注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
Compute Module の使用と料金
コンピュートモジュール機能はベータ版であり、すべてのエンロールメントで利用できるわけではありません。ユーザーのエンロールメントでコンピュートモジュールが利用可能な場合は、Compute Modules アプリケーションに移動して最新のドキュメントをご覧ください。
Compute Modules 機能を使用すると、インタラクティブコンテナをデプロイできます。コンピュートの使用状況を理解するには、これらのデプロイメントが自動的に水平スケールアップおよびスケールダウンでき、予測オートスケーリングのためにリクエストなしでも行われる可能性があることを知っておく必要があります。デプロイメントが実行中のときにビルドをクリックすると、使用量が消費されることがあります。
コンピュート使用量が消費される場合、その使用量は Compute Module 自体に帰属されます。コンピュート使用量は "レプリカ" が開始または実行されているときに消費され、レプリカが開始または実行されていない場合には消費されません。消費される使用量は、レプリカの数とその関連リソース使用量によって異なります。
ユーザーの使用状況を最適に理解するには、Compute Module が多くのレプリカを持つことができ、それぞれのレプリカが多くのコンテナを持つことができることを知っておく必要があります。
料金
Compute Module の使用状況は Foundry のコンピュート秒として追跡されます (詳細は Usage Types を参照)。レプリカが開始またはアクティブである限り、コンピュート秒が測定されます。使用されたコンピュート秒を決定するために使用されるいくつかの要素があります:
- レプリカごとの vCPU の数
- レプリカごとの RAM の GiB 数
- レプリカごとの GPU の数
- レプリカの数
- どの時点でもレプリカの数は動的ですが、すべて同じリソース構成を持っています
Foundry の使用量を支払う場合、デフォルトの使用料金は以下の通りです:
| vCPU / GPU | 使用料金 |
|---|---|
| vCPU | 0.2 |
| T4 GPU | 1.2 |
| V100 GPU | 3 |
| A10G GPU | 1.5 |
Palantir とエンタープライズ契約を結んでいる場合は、コンピュート使用量の計算を進める前に Palantir の担当者に連絡してください。
# vCPUの計算秒数を求める式
# 各レプリカにおけるvCPU数とメモリ量(GB)を基に計算
# 7.5で割ることで、メモリの影響を補正
# 最大値を取り、レプリカ数、使用率、アクティブな時間(秒)を掛け合わせる
vcpu_compute_seconds = max(vCPUs_per_replica, GiB_RAM_per_replica / 7.5) * num_replicas * vcpu_usage_rate * time_active_in_seconds
以下の数式は GPU コンピュート秒を測定します。
# GPUの計算秒数を計算するための式
# 各変数の意味:
# GPUs_per_replica: 各レプリカあたりのGPU数
# num_replicas: レプリカの数
# gpu_usage_rate: GPUの使用率
# time_active_in_seconds: GPUがアクティブな時間(秒単位)
gpu_compute_seconds = GPUs_per_replica * num_replicas * gpu_usage_rate * time_active_in_seconds
Compute Modules のスケーリング設定
最小および最大レプリカ数を直接設定ページで設定できます。
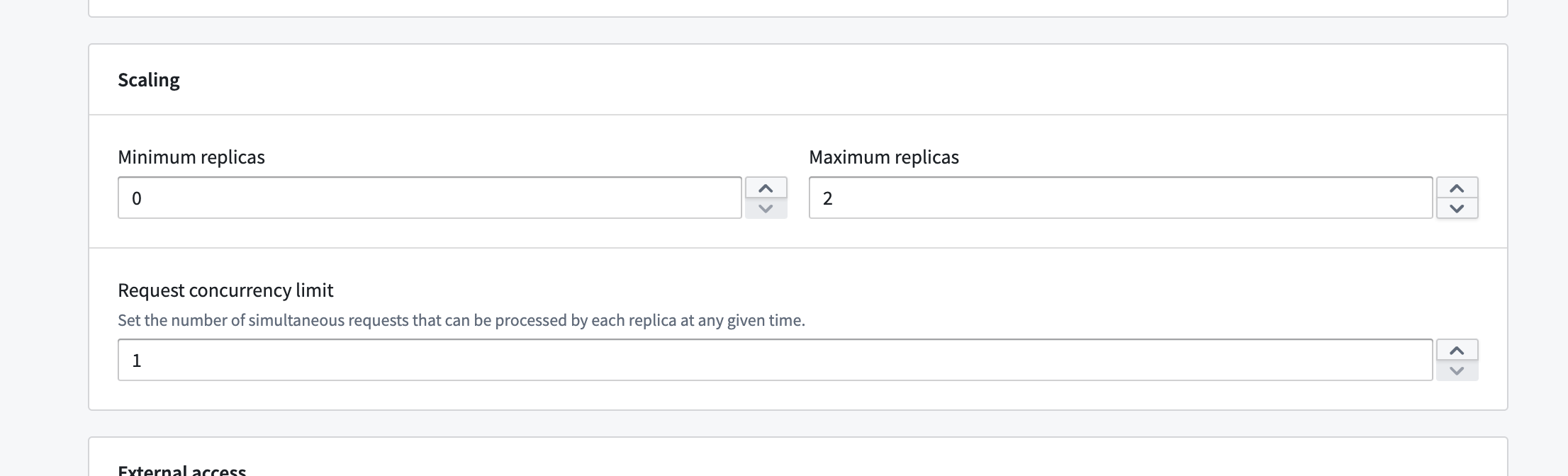
この範囲を設定することで、自動水平スケーリングをある程度制御できます。基本的には、設定した範囲内で任意のタイミングで任意のレプリカ数にスケールすることができます。また、レプリカごとの同時実行制限を設定することもでき、これがスケーリングに影響を与えます。同時実行制限が低い場合、同じ負荷であってもより積極的な水平スケーリングが行われる可能性があります。
最小レプリカ数を 0 以外に設定すると、デプロイメントをアクティブに使用していない場合でもコンピュート使用量が消費されます。最小値を 0 に設定し、しばらくの間デプロイメントにリクエストが送信されなかった場合は、0 にスケールダウンすることができます。その場合、使用量は消費されません。ただし、リクエストが送信された場合、初回デプロイ時、および負荷が予測される場合にはすぐに 0 からスケールアップします。
Compute Modules には予測スケーリングがあり、デプロイメントの過去のクエリ負荷を追跡し、予測された需要を満たすために事前にスケールアップを試みます。予測が不正確だった場合、次回の予測を改善するためにそのデータを使用し、比較的迅速にスケールダウンします。このシステムは設定された最大レプリカ数を尊重するため、デプロイメントのスケーリングを定期的に監視し、スケーリング設定を調整する必要があります。
Compute Modules のリソース設定
Compute Modules インターフェースを使用すると、レプリカごとに各コンテナのリソースを設定できます。CPU、メモリ、および GPU のリソース要求と制限は、すべてのレプリカごとに設定できます。
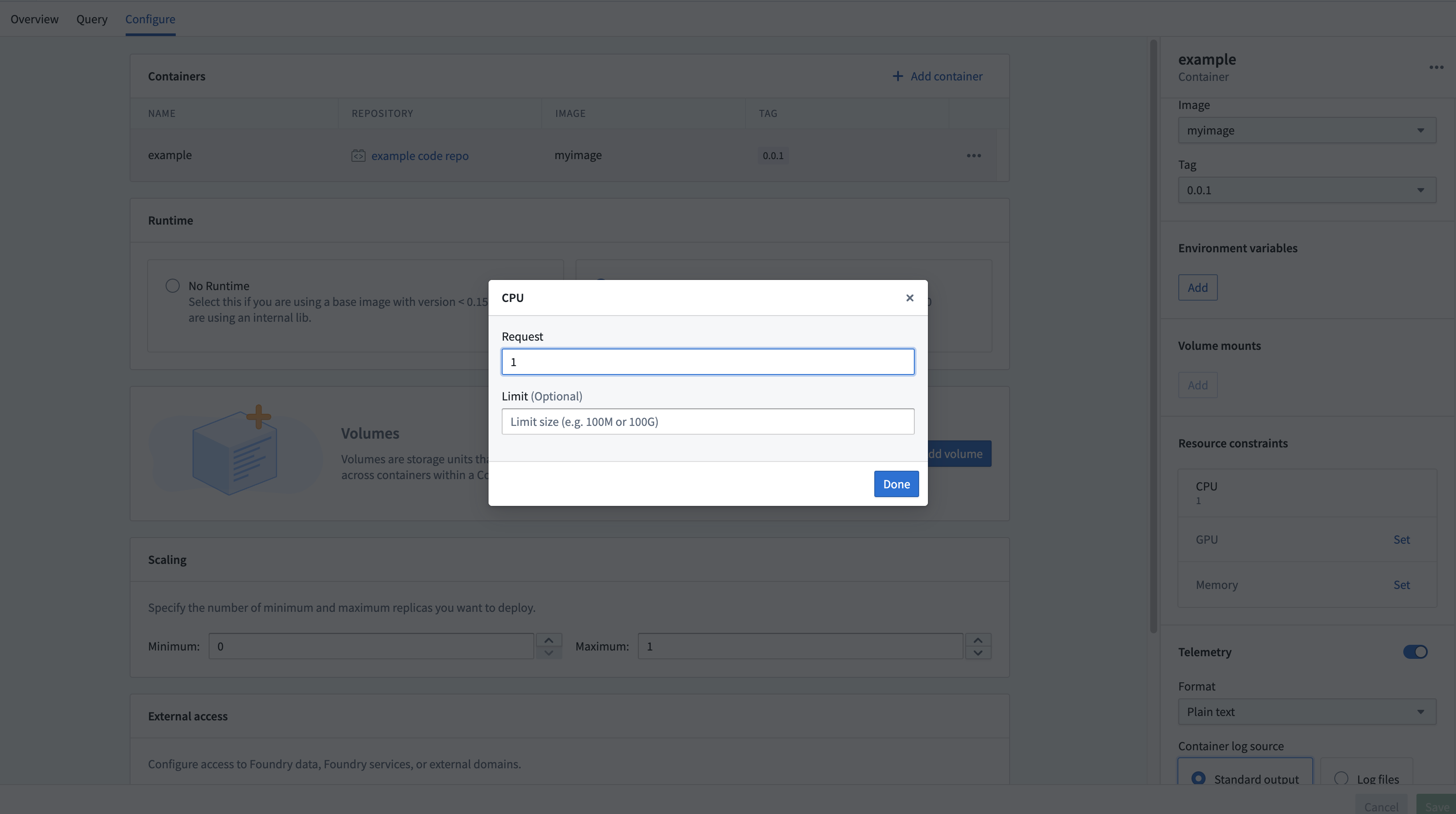
これらのリソースの設定は任意です。設定がない場合、レプリカはデフォルトで 1 vCPU、4 GB メモリ、GPU なしで動作します。各レプリカは設定されたリソース量を要求し、設定された制限を尊重します。つまり、デフォルトのリソース (1 vCPU と 4 GB メモリ、制限なし) を使用し、4 個のレプリカがある場合、4 vCPU と 16 GB メモリを消費している可能性があります(リクエスト負荷に応じて、さらに多くまたは少なく消費することがあります)。