- Capabilities
- Getting started
- Architecture center
- Platform updates
Sequencing development
The Palantir "levels" framework ↗ provides a map for enterprise-wide digital transformation. For a use case, the framework embodies one reasonable approach for the implementation sequence.
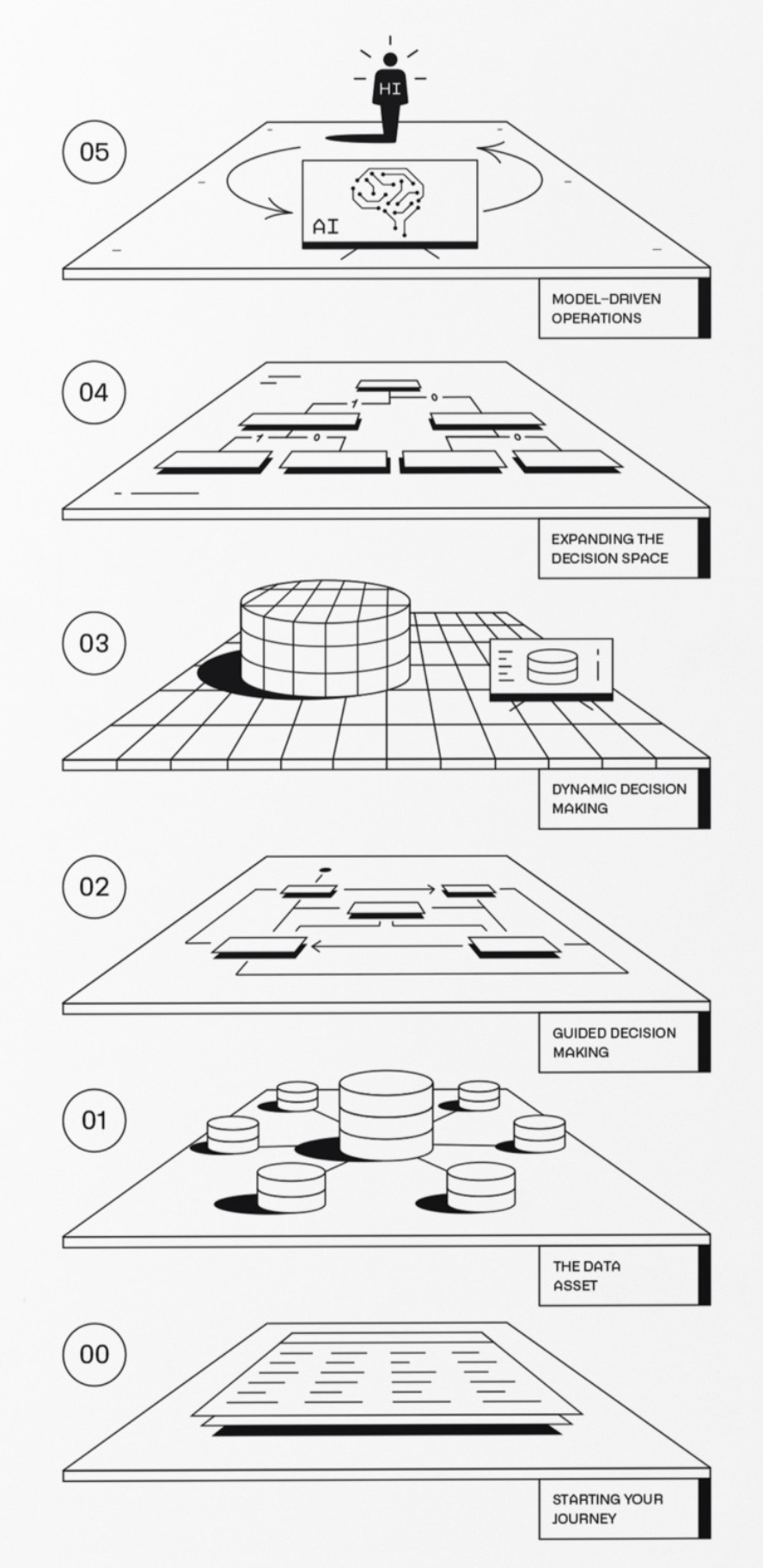 | The article linked above shares a number of considerations. Most relevant to the use case implementation sequence is the importance of first establishing a data asset (1) and guided decision-making (2) - in this context, the data pipeline, ontology structure, and initial interfaces. You can then proceed into decision space expansion and enrichment, incorporating data science techniques for model-driven operational workflows. |
Specifically, this means putting development effort and focus into the use case foundations:
- a robust and efficient pipeline
- a balanced, reflective, and practical object model
- a flexible approach to enriching data with labels and metrics based on data science, rules, and manual approaches
- re-usable interface components for object views and decision capture.
At the same time, you can explore and understand the integration story for model-driven feedback loops, digital twins, and chained scenario planning while recognizing that lower-level building blocks enable valuable multiplier technologies.
You should remember that these building blocks are not the entirety of your use case potential. Building a set of comprehensive views on top of an integration pipeline and ontology structure is your starting point for unlocking potential for flexible, interconnected, and data-driven operational workflows.