注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
ライブデプロイメントのコンピュート使用量
Foundry Machine Learningのライブデプロイメントは、モデルリリースのための持続可能でスケーラブルなデプロイメントで、APIエンドポイントを介して操作できます。ライブデプロイメントは、専用のコンピューティングリソースを継続的に確保して、着信トラフィックに迅速に対応できるようにします。その結果、デプロイメントがアクティブな間、Foundry のコンピュート秒を使用します。ただし、これはモデルを利用したデプロイメントのみであり、JavaScript 関数を利用したデプロイメントはこのドキュメントの範囲外です。
実行中の Foundry Machine Learning Live のコンピュート使用量は、モデリング目的自体に帰属し、モデリング目的を含むプロジェクトのレベルで集計されます。Foundryにおけるコンピュート秒の定義や、使用量計算に使用される式の起源については、使用タイプのドキュメントを参照してください。
コンピュート秒の計測
Foundry Machine Learning Live は、Foundry のポッドベースの計算クラスタで実行される専用の "レプリカ" というインフラストラクチャ上にホストされます。各レプリカには、vCPU と RAM の GiB で測定される一連の計算リソースが割り当てられます。各レプリカは、モデルをローカルにホストし、計算リソースを使用して着信リクエストに対応します。
Foundry Machine Learning Liveデプロイメントは、アクティブな間コンピュート秒を使用します。これは、受信リクエストの数に関係なく、デプロイメントが開始されるとすぐに「アクティブ」と見なされ、デプロイメントがグラフィカル・インターフェースまたは API でシャットダウンされるまで続きます。ライブデプロイメントが関連付けられているモデリング目的がコンパスゴミ箱に送られると、ライブデプロイメントもシャットダウンされます。
ライブデプロイメントのコンピュート秒使用量は、主に以下の3つの要素に依存します。
- レプリカごとの vCPU 数
- ライブデプロイメントでは、vCPU はミリコアで測定され、それぞれが vCPU の 1/1000 です
- レプリカごとの RAM の GiB
- レプリカごとの GPU 数
- レプリカの数
- デプロイメント内の各レプリカは、vCPU と RAM の GiB が同じ数です
Foundry 使用量を支払う際のデフォルトの使用率は、以下のとおりです。
| vCPU / GPU | 使用率 |
|---|---|
| vCPU | 0.2 |
| T4 GPU | 1.2 |
| V100 GPU | 3 |
これらは、Foundryの並列計算フレームワークの下で、ライブモデルがコンピューティングプロファイルに基づいてコンピューティングを使用するレートです。Palantirとエンタープライズ契約を結んでいる場合は、コンピュート使用量の計算を行う前に、Palantirの担当者に連絡してください。
以下の式で vCPU コンピュート秒を測定します。
# live_deployment_vcpu_compute_seconds は、ライブデプロイメントの仮想CPUの使用時間を計算するための変数です。
live_deployment_vcpu_compute_seconds = max(vCPUs_per_replica, GiB_RAM_per_replica / 7.5) * num_replicas * live_model_vcpu_usage_rate * time_active_in_seconds
次の式はGPUのコンピュート秒を測定します:
# リアルタイムデプロイメントのGPU計算時間を算出します。この時間は、各レプリカのGPU数、レプリカの数、
# モデルがGPUを使用する割合、そして活動時間(秒)によって決まります。
live_deployment_gpu_compute_seconds = GPUs_per_replica * num_replicas * live_model_gpu_usage_rate * time_active_in_seconds
モデリング目標の使用状況の調査
プラットフォーム内のすべてのコンピュート秒使用状況は、Resource Management Appで確認できます。
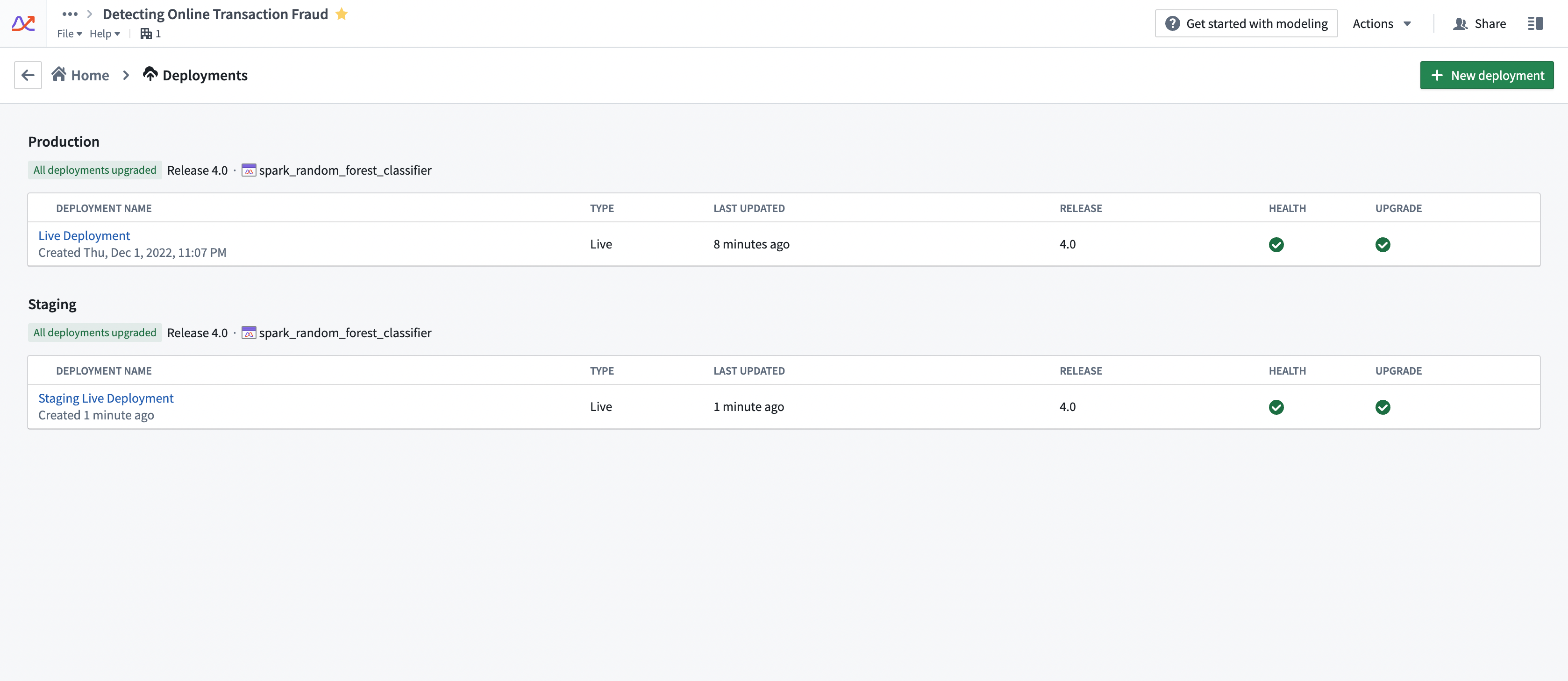
デプロイメントのコンピュート使用状況は、それがデプロイされるFoundry モデリング目標に付随します。任意の目標に対して複数のライブデプロイメントがアクティブになることに注意してください。モデリング目標のライブデプロイメントは、デプロイメントセクションで見つけることができます。以下のスクリーンショットは例です。
使用量の増減の要因
ライブデプロイメントは、アクティブである間コンピュート秒を使用します。デプロイメントの全体的な使用状況を制御するためのいくつかの戦略があります。
- 予想されるリクエスト負荷に対してデプロイメントが適切にチューニングされていることを確認してください。デプロイメントは、同時に予想されるリクエストの最大数に対してチューニングする必要があります。デプロイメントがリソース不足の場合、リクエストに対して失敗した応答を返し始めます。しかし、デプロイメントのリソースを過剰に確保すると、必要以上のコンピュート秒を使用することになります。
- Palantirは、ライブデプロイメントの管理者が、モデルを運用上重要な環境にデプロイする前に、ライブデプロイメントのエンドポイントに対してストレステストを行うことを推奨します。
- ライブデプロイメントは、明示的に停止されたりキャンセルされたりしない限り、稼働し続けます。デプロイメントが必要ないときに誤って稼働させたままにならないように、ライブデプロイメントの使用状況を監視することが重要です。これはステージングデプロイメントでよく見られます。
- デプロイメントのプロファイルを変更せずにAPI負荷を増減させると、そのコンピュート使用状況に影響はありません。ライブデプロイメントは、そのリソースが許す限り多くのリクエストを処理し、コンピュート秒の使用数を変えることはありません。
使用状況の管理
ライブデプロイメントのリソース使用状況は、そのプロファイルによって定義されます。プロファイルはライブデプロイメントの作成時に設定できます。プロファイルはデプロイメントがアクティブな間に変更することができます。デプロイメントはダウンタイムなしで更新されたプロファイルを自動的に受け取ります。
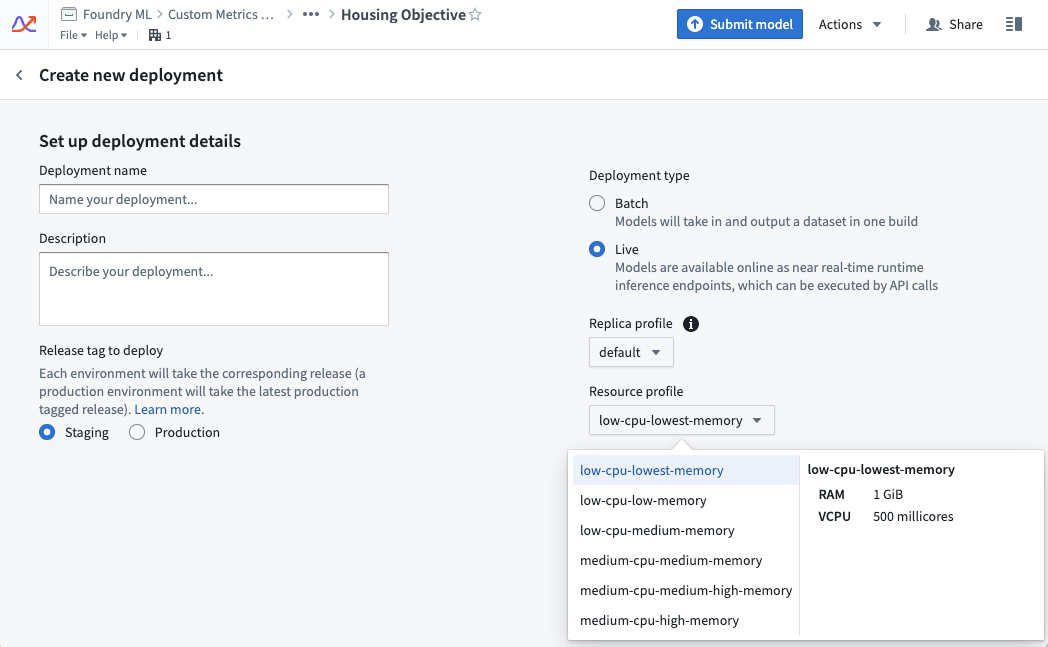
使用例
例1:vCPUコンピュート
デフォルトのレプリカプロファイルが2つのレプリカで、"low-cpu-lowest-memory"プロファイルで20秒間アクティブであるライブデプロイメント。
resource_config:
num_replicas: 2 # レプリカの数:2
vcpu_per_replica: 0.5 vCPU # レプリカごとのvCPU:0.5 vCPU
GiB_RAM_per_replica: 1 GiB # レプリカごとのRAM:1 GiB
seconds_active: 20 seconds # アクティブな時間:20秒
live_model_vcpu_usage_rate: 0.2 # ライブモデルのvCPU使用率:0.2
# 計算秒数 = max(vCPU/レプリカ, RAM/レプリカ / 7.5) * レプリカ数 * ライブモデルのvCPU使用率 * アクティブ時間(秒)
compute seconds = max(vcpu_per_replica, GiB_RAM_per_replica / 7.5) * num_replicas * live_model_vcpu_usage_rate * time_active_in_seconds
= max(0.5vCPU, 1GiB / 7.5) * 2レプリカ * 0.2 * 20秒
= 0.5 * 2 * 0.2 * 20
= 4 計算秒数
例 2: GPU コンピュート
次の例では、実行中のデプロイメントの使用率を示しています。この実行中のデプロイメントは、2つのレプリカがあるデフォルトのレプリカプロファイルを持っており、GPU V100 プロファイルで20秒間アクティブになっています。
resource_config:
num_replicas: 2 # レプリカの数
gpu_per_replica: 1 V100 GPU # レプリカあたりのGPU(ここではV100)
seconds_active: 20 seconds # 活動時間(秒)
live_model_gpu_usage_rate: 3 # ライブモデルのGPU使用率
compute seconds = gpu_per_replica * num_replicas * live_model_gpu_usage_rate * time_active_in_seconds
= 1 * 2レプリカ * 3 * 20秒
= 1 * 2 * 3 * 20
= 120 compute-seconds # 計算時間(秒)