注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
集約に関する考慮事項
Foundry では、取り扱っているデータの複雑さや量によって、アプリケーションが完全な精度(いわゆる「不完全な集約」)で結果を表示できない場合があります。これは、高いカーディナリティを持つ集約の性質によるものです。
object-set-service API には、以下の集約精度に関連するフィールドがあり、利用可能な場合は精度を向上させるために使用できます。
- API の呼び出し元は、リクエストに
AggregationExecutionModeを追加し、PREFER_ACCURACYに設定することができます。設定されている場合、API の応答は遅くなりますが、完全な精度の保証はありませんが、より正確な結果が得られます。 - 集約応答には
AggregateResultAccuracyフィールドが含まれており、結果が正確であるかどうかを示します。
Foundry の各製品では、集約が不完全であることを示す動作がわずかに異なります。以下のセクションで、Foundry で不完全な集約がどのように現れるかの例と、精度を追求する際のユーザーの考慮事項を確認してください。
詳細なガイダンスが必要な場合は、Palantir サポートにお問い合わせください。
Object Explorer と Workshop
以下の 2 つのヒストグラムのスクリーンショットを考慮してください。これらは、2,000 万のオブジェクトを持つデータセットからのデータを示しています。最初のスクリーンショットは、Object Explorer に取り込まれたデータセットであり、2 番目は、Workshop 内の Workshop Filter List ウィジェットです。
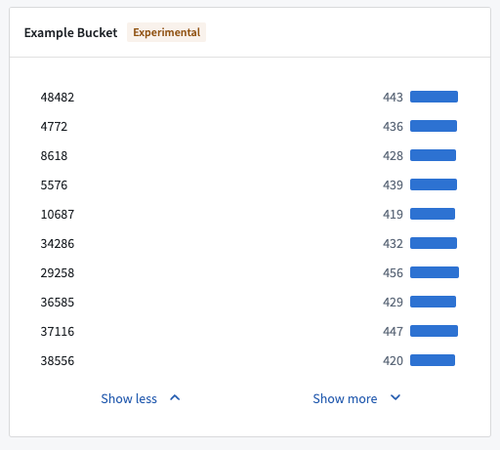

ヒストグラムは、2 つの集約リクエストを使用して構築されました。最初のリクエストでは、カウントで上位 100 のバケットを取得しようとして、おおよその応答を受け取ります。2 番目のリクエストでは、同じ 100 のバケットのカウントを再度取得しますが、さらに、これらの 100 のバケットのみにフィルター処理して、カウントの正確さを確保します。
表示されるカウントは正確ですが、2 番目のヒストグラムは、表示されるバケットがカウントの実際の上位 100 のバケットではないという意味で、まだ不正確です。これは、最初の集約応答が正確ではなかったためです。
Object Explorer と Workshop からの OSS へのリクエストは、AggregationExecutionMode を指定せず、OSS は PREFER_SPEED をデフォルトとして使用します。
Quiver ピボットテーブルと Workshop ピボットテーブル
Quiver と Workshop のピボットテーブルで、カウントで降順に列を並べ替える場合、上位のバケットが適切な順序で表示されません。この場合、不完全な集約は、以下のエラーメッセージのいずれかで特徴付けられることがあります。
- "
columnの値が多すぎて、すべては表示されません" - "計算上の制限のため、おおよその結果が表示されています"
- "プロパティごとに最初の 1,000 の値のみを読み込んでいます。データをフィルター処理することで、より正確な結果が得られます。"
以下の例では、Example Bucket 列が、所望の降順でランク付けされていません。
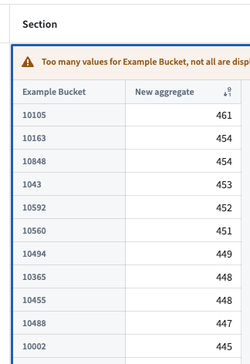
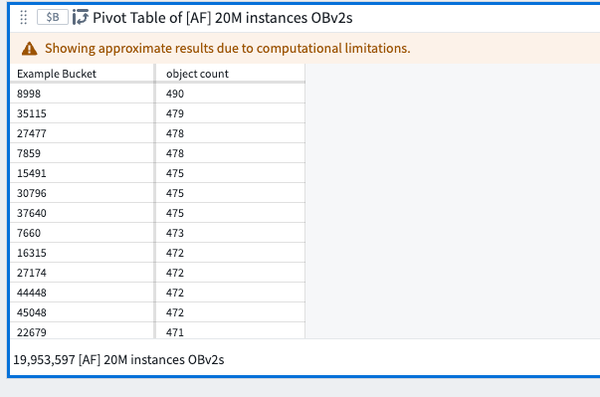

これらは、Quiver と Workshop がピボットテーブルをバックアップする集約リクエストで順序付けを指定しないため、実際の上位バケットではありません。並べ替えは、返されたバケットを使用してフロントエンドで完了されます。
Ontology SDK(OSDK)
OSDK は PREFER_ACCURACY に設定されており、限定的な集約複雑さにより、すべてのクエリ応答が ACCURATE になります。
関数
関数は常に PREFER_ACCURACY を使用するため、特定のバケットの値は正確です。現在、関数呼び出し中に groupBy と orderBy を同時に行う方法はありません。以下のコードスニペットは、バックエンドでの groupBy およびメモリ内での順序付けの現在の例を示しています。
@Function()
public async aggregateOnMoreBucketsThanAuthorized(): Promise<TwoDimensionalAggregation<string, Double>> {
// 集計して合計します
const aggregation = await Objects.search()._af20mInstancesObv2()
.groupBy(o => o.exampleBucket.topValues())
.count()
// バケットを値の降順でソートします
aggregation.buckets.sort((b1, b2) => b2.value - b1.value);
return aggregation;
}
例の結果:
{
"buckets": [
{
"key": {
"string": "10105",
"type": "string"
},
// 値:461(データ型:倍精度浮動小数点数)
"value": {
"double": 461,
"type": "double"
}
},
{
"key": {
"string": "10163",
"type": "string"
},
// 値:454(データ型:倍精度浮動小数点数)
"value": {
"double": 454,
"type": "double"
}
},
{
"key": {
"string": "10848",
"type": "string"
},
// 値:454(データ型:倍精度浮動小数点数)
"value": {
"double": 454,
"type": "double"
}
},
...