注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
Funnelバッチパイプライン
Funnelバッチパイプラインは、Foundryのデータソースやユーザーの編集からのデータをバッチ方式でOSv2に効率的にインデックス化する内部ジョブパイプラインであり、オントロジー内のデータとメタデータの最新性を確保します。
Funnelバッチパイプラインの構成要素
Funnelバッチパイプラインは、一連のFoundryビルドジョブで構成されます。
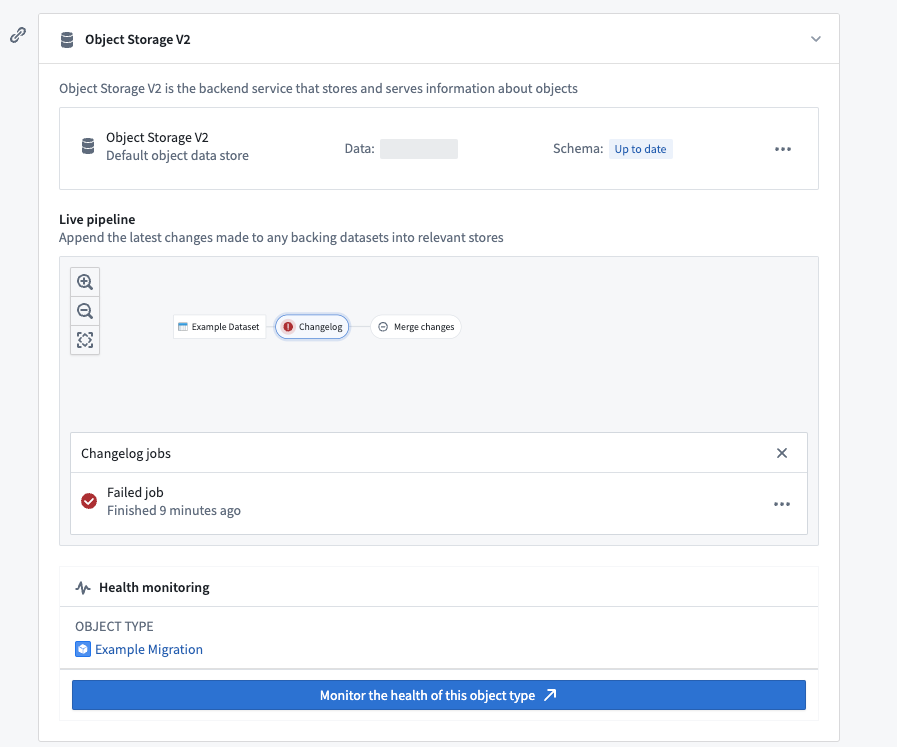
以下のスクリーンショットは、Funnelバッチパイプラインの例を示しています。
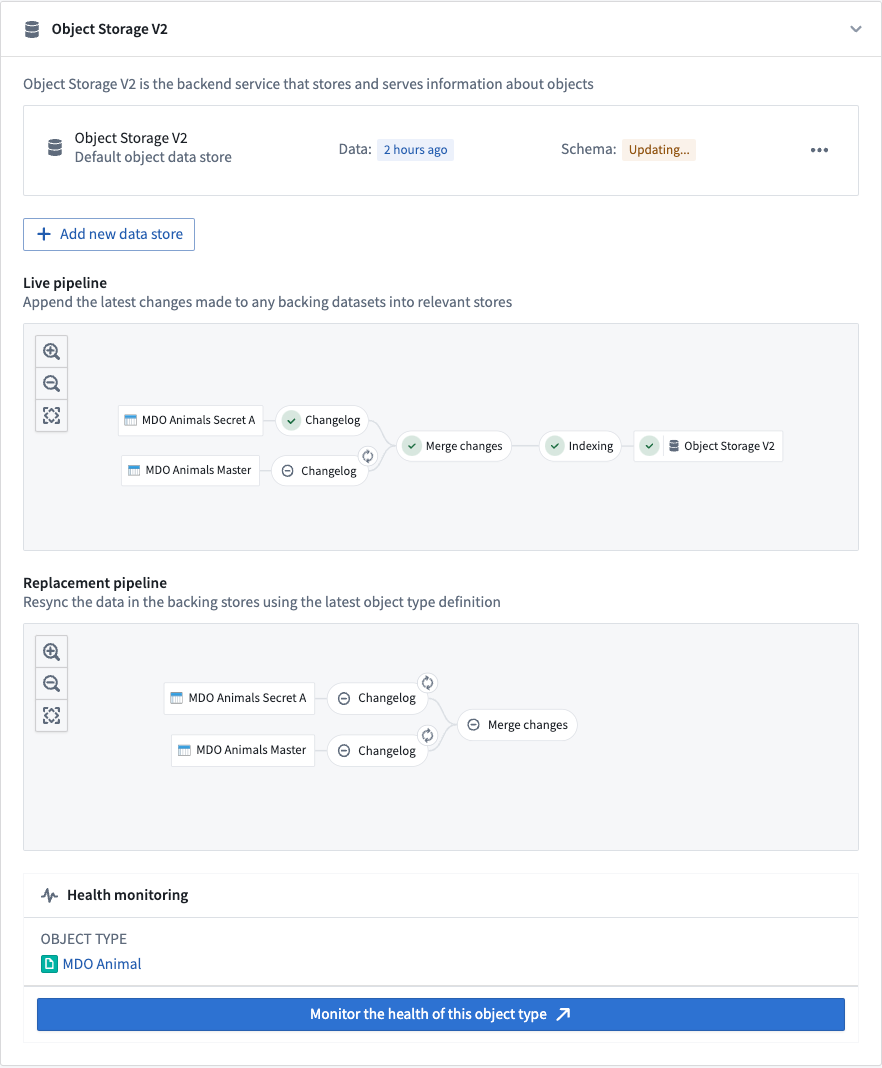
Changelog
Changelogジョブでは、Funnelがすべてのデータソースのデータ差分を自動的に計算し、新しいデータやトランザクションがデータソースに届くと、Funnelパイプライン内で中間のchangelogデータセットを作成します。Changelogデータセットは、各トランザクションのデータ差分を含むAPPENDトランザクションを受け取り、増分計算のセマンティクスを提供します。これらのchangelogデータセットはFunnelによって所有および管理されており、ユーザーはアクセスできません。
Merge changes
Merge changesジョブでは、changelogステップからのすべてのchangelogデータセットおよびActionsからの最近のユーザー編集がオブジェクトタイプの主キーで結合され、すべての変更がマージされ、別のデータセットに保存されます。これらのマージされたデータセットはFunnelによって所有および管理されており、ユーザーはアクセスできません。
Indexing
変更がマージされた後、Funnelはオブジェクトデータベースごとにインデックスジョブを開始し、すべての変更がマージされた最終データセット内のすべての行を、オブジェクトタイプに設定されたオブジェクトデータベースと互換性のある形式に変換します。たとえば、標準のOSv2データベースの場合、前のステップからのマージされた変更データセット内のすべての行がインデックスファイルに変換され、これらのファイルは別のインデックスデータセットに保存されます。これらのインデックスデータセットはFunnelによって所有および管理されており、ユーザーはアクセスできません。
Hydration
インデックスジョブが完了すると、オブジェクトデータベースはクエリのためにインデックスされたデータを準備する必要があります。OSv2を例にとると、この準備ステップには、インデックスファイルをデータセットからOSv2データベースの検索ノードのディスクにダウンロードすることが含まれます。このプロセスはhydrationとして知られており、オブジェクトタイプのデータを更新するためのFunnelバッチパイプラインの最終ステップです。
Hydrationジョブの進行状況は、Ontology Managerアプリケーションで報告され、以下のスクリーンショットに示されています。
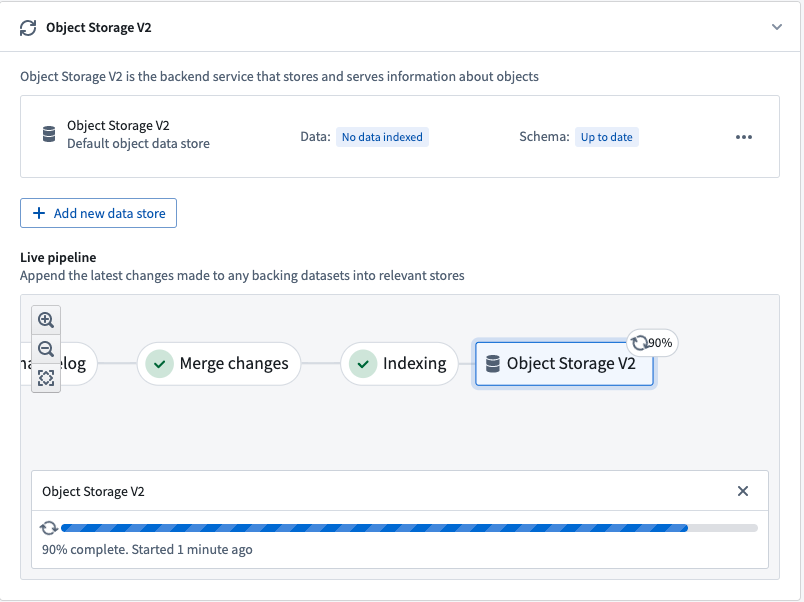
これらのステップが完了すると、オブジェクトタイプは使用可能になり、他のサービスやFoundry内でクエリを実行できます。
ライブおよび置換Funnelパイプライン
オブジェクトタイプにデータ更新またはスキーマ更新がある場合、2つの別々のFunnelパイプラインが関与します。以下のスクリーンショットは、これら2つのFunnelパイプラインを示しています。
ライブパイプライン
Funnel ライブパイプラインは、Foundryデータソースからの新しいデータを使って本番環境のオブジェクトタイプを更新します。ライブパイプラインは、それぞれのデータソースが更新されるたびに実行されます。さらに、オブジェクトに対するユーザーの編集が検出された場合、ライブパイプラインは明示的な元データセットの更新がなくても6時間ごとに実行され、ユーザーの編集がFunnel所有のデータセットにインデックス化されるマージ変更ステップで永続化されることを保証します。
ユーザーの編集はオブジェクトデータベースのインデックスに即時に適用されることに注意してください。定期的な6時間のジョブ間隔は、このデータをFoundryに永続的に保存するための組み込み制御メカニズムを提供します。
置換パイプライン
オブジェクトタイプのスキーマが変更され、以前のパイプラインのスキーマが最新でなくなった場合、新しい置換パイプラインがオブジェクトタイプの更新を調整するために準備される必要があります。スキーマの変更には、オブジェクトタイプに新しいプロパティタイプを追加する、既存のプロパティタイプを変更する、またはオブジェクトタイプの入力データソースを別のデータソースに置き換えることが含まれます。
ライブパイプラインは通常のスケジュールで実行され続けますが、Funnelはバックグラウンドで置換パイプラインを調整し、ユーザーに提供されるライブデータに影響を与えることなく実行します。置換パイプラインが初めて正常に実行されると、ライブパイプラインは破棄され、置換パイプラインに置き換えられます。これにより、オブジェクトタイプのスキーマとデータが更新されます。
インクリメンタルおよび完全再インデックス化
以下のドキュメントは標準のObject Storage V2データストアに特化しています。Object Storage V1 (Phonograph) のインデックス化動作に関する情報は、OSv1ドキュメントを参照してください。
インクリメンタルインデックス化 (デフォルト)
標準のObject Storage V2データストアは、データソース内のすべての新しいトランザクションに対してデータ差分を自動的に計算し、新しいデータ更新のみをインクリメンタルにインデックス化します。Funnelパイプラインはすべてのオブジェクトタイプに対してデフォルトでインクリメンタルインデックス化を使用します。インクリメンタルインデックス化により、すべてのデータを再インデックス化する場合に比べてFunnelパイプラインは迅速に実行されます。
たとえば、100行のデータソースを利用した100個のオブジェクトインスタンスを持つオブジェクトタイプがあるとします。新しいデータ更新でそのうちの10行が変更された場合、入力データソースのトランザクションタイプに関係なく、すべての100個のオブジェクトインスタンスを再インデックス化する代わりに、Funnelバッチパイプラインは変更された10行のみを含む新しいAPPENDトランザクションをchangelogデータセットに作成します。
増分データセットのインクリメンタルインデックス化
Object Storage V2は、増分データセットを利用したオブジェクトタイプの同期時に「最新のトランザクションが優先される」戦略を使用します。データセット内に同じ主キーを持つ複数の行が含まれている場合、オントロジーには最新のトランザクションの行のデータが存在します。1つのトランザクション内に重複する主キーを持つことはできません。この動作はユーザー編集とデータソース更新の競合の処理方法には関係ありません。
通常、changelogデータセットと呼ばれる増分データセットがAPPENDトランザクションを通じて行の更新を受け取ると仮定します。同じデータの新しいバージョンは、新しい値を持ちますが同じ主キーを持つ新しい行としてデータセットに追加されます。changelogデータセットにはBoolean型のis_deleted列が含まれる場合があります。is_deleted列の値がtrueの場合、その行は削除されたと見なされます。
Object Storage V2はchangelogデータセットを以下のように同期します。
- 主キーが複数のトランザクションに表示される場合、最新のトランザクションの行が保持されます。
- 各トランザクションには、主キーごとに最大1行を含めることができます。
- データセットがObject Storage V1のchangelogである場合、Object Storage V2は
is_deleted列を尊重しますが、順序付け列は尊重しません。
各トランザクションに主キーごとに最大1行を含めるように、changelogデータセットに対してインクリメンタルウィンドウトランスフォームを実行する必要がある場合があります。
Copied!1 2 3 4 5 6 7 8 9 10 11from pyspark.sql.window import Window from pyspark.sql import functions as F # ウィンドウ関数を定義し、primary_keyでパーティションを分け、ordering列を降順に並べる ordering_window = Window().partitionBy('primary_key').orderBy(F.col('ordering').desc()) # rank列を追加し、ウィンドウ関数を使用して各パーティション内で行番号を付与 df = df.withColumn('rank', F.row_number().over(ordering_window)) # rankが1で、is_deletedがFalseの行だけをフィルタリング df = df.filter((F.col('rank') == 1) & ~F.col('is_deleted'))
フル再インデックス(特殊なケース)
Funnelパイプラインは、以下の2つのケースでバッチインデックス(すべてのオブジェクトインスタンスを再インデックス)を使用します:
- 入力データソースの行の一定割合以上が同じトランザクションで変更された場合、変更履歴を計算してインクリメンタルにインデックスするよりも、再インデックスの方が計算コストが低く、速くなることがあります。デフォルトの閾値は、同じトランザクションで変更された行の80%に設定されています。
- オブジェクトタイプのスキーマの特定の変更は、Funnel置換パイプラインを必要とし、これによりバックグラウンドで新しいFunnelパイプラインが作成されます(OSv2インデックスを含む)。
Funnelパイプラインの監視
Funnelパイプラインは複数のビルドジョブで構成されており、監視ビューによりユーザーはFunnelパイプライン内の特定のジョブの健康状態を追跡することができます。これには、監視ルールのセットを作成することが含まれます。
ユーザーは、オントロジーマネージャーでこのオブジェクトタイプの健康状態を監視を選択することで、監視ビューを作成できます。これにより、以下のスクリーンショットに示されるように、Data Healthアプリケーションの監視ビュータブに移動します。
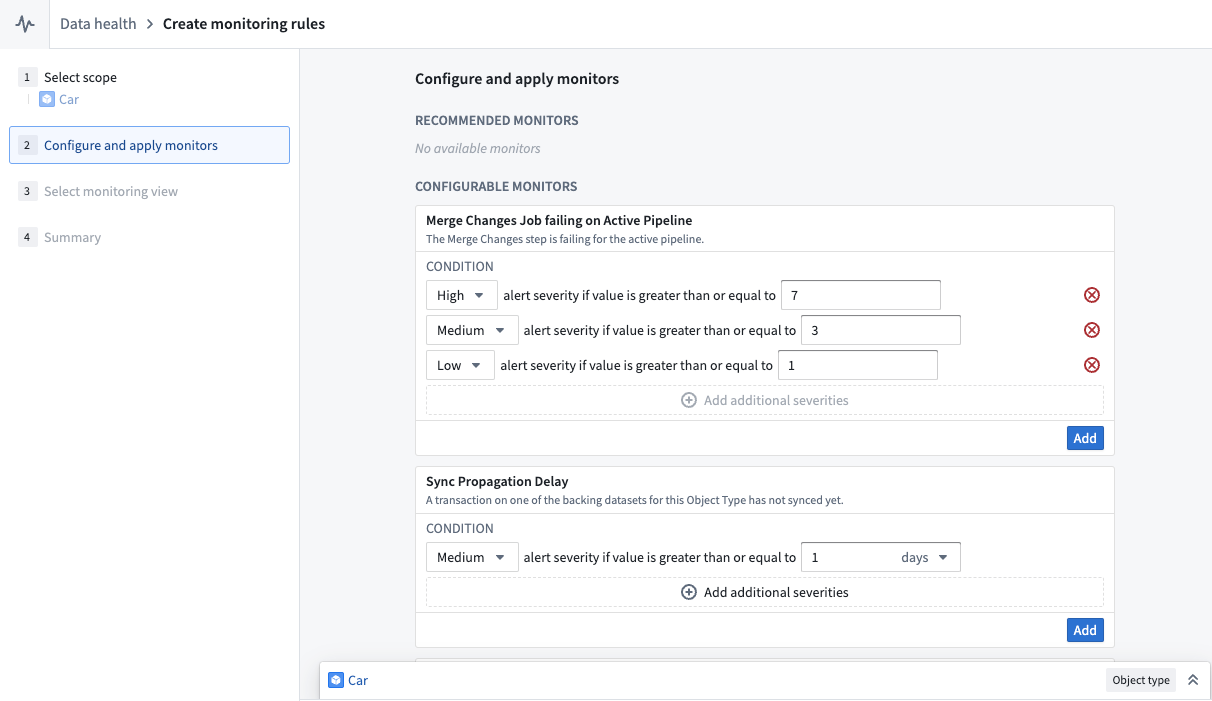
監視ビュータブから、ユーザーはライブパイプラインおよび置換パイプラインのジョブを監視するルールを作成できます。また、インデックスされたデータの新鮮さがルールで定義された閾値を超えたときに通知を受けるための同期伝播遅延ルールを追加することもできます。
一方、Object Storage V1(Phonograph)は、オントロジーエンティティの同期を監視するためにヘルスチェックを使用します。OSv1ではオブジェクトタイプに対して単一の同期ジョブしか存在せず、ユーザーはこれらのヘルスチェックを直接同期ジョブに定義することができます。
パイプラインのデバッグ
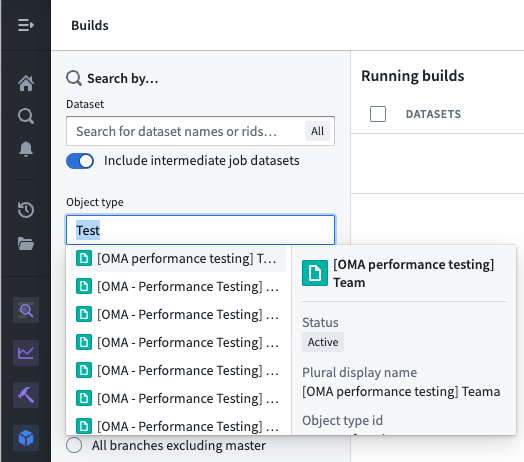
Foundryビルドジョブはさまざまな理由で失敗することがあります。オブジェクトタイプの元データセットに対してView権限を持つユーザーは、オブジェクトタイプのデータソースタブのライブパイプラインダッシュボードを通じてパイプラインエラーを確認できます。パイプライングラフで失敗したジョブを選択し、以下のスクリーンショットに示されるように失敗したジョブを選択します。
または、Buildsアプリケーションに移動し、左パネルの検索フィルターでオブジェクトタイプをフィルター処理することで、特定のオブジェクトタイプに対するすべてのビルドジョブを一覧表示することもできます。