注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
ドキュメント処理
このページでは、PDFドキュメントや画像からデータを抽出するためのいくつかの有用な考慮事項について説明します。
データ抽出
このページでは、Pipeline Builder を使用してPDFを解析し、セマンティック検索に利用するための基本的なガイドを提供し、テキストコンテンツのみを持つ場合に情報を Workshop アプリケーションで表示するための推奨事項を含んでいます。
セマンティック検索はPDFで使用する強力なツールであり、特にコンテンツが別々に埋め込まれた小さな「チャンク」に分割されている場合、ユーザーとワークフローがアクセスしにくい重要な情報を見つけるのに役立ちます。これは、PDFに含まれる膨大な量の非構造化知識がしばしば見逃されることを考慮すると特に有用です。
使用するには、単にPDFをFoundryにアップロードし、テキストを抽出し、同じテキストをチャンクに分割し、それらのチャンクを検索し、対応するPDFを横に表示してユーザーがクロスバリデーションを行えるように結果を表示します。
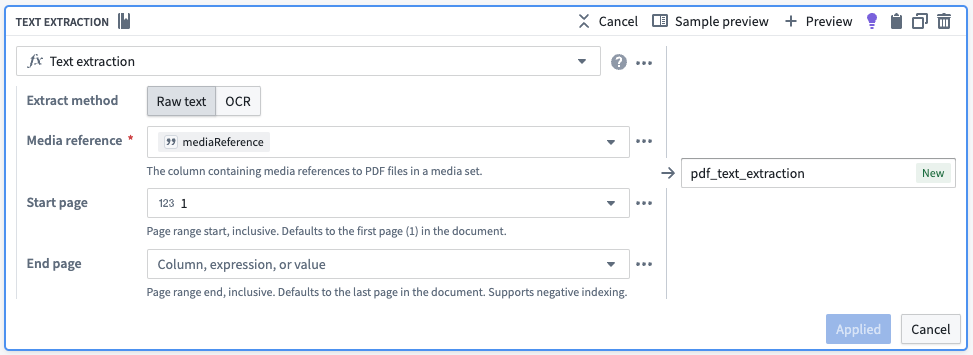
以下の手順に従ってPDFをインポートし、PDFからテキストを抽出します:
- メディアセットとしてPDFをインポートします。
- メディアセットをPipeline Builderに追加します。
- Get Media Referencesボードを使用します。

- Text Extractionボードを使用します。
チャンク化
このページでは、セマンティック検索ワークフローに基本的なチャンク化戦略を取り入れる方法について説明します。このコンテキストでのチャンク化とは、大きなテキストを小さなテキストに分割することを意味します。これは、埋め込みモデルがテキストの最大入力長を持ち、さらに小さなテキストが検索中によりセマンティックに明確になるため、有利です。チャンク化は、大きなドキュメント(たとえばPDF)を解析する際によく使用されます。
主な目的は、長いテキストをそれぞれオントロジーオブジェクトに関連付けられた小さな「チャンク」に分割することです。
チャンク化の例
最初に、コードを使用せずにPipeline Builderで基本的なチャンク化戦略を実行する方法を示します。より高度な戦略については、パイプラインの一部としてコードリポジトリを使用することをお勧めします。
説明のために、2 行 2 列のシンプルなデータセットを使用します。object_id と object_text が含まれます。理解しやすいように、以下の object_text の例は意図的に短くしています。
| object_id | object_text |
|---|---|
| abc | gold ring lost |
| xyz | fast cars zoom |
プロセスは、チャンク化された object_text の配列を含む追加の列を導入する Chunk String ボードを使用して開始します。このボードは、各セマンティックコンセプトが一貫してユニークであることを保証するために、重複やセパレーターなどのさまざまなチャンク化アプローチをサポートします。
以下の Chunk String ボードのスクリーンショットは、ユーザーの使用例に合わせて変更できるシンプルな戦略を示しています。以下の設定では、約 256 文字のサイズのチャンクを返すことを試みます。ボードは、各チャンクがチャンクサイズ以下になるまで、最も優先度の高いセパレーターでテキストを分割します。最も優先度の高いセパレーターで分割できなくなり、一部のチャンクがまだ大きすぎる場合は、すべてのチャンクがチャンクサイズ以下になるか、使用できるセパレーターがなくなるまで、次のセパレーターに移動します。最後に、ボードは各チャンクを特定し、次のチャンクが前のチャンクの最後の 20 文字をカバーする重複を持つようにします。
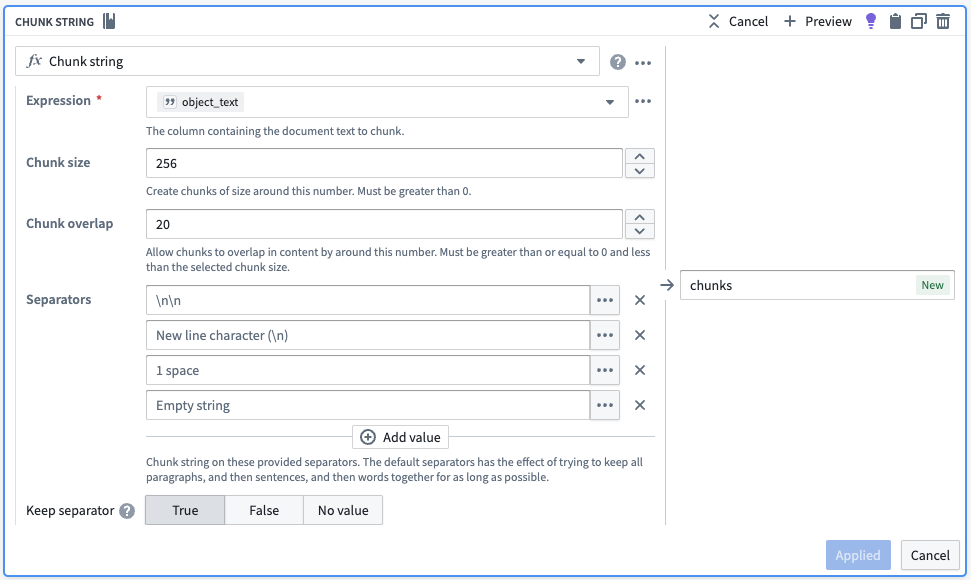
| object_id | object_text | chunks |
|---|---|---|
| abc | gold ring lost | [gold,ring,lost] |
| xyz | fast cars zoom | [fast,cars,zoom] |
次に、配列内の各要素が独自の行を持つようにします。 Explode Array with Position ボードを使用して、データセットを 6 行に変換します。各行の新しい列(以下に示すように)は、配列内の位置と配列内の要素の 2 つのキーと値のペアを持つ構造体(マップ)です。
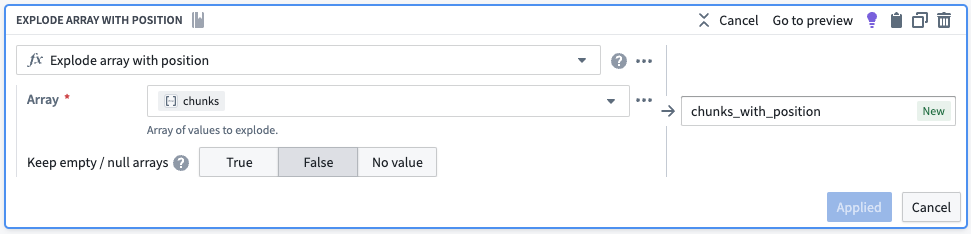
| object_id | object_text | chunks | chunks_with_position |
|---|---|---|---|
| abc | gold ring lost | [gold,ring,lost] | {position:0, element} |
| abc | gold ring lost | [gold,ring,lost] | {position:1, element} |
| abc | gold ring lost | [gold,ring,lost] | {position:2, element} |
| xyz | fast cars zoom | [fast,cars,zoom] | {position:0, element} |
| xyz | fast cars zoom | [fast,cars,zoom] | {position:1, element} |
| xyz | fast cars zoom | [fast,cars,zoom] | {position:2, element} |
そこから、位置と要素を独自の列に取り出します。
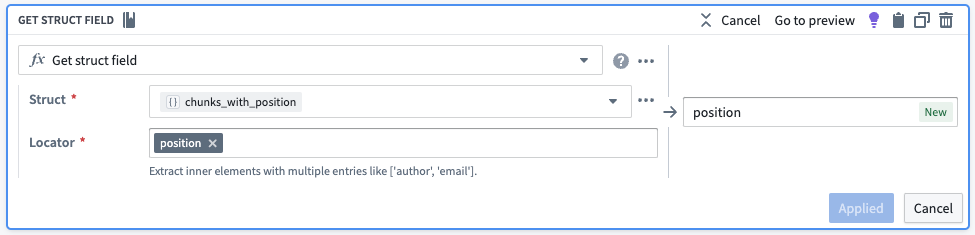
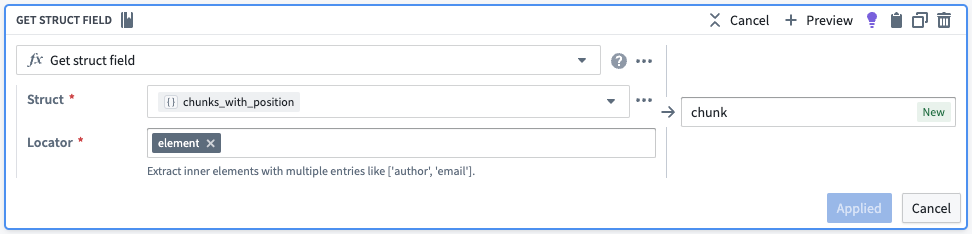
| object_id | object_text | chunks | chunks_with_position | position | chunk |
|---|---|---|---|---|---|
| abc | gold ring lost | [gold,ring,lost] | {position:0, element} | 0 | gold |
| abc | gold ring lost | [gold,ring,lost] | {position:1, element} | 1 | ring |
| abc | gold ring lost | [gold,ring,lost] | {position:2, element} | 2 | lost |
| xyz | fast cars zoom | [fast,cars,zoom] | {position:0, element} | 0 | fast |
| xyz | fast cars zoom | [fast,cars,zoom] | {position:1, element} | 1 | cars |
| xyz | fast cars zoom | [fast,cars,zoom] | {position:2, element} | 2 | zoom |
各チャンクに一意の識別子を作成するために、配列内のチャンク位置を文字列に変換し、それを元のオブジェクトIDに連結します。また、不要な列を削除します。
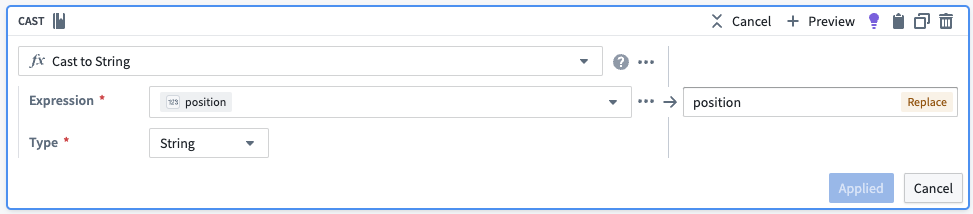
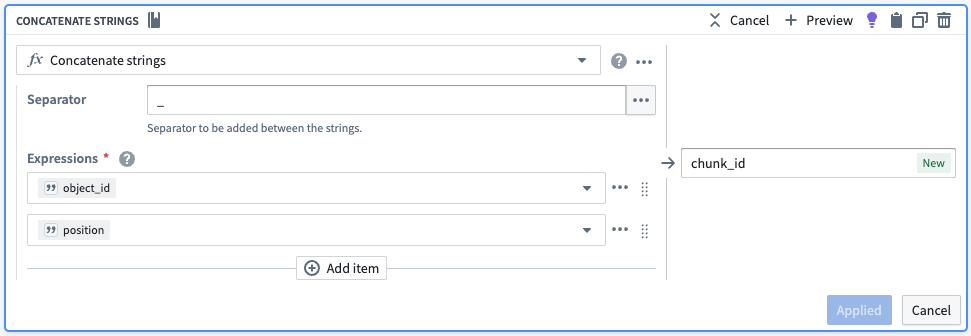

| object_id | chunk | chunk_id |
|---|---|---|
| abc | gold | abc_0 |
| abc | ring | abc_1 |
| abc | lost | abc_2 |
| xyz | fast | xyz_0 |
| xyz | cars | xyz_1 |
| xyz | zoom | xyz_2 |
これで、6 行が 6 個の異なるチャンクを表し、それぞれに(リンク用の)object_id、新しい主キーとなる新しい chunk_id、およびセマンティック検索ワークフロー で説明されているように埋め込まれる chunk が含まれます。これにより、以下のようなテーブルが得られます:
| object_id | chunk | chunk_id | embedding |
|---|---|---|---|
| abc | gold | abc_0 | [-0.7,...,0.4] |
| abc | ring | abc_1 | [0.6,...,-0.2] |
| abc | lost | abc_2 | [-0.8,...,0.9] |
| xyz | fast | xyz_0 | [0.3,...,-0.5] |
| xyz | cars | xyz_1 | [-0.1,...,0.8] |
| xyz | zoom | xyz_2 | [0.2,...,-0.3] |