注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
JDBC ソース
Foundry を JDBC ソースに接続して、ほとんどのリレーショナルデータベースやデータウェアハウスとの間でデータの読み取りと同期を行います。
ソースが設定されると、抽出定義で指定された SQL クエリを使用してデータベースからのデータ同期方法を柔軟に定義できます。さらに、インクリメンタル同期を設定して、最後に同期が実行されてから更新されたデータのみを読み込むことができます。
設定
- Data Connection アプリケーションを開き、画面右上の+ 新規ソースを選択します。
- 一覧表示されているタイプから特定のソース(BigQuery や PostgreSQL など)を見つけます。コネクタタイプが一覧にない場合は、JDBC を選択してください。
- インターネット経由の ダイレクト接続 を使用するか、中間エージェント経由で接続するかを選択します。
- 以下のセクションの情報を使用して、コネクタの設定を続けるための追加の設定プロンプトに従います。
設定オプション
| パラメーター | 必須? | 説明 |
|---|---|---|
URL | はい | JDBC URL 形式については、ソースシステムのドキュメントを参照し、Java ドキュメントを確認してください。 |
Driver class | はい | データベースに接続する際に使用するドライバークラスを入力します。このドライバーは、Data Connection の実行時にクラスパス上にある必要があります。以下の JDBC ドライバー について詳しく説明しています。 |
Credentials | はい | JDBC 接続のユーザー名とパスワードの資格情報。 |
JDBC properties | いいえ | 接続動作を設定するためのプロパティ名と値を追加します。以下の JDBC プロパティ について詳しく説明しています。 |
Advanced Options | いいえ | このフィールドを展開して、オプションの JDBC 出力設定を追加します。以下の 出力設定 について詳しく説明しています。 |
JDBC ドライバー
デフォルトでは、Data Connection エージェントは、JDBC 互換システムに接続する機能が付属しています。ただし、システムに正常に接続するには、JDBC ドライバー を提供する必要があります。また、通常は特定のドライバーのパブリックドキュメントに記載されているドライバークラスを指定する必要があります。例えば、Snowflake の JDBC ドライバーのクラスは、パブリックドキュメントで見つけることができます。
- エージェントベースのソースでは、Palantir によって署名されたドライバーが必要です。Palantir サポートに連絡して、接続に必要なドライバーにアクセスしてください。署名されたドライバーを入手したら、Data Connection でエージェントにアップロードしてください。
- ダイレクト接続では、インターネット経由で Palantir が署名したドライバーは必要ありません。特定のソースタイプのドキュメント(Google BigQuery など)からドライバーを見つけてダウンロードすることができます。次に、接続を設定する際にドライバーをアップロードできます。
署名されたドライバー
一般的な JDBC セットアップを使用して中間エージェントで作業している場合は、以下の Palantir が署名した JDBC ドライバーを使用して接続を設定します。New Source ページからソースタイル(BigQuery や PostreSQL など)を選択した場合は、ドライバーが自動的に接続に利用可能になります。追加のドライバーを設定する必要はありません。
JDBC プロパティ
必要に応じて、JDBC 接続にプロパティ を追加して、動作を設定することができます。接続設定に追加する特定のソースの利用可能な JDBC プロパティについては、ソースのドキュメントを参照してください。
出力の上書き:ソース
出力ファイルのタイプと JDBC 同期方法を変更するために、出力の上書きを追加することができます。設定された設定は、ソースを使用して行われるすべての JDBC 同期に適用されます。特定の同期のパラメータを上書きするには、同期設定を編集します。出力上書きを追加するには、設定ページの下部にある Advanced Options セクションを展開し、以下の内容を入力します。
| パラメーター | 必須? | デフォルト | 説明 |
|---|---|---|---|
Output | はい | Parquet | 出力ファイルの形式(Avro または Parquet) |
Compression Method | いいえ | なし | SNAPPY、ZSTD、または圧縮方法なしのいずれかを選択します。 |
Fetch size | いいえ | なし | クエリに対するデータベースのラウンドトリップごとにフェッチされる行数。以下のセクションで詳しく説明しています。 |
Max file size | いいえ | なし | 出力ファイルの最大サイズ(バイト単位または行単位)を指定します。以下のセクションで詳しく説明しています。 |
フェッチサイズ
出力のフェッチサイズは、クエリに対するデータベースのラウンドトリップごとにフェッチされる行数です。フェッチサイズを調整することで、同期ごとのネットワークコールの総数を変更できます。ただし、フェッチサイズはメモリ使用量に影響します。フェッチサイズを増やすと、メモリ使用量が増える代わりに同期が速くなります。フェッチサイズ:500 から始めて、適切に調整することをお勧めします。
フェッチサイズの設定は、JDBC ドライバーに基づいて利用できます。出力設定にフェッチサイズパラメータが必要な場合は、ドライバーがフェッチサイズパラメータに対応していることを確認してください。
最大ファイルサイズ
また、出力ファイルの最大サイズ(バイト単位または行単位)を調整することもできます。これにより、Foundry へのデータアップロードのパフォーマンスと耐性が向上する場合があります。
ファイルサイズを Bytes で指定する場合、バイト数は Parquet(128MB)または Avro(64KB)ライターのメモリバッファサイズの少なくとも 2 倍でなければなりません。
バイト単位での最大ファイルサイズは概算です。出力ファイルサイズは、若干小さくなることも大きくなることもあります。
JDBC ソースからのデータ同期
JDBC 同期を設定するには、ソース概要画面の右上にある Explore and create syncs を選択します。次に、Foundry に同期させたいテーブルを選択します。同期する準備ができたら、Create sync for x datasets を選択します。
Foundry での ソース探索 について詳しく説明しています。
JDBC 同期の設定
プリクエリ
プリクエリは、実際の SQL クエリが実行される前に実行される SQL クエリのオプションの配列です。データベースの再読み込みを実際のクエリが実行される前にトリガーする必要があるユースケースでは、プリクエリを使用することをお勧めします。
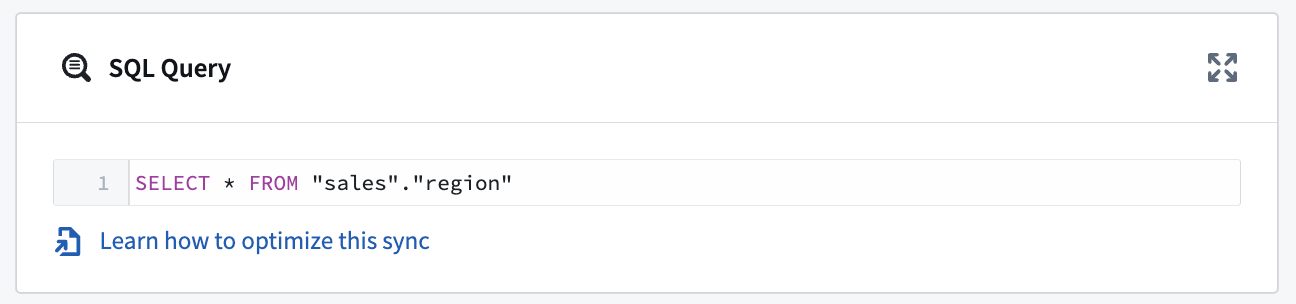
SQL クエリ
1 つの同期ごとに 1 つの SQL クエリを実行できます。このクエリは、データのテーブルを出力として生成する必要があり、ストアドプロシージャの呼び出しのような操作は実行しないでください。クエリの結果は、Foundry の出力データセットに保存されます。
出力の上書き:同期
ソース設定レベルで出力上書きを設定することとは別に、個々の同期出力に特定の上書きを適用することを選択できます。保存された設定は、個々の同期にのみ適用されます。設定オプションについては、上記の 出力の上書き セクションを参照してください。
精度制限
同期設定レベルで、個々の JDBC 同期の Enforce precision limits を選択して、精度制限を設定できます。この制限は、38 桁を超える精度の数値を拒否します。この設定は、デフォルトで無効になっています。
JDBC 同期の最適化
新しい同期を設定している場合や、パフォーマンスの問題が発生している場合は、同期の速度と信頼性を向上させるために、インクリメンタル同期に切り替えたり、SQL クエリを並列化したりすることを検討してください。
まず、インクリメンタル同期方法を試してみてください。問題が解決しない場合は、SQL クエリの並列化に進んでください。
インクリメンタル JDBC 同期
通常、同期は、同期間にデータが変更されたかどうかにかかわらず、対象テーブルから一致するすべての行をインポートします。それに対して、インクリメンタル同期は、同じテーブルからの APPEND スタイルのトランザクションを行うことができます。
インクリメンタル同期は、JDBC ソースから大量のテーブルを取り込む場合に使用できます。インクリメンタル同期を使用するには、テーブルに厳密に単調増加する列が含まれている必要があります。
インクリメンタル JDBC 同期を設定するには、以下の手順に従います。
- Edit syncs ページでトランザクションタイプを
APPENDに設定します。 - 次に、Incremental セクションで Enable を選択します。
- 次に、単調増加する列とその列の初期値を提供します。インポートするつもりのある値よりも小さい値を選択してください。インクリメンタル同期では、すでにインポートされた最大の値よりも大きい値がある行がインポートされます。
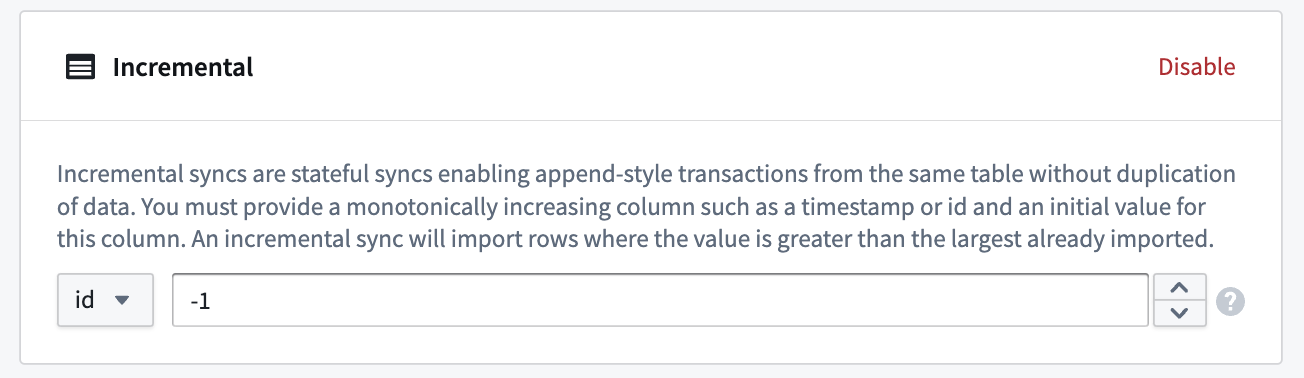
例: 5 TB のテーブルには、JDBC ソースに同期させたい何十億もの行が含まれています。テーブルには、id という単調増加する列があります。同期は、id 列をインクリメンタル列として、初期値 -1、設定された制限 5000 万行で、一度に 5000 万行を取り込むように設定できます。
同期が初めて実行されると、id の値が -1 より大きい最初の 5000 万行(id に基づいて昇順)が Foundry に取り込まれます。例えば、この同期が何度も実行され、最後の同期で取り込まれた最大の id 値が 19384004822 だった場合、次の同期では 19384004822 より大きい最初の id 値から次の 5000 万行が取り込まれます。
また、SQL クエリに制限を追加することも忘れずに。たとえば、クエリが SELECT * FROM "sales"."region" だった場合、SELECT * FROM "sales"."region" WHERE sale_id > ? limit 100000 に変更することができます。ビルドが実行されるたびに、Foundry に 100000 行がインポートされます。クエリの ? 値は、最後に実行された値で自動的に更新されます。
SQL クエリの並列化
並列機能は、対象データベースに対して別々のクエリを実行します。SQL クエリを並列化する前に、異なる時間に実行されるクエリによって異なる方法で扱われる可能性があるリアルタイム更新テーブルにどのように影響を与えるかを考慮してください。
インクリメンタル同期に切り替えた後もパフォーマンスが向上しない場合は、SQL クエリを並列化して、それを複数の小さなクエリに分割し、エージェントが並行して実行できるようにすることができます。
これを実現するために、SQL クエリを新しい構造に変更する必要があります。例えば:
Copied!1 2 3 4 5 6SELECT /* FORCED_PARALLELISM_COLUMN(<column>), FORCED_PARALLELISM_SIZE(<size>) */ /* FORCED_PARALLELISM_COLUMN(<列名>), FORCED_PARALLELISM_SIZE(<サイズ>) */ * FROM <table_name> /* <テーブル名>から */
以下に、クエリの必要な並列性の詳細を説明します。
FORCED_PARALLELISM_COLUMN(<行>):テーブルが分割される行を指定します。これは、可能な限り均等な分布を持つ数値行(または数値行を生成する行式)であるべきです。
FORCED_PARALLELISM_SIZE(<size>):並列性の度合いを指定します。例えば、4を指定すると、同時に五つのクエリが実行されます:四つのクエリは指定した並列性行の値を分割し、もう一つのクエリは並列性行でNULL値をクエリします。
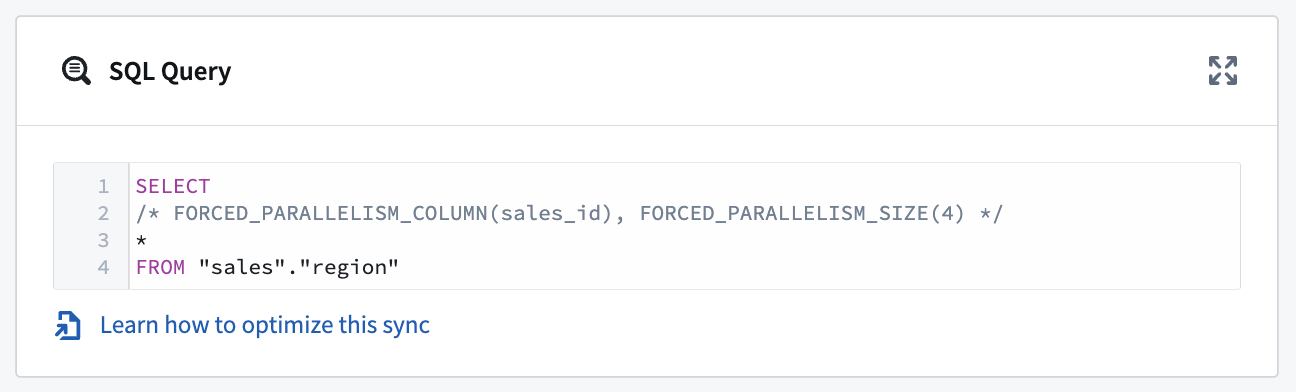
例えば、上述のSQLクエリSELECT * FROM sales_dataを使用して、以下のように詳細を追加することで並列化できます:
Copied!1 2 3 4 5SELECT /* FORCED_PARALLELISM_COLUMN(sales_id)、FORCED_PARALLELISM_SIZE(4) これらのコメントは、強制的に並列処理を行うためのものです。 */ /* "sales_id" 列に対して並列処理を行い、そのサイズを 4 に設定します。 */ * FROM "sales"."region" /* "sales" スキーマの "region" テーブルから全てのデータを選択します。 */
WHERE 句に OR 条件を含む並列処理を使用する場合は、条件を括弧で囲って条件の評価方法を示してください。例:SELECT /* FORCED_PARALLELISM_COLUMN(sales_id), FORCED_PARALLELISM_SIZE(4) */ * FROM "sales"."region" WHERE (condition1 = TRUE OR condition2 = TRUE)
JDBC ソースへのデータのエクスポート
Data Connection は、データセットを JDBC ソースにエクスポートすることをサポートしています。
JDBC エクスポートを有効化、設定、スケジュールする方法については、ドキュメントを参照してください。JDBC エクスポートの有効化、設定、スケジュール。
ヘルスチェック
ヘルスチェックは、ソースの下にあるソースの活性と可用性を検証するために実行されます。デフォルトでは、これらは 60 分ごとに実行され、ソースに割り当てられた各エージェントから実行されます。JDBC ソースの場合、ヘルスチェックは SELECT 1 クエリとして実装されています。