注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
2b. チュートリアル - Code Repositories でモデルを学習させる
このチュートリアルのステップを開始する前に、 モデリングプロジェクトの設定 を完了しておく必要があります。 このチュートリアルでは、 Jupyter® ノートブック でモデルを学習させるか、Code Repositories で学習させるかを選ぶことができます。 Jupyter® ノートブックは、迅速で反復的なモデル開発におすすめであり、Code Repositories は本番環境向けのデータとモデルパイプラインにおすすめです。
このチュートリアルのステップでは、 Code Repositories でモデルを学習させます。 このステップでは以下の内容をカバーします。
- モデル学習用のコードリポジトリを作成する方法
- テストと学習用の機能データを分割する方法
- Code Repositories でモデル学習ロジックを作成する方法
- Code Repositories で推論ロジックをテストする方法
- モデルを表示し、モデリングの目的に送信する方法
2b.1 モデル学習用のコードリポジトリを作成する方法
Foundry の Code Repositories アプリケーションは、本番環境向けのデータと機械学習パイプラインを作成するためのウェブベースの開発環境です。 Foundry は、 Model Training テンプレートという機械学習用のテンプレートリポジトリを提供しています。
アクション: このチュートリアルの前のステップで作成した code フォルダーを選択し、+ New > Code repository を選択します。 コードリポジトリは、学習させるモデルに関連する名前で命名する必要があります。 この場合、リポジトリの名前を "median_house_price_model_repo" にします。Model Training テンプレートを選択し、Initialize をクリックします。
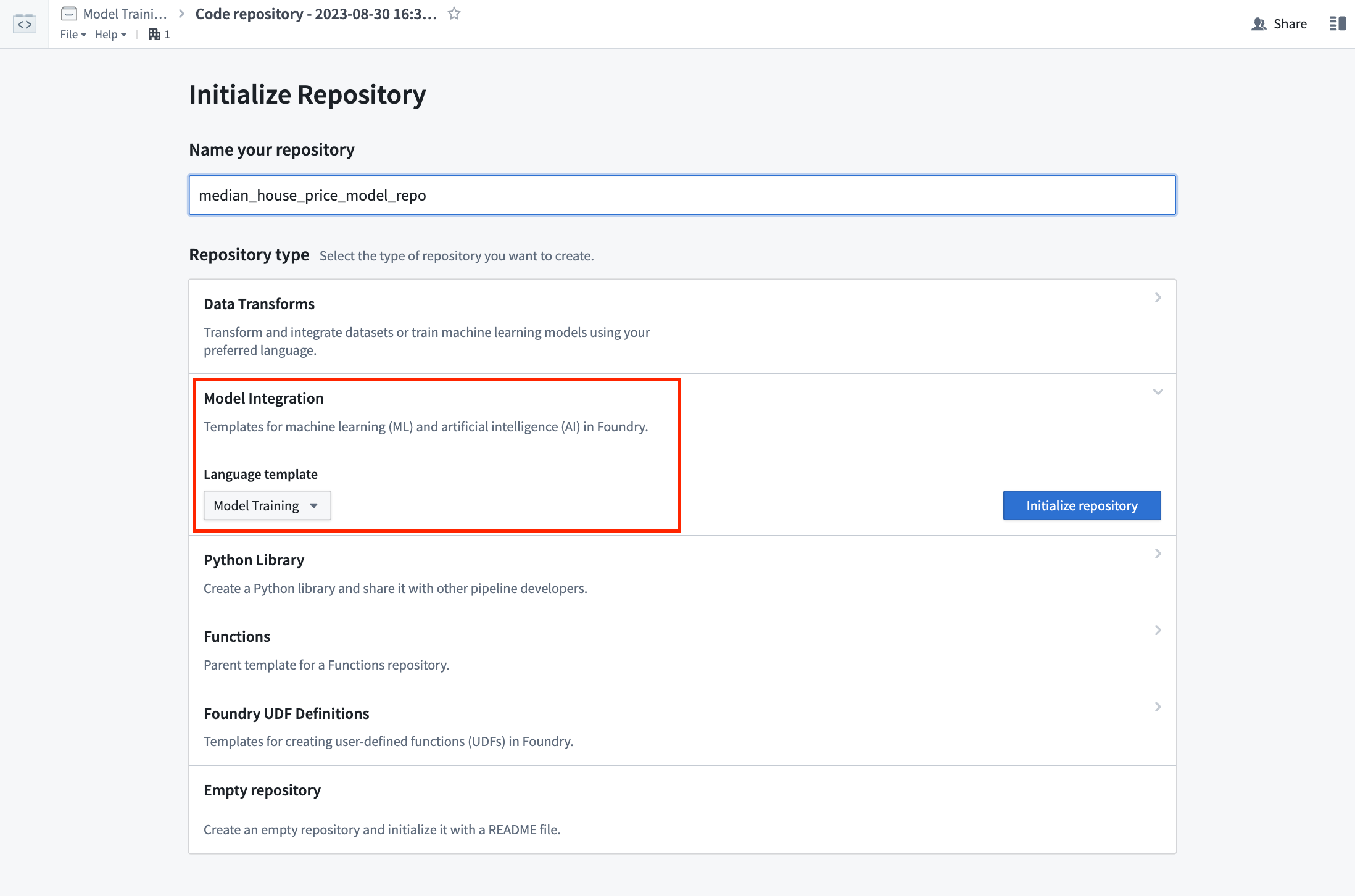
モデル学習テンプレートには、このチュートリアルに適応させる例の構造が含まれています。 左側にあるファイルを展開すると、例のプロジェクトが表示されます。
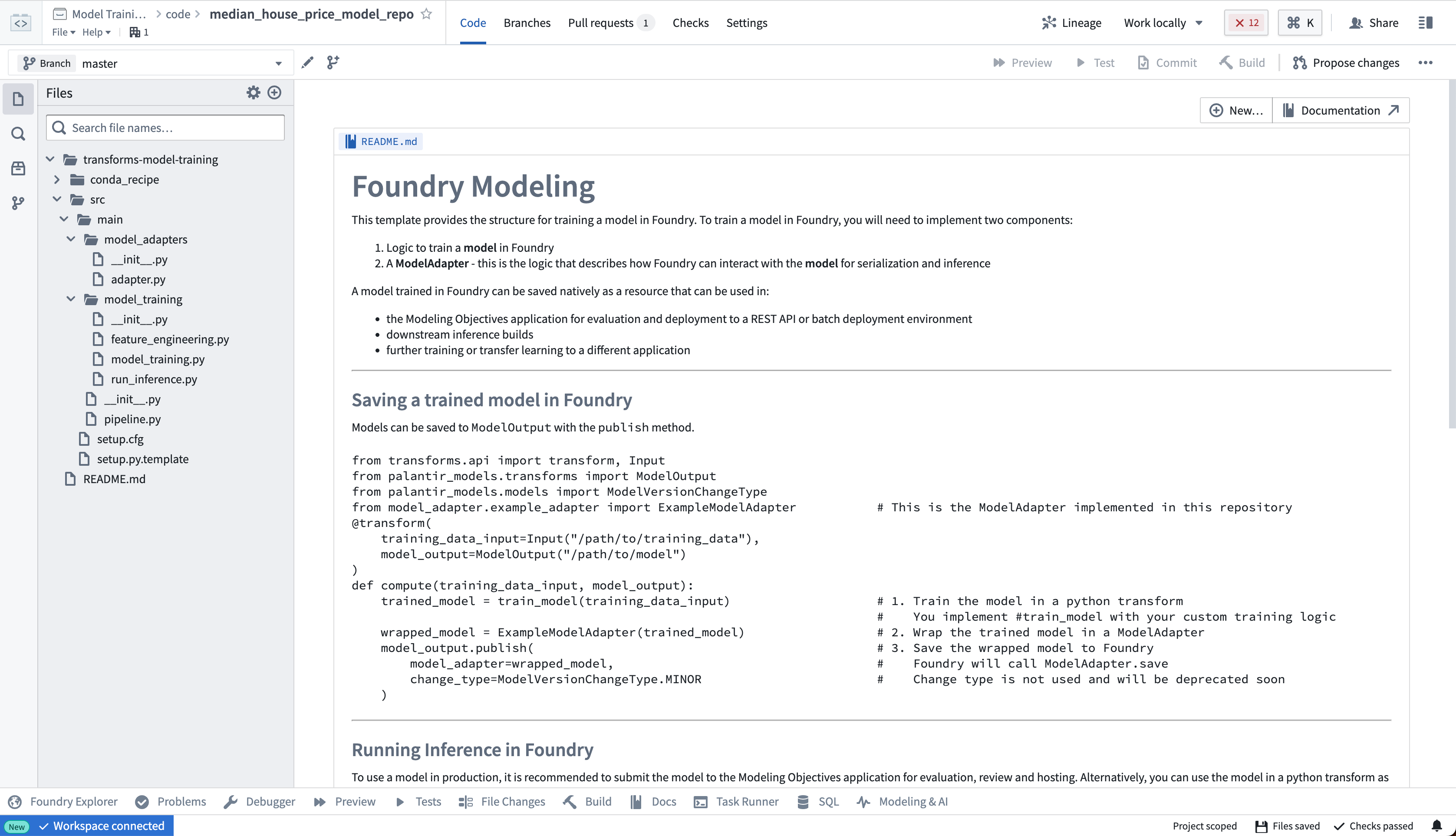
2b.2 テストと学習用の機能データを分割する方法
教師あり機械学習プロジェクトの最初のステップは、ラベル付きの特徴データを学習用とテスト用の別々のデータセットに分割することです。 最終的には、新しいデータに対するモデルのパフォーマンスを測定するパフォーマンス指標を作成し、このモデルが本番環境で使用するのに十分に良いかどうかを判断し、他の関係者とこのモデルの結果をどれだけ信頼するかを伝えるために使用します。 この検証のために別のデータを使用する必要があります。これにより、パフォーマンス指標が現実世界で見られるものを代表していることが確認できます。
そのため、ラベル付きの特徴データを入力として、それを学習用とテスト用の2つのデータセットに分割する Python トランスフォーム を記述します。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21from transforms.api import transform, Input, Output # トランスフォーム(データの変換や加工)機能を利用します @transform( # 入力データとして、特徴量とラベルを含むデータを指定します features_and_labels_input=Input("<YOUR_PROJECT_PATH>/data/housing_features_and_labels"), # 出力データとして、学習用データを指定します training_output=Output("<YOUR_PROJECT_PATH>/data/housing_training_data"), # 出力データとして、テスト用データを指定します testing_output=Output("<YOUR_PROJECT_PATH>/data/housing_test_data"), ) def compute(features_and_labels_input, training_output, testing_output): # TransformInputをPySparkのDataFrameに変換します features_and_labels = features_and_labels_input.dataframe() # データフレームをランダムに分割し、80%を学習用データ、20%をテスト用データとします training_data, testing_data = features_and_labels.randomSplit([0.8, 0.2], seed=0) # 学習用データとテスト用データをFoundryに書き戻します training_output.write_dataframe(training_data) testing_output.write_dataframe(testing_data)
アクション:リポジトリ内の feature_engineering.py ファイルを開き、上記のコードをリポジトリにコピーします。このチュートリアルの前のステップでアップロードしたデータセットを正しく指すようにパスを更新します。左上の Build を選択してコードを実行します。オプションで、データのサブセットでこのロジックをテストするために Preview を選択し、より速く反復処理を行うことができます。
このビルドが実行されている間に、2b.3 を続行できます。
2b.3 コードリポジトリでモデルトレーニングロジックを作成する方法
Foundry のモデルは、モデル作成物(モデルトレーニングジョブで生成されるモデルファイル)とモデルアダプタ(Foundryが推論を行うためにモデル作成物とどのようにやり取りするかを説明するPythonクラス)の2つのコンポーネントで構成されています。
モデルトレーニングテンプレートは、トレーニングジョブ用の model_training とモデルアダプタ用の model_adapters の2つのモジュールで構成されています。
モデルの依存関係
モデルのトレーニングには、ほとんどの場合、モデルのトレーニング、シリアル化、推論、または評価ロジックを含むPythonの依存関係の追加が必要になります。Foundryは、condaを通じて依存関係の仕様を追加することをサポートしています。これらの依存関係の仕様は、モデルトレーニングジョブの実行のための解決されたPython環境の作成に使用されます。
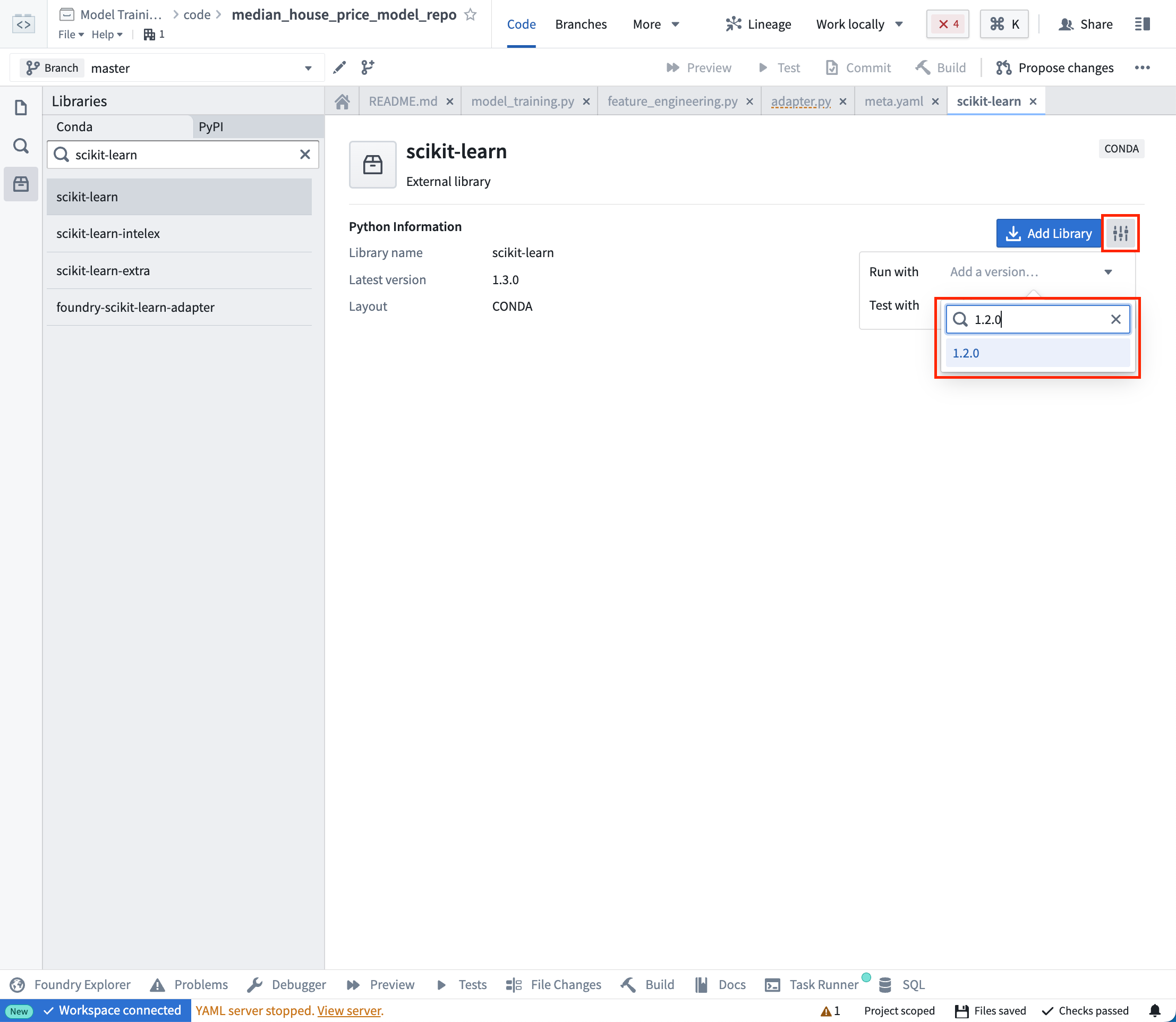
Foundryでは、これらの解決された依存関係は自動的にユーザーのモデルと一緒にパッケージ化され、モデルが推論(予測の生成)を行うために必要なすべてのロジックを自動的に持つことが保証されます。この例では、モデルの生成と保存のために pandas と scikit-learn を使用し、モデルを保存するために dill を使用します。
アクション:左側のバーで Libraries を選択し、scikit-learn = 1.2.0、pandas = 1.5.2、dill = 0.3.7 の依存関係を追加します。その後、Commit を選択して解決されたPython環境を作成します。
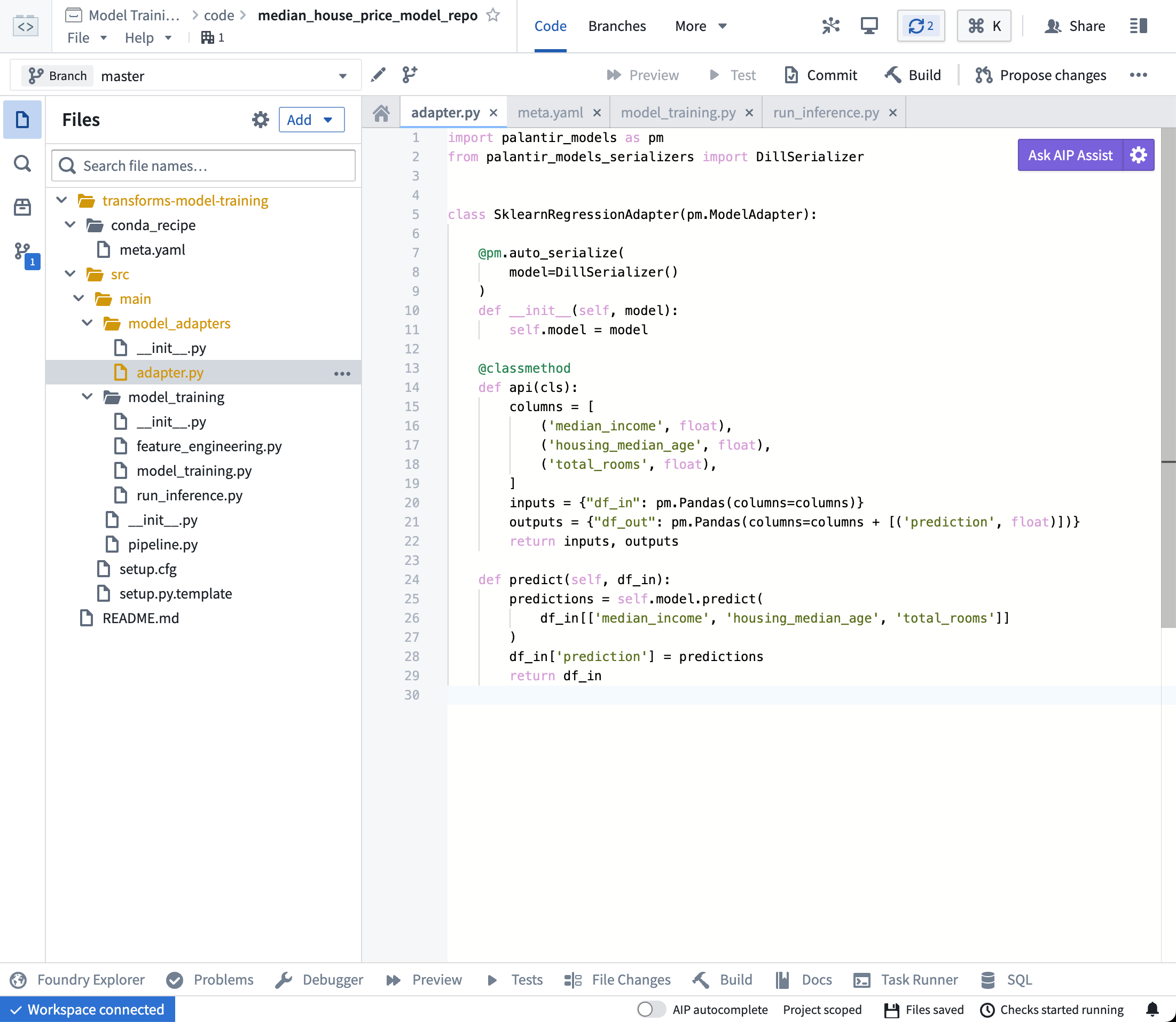
モデルアダプタロジック
モデルアダプタは、Foundry内のすべてのモデルに対する標準的なインターフェースを提供します。この標準インターフェースにより、すべてのモデルがすぐに本番環境のアプリケーションで使用できるようになり、Foundryがモデルのロード、Python依存関係、APIの公開、モデルとのインターフェース処理を担当します。
これを実現するために、この通信層として機能する ModelAdapter クラスのインスタンスを作成する必要があります。
実装すべきは以下の4つの関数です:
- モデルの保存とロード:モデルを再利用するためには、モデルの保存とロード方法を定義する必要があります。Palantirは、シリアル化(保存)のデフォルトの方法を多数提供しており、より複雑なケースでは、カスタムシリアル化のロジックを実装できます。
- api:モデルのAPIを定義し、モデルが必要とする入力データのタイプをFoundryに伝えます。
- predict:Foundryからデータを提供するように呼び出され、モデルに入力データを渡して推論(予測)を生成する場所です。
アクション
model_adapters/adapter.pyファイルを開き、上記のロジックをファイルに貼り付けます。
モデル訓練ロジック
依存関係が設定され、モデルアダプターが記述されたので、Foundry でモデルを訓練できます。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52from transforms.api import transform, Input from palantir_models.transforms import ModelOutput from main.model_adapters.adapter import SklearnRegressionAdapter @transform( training_data_input=Input("<YOUR_PROJECT_PATH>/data/housing_training_data"), model_output=ModelOutput("<YOUR_PROJECT_PATH>/models/linear_regression_model"), ) def compute(training_data_input, model_output): training_df = training_data_input.pandas() model = train_model(training_df) # 訓練済みのモデルをModelAdapterにラップする foundry_model = SklearnRegressionAdapter(model) # 訓練済みのモデルをFoundryに公開し、書き込む model_output.publish( model_adapter=foundry_model ) def train_model(training_df): from sklearn.impute import SimpleImputer from sklearn.linear_model import LinearRegression from sklearn.pipeline import Pipeline from sklearn.preprocessing import StandardScaler # 数値特徴量を定義 numeric_features = ['median_income', 'housing_median_age', 'total_rooms'] # 数値特徴量の前処理パイプラインを定義(欠損値補完とスケーリング) numeric_transformer = Pipeline( steps=[ ("imputer", SimpleImputer(strategy="median")), ("scaler", StandardScaler()) ] ) # モデル全体のパイプラインを定義(前処理と分類器) model = Pipeline( steps=[ ("preprocessor", numeric_transformer), ("classifier", LinearRegression()) ] ) # 訓練データを定義 X_train = training_df[numeric_features] y_train = training_df['median_house_value'] # モデルの訓練 model.fit(X_train, y_train) return model
オプション: モデルのトレーニングとモデルアダプタのロジックを繰り返し行う際には、ビルドを実行する前にトレーニングデータの一部で変更をテストすると便利です。左上の Preview を選択してコードをテストします。
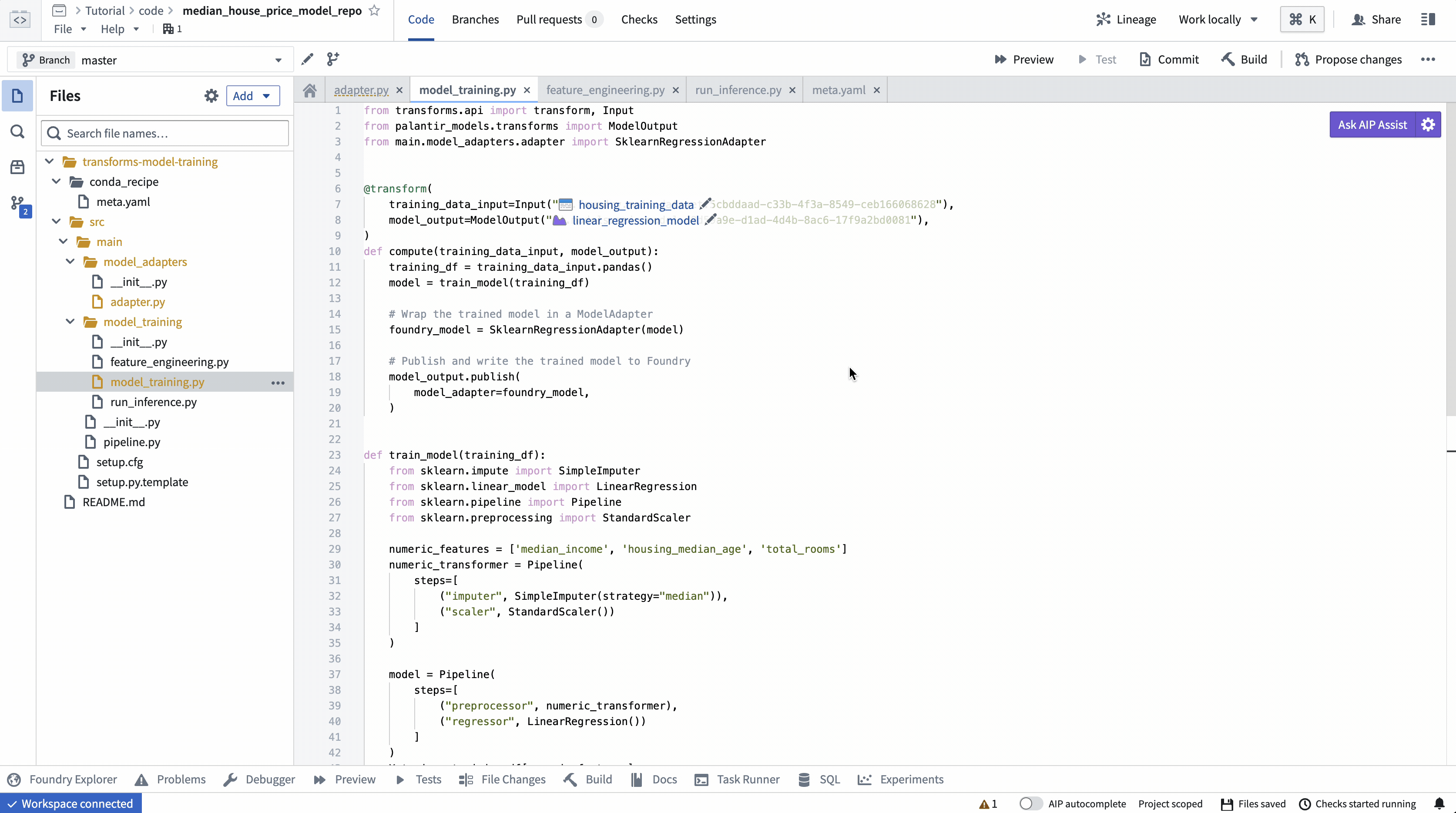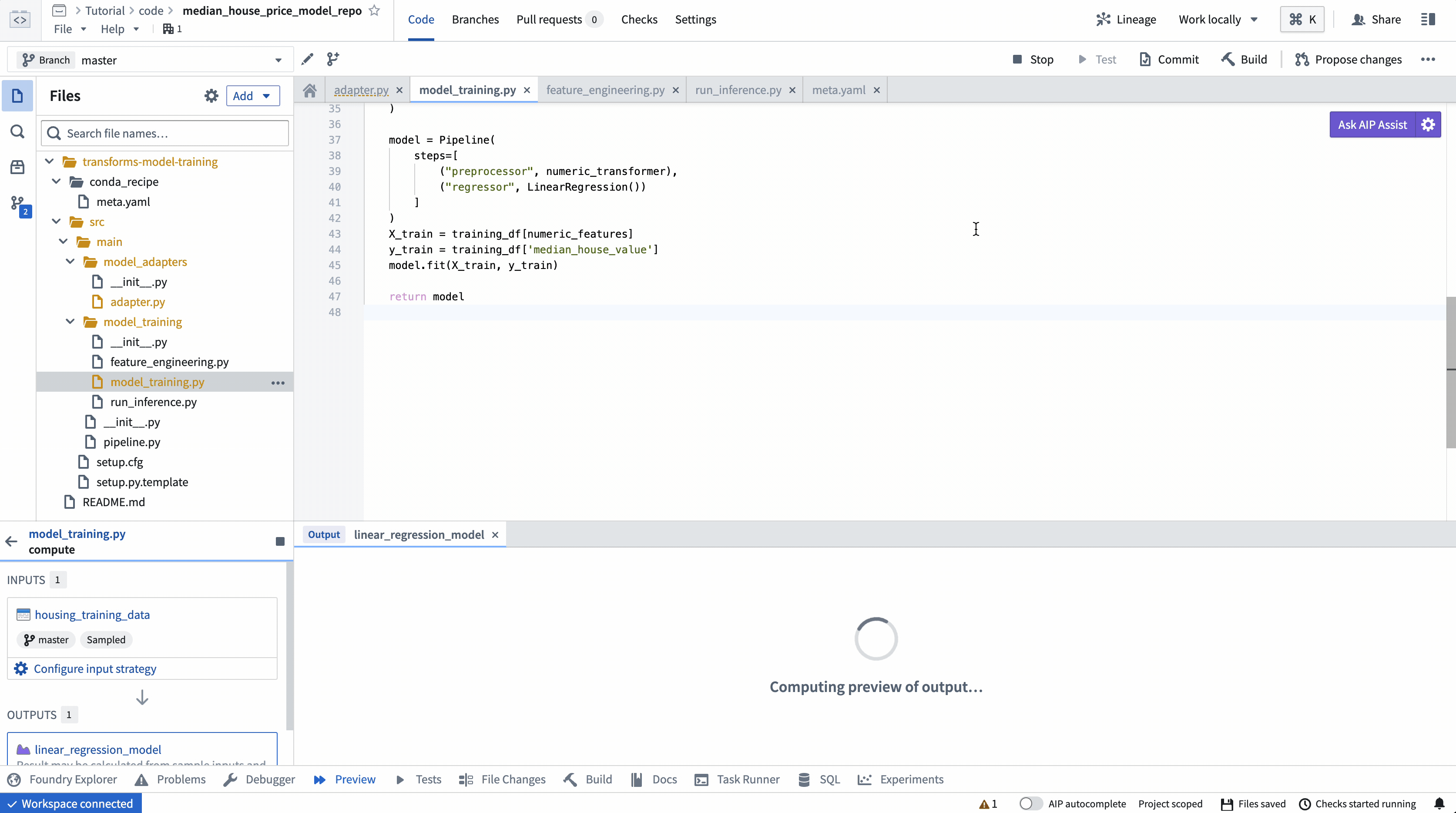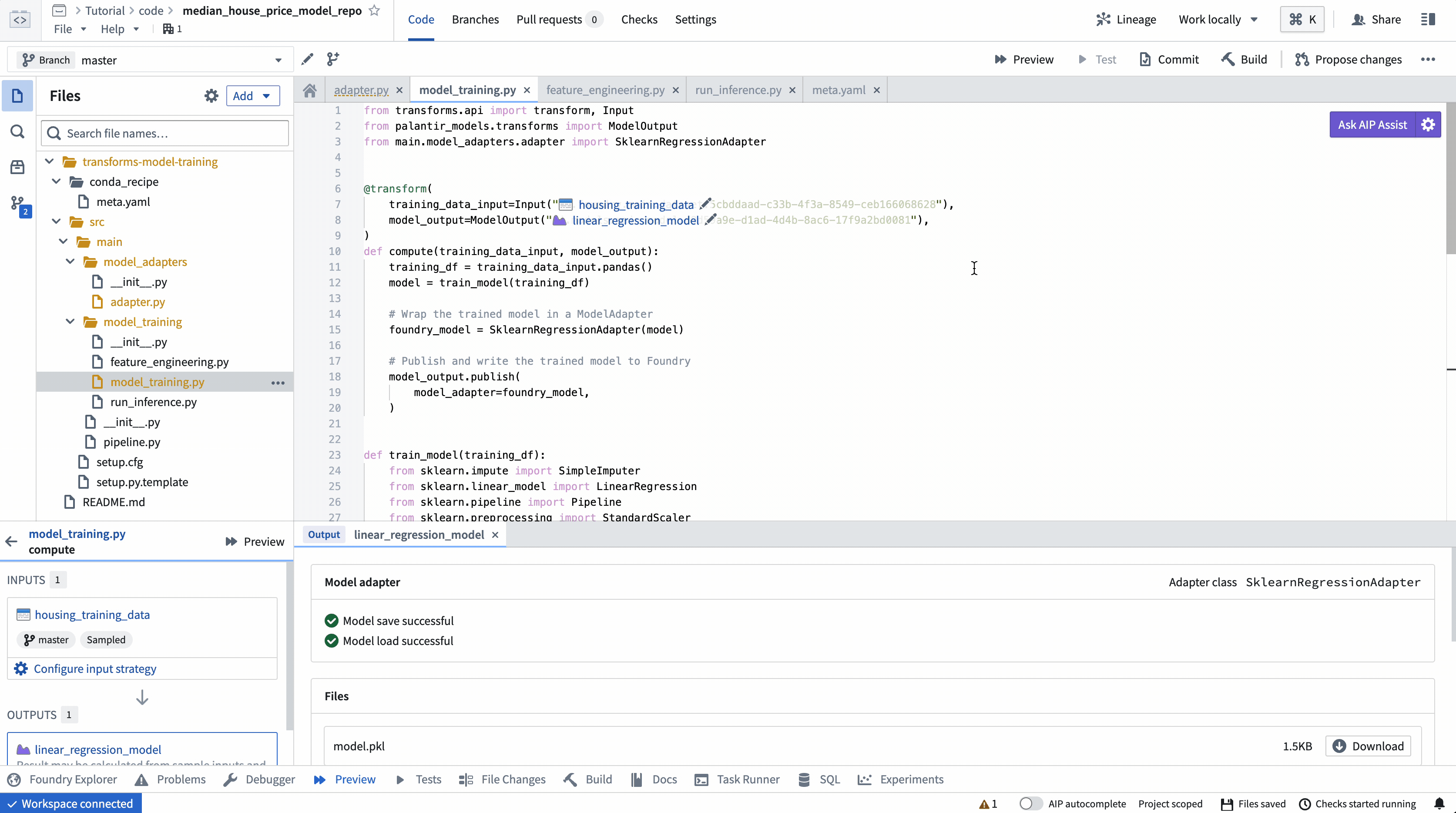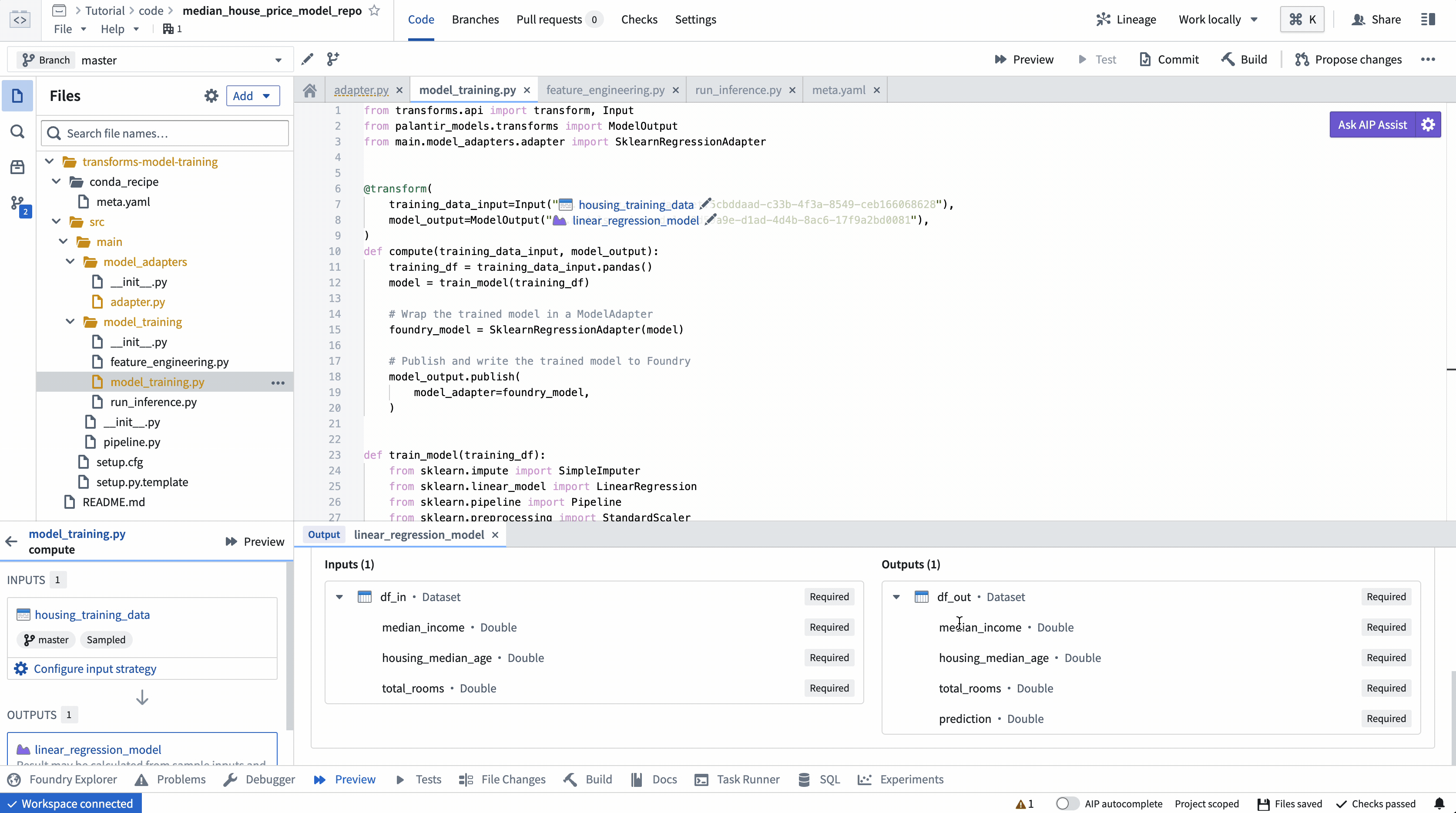
アクション: リポジトリの model_training/model_training.py ファイルを開き、上記のコードをリポジトリにコピーします。トレーニングデータセットとステップ 1.1で作成したモデルフォルダーを正しく指すようにパスを更新します。左上の Build を選択してコードを実行します。
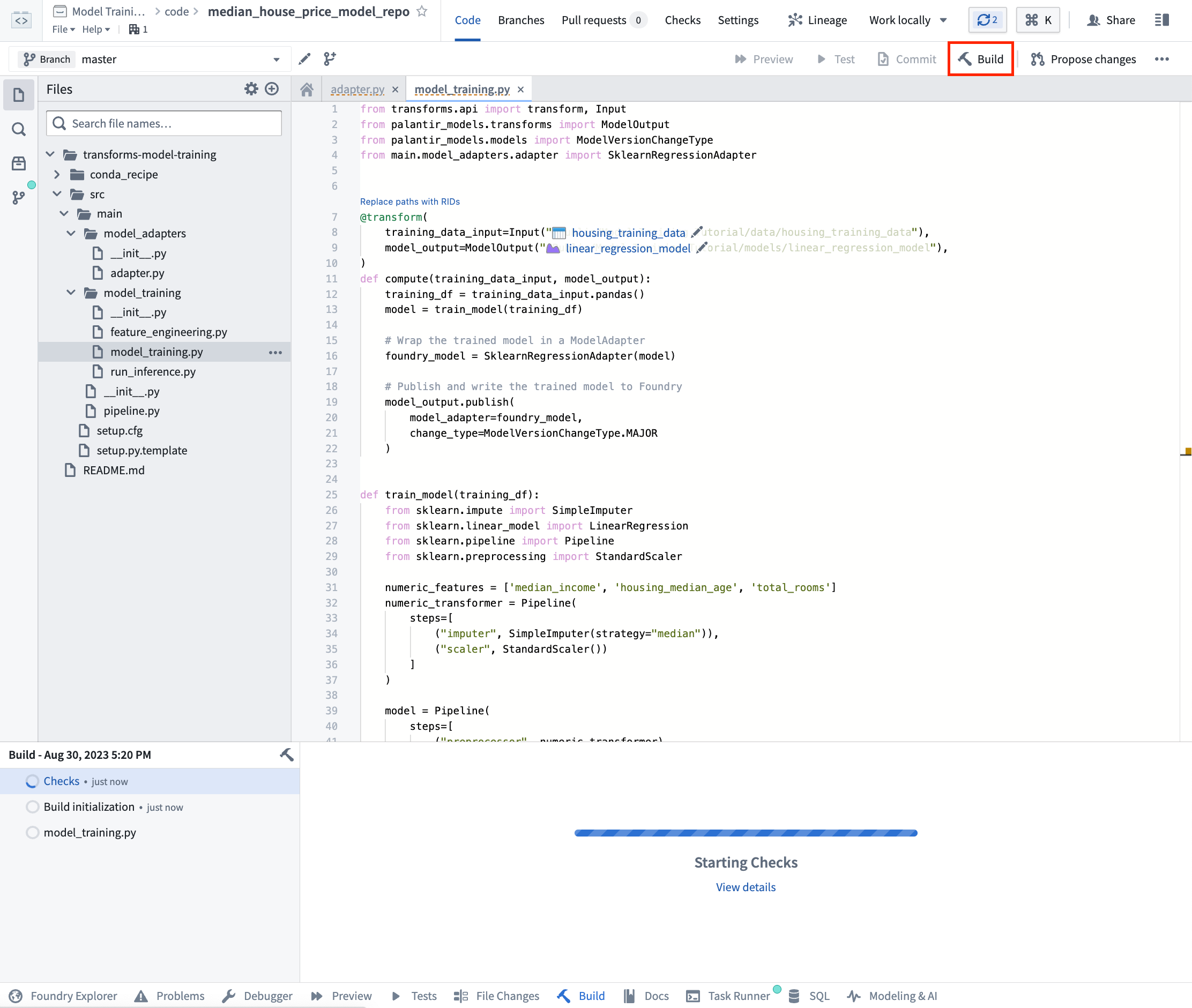
2b.4 コードリポジトリで推論ロジックをテストする方法
モデルのトレーニングロジックが終了したら、コードリポジトリ内で直接予測(別名: 推論)を生成することができます。
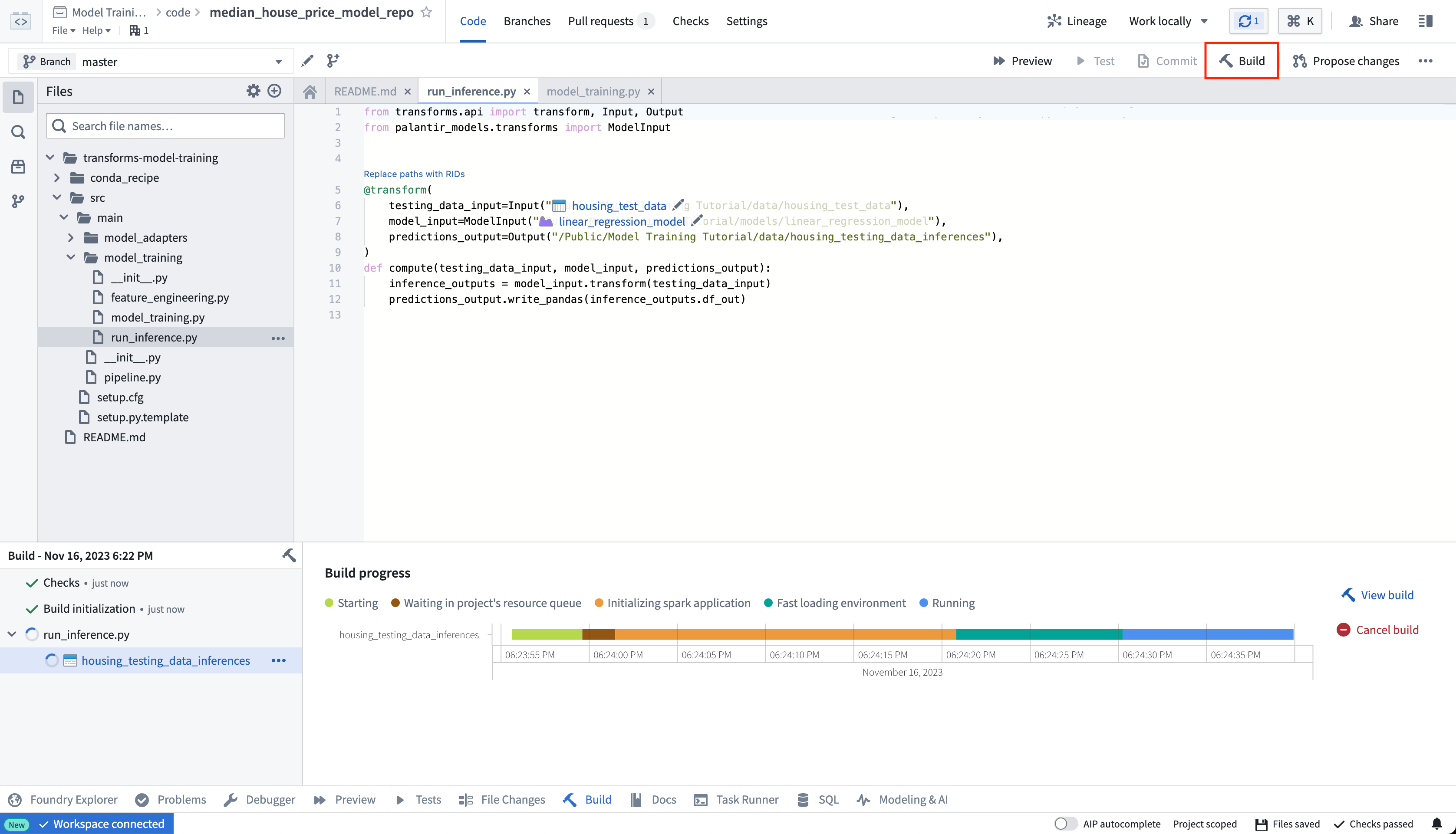
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20# transformsとpalantir_modelsから必要なものをインポートします。 from transforms.api import transform, Input, Output from palantir_models.transforms import ModelInput # 以下の関数は、モデルを使って新しいデータに対する予測を計算します。 # 入力として、テストデータとモデルが必要です。 # 出力として、予測結果が必要です。 @transform( # テストデータのパスを指定します。 testing_data_input=Input("<YOUR_PROJECT_PATH>/data/housing_test_data"), # 使用するモデルのパスを指定します。 model_input=ModelInput("<YOUR_PROJECT_PATH>/models/linear_regression_model"), # 予測結果を保存するパスを指定します。 predictions_output=Output("<YOUR_PROJECT_PATH>/data/housing_testing_data_inferences") ) def compute(testing_data_input, model_input, predictions_output): # モデルを使ってテストデータに対する予測を計算します。 inference_outputs = model_input.transform(testing_data_input) # 予測結果を指定したパスに保存します。 predictions_output.write_pandas(inference_outputs.df_out)
アクション: リポジトリ内の model_training/run_inference.py ファイルを開き、上記のコードをリポジトリにコピーします。 以前に作成したモデルアセットとテストデータセットを正確に指すようにパスを更新します。 左上にある**[Build]** を選択してコードを実行します。
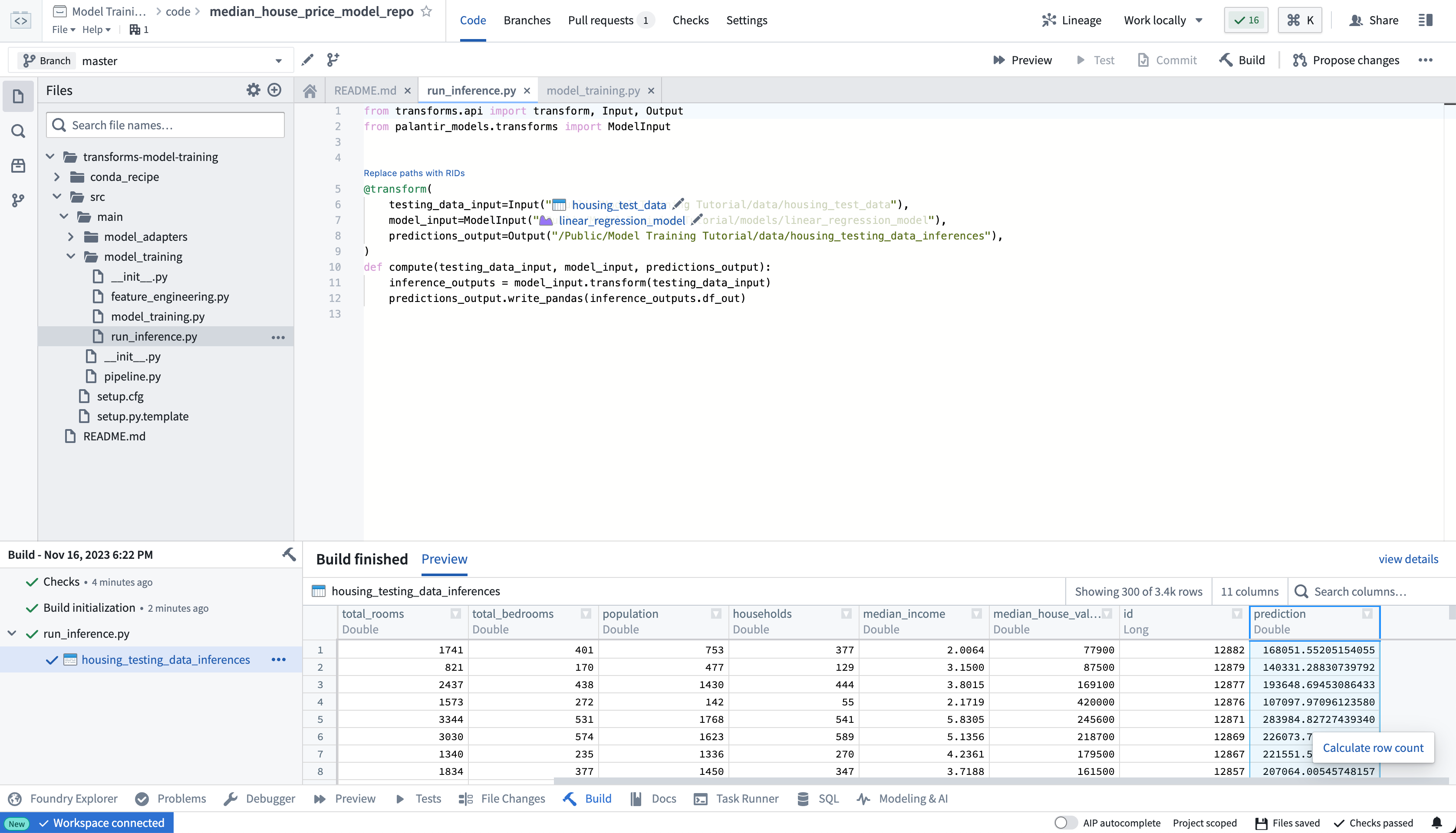
ビルドが完了すると、ビルド出力パネルで生成された予測を確認できます。
2a.5 オプション: ライブ予測の設定
オプションとして、このモデルは直接デプロイメントにより REST API として使用できます。直接デプロイの設定方法についてはこちらを参照してください。
2b.6 モデルの表示とModeling Objectivesへの送信方法
モデルが構築されたら、model_training/model_training.pyファイルでlinear_regression_modelを選択するか、または以前に作成したフォルダー構造でモデルに移動することで、モデルを開くことができます。
モデルビューには、モデルがトレーニングされたソース、このモデルを生成するために使用されたトレーニングデータセット、モデルAPI、およびこのモデルが公開されたモデルアダプターがあります。重要なのは、同じモデルに多くの異なるバージョンを公開できることです。これらのモデルバージョンは、左サイドバーのドロップダウンメニューで利用できます。
モデルバージョンはトレーニング時に使用された特定のモデルアダプターに関連付けられているため、モデルアダプターのロジックに変更を加える場合は、モデルのトレーニングプロセスを再公開して構築する必要があります。
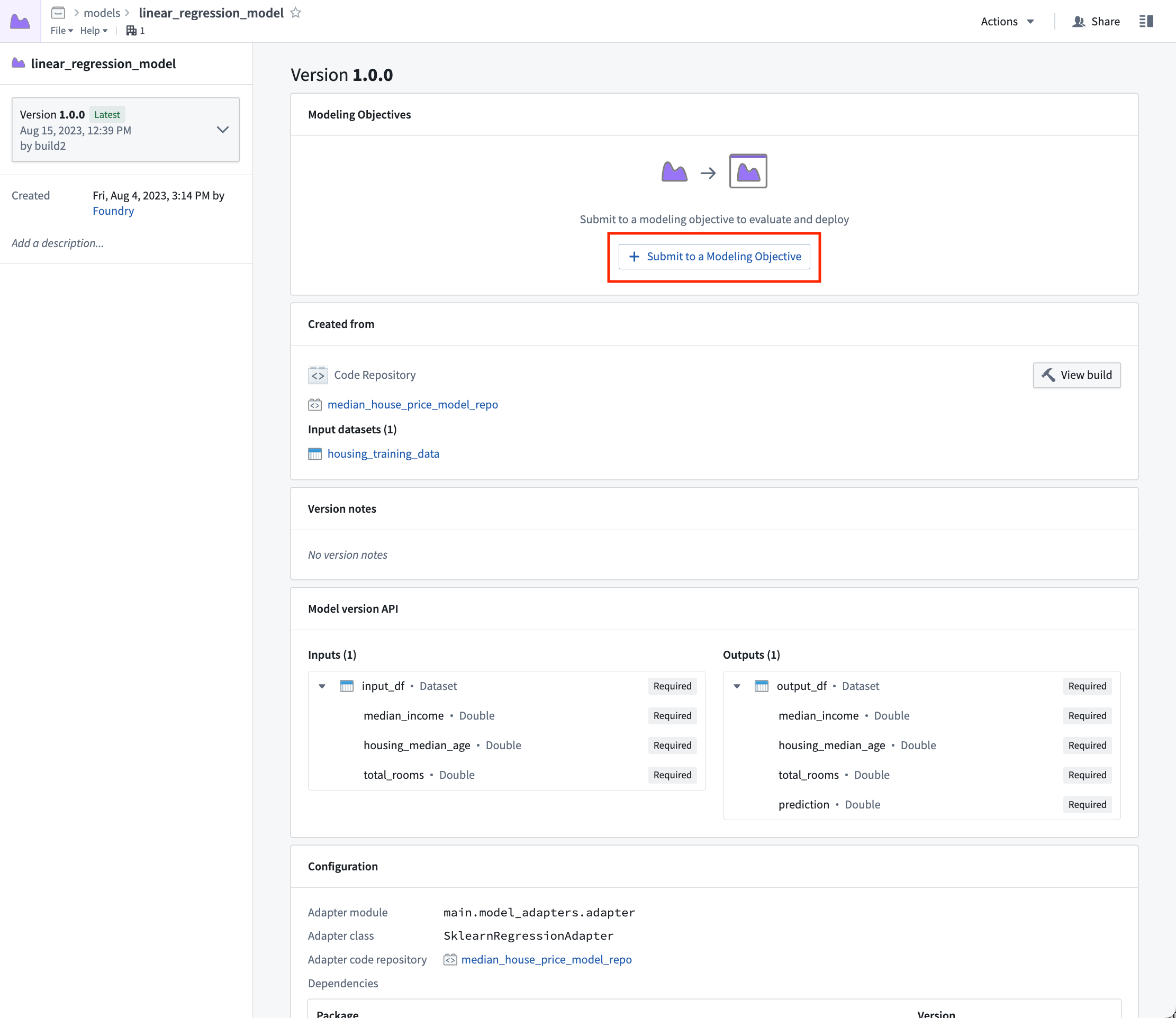
モデルが作成されたので、そのモデルをモデリング目的に提出して、管理、評価、運用アプリケーションへのリリースを行うことができます。
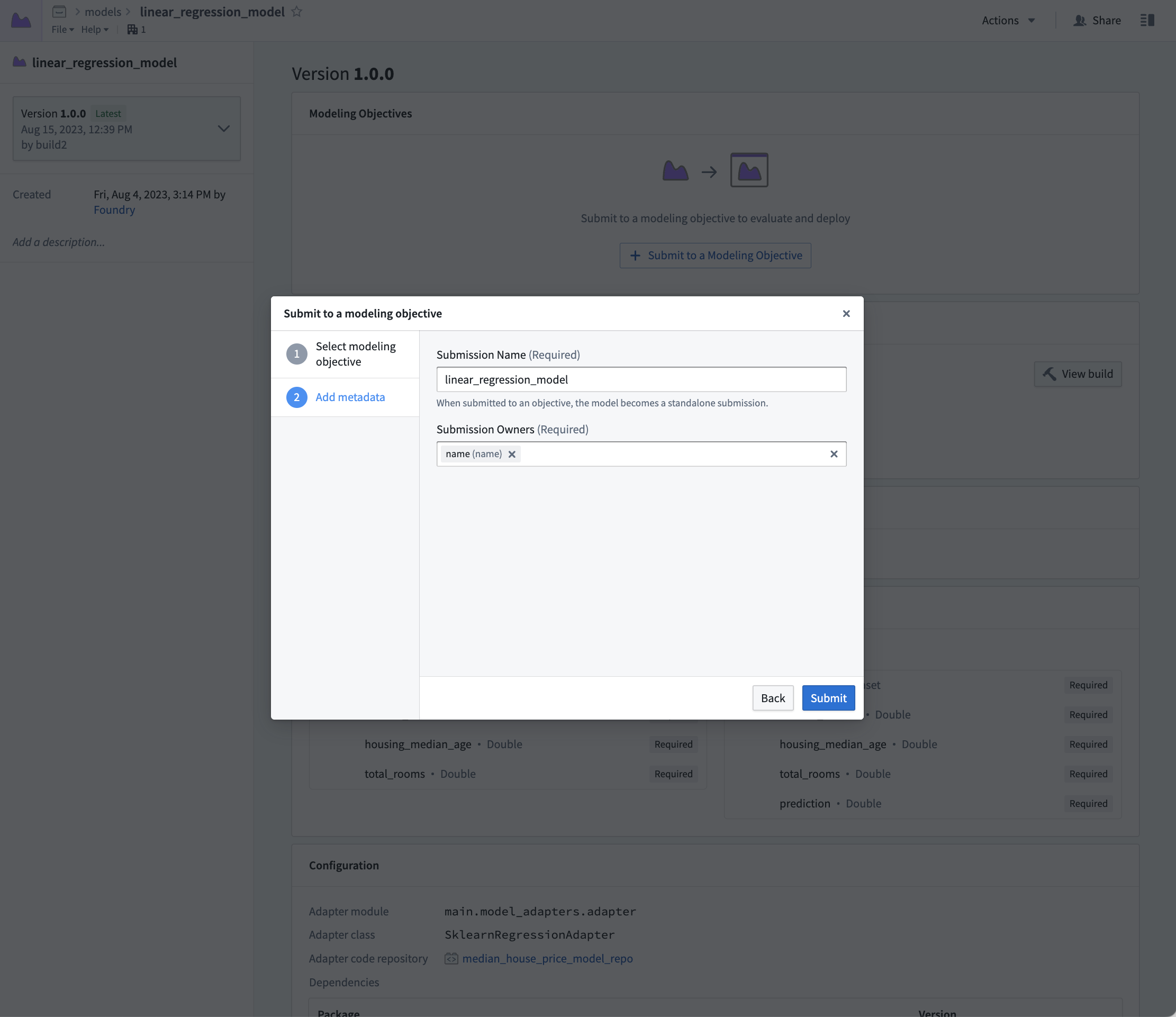
アクション: 作成したモデルアセットに移動するためにコードでlinear_regression_modelを選択し、Submit to a Modeling Objective(モデリング目的への提出)を選択して、このチュートリアルのステップ1で作成したモデリング目的にそのモデルを提出します。提出名と提出オーナーの指定を求められます。これは、モデリング目的内でモデルを一意に追跡するために使用されるメタデータです。モデル名を linear_regression_model とし、提出オーナーとしてご自身をマーキングしてください。
次のステップ
これで、Foundryでモデルをトレーニングしたので、モデル管理、テスト、モデル評価に進むことができます。Modeling Objectivesで実行できる追加ステップの例を以下に示します。
- 自動モデル評価
- モデル提出のチェックの設定
- ライブ と バッチ推論 も、Modeling Objective から設定できます。
オプションとして、Code Workspaces アプリケーションを使用して Jupyter® ノートブックでモデルをトレーニング して、高速かつ反復的なモデル開発を行うこともできます。