注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
チャンキング
このページでは、意味的な検索のワークフローに基本的なチャンキング戦略を取り入れる方法を概説します。この文脈でのチャンキングとは、大きなテキストをより小さなテキストに分割することを意味します。これは有益なことで、埋め込みモデルにはテキストの最大入力長があり、重要なことに、より小さなテキストは検索時に意味的に明確になります。チャンキングは、PDFのような大きなドキュメントを解析する際によく使用されます。
主に、目的は長いテキストを小さな "チャンク" に分割し、それぞれを元のオブジェクトにリンク付けしたオントロジーオブジェクトと関連付けることです。
チャンキングの例
出発点として、Pipeline Builderでコードを使用せずに基本的なチャンキング戦略がどのように達成できるかを示します。より高度な戦略については、パイプラインの一部としてコードリポジトリを使用することをお勧めします。
説明のため、簡単な二行のデータセットを使用し、二つの行、object_idとobject_textを使用します。理解しやすいように、以下の object_textの例は意図的に短くしています。
| object_id | object_text |
|---|---|
| abc | gold ring lost |
| xyz | fast cars zoom |
まず、Chunk String ボードを使用してプロセスを開始します。これは、object_textがより小さな部分に分割された配列を含む追加の行を導入します。このボードは、重複やセパレータなど、さまざまなチャンキング手法に対応しており、各意味的概念が独特で一貫したままであることを保証します。
以下の Chunk String ボードのスクリーンショットは、あなたが自分のユースケースに向けて変更可能な簡単な戦略を示しています。以下の設定では、約256文字の大きさのチャンクを返そうとします。基本的に、ボードは最高優先度のセパレータでテキストを分割し、各チャンクがチャンクサイズ以下になるまで分割します。最高優先度のセパレータがなく、一部のチャンクがまだ大きすぎる場合、全てのチャンクがチャンクサイズ以下になるか、または使用できるセパレータがなくなるまで次のセパレータに移ります。最後に、ボードは、特定のチャンクの後に続くチャンクが、前のチャンクの最後の20文字をカバーする重複を持つことを保証します。
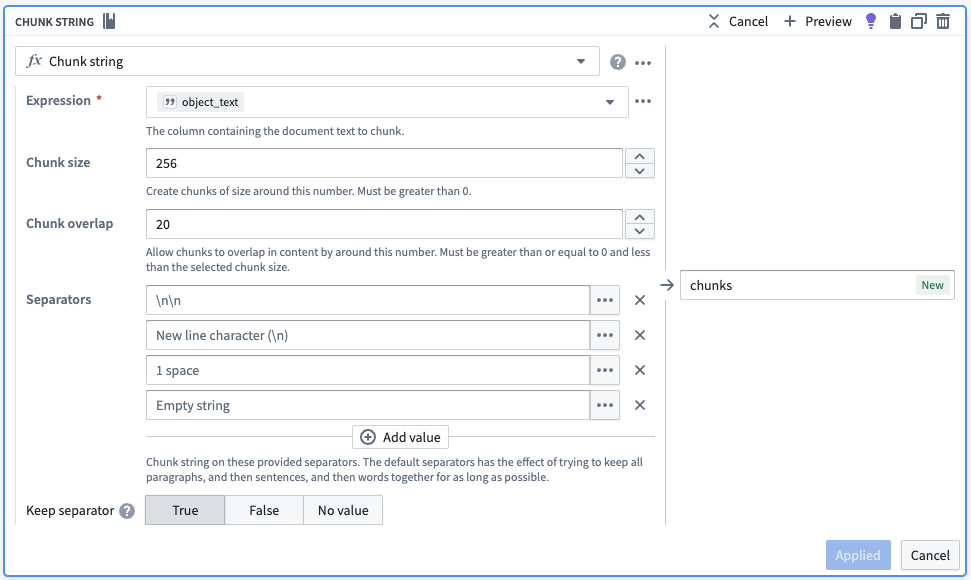
| object_id | object_text | chunks |
|---|---|---|
| abc | gold ring lost | [gold,ring,lost] |
| xyz | fast cars zoom | [fast,cars,zoom] |
次に、配列の各要素が自分の行を持つようにしたいと思います。Explode Array with Position ボードを使用して、6行のデータセットに変換します。新しい行の各行には、配列の位置と配列の要素の2つのキー値ペアを持つ構造体(マップ)があります。
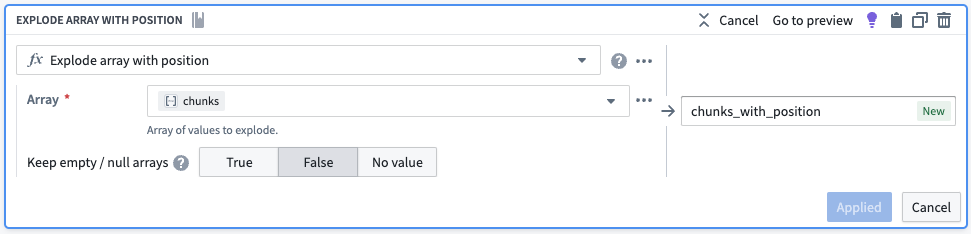
| object_id | object_text | chunks | chunks_with_position |
|---|---|---|---|
| abc | gold ring lost | [gold,ring,lost] | {position:0, element} |
| abc | gold ring lost | [gold,ring,lost] | {position:1, element} |
| abc | gold ring lost | [gold,ring,lost] | {position:2, element} |
| xyz | fast cars zoom | [fast,cars,zoom] | {position:0, element} |
| xyz | fast cars zoom | [fast,cars,zoom] | {position:1, element} |
| xyz | fast cars zoom | [fast,cars,zoom] | {position:2, element} |
そこから、位置と要素をそれぞれ独自の行に引き出します。
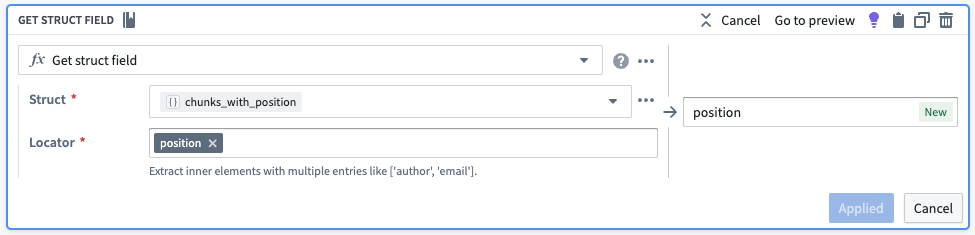
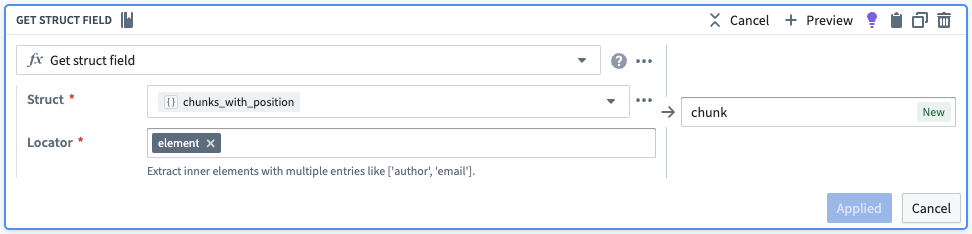
| object_id | object_text | chunks | chunks_with_position | position | chunk |
|---|---|---|---|---|---|
| abc | gold ring lost | [gold,ring,lost] | {position:0, element} | 0 | gold |
| abc | gold ring lost | [gold,ring,lost] | {position:1, element} | 1 | ring |
| abc | gold ring lost | [gold,ring,lost] | {position:2, element} | 2 | lost |
| xyz | fast cars zoom | [fast,cars,zoom] | {position:0, element} | 0 | fast |
| xyz | fast cars zoom | [fast,cars,zoom] | {position:1, element} | 1 | cars |
| xyz | fast cars zoom | [fast,cars,zoom] | {position:2, element} | 2 | zoom |
各チャンクに一意の識別子を作成するために、チャンクの位置を文字列に変換し、元のオブジェクトIDに連結します。また、不要な行を削除します。
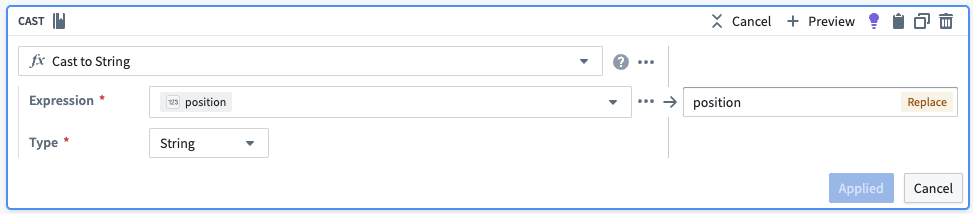
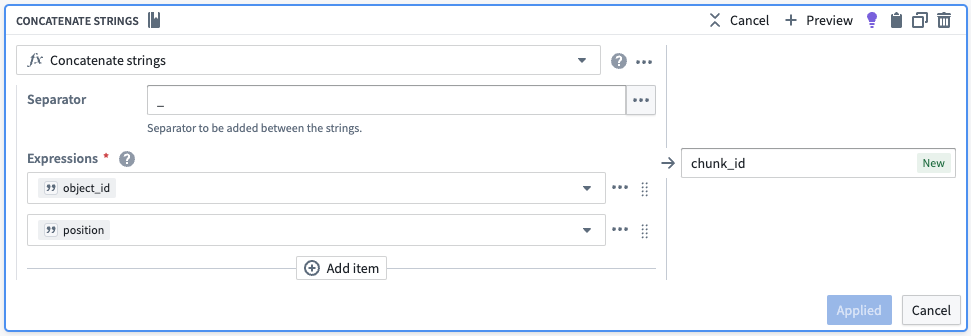

| object_id | chunk | chunk_id |
|---|---|---|
| abc | gold | abc_0 |
| abc | ring | abc_1 |
| abc | lost | abc_2 |
| xyz | fast | xyz_0 |
| xyz | cars | xyz_1 |
| xyz | zoom | xyz_2 |
現在、6つの異なるチャンクを表す6行ができました。各チャンクには object_id(リンク用)、新しい chunk_id(新しい主キー用)、そして chunk(意味的検索ワークフローで説明されているように埋め込む)が含まれています。これにより以下の表が得られます。
| object_id | chunk | chunk_id | embedding |
|---|---|---|---|
| abc | gold | abc_0 | [-0.7,...,0.4] |
| abc | ring | abc_1 | [0.6,...,-0.2] |
| abc | lost | abc_2 | [-0.8,...,0.9] |
| xyz | fast | xyz_0 | [0.3,...,-0.5] |
| xyz | cars | xyz_1 | [-0.1,...,0.8] |
| xyz | zoom | xyz_2 | [0.2,...,-0.3] |