注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
カスタムモデルを使用してセマンティックサーチワークフローを作成する
このチュートリアルは、Palantir が提供していない埋め込みモデルを使用するユーザー向けです。 Palantir 提供モデルの一覧 および Palantir 提供モデルセマンティックサーチチュートリアル を参照してください。
このページでは、プロンプトが与えられたときに関連するドキュメントを取得できる概念的なエンドツーエンドのドキュメント検索サービスを構築するプロセスを示します。このサービスは、ドキュメントを埋め込み、その特徴をベクトルに抽出するために Foundry modeling objective を使用します。これらのドキュメントと埋め込みは、ベクトルプロパティを持つオブジェクトタイプに保存されます。
この例では、まず Foundry にモデルを設定し、埋め込みを生成するためのパイプラインを作成します。次に、新しいオブジェクトタイプと自然言語でクエリを実行するための関数を作成します。
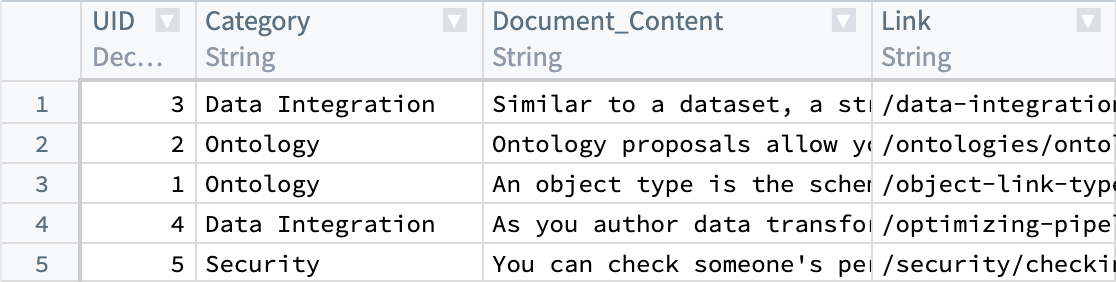
まず、現在解析済みドキュメントとメタデータ(Document_Content や Link など)を含むデータセットを用意します。次に、Document_Content から埋め込みを生成して、セマンティックサーチを通じてクエリを実行できるようにします。
KNN 機能の詳細については、Foundry ドキュメントの KNN Functions on Objects セクションを参照してください。
このワークフロー全体で、一貫して使用する限り、任意の値を置換できます。たとえば、ObjectApiName のすべてのインスタンスを常に Document に置換します。
置換する必要がある値は以下の通りです。
ObjectApiName: 一意の ObjectType の識別子。ここではDocument。 注: 識別子は時々objectApiNameのように最初の文字が小文字で表示されることがあります。ModelApiName: 一意のモデルの識別子。OutputDatasetRid: embedding transform の出力データセットの識別子。InputDatasetRid: embedding transform の入力データセットの識別子。ModelRid: embedding transform および Live Modeling Deployment の作成 で使用されるモデルの識別子。
1. Foundry でモデルを使用して埋め込みを作成する
Foundry でモデルから埋め込みを作成するにはいくつかのオプションがあります。この例では、インポートされたオープンソースモデル と対話するためのトランスフォームを作成します。all-MiniLM-L6-v2 モデルを使用します。これは一般的なテキスト埋め込みモデルであり、次元(サイズ)384 のベクトルを作成します。このモデルは、Foundry オントロジー vector タイプ と互換性のあるベクトルを出力する他の既存モデルと交換可能です。新しいオープンソースモデルをインポートするには、言語モデルのドキュメント を参照してください。
この例では、このモデルを使用して埋め込みを生成し、必要な後処理を実行するトランスフォームを実行します。この場合、データをモデルに通して embedding を返し、その embedding 値(ダブル配列)をベクトル埋め込みに必要なタイプに一致させるためにフロートにキャストします。
いくつか考慮すべき点は以下の通りです。
schema変数の各StructFieldは、処理された入力データセット(InputDatasetRid)に存在する列と、モデルによって追加されたembedding列に関連しています。- 大規模なデータを扱う場合、Pandas データフレームが非常に大きい場合、トランスフォームが失敗することがあります。このような場合、トランスフォームは Spark で実行する必要があります。
- グラフィックス処理ユニット (GPU) を利用して、トランスフォームによる埋め込み生成の速度を上げることができます。GPU はトランスフォームに
@configureデコレーターを追加することで使用できます。環境でこれを有効にすることに興味がある場合は、Palantir の担当者にお問い合わせください。
以下にトランスフォームの例を示します。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40from transforms.api import configure, transform, Input, Output from palantir_models.transforms import ModelInput from pyspark.sql.functions import pandas_udf, PandasUDFType from pyspark.sql.types import StructType, StructField, IntegerType, StringType, FloatType, ArrayType import numpy as np @configure(profile=["DRIVER_GPU_ENABLED"]) # 環境でGPUが有効になっていない場合は、この行を削除してください @transform( dataset_out=Output("OutputDatasetRid"), dataset_in=Input("InputDatasetRid"), embedding_model=ModelInput("ModelRid") ) def compute(ctx, dataset_out, dataset_in, embedding_model): # モデルの入力カラムを一致させる spark_df = dataset_in.dataframe().withColumnRenamed("Document_Content", "text") def embed_df(df): # 埋め込みを作成する output_df = embedding_model.transform(df).output_data # フロート配列にキャストする output_df["embedding"] = output_df["embedding"].apply(lambda x: np.array(x).astype(float).tolist()) # 不要なカラムを削除する return output_df.drop('inference_device', axis=1) # 更新されたスキーマ schema = StructType([ StructField("UID", IntegerType(), True), StructField("Category", StringType(), True), StructField("text", StringType(), True), StructField("Link", StringType(), True), StructField("embedding", ArrayType(FloatType()), True) ]) # pandas_udfを使用してデータフレームをグループ化し適用する udf = pandas_udf(embed_df, returnType=schema, functionType=PandasUDFType.GROUPED_MAP) output_df = spark_df.groupBy('UID').apply(udf) # 出力データフレームを書き込む dataset_out.write_dataframe(output_df)
次に、ユーザーのクエリから埋め込みを作成し、既存のベクトルに対して検索を行うために、ライブモデリングデプロイメントが必要です。この部分で使用するモデルは、現在のステップで最初の埋め込みを生成するために使用したものと同じである必要があります。
2. オブジェクトタイプを作成する
これまでに、バッチモデリングデプロイメントを使用して生成されたフロートベクトル埋め込みを含む列を持つ新しいデータセットがあるはずです。最初のステップからです。次に、オブジェクトタイプを作成します。
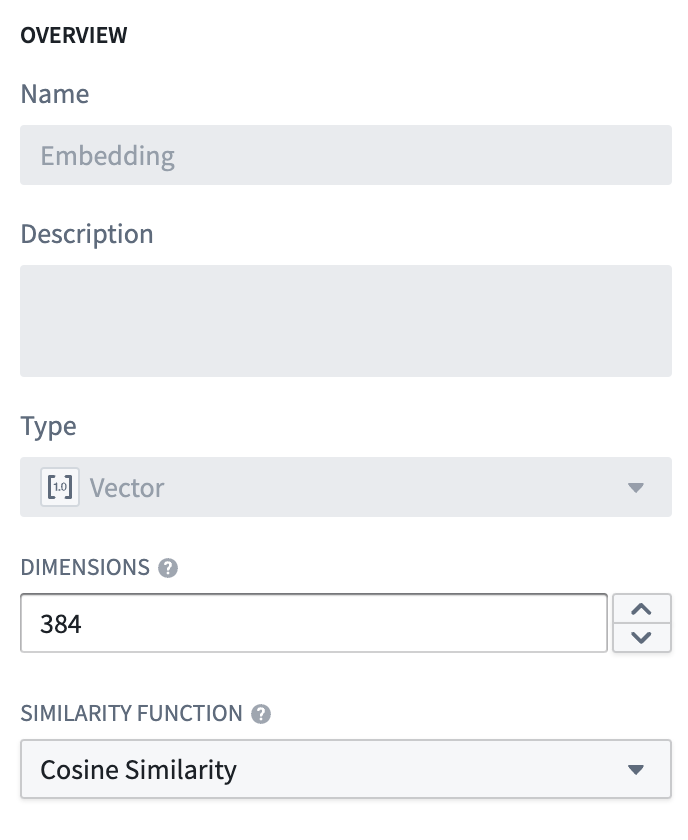
オブジェクトタイプを Document と名付け、embedding プロパティをプロパティタイプ Vector に設定します。これには、2 つの値を設定する必要があります。
- 次元数: これは列
embeddingで生成される配列の長さです。 - 類似性関数: 異なるオブジェクトからの 2 つの
embedding値間の距離を計算する方法です。
このオブジェクトタイプが作成されると、Documentation オブジェクトをセマンティックに検索するために使用できるプロパティ (embedding) が得られます。
ObjectApiName の値はオブジェクトタイプが保存された後に利用可能になり、作成されたオブジェクトタイプの設定ページで見つけることができます。詳細については、ドキュメントの Create an object type セクションを参照してください。
3. ライブモデリングデプロイメントを作成する
オブジェクトに埋め込みがプロパティとして追加されたので、低遅延でユーザーのクエリの埋め込みを生成する必要があります。これらの埋め込みは、類似の埋め込み値を持つオブジェクトを見つけるために使用されます。これを行うには、Functionsを使用して高速で低遅延のアクセスのためにライブモデルデプロイメントを作成します。
ライブモデリングデプロイメントの設定に関する指示 または関連する よくある質問 をモデリングセクションで確認してください。
Live Deployment API Name に設定する値は、上記で言及された代替値 ModelApiName と同等です。
4. ModelsでのFunctionsを使用して埋め込みを作成する
先に進む前に、functions.json ファイルに "enableVectorProperties": true および "useDeploymentApiNames": true のエントリが 両方 含まれていることを確認してください。これらのエントリが存在しない場合は、functions.json に追加し、変更をコミットして続行してください。さらに支援が必要な場合は、Palantirの担当者に連絡してください。
最終ステップは、このオブジェクトタイプをクエリする関数を作成することです。検索フェーズでは、ユーザーの入力を受け取り、ライブモデリングデプロイメント 以前に作成された を使用してベクトルを生成し、その後 KNN検索 をオブジェクトタイプに対して行うことが目標です。 このユースケースのサンプル関数は以下に示され、配置すべきファイル構造も含まれています。
ベクトルプロパティの編集は、Actions および Functions によって適用できます。
詳細は Functions on models documentation を参照してください。
ファイル構造
|-- functions-typescript
| |-- src
| | |-- tests
| | | |-- index.ts # テストコードを含むファイル
| | |-- index.ts # エントリーポイントのファイル
| | |-- semanticSearch.ts # セマンティック検索に関連するロジックを含むファイル
| | |-- service.ts # サービスロジックを含むファイル
| | |-- tsconfig.json # TypeScriptの設定ファイル
| | |-- types.ts # 型定義を含むファイル
| |-- functions.json # 関数の設定ファイル
| |-- jest.config.js # Jestテストフレームワークの設定ファイル
| |-- package-lock.json # パッケージの依存関係を固定するファイル
| |-- package.json # プロジェクトの依存関係とスクリプトを定義するファイル
|-- version.properties # プロジェクトのバージョン情報を含むファイル
functions-typescript/src/types.ts
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19import { Double } from "@foundry/functions-api"; // 埋め込みモデルのインターフェースを定義 export interface IEmbeddingModel { // コンテンツを埋め込むメソッド。非同期で埋め込み結果を返す。 embed: (content: string) => Promise<IEmbeddingResponse>; } // 埋め込み結果のインターフェースを定義 export interface IEmbeddingResponse { text: string // 元のテキスト embedding: Double[] // 埋め込みベクトル inference_device?: string // 推論に使用したデバイス (オプション) } // 埋め込みリクエストのインターフェースを定義 export interface IEmbeddingRequest { text: string // 埋め込み対象のテキスト }
functions-typescript/src/service.ts
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15import { ModelApiName } from "@foundry/models-api/deployments"; import { IEmbeddingRequest, IEmbeddingResponse } from "./types"; // モデルにアクセスするサービス export class EmbeddingService { // 指定されたコンテンツを埋め込み、埋め込みのレスポンスを返す非同期メソッド public async embed(content: string): Promise<IEmbeddingResponse> { const request: IEmbeddingRequest = { "text": content, }; // モデルAPIを呼び出し、レスポンスを取得して返す return await ModelApiName.transform([request]) .then((output: any) => output[0]) as IEmbeddingResponse; } }
functions-typescript/src/semanticSearch.ts
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55import { Function, Integer, Double } from "@foundry/functions-api"; import { Objects, ObjectApiName } from "@foundry/ontology-api"; import { EmbeddingService } from "./service"; import { IEmbeddingResponse, IEmbeddingModel } from './types'; export class SuggestedDocs { embeddingService: IEmbeddingModel = new EmbeddingService; @Function() public async fetchSuggestedDocuments(userQuery: string, kValue: Integer, category: string): Promise<ObjectApiName[]> { // クエリに基づいて埋め込みを取得 const embedding: IEmbeddingResponse = await this.embeddingService.embed(userQuery); const vector: Double[] = embedding.embedding; // 埋め込みベクトルに最も近いオブジェクトを検索 return Objects.search() .objectApiName() .filter(obj => obj.category.exactMatch(category)) // カテゴリでフィルタリング .nearestNeighbors(obj => obj.embedding.near(vector, {kValue: kValue})) // k近傍法で検索 .orderByRelevance() // 関連度でソート .take(kValue); // 上位k件を取得 } /** * fetchSuggestedDocumentsの代替として、類似性の閾値を適用するメソッド * 類似度に関係なく、常にkValue件のドキュメントを返すのではなく、一定の類似度を満たすもののみを返す * 距離関数の計算は、埋め込みプロパティに定義されている距離関数に依存する。 * ここでは、埋め込みモデルが正規化されたベクトルを生成する場合、単純なベクトルの内積でコサイン類似度を計算できると仮定する。 */ @Function() public async fetchSuggestedDocumentsWithThreshold(userQuery: string, kValue: Integer, category: string, thresholdSimilarity: Double): Promise<ObjectApiName[]> { // クエリに基づいて埋め込みを取得 const embedding: IEmbeddingResponse = await this.embeddingService.embed(userQuery); const vector: Double[] = embedding.embedding; // 埋め込みベクトルに最も近いオブジェクトを検索 return Objects.search() .objectApiName() .filter(obj => obj.category.exactMatch(category)) // カテゴリでフィルタリング .nearestNeighbors(obj => obj.embedding.near(vector, {kValue: kValue})) // k近傍法で検索 .orderByRelevance() // 関連度でソート .take(kValue) // 上位k件を取得 .filter(obj => SuggestedDocs.dotProduct(vector, obj.embedding! as number[]) >= thresholdSimilarity); // 類似度の閾値を適用 } private static dotProduct<K extends number>(arr1: K[], arr2: K[]): number { // ベクトルの次元が同じであることを確認 if (arr1.length !== arr2.length) { throw EvalError("Two vectors must be of the same dimensions"); } // ベクトルの内積を計算 return arr1.map((_, i) => arr1[i] * arr2[i]).reduce((m, n) => m + n); } }
functions-typescript/src/index.ts
Copied!1 2// SuggestedDocs を semanticSearch モジュールからエクスポート export { SuggestedDocs } from "./semanticSearch";
5. 関数を公開し、例で使用する
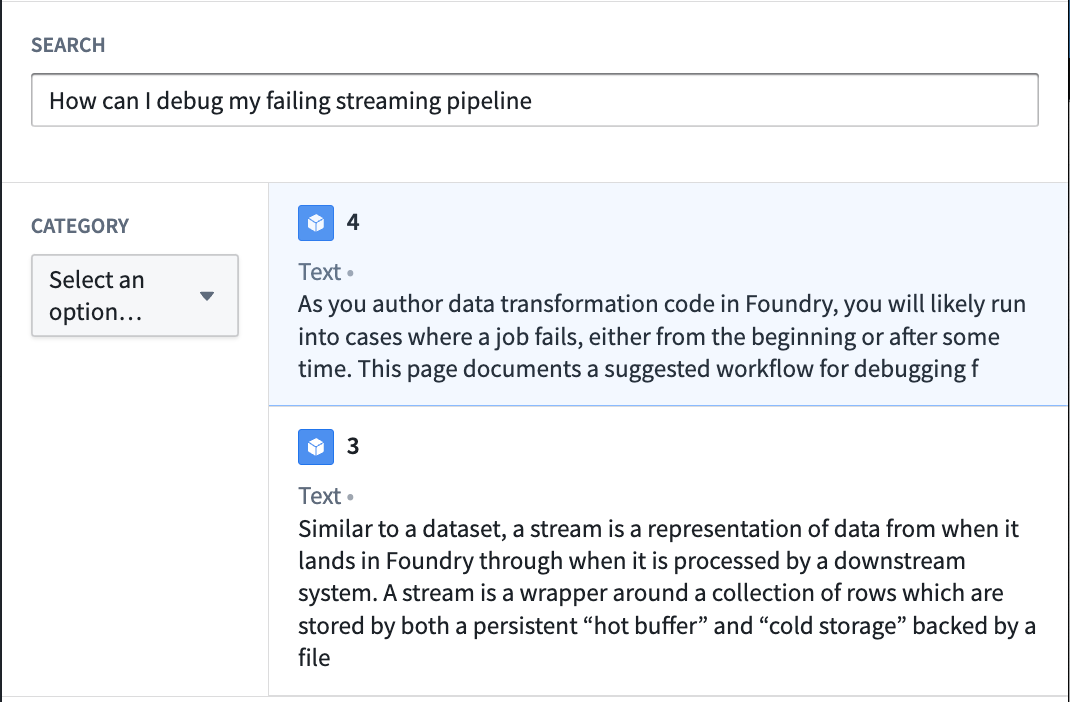
ここまでで、自然言語でオブジェクトをクエリするためのセマンティック検索を実行できる関数ができました。最終ステップは、関数を公開し、ワークフローで使用することです。ドキュメント検索の例をさらに構築するために、この関数をテキスト入力で呼び出し、ユーザーに最も一致するドキュメント記事 2 個を返す Workshop アプリケーションを作成します。
例のドキュメントサービスにセマンティック検索を作成する手順は以下のとおりです:
- Workshop アプリケーションを作成します。
- テキスト入力と文字列セレクターを追加します。文字列セレクターはフィルター処理するドキュメントカテゴリーを選択するために使用します。テキスト入力と文字列セレクターは、公開された KNN ドキュメント取得関数への入力として機能します。
- 最後に、関数から生成された入力オブジェクトセットと選択された入力を使用してオブジェクトリストウィジェットを追加します。以下のように設定します:
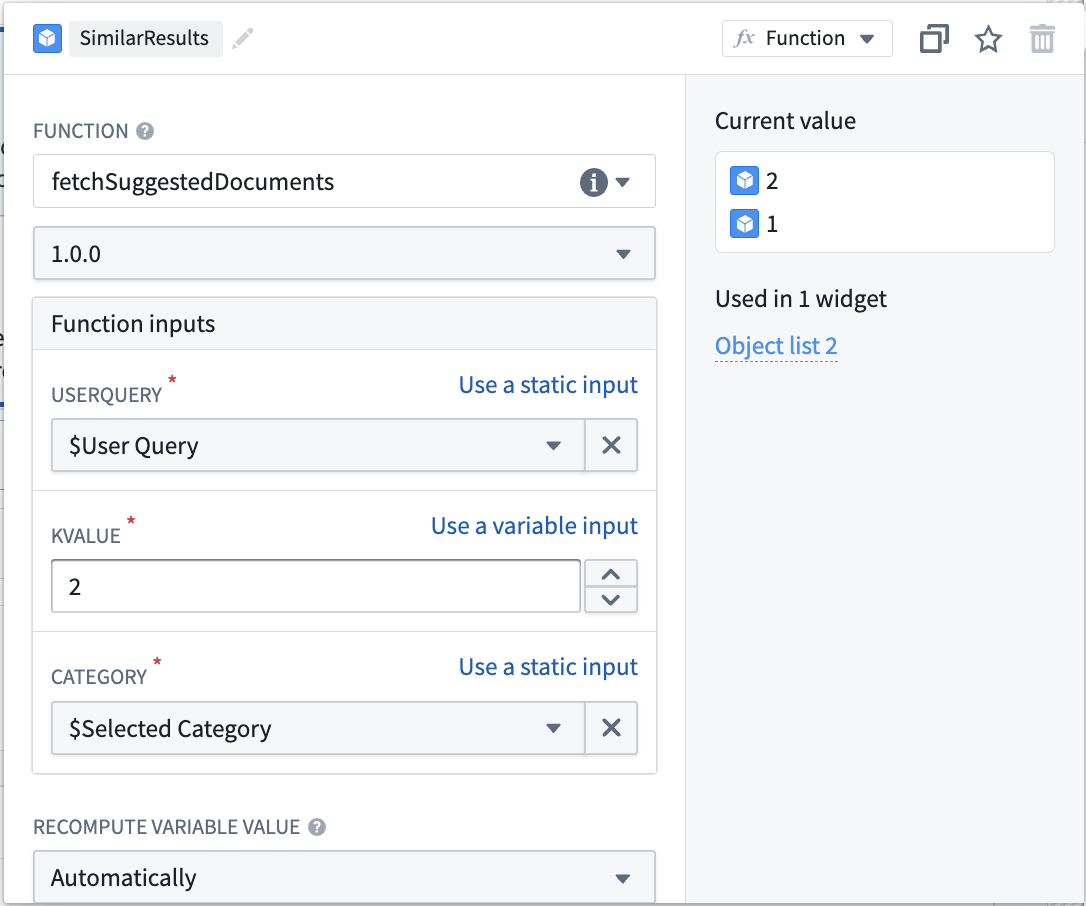
この時点で、入力はオブジェクトタイプ内のドキュメントをセマンティック検索し、最も関連性の高い 2 つを返します。これはベクトルプロパティとセマンティック検索の単純な使用例の 1 つに過ぎません。完成した Workshop アプリケーションの例は、以下のスクリーンショットをご覧ください: