注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
foundry_ml から palantir_models への移行
Python ライブラリ foundry_ml は サンセット期間 に入りました。foundry_ml ライブラリは 2025 年 10 月 31 日に廃止される予定で、これは Python 3.9 の計画的な廃止に対応しています。その代わりに、palantir_models フレームワークを使用してプラットフォームでモデルを開発、テスト、および提供することを推奨します。
foundry_ml でトレーニングされたモデルは、2025 年 10 月 31 日までに palantir_models フレームワークを使用するように更新する必要があります。foundry_ml で開発されたモデルは、モデリングの目的、Pythonトランスフォーム、またはモデリングの目的のデプロイメントではサポートされません。Code リポジトリで foundry_ml を使用して構築されたモデルは、Model Training テンプレートで初期化された新しいコードリポジトリで再構築する必要があります。Code Workbook で foundry_ml を使用して構築されたモデルは、Jupyter Code Workspaces で再構築する必要があります。
palantir_models を使用して新しいモデルを構築するためのガイダンスについては、Code リポジトリでのモデルのトレーニング方法 または Jupyter notebook でのモデルのトレーニング方法 を参照してください。
このチュートリアルでは、Code リポジトリで foundry_ml を使用して構築されたモデルを palantir_models に移行します。foundry_ml を使用してモデルを構築するためのコードを提供し、これを palantir_models を使用して書き直す方法を示します。
Code リポジトリで foundry_ml を使用して構築されたモデルの例
以下のスニペットでは、foundry_ml を使用して scikit-learn の線形回帰モデルを作成しました。これを palantir_models に移行します。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35from transforms.api import transform, Input, Output from foundry_ml import Model, Stage from sklearn.linear_model import LinearRegression from sklearn.pipeline import Pipeline from sklearn.preprocessing import StandardScaler @transform( training_data_input=Input("<YOUR_PROJECT_PATH>/data/housing_train_data"), model_output=Output("<YOUR_PROJECT_PATH>/models/linear_regression_foundry_ml"), ) def create_model(training_data_input, model_output): # トレーニングデータをデータフレームとして読み込み training_df = training_data_input.pandas() # 数値特徴量を選択 numeric_features = ['median_income', 'housing_median_age', 'total_rooms'] # パイプラインの作成:標準化スケーリングと線形回帰 pipeline = Pipeline([ ("scaler", StandardScaler()), ("regressor", LinearRegression())]) # 特徴量とターゲット変数を分割 X_train = training_df[numeric_features] y_train = training_df['median_house_value'] # モデルのトレーニング pipeline.fit(X_train, y_train) # モデルの保存用にStageを設定 model = Model(Stage(pipeline["scaler"], output_column_name="features"), Stage(pipeline["regressor"])) # モデルを指定された出力パスに保存 model.save(model_output)
Code リポジトリで foundry_ml から palantir_models への移行
上記のコードを foundry_ml から palantir_models に移行するには、以下の手順に従ってください。
ステップ 1: モデルトレーニングテンプレートで新しいコードリポジトリを開く
Palantir プラットフォームは、機械学習用のテンプレート化されたリポジトリである モデルトレーニング テンプレートを提供しています。コードリポジトリでこれにアクセスするには、何を構築していますか? と尋ねられたときにまず Models を選択します。
リポジトリのタイプとして Model Training を選択します。
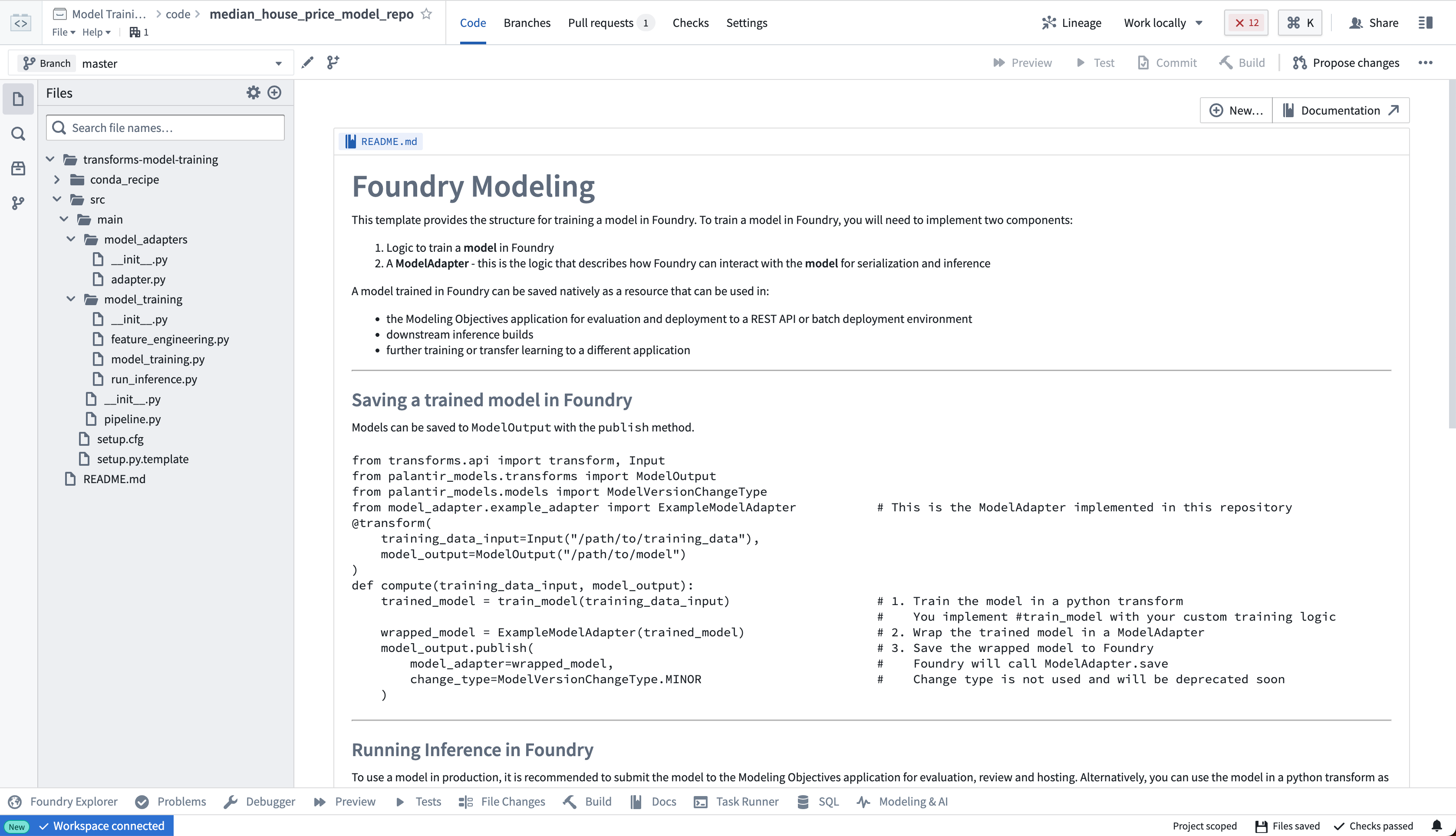
モデルトレーニングテンプレートには、このチュートリアルのために適応する例の構造が含まれています。左側のファイルを展開して、例のプロジェクトを確認できます。
ステップ 2: モデルadapterを作成する
モデルadapterは、Foundry内のすべてのモデルに標準インターフェースを提供します。この標準インターフェースは、すべてのモデルが即座に本番アプリケーションで使用できることを保証します。Palantir プラットフォームは、モデルとその Python 依存関係を読み込むためのインフラストラクチャを処理し、インターフェースを提供し、その API を公開します。
これを有効にするには、ModelAdapter クラスのインスタンスを作成して、この通信層として機能させる必要があります。
3 個の関数を実装します。
- モデルの保存と読み込み: ユーザーのモデルを再利用するためには、モデルをどのように保存し、読み込むかを定義する必要があります。Palantir は多くのデフォルトメソッドを提供しており、より複雑な場合にはカスタムのシリアライズロジックを実装することができます。
- API: モデルの API を定義し、Palantir プラットフォームにモデルが必要とする入力データのタイプを伝えます。
- 予測: Palantir プラットフォームによってモデルにデータを提供するために呼び出されます。ここで、入力データをモデルに渡し、推論(予測)を生成します。
model_adapters/adapter.py ファイルを開いて、モデルadapterを作成してください。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29import palantir_models as pm from palantir_models_serializers import DillSerializer # SklearnRegressionAdapterクラスはpalantirモデルのアダプターを継承 class SklearnRegressionAdapter(pm.ModelAdapter): # コンストラクタでモデルをDillSerializerを用いて自動シリアライズ @pm.auto_serialize( model=DillSerializer() ) def __init__(self, model): self.model = model # クラスメソッドでAPIの仕様を定義 @classmethod def api(cls): columns = [ ('median_income', float), # 中央収入 ('housing_median_age', float), # 住宅の中央値年齢 ('total_rooms', float) # 総部屋数 ] return {'df_in': pm.Pandas(columns=columns)}, \ {'df_out': pm.Pandas(columns=columns + [('prediction', float)])} # 予測結果を追加した出力 # 予測を行うメソッド def predict(self, df_in): # モデルを使って予測を行い、入力データフレームに'prediction'列として追加 df_in['prediction'] = self.model.predict(df_in[['median_income', 'housing_median_age', 'total_rooms']]) return df_in
モデル adapter ロジックの詳細については、author a model adapterを参照してください。
ステップ 3: モデル学習ロジックの記述
以下の例では、train_model 関数が foundry_ml からの学習ロジックの変更されていない例を含んでいます。compute 関数はモデルをモデル adapter でラップし、モデルを公開します。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41from transforms.api import transform, Input from palantir_models.transforms import ModelOutput from main.model_adapters.adapter import SklearnRegressionAdapter from sklearn.linear_model import LinearRegression from sklearn.pipeline import Pipeline from sklearn.preprocessing import StandardScaler @transform( training_data_input=Input("<YOUR_PROJECT_PATH>/data/housing_train_data"), model_output=ModelOutput("<YOUR_PROJECT_PATH>/models/linear_regression_model"), ) def compute(training_data_input, model_output): training_df = training_data_input.pandas() # トレーニングロジック model = train_model(training_df) # モデルをアダプターでラップ foundry_model = SklearnRegressionAdapter(model) # モデルを公開 model_output.publish(model_adapter=foundry_model) def train_model(training_df): ''' トレーニングロジックはオリジナルのfoundry_ml例から変更されていません。 ''' numeric_features = ['median_income', 'housing_median_age', 'total_rooms'] # パイプラインの作成 pipeline = Pipeline([ ("scaler", StandardScaler()), # 特徴量のスケーリング ("regressor", LinearRegression())]) # 線形回帰モデル X_train = training_df[numeric_features] y_train = training_df['median_house_value'] # モデルのフィッティング pipeline.fit(X_train, y_train) return pipeline
このコードは、住宅価格予測のための線形回帰モデルをトレーニングし、モデルを発行するためのものです。トレーニングデータは指定されたパスから読み込まれ、モデルはLinearRegressionを使用してトレーニングされます。特徴量は標準化され、結果のモデルはSklearnRegressionAdapterによってラップされ、発行されます。
ユーザーのリポジトリ内の model_training/model_training.py ファイルを開き、モデルのための compute 関数を作成します。モデルの機械学習ロジックを train_model 関数にコピーします。トレーニングデータセットとモデルへのパスを正しく更新します。右上の Build を選択してコードを実行します。
ステップ 4: モデル推論ロジックを書く
ユーザーのリポジトリ内の model_training/run_inference.py ファイルを開き、モデル推論ロジックを作成します。モデルとテストデータセットへのパスを正しく更新します。右上の Build を選択してコードを実行します。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14from transforms.api import transform, Input, Output from palantir_models.transforms import ModelInput # データ変換デコレータを使用して、入力と出力を定義 @transform( testing_data_input=Input("<YOUR_PROJECT_PATH>/data/housing_test_data"), # テストデータの入力 model_input=ModelInput("<YOUR_PROJECT_PATH>/models/linear_regression_model_asset"), # モデルの入力 predictions_output=Output("<YOUR_PROJECT_PATH>/data/housing_testing_data_inferences") # 予測結果の出力 ) def compute(testing_data_input, model_input, predictions_output): # モデルを使用してテストデータに対する推論を実行 inference_outputs = model_input.transform(testing_data_input) # 推論結果を指定した出力に書き込む predictions_output.write_pandas(inference_outputs.df_out)
このコードは、指定された線形回帰モデルを用いて住宅テストデータに対する予測を行い、その結果を出力データセットに保存するためのものです。
以下の手順に従うことで、既存の foundry_ml モデルを Code リポジトリから palantir_models に正常に移行できます。