注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
パフォーマンスの最適化
このセクションでは、ユーザーがFunctionsで経験する最も一般的なパフォーマンス問題を説明し、ボトルネックを回避するためのコード最適化方法を文書化することを目的としています。
パフォーマンスタブを使用してFunctionのパフォーマンスを向上させる
パフォーマンスタブは、Functionsのパフォーマンス問題を分析し特定するためのツールを提供します。これは、Functionが実行された後にFunctionsヘルパーで見つけることができます。
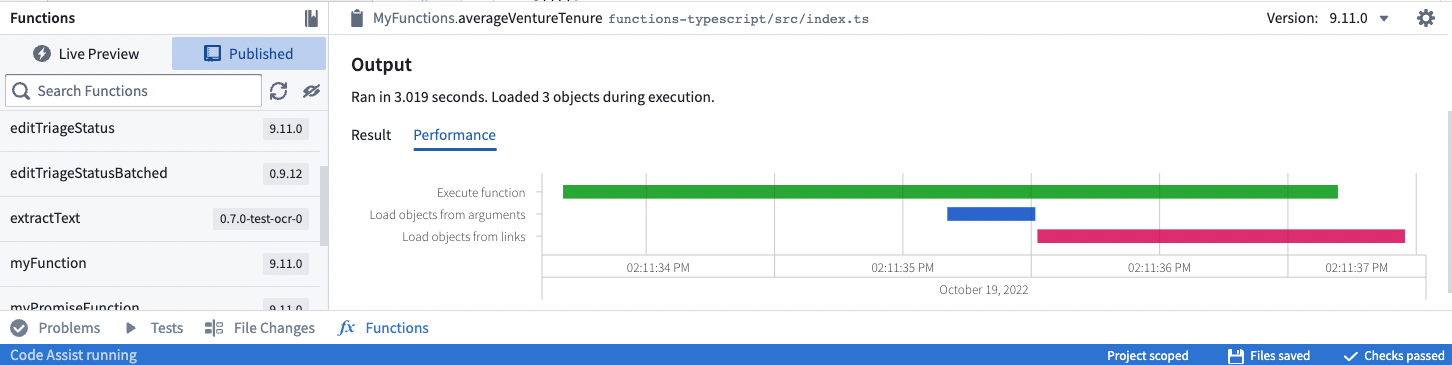
ウォーターフォールグラフは、X軸上の時間に沿って水平バーとして操作を表します。各操作には、時間の費やされ方を示すマーカーがあります。
- Execute Functionは、Functionコードを実行するために費やされたCPU時間を示します。
- Load objects from argumentsおよびLoad objects from linksは、基盤となるオントロジーバックエンドデータベースサービス(OSS)を呼び出すために費やされた時間を示します。
パフォーマンスを向上させるために、次のことができます:
- オブジェクトAPIを使用して、TypeScriptよりも迅速にリンクを集計およびトラバースする(以下で説明されているように)。
- オントロジーバックエンドサービスの呼び出しが並行して行われるようにして、シーケンシャルな読み込みを避ける。複数の
async/await呼び出しがある場合、Promise.allを使用してすべての呼び出しを並行してawaitする。- たとえば、一般的なパターンとして、リスト内の各オブジェクトに対して
.map()を使用して呼び出しをそのPromisesにマップし、その後、結果のリストに対してPromise.allを使用する。
- たとえば、一般的なパターンとして、リスト内の各オブジェクトに対して
- 実行時間を増加させる可能性のある不要なネストループを避ける。
可能な限りオブジェクトAPIを使用することを推奨
Workshopのderived propertiesを使用する際の一般的なパラダイムは、各オブジェクトのリンクを集計してプロパティ値を計算することです(例:関連オブジェクトの数をカウントする)。
以下のコードは機能しますが、Function自体がすべてのリンクされたオブジェクトを取得し、その後集計(この場合、長さを計算)を実行する必要があります:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15@Function() public async getEmployeeProjectCount(employees: Employee[]): Promise<FunctionsMap<Employee, Integer>> { // 各従業員のプロジェクト履歴を非同期で取得するプロミスを作成 const promises = employees.map(employee => employee.workHistory.allAsync()); // すべてのプロミスが解決されるまで待機し、結果を取得 const allEmployeeProjects = await Promise.all(promises); // FunctionsMapを初期化 let functionsMap = new FunctionsMap(); // 各従業員とそのプロジェクト数をFunctionsMapに設定 for (let i = 0; i < employees.length; i++) { functionsMap.set(employees[i], allEmployeeProjects[i].length); } // 完成したFunctionsMapを返す return functionsMap; }
上記は非同期APIおよび非同期関数(リンクトラバーサルの最適化を参照)を活用していますが、多くの場合、Objects API が提供する集計メソッドを使用することが有益です。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26@Function() public async getEmployeeProjectCount(employees: Employee[]): Promise<FunctionsMap<Employee, Integer>> { const result: FunctionsMap<Employee, Integer> = new FunctionsMap(); // employeesパラメータからemployeeIdが一致するすべてのプロジェクトを取得し、 // 各employeeIdにマッピングされるプロジェクトの数をカウントする const aggregation = await Objects.search().project() .filter(project => project.employeeId.exactMatch(...employees.map(employee => employee.id))) .groupBy(project => project.employeeId.byFixedWidths(1)) .count(); const map = new Map(); aggregation.buckets.forEach(bucket => { // bucket.key.minはemployeeIdを表し、各バケットのサイズは1である。 map.set(bucket.key.min, bucket.value); }); employees.forEach(employee => { const value = map.get(employee.primaryKey); if (value === undefined) { return; } result.set(employee, value); }); return result; }
この方法では、最初にすべてのリンクされたプロジェクトを取り込む必要なく、1ステップで集計を実行できます。
通常の集計の制限が適用されることに注意してください。特に、文字列IDに対する .topValues() は上位 1000 個の値しか返しません。集計は現在最大 10K バケットに制限されているため、目的の結果を取得するために複数の集計を行う必要があるかもしれません。詳細については Computing Aggregations を参照してください。
リンクトラバーサルの最適化
Functions におけるパフォーマンス問題の最も一般的な原因は、リンクを効率的でない方法でトラバースすることにあります。多くの場合、これは多くのオブジェクトをループし、ループの各反復で関連するオブジェクトをロードするためのAPIを呼び出すコードを書いたときに発生します。
Copied!1 2 3 4for (const employee of employees) { // 各従業員の過去のプロジェクトを取得する const pastProjects = employee.workHistory.all(); }
この例では、ループの各反復で個々の従業員の過去のプロジェクトをロードし、データベースへの往復を引き起こします。この遅延を回避するために、多くのリンクを一度にトラバースする場合は、非同期リンクトラバーサルAPI(getAsync() および allAsync())を使用できます。以下は、リンクを非同期でロードするように書かれた関数の例です:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24@Function() public async findEmployeeWithMostProjects(employees: Employee[]): Promise<Employee> { // 各従業員のプロジェクトを非同期で読み込むためのPromiseを作成する const promises = employees.map(employee => employee.workHistory.allAsync()); // 全てのPromiseを実行し、全てのリンクを並列で読み込む const allEmployeeProjects = await Promise.all(promises); // 結果を反復して、最も多くのプロジェクトを持つ従業員を見つける let result; // 最終的に最もプロジェクト数が多い従業員を格納する変数 let maxProjectsLength; // 最大プロジェクト数を格納する変数 for (let i = 0; i < employees.length; i++) { const employee = employees[i]; const projects = allEmployeeProjects[i]; // 現在の従業員のプロジェクト数が最大プロジェクト数より多い場合、結果を更新する if (!result || projects.length > maxProjectsLength) { result = employee; maxProjectsLength = projects.length; } } return result; // 最も多くのプロジェクトを持つ従業員を返す }
この例では、ES6 の 非同期関数 ↗ を使用しています。これにより、.getAsync() および .allAsync() メソッドから返される Promise の戻り値を便利に処理することができます。
派生列生成の最適化
Workshop は、オブジェクト (FOO) に対して関数を利用して derived properties を計算することをサポートしています。Workshop アプリケーションは通常、オブジェクトテーブルから数十行のコンテンツを持つこれらの関数を呼び出します。その後、関数は各オブジェクトが派生列の表示値にマッピングされるマップを返します。以下は、最適化されていない実装の例です:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44import { Function, FunctionsMap, Double } from "@foundry/functions-api"; // 処理対象のオブジェクトタイプを "objectTypeA" から必要なものに置き換えてください。 import { Objects, ObjectSet, objectTypeA } from "@foundry/ontology-api"; export class MyFunctions { /* * この関数は ObjectSet を入力として受け取り、派生列を出力として生成します。 * この派生列は各オブジェクトインスタンスを数値にマッピングし、その値が列を埋めるようにします。 * この実装はオブジェクトのプロパティに定数値を掛ける単純な for ループです。 * これは後で改善する基本ケースとして役立ちます。 */ @Function() public getDerivedColumn_noOptimization(objects: ObjectSet<objectTypeA>, scalar: Double): FunctionsMap<objectTypeA, Double> { // 返却する結果マップを定義 const resultMap = new FunctionsMap<objectTypeA, Double>(); /* メモリにロードできるオブジェクト数には制限があります。 * 現在のオブジェクトセットのロード制限については、制限に関するドキュメントを参照してください。 */ const allObjs: objectTypeA[] = objects.all(); // ロードされた各オブジェクトに対して計算を行います。結果が定義されている場合、それを結果マップに保存します。 allObjs.forEach(o => { const result = this.computeForThisObject(o, scalar); if (result) { resultMap.set(o, result); } }); return resultMap; } // 指定されたオブジェクトに対して必要な値を計算する関数の例。 private computeForThisObject(obj: objectTypeA, scalar: Double): Double | undefined { if (scalar === 0) { // ゼロ除算エラー return undefined; } // exampleProperty が定義されているか確認し、そうであれば除算を行います。定義されていない場合は undefined を返します。 return obj.exampleProperty ? obj.exampleProperty / scalar : undefined; } }
計算が簡単であれば、関数はすばやく実行されます。計算が複雑な場合、非同期実行を使用して計算時間を短縮することが可能です。この方法では、各オブジェクトの計算が並行して実行されます。以下はその例です:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92import { Function, FunctionsMap, Double, TwoDimensionalAggregation } from "@foundry/functions-api"; // "objectTypeA"を処理するオブジェクトタイプに置き換えます。 import { Objects, ObjectSet, objectTypeA, objectTypeB } from "@foundry/ontology-api"; /* * この関数は、オブジェクトのprimaryKeyのリストを入力として受け取り、派生列を出力として生成します。 */ @Function() public async getDerivedColumn_parallel(objects: ObjectSet<objectTypeA>, scalar: Double): Promise<FunctionsMap<objectTypeA, Double>> { // 結果マップを定義します。 const resultMap = new FunctionsMap<objectTypeA, Double>(); /* メモリにロードできるオブジェクトの数には制限があります。 * 現在のオブジェクトセットのロード制限については、制限に関するドキュメントを参照してください。 * これは、ユーザーがスクロールしている間にワークショップが遅延ロードできるため、問題にはならないはずです。 */ const allObjs: objectTypeA[] = objects.all(); // 配列内の各オブジェクトに対して並列計算を開始します。以下のcomputeForThisObject_filterOntologyの代替例を参照してください。 const promises = allObjs.map(currObject => this.computeForThisObject(currObject, scalar)); // Promise.allを使用して、ヘルパー関数の非同期実行を並列化します。 const allResolvedPromises = await Promise.all(promises); // バケットを結果マップに追加し、その値を計算します。 for (let i = 0; i < allObjs.length; i++) { resultMap.set(allObjs[i], allResolvedPromises[i]); } return resultMap; } // 提供されたオブジェクトに対して必要な値を計算する関数の例。 private async computeForThisObject(obj: objectTypeA, scalar: Double): Promise<Double | undefined> { if (scalar === 0) { // ゼロ除算エラー return undefined; } // examplePropertyが定義されているかどうかを確認し、定義されている場合は除算します。そうでない場合はundefinedを返します。 return obj.exampleProperty ? obj.exampleProperty / scalar : undefined; } /* * 提供されたオブジェクトに対して必要な値を計算する関数の例。 * 特定のオブジェクトに対して、オントロジーをクエリします(他のオブジェクトをフィルタリングしたり、別のオブジェクトセットを検索したりします)。 */ @Function() private async computeForThisObject_filterOntology(obj: objectTypeA): Promise<Double> { // いくつかのプロパティでフィルタリングしてオブジェクトセットを作成します const currObjectSet = await Objects.search().objectTypeB().filter(o => o.property.exactMatch(obj.exampleProperty)); // 注意: ObjectTypes間に既存のリンクがある場合、代替方法として次のようにすることもできます: // const currObjectSet = await Objects.search().objectTypeA([obj]).searchAroundObjectTypeB(); // このオブジェクトセットの集計を計算します return await this.computeMetric_B(currObjectSet); } @Function() public async computeMetric_B(objs: ObjectSet<objectTypeB>): Promise<Double> { // 式の別の部分への呼び出しを設定します。 const promises = [this.sumValue(objs), this.sumValueIfPresent(objs)]; // すべてのPromiseを実行します。 const allResolvedPromises = await Promise.all(promises); // Promiseから値を取得します。 const sum = allResolvedPromises[0]; const sumIfPresent = allResolvedPromises[1]; // 計算を行います return sum / sumIfPresent; } @Function() public async sumValue(objs: ObjectSet<objectTypeB>): Promise<Double> { // オブジェクトの値を合計します(これらのオブジェクトのメトリックが何であれ)。 const aggregation = await objs.sum(o => o.propertyToAggregateB); const firstBucketValue = aggregation.primaryKeys[0].value; return firstBucketValue; } @Function() public async sumValueIfPresent(objs: ObjectSet<objectTypeB>): Promise<Double> { // オブジェクトの値がnullでない場合にその値を合計します。 const aggregation = await objs.filter(o => o.metric.hasProperty()).sum(o => o.propertyToAggregateA); const firstBucketValue = aggregation.primaryKeys[0].value; return firstBucketValue; }
注: Workshop の Chart XY ウィジェット にデータを表示する TwoDimensionalAggregation にも同じことが当てはまります。オブジェクトインスタンスのリストの代わりに、計算するカテゴリ文字列(バケット)のリストを渡すことができます。以下はその例です。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19// ==== Utils - convert to a TwoDimensionalAggregation for the Chart XY widget in Workshop ==== @Function() public async getDerivedColumn_parallel_asTwoDimensional(objects: ObjectSet<objectTypeA>, scalar: Double): Promise<TwoDimensionalAggregation<string>> { const resultMap: FunctionsMap<objectTypeA, Double> = await this.getDerivedColumn_parallel(objects, scalar); // Create a TwoDimensionalAggregation from the resultMap // resultMapからTwoDimensionalAggregationを作成する const aggregation: TwoDimensionalAggregation<string> = { // Map the entries (object -> Double) of resultMap (string -> Double) // resultMapのエントリ (object -> Double) を (string -> Double) にマップする buckets: Array.from(resultMap.entries()).map(([key, value]) => ({ key: key.pkProperty, // Destructure key to get its id property // keyを分解してそのidプロパティを取得 value })), }; return aggregation; }