- Capabilities
- Getting started
- Architecture center
- Platform updates
Preview transforms
The Palantir extension for Visual Studio Code allows you to preview Python transforms directly from your local Visual Studio Code environment or a VS Code Workspace in the Palantir platform. Preview is a live testing environment where you can see how your data transformations work before committing them to a full build. Write code and quickly preview changes to receive immediate feedback without builds or context switching.
Why use preview?
Faster development cycles: Get immediate feedback on your transforms without running full pipeline builds. This can save considerable time when iterating on complex logic.
Catch errors early: Spot data issues, logic errors, or unexpected results before they make it into production pipelines.
Experiment confidently: Try different approaches and see results instantly, which is especially useful when exploring data or testing edge cases.
Debug efficiently: See exactly what your code does with real data, making it easier to identify and fix issues.
Preview your transforms
Start a preview
You can start a preview in any of the following four ways, depending on what works best for your workflow:
-
Command Palette: Select the Run preview command from the Command Palette.

-
Palantir side panel: Select the Preview icon from the toolbar.
-
CodeLens: Select Preview above the transform.

-
Preview panel: Open the Preview panel and select the Preview button next to the code filename.

The extension will execute your transform using real data from your inputs and show you the results immediately.
Choose your data loading strategy
One of the most powerful features in transform preview is controlling how data is loaded. This is particularly important because different transformations have different data needs; a simple aggregation works well with any sample, while testing a narrow filter or complex join requires more careful data selection.
To choose a strategy, select Configure input strategy in the Preview panel and choose between Sampled, Full dataset, or Code-defined filters options.
Sampled (default)
The sampled strategy loads a random sample of your input data, with a default of 1000 rows. The subset is randomly sampled from the input, and you can configure the number of rows.
Ideal use: Transformations where sampling is adequate and does not introduce statistical bias. Good for quick sanity checks of transform logic.
Limitations: For certain transformations, such as narrow filters or joins between multiple inputs, the result can be deceivingly short as matching values for the filtering expressions are less likely to appear in the sample. The problem becomes exponentially worse for joins between multiple inputs.
Full dataset
The full dataset option uses intelligent data loading based on your transform logic, and no pre-sampling occurs. Instead, Preview Engine relies on modern data processing engines, such as Spark or Polars, to push down predicates ↗ to the data source level and only download chunks of the dataset that are most likely to match the query.
Ideal use: Filters or other narrowing expressions used anywhere within the transform code may be eligible for pushdown, resulting in fully accurate preview results without much extra computational time incurred. This is especially valuable for testing filters and joins accurately.
Best practice: Some pipelines cannot take full advantage of predicate pushdown (for example, pipelines that do not contain filter expressions). In these cases, you can introduce conditional filter expressions in your code to speed up your preview runs during development. The efficacy of the predicate pushdown logic is highly dependent on the chosen data processing engine. Spark and DuckDB usually produce the fastest results, Polars in streaming mode is adequate, while Pandas does not support predicate pushdown.
Code-defined filters
Write your own custom filter functions that control exactly what data gets loaded during preview. This option allows you to specify your own custom filtering strategy implemented directly in your code.
Ideal use: When you need fine-grained control over what data is used for preview, want to create reusable filtering logic, or need to test specific scenarios that neither random sampling nor full dataset loading address effectively. Sampling can be effectively used to speed up preview, however, this not only requires a sufficiently small output set produced by the filter but also an efficiently implemented filtering logic. This is because the code-defined filter will be run with the entire production dataset as its input.
For more details, review our code-defined input filtering documentation.
Understanding incremental preview results
When working with incremental transforms, the Preview panel provides detailed feedback about how your transform executed. The Python transforms VS Code integration uses the same logic for incremental resolution and evaluation as production builds, so running a preview will produce the same results as a build (ignoring sampling) if it was triggered at the same time.
If the transform ran incrementally: A Ran incrementally tag will appear in the Preview panel.
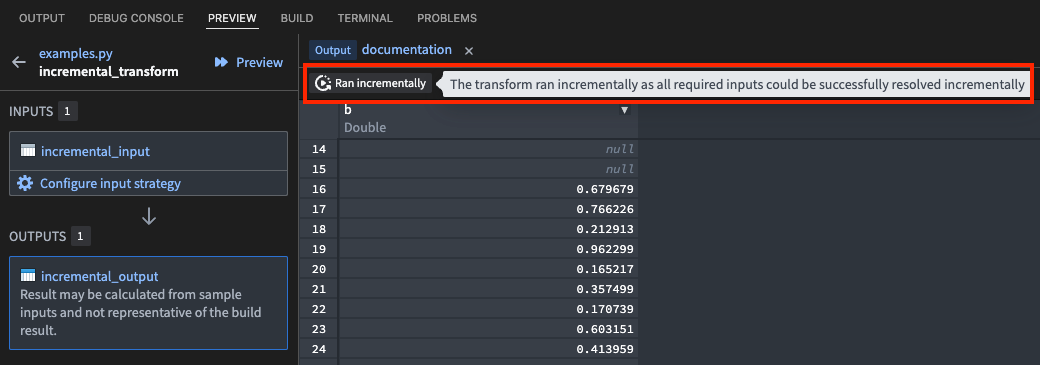
If the transform ran as a snapshot: A Ran as a snapshot tag will appear. Hover over this tag to view the reason why the transform could not run incrementally (such as a change to the semantic_version parameter, or certain transaction types on the inputs).
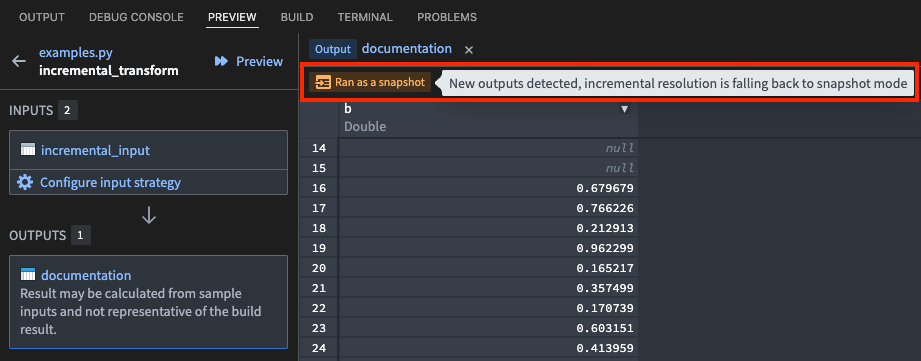
Accurate incremental preview is only supported for Spark transforms using incremental V1 semantics. If V2 semantics are enabled by setting the v2_semantics=True argument, this is ignored and V1 semantics are applied instead.
Incremental preview in VS Code for lightweight transforms always results in a snapshot mode run even if the build will run incrementally. This behavior is the same in Code Repositories.
For more context on incremental transformations and their evaluation logic, review the incremental transformations documentation.
Additional resources:
- Prerequisites for local development: Setup requirements and permissions
- Spark profiles: Configure Spark behavior during preview
Technical details
Prerequisites for local development
The Palantir extension for Visual Studio Code runs local preview using the Preview Engine. This Preview Engine streams parts of datasets to your machine if you have Download permissions for the data. For more on the security implications and data storage of local preview, review our documentation on security considerations for local development.
To use preview during local development, local preview must be enabled by your platform administrator from the Code Repositories settings page in Control Panel.
For Java transforms local preview setup using Gradle, review our documentation on preview transforms in local development.
When opening a Palantir repository, the extension will configure the environment. Once the environment is set up and transforms are detected, you will be able to execute previews locally.
Feature support comparison
The following table shows the current support matrix for different features between the preview in Code Repositories and VS Code. Code Repositories preview is not only used in Code Repositories. When previewing in VS Code, users can choose to use Full dataset, Sampled, or Code-defined filters (which applies user-defined filters to sample-less) dataset loading modes and all of these result in using Preview Engine.
| Code Repositories | VS Code preview (Preview Engine) | |
|---|---|---|
| Debugging | Supported | Supported |
| Foundry datasets | Supported | Supported |
| Transform generators | Supported | Supported |
| Data expectations | Supported | Supported |
| Lightweight transforms | Supported | Supported |
| Views and object materializations | Supported | Supported |
| Incrementality | Not supported | Supported |
| External transforms | Supported | Supported in Code Workspaces |
| Column statistics and filtering | Supported | Supported |
| Media sets | Not supported | Supported[1] |
| Models | Supported | Supported for Spark transforms[2] |
| Spark profiles | Not supported | Supported for some Spark configurations |
| Cipher | Supported | Not supported |
| Language models | Supported | Not supported |
| Virtual tables | Supported | Supported in Code Workspaces |
| Iceberg tables | Not supported | Supported in Code Workspaces |
| Complex input sampling | Supported | Supported with Code-defined (tabular and raw files) |
| Preview variables during debugging | Supported | Supported |
| Spark sidecars | Not supported | Not supported |
[1] Only put_media_item is supported in media set output preview. Incremental is not supported for media set preview.
[2] Model input and output preview is supported in both VS Code workspaces and local development. Model input preview is only supported in VS Code workspaces.
Spark profiles
Spark profiles allow users to quickly define and use custom spark configuration values to specify the behavior of the Spark engine while previewing or building the transform. Review the documentation on Spark profiles for more details.
VS Code preview applies some configurations from the previewed transform's Spark profiles. This includes configurations that affect the runtime behavior of the execution engine, most often for maintaining backward compatibility during breaking changes. It is not possible to change the resources allocated for preview through Spark profiles; this can be changed separately on the Code Workspaces settings page.
Both built-in and user-defined Spark profiles are supported during preview. Options omitted from the list below are ignored:
spark.sql.legacy.timeParserPolicyspark.sql.parquet.datetimeRebaseModeInReadspark.sql.legacy.parquet.datetimeRebaseModeInReadspark.sql.legacy.parquet.datetimeRebaseModeInWritespark.sql.analyzer.failAmbiguousSelfJoinspark.sql.legacy.dataset.nameNonStructGroupingKeyAsValuespark.sql.legacy.fromDayTimeString.enabledspark.sql.legacy.typeCoercion.datetimeToString.enabledspark.sql.legacy.followThreeValuedLogicInArrayExistsspark.sql.legacy.allowUntypedScalaUDFspark.sql.legacy.allowNegativeScaleOfDecimalspark.sql.legacy.allowHashOnMapTypespark.sql.legacy.avro.datetimeRebaseModeInReadspark.sql.legacy.avro.datetimeRebaseModeInWritespark.sql.legacy.charVarcharAsStringspark.sql.optimizer.collapseProjectAlwaysInlinespark.foundry.sql.allowAddMonthsspark.sql.parquet.int96AsTimestamp
External transforms
External transforms in Code Workspaces enforce strict export controls. The Code Workspaces application maintains a historical record of a workspace's inputs, so previous inputs that contain additional security markings may stop a preview due to marking violations. Additionally, the application accounts for all previously incorporated container markings when a workspace computes its marking security checks and export controls to avoid the inappropriate exposure of marked data.
If a workspace contains markings that are incompatible with an external transform, restart the workspace without checkpoints to clear tracked markings. Review the external transforms documentation for additional information.