注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
4. チュートリアル - モデルを本番環境にデプロイする
このチュートリアルを進める前に、モデルプロジェクトのセットアップとモデルトレーニングを完了し、オプションとしてモデル評価のチュートリアルも完了していることを確認してください。この時点で、モデリングの目的に少なくとも 1 つのモデルが含まれている必要があります。
このチュートリアルのステップでは、機械学習モデルを取り、本番環境での使用を設定します。
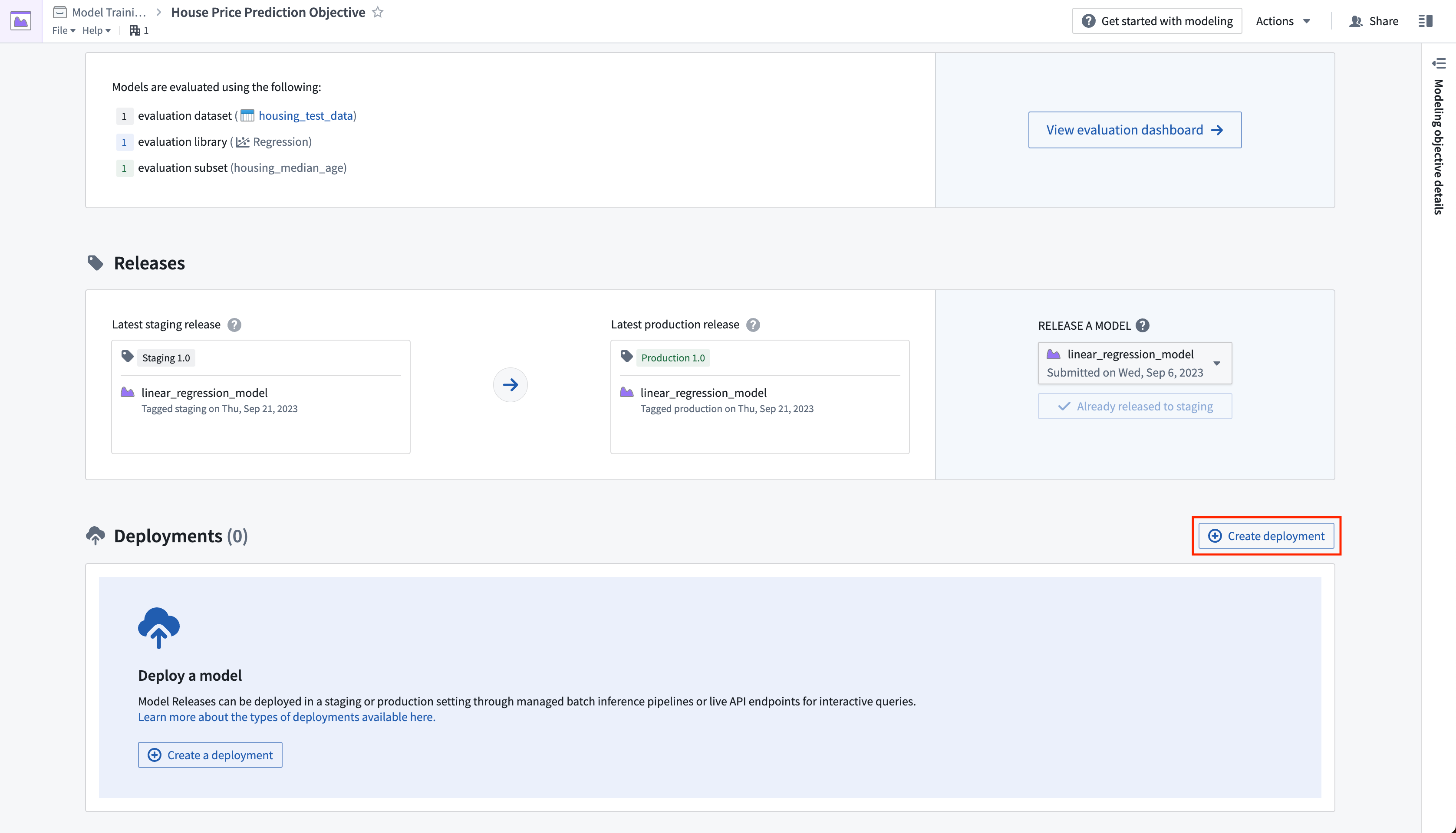
4.1 モデリングの目的でモデルをリリースする
モデルができたので、それを本番環境にデプロイすることができます。このモデルの使用目的に応じて、いくつかの方法で本番環境にデプロイすることができます。モデルは、ドキュメンテーション、評価、および複数のバックモデルからの提出物の比較をサポートするフル機能のリリースとモデル管理を提供する Modeling Objectives からデプロイできます。
Modeling Objectives からのデプロイメントは以下の方法で行うことができます:
- バッチデプロイメント: データセットに対して予測を生成する、一度に一群のレコードの予測を計算するのに推奨されます。
- ライブデプロイメント: モデルを REST エンドポイントの背後にホストする、外部システムからモデルを使用する場合や、モデルとのリアルタイムな対話が必要な場合に推奨されます。
- Pythonトランスフォーム: トランスフォームでの迅速な反復に便利です。
また、より軽量なセットアップを好むユーザーは、Code Repositories での推論ロジックのテストに関するチュートリアルで説明されているように、バッチ推論のためにトランスフォームにモデルをインポートするか、直接デプロイメントを使用して REST エンドポイントの背後にデプロイできます。
Modeling Objectives におけるライブデプロイメントと直接デプロイメントの違いについてさらに学びましょう。
モデリングの目的でのリリースとは?
バッチおよびライブデプロイメントはモデルリリースによってサポートされています。モデリングの目的で新しいモデルをリリースすると、そのモデリングの目的におけるデプロイメントは自動的に新しくリリースされたモデルを使用するようにアップグレードされます。
これにより、モデル消費者はその具体的な実装を気にすることなくモデルを使用できます。データサイエンティストはモデルの改善に集中でき、アプリケーション開発者は有用なアプリケーションの構築に集中できます。
リリース管理
リリースとデプロイメントはステージングと本番に分類されます。モデル開発者はモデルを本番リリース前にステージング環境にリリースできます。これにより、ステージングデプロイメントがアップグレードされますが、本番デプロイメントは変更されません。データサイエンティストやアプリケーションビルダーは、ステージング環境で新しいモデルをテストしてから、モデルを本番環境にデプロイすることができます。
すべてのリリースおよびモデルをリリースした個人は記録され、チームがどのモデルがいつ使用されたかを追跡できるようにします。これにより、GDPR や EU AI Act によって求められるような規制上の質問に答えるのに役立ちます。
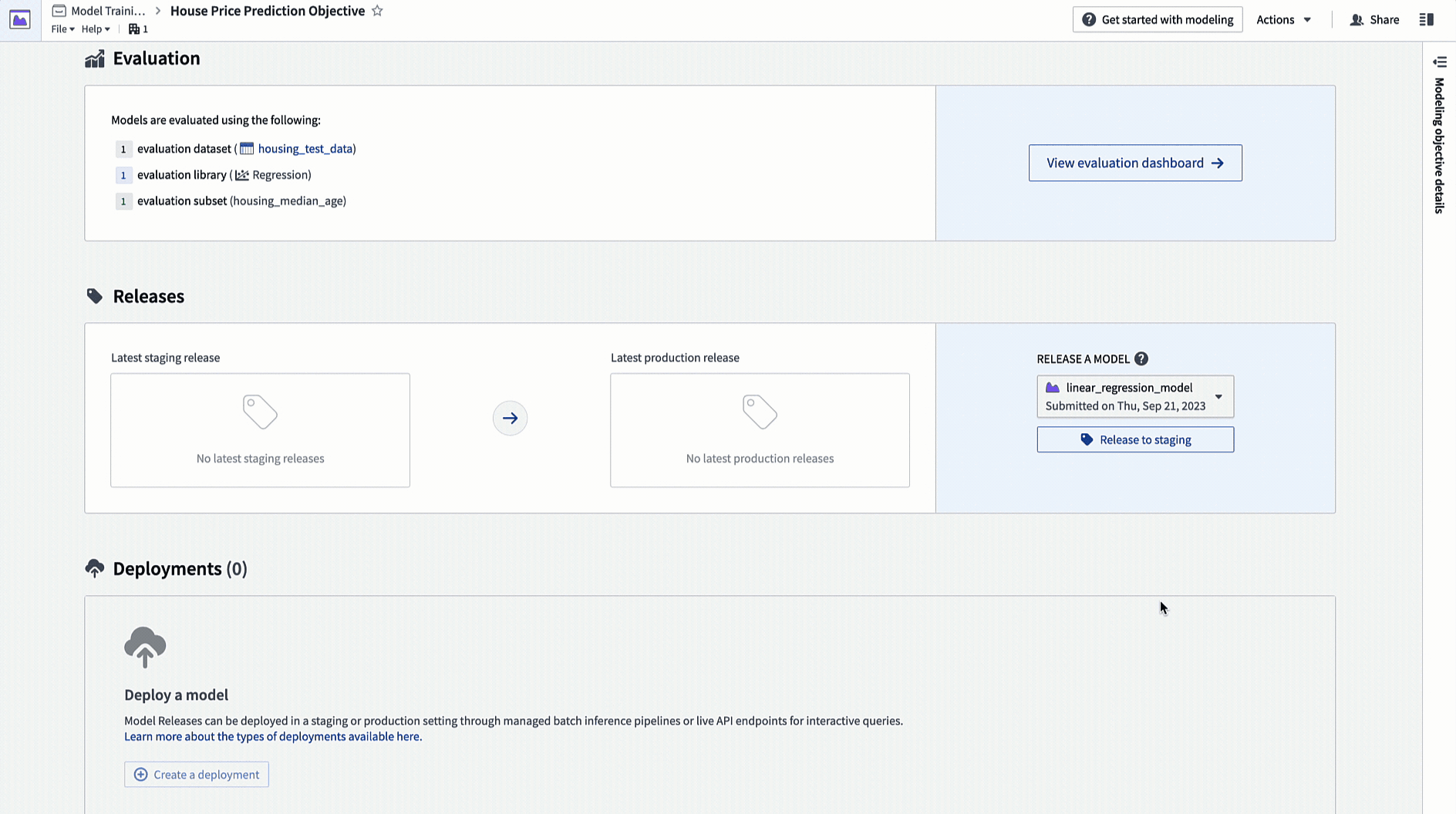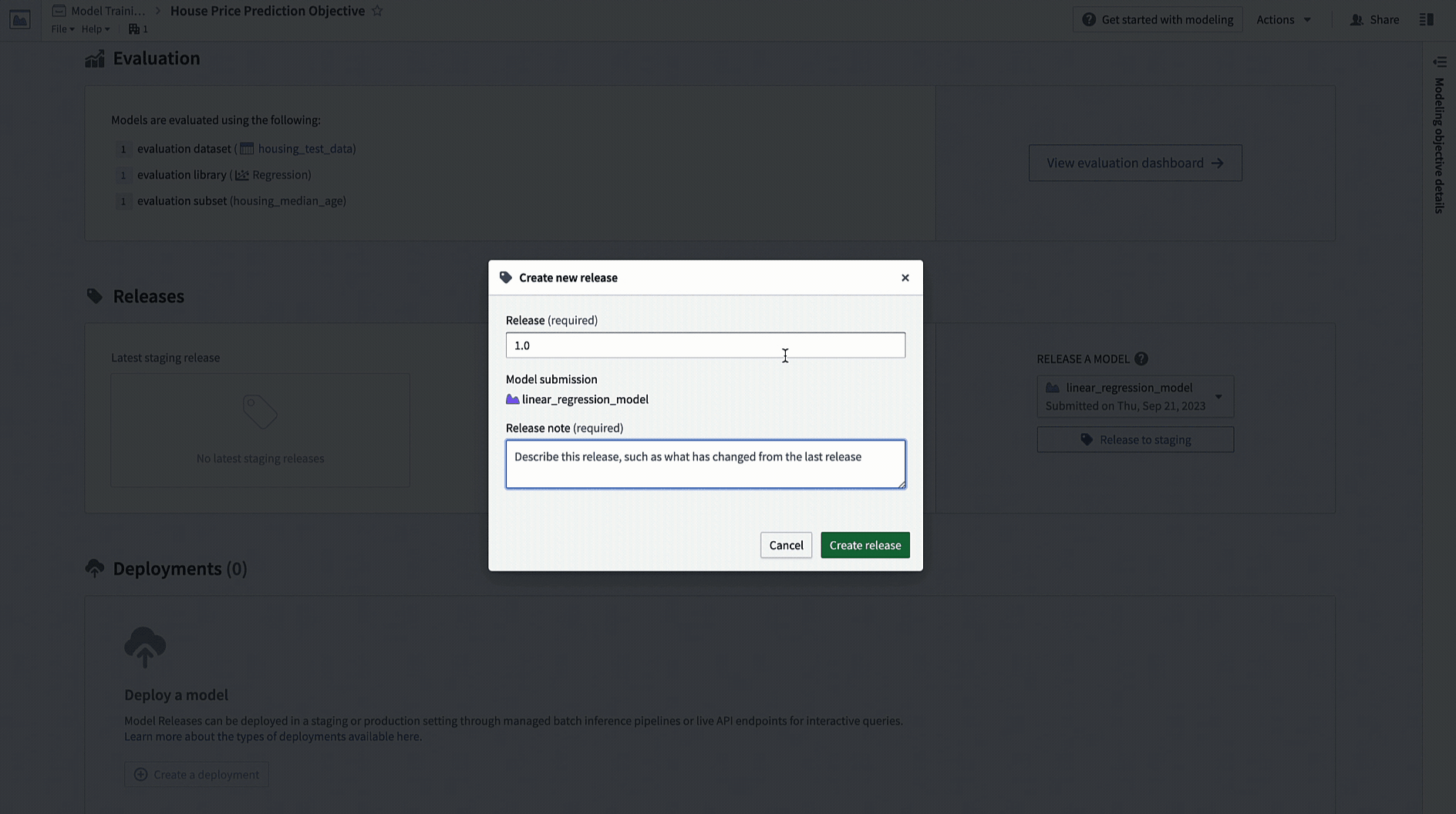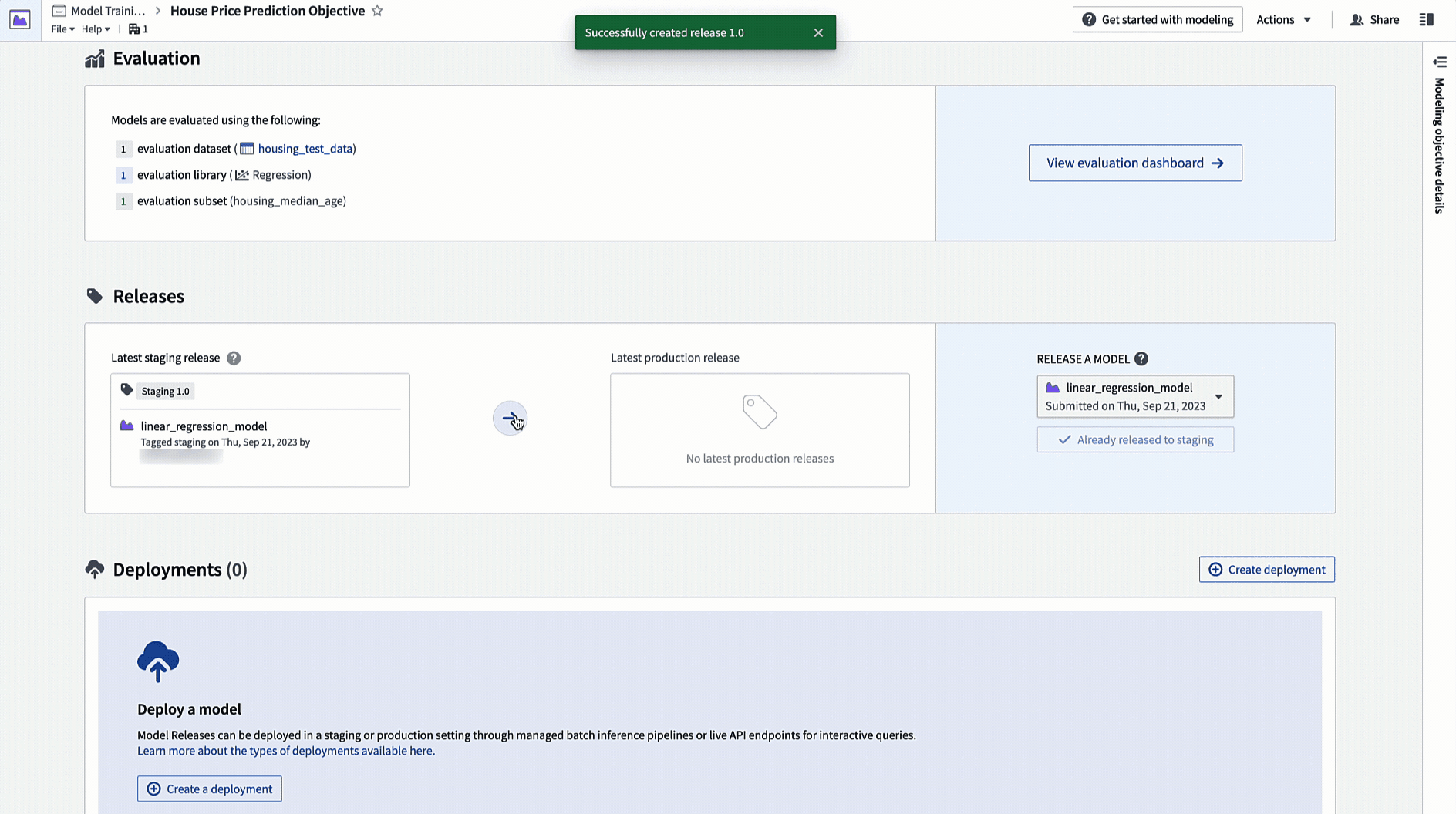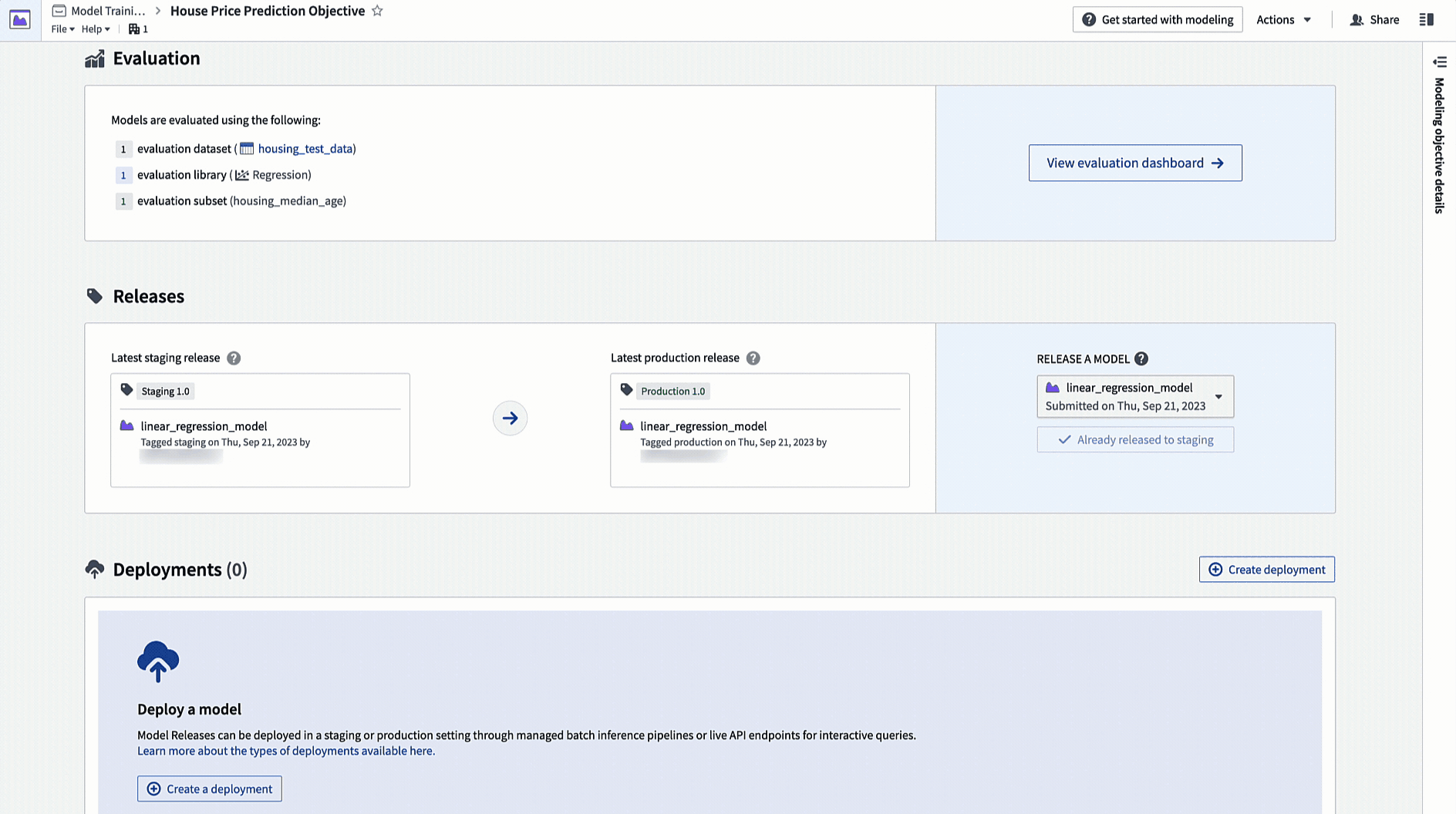
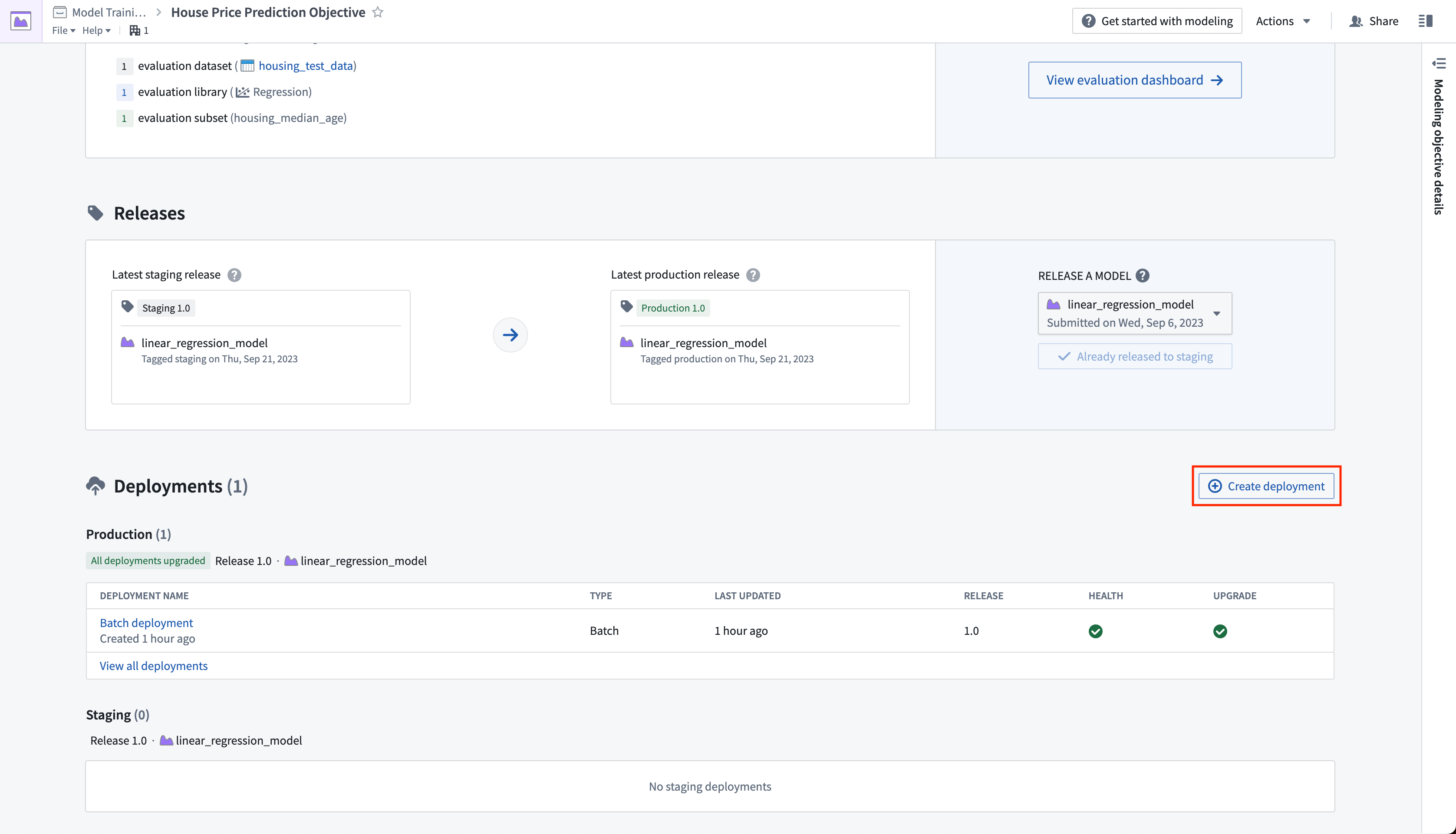
アクション: モデリングの目的のホームページに移動し、リリースセクションまでスクロールします。ステージングにリリースを選択し、次に矢印アイコンを選択してモデルを本番にリリースします。リリースには「1.0」のようなリリース番号を付ける必要があります。
4.2 バッチ処理のためのバッチデプロイメントを作成する方法
バッチデプロイメントは、入力データセットから Foundry トランスフォームを作成します。バッチデプロイメントの出力は、モデルを使用して入力データセットに対して推論(予測生成)を実行した結果のデータセットです。
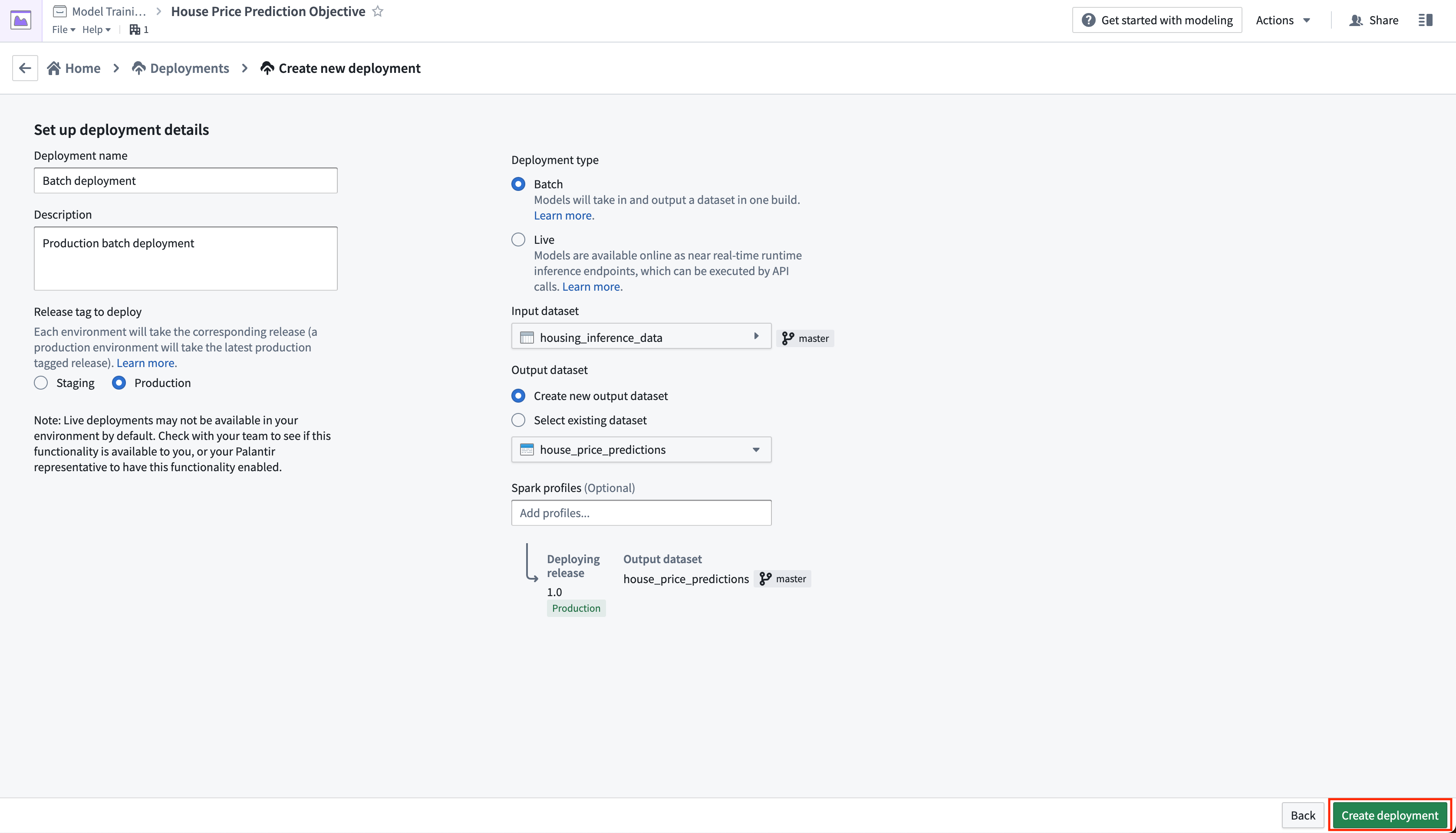
アクション: デプロイメントを作成をクリックし、バッチデプロイメントの本番環境デプロイメントを構成します。デプロイメントに Batch deployment という名前を付け、Production batch deployment という説明を付けます。入力データセットとして先に作成した housing_inference_data データセットを選択し、data フォルダーに house_price_predictions という新しい出力データセットを作成します。デプロイメントを作成を選択して構成を保存します。
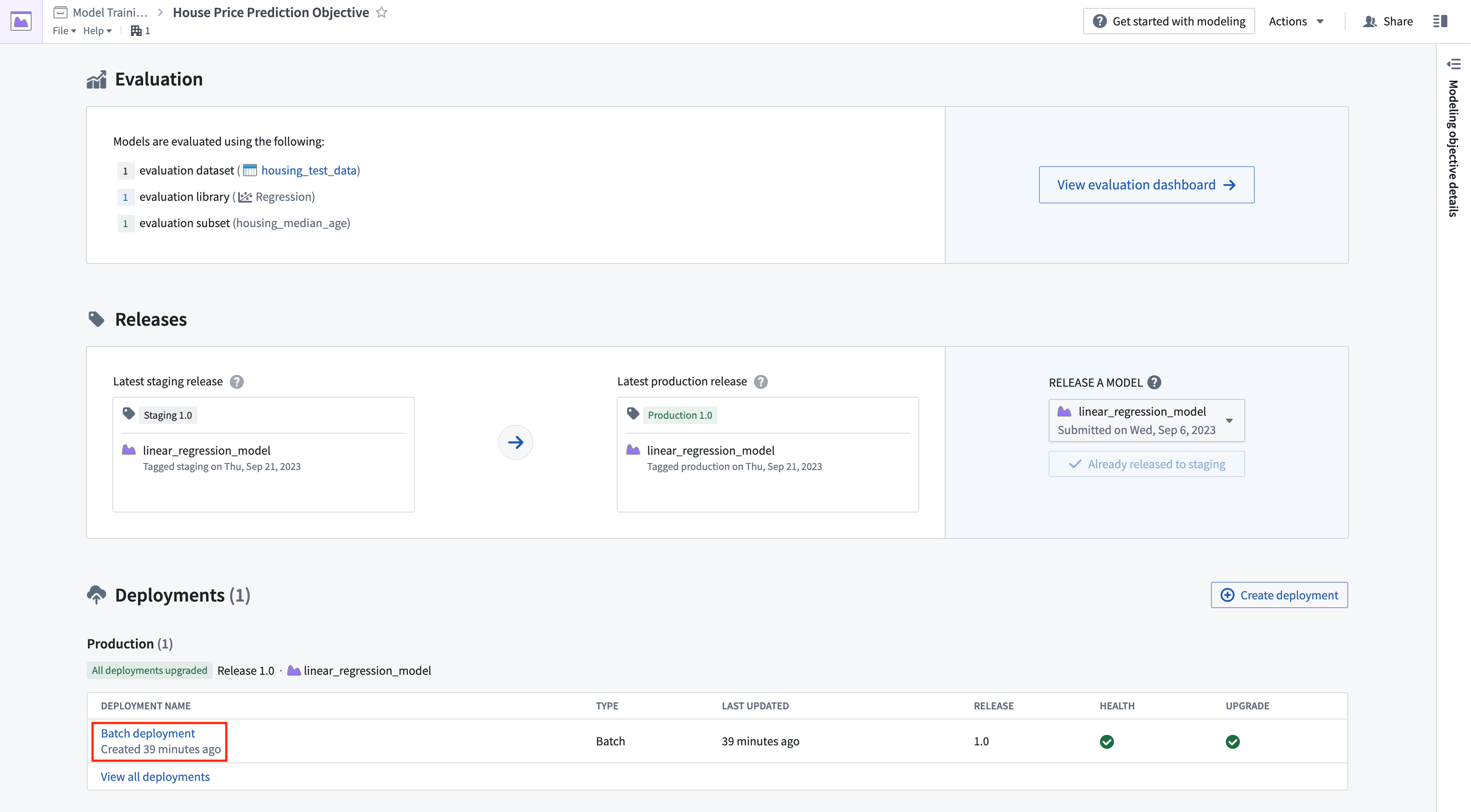
これで、モデルがリリースされるたびに出力データセットが自動的に更新されるようにバッチデプロイメントをスケジュールできます。これにより、常に最良の予測を使用することができます。出力データセットに新しいロジックを受け取るたびに再構築されるようにスケジュールを追加しましょう。
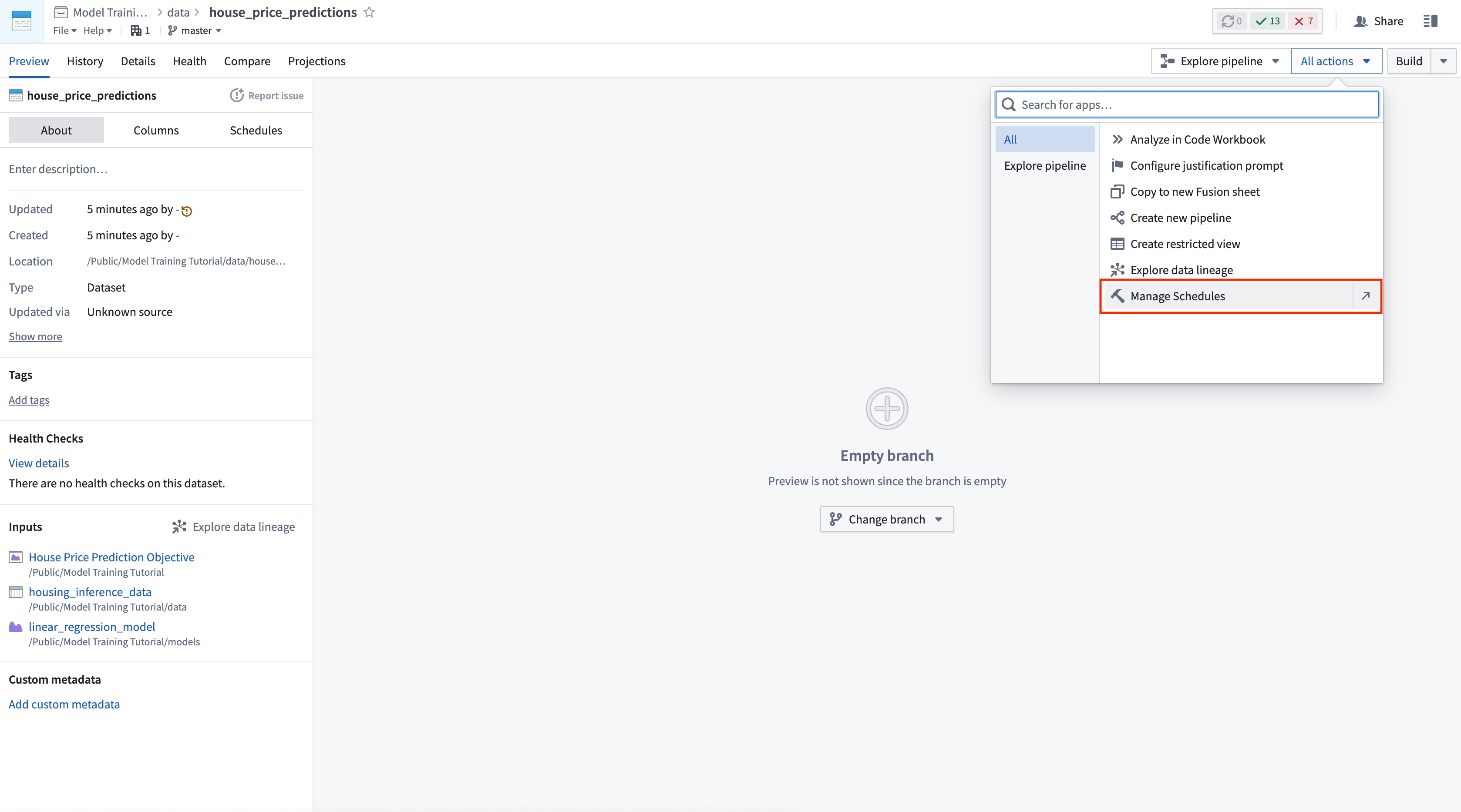
アクション: デプロイメントテーブルでバッチデプロイメントを選択します。house_price_predictions という名前の出力データセットを選択します。すべてのアクションの下で、スケジュールを管理を選択します。house_price_predictions データセットで、新しいスケジュールを作成 -> 複数の時間またはイベント条件が満たされたときを選択し、house_price_predictions データセットが 新しいロジック を受け取るときにスケジュールを作成します。最後に、スケジュールを保存するために保存を選択します。
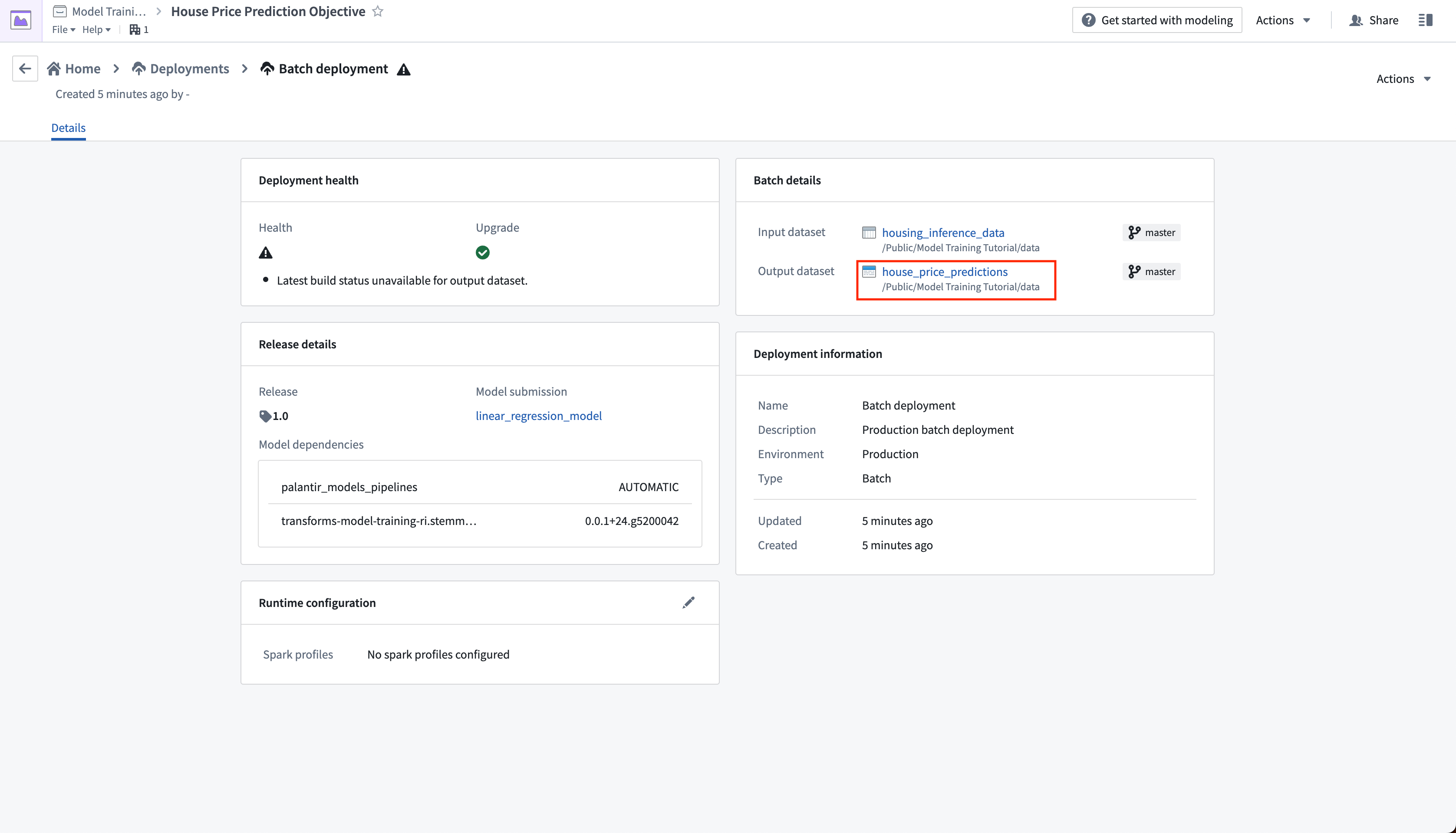
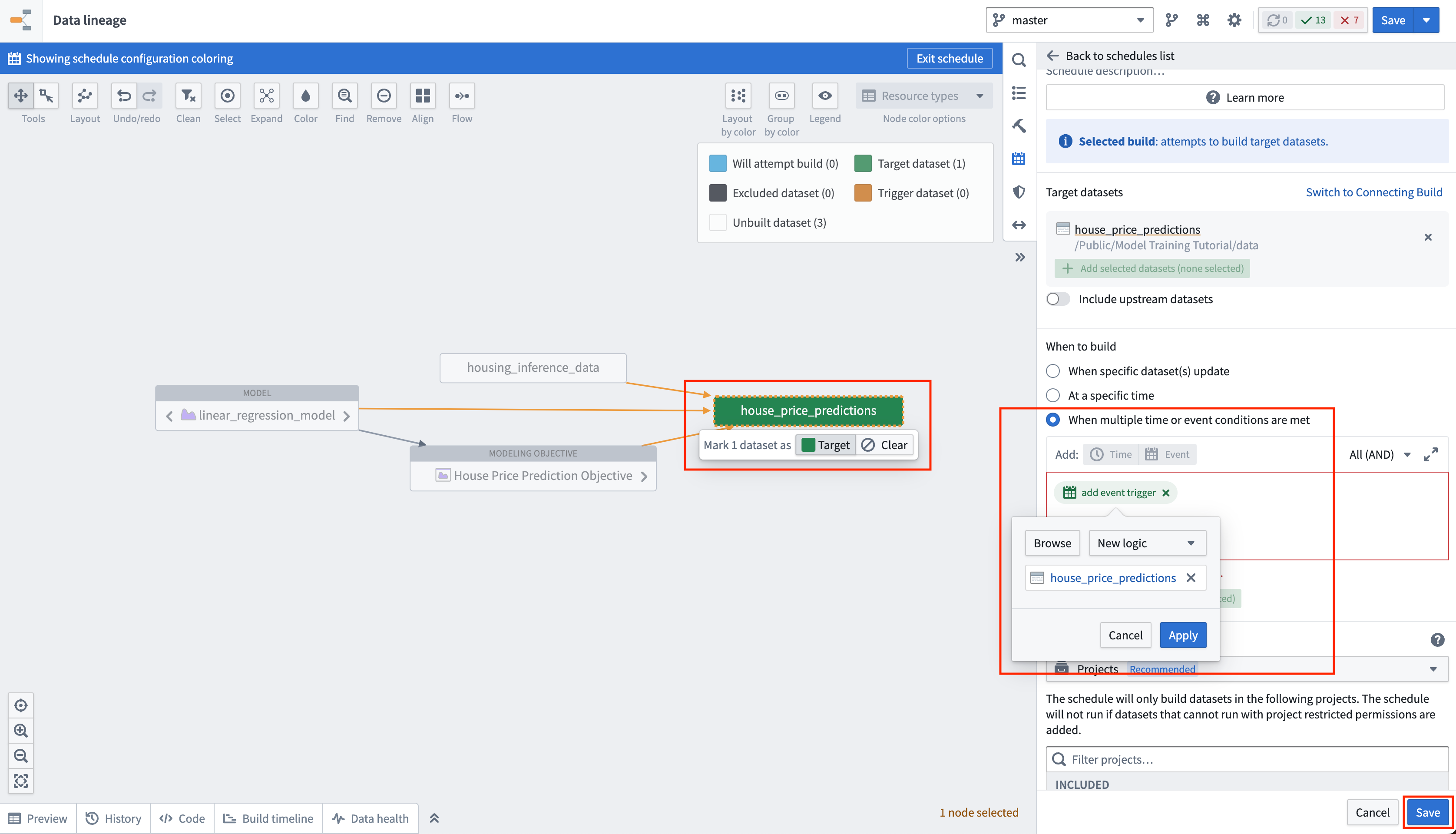
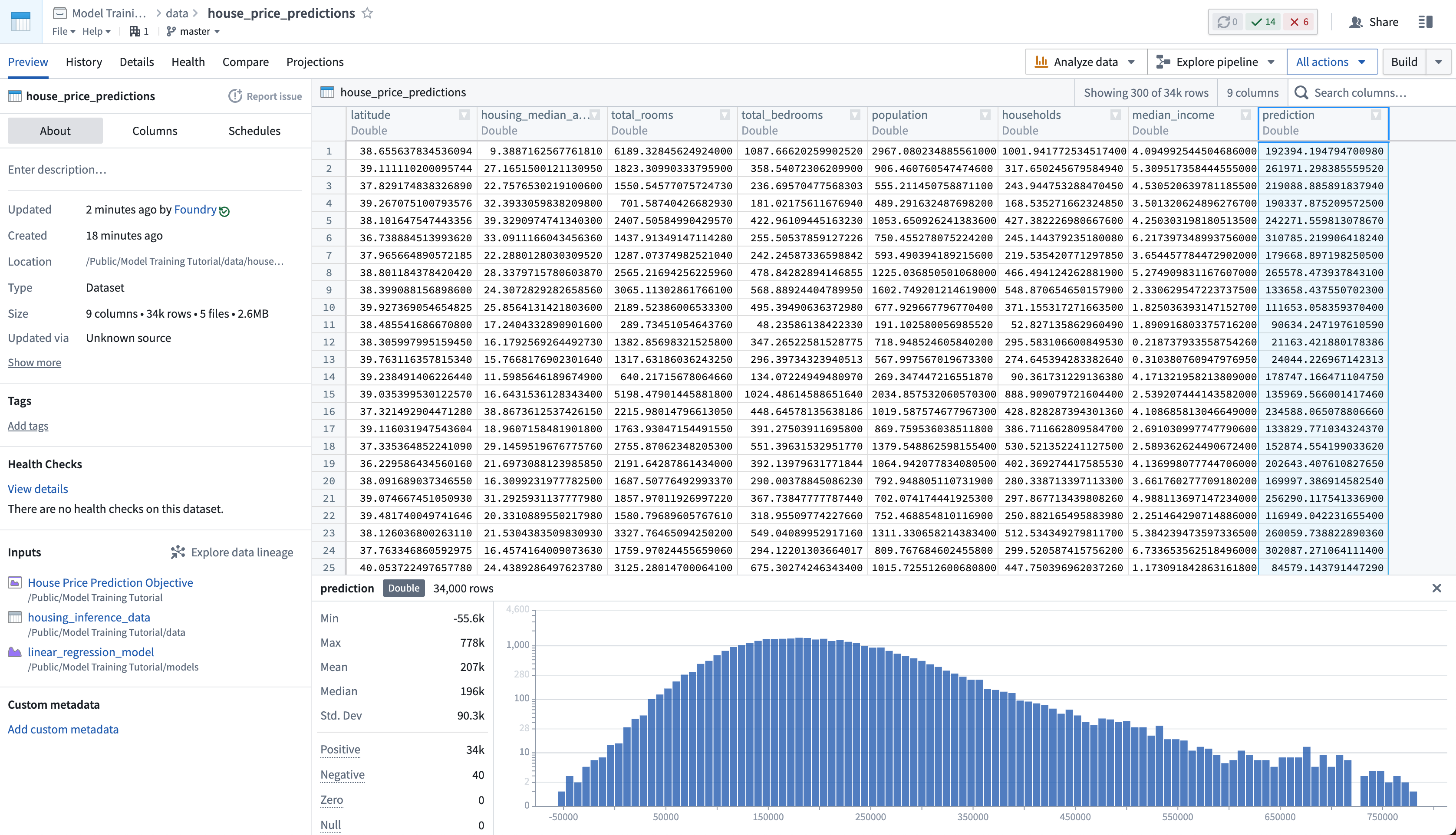
最後に、house_price_predictions データセットを更新していないため、これを実行して予測を生成できます。ビルドが完了したら、house_price_predictions データセットを開いて、prediction 列に新しく生成された予測を確認できます。
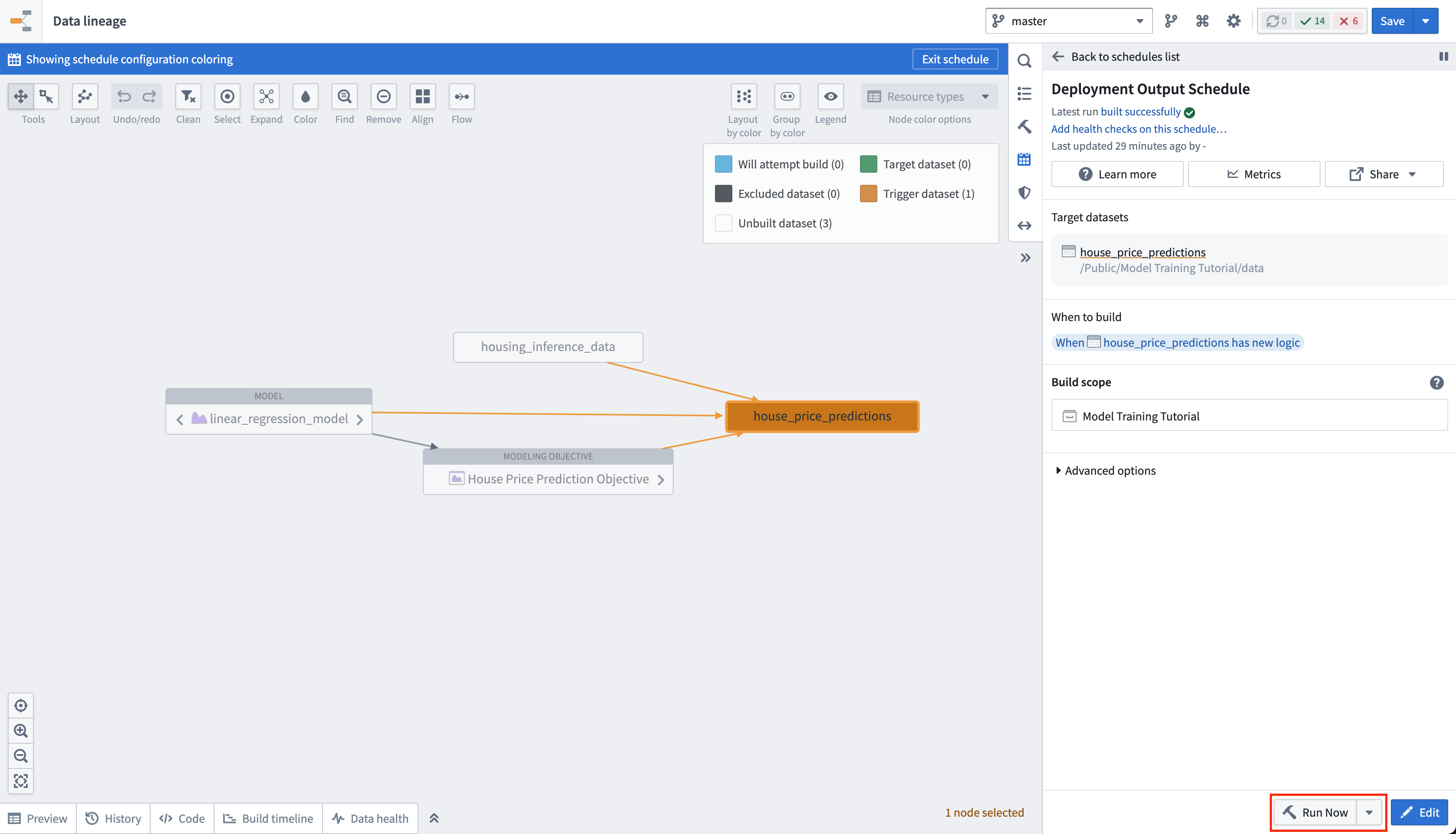
アクション: スケジュールビューで今すぐ実行を選択して house_price_predictions データセットをビルドします。ビルドが完了したら、house_price_predictions データセットを右クリックして開くを選択し、生成された予測を確認できます。
4.3 モデルのインタラクティブなライブエンドポイントを作成する方法
ライブデプロイメントは、REST エンドポイントの背後に本番モデルをホストするクエリエブルエンドポイントです。ライブデプロイメントは、モデルと対話的にやり取りしたい場合に有用であり、以下からクエリできます:
- Functions on Models: Functions on Models は、Foundry の Slate や Workshop アプリケーションからモデルを直接クエリできます。
- リアルタイムの外部システム: たとえば、ユーザーの行動からライブ予測を生成する必要があるウェブサイト。
- CURL: ローカルでのモデルのテストに使用されます。
この例では、たとえば、ユーザーが国勢調査地区に関する詳細を入力し、それが中央値の住宅価格にどのように影響するかを確認できるインタラクティブなダッシュボードを構築したいかもしれません。
アクション: 目的のホームページから、デプロイメントを作成をクリックし、ライブデプロイメントの本番環境デプロイメントを構成します。デプロイメントに Live deployment という名前を付け、Production live deployment という説明を付けます。デプロイメントを作成をクリックして構成を保存します。
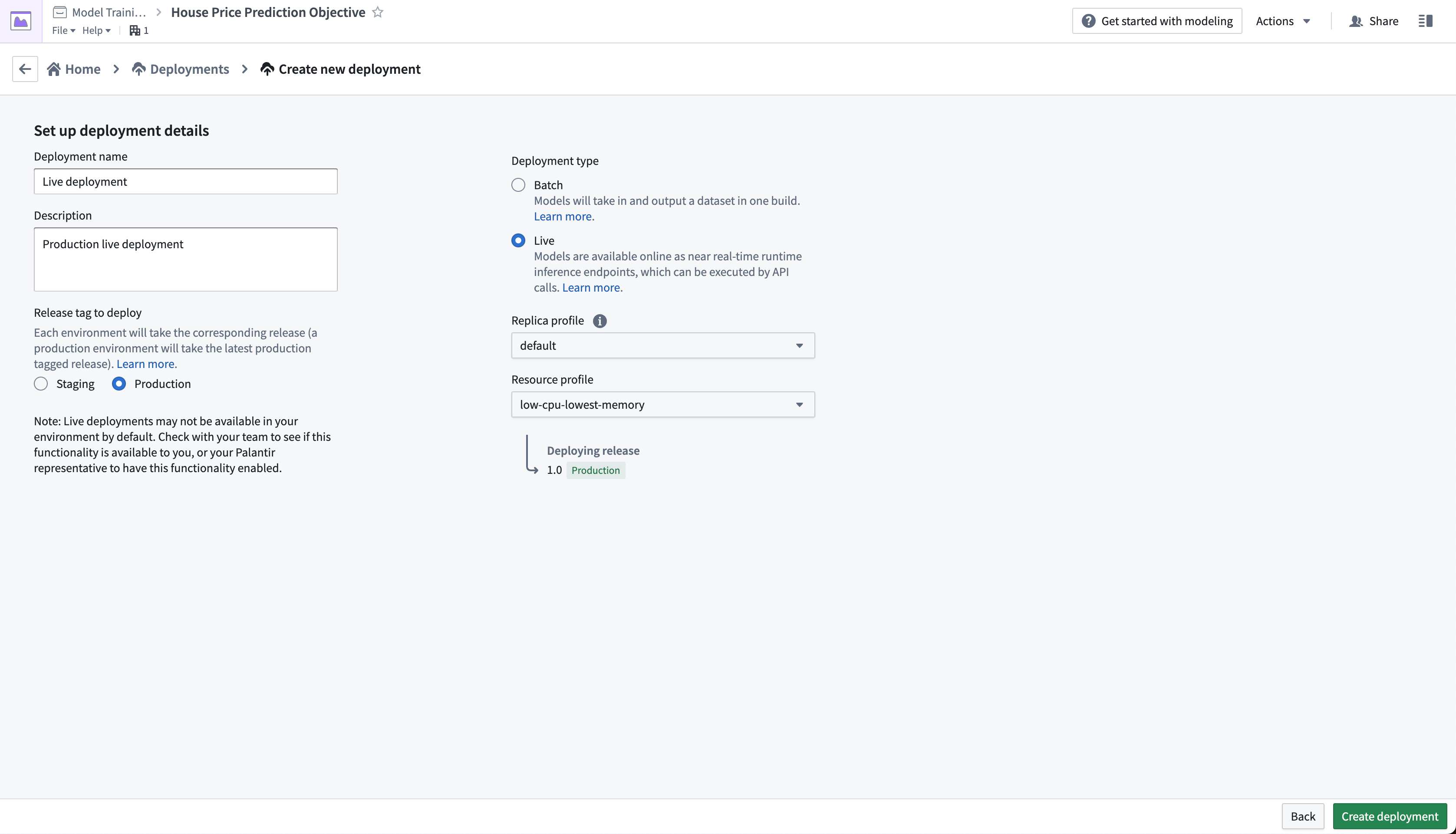
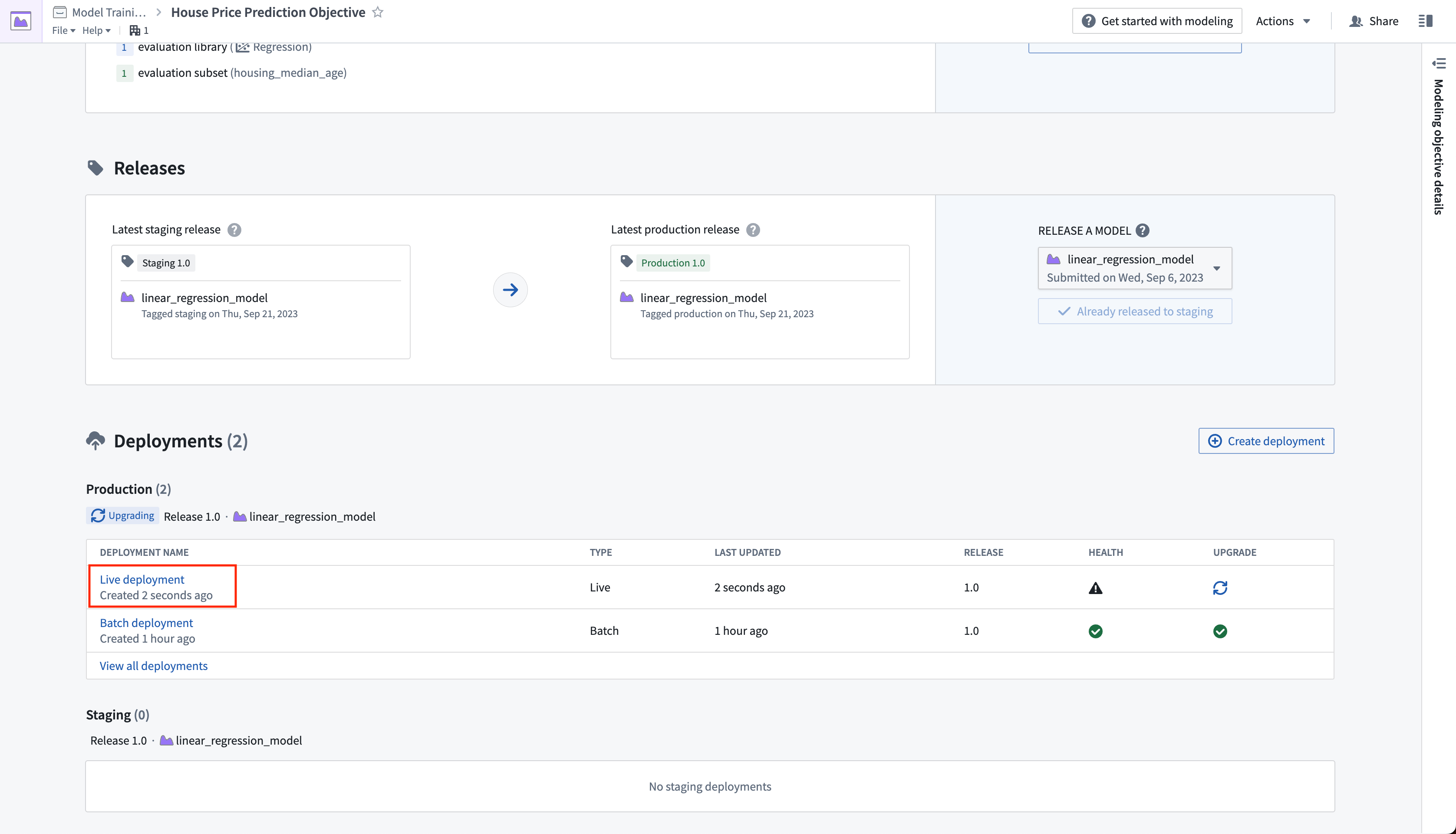
ライブデプロイメントが開始されるまでに数分かかる場合があります。初期化が完了したら、リアルタイムの運用アプリケーションを設定してモデルに接続できます。
アクション: ライブデプロイメントを選択します。デプロイメントがアップグレードされたら、クエリタブを開きます。以下の例を貼り付けて、実行を選択してモデルをテストします。
Copied!1 2 3 4 5 6 7 8 9 10[ { "housing_median_age": 33.4, // 住宅の中央値の築年数 "total_rooms": 1107.0, // 総部屋数 "total_bedrooms": 206, // 総寝室数 "population": 515.3, // 人口 "households": 200.9, // 世帯数 "median_income": 4.75 // 中央収入 (単位: 万ドル) } ]
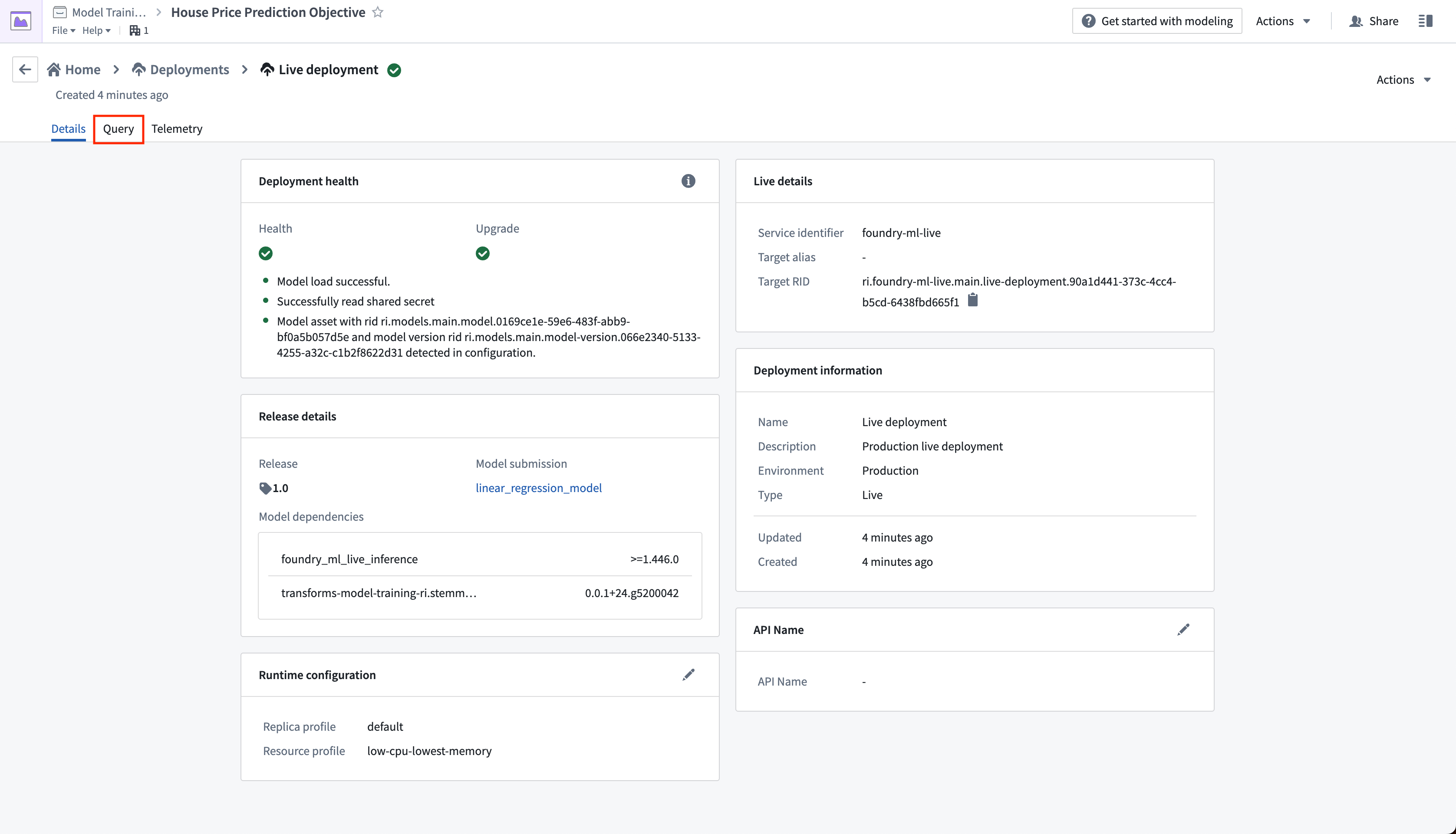
任意: クエリテキストボックスに表示される例のクエリを使用して、コピーアイコンを選択し、モデルをローカルでテストするためのCURLリクエストの例をコピーします。ユーザーの Foundry 環境とライブデプロイメントに一致するように <BEARER_TOKEN>、、および <DEPLOYMENT_RID> を更新する必要があります。<BEARER_TOKEN> はユーザートークン生成ドキュメントに従って生成できます。
Copied!1 2 3 4 5 6 7 8 9 10 11curl --http2 -H "Content-Type: application/json" -H "Authorization: <BEARER_TOKEN>" -d '{"requestData":[ { "housing_median_age": 33.4, "total_rooms": 1107.0, "total_bedrooms": 206, "population": 515.3, "households": 200.9, "median_income": 4.75 } ], "requestParams":{}}' --request POST <STACK>/foundry-ml-live/api/inference/transform/<DEPLOYMENT_RID> # このコマンドは、HTTP/2プロトコルを使用してPOSTリクエストを送信します。 # -H はヘッダーを指定するオプションです。 # "Content-Type: application/json" はリクエストの内容がJSON形式であることを示します。 # "Authorization: <BEARER_TOKEN>" は認証トークンをヘッダーに含めています。 # -d オプションはリクエストボディを指定します。 # '{"requestData":[ { "housing_median_age": 33.4, "total_rooms": 1107.0, "total_bedrooms": 206, "population": 515.3, "households": 200.9, "median_income": 4.75 } ], "requestParams":{}}' はリクエストボディのJSONデータです。 # housing_median_age, total_rooms, total_bedrooms, population, households, median_income は送信するデータの属性です。 # --request POST はHTTPメソッドとしてPOSTを指定します。 # <STACK>/foundry-ml-live/api/inference/transform/<DEPLOYMENT_RID> はリクエストを送信するエンドポイントURLです。
ライブデプロイメントは常に稼働しているサーバーを利用したものです。一度開始すると、Foundryはステージングや本番環境のデプロイメントを自動的に終了しません。ライブデプロイメントはコストが高くなる可能性があるため、チュートリアルを完了した後はこのライブデプロイメントを無効化または削除することをお勧めします。なお、直接デプロイメントは必要に応じてサーバーをゼロまでスケールダウンし、サーバーを起動するように構成できますが、最初の呼び出しはサーバーが起動する間に応答時間が長くなります。
ライブデプロイメントビューのアクションドロップダウンからライブデプロイメントを無効化または削除できます。
次のステップ
ここまでで、機械学習プロジェクトの設定、新しいモデルの構築、その性能評価、およびデプロイメントを行い、モデルが運用に使用できる状態になりました。
おわりにを読む前に、新しいバージョンのモデルをトレーニングし、それを評価して、新しい本番リリースを作成してデプロイメントを更新することを検討してください。以下のロジックを使用して、scikit-learnを用いたランダムフォレスト回帰モデルと新たに派生したプロパティhousing_age_per_incomeをトレーニングできます。以下のコードについて、モデルadapterロジックを更新する必要はありません。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60from transforms.api import transform, Input from palantir_models.transforms import ModelOutput from main.model_adapters.adapter import SklearnRegressionAdapter @transform( training_data_input=Input("<YOUR_PROJECT_PATH>/data/housing_training_data"), model_output=ModelOutput("<YOUR_PROJECT_PATH>/models/random_forest_regressor_model"), ) def compute(training_data_input, model_output): training_df = training_data_input.pandas() model = train_model(training_df) # 学習済みモデルをModelAdapterでラップする foundry_model = SklearnRegressionAdapter(model) # 学習済みモデルをFoundryに公開し、書き込む model_output.publish( model_adapter=foundry_model ) def derive_housing_age_per_income(X): X['housing_age_per_income'] = X['housing_median_age'] / X['median_income'] return X def train_model(training_df): from sklearn.ensemble import RandomForestRegressor from sklearn.impute import SimpleImputer from sklearn.pipeline import Pipeline from sklearn.preprocessing import StandardScaler, FunctionTransformer # 使用する数値特徴量のリスト numeric_features = ['median_income', 'housing_median_age', 'total_rooms'] numeric_transformer = Pipeline( steps=[ # 特徴量エンジニアリング:収入あたりの住宅年齢を計算 ("rooms_per_person_transformer", FunctionTransformer(derive_housing_age_per_income, validate=False)), # 欠損値処理:中央値で補完 ("imputer", SimpleImputer(strategy="median")), # 標準化 ("scaler", StandardScaler()) ] ) model = Pipeline( steps=[ ("preprocessor", numeric_transformer), ("regressor", RandomForestRegressor()) ] ) # 特徴量とターゲット変数を分割 X_train = training_df[numeric_features] y_train = training_df['median_house_value'] # モデルの学習 model.fit(X_train, y_train) return model