注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
Machinery プロセスを作成する
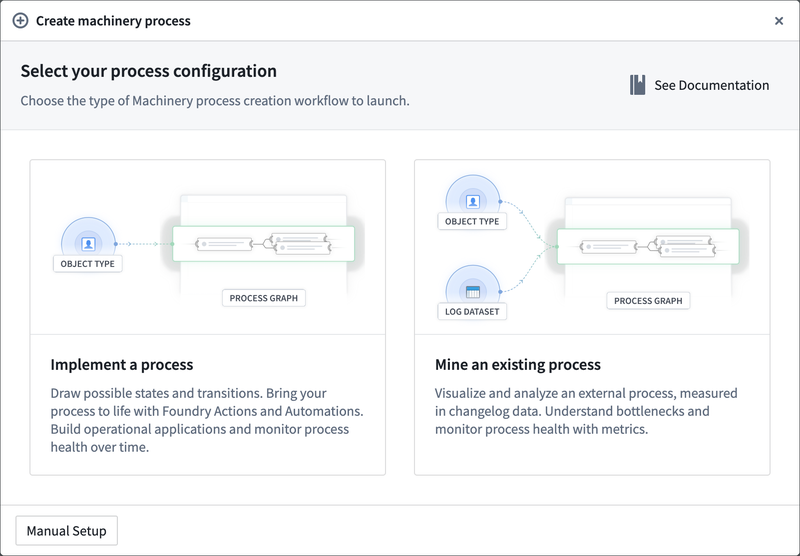
Machinery で New Process を選択するか、Ontology Manager のオブジェクトタイプの Dependents セクションから新しいプロセスを作成できます。 次のいずれかのセットアップオプションを選択するよう求められます。
-
プロセスを実装する: すべてのプロセスコンポーネントが Foundry 内にあり、外部の変更ログがない場合にこのオプションを選択します。プロセスのコンポーネントは
Processオブジェクトタイプ、Actions、および Automations です。これらのいくつかはすでに存在するかもしれませんが、セットアップワークフローの一部として生成することもできます。 -
既存のプロセスをマインする: 外部プロセスを理解し、監視したい場合にこのオプションを選択します。主な必要入力は、プロセスオブジェクトの変更を追跡する変更ログデータセットです。Machinery はオントロジー対応のため、Process および Process Log オブジェクトタイプを提供するか、Machinery に生成させることができます。
-
手動設定: ユーザーがすでに管理しているオブジェクトタイプがあり、それが Machinery の仕様を満たしている場合、手動設定を選択できます。このオプションを選択すると、設定ダイアログがスキップされ、任意の時点でオントロジーの描画および設定を直接開始できます。
Machinery は現在、外部プロセスに対して読み取り専用ビューをサポートしています。Foundry 内でプロセスに対する Actions を定義したい場合、外部および内部の変更を調整する必要があり、この機能は近日中に Machinery がサポートします。今日この機能が必要な場合は、手動設定を選択するか、Palantir サポートに連絡してください。
要件
Machinery でオブジェクトタイプを設定する際、ユーザーのプロパティ(名前付き)を必要なフィールドにマッピングできます。
プロセスオブジェクトタイプ
プロセスを経るエンティティを表すオブジェクトタイプ。
- Process ID (string) [必須]: プロセスエンティティのプライマリキー
- State (string) [必須]: プロセスエンティティの現在の状態
変更ログデータセット
この設定は 既存のプロセスをマインする オプションにのみ必要です。外部プロセスの測定を表します。データセットの各行は、特定の時点でのプロセスオブジェクトの変更を表します。
- processId (string) [必須]: プロセスエンティティの一意識別子。
- state (string) [必須]: プロセスが入った新しい状態。
- timestamp (timestamp) [必須]: 遷移が発生したタイムスタンプ。
- isDeleted (boolean) [オプション]: エンティティが削除されたことを示すプロパティ。最新のログの isDeleted が
Trueの場合、そのオブジェクトはオントロジーに表示されません。
プロセスログオブジェクトタイプ
ログは、タイムスタンプ T の時点での古い状態から新しい状態への遷移を表します。プロセスログオブジェクトタイプは通常、Machinery によって作成および管理されます。手動設定オプションを選択した場合、次のプロパティを提供する必要があります。オプションのプロパティが欠けている場合、Machinery の機能の一部が利用できなくなります。
- Log ID (string) [必須]: ログオブジェクトのプライマリキー。
- Process ID (string) [必須]: 追跡されるプロセスオブジェクトのプライマリキー。Process オブジェクトと Log オブジェクトの間の オントロジーリンクの設定 に使用します。
- Old State (string) [必須]: 遷移の開始状態。
- New State (string) [必須]: 遷移の終了状態。
- Timestamp (timestamp) [必須]: 終了状態に入るタイムスタンプ。
- isLatest (boolean) [オプション]: このログがプロセスオブジェクトの最新である場合は
True、それ以外の場合はFalse。 - Duration (long) [オプション]: 古い状態に入ってからのミリ秒単位の期間。
- Path (string) [オプション]: 現在の状態を含む、これまでに遭遇したすべての状態のリスト。シリアル化された JSON 文字列である必要があります。
プロセスグラフの生成
Machinery はプロセスを詳細に示す場所です。何が起こりうるか、または何が起こるべきかを詳細に示します。プロセスの以下のコンポーネントを定義する必要があり、これらは Machinery グラフ上でノードおよびエッジとして表されます。
- 許可される状態
- 可能な状態遷移
- 状態遷移を担当するアクション
- 宣言された入力状態に基づいて自動的に発生するアクション
描画
クリックおよび描画操作を使用して新しい状態とアクションを作成できます。状態およびアクションノードを接続することで、可能な状態遷移を決定します。グラフ上のノードをドラッグすることで、その位置を設定するか、コントロールバーから自動レイアウト機能を選択できます。

マイニング
または、Log オブジェクトタイプが正常にインデックスされ、データが含まれている場合、マイニング によって履歴データから状態と遷移のセットを取得できます。これは、変更ログデータセットを利用したプロセスに最も一般的なワークフローです。Actions メニューから Mine を選択します。
値タイプ
Machinery の状態 ID は、ユーザーのデータ内の状態値と同等です。タイプミスやその他の逸脱を避けるために、状態プロパティを列挙型の Value Type でサポートできます。これにより、オントロジー内のデータがあらかじめ定義された値のセットのみを取ることが保証されます。Machinery はその設定を検出し、プロセス状態を同期します。
期待される遷移
履歴ログから状態および遷移をマイニングする際、データヘルスの問題はしばしば予期しない遷移を引き起こすことがあります。たとえば、Patient が 治療中 から 入院 状態に移行するのは、健全な遷移ではありません。Expected Transitions モードに切り替えることで、期待されるエッジを定義できます。このフィルターは、Machinery ウィジェットでグラフの関連部分のみを表示するために使用されます。