注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
2a. チュートリアル - Jupyter® ノートブックでモデルを学習させる
このチュートリアルのステップを開始する前に、モデリングプロジェクトのセットアップ を完了している必要があります。このチュートリアルでは、Jupyter® ノートブックでモデルをトレーニングするか、Code Repositories でトレーニングするかのいずれかを選択できます。Jupyter® ノートブックは高速で反復的なモデル開発に、コードリポジトリは実稼働環境のデータやモデルパイプラインに適しています。
このチュートリアルのステップでは、Code Workspaces を使用して、Jupyter® ノートブックでモデルをトレーニングします。このステップでは、以下の内容を取り上げます。
- モデルのトレーニング用Jupyter® Code Workspaceの作成
- テストとトレーニング用の特徴データの分割
- Code Workspacesでのモデルのトレーニング
- Code Workspacesからのモデルの公開
- モデルの表示とモデリング目的への提出
2a.1 モデルのトレーニング用ノートブックの作成方法
FoundryのCode Workspacesアプリケーションは、データ分析とモデル開発用のサードパーティIDEを提供するWebベースの開発環境です。Foundry内のJupyter®ノートブックから、下流アプリケーションで使用できるモデルを直接公開できます。
Code Workspacesは、ワークスペースを使用している間、継続的に利用可能なコンピューティングリソースを確保することで、インタラクティブな開発環境を提供します。Code Workspacesを使用すると、コンピューティングリソースを待ったりPython環境をパッケージ化したりすることなく、Python環境の構成、データのトランスフォーム、チャートのプロット、モデルのトレーニングを行うことができます。
アクション: このチュートリアルの前のステップで作成した code フォルダーで、+ New > Jupyter Code Workspace を選択します。 コードワークスペースは、トレーニングするモデルに関連する名前を付ける必要があります。 この場合、リポジトリの名前を median_house_price_model_notebook とします。 Continue を選択してデフォルトの計算リソースとリポジトリ構成を使用し、次に Create を選択してワークスペースを作成して起動します。
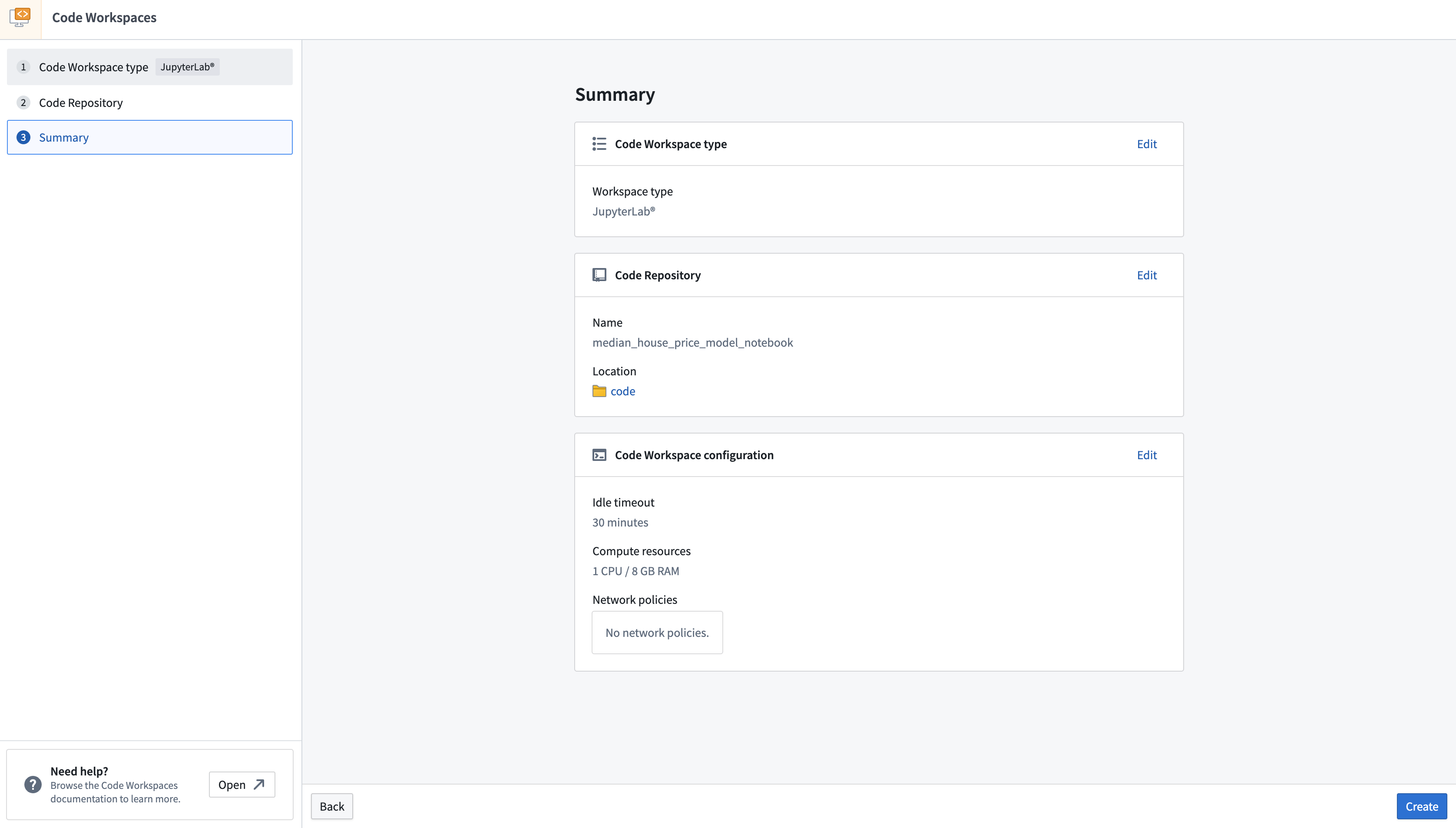
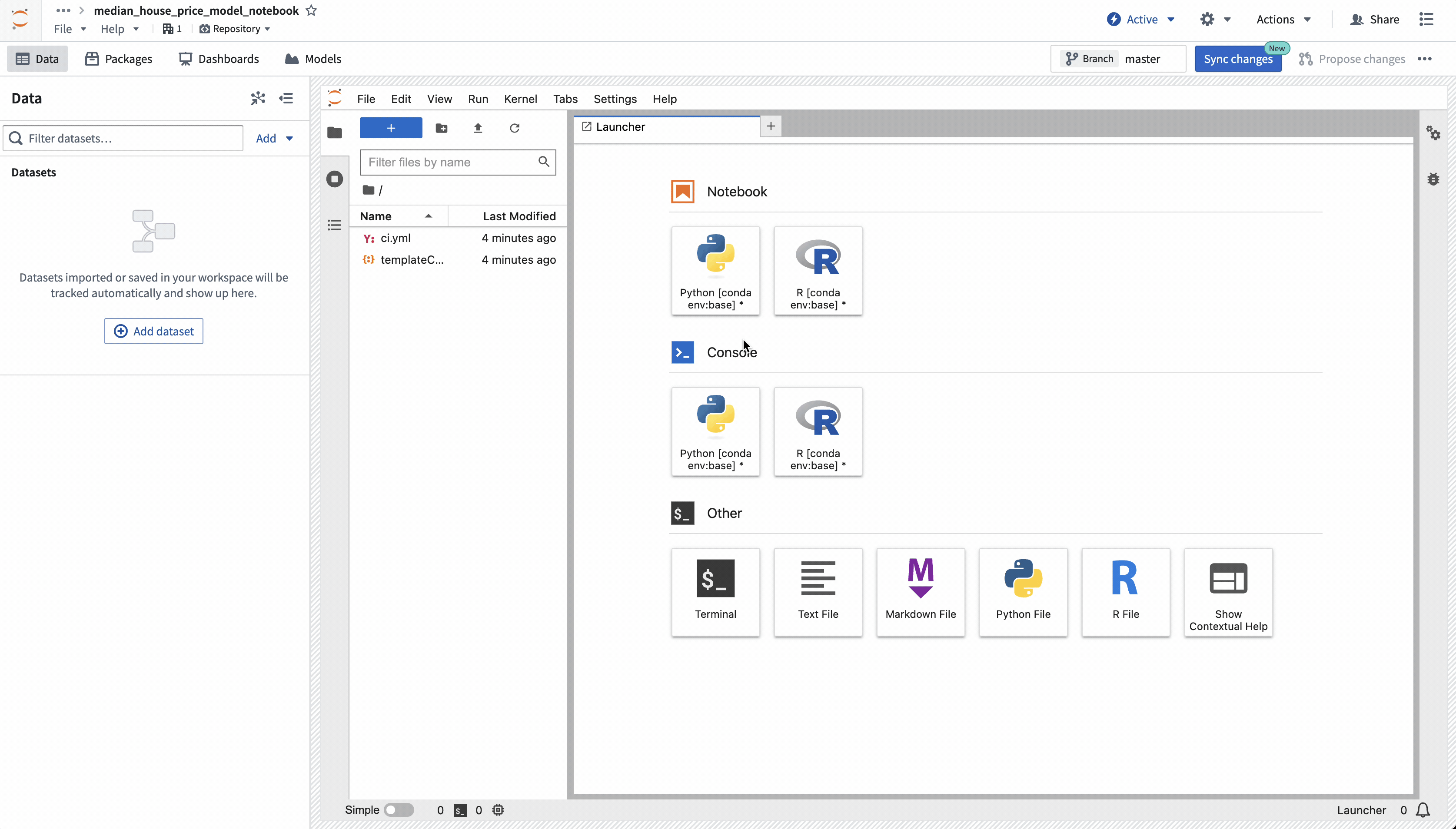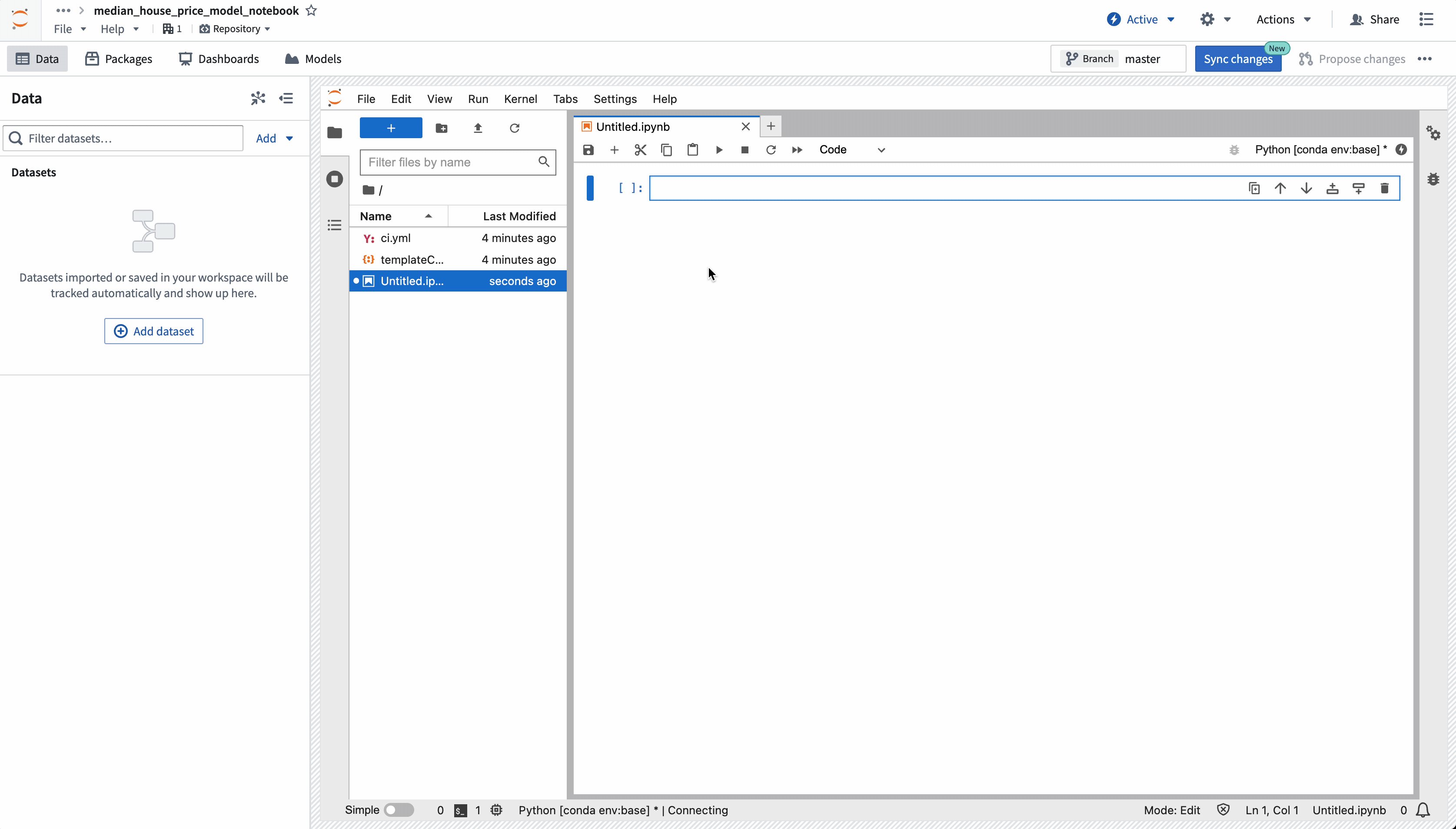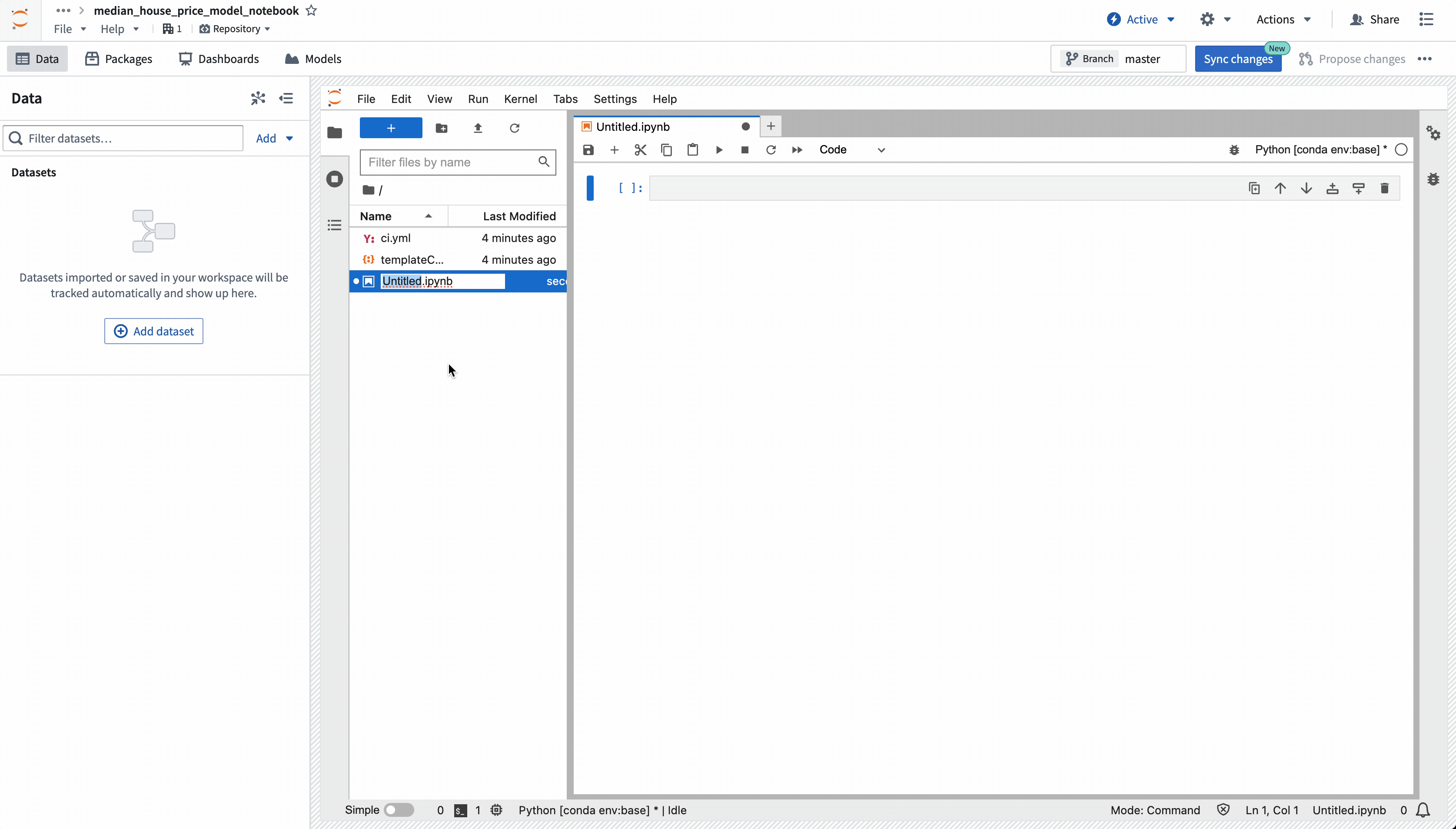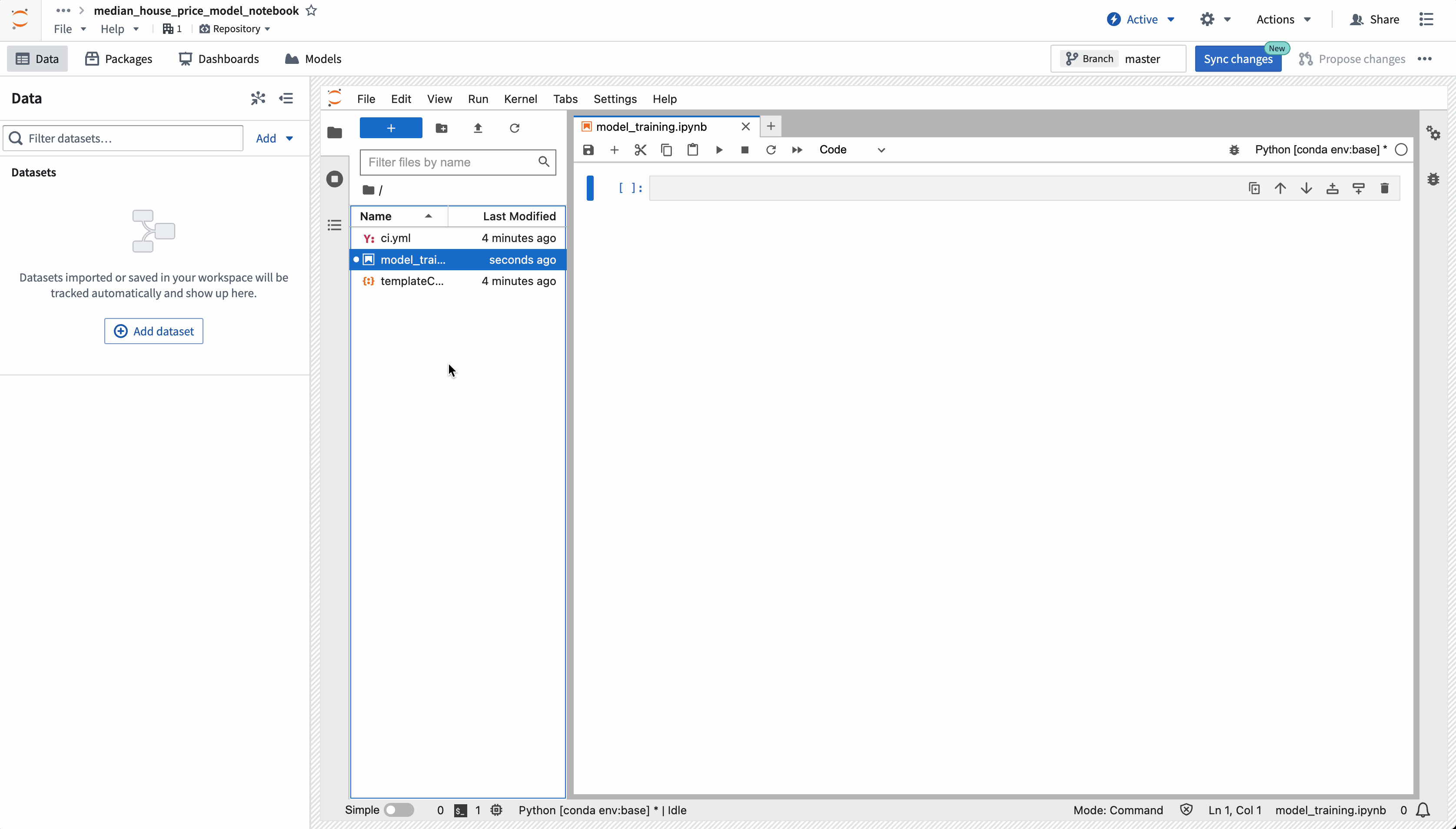
ワークスペースが作成されたら、モデルをトレーニングするために、ノートブックを作成し、いくつかの依存関係をインストールする必要があります。Jupyterlab®ランチャースクリーンで、使用するノートブックカーネルを選択します。
アクション: ベースのPython conda カーネルを選択して新しいノートブックを作成し、ファイル名を model_training.ipynb に変更します。
2a.2 テストとトレーニング用の特徴データを分割する方法
教師あり機械学習プロジェクトの最初のステップは、ラベル付きの機能データをトレーニング用とテスト用の個別のデータセットに分割することです。最終的には、パフォーマンス指標(新しいデータに対するモデルのパフォーマンスを推定する)を作成して、このモデルが本番環境で使用するのに十分なものであるかどうかを判断し、他の関係者とこのモデルの結果をどの程度信頼できるかを伝えることができるようにします。この検証には別のデータを使用する必要があります。これにより、パフォーマンス指標が現実の世界で実際に目にするものを反映したものになるよう確実にします。
データセットをCode Workspaceにインポートする
まず、Code WorkspacesのJupyter®ノートブックで使用できるように、データセットを用意します。Code Workspacesでは、入力データの「エイリアス」を作成でき、コードの可読性を高めることができます。ここでは、エイリアス「training_data」を使用します。
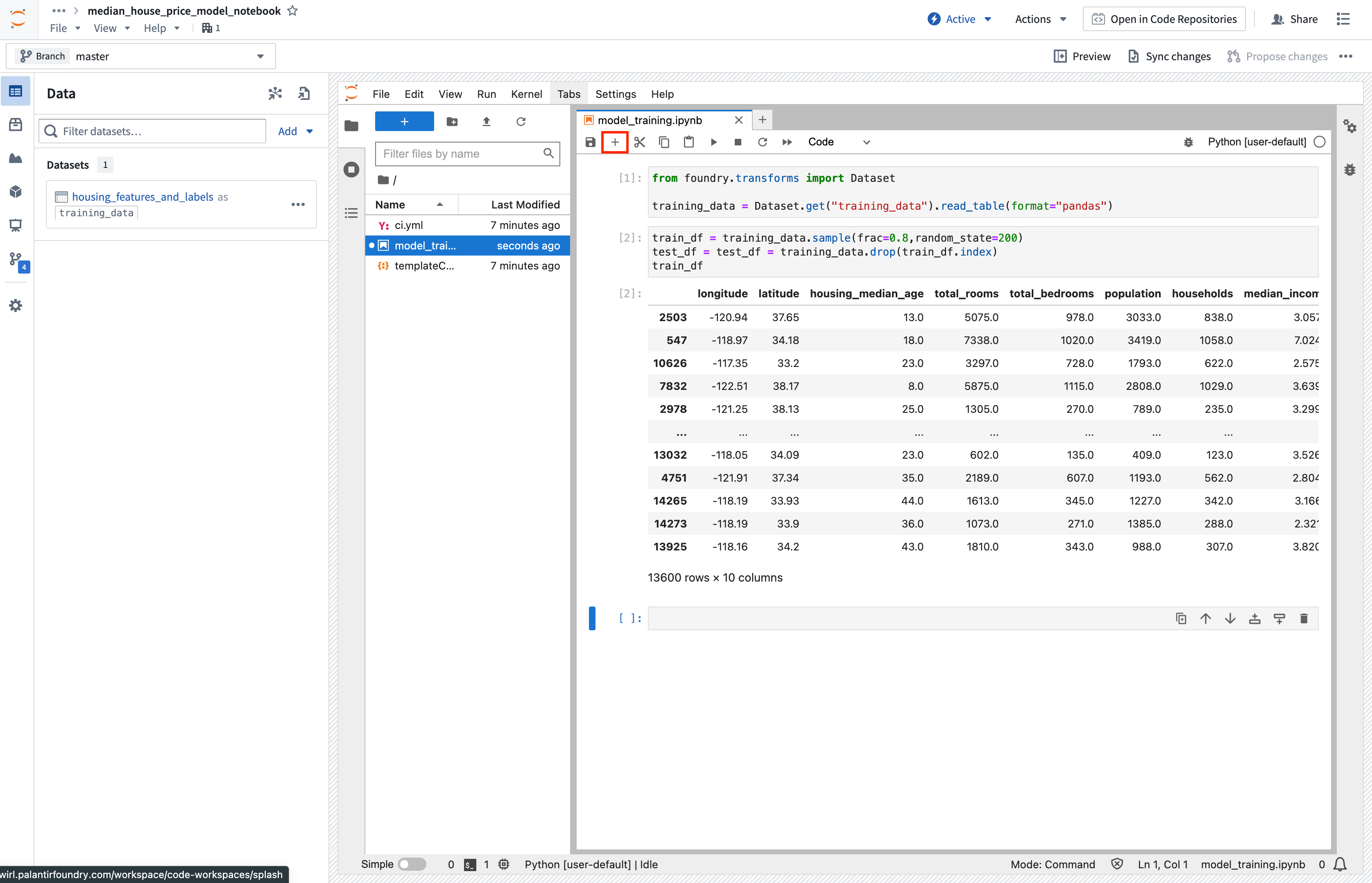
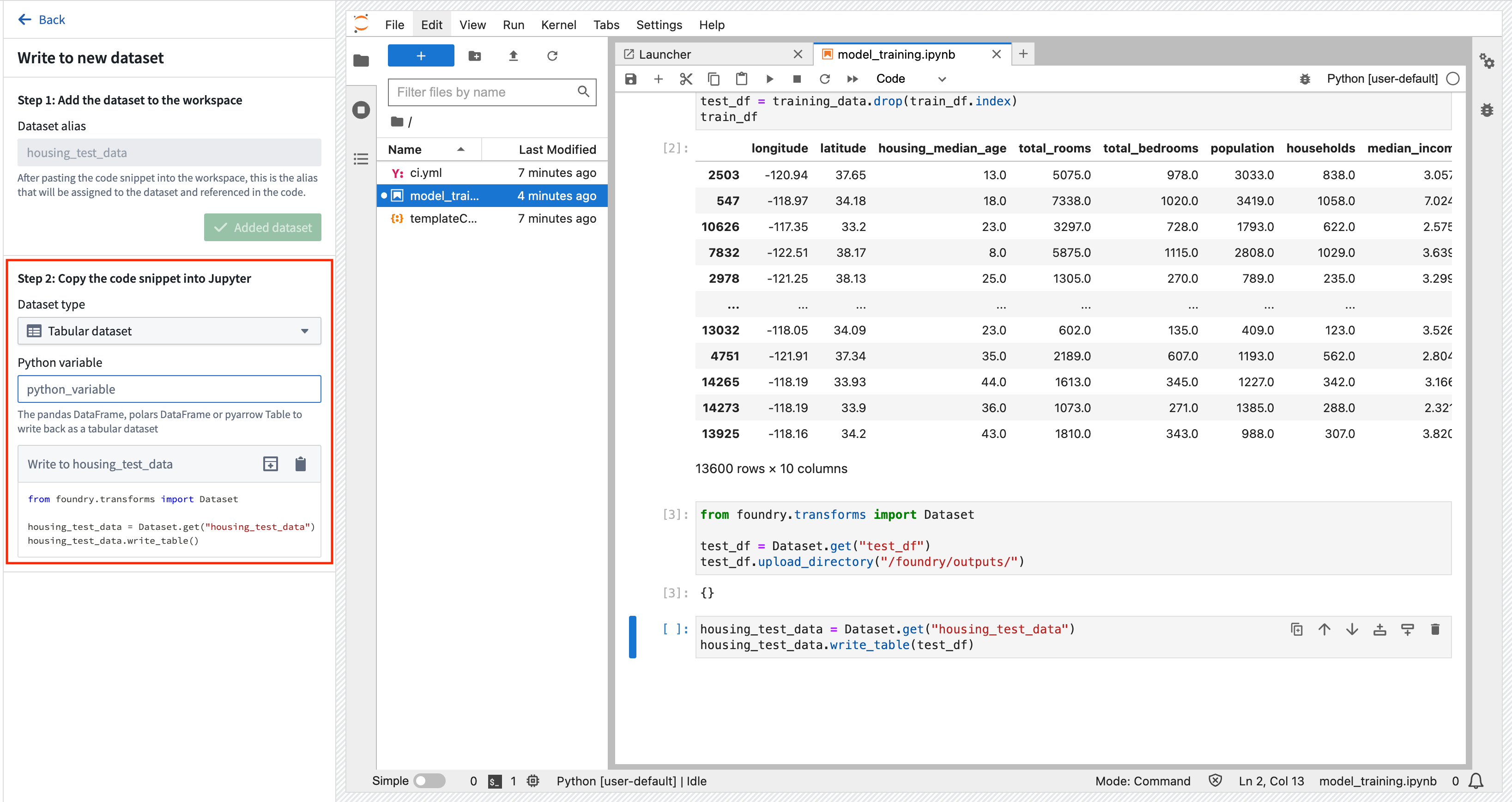
アクション: データタブを開き、データセットの追加 > 既存のデータセットの読み込み を選択します。 以前に作成した housing_features_and_labels データセットを追加し、エイリアスとして training_data を指定します。 指定したインポートロジックを Jupyter® ノートブックのセルにコピーします。 Shift + Enter キーを押してコードセルを実行します。
Copied!1 2 3from foundry.transforms import Dataset training_data = Dataset.get(「training_data」).read_table(format=「pandas」)
データをテスト用とトレーニング用に分割
データセットをインポートしたので、データをテスト用とトレーニング用のデータフレームに分割してみましょう。
アクション: ノートブックの上部にある**+**オプションを使用して新しいノートブックセルを作成し、以下のスニペットをコピーしてセルを実行します。
Copied!1 2 3train_df = training_data.sample(frac=0.8,random_state=200) test_df = training_data.drop(train_df.index) train_df
テストデータセットをFoundryに保存
次に、テストとトレーニングで分割したデータをFoundryに保存します。これにより、トレーニングとテストに使用したデータセットの記録を将来参照できるように保存できます。
アクション: 追加 > 新しいデータセットへのデータの書き込み を選択して、新しいデータセット出力を作成します。 出力に housing_test_data と名前を付け、以前の data フォルダーに出力を保存します。 データセットの種類として 追加データセット と 表形式データセット を選択し、Python 変数として test_df を選択します。 その後、新しいセルにコードをコピーして実行し、データセットを Foundry に保存します。
Copied!1 2 3 4from foundry.transforms import Dataset housing_test_data = Dataset.get(「housing_test_data」) housing_test_data.write_table(test_df)
2a.3 Code Workspacesでモデルをトレーニングする方法
Foundryのモデルは、2つのコンポーネントで構成されています。
- モデル作成物:モデルトレーニングジョブで作成されたモデルファイル。
- モデルアダプター:推論を実行するために、Foundryがモデル作成物とどのようにやり取りすべきかを記述するPythonクラス。
モデルの依存関係
モデルトレーニングには、モデルトレーニング、シリアライゼーション、推論、または評価ロジックを含むPythonの依存関係を追加する必要がほとんどの場合あります。Foundryは、CondaとPyPI(pip)による依存関係の指定をサポートしています。これらの依存関係の指定により、モデルトレーニングに使用できるPython環境が作成されます。
Foundryでは、解決されたこれらの依存関係と、Jupyter®ノートブック内のすべてのPython .pyファイルが、モデルとともに自動的にパッケージ化され、本番環境で推論(予測の生成)を実行するために必要なすべてのロジックがモデルに自動的に組み込まれるようになっています。Jupyter® Code Workspacesの環境は、マエストロコマンドによって管理されます。この例では、モデルの作成には pandas と scikit-learn を使用し、モデルの保存には dill を使用します。
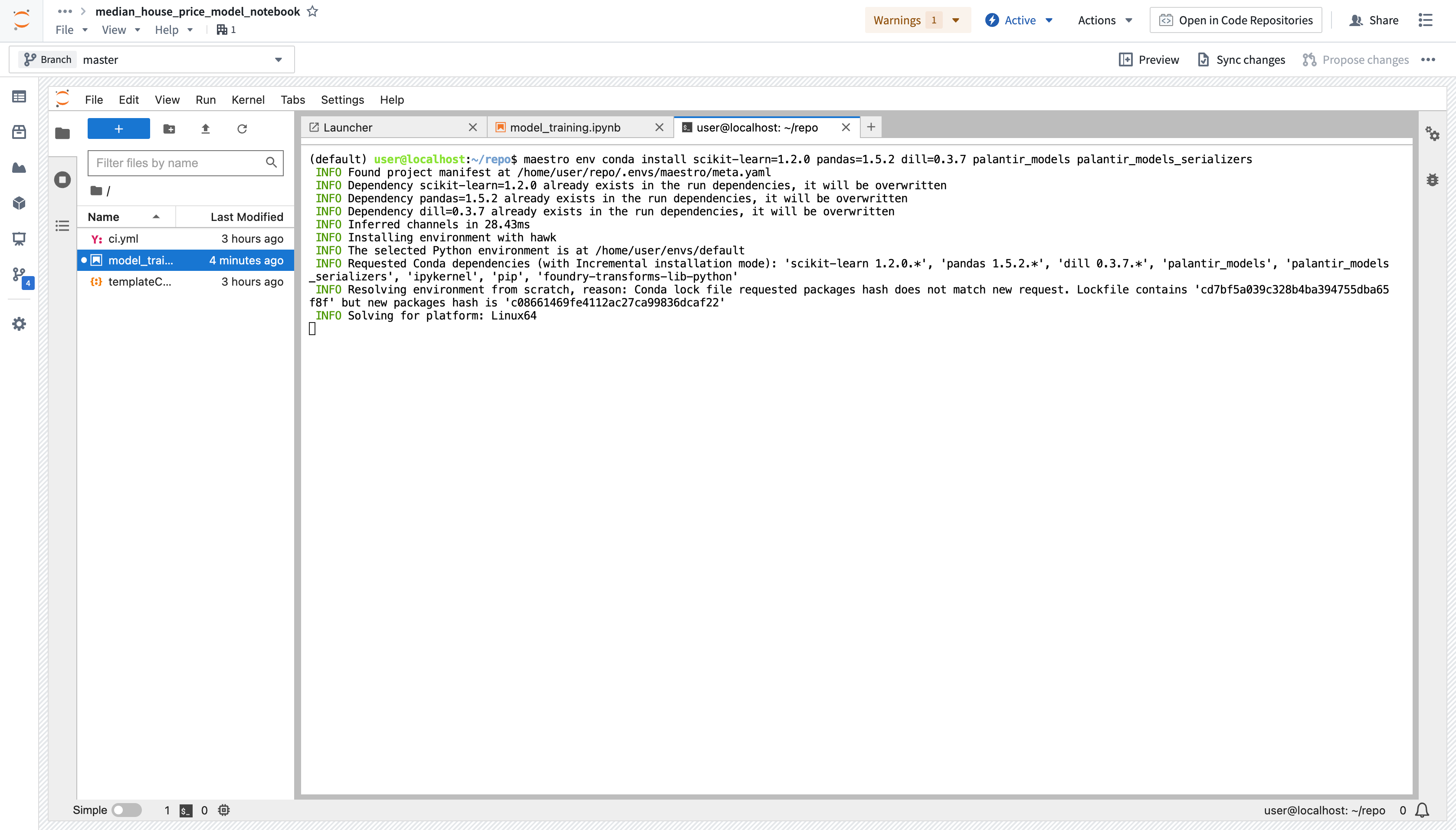
アクション:青い+ボタンを選択してLauncherを開き、ターミナルを起動します。以下のコマンドを実行して、3つの依存関係をすべて追加します。サイドバーのPackagesタブを使用して、インストールするパッケージのバックエンドリポジトリをインストールすることもできます。これにより、ターミナルが開き、maestroコマンドが実行されます。
maestro env conda install scikit-learn=1.2.0 pandas=1.5.2 dill=0.3.7 palantir_models palantir_models_serializers
モデルのトレーニング
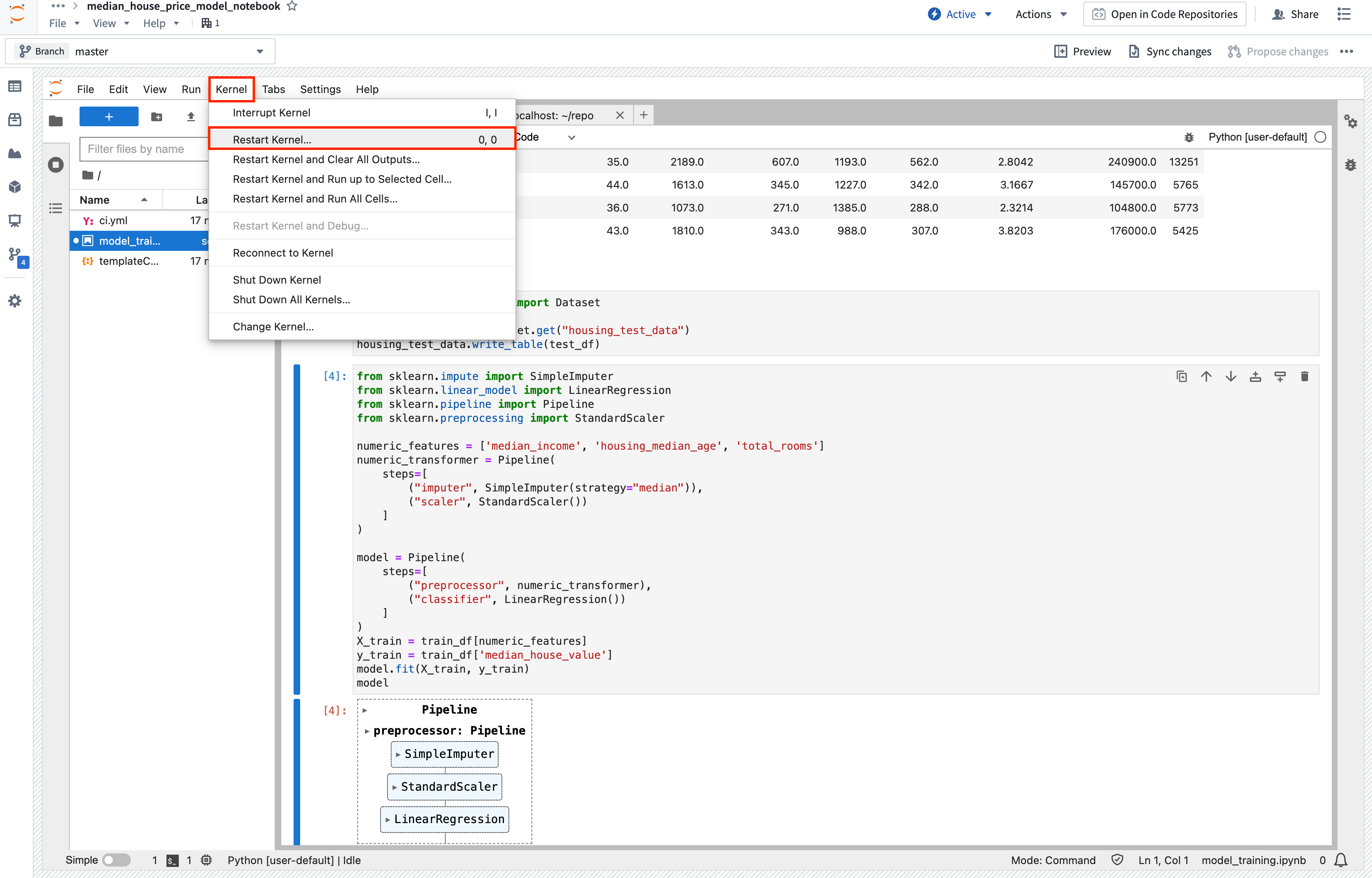
アクション: 上記のコードを新しいセルにコピーし、実行して、Jupyter® ノートブックのメモリ内に新しいモデルをトレーニングします。 ModuleNotFoundError または ImportError が発生した場合は、カーネルを再起動(Kernel > Restart Kernel...)して、環境が要求された依存関係の変更を確実に認識するようにします。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21from sklearn.impute import SimpleImputer from sklearn.linear_model import LinearRegression from sklearn.pipeline import Pipeline from sklearn.preprocessing import StandardScaler numeric_features = ['median_income', 'housing_median_age', 'total_rooms'] numeric_transformer = Pipeline( steps=[ (「imputer」, SimpleImputer(strategy=「median」)), (「scaler」, StandardScaler()) ]) model = Pipeline( steps=[ (「preprocessor」, numeric_transformer), (「classifier」, LinearRegression()) ]) X_train = train_df[numeric_features] y_train = train_df['median_house_value'] model.fit(X_train, y_train) model
(オプション) モデル実験のメトリクスとハイパーパラメータをログに記録する
モデル実験 は、モデルのトレーニング実行中に生成されたメトリクスとハイパーパラメータを記録するための軽量なフレームワークです。
2a.4 Code Workspaces からモデルを公開する方法
モデルを作成したので、それを Foundry に公開して本番アプリケーションと統合することができます。モデルを公開するには、モデルを保存する Foundry のモデルリソースを作成し、次にモデルアダプタでモデルをラップして、Foundry がモデルとどのようにやり取りするかを認識できるようにする必要があります。
アクション: Models タブで Add model > Create new model を選択し、linear_regression_model と名付けます。 モデルを先ほど作成した models フォルダーに保存し、Create を選択してリソースを作成します。
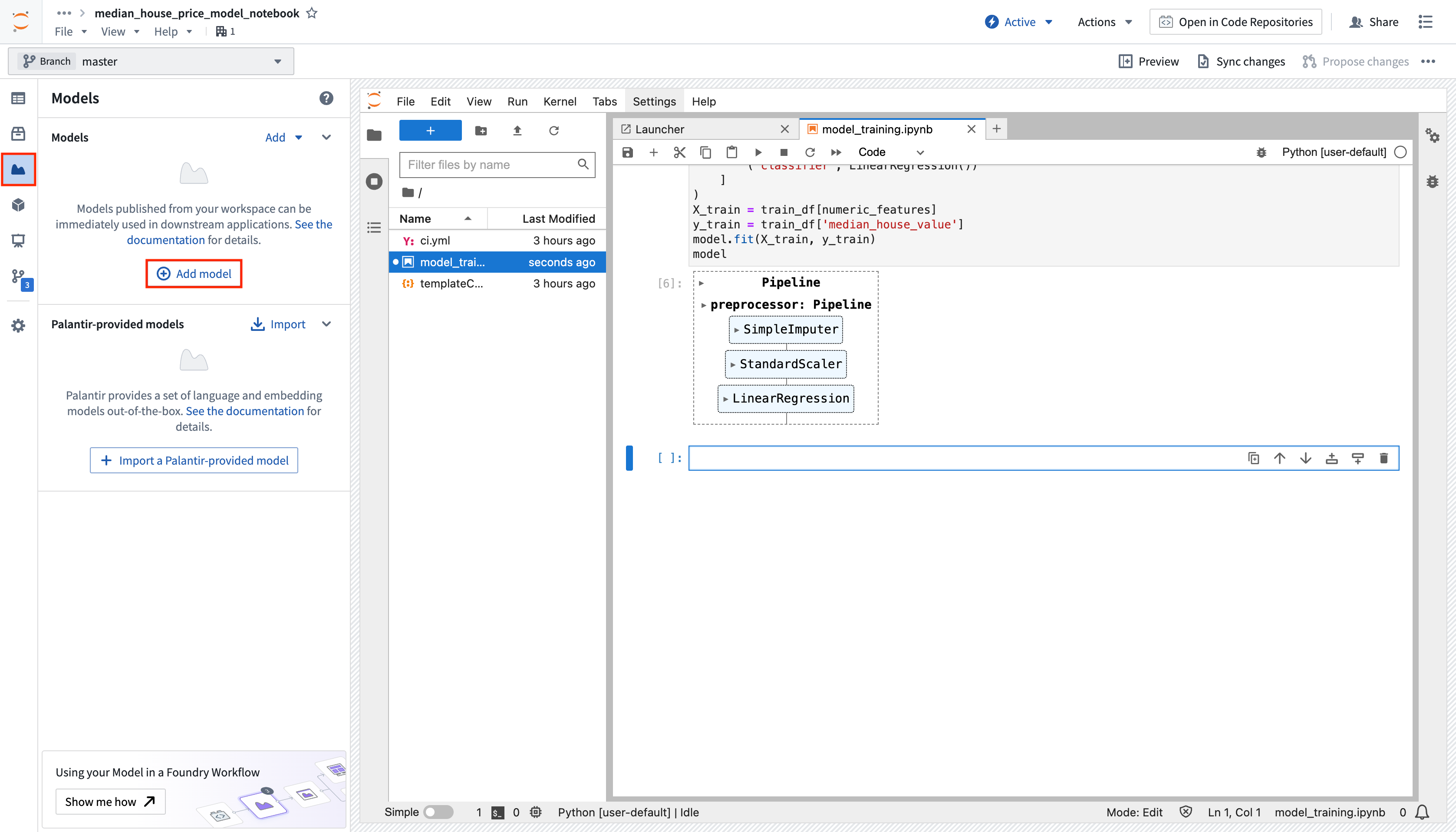
モデルリソースを作成すると、Foundryが自動的にモデルアダプターを実装するための新しいPythonファイルを作成します。モデルアダプター(モデルアダプター)は、Foundry内のすべてのモデルに対する標準インターフェースを提供します。標準インターフェースにより、Foundryがモデルのロード、Python依存関係、APIの公開、およびモデルとのインターフェースなどのインフラストラクチャを処理するため、すべてのモデルを実稼働アプリケーションですぐに使用できるようになります。
Code Workspacesのモデルアダプターは、個別のPython(.py)ファイルで定義し、ノートブックにインポートする必要があります。
モデルアダプターを作成するには、4つの関数を実装する必要があります。
- モデルの保存と読み込み: モデルを再利用するには、モデルの保存と読み込み方法を定義する必要があります。 Palantir にはシリアライズ(保存)の デフォルトのメソッド が多数用意されており、より複雑なケースでは、カスタムのシリアライズ ロジックを実装することもできます。
api: モデルの API を定義し、モデルに必要な入力データのタイプを Foundry に通知します。predict: Foundry によって呼び出され、モデルにデータを渡します。 ここで、入力データをモデルに渡し、推論(予測)を生成します。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26import palantir_models as pm from palantir_models_serializers import DillSerializer class LinearRegressionModelAdapter(pm.ModelAdapter): @pm.auto_serialize( model=DillSerializer() ) def __init__(self, model): self.model = model @classmethod def api(cls): columns = [ ('median_income', float), ('housing_median_age', float), ('total_rooms', float), ] return {「df_in」: pm.Pandas(columns)}, {「df_out」: pm.Pandas(columns + [('prediction', float)])} def predict(self, df_in): df_in['prediction'] = self.model.predict( df_in[['median_income', 'housing_median_age', 'total_rooms']] ) return df_in
アクション: 上記のコードを linear_regression_model_adapter.py という名前の新しいファイルにコピーします。左側のモデルサイドバーからモデルのバージョンを公開するスニペットを選択し、Foundryに公開セクションを展開して、対応するコードスニペットをメインのノートブックにコピーします。Pythonの新しいmodel変数に合わせてコードスニペットを調整してください。実際に.publish関数を呼び出す前に、モデルアダプターをテストしたい場合もあるでしょう。アダプターモデルインスタンスから.transformを実行することで、テストを行うことができます。
適応されたモデルのインスタンスを作成し、テストします。
Copied!1 2 3 4 5 6 7 8 9# autoreload 拡張モジュールをロードし、すべてのモジュールを自動的に再ロードします。 %load_ext autoreload %autoreload 2 from palantir_models.code_workspaces import ModelOutput from linear_regression_model_adapter import LinearRegressionModelAdapter # クラス名またはファイル名が変更された場合は更新します。 # Foundry 用にトレーニングされたモデルをモデルアダプターでラップします。 linear_regression_model_adapter = LinearRegressionModelAdapter(model) linear_regression_model_adapter.transform(test_df).df_out
Foundryにモデルを公開します。
Copied!1 2 3# モデルリソースへの書き込み可能な参照を取得します。 model_output = ModelOutput(「linear_regression_model」) model_output.publish(linear_regression_model_adapter) # Foundryにモデルを公開します

2a.5 オプション: 推論または再トレーニングジョブの設定
推論および/または再トレーニングのジョブを作成し、Jupyter®ノートブックから直接スケジュールに従って実行するように設定できます。これにより、Palantirのビルドインフラストラクチャを活用した変換として.ipynbファイルが実行され、Data Lineageと権限が追跡されます。この機能により、Jupyter®ノートブックで反復を継続しながら、長時間かかるトレーニングジョブを並列で設定することもできます。ノートブックから直接モデル出力を用いて変換を作成する方法(../code-workspaces/training-models.md#transforms)と、[Code Repositoryからモデルを消費する方法(./tutorial-train-code-repositories.md#2b4-how-to-test-inference-logic-in-code-repositories)]を学んでください。
このモデルは、直接デプロイすることで、REST APIとして消費することもできます。直接デプロイメントの構成方法についてはこちらを参照してください。
2a.6 モデルの表示とモデリング目標への提出方法
モデルが作成されたので、そのモデルをモデリング目標に提出して、問題のモデルライフサイクル全体を管理することができます。モデリング目標を使用すると、新しいリリースの検証と継続的な評価を行うためのチェックを構成することができます。
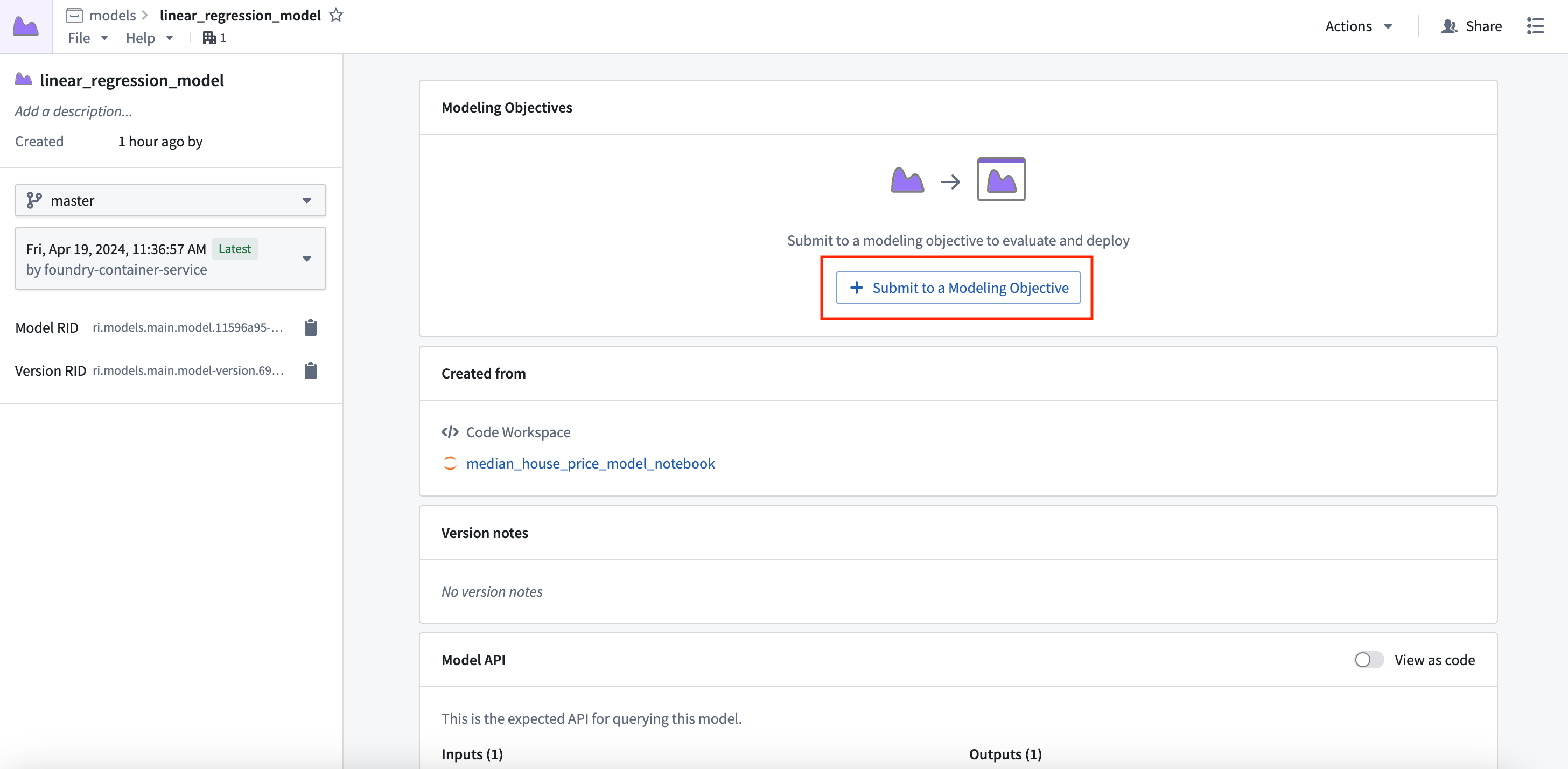
アクション: プレビューウィンドウでView model version を選択して作成したモデルアセットに移動し、Submit to a Modeling Objective を選択して、このチュートリアルのステップ1で作成したモデリング目的にそのモデルを提出します(./tutorial-set-up-project.md#11-how-to-structure-a-foundry-project-for-machine-learning)。提出名と提出オーナーを入力するよう求められます。これは、モデリング目的内でモデルを一意に追跡するために使用されるメタデータです。モデルの名前を linear_regression_model にし、ご自身を提出物のオーナーとしてマーキングしてください。
次のステップ
これで、Foundryでモデルをトレーニングしたので、モデル管理、テスト、モデル評価に進むことができます。Modeling Objectivesで実行できる追加ステップの例を以下に示します。
- 自動モデル評価
- モデル提出のチェックの設定
- ライブ と バッチ推論 も、Modeling Objectives から設定できます。
オプションとして、Code Repositories アプリケーション でモデルをトレーニングすることもできます。これは、実稼働環境向けのモデルトレーニングパイプラインを作成するために設計されています。
Jupyter®、JupyterLab®、およびJupyter®ロゴはNumFOCUSの商標または登録商標です。
参照されているすべてのサードパーティ商標(ロゴおよびアイコンを含む)は、それぞれの所有者に帰属します。提携や推奨を意味するものではありません。