Warning
注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
結論と次のステップ
このチュートリアルでは、Foundryで監督機械学習プロジェクトを作成しました。その中で、以下の作業を行いました。
- 反復的なモデル実験と開発のためのプロジェクトを作成しました。
- 初期の特徴量の準備とパイプライン処理を行いました。
- 本番環境で使用可能なモデルを学習しました。
- ライブホストされたエンドポイントと自動更新されるバッチパイプラインにモデルをデプロイしました。
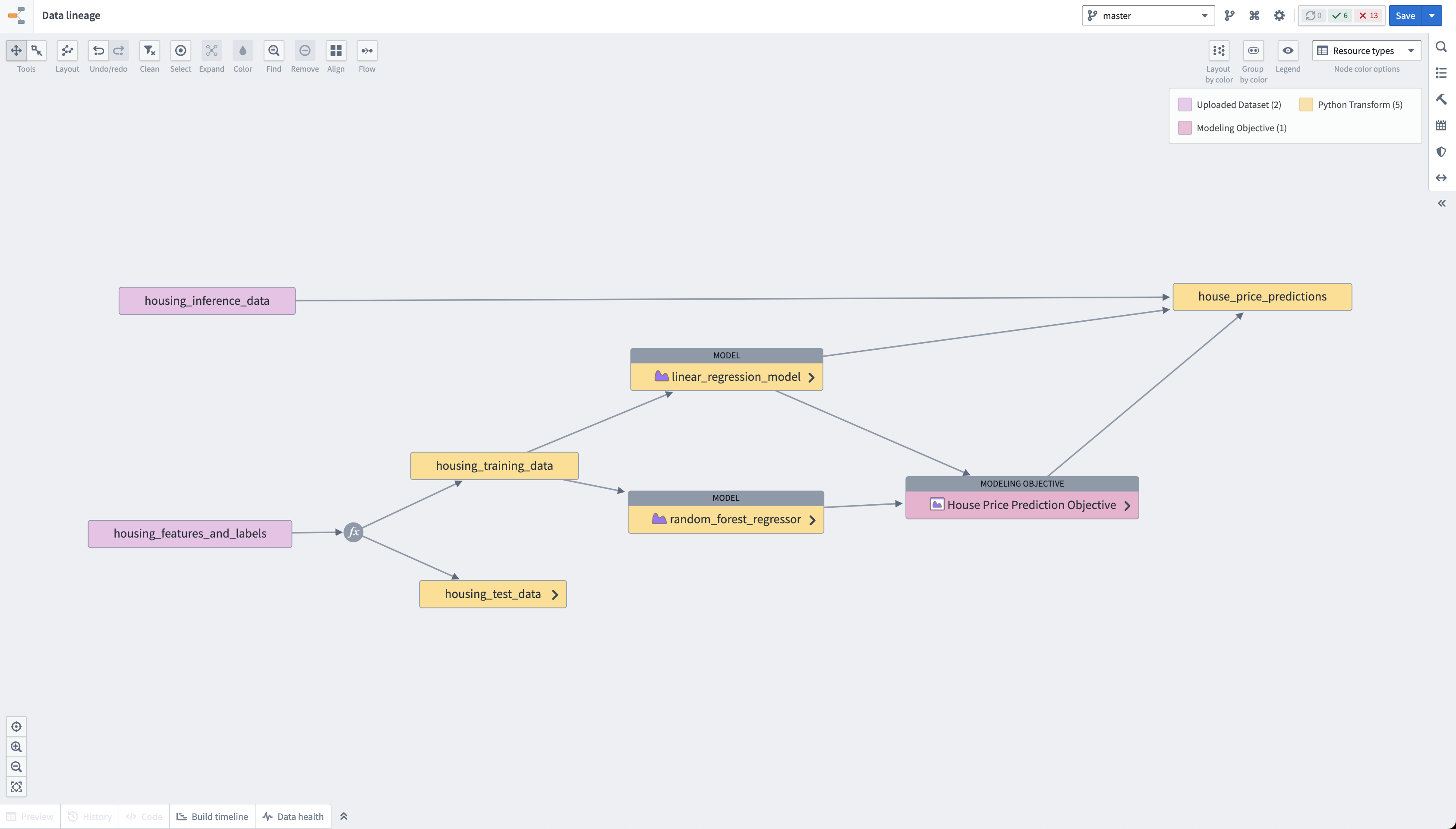
Foundryは、プラットフォーム内で生成されるすべてのリソースのデータフローを自動的に追跡します。このチュートリアルの最後には、以下のスクリーンショットに示すようなパイプラインができあがります。
アクション: house_price_predictionsデータセットに移動し、Explore pipelines > Explore data lineage を選択します。
次のステップ
次のステップは、この例のワークフローを組織の実際のワークフローに変換することです。
これには通常、以下の作業が含まれます。
- Foundryにさまざまなデータソースからのデータを統合し、
features_and_labelsデータセットを作成して、さまざまなモデルの学習とテストに使用できるようにします。 - 最適なモデルのパフォーマンスを得るために、異なるモデルアーキテクチャ、パラメーター、および特徴量を試してみてください。
- バッチデプロイメント、ライブデプロイメント、またはPythonトランスフォームを使用して、モデルの予測をFoundryオントロジーに統合し、運用アプリケーションで使用できるようにします。
- リリース前のチェックを作成して、モデリングの目的でモデルがリリース前に承認されることを確認します。
- 「書き戻し」アクションを作成して、ユーザーのアクションを新しいデータセットとしてキャプチャし、このデータを使用してモデルの継続的な再学習と改善を行います。
- モデル推論履歴を作成して、より正確なパフォーマンスと使用のためにモデルを改善・反復処理します。