows(node_path): def _get_json_object(row): parsed_json = json.loads(row[0]) node = parsed_json for segment in node_path: node = node[segment] return [json.dumps(x) for x in node] return _get_json_object
次のようなコードで Pythonトランスフォームを作成することができます:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15from transforms.api import transform, Input, Output from utils import read_json # 変換デコレータの定義: 入力と出力のパスを指定 @transform( output=Output("/output"), json_raw=Input("/raw/json_files"), ) def my_compute_function(json_raw, output, ctx): # JSONファイルを読み込み、データフレームに変換 df = read_json.parse_json(json_raw, ['response', 'items'], ctx.spark_session) # JSONカラムのスキーマをフラット化 df = read_json.flattenSchema(df, jsonCols=['com.palantir.metadata']) # データフレームを出力先に書き込む output.write_dataframe(df)
これによりデータセットが作成されます:
item_id | status_modifiedAt | com_palantir_metadata
1 | "2020-02-11" | "{ ... }" # アイテムID 1、状態変更日時 2020年2月11日、メタデータ
2 | "2020-02-12" | "{ ... }" # アイテムID 2、状態変更日時 2020年2月12日、メタデータ
3 | "2020-02-13" | "{ ... }" # アイテムID 3、状態変更日時 2020年2月13日、メタデータ