注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
Code Repositories でのデータセットモデル
以下のドキュメントは、プラットフォームでの使用が推奨されなくなった foundry_ml ライブラリについて説明しています。代わりに palantir_models ライブラリを使用してください。また、foundry_ml から palantir_models フレームワークにモデルを移行する方法については、こちらの例をご覧ください。
foundry_ml ライブラリは 2025年10月31日に削除されます。これは Python 3.9 の廃止予定に対応しています。
データセットモデルは、Code Workbooks および Code Repositories から作成できます。Code Workbooks はよりインタラクティブで高度なプロット機能を備えている一方、Code Repositories は完全な Git 機能、PR ワークフロー、およびメタプログラミングをサポートしています。
このワークフローでは、Code Repositories および Pythonトランスフォーム に関する知識が前提となります。
Code Repositories でのモデルの作成
セットアップ
新しいリポジトリを作成した場合(または既存のリポジトリを開いた場合)、foundry_ml および scikit-learn が Conda 環境で利用可能 であることを確認してください。結果を検証するには、meta.yaml ファイルを確認します。以下のコードを実行するために必要な meta.yaml ファイルの例は次のとおりです。
![]()
ロジスティック回帰モデルの作成
transform デコレータを使用して、Model オブジェクトの model.save(transform_output) インスタンスメソッドを使用してモデルを保存します。
注: 以下のコードでは、複数の Stage オブジェクトが作成され、単一のトランスフォーム内で単一の Model に結合されています。これは、Code Workbook ベースの Getting Started チュートリアルで個別に保存されているステージとは異なります。どちらのアプローチも機能します。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36from sklearn.compose import make_column_transformer from sklearn.linear_model import LogisticRegression from transforms.api import transform, Input, Output from foundry_ml import Model, Stage from foundry_ml_sklearn.utils import extract_matrix @transform( iris=Input("/path/to/input/iris_dataset"), # 入力データセット out_model=Output("/path/to/output/model"), # 出力モデルの保存先 ) def create_model(iris, out_model): df = iris.dataframe().toPandas() # PySparkのDataFrameをPandasのDataFrameに変換 column_transformer = make_column_transformer( ('passthrough', ['sepal_width', 'sepal_length', 'petal_width', 'petal_length']) # カラムをそのまま通過させる ) # カラム変換器を適用してベクトル化器としてフィットさせる column_transformer.fit(df[['sepal_width', 'sepal_length', 'petal_width', 'petal_length']]) # ベクトル化器をStageとしてラップし、モデルに適用される変換であることを示す vectorizer = Stage(column_transformer) # ベクトル化器を適用して、元のすべてのカラムとベクトル化されたデータのカラム(デフォルト名は"features")を持つデータフレームを生成 training_df = vectorizer.transform(df) # ベクトルのカラムをNumPyの行列に変換し、疎行列の処理を行うヘルパー関数を使用 X = extract_matrix(training_df, 'features') y = training_df['is_setosa'] # ロジスティック回帰モデルの訓練 - 将来の警告を防ぐためにsolverを指定 clf = LogisticRegression(solver='lbfgs') clf.fit(X, y) # 変換パイプラインを含むModelオブジェクトを返す model = Model(vectorizer, Stage(clf, input_column_name='features')) # モデルを保存するための構文 model.save(out_model)
モデルの読み込みと使用
transformデコレーターを使用して、ModelクラスのModel.load(transform_input)クラスメソッドを使用してモデルを読み込みます。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15@transform( in_model=Input("/path/to/output/model"), test_data=Input("/path/to/data"), out_data=Output("/path/to/output/data/from/applying/model"), ) def apply_model(in_model, test_data, out_data): # 保存されたモデルをロード model = Model.load(in_model) # モデルをスコアリングまたはテストデータセットに適用 pandas_df = test_data.dataframe().toPandas() output_df = model.transform(pandas_df) # 変換の出力にはnumpy配列の列が含まれているため、保存前に変換 output_df['features'] = output_df['features'].apply(lambda x: x.tolist()) # モデルを適用した結果を書き込む out_data.write_pandas(output_df)
# 保存されたモデルをロード: "Load the saved model from above"# モデルをスコアリングまたはテストデータセットに適用: "Apply the model on the scoring or testing dataset"# 変換の出力にはnumpy配列の列が含まれているため、保存前に変換: "the output of the transformation contains a column that is a numpy array, cast before saving it down"# モデルを適用した結果を書き込む: "Write the results of applying the model"
メトリクスセットの保存と読み込み
メトリクスセットは、モデルと同じ構文を使用して保存および読み込みます。すなわち、metric_set.save(transform_output) と MetricSet.load(transform_input) です。
メトリクスセットは、モデルを生成する同じトランスフォーム (たとえば、トレーニング時のホールドアウトメトリクス) から生成することも、モデルを読み込んで実行する下流のトランスフォームから生成することもできます。
モデルの自動提出
これは現在開発中の実験的な機能です。ユーザーインターフェースは今後のバージョンで変更される可能性があります。
Code Repositories では、モデルをビルドするときに自動的に Modeling objective に提出するようにモデルを設定できます。設定すると、Modeling objective はモデルを サブスクライブ し、そのモデルにトランザクションが正常にコミットされるたびに新しい提出を作成します。
前提条件
この機能を使用するには、まず以下を行う必要があります:
-
Transforms Python Code Repository を作成します。リポジトリのセットアップに関する情報は、Python transforms tutorial を参照してください。
-
meta.yamlファイルにfoundry_mlパッケージをランタイム依存関係として追加し、変更をコミットします。コミットすると、以下のスクリーンショットに示されているように、インターフェースの下部に他のパネルと並んで Modeling objective ヘルパーパネルが表示されます。
- 上記の説明に従ってモデルデータセットを出力するトランスフォームを作成します。
- データセットを少なくとも 1 回ビルドします。これにより、ヘルパーパネルがリポジトリ内のモデルを検出し、自動提出を設定できるようになります。
自動提出の設定
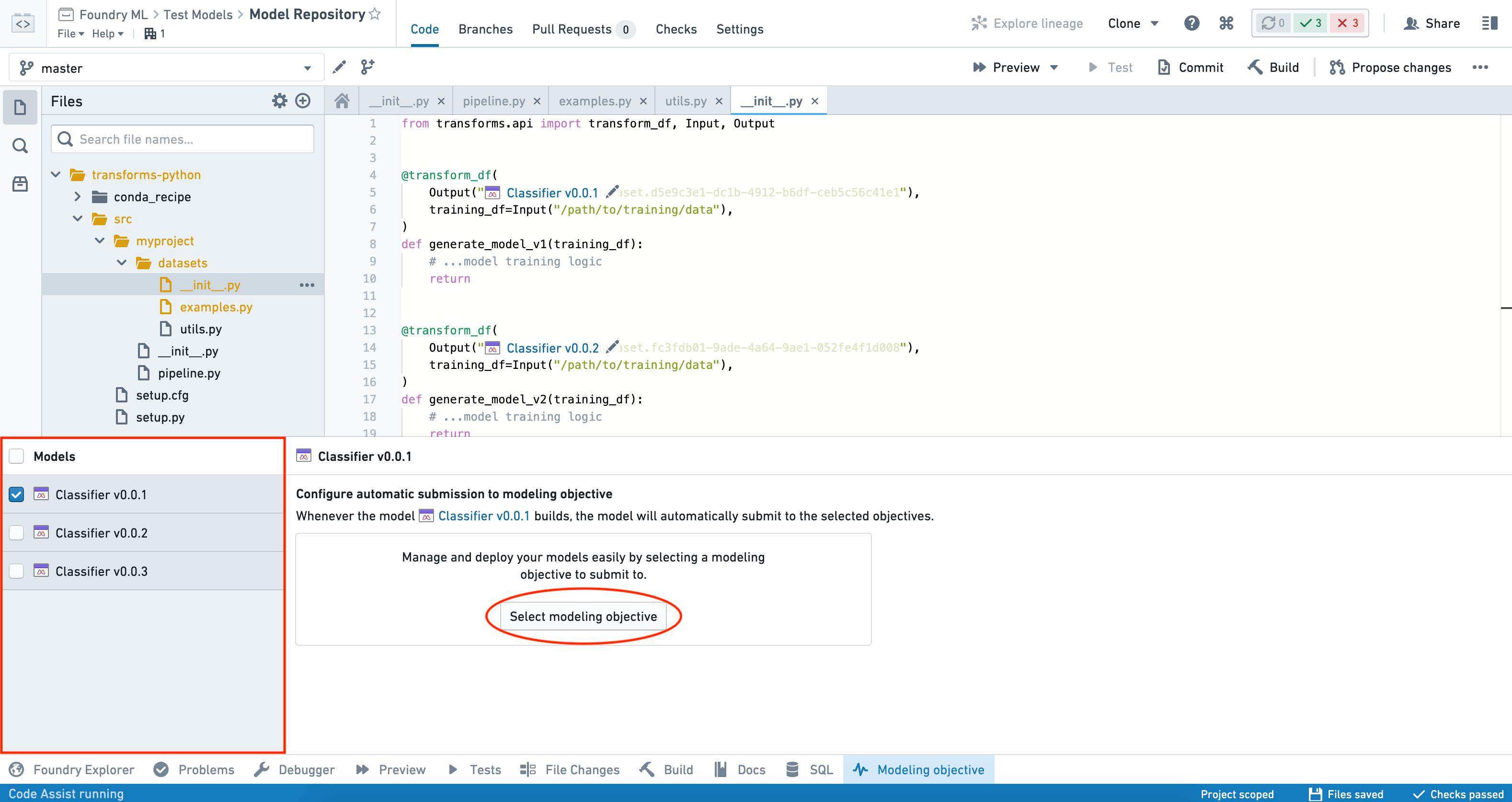
自動提出は、1 回に 1 つのモデルに対してのみ設定できます。複数のモデルを選択した場合、モデルが提出する目的のリストを表示できますが、一括で自動提出を設定することはできません。
モデルに対して自動提出を設定するには、インターフェースの左側の Models パネルからモデルを選択し、Select modeling objective ボタンをクリックして、モデルを提出したい目的を選択します。
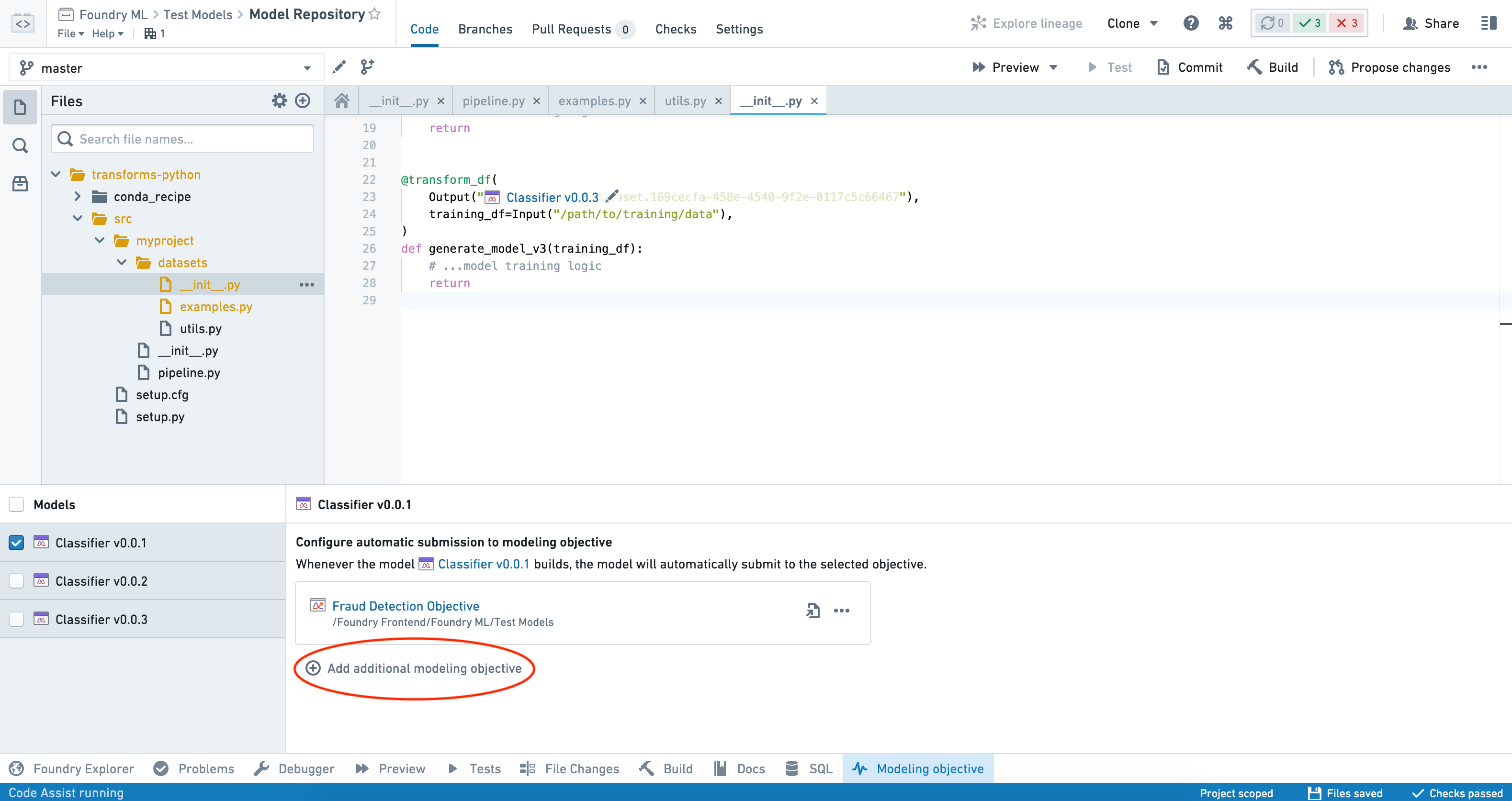
モデルがビルドされると、その目的に自動的に提出されるようになります。追加の目的に提出するには、Add additional modeling objective をクリックしてこれらの手順を繰り返します。
自動提出の無効化
特定のモデルの目的への提出を停止するには、インターフェースの左側の Models パネルからモデルを選択し、削除したい目的の横にある 3 点 (...) をクリックします。
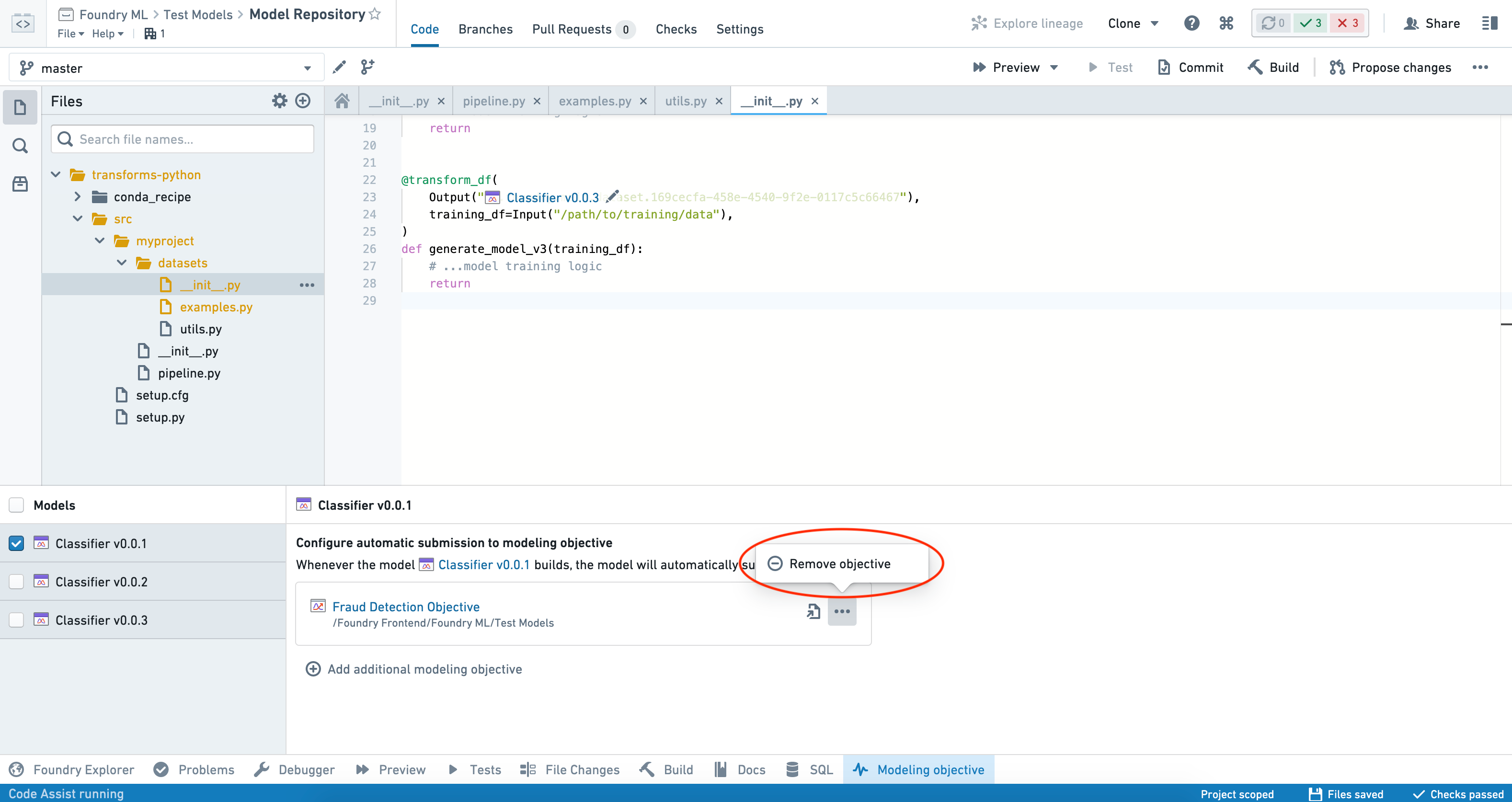
Remove objective を選択し、決定を確認します。
基準に基づく自動提出
設定されている場合、モデルはそのモデルにトランザクションが正常にコミットされるたびに自動的に提出されます。ただし、すべての再トレーニング後にモデルを再提出することが望ましいわけではないため、ユーザーの希望する基準に基づいてモデルの再トレーニングと自動提出を中止できます。
たとえば、トレーニング時にモデルが以前の提出よりも低いホールドアウトメトリクスを持つ場合、再トレーニング後の自動提出を停止することができます。これを行うには、モデルの再トレーニングトランスフォームで次の手順を実行します:
- モデルを再トレーニングし、上記の説明に従って新しいホールドアウトメトリクスを生成します。
- Foundry の 増分トランスフォーム動作 を使用して、以前のホールドアウトメトリクスを読み取ります。
- 新しいホールドアウトメトリクスを以前のホールドアウトメトリクスと比較します。
- 新しいホールドアウトメトリクスが以前のメトリクスより優れている場合、
model.save(transform_output)を使用してモデルを保存します。 - 新しいホールドアウトメトリクスが以前のメトリクスより劣っている場合、モデルトレーニングトランスフォームを中止 し、モデルの自動提出を中止します。
- 新しいホールドアウトメトリクスが以前のメトリクスより優れている場合、
上記の手順は、モデル再トレーニング中に多くのライブチェックを実行するために容易に再利用できます。
自動再トレーニングの設定
自動提出と build schedules を組み合わせることで、体系的なモデル再トレーニングを設定できます。
モデルに自動提出を設定したら、同じモデルにスケジュールを追加します。必要に応じて上流のデータセットも含めることができます。たとえば:
- モデルを生成するトランスフォームに別々にトレーニングされたステージが含まれている場合、それらをスケジュールに含めることを検討するかもしれません。
- 場合によっては、トレーニングデータセットをスケジュールの一部に含めることが適切な場合もあります。
スケジュール内で任意の組み合わせの 時間ベースおよびイベントベースのトリガー を設定できます。
一般的な構成には以下が含まれます:
- 純粋な時間ベースのトリガー (たとえば、24 時間ごとに再トレーニング)。
- 純粋なイベントベースのトリガー (たとえば、トレーニングセットが更新されるたびに再トレーニング)。
- 上記の
ANDまたはORの組み合わせを使用した高度な構成。
高度な再トレーニングトリガー
高度な再トレーニングトリガーを進める前に、増分トランスフォーム に慣れておくことをお勧めします。
計算コストの高いトレーニングジョブなどの場合、モデルのビルドスケジュールを他のデータセットに基づいてトリガーすることで、選択的にモデルを再トレーニングできます。これにより、特徴量のドリフト、スコアのドリフト、モデルの劣化、ユーザーのフィードバック、その他の指標に基づいて再トレーニングをトリガーできます。
これを行うには、"アラート" データセットを作成してスケジュールすることをお勧めします。これは、ユーザーのユースケースに適した要素の組み合わせを使用できます。
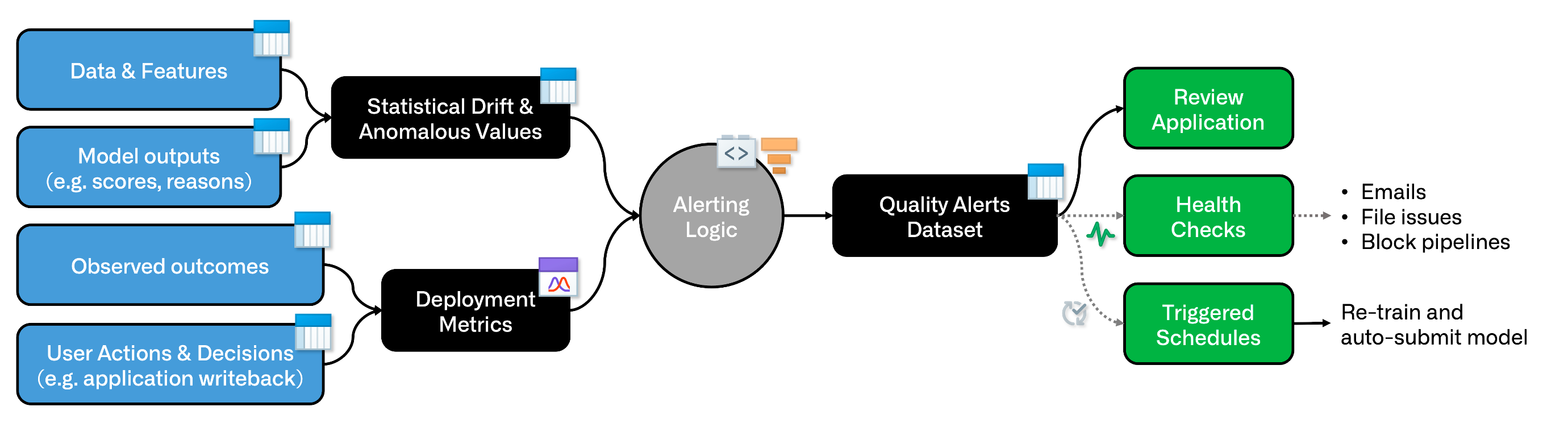
コードベースまたはロー/ノーコードツール (たとえば Contour) を使用してロジックをエンコードできます。
アラートロジックの下流では、コードリポジトリ内の Python transforms を使用して追加専用の増分 "アラート" データセットを生成します。トランスフォームロジック内で、新しいアラートがない場合は トランザクションを中止 します。
これで、"Transaction committed" イベントトリガー に基づいてモデルの再トレーニングスケジュールをトリガーできます。
アラートデータセットに ヘルスチェック を設定したり、カスタムレビューアプリケーション で使用することもできます。