注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
1. チュートリアル - Foundryで機械学習プロジェクトを設定する
このチュートリアルのステップでは、Foundryで機械学習プロジェクトを作成します。このステップは必須であり、以下の内容をカバーします:
1.1 Foundryプロジェクトを機械学習用に構造化する方法
Foundryプロジェクトは、関連する作業を保存するためのフォルダ構造です。各機械学習プロジェクトに個別のFoundryプロジェクトを持つことをお勧めします。このプロジェクトには以下のものが含まれている必要があります:
- このプロジェクトで使用されるデータセットを保存するための
dataフォルダ、 - このプロジェクトのモデルを保存するための
modelsフォルダ、 - このプロジェクトで使用されるモデルのトレーニングロジックを保存するための
codeフォルダ、 - 本番モデルを管理およびデプロイするためのモデリングオブジェクティブ。
新しいプロジェクトを作成する権限がない場合は、既存のプロジェクトに新しいフォルダを作成して、機械学習プロジェクトのルートディレクトリとして機能させることができます。
アクション: このチュートリアルのために新しいFoundryプロジェクトを作成し、上記のフォルダを作成します - 方法を見る。新しいFoundryプロジェクトを作成できない場合は、既存のプロジェクトに空のフォルダを作成して、新しいプロジェクトのルートを模倣します。
アクション: Foundryプロジェクトで、+新規 > モデリングオブジェクティブ を選択します。モデリングオブジェクティブは、解決しようとしている機械学習問題の名前に関連して命名する必要があります。この場合、オブジェクティブの名前を「House Price Prediction Objective」とします。
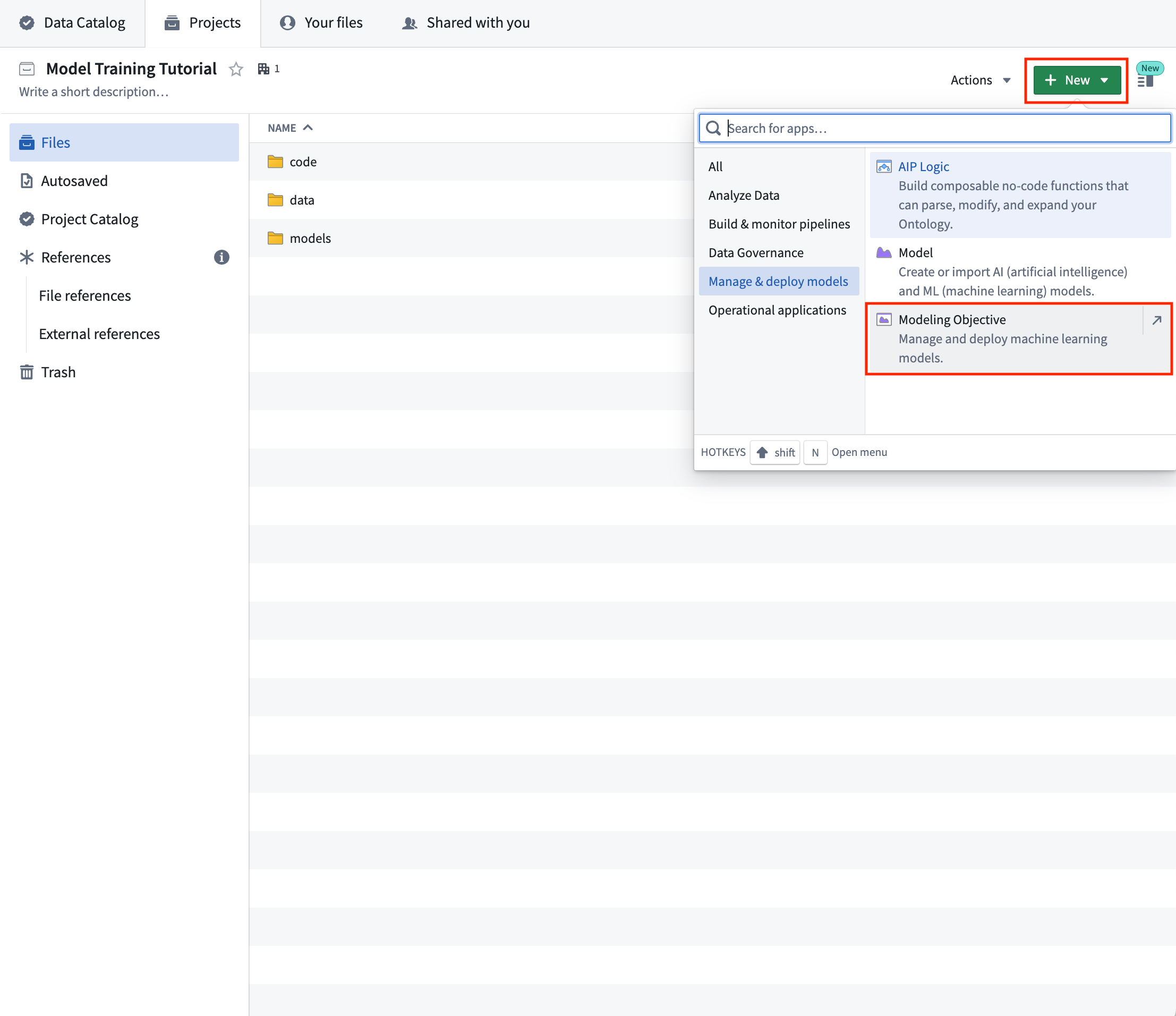
完成したプロジェクト構造
1.2 機械学習のためのデータを管理する方法
このチュートリアルでは、アメリカの国勢調査地区の中央値の住宅価格を推定する機械学習モデルを構築します。
フィーチャーデータ(アメリカの国勢調査地区に関する過去の詳細)とラベル(その時点でのその国勢調査地区の中央値の住宅価格)を使用して、フィーチャーとラベルの関係を明らかにし、その関係をFoundryで再利用可能なモデルとして保存します。将来、最新のフィーチャーデータ(アメリカの国勢調査地区に関する詳細)があるが、最新のラベル(中央値の住宅価格)がない場合、国勢調査地区のフィーチャーデータにモデルを適用して、その国勢調査地区の住宅価格の推定値を見つけることができます。このタイプの機械学習プロジェクトは、教師あり機械学習と呼ばれ、最も一般的な機械学習プロジェクトのタイプです。
Foundryでは、教師あり機械学習プロジェクトには2つのデータセットが必要です:
- モデルのトレーニングとテストに使用できるラベル付きデータセット、
- 最新のフィーチャーを含むがラベルがないラベルなしデータセット。このデータセットにモデルを適用して、ラベルの推定(予測)を生成します。
これらのデータセットは、多くの場合、本番ソースへのデータ接続やオントロジーから来ます。しかし、このチュートリアルでは、これらの本番ソースをシミュレートするためにCSVファイルをアップロードします。
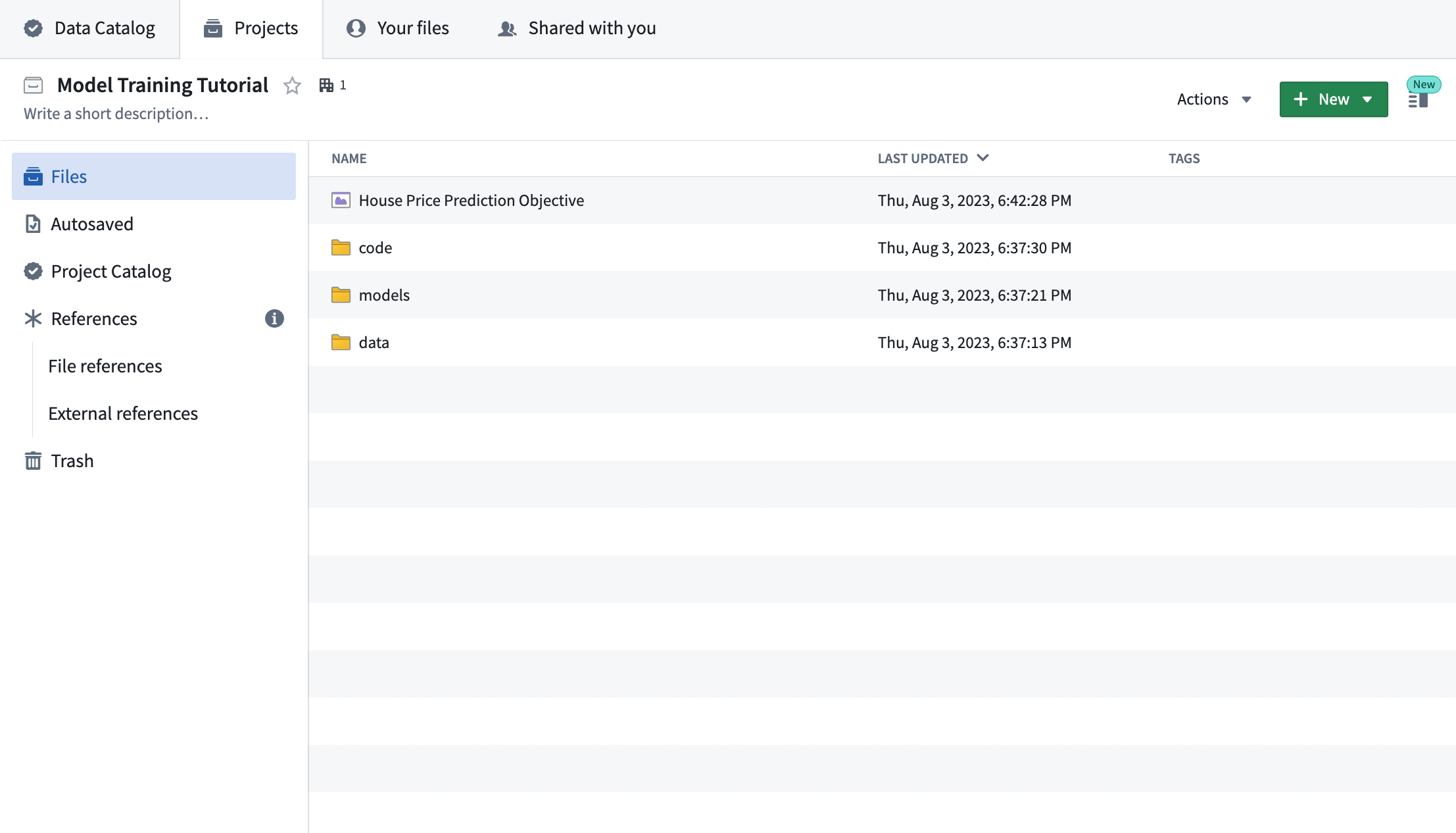
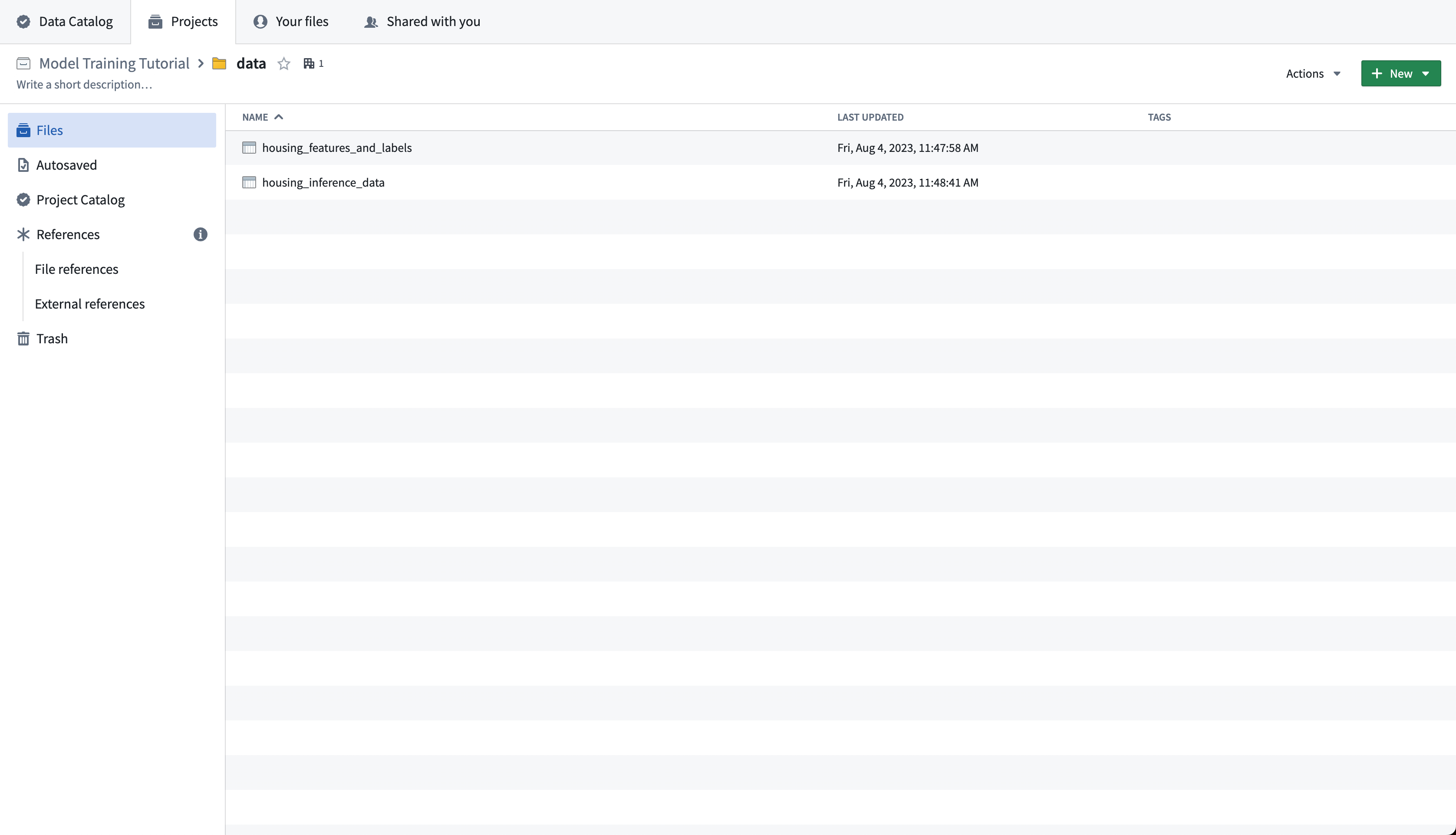
アクション: ラベル付きアメリカ住宅データソースをダウンロードし、data フォルダに housing_features_and_labels としてアップロードします。ラベルなしアメリカ国勢調査データソースをダウンロードし、data フォルダに housing_inference_data としてアップロードします。CSVファイルをFoundryにアップロードするには、フォルダ構造にドラッグアンドドロップします - このチュートリアルでは、構造化データセットとしてアップロードします。
完成したデータフォルダ
1.3 機械学習モデルを管理する方法
Foundryでトレーニングされたモデルは、それらをトレーニングするために使用されたデータ、コード、および開発環境にリンクされています。これは、すべてのモデルがどのように生成されたかの管理された記録を提供し、過去の実験の詳細を記録および共有するのに役立ちます。
機械学習モデルは、FoundryのCode Repositoriesアプリケーションでトレーニングできます。
Code Repositories
Code Repositoriesアプリケーションは、データパイプラインや機械学習ロジックを作成するためのWebベースの開発環境です。Foundryには、Model Training テンプレートと呼ばれる機械学習用のテンプレートリポジトリが提供されています。
Code Repositoriesはローカルコードの反復作業のためにGitをサポートしていますが、Foundry内でビルドを実行するためにはコミットされたコードが必要です。Code Repositoriesアプリケーションは、本番グレードのデータパイプラインや機械学習ロジックを作成するのに最適です。
既存のモデルを統合する
既に使用したいモデルがある場合は、次の方法で既存のモデルを統合できます:
Foundryは、モデリングオブジェクティブアプリケーションを通じてインポートできるいくつかのオープンソースの言語モデルも提供しています。
このチュートリアルのこのステップには必須のアクションはありません。
1.4 機械学習プロジェクトを管理する方法
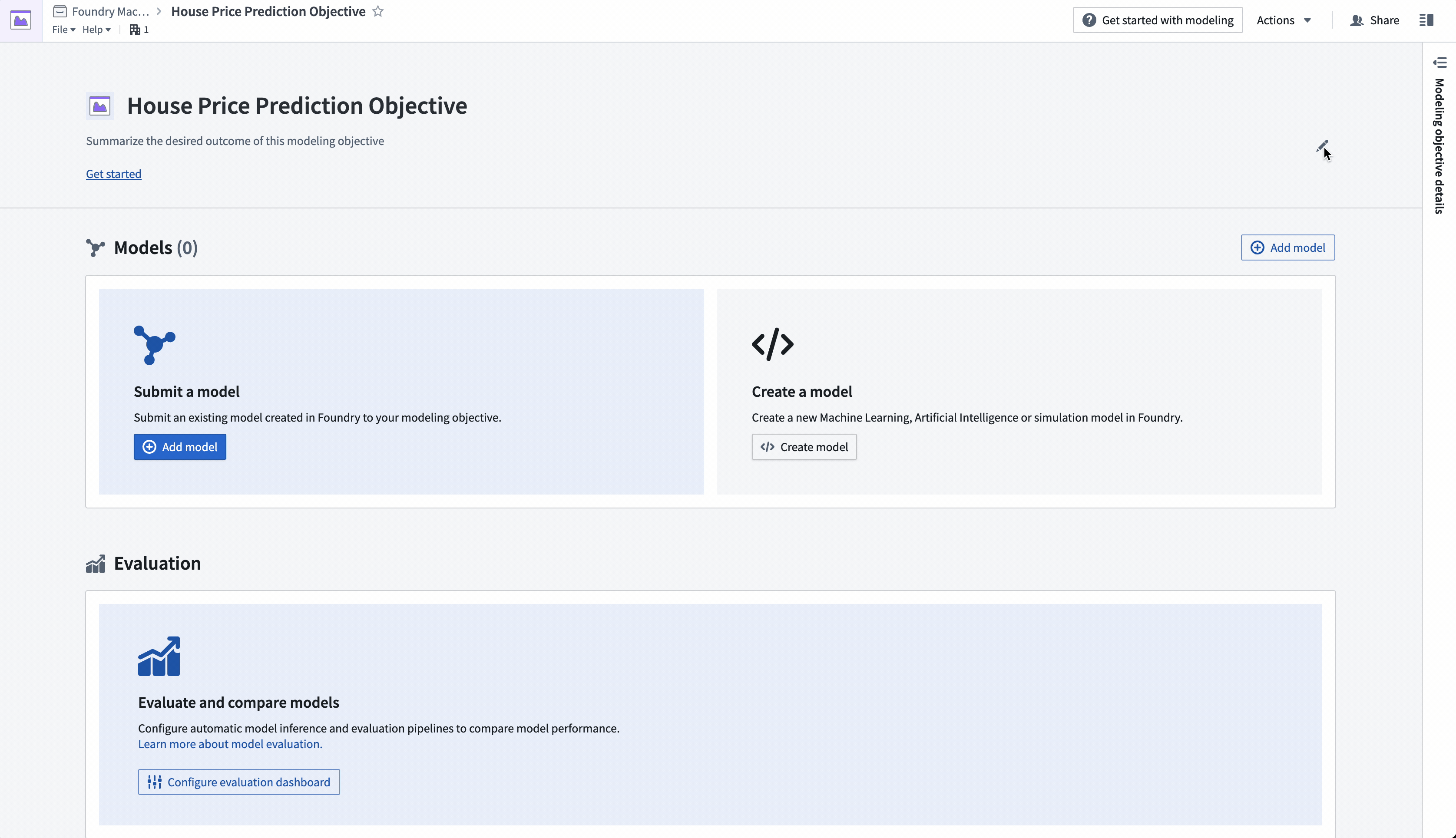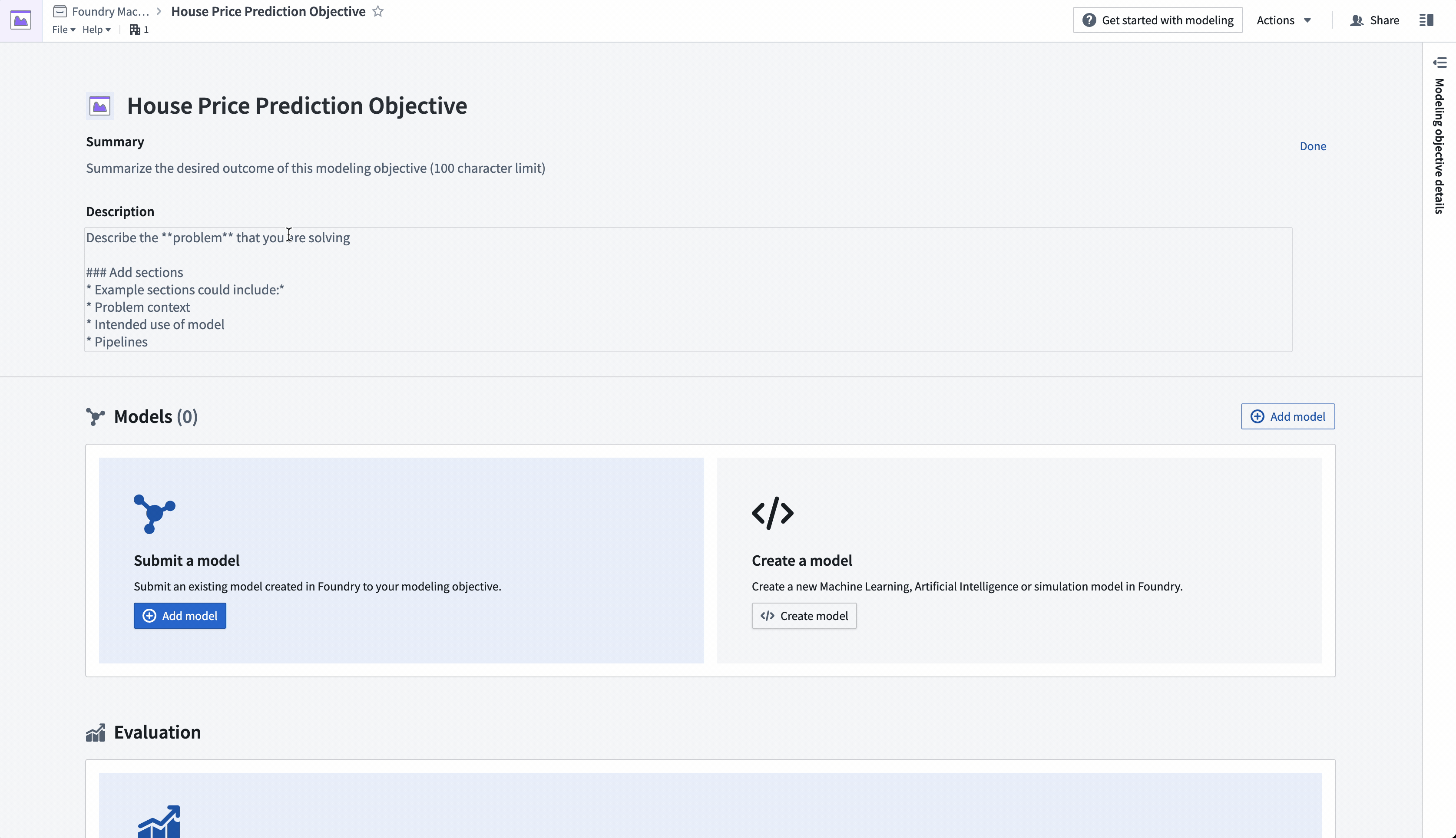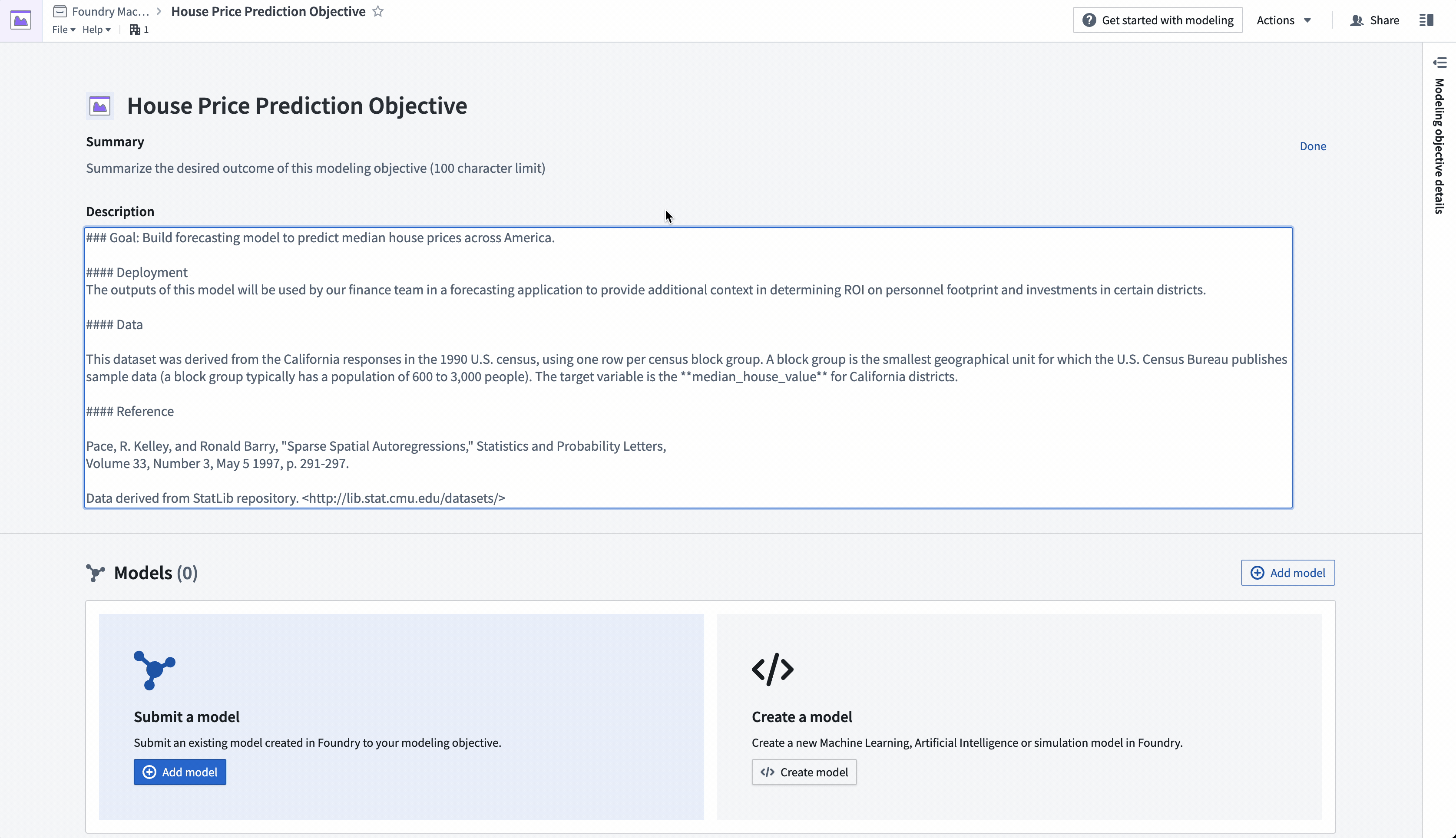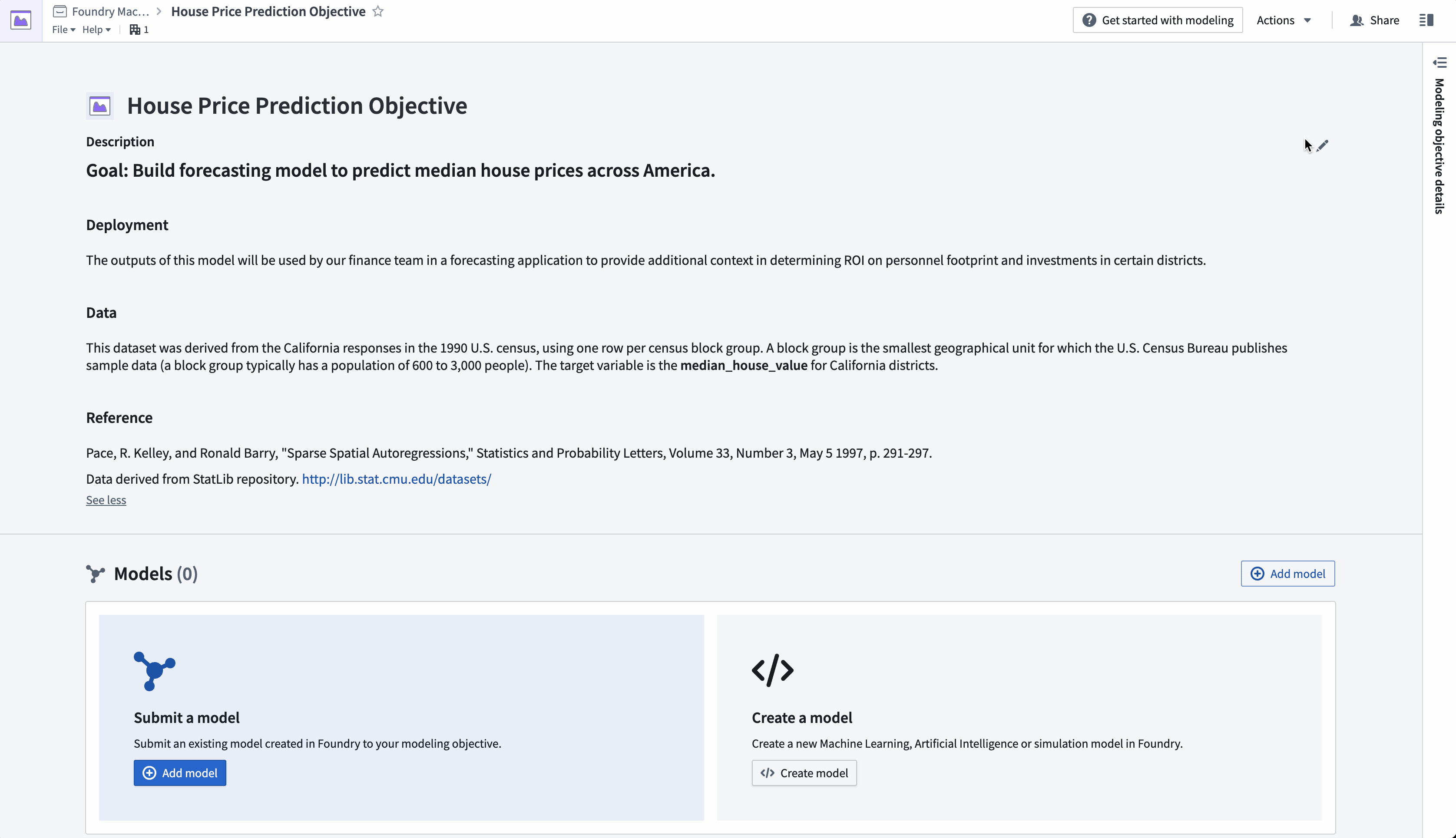
Foundryでは、機械学習プロジェクトはモデリングオブジェクティブアプリケーションで管理されます。モデリングオブジェクティブは、次の方法で機械学習プロジェクトの管理にベストプラクティスを提案します:
- 特定の問題に焦点を当てた機械学習プロジェクトを指向する
- システマティックなモデル評価の標準を作成する
- 本番使用前にモデルの多方面レビューを可能にする
- 本番で使用されたすべてのモデルの履歴記録を維持する
- バッチパイプラインやリアルタイムホスト推論にモデル開発を統合する
このチュートリアルでは、モデリングオブジェクティブは国勢調査地区の中央値の住宅価格を予測することです。
アクション: 以前に作成した "House Price Prediction Objective" モデリングオブジェクティブに移動します。モデリングオブジェクティブのヘッダー部分にプロジェクトのコンテキストを追加して、他のチームに問題を説明します。右側のペンアイコンを選択して編集モードに入り、オブジェクティブの要約と説明を追加します。説明フィールドはMarkdownをサポートしています。推奨される内容の例は以下の通りです:
#### 目標: アメリカ全州の中央値の住宅価格を予測するモデルを構築する。
#### データ
このデータセットは、1990年の米国国勢調査のカリフォルニア州の回答に基づいており、国勢調査ブロックグループごとに1行を使用しています。ブロックグループは、米国国勢調査局がサンプルデータを公開する最小の地理単位であり(通常、ブロックグループの人口は600〜3,000人です)。
対象変数は、カリフォルニア州の地区の**median_house_value**です。
#### 参考文献
Pace, R. Kelley, and Ronald Barry, "Sparse Spatial Autoregressions," Statistics and Probability Letters,
Volume 33, Number 3, May 5 1997, p. 291-297.
データはStatLibリポジトリから取得されました。<http://lib.stat.cmu.edu/datasets/>
次のステップ
機械学習プロジェクトの構造を整えたので、次はモデルのトレーニングに進みます。このチュートリアルでは、次のステップはモデルをJupyter®ノートブックでトレーニングするか、Code Repositoriesでモデルをトレーニングするのどちらかです。Jupyter®ノートブックは迅速かつ反復的なモデル開発に推奨されますが、Code Repositoriesは本番グレードのデータおよびモデルパイプラインに推奨されます。