注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
3. チュートリアル - Modeling Objectives アプリケーションでモデルを評価する
このチュートリアルを開始する前に、モデリングプロジェクトのセットアップを完了し、Jupyter® ノートブックまたはCode Repositoriesでモデルをトレーニングしている必要があります。この時点で、ユーザーのモデリングの目的には少なくとも1つのモデルが存在しているはずです。
このチュートリアルのこのステップでは、モデルの性能を評価し、そのモデルをモデリングの目的にリリースします。このステップは推奨されますが、このチュートリアルの後続のステップには影響しないため、後から戻ってくることができます。以下の内容をカバーします。
3.1 モデリングの目的とは?
モデリングの目的は、潜在的に生産に値するモデルバージョンのカタログと考えることができます。モデリングの目的にモデルを提出することで、そのカタログにモデルが追加され、特定のモデリング問題や目標の文脈で評価およびレビューが可能になります。各モデルの提出は、最終的に生産化されるかどうかにかかわらず、モデリングプロジェクトの進捗を追跡し、プロジェクトの実験と学習の歴史を維持するのに役立ちます。
このステップでは必要なアクションはありません。
3.2 自動モデル評価の設定方法
モデリングの目的にモデル候補があるので、このモデルの性能を評価し、モデルのパフォーマンスメトリクスを生成することで、このモデリングの目的の中でどれだけうまく機能するかを評価できます。パフォーマンスメトリクスは、モデルの性能やモデルの動作理由を理解するための重要なツールです。
このチュートリアルの目的が数値(アメリカの国勢調査地区の平均住宅価格)を推定することであるため、モデリング問題は回帰モデリング問題として分類できます。回帰モデリング問題では、平均絶対誤差や二乗平均平方根誤差などの評価メトリクスを見るのが一般的です。これらのメトリクスは Foundry のデフォルトの回帰評価器に含まれているため、このライブラリを使用してモデル提出のパフォーマンスを評価します。
アクション: モデリングの目的から 評価ダッシュボードの設定 を選択します。
モデル評価の設定
自動モデル評価は、モデルが標準化された方法で評価されることを保証する有用な方法です。標準化は一貫したモデル比較を保証し、どのモデルを生産で使用するのが最適かを自信を持って選択できるようにします。
評価パイプライン管理が有効になっている場合、Foundry はモデル提出と評価データセットの各組み合わせごとに推論データセットを自動的に生成します。推論データセットは、評価データセットに対してモデルの推論(予測を生成する)を実行した結果です。評価データセットは、モデルの標準化されたテストセットとしてユーザーによって定義され、予測を生成するために使用される特徴と、モデルの推論を真実のラベルと比較するためのラベルの両方を必要とします。
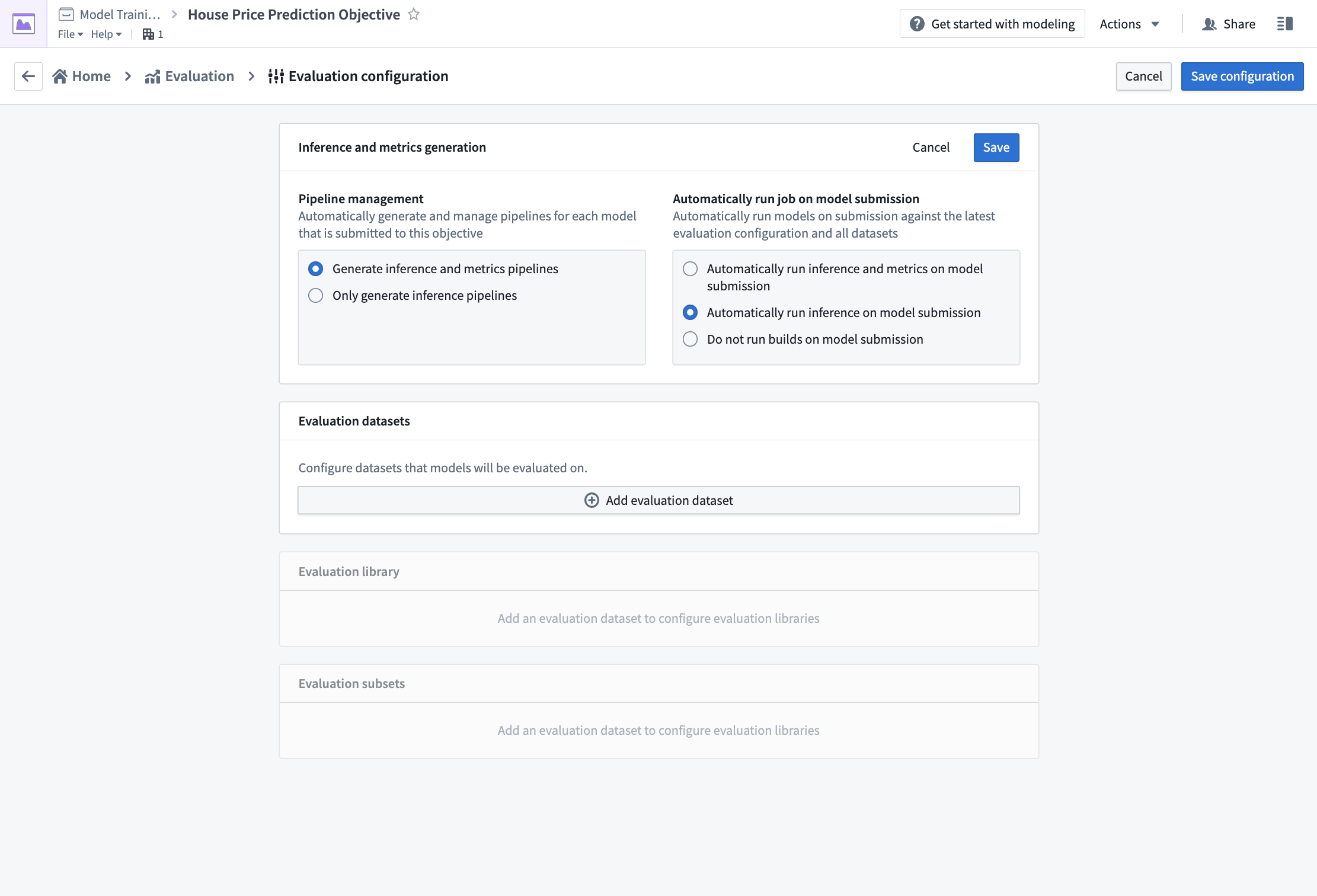
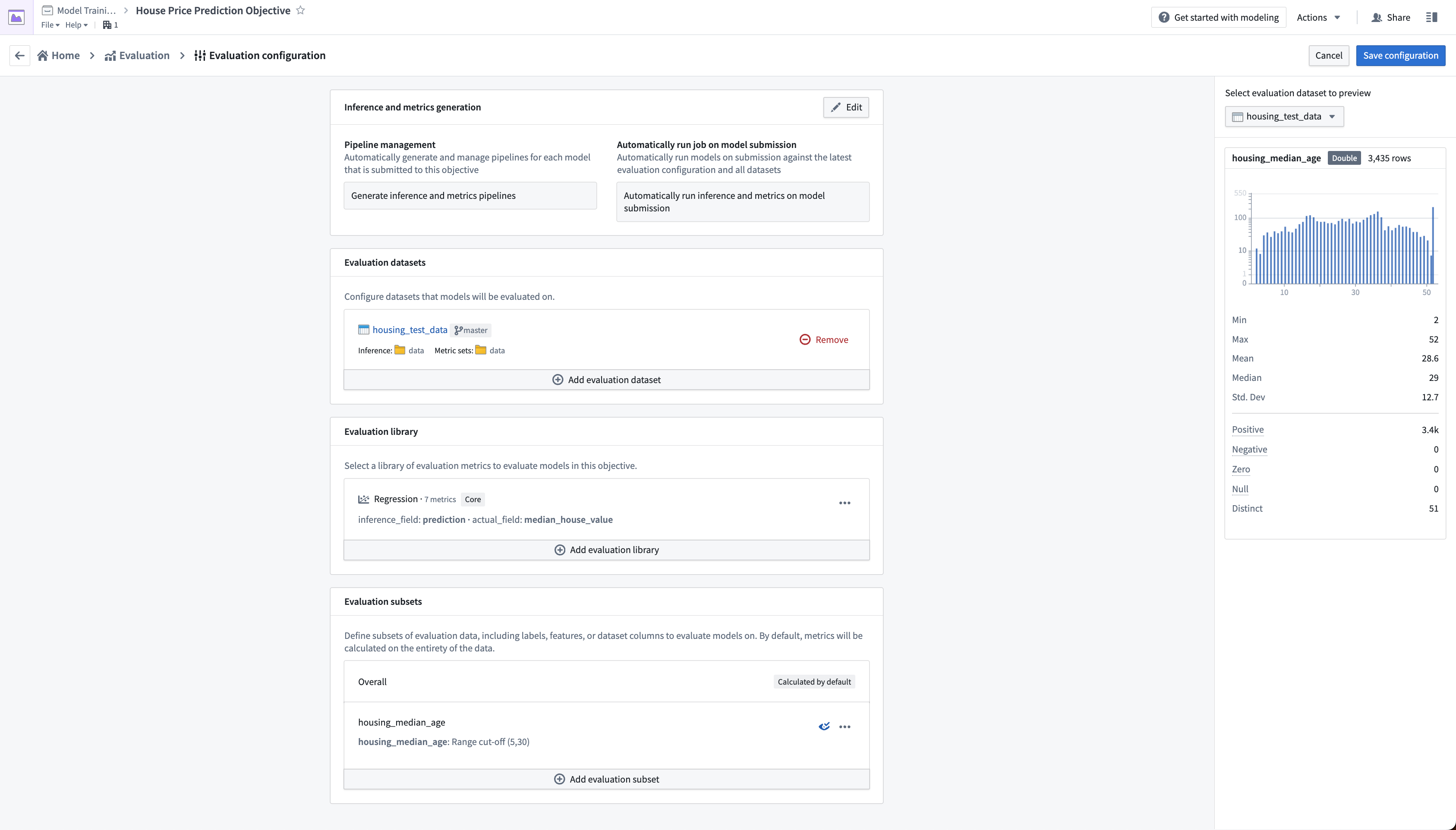
アクション: パイプライン管理を設定するには、編集 を選択し、次に 推論およびメトリクスパイプラインの生成 と モデル提出時に推論およびメトリクスを自動実行 の両方のオプションを選択します。次に 保存 を選択してパイプライン管理設定を確定します。
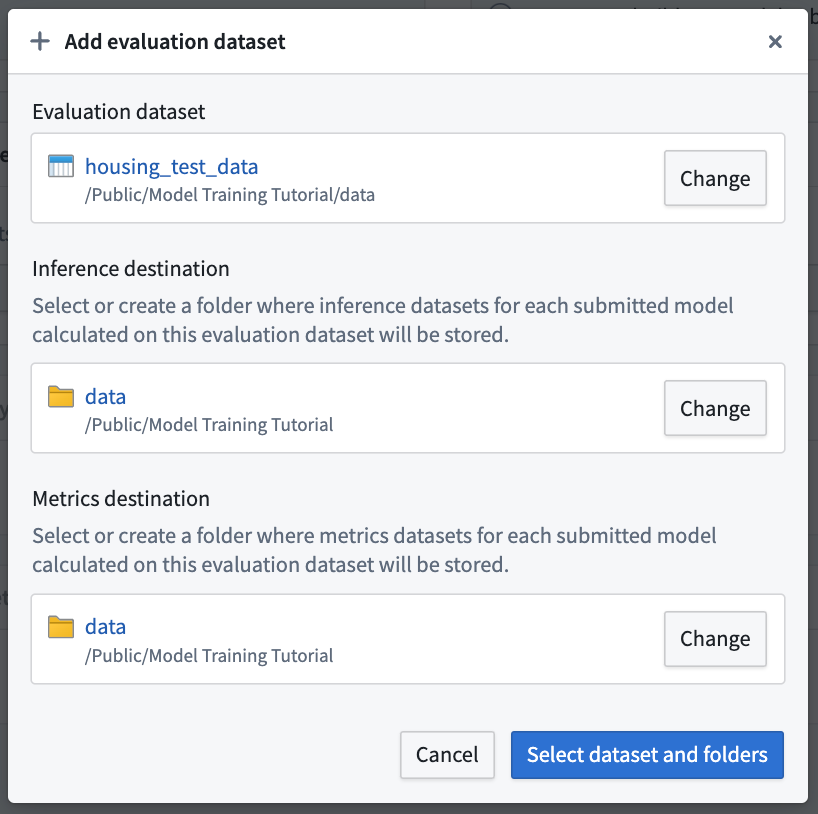
アクション: 評価データセットを設定するには、評価データセットの追加 を選択し、モデルトレーニングチュートリアルで作成した housing_test_data データセット を評価データセットとして選択します。推論先とメトリクス先として data フォルダーを選択します。データセットとフォルダーの選択 を選択して選択を確定します。
評価ライブラリの設定
評価ライブラリは、推論データセットを取り込み、評価メトリクスを生成してモデリングの目的の評価ダッシュボードに追加するために使用されるパラメータ化可能な Foundry ライブラリです。Foundry には回帰およびバイナリ分類のデフォルト評価ライブラリが付属していますが、特定のモデリング問題に合わせてカスタム評価ライブラリを作成することも可能です。
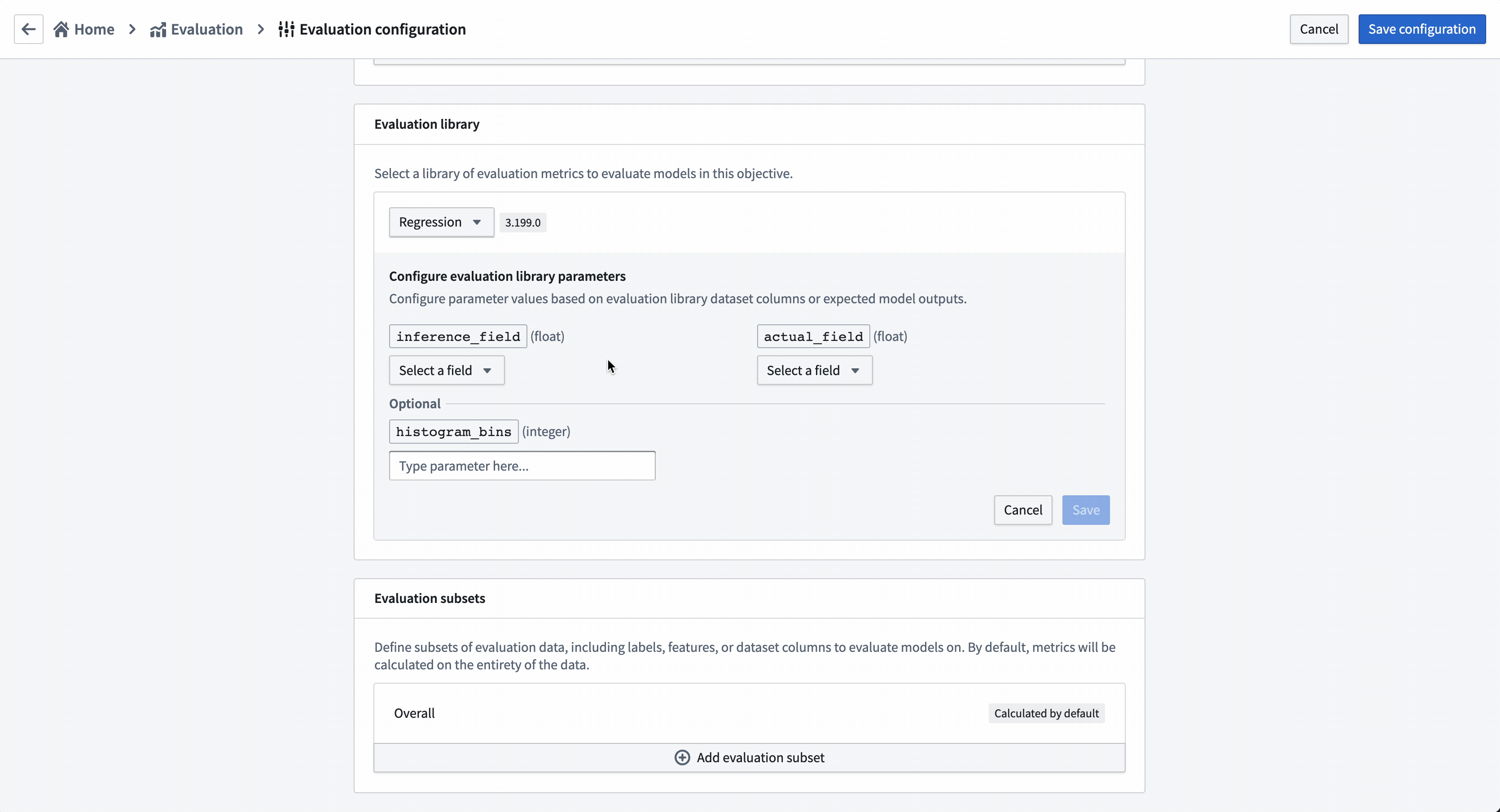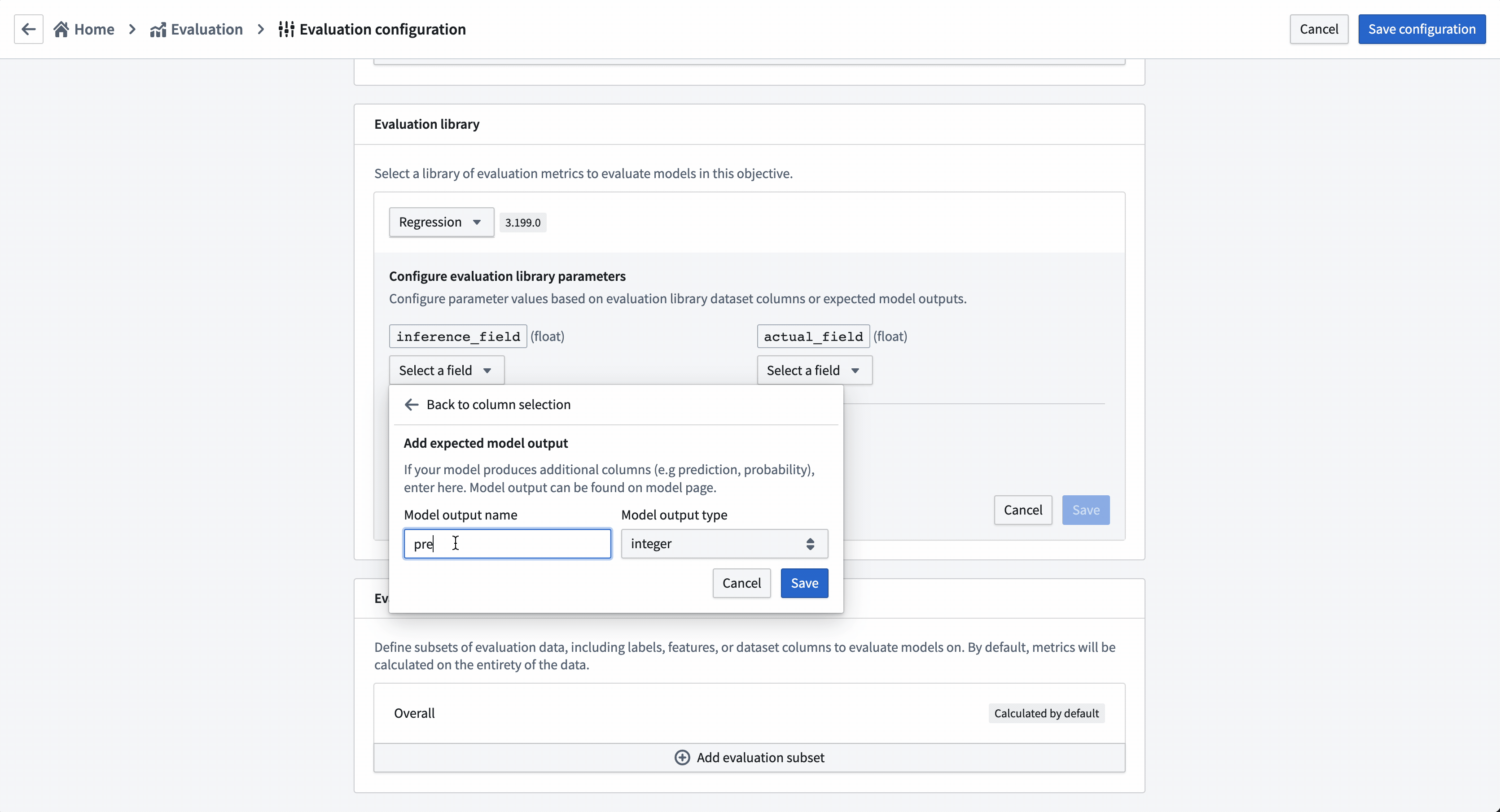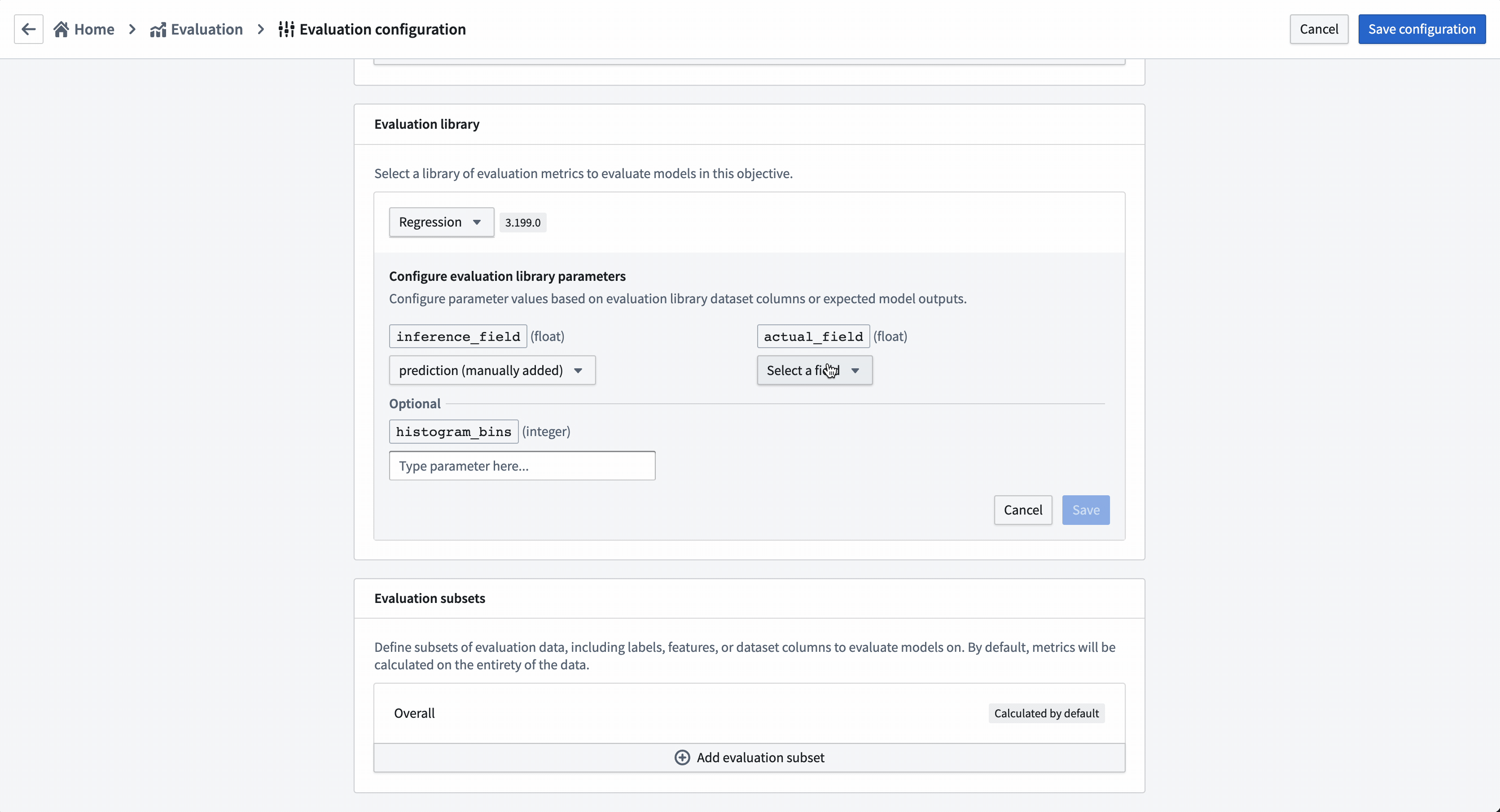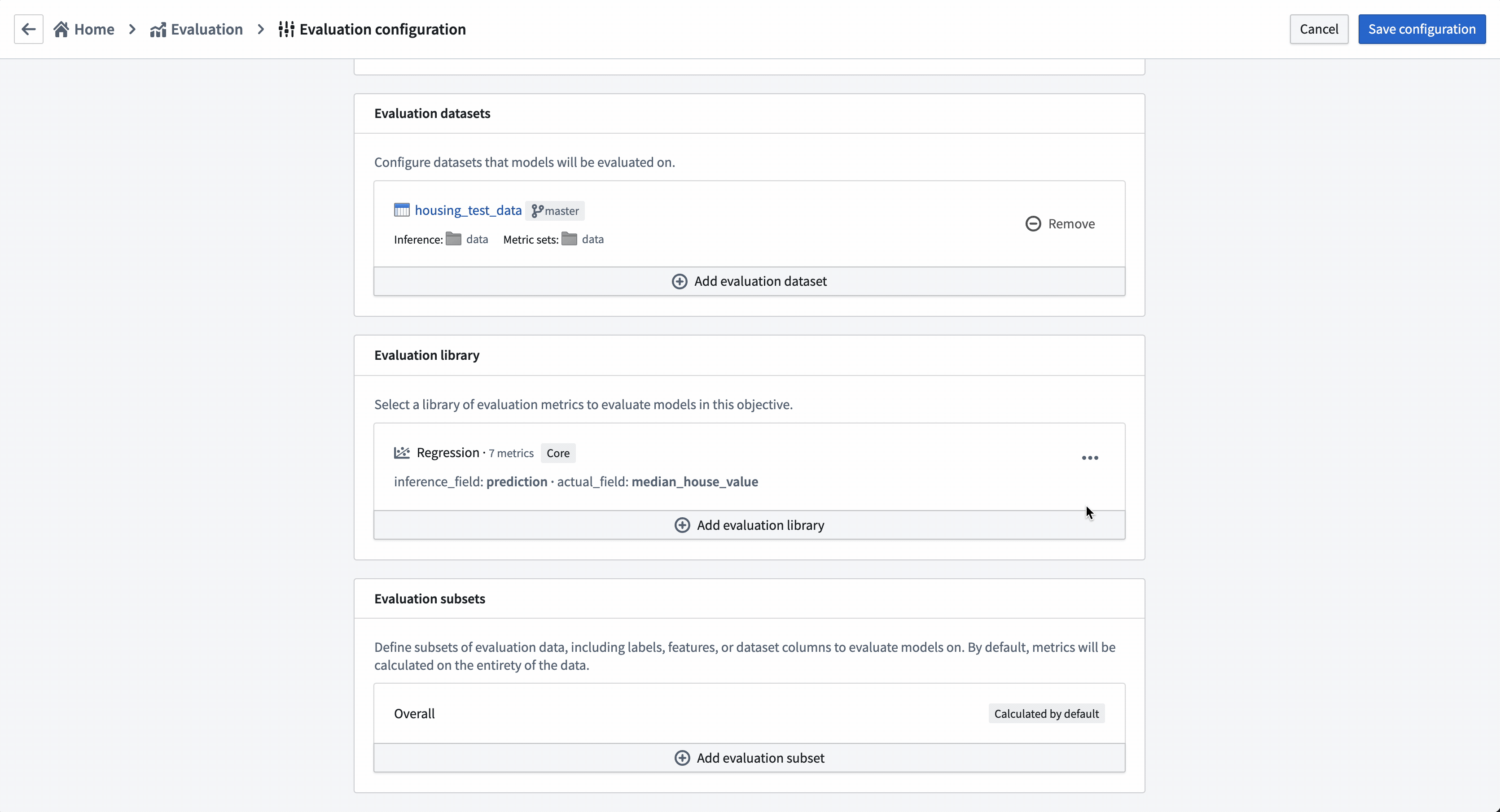
このモデリングの目的に追加されたすべてのモデルを評価するには、すべてのモデル提出が一貫して評価スコアを生成する必要があります。このモデリングの目的では、すべてのモデルが prediction という名前の推論列を float 型で生成することを期待します。
アクション: 評価ライブラリの選択 を選択し、次に 回帰デフォルトライブラリ を選択します。推論フィールドを prediction の float 型として設定し、実際のフィールド(推定しようとしているプロパティ)を median_house_value として設定し、ヒストグラムビン は空のままにします。保存 を選択して評価ライブラリの設定を保存します。
評価サブセットの設定
評価サブセットの設定は、特定の評価データの部分に対して個別にメトリクスを生成できるようにするモデル評価のオプションのステップです。これらのメトリクスはすべて評価ダッシュボードで個別に分析できます。
評価サブセットを有効にする理由は次のとおりです。
- データのセグメントによってモデルのパフォーマンスが異なるかどうかを理解したい場合。これにより、このモデルを生産で使用すべき範囲を把握できます。
- モデルがうまく機能しない部分があるかどうかを理解したい場合。これにより、今後の開発努力を集中させることができます。
- モデルが評価データ内の保護されたグループに対して偏りがないことを確認したい場合。
この場合、平均住宅年齢が 5 年未満または 30 年以上の場所でモデルのパフォーマンスを調べます。
アクション: 評価サブセットの追加 を選択し、housing_median_age フィールドを選択します。これは数値フィールドであるため、使用する定量的なバケッティング戦略を定義できます。この例では、範囲のカットオフ を使用し、バケットを 5 と 30 に設定します。アクション: サブセット設定を 保存 します。
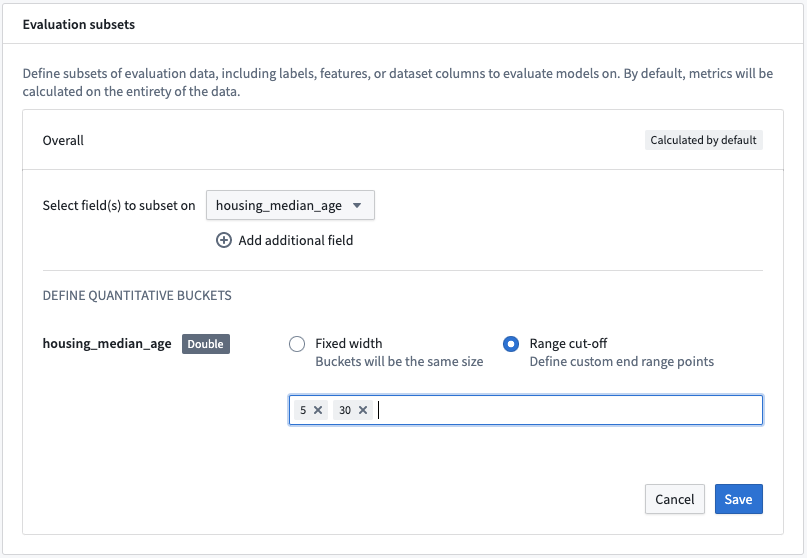
このサブセット設定により、各評価データセットで 4 個の異なるデータセットでモデルが評価されます。
全体: これは評価データセット全体です。housing_median_age (<5):housing_median_ageが 5 未満の評価データセット。housing_median_age (>= 5, < 30):housing_median_ageが 5 以上 30 未満の評価データセット。housing_median_age (>= 30):housing_median_ageが 30 以上の評価データセット。
これにより、housing_median_age が異なる場合にモデルが同様に動作しているかどうかを判断できます。
アクション: ページの右上にある 設定を保存 を選択して設定を保存し、評価ダッシュボードに戻ります。これ以降、モデリングの目的に提出された任意のモデルは、自動的に推論およびメトリクスデータセットを生成および構築し、モデルの評価に使用できます。
3.3 メトリクスパイプラインの構築方法
メトリクスパイプラインを設定すると、モデルをこのモデリングの目的に提出するたびに、推論データセットとメトリクスデータセットが作成され、開始されます。設定されている場合、Foundry はこれらのデータセットを自動的に実行し、モデリングの目的の評価ダッシュボードにメトリクスを追加します。
この場合、すでにモデルをこの目的に追加していたため、これらのデータセットの構築を手動で開始する必要があります。
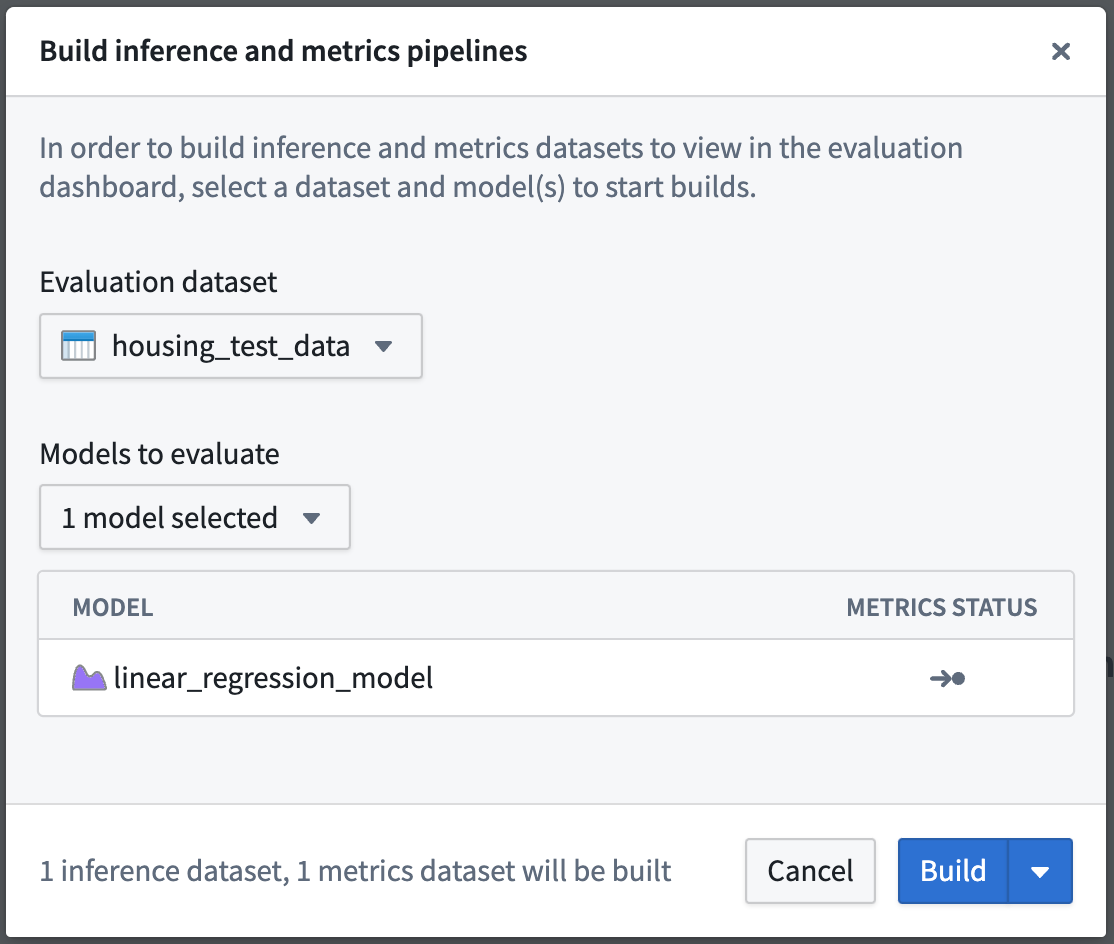
アクション: 評価ダッシュボードの右上にある 評価の構築 を選択し、評価ダッシュボードとして housing_test_data を選択し、評価するモデルとして linear_regression_model を選択します。次に 構築 を選択して推論およびメトリクスのビルドを開始します。
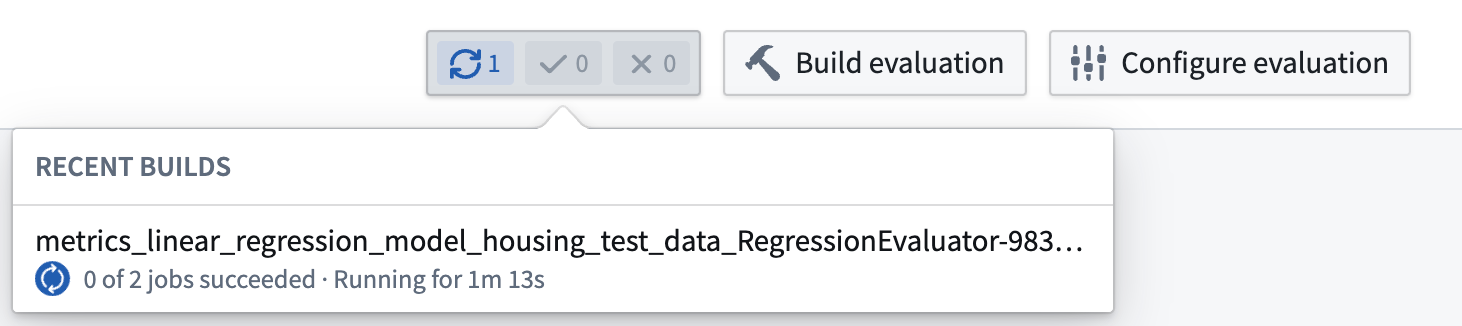
評価パイプラインの作成には数分かかる場合があります。構築 アクションがアクティブになるまで待つ必要があるかもしれません。
ビルドが開始されると、評価ダッシュボードの右上にある最近のビルドドロップダウンを見て、ビルドの進行状況を確認できます。
Foundry インスタンスの負荷によっては、評価パイプラインの実行に数分かかる場合があります。
3.4 評価ダッシュボードでのモデル評価方法
このチュートリアルを進める前に、評価ダッシュボードで推論およびメトリクスデータセットのビルドが正常に完了している必要があります。メトリクスが完了すると、モデリングの目的に追加されたすべてのモデルのメトリクスを表示および比較できるようになります。これにより、モデリングプロジェクトのパフォーマンスの集中管理ソースが作成されます。
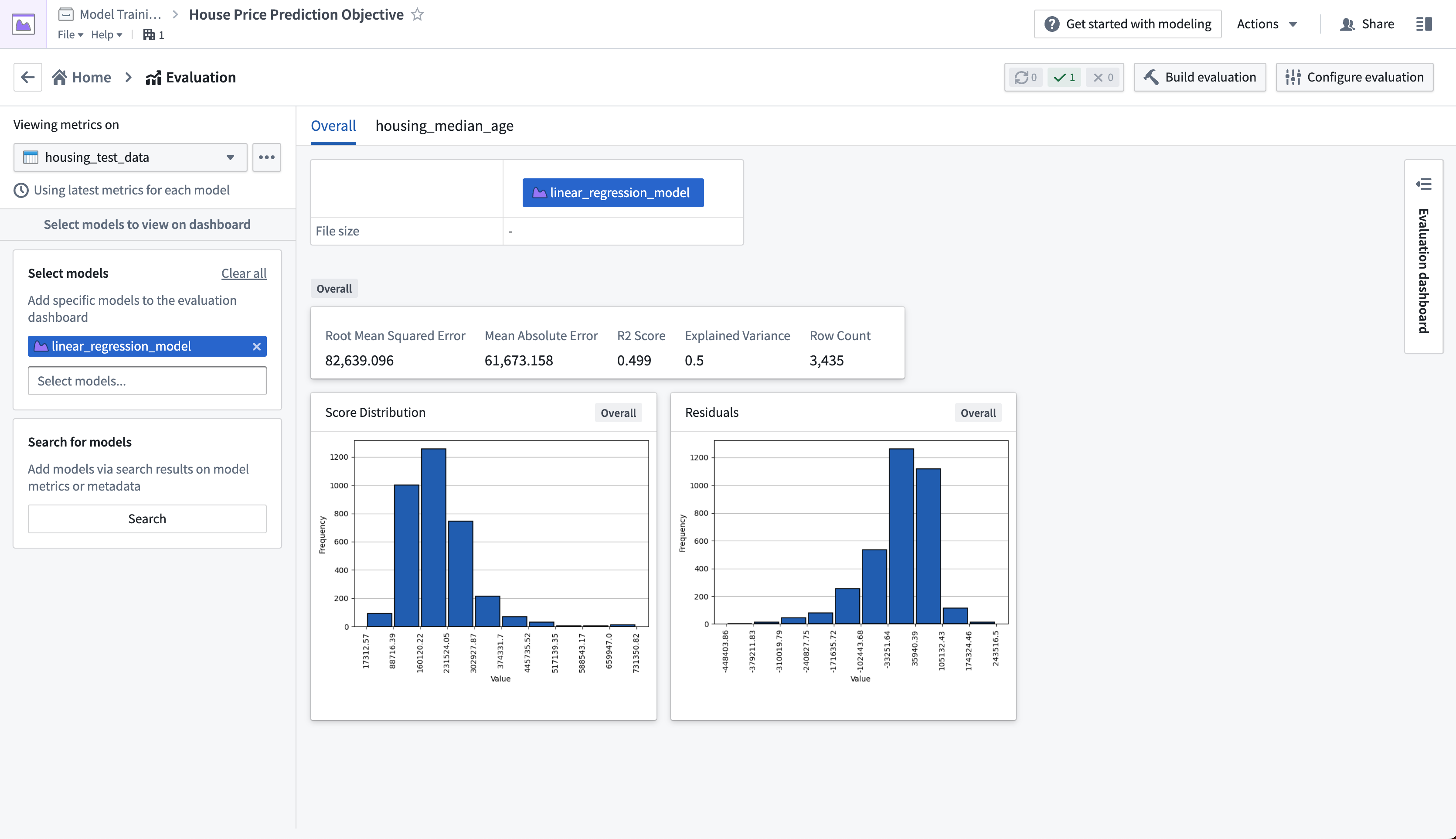
回帰評価ライブラリでは、評価ダッシュボードで利用可能なさまざまなメトリクスが生成されました。これらのメトリクスは、テストデータに対するモデルのラベル(国勢調査地区の中央値住宅価格)をどれだけ正確に予測できるかを理解するのに役立ちます。
どのメトリクスを使用するか、および適切なパフォーマンスとは何かを決定することはプロジェクトごとに異なります。このプロセスには通常、ステークホルダーとの議論が必要ですが、架空の例では、このモデルが十分に良好に動作していると仮定します。この場合、82639.10 の二乗平均平方根誤差は、モデルの予測がテストデータのラベルから平均で $82,639.10 離れていることを意味します。
アクション: ページを更新し、左側のバーのデータセットセレクターで housing_test_dataset データセット を選択し、モデルセレクターで linear_regression_model を選択します。
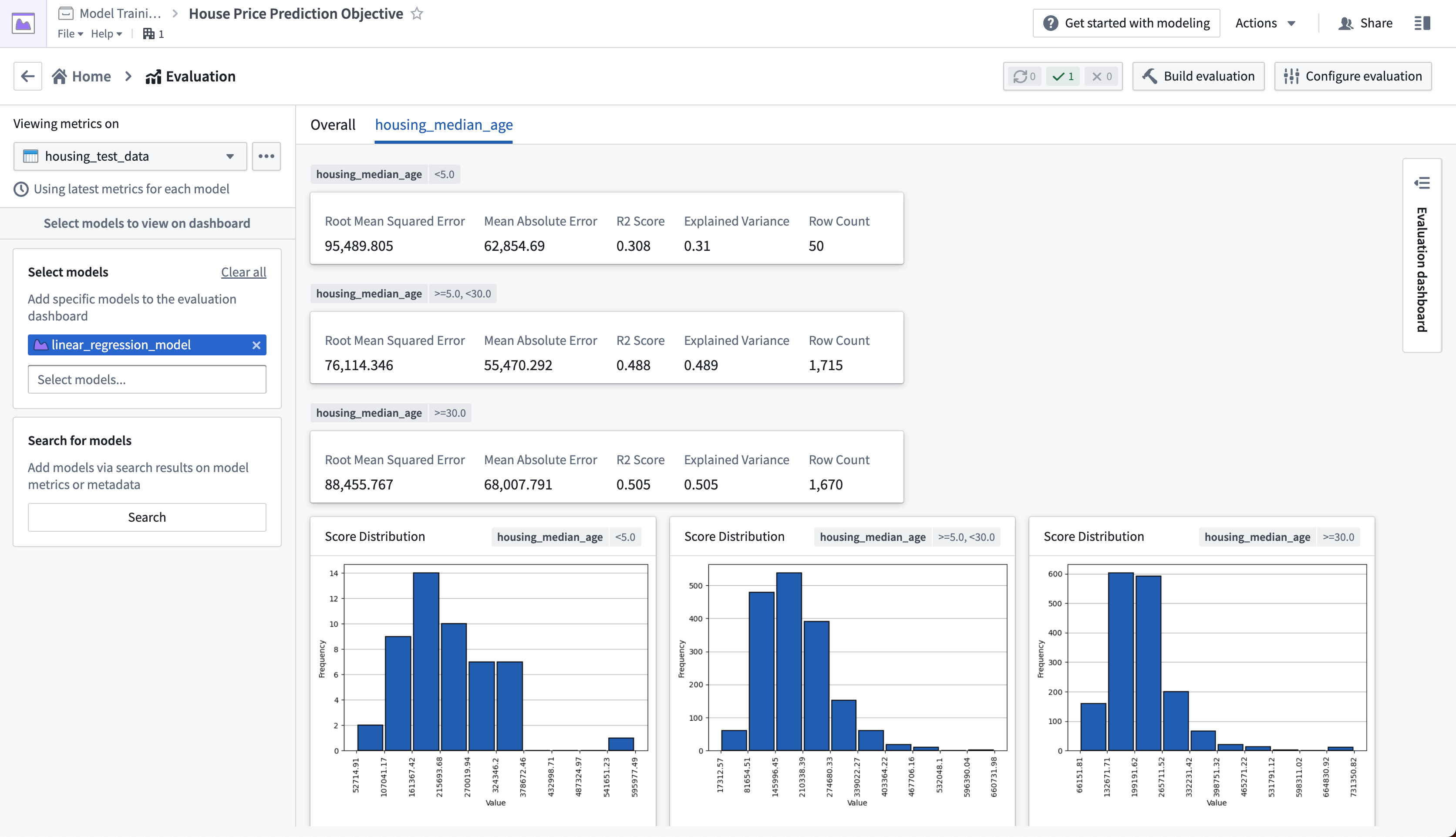
評価ダッシュボードは、前述のサブセットごとにモデルのパフォーマンスも表示します。評価ダッシュボードのタブは、利用可能なサブセットグループを反映しており、これらのメトリクスを確認できます。この場合、モデルが housing_median_age が 5 歳から 30 歳の間で最も良く動作することがわかります。
アクション: 評価ダッシュボードの上部にある housing_median_age タブを選択します。
次のステップ
機械学習モデルを評価したので、このモデルをプロダクションアプリケーションに統合できます。モデルをプロダクション化する チュートリアルをレビューしてください。