注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
実体化
最新のデータは多くの Foundry ワークフローにとって重要です。オントロジーのユーザーは、入力データソースとユーザー編集からのデータを組み合わせることにより、オントロジーから各オブジェクトインスタンスの最新状態を含むインデックス化されたデータの 実体化 を作成できます。
実体化のユースケース
実体化の主なユースケースは以下の 2 つです:
- ユーザー編集を含む各オブジェクトインスタンスの最新状態を必要とする下流の Foundry パイプラインを構築する。
- オブジェクトタイプのすべてのオブジェクトインスタンスの最新状態を含むオントロジーデータのダウンロードを可能にする。
一括ダウンロードを Foundry でオーケストレーションするには、実体化データセットを作成し、他の Foundry データセットの既存のダウンロードワークフロー(たとえば、データエクスポートや Foundry Transforms を通じたエクスポート)を通じてダウンロードを開始することをお勧めします。
実体化データセットの作成
オントロジーマネージャーのデータソースタブで編集構成を切り替えて 実体化タブに移動します。実体化タブでは、入力データソースタイプ に応じたさまざまな構成で、実体化オブジェクトデータセットやオブジェクト制限付きビューを作成できます。
書き戻しデータセットと実体化データセットの比較
Object Storage V1 (Phonograph) では、書き戻しデータセット が実体化データセットに相当します。書き戻しデータセットは、結合テーブルを持つ多対多リンクタイプのオブジェクトタイプでユーザー編集を有効にするために OSv1 で必要です。
Object Storage V2 では、オブジェクトタイプでユーザー編集を有効にするために実体化データセットは必要ありません。代わりに、ユーザーはオントロジーマネージャーのデータソースタブで編集構成を切り替えることで、オブジェクトタイプのユーザー編集を有効にできます。これにより、上記の 2 つの主要なユースケースが必要な場合にのみ実体化を作成することが OSv2 ではオプションとなります。OSv2 では、オブジェクトタイプのプロパティの一部のみを実体化したい場合に、複数の実体化データセットを作成することも可能です。
以下に記載されているように、OSv1 の書き戻しデータセットと OSv2 の実体化データセットには他の動作の違いもあります。
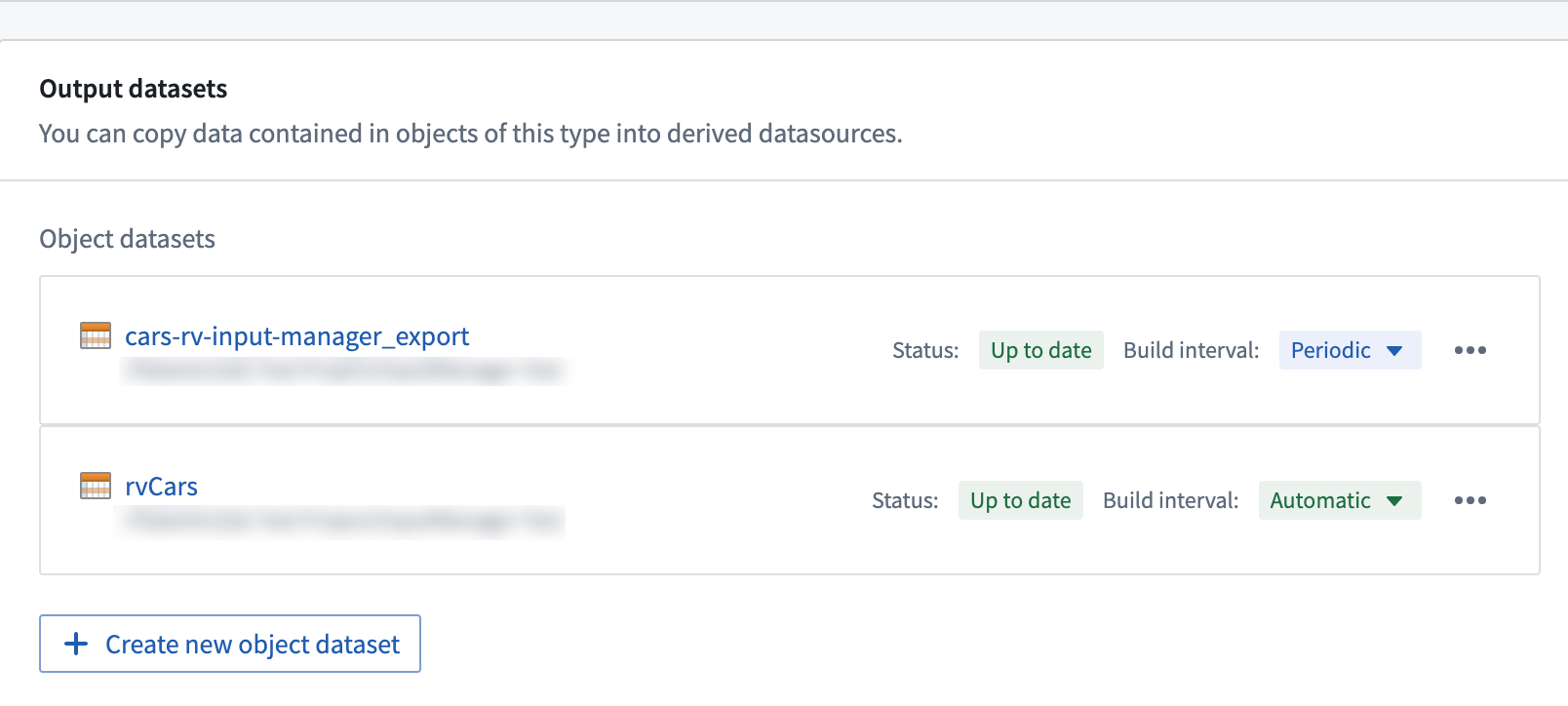
書き戻しデータセットと実体化データセットのビルドスケジュール
Object Storage V1 (Phonograph) の書き戻しデータセットと Object Storage V2 の実体化データセットは、ビルドスケジュールの扱いが異なります。
- OSv1 では、新しいユーザー編集があったときに書き戻しデータセットのビルドをトリガーするメカニズムはありません。代わりに、ユーザーは書き戻しデータセットのビルドを希望する頻度でスケジュールを作成できます。新しいデータがない場合、これらのビルドは追加の計算リソースを使用しないように自動的に中止されます。スケジュールが設定されておらず、書き戻しデータセットがビルドされていない場合、書き戻しデータセットのデータはオントロジーの正確な表現ではない可能性があります。
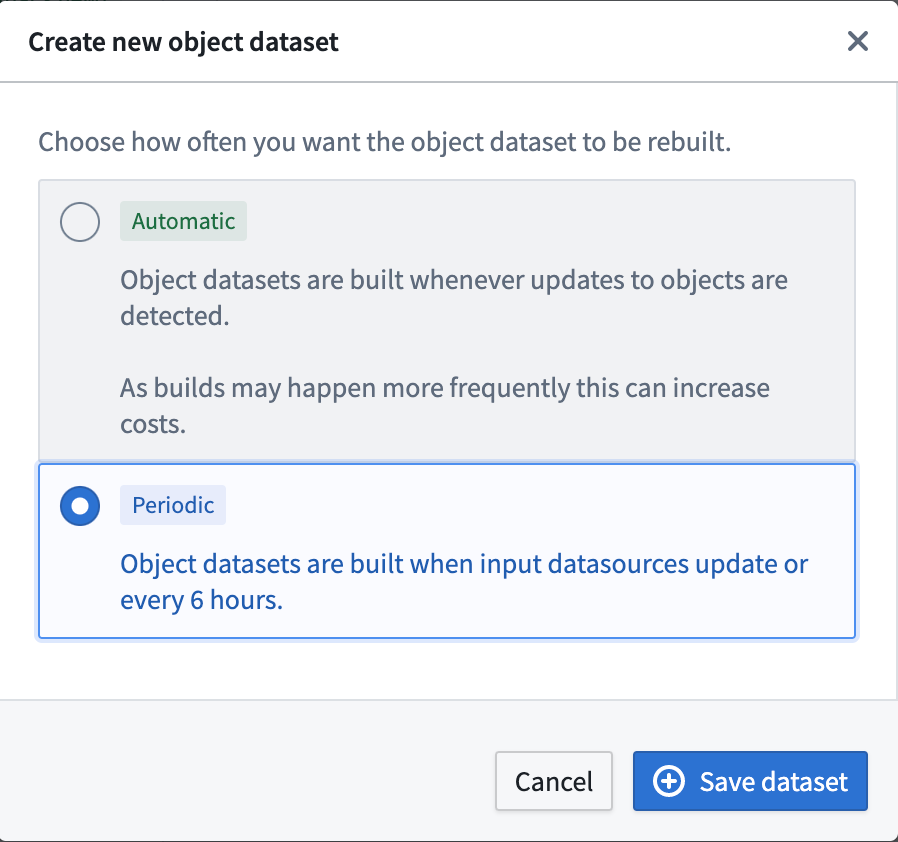
- OSv2 では、2 つの異なるユースケースに対処するための設計が行われています。
- 編集が適用されるとすぐに実体化データセットにユーザー編集を反映させるために、ユーザーは自動プロパゲーションを有効にできます。このモードでは、ユーザー編集が数分の遅延で自動的に設定された実体化データセットにプロパゲートされます。新しいユーザー編集の頻度に応じてより頻繁にビルドが発生する可能性があるため、追加コストが発生する場合があります。
- 実体化データセットへのユーザー編集のプロパゲーションの遅延が重要でない場合、ユーザーは定期的ビルドを構成することでコストを削減できます。このモードでは、入力データソースに新しいデータがある場合や 6 時間ごとに実体化データセットが再ビルドされます。
書き戻しデータセットと実体化データセットの保持
書き戻しデータセットと実体化データセットの保持は同じではありません。
-
OSv1 では、書き戻しデータセットはプラットフォーム内で指定できる特定の保持ポリシーに設定できる通常のデータセットのように機能します。これにより、書き戻しデータセットが定期的にビルドされる場合、オブジェクトタイプの状態の履歴スナップショットを遡って確認できます。
-
OSv2 では、実体化データセットはカスタマイズ可能な保持が適用されません。履歴トランザクションは常に削除され、最新のスナップショットのみが利用可能であることが保証されます。この場合、オブジェクトタイプの状態の履歴スナップショットを保持することが重要な場合は、下流にトランスフォームを設定する必要があります。
書き戻しデータセットと実体化データセットのスキーマ
Object Storage V1 (Phonograph) の書き戻しデータセットと Object Storage V2 の実体化データセットは、入力データソースのスキーマとの関係が異なります。
- OSv1 では、入力データソースのスキーマがコピーされ、書き戻しデータセットのスキーマとして使用されます。
- OSv2 では、Foundry オントロジーの可読性を高めるために、この動作が変更されました。ユーザーがオントロジーからデータを実体化しているため、実体化データセットに使用されるスキーマは、元のデータソースの構成に依存するのではなく、オントロジーの定義からコピーされます。具体的には、各プロパティのAPI 名メタデータが実体化データセットのスキーマとして使用されます。入力データソースのスキーマを引き続き使用したい場合は、OSv1 から OSv2 への移行中に Palantir の担当者に連絡してください(たとえば、既存の書き戻しデータセットの後方互換性を保証するため)。
__ で始まる列(たとえば __is_deleted、__patch_offset)は、オブジェクトタイプの状態に関する情報を表すものではなく、Foundry が重複排除の目的で使用するメタデータ列です。これらの列は、事前の警告なしに将来のリリースで名前が変更されたり削除されたりする可能性があり、本番ワークフローで使用すべきではありません。
書き戻しデータセットと実体化データセットの制限付きビュー
Object Storage V1 (Phonograph) では、入力データソースとして制限付きビューを使用して細かく権限設定されたオブジェクトタイプの制限付きビューを実体化することはできません。ユーザーは、制限付きビューの入力データソースの元データセットからすべての行を含む書き戻しデータセットのみを実体化できます。その後、ユーザーはアクセス制限に基づいて書き戻しデータセットへのアクセスを適切に保護する責任があります。
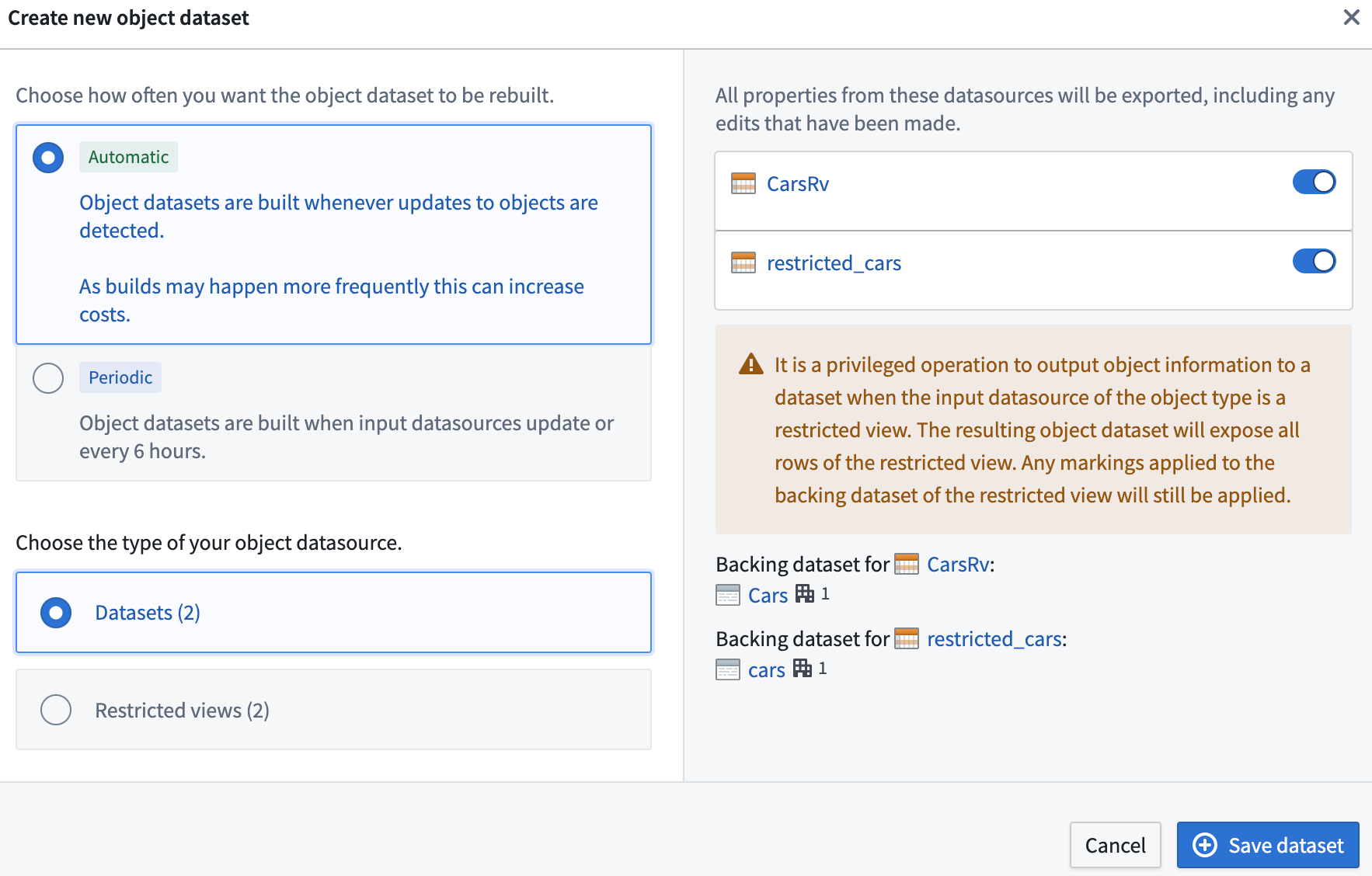
Object Storage V2 では、ユーザーは、入力データソースとして制限付きビューを使用して細かく権限設定されたオブジェクトタイプのために、通常のデータセットまたは制限付きビューの両方を実体化リソースとして構成できます。以下に示すように。
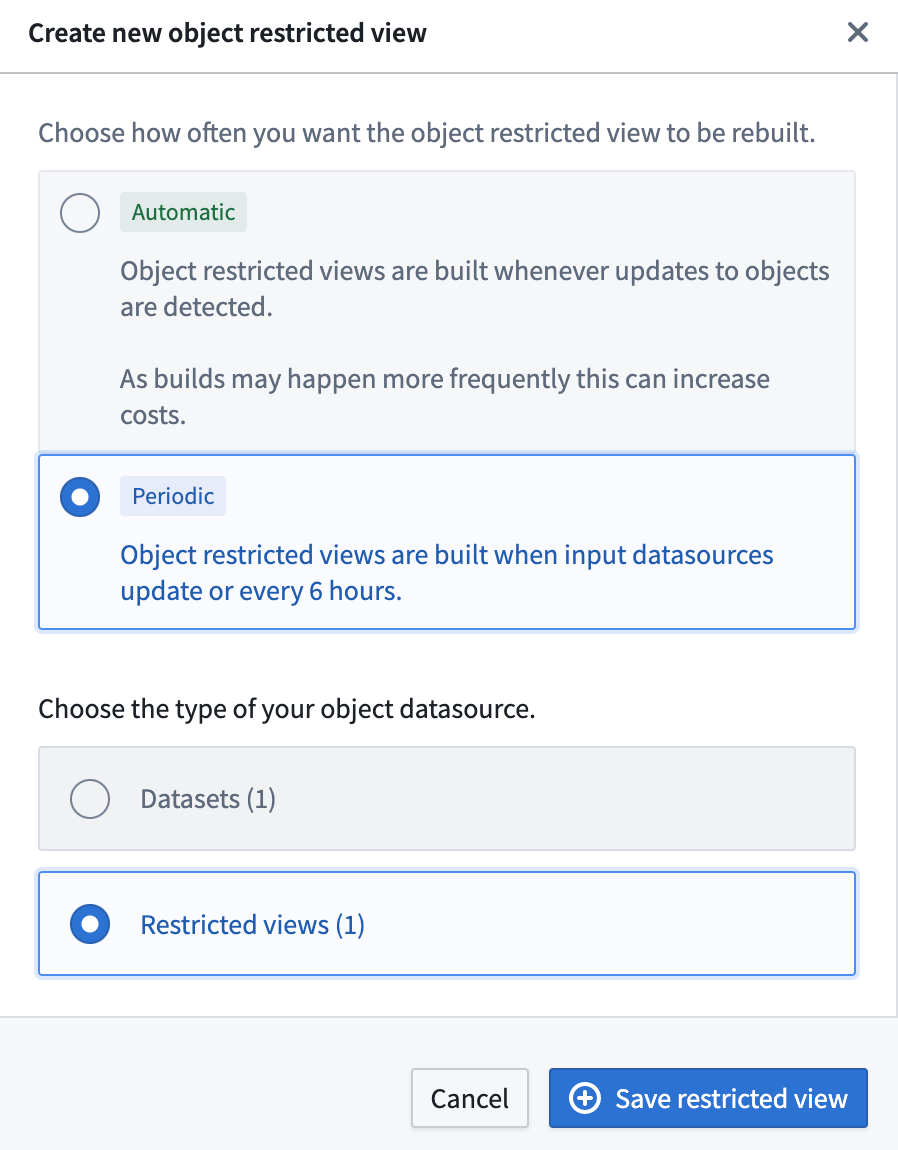
複数の入力データソースを持つオブジェクトタイプの場合、ユーザーはどの入力データソースからデータを実体化するかを選択して実体化データセットを構成できます。入力データソースが選択されていない場合、その入力データソースからマッピングされたオブジェクトタイプのプロパティは実体化データセットに反映されません。入力データソースの一部が制限付きビューの場合、ユーザーには次の 2 つのオプションがあります:
- 制限付きビューリソースの 1 つを選択して制限付きビューとして実体化することができます。以下に例の構成を示します。
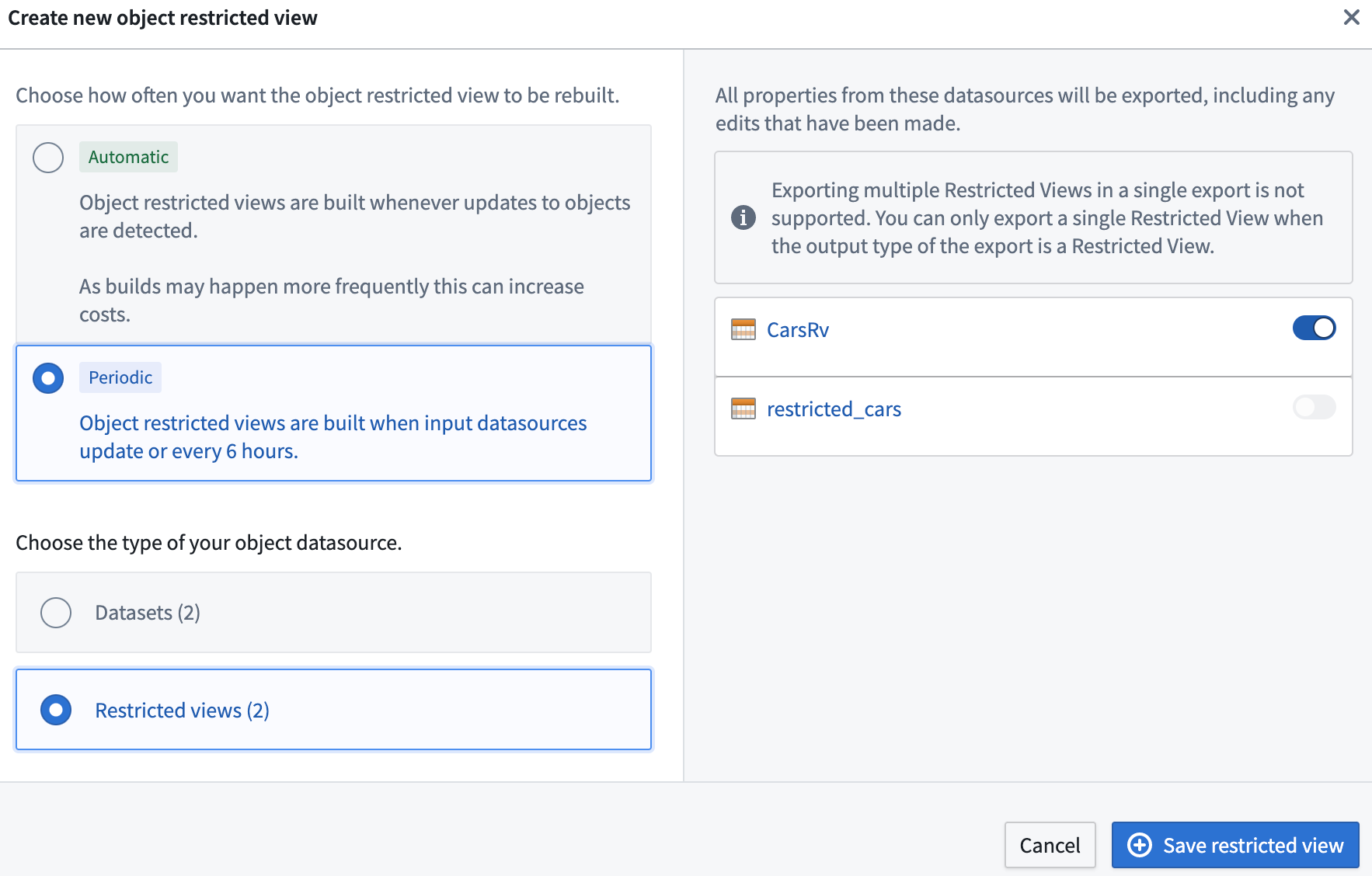
- 複数の入力データソースを選択することもできますが、その場合はオントロジーデータをFoundry データセットとしてのみ実体化できます。この制限は、異なる制限付きビュー入力データソースが異なるポリシー構成を持つ可能性があり、制限付きビューが現在、列レベルのポリシー設定をサポートしていないためです。以下に例の構成を示します。