注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
お知らせ
**ご案内: ** Foundry ニュースレターにご登録いただくと、プラットフォーム全体の新製品、新機能、改良点についてまとめた情報を直接メールでお届けいたします。購読方法の詳細については、Foundry ニュースレターと製品に関するフィードバックチャンネルのお知らせ をご参照ください。
AIP Logic の紹介 [GA]
公開日:2023年12月14日
AIP Logic は、大規模言語モデルを搭載したノーコードの開発環境で、関数のビルドやテスト、リリースを行うことができます。AIP Logic では、開発環境やAPIの呼び出しにありがちな複雑さを経験せずに、オントロジーを活用して機能豊富かつAIを利用した関数をビルドできます。アプリケーションを構築するユーザーは、Logic の直感的なインターフェースを使用して、プロンプトのエンジニアリング、テスト、評価、監視、自動化の設定などを実行できます。
AIP Logic を使用して、重要な情報を構造化されていない入力からオントロジーに接続したり、スケジュールでの重複を解消したり、最適な割り当てを明らかにして資産のパフォーマンスを最適化したり、サプライチェーンでの混乱に対応したりするなど、重要なタスクの自動化とサポートを行うことができます。
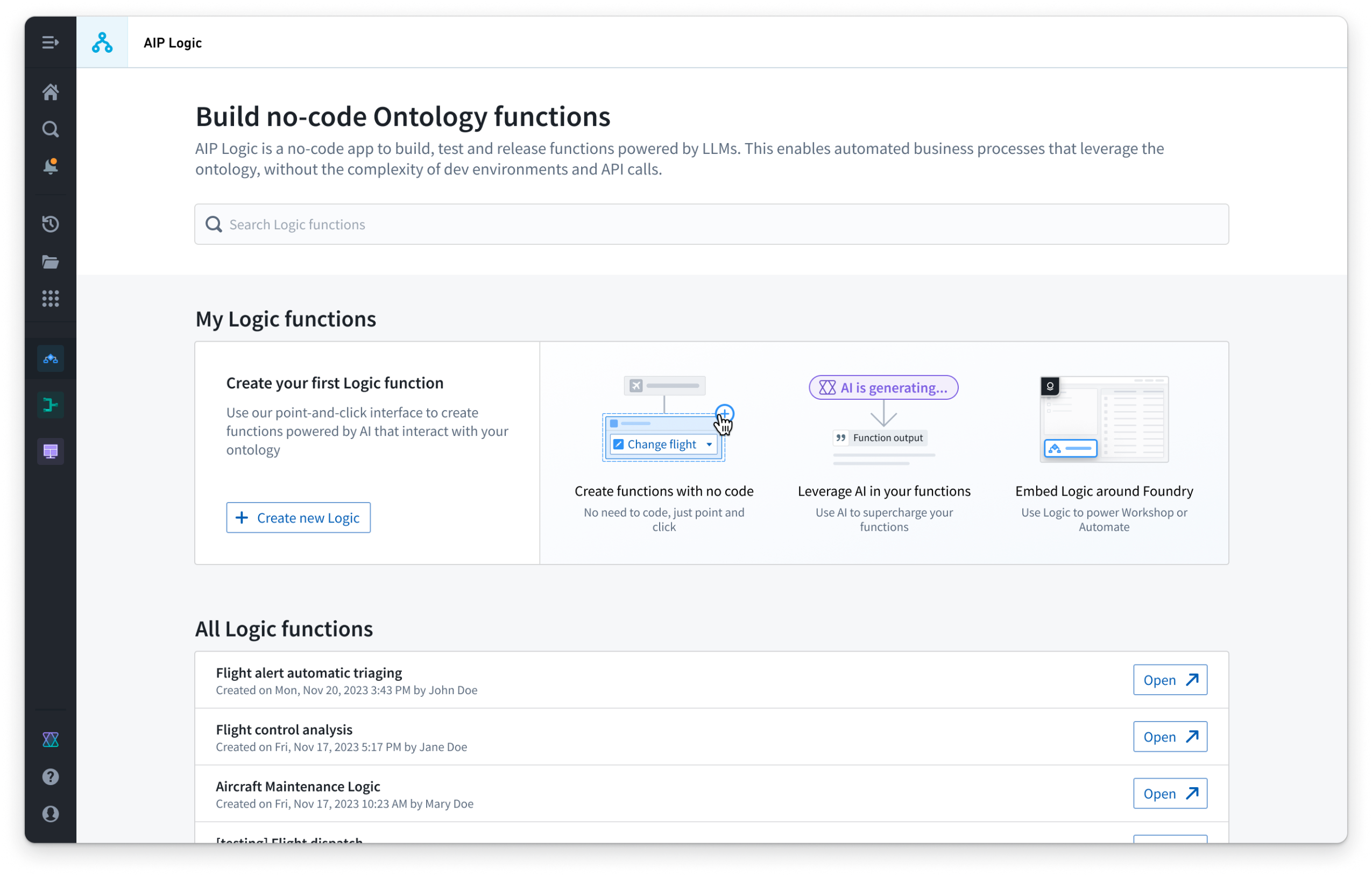
AIP Logic のランディングページ。
AIP Logic へのアクセス
AIP Logic は、プラットフォームのワークスペースナビゲーションバーからアクセスしたり、クイック検索ショートカット CMD + J(macOS)または CTRL + J(Windows)を使ってアクセスすることができます。また、ファイルから新しいロジック関数を作成する場合は、+新規を選択し、次にAIP Logicを選択します。下記のように表示されます。
+ 新規ドロップダウンメニュー。
開発ロードマップには何が含まれていますか?
AIP Logic には現在、以下の機能が開発中です。
- Logic アシスタント: プロンプトの作成に AI アシスタントを活用し、欠けているツールやデータを確認します。より信頼性の高い Logic 関数を構築し、プロンプトの反復回数を減らし、エラー率を低減させます。
- バージョン管理とブランチ: AIP Logic 関数の異なるバージョンやブランチを作成、管理、マージします。
- 評価: オントロジーでの定義を用いた評価とテスト用フレームワークを設定し、Logic 関数の効果を測定します。
AIP Logic を始めるには
まず、はじめに を参照してください。また、主要な概念 について詳細をご確認ください。
Derived Series [ベータ版]の紹介
公開日:2023年12月14日
Derived series は、要求に応じて利用できるベータ機能であり、Quiver 分析内の時系列データに対して行われる計算を保存および複製する方法を新たに提供します。Derived series を Foundry リソースとして保存すると、ロジックが共有可能になってオントロジーにリンクできるようになります。また、未加工の時系列データのように動作して、追加のストレージや繰り返し計算が不要な状態で、オンデマンドで計算されるようになります。
Derived series の有効化については、Palantir の担当者にお問い合わせください。
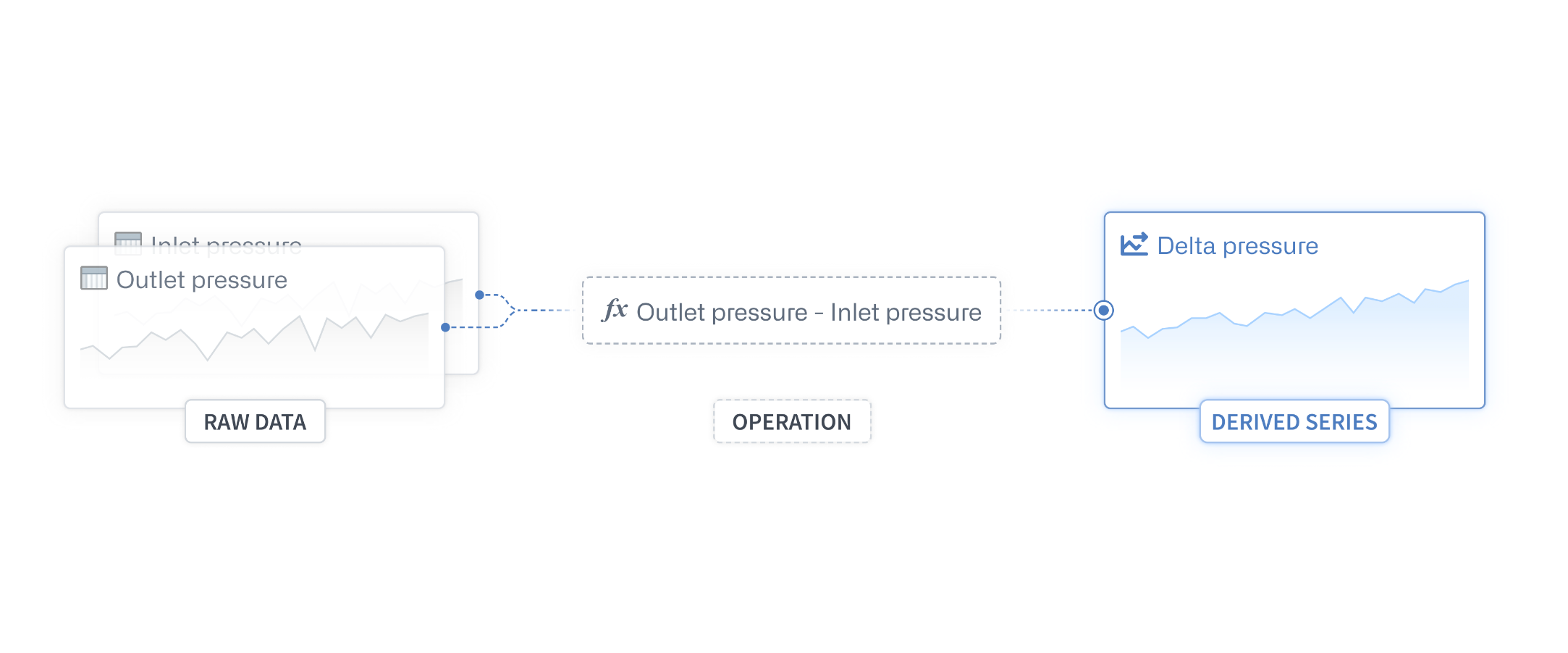
Derived series は、未加工の時系列データに対する変換や計算の組み合わせであり、Foundry リソースとして保存され、さまざまなワークフローで再利用されます。
Derived series の作成
ユーザーは、Quiver 分析から時系列データの変換を Derived series として保存することができます。時系列カード(時系列式や連続集計など)には、Derived series を保存オプションが追加され、Quiver 分析内のロジックツリー全体を実行時に実行できるコーデックステンプレートに変換します。
Derived series の作成については、こちらで詳細をご確認ください。
詳細およびオブジェクトタイプの選択設定後に Derived series を保存します。
Derived series の管理
さらに、Derived series の管理ページにアクセスして、Derived series リソースおよびコーデックステンプレートを管理することができます。Derived series に関する情報の確認や、ロジックやメタデータの変更、Derived series テンプレートの新しいバージョンの再公開を行えます。
Derived series の管理については、こちらで詳細をご確認ください。
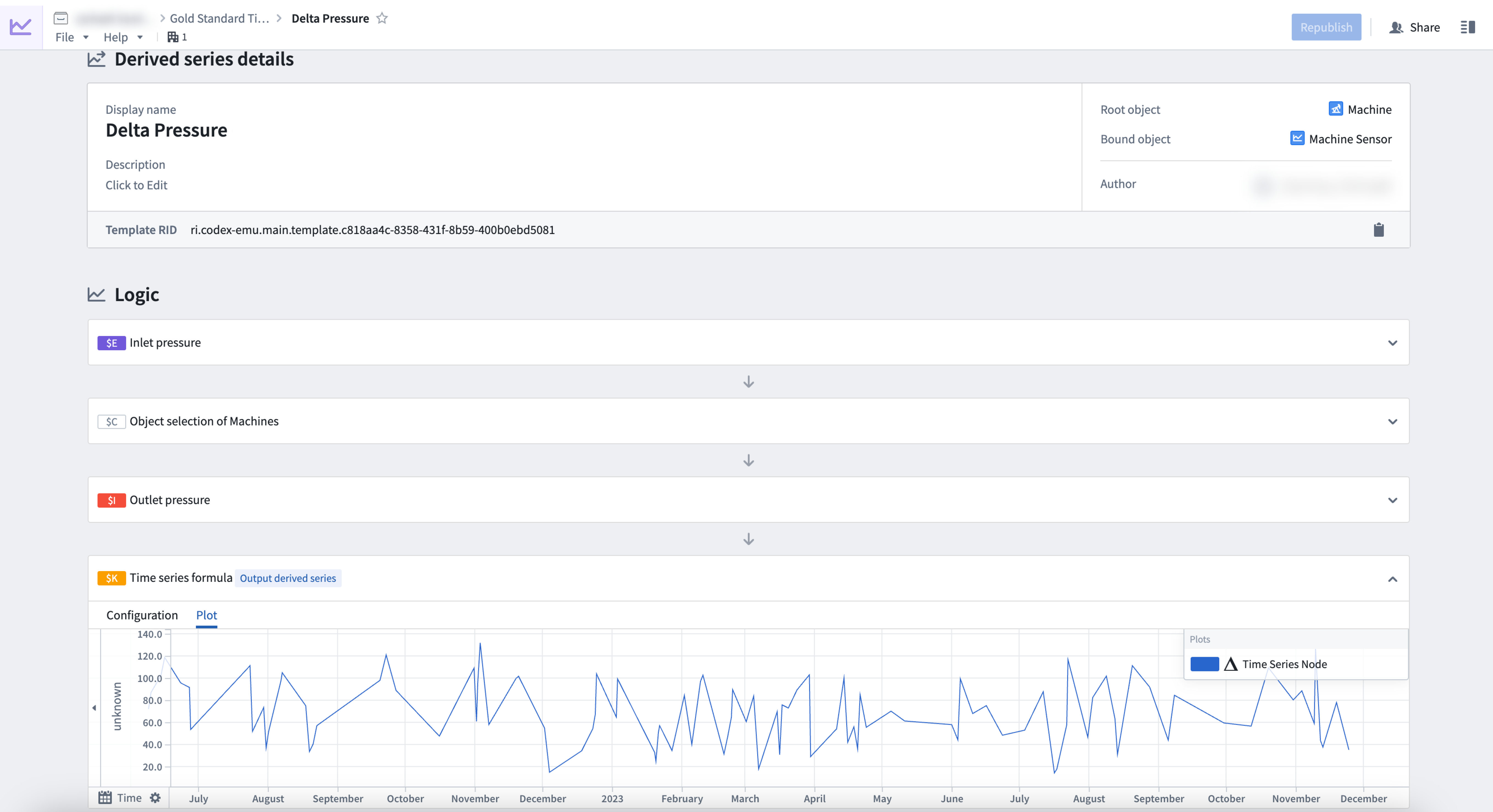
Derived series の詳細を一覧で表示。
開発ロードマップには何が含まれていますか?
現在、派生系列におけるオントロジー化のステップでは、分析または運用アプリケーションでの派生系列を、未加工の時系列と同じように幅広く利用できるようにするために、系列をルートまたはセンサーのオブジェクトタイプにリンクするパイプラインをユーザーが手動でビルドし、管理する必要があります。また、Derived series ワークフロー構築の完全自動化の開発を積極的に実施しており、オントロジーのパイプラインを手動で管理する必要性をなくし、シームレスなユーザーエクスペリエンスを実現しています。
Derived series を始めるには
詳細については、以下の関連ドキュメントをご参照ください。
HyperAuto V2 による同期の自動作成の紹介 [GA]
公開日:2023年12月12日
HyperAuto V2 パイプラインの同期の自動作成機能が一般提供されるようになり、HyperAuto パイプラインの設定時に、ソース内の任意の表示可能なテーブルを選択できます。同期がまだ存在しない場合、HyperAuto はユーザーが自由に設定できる同期をインテリジェントに作成します。
データ接続同期がないテーブルを入力として使用する
入力設定ステップで、データ接続同期がないテーブルを入力として選択できるようになりました。選択した入力に同期が存在する場合、HyperAuto は最も最近実行された同期を使用するようにデフォルト設定されます。選択した入力を鉛筆アイコンの入力テーブルの設定オプションを使って再設定でき、別の既存の同期を使用するか、新しい同期を作成することができます。
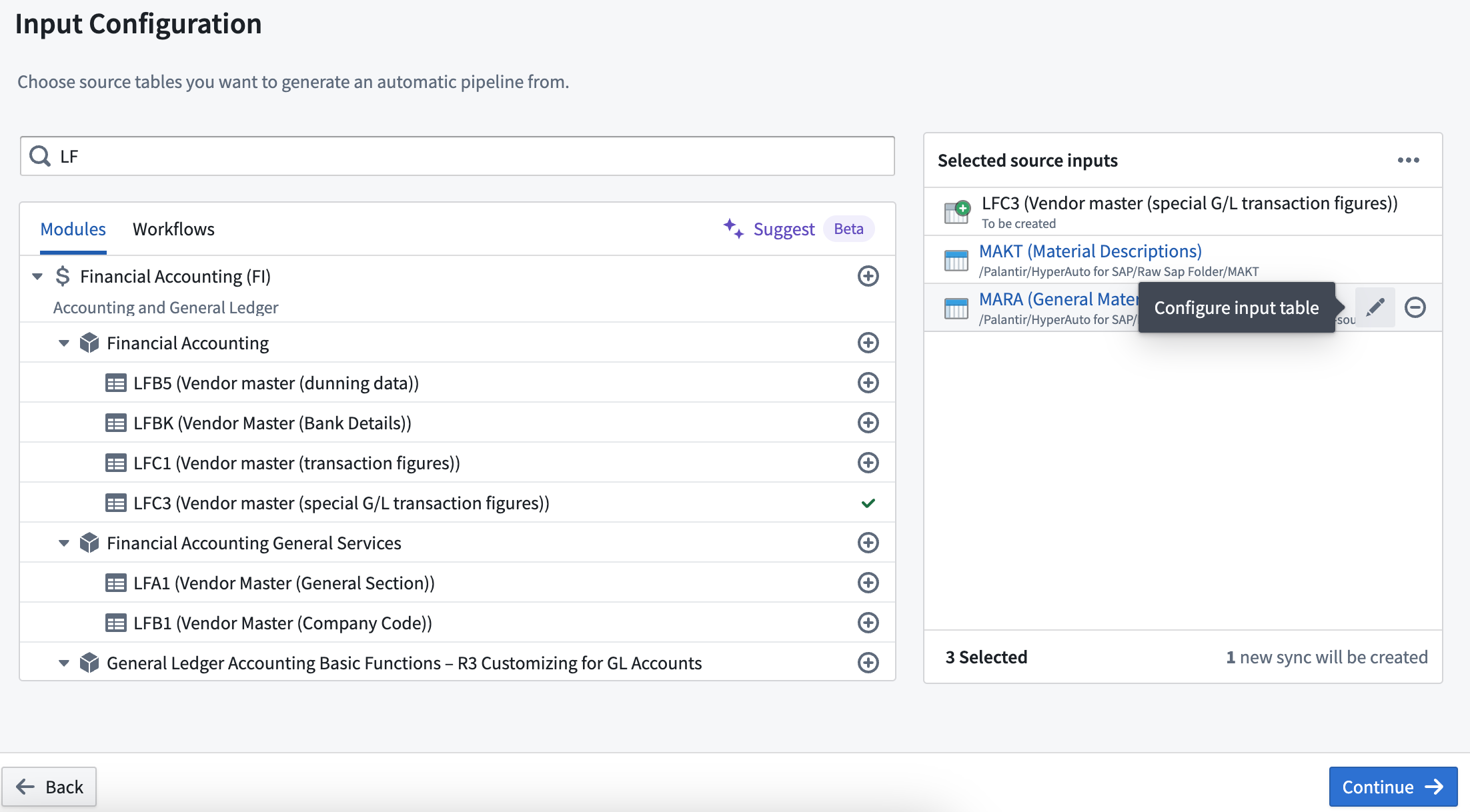
データ接続同期がないテーブルを入力として許可する入力設定ウィンドウ。
入力テーブル設定パネルから、このテーブル用の SAP ソースから新しい同期を作成するを選択し、保存をクリックします。
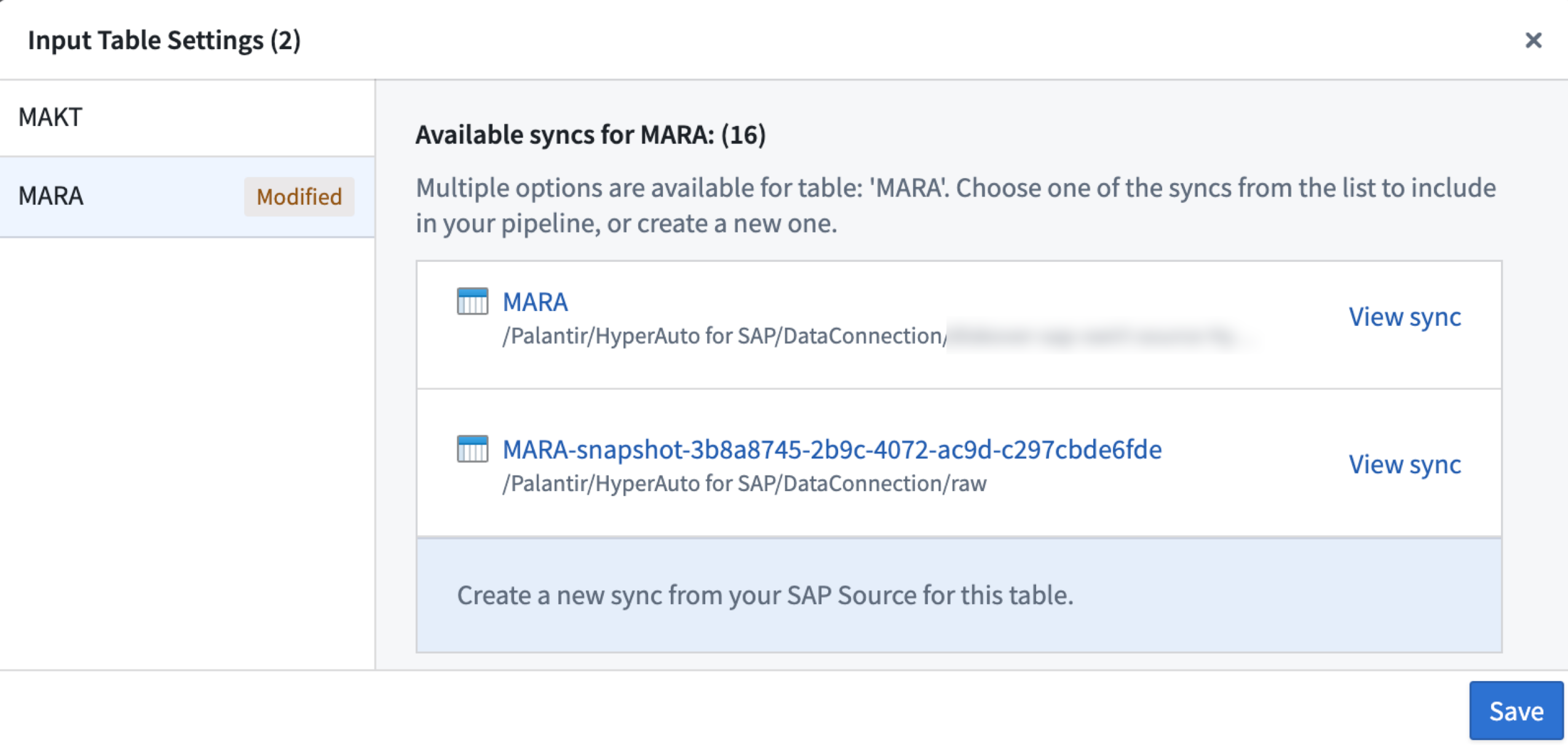
入力テーブル設定パネルから新しい同期を作成するオプションが利用可能。
HyperAuto パイプラインが作成されると、同期が設定されているかどうかを(インターフェース内では「初期化」とも呼ばれています)概要ページから確認できます。
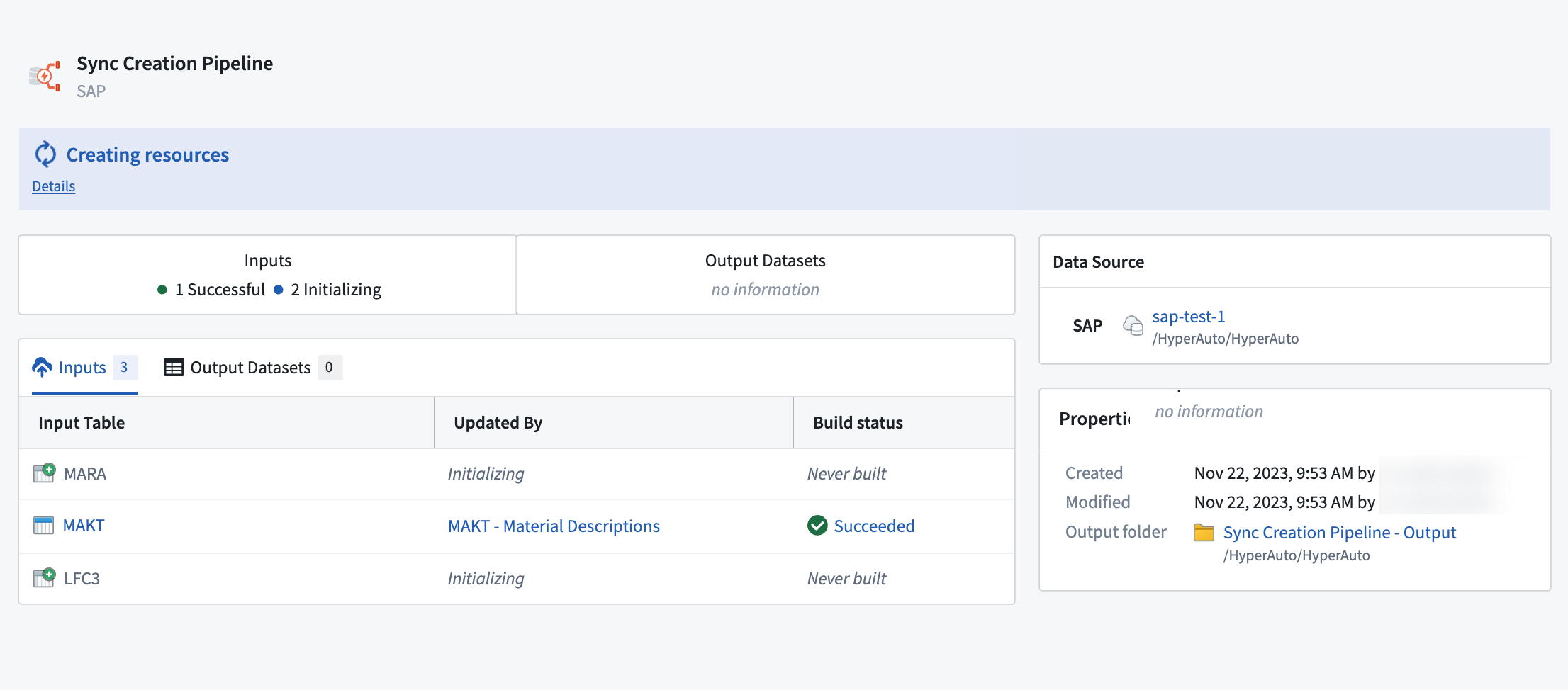
自動的に生成される同期を示す概要ページ。
HyperAuto は、パイプラインロジックを展開する前に、概要ページに表示される同期を作成して実行します。
HyperAuto の開始方法については、こちらで詳細をご確認ください 。
Free-form Analysis ウィジェットの紹介
公開日:2023-12-12
Free-form Analysis Workshop ウィジェット を使うことで、ユーザーは Workshop アプリケーション内でオブジェクトデータを自由に調査できます。現在一般提供されているこのウィジェットを使用すると、Quiver の堅牢な機能セットによって駆動されたシンプルなパスベースの分析インターフェースが利用できます。
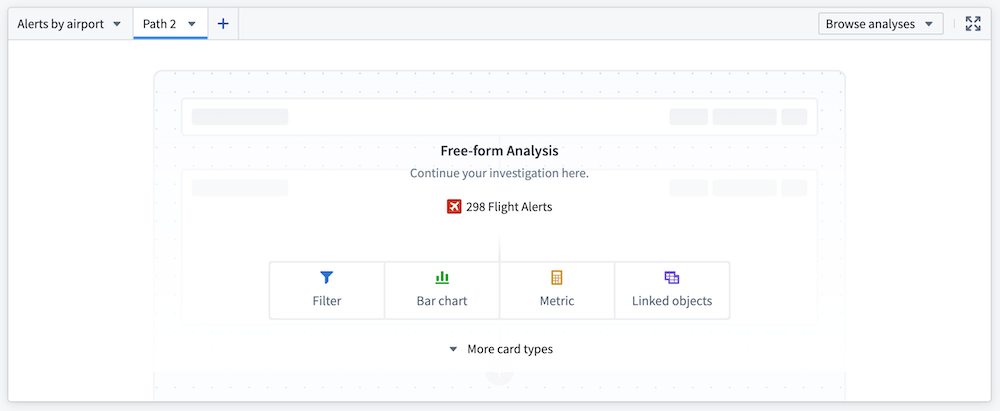
Workshop アプリケーション内で直接データを調査する Free-form Analysis ウィジェット。
Workshop アプリケーション内でのシームレスなデータ探索
Free-form Analysis ウィジェットを使うことで、ユーザーは Workshop アプリケーション内でオブジェクトデータを探索し、他の人と調査を共有して、重複する作業を減らし、ワークフローを強化することができます。以前は、ユーザーが Workshop アプリケーションでデータを調べる場合、Contour や Quiver を使用して調査をサポートする必要がありました。
Free-form Analysis ウィジェットがあることで、以下のユースケースにプラスの効果をもたらします。
- データ探索: 既存の Workshop アプリケーション内でデータを探索し、オーダーメイドの調査を行います。
- 根本原因の調査: アラートがあった場合、ユーザーは事前に定義されたビジュアライゼーションセットに基づいてデータを調べ、関連するオブジェクトタイプを含む調査に最も関連性のある方向にドリルダウンできます。
- アプリケーションのプロトタイピング: ビルダーは、保存された分析を確認して、共通のオフロードパターンを理解し、それらを本番ワークフローに組み込むことができます。
- コホート作成: ユーザーは、カスタムコホートを作成するためにドリルダウンし、それをアプリケーションの他の場所で使用するグループとして保存できます。
Free-form Analysis ウィジェットを使い始める
Free-form Analysis ウィジェットを使い始めるには、まず Workshop ウィジェットホームページでウィジェットを検索します。次に、以下の手順で設定します。
- 分析の基本入力として使用する入力オブジェクトセットを提供します。
- パス内にカードがない場合のウィジェットの設定方法を決定するために、空の状態のヘッダーと空の状態の説明を設定します。
- 出力オブジェクトセットを決定し、Workshop 内で参照するための出力オブジェクトセットを保存します。
- 必要に応じて、パスの保存を有効にするをオンにし、パス内の個々のカードをNotepad文書に追加できるようにします。ただし、カードは、保存された分析パス内にある場合にのみコピーできます。
分析パスは、公開または非公開で保存し、将来の参照のために Quiver で開くか、Notepad文書にコピーすることができます。
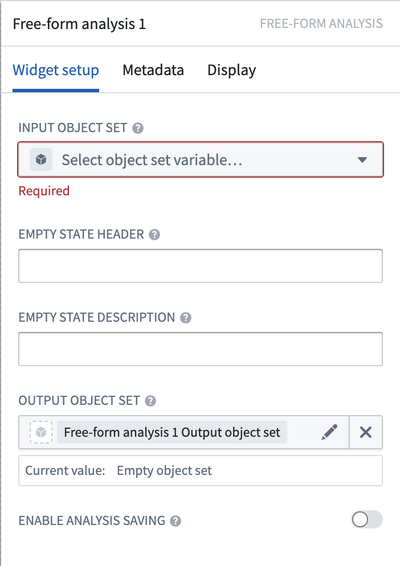
Free-form Analysis ウィジェットの設定
詳細については、Free-form Analysis ウィジェット のドキュメントを参照してください。
AIP 開発者機能向けの拡張 LLM 統合の導入
公開日:2023年12月7日
大規模言語モデル(LLM)を使用した AIP 開発者機能 に対するサポートが拡張されました。これには以下が含まれます。
- コントロールパネルでの AIP 開発者機能での権限設定管理
- Python 変換での言語モデル
- オブジェクト上の関数での言語モデル
- Pipeline Builder の Text to Embeddings ボード
コントロールパネルでの AIP 開発者機能の権限設定管理
AIP を有効にしたスタックの管理者は、コントロールパネルの新しい AIP 設定ページを利用して、AIP 開発者ワークフロー内の LLM へのアクセスを管理することができます。このページから、管理者は、カスタム LLM や Palantir が提供する LLM を利用したワークフローを構築するために、どのユーザーグループにアクセスを許可するかを選択し、有効化、無効化することができます。
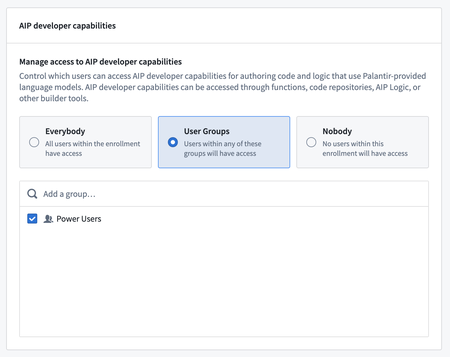
コントロールパネルでの AIP 開発者機能の権限設定管理
Python 変換で言語モデルを使用する
Python 変換を使用するパイプライン作成者は、Palantir が提供する LLM や埋め込みモデルを活用したデータパイプラインを簡単に構築できるようになりました。palantir_models Python パッケージに含まれる Python SDK を利用するだけですみます。

palantir_models Python パッケージを使用して、データパイプラインに LLM を組み込む
設定の例
以下のコードスニペットは、パイプライン開発者がロジック内で OpenAI の GPT-4 を実装し、プラットフォーム上の任意のデータパイプラインに対して LLM の潜在能力を簡単に活用できる方法を示しています。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13from transforms.api import transform, Input, Output from palantir_models.transforms import OpenAiGptChatLanguageModelInput from palantir_models.models import OpenAiGptChatLanguageModel # transformデコレーターを使用して、データ変換関数を定義します。 # この関数は、ソースデータセットとOpenAI GPT-4 チャット言語モデルを入力とし、出力データセットを生成します。 @transform( source_df=Input("/path/to/input/dataset"), # 入力データセットへのパス gpt_4=OpenAiGptChatLanguageModelInput("ri.language-model-service..language-model.gpt-4_azure"), # OpenAI GPT-4 チャット言語モデル output=Output("/path/to/output/dataset"), # 出力データセットへのパス ) def compute(ctx, source_df, gpt_4: OpenAiGptChatLanguageModel, output): # データ変換関数 ...
プラットフォーム内で利用可能なLLMやその使用法についての詳細は、ドキュメンテーションのPalantir提供の変換モデル内を参照してください。
オブジェクト上の機能で言語モデルと対話する
ユーザーは現在、Palantirが提供する言語モデルを用いてTypescript関数を用いてカスタムロジックを作成することができ、これにより要約、Q&A、セマンティックサーチなどのワークフローが容易になります。更新されたモデルインポートパネルは、Palantir提供のモデルとカスタムオーサリングの両方のモデルをサポートします。すべてのインポートされたLLMについて、Typescriptクラスが生成され、ユーザーが作成した関数内でLLMを使用するための直感的なインターフェースが提供されます。
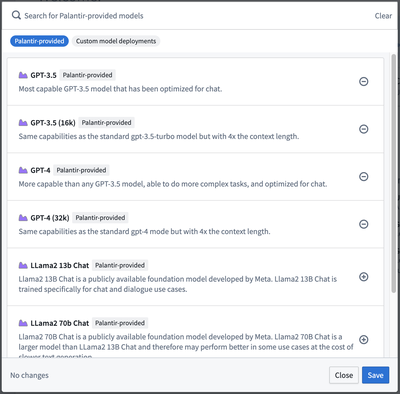
Palantirが提供するLLMのサンプル - スタック間で利用可能性が異なる場合があります
使用例
例えば、以下のコードは、GPT_4 モデルを使用してカスタム Typescript 関数を書き、提供されたテキストに対してシンプルなセンチメント分析を実行する方法を示しています。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22import { GPT_4 } from "@foundry/models-api/language-models"; @Function() public async sentimentAnalysis(userPrompt: string): Promise<string> { // システムプロンプトを設定します。ユーザーが提供したテキストの感情を推定します。 // Good(良い)、Bad(悪い)、Uncertain(不確定)のいずれかで応答してください。 // テキストが良いか悪いかを確信が持てる場合にのみ、GoodまたはBadを選択します。 // テキストが中立であるか、判断できない場合は、Uncertainを選択します。 const systemPrompt = "Provide an estimation of the sentiment the text the user has provided. \ You may respond with either Good, Bad, or Uncertain. Only choose Good or Bad if you are overwhelmingly \ sure that the text is either good or bad. If the text is neutral, or you are unable to determine, choose Uncertain." // システムメッセージとユーザーメッセージを設定します。 const systemMessage = { role: "SYSTEM", content: systemPrompt }; const userMessage = { role: "USER", content: userPrompt }; // GPT-4によるチャット完了を作成します。メッセージとパラメータを渡します。 const gptResponse = await GPT_4.createChatCompletion({messages: [systemMessage, userMessage], params: { temperature: 0.7 } }); // GPTからの応答を返します。応答がない場合は、"Uncertain"を返します。 return gptResponse.choices[0].message.content ?? "Uncertain"; }
利用方法や例については、Functions 内の言語モデルのドキュメントを参照してください。
Pipeline Builder の Text to Embeddings ボード
Pipeline Builder には、新しい Text to Embeddings ボードが追加されました。Embeddingsは、テキストから単語やフレーズの意味を捉えるために設計された密なベクトル表現で、LLM で処理されるテキストを表現します。Embeddings は、テキストを LLM で処理できる数値形式に変換します。
この数値表現(埋め込み)により、文法的な類似性だけでなく、文脈的な類似性に基づいてテキストデータを比較することができます。例えば、「cat」、「dog」、「balloon」という単語を比較する際、埋め込みは「cat」と「dog」が「cat」と「balloon」よりも意味的に密接に関連していることを判断し、その理解をもとに高度なテキスト解析や操作を行います。
Pipeline Builder での埋め込みの使用は、特に意味的検索を含むワークフローに有益であり、LLM がベクトルの類似性を評価することで、より効果的でニュアンス豊かで正確な検索が可能になります。
例
このボードは、文字列の列を入力として受け取り、Palantir 提供の text-embedding-ada-002 モデルを使用して埋め込みベクトルを作成します。
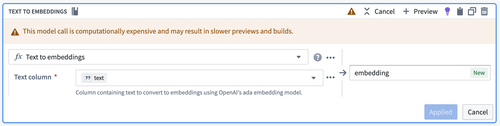
Text to Embeddings ボードの設定
これらの埋め込みは、オントロジーの Embedded vector プロパティとして追加され、LLM 駆動のワークフローで下流で使用されます。
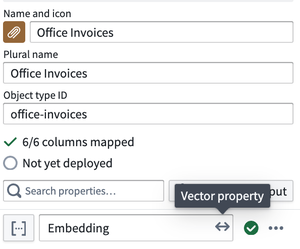
ワークフローの一部として埋め込みを使用する
詳細を学ぶ
上記の機能について詳しく知るには、次のドキュメントを参照してください。
- Control Panel で AIP 設定を管理する
- Python Transforms 内の言語モデルの使用方法
- Functions 内の言語モデルの使用方法
- Pipeline Builder の Embeddings
その他のハイライト
Foundry Developer Console
公開日:2023-12-12
Developer Console で OpenAPI 仕様をエクスポート | ユーザーは、Developer Console のアプリケーション用の OpenAPI 仕様を生成し、YAML ファイルとしてエクスポートできるようになりました。この機能は、SDK Generation タブ(以前は Version history と呼ばれていました)を通じてアクセスできます。
マーケットプレイス
公開日:2023-12-12
マーケットプレイスでの改善されたプロダクト画像の整列とレイアウト | マーケットプレイスの商品ページでは、商品画像の整列が改善され、レイアウトが強化されました。
アプリビルディング | Workshop
公開日:2023-12-12
大規模モジュールの高速埋め込みモジュールの読み込み | このアップデートにより、Workshop での非常に大規模な埋め込みモジュールの読み込み時間が大幅に改善されました。大規模なモジュールを扱うユーザーは、最大 5 倍の読み込み速度向上を体験できます。
データインテグレーション | コードリポジトリ
公開日:2023-12-12
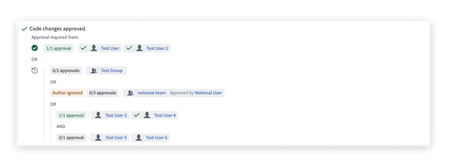
高度なプルリクエスト承認ポリシー | プルリクエストの承認を設定するための緻密でルールベースのシステムが導入されました。高度な PR 承認ポリシーにより、変更されたファイルに基づいて PR を承認する必要があるユーザーやグループを指定できるようになりました。ポリシーは YAML と対話型の承認ポリシーエディタの両方で編集できます。
ポリシーは、新しく作成されたプルリクエストに適用されます。必要な承認者は、新しいユーザーインターフェースで表示され、満たされたルールやまだ必要な承認の数が表示されます。
この機能を使用するには、保護されたブランチを作成し、Code Repository の設定ペインの Branches タブからポリシーを編集してください。
マーケットプレイス
公開日:2023-12-12
Marketplace Modeling Integration が一般提供開始 | Marketplace modeling integration が一般提供開始となり、ユーザーは機械学習、予測、最適化、物理モデル、ビジネスルールなどの機能ロジックをカプセル化したコンテナ化された実行可能ファイルをパッケージ化できるようになりました。
管理 | Control Panel
公開日:2023-12-12
AWS ホストスタックの強化されたエグレスポリシー | AWS ホストスタックのユーザーは、同じリージョンで所有する S3 バケットへのエグレスポリシーを作成できるようになり、データアクセスをより制御できるようになりました。今後のアップデートで、バケットのリージョンに基づいたポリシーの適格性について明確なフィードバックが提供されるようになる予定です。
オブジェクト監視
公開日:2023-12-12
強化された自動化ビューと編集モード | オブジェクト監視アプリケーションでは、自動化ヘッダーのビューモードセレクタが改善され、ユーザーは自動化の編集モードとビューモードを切り替えるオプションが増えました。実行モードの選択がより明確になり、自動化条件アイコンが統合され、ユーザー体験が向上しました。
データインテグレーション | コードリポジトリ
公開日:2023-12-12
Spark モジュールランタイムが Spark 3.4 にアップグレード | Foundry の Spark モジュールランタイムが Spark 3.4 にアップグレードされ、ユーザーに最新のパフォーマンスとセキュリティ強化が提供されます。このアップグレードは、次のバージョン以降のすべてのモジュールに適用されます: Python 1.975.0, Java 1.997.0, SQL 1.861.0。ユーザーからのアクションは不要で、モジュールは自動的にアップグレードされます。
Foundry Developer Console
公開日:2023-12-12
Developer Console での API トークン作成 | ユーザーは、Developer Console で制限された機能を持つ長寿命 API トークンを個人用および CI/CD ワークフロー用に生成できるようになりました。最初の機能は、SDK アーティファクトリポジトリと Foundry SDK アセットバンドルの両方に artifacts の範囲で SDK をインストールすることができます。Application SDK 設定ページまたは getting started インストラクションで Create API Token ダイアログにアクセスしてください。
オブジェクト監視
公開日:2023-12-12
強化されたオブジェクト監視機能 | このアップデートにより、オブジェクト監視アプリケーションがいくつかの強化を受けました。ユーザーは、ランディングページで過去 28 日間の障害イベントを表示できるようになり、最近の問題に対する可視性が向上しました。また、自動化の削除オプションが追加され、ワークフローの管理とメンテナンスが容易になりました。アクションメニューが再編成され、自動化オプションが別のメニューに移動され、アクセスが容易になりました。最後に、評価遅延情報が改善され、オブジェクトの追加と削除に関する時間条件の組み合わせについてのヒントが追加され、文言が明確になりました。
セキュリティ | プロジェクト
公開日:2023-12-05
プロジェクトコンタクト選択の強化 | 連絡先情報がないユーザーやグループをプロジェクトコンタクトとして追加できるようになり、プロジェクト管理の柔軟性が向上しました。更新されたインターフェースは、メールアドレスがないユーザーや連絡先詳細がないグループに対応した UI を表示します。
アプリビルディング | Workshop
公開日:2023-12-05
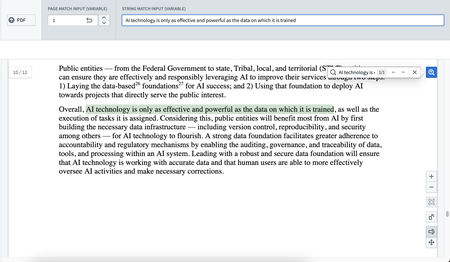
キーワード検索機能付きの新しい PDF Viewer ウィジェット | Workshop の PDF Viewer ウィジェットが一般提供開始となり、テキストのハイライトとマッチ時の自動スクロールを備えたキーワード検索機能が追加されました。この強化により、手動または変数ベースの入力を通じた PDF ワークフローが向上しました。
管理 | Control Panel
公開日:2023-12-05
Control Panel での Cloud Runtime Egress IP 公開 | ユーザーは、Control Panel で直接クラウドランタイムのエグレス IP アドレスにアクセスできるようになり、API やクラウドソースのイングレスフィルタリングの設定が容易になりました。このアップデートにより、ユーザーはクラウドランタイムに必要な IP アドレスをより文脈的で便利な方法で取得できるようになります。
セキュリティ | プロジェクト
公開日:2023-12-05
Vertex および Vortex オントロジー依存関係のサポート | プロジェクトは、Vertex および Vortex オントロジー依存関係をサポートするようになり、オントロジーアクセスチェッカの機能をより効率的かつ正確に管理できるようになりました。
データインテグレーション | コードリポジトリ
公開日:2023-12-05
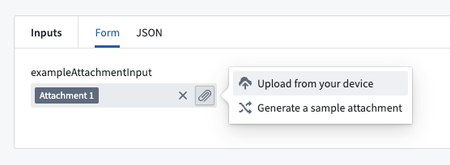
Code Repositories での添付ファイルを関数の入力として使用 | ユーザーは、Code Repositories で関数の入力として添付ファイルをアップロードできるようになり、Live Preview および公開された関数の両方で添付ファイルを使用するワークフローがよりシームレスになりました。始めるには、Attachment または Attachment[] 入力タイプの関数を追加し、Live Preview タブを開いて添付ファイルをアップロードします。関数を使用する際の入力および出力タイプのドキュメントをご確認ください。
オントロジー | オントロジー管理
公開日:2023-12-05
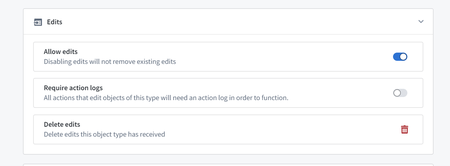
オントロジー管理の Action Log 必須性トグル | オントロジー管理に新しい Requires action log トグルが追加されました。有効にすると、指定されたオブジェクトタイプを編集するアクションは、アクションログルールが必要になり、そのタイプのオブジェクトへのすべての編集がログに記録され、可視性と追跡性が向上します。