注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
Jupyter® ノートブック内で Palantir が提供する言語モデルを使用する
Palantir が提供する言語モデルを使用するには、まず ユーザーのエンロールメントで AIP を有効にする 必要があります。
Palantir は、Jupyter® ノートブック内で使用できる 言語および埋め込みモデルのセット を提供しています。これらのモデルは palantir_models ライブラリを通じて使用できます。このライブラリは、モデルと対話するためのバインディングを提供する一連のクラスを提供します。
Code Workspaces での Palantir が提供するモデルのセットアップ
ノートブックに言語モデルのサポートを追加するには、Code Workspace の左側にあるパッケージ検索パネルを開きます。palantir_models を検索し、Latest を選択します。これにより、インストールコマンドがクリップボードにコピーされます。これを空のセルに貼り付けて実行します。
ノートブックに Palantir が提供するモデルを追加する
ノートブックに言語モデルを追加するには、Code Workspace の左側にある Models パネルを開きます。まだモデルをインポートしていない場合は、Palantir が提供するモデルをインポートする をクリックします。すでにモデルをインポートしている場合は、パネルの上部にある + アイコンを選択して追加のモデルをインポートできます。
次に、ユーザーが利用できるモデルの検索可能なリストが表示されます。モデルは、チャット完了モデルと埋め込みモデルの2つのカテゴリにリストされています。必要なモデルを選択して Code Workspace にインポートします。
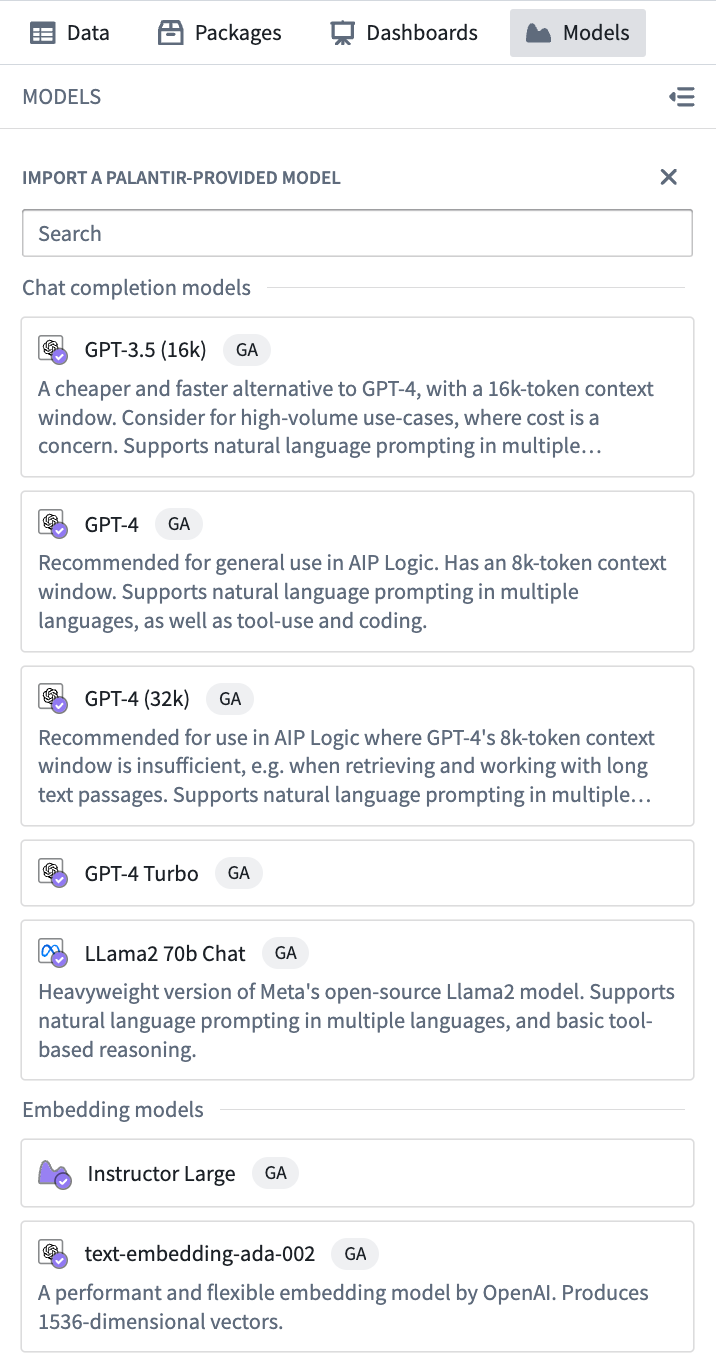
モデルの利用可能性は、顧客によって異なる場合があります。詳細については、Palantir の代表者にお問い合わせください。
インポート後、モデルは Models パネルに表示されます。Models パネルでモデルを選択すると、そのモデルの基本的な機能を示すコードスニペットが表示されます。
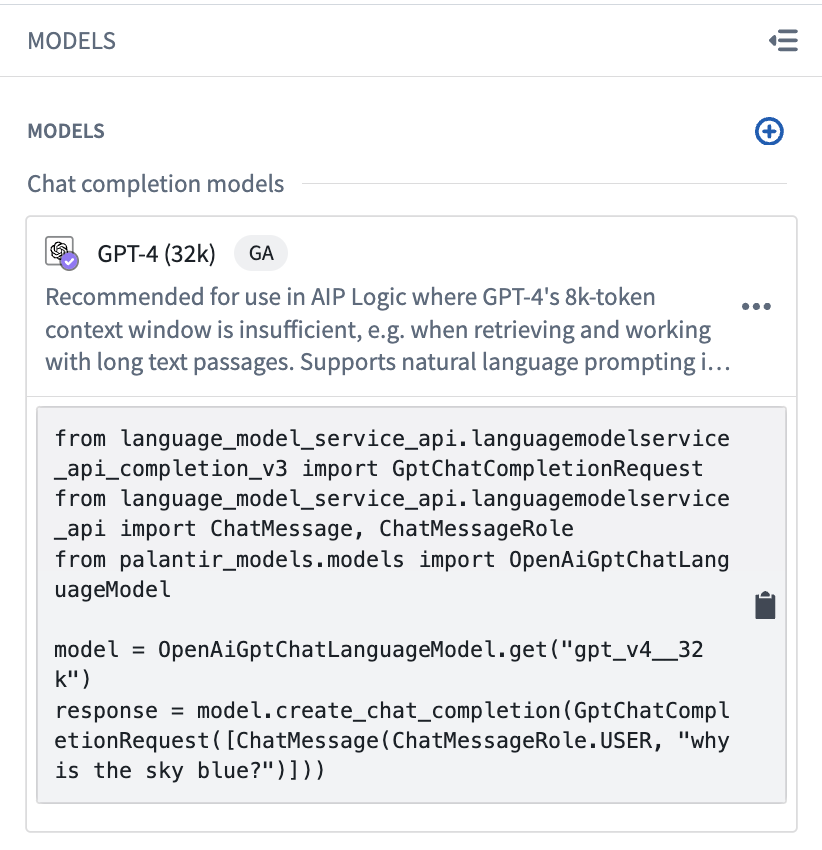
モデルの使用を開始するには、スニペットをクリックしてコードをコピーし、ノートブックの任意のセルに貼り付けます。
言語モデルを使用して補完を生成する
この例では、OpenAI モデルを使用して質問に答えます。すでにモデルをインポートしていると仮定して、以下のコードスニペットを任意のセルにコピーして進めます。