注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
ライブデプロイメントの設定と利用
ライブデプロイメントは、APIエンドポイントを通じてユーザーが操作できる、リリース用の持続可能でスケーラブルなデプロイメントです。 ライブデプロイメントは、自動アップグレード、観測可能性、権限構造の全ての利点を享受しながら、バッチデプロイメントと共にモデリングの目的で管理できます。
必要条件
新しいライブデプロイメントを作成する前に、モデリングの目的には対応するタグ(StagingまたはProduction)を持つ既存のリリースが含まれていなければなりません。
一部の環境では、TypeScript Functions をライブデプロイメントを通じて利用可能にするサポートが提供されています。ライブデプロイメントで TypeScript Functions を使用する方法について詳しく学びましょう。
デプロイメントの作成
新しいライブデプロイメントを作成するには、ユーザーのモデリングの目的の下部にあるDeploymentsセクションに移動し、青い**+ Create a deployment**ボタンを選択します。
デプロイメントの名前、説明、そしてこのデプロイメントが現在のステージングモデルまたはプロダクションモデルに基づいているかどうかを入力します。設定が完了したら、Create deploymentをクリックします。
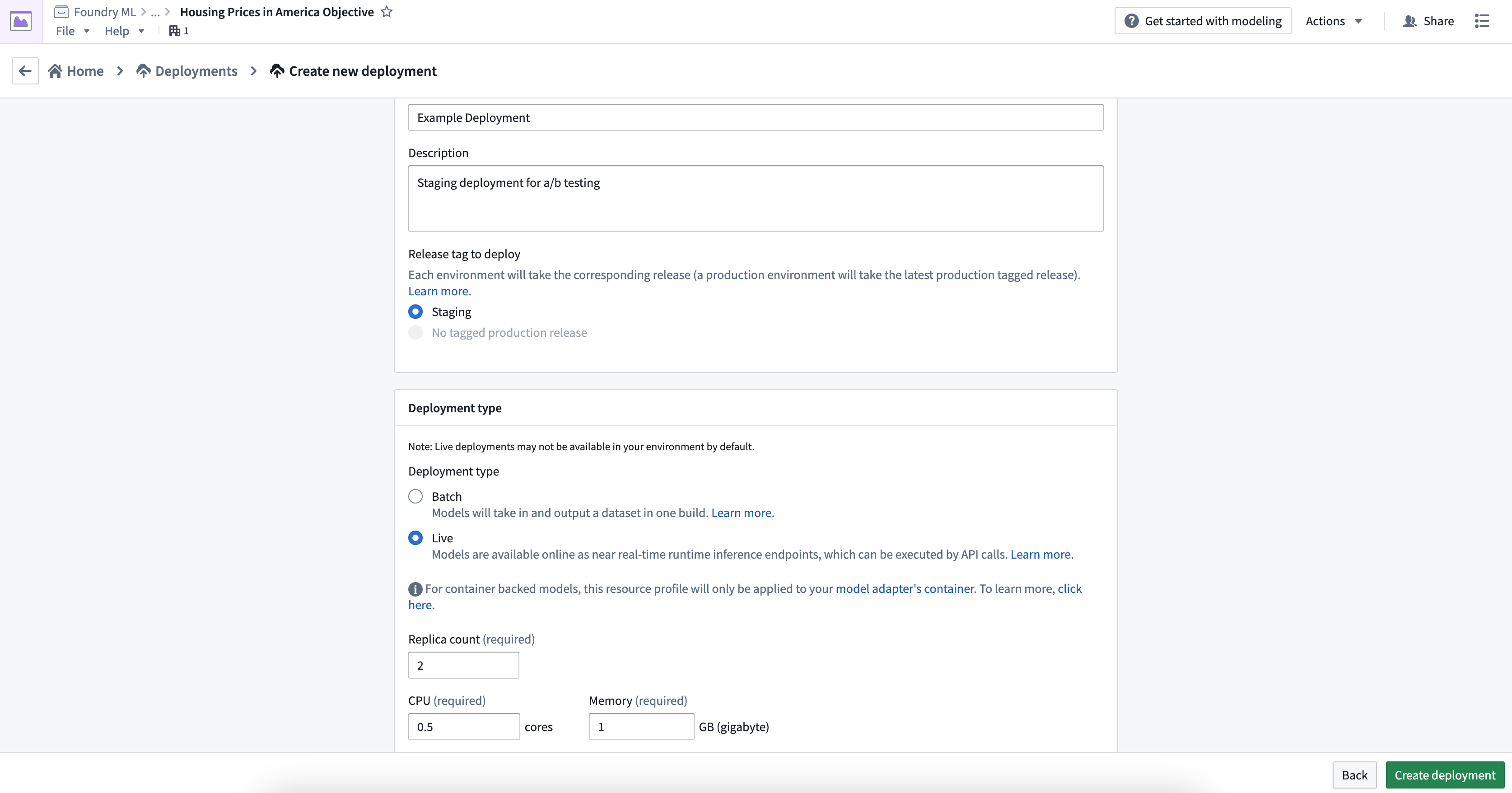
新しく作成したデプロイメントを選択して詳細を開きます。そこでは、最新のリリースと推論コードを含むコンテナイメージがデプロイされていることを示す中間ステータスを確認できます。
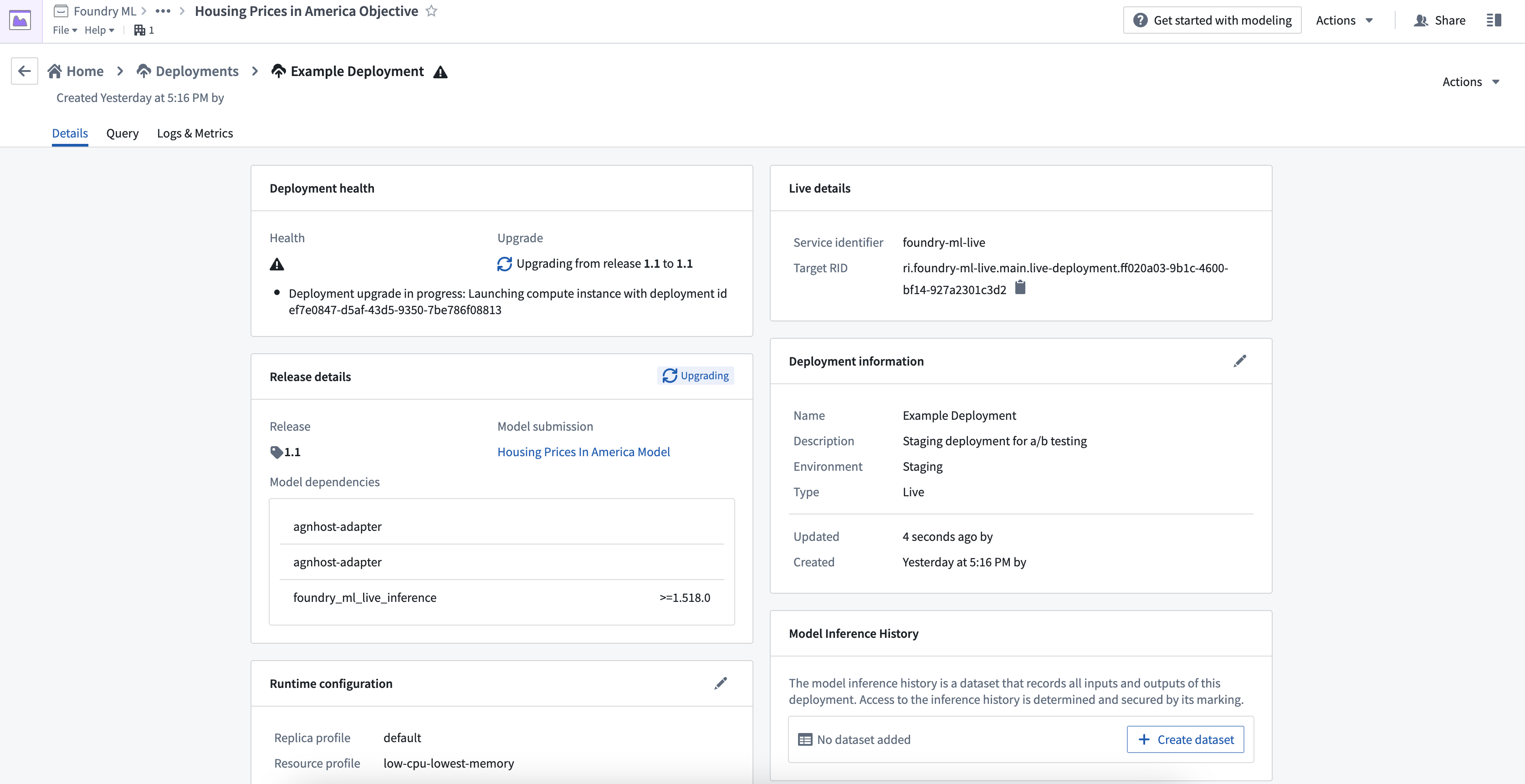
API名
Functions on modelsを用いたモデルの運用化には、デプロイメントのAPI名を定義する必要があります。API名は、デプロイメントが存在するspace内でユニークでなければなりません。API名を定義するには、API Nameの隣にある鉛筆アイコンを選択します。
ステータスとヘルス
デプロイメントの更新が完了した後、ステータスとヘルスは両方とも緑色のチェックマークとして表示されるはずです。これらは、デプロイメントがクエリの準備ができており、最新のリリースモデルが成功裏に含まれていることを示しています。

ライブデプロイメントのテスト
デプロイメント詳細ページのQueryタブに移動することで、ライブデプロイメントエンドポイントをテストできます。ユーザーは入力リクエストを作成し、それをライブエンドポイントに送信し、モデル出力レスポンスを表示できます。利用可能なクエリタイプは2つあります:single I/Oとmulti I/O。
Single I/Oクエリは単一の表形式の入力/出力のみをサポートし、multi I/Oクエリはモデルアセットで定義されたModelAdapter APIのみをサポートします。モデルアセットはsingle I/Oとmulti I/Oの両方のクエリタイプをサポートしていますが、データセットを利用したデプロイメントはsingle I/Oクエリのみをサポートしています。
例:コマンド
以下に、transformエンドポイントでsingle I/Oを使用してcurlを通じてライブデプロイメントをクエリする例を示します:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17# 'curl' コマンドを使用して HTTP POST リクエストを送信します。 # このリクエストは、特定の URL (https://<URL>/foundry-ml-live/api/inference/transform/ri.foundry-ml-live.main.live-deployment.<RID>) に対して送信されます。 curl -X POST https://<URL>/foundry-ml-live/api/inference/transform/ri.foundry-ml-live.main.live-deployment.<RID> # このリクエストは "Authorization" というヘッダーに "BEARER_TOKEN" を含みます。 -H "Authorization: <BEARER_TOKEN>" # "Accept" ヘッダーは、クライアントが理解できるレスポンスの種類をサーバーに通知します。この場合、クライアントは "application/json" 形式のレスポンスを受け取ることができます。 -H "Accept: application/json" # "Content-Type" ヘッダーは、送信するデータのメディアタイプを指定します。この場合、データは "application/json" 形式です。 -H "Content-Type: application/json" # '-d' オプションは、POST リクエストで送信するデータを指定します。ここでは JSON 形式のデータを送信しています。 # このデータには、リクエストに必要な情報(家の場所、ベッドルームの数、バスルームの数)が含まれています。 -d '{"requestData":[{"house-location":"New York", "bedrooms":3,"bathrooms":1.5}], "requestParams":{}}'
その代わりに、以下の例は、transformV2エンドポイントを使用してmulti I/Oでcurlを使ってライブデプロイメントをクエリする方法を示しています:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15# 以下のコードは、curl コマンドを使用して HTTP POST リクエストを送信します。その URL は機械学習モデルがデプロイされている場所を指しています。 # このリクエストは、モデルに対して新しいデータ("input_df")を送信し、その結果を取得する目的があります。 # データは JSON 形式で、2つの住宅に関する情報(場所、ベッドルーム数、バスルーム数)を含んでいます。 curl -X POST https://<URL>/foundry-ml-live/api/inference/transform/ri.foundry-ml-live.main.live-deployment.<RID>/v2 -H "Authorization: <BEARER_TOKEN>" -H "Accept: application/json" -H "Content-Type: application/json" -d '{"input_df":[{"house-location":"New York", "bedrooms":3,"bathrooms":1.5},{"house-location":"San Francisco", "bedrooms":2,"bathrooms":1}]}' # ここで、 # -X POST: HTTP POST メソッドを指定 # -H: ヘッダー情報を指定 # "Authorization: <BEARER_TOKEN>": 認証トークンを提供 # "Accept: application/json": クライアントが受け入れ可能なレスポンスの形式を指定 # "Content-Type: application/json": 送信するデータの形式を指定 # -d: 送信するデータを指定
Copied!1tags.node_id:{ここにUUIDを挿入} # UUIDを挿入するためのプレースホルダー
モデルから直接ログを出力するには、標準の Python ロギングモジュールを使用できます。ライブデプロイメントでは、各ログ行をログ & メトリクス タブからクエリ可能になります。
Copied!1 2 3 4 5 6import logging # 'model-logger'という名前のロガーを取得します log = logging.getLogger('model-logger') # モデルから直接情報を出力します log.info("Emitting info directly from the model")
コンテナを利用したモデルからログを出力するには、モデルバージョンの設定でテレメトリーを有効にします。
ユーザーのライブデプロイメントからのログは、7日間保持された後、閲覧やダウンロードができなくなります。
デプロイメントメトリクスの表示
ログ&メトリクスタブには、Kubernetes ホストと推論コンテナの2種類のメトリクスが提供されています。モデルを適切に監視およびデバッグするためには、これらのメトリクスの種類の違いを理解しておく必要があります。
Kubernetes ホストメトリクス
Kubernetes ホストメトリクスは、ホスト上で実行されているすべてのプロセスによって使用されているメモリと CPU 使用率のパーセンテージを表示します。これは特定のモデルに関連するプロセスだけでなく、スケジューリングやリソースの制限に関連する問題のデバッグに重要です。たとえば、ユーザーのモデルのパフォーマンスが遅いがホストメトリクスが 100% の場合、モデルが Kubernetes ホストによって制限されている可能性があります。
推論コンテナメトリクス
推論コンテナメトリクスは、Python モデルやモデルアダプタロジックのリソース使用状況のデバッグに役立ちます。これらのメトリクスは、推論コンテナの正確なメモリ使用量と CPU コア使用量を提供し、Kubernetes ホスト全体とは独立しています。現在、コンテナベースのモデルには使用メトリクスは利用できません。
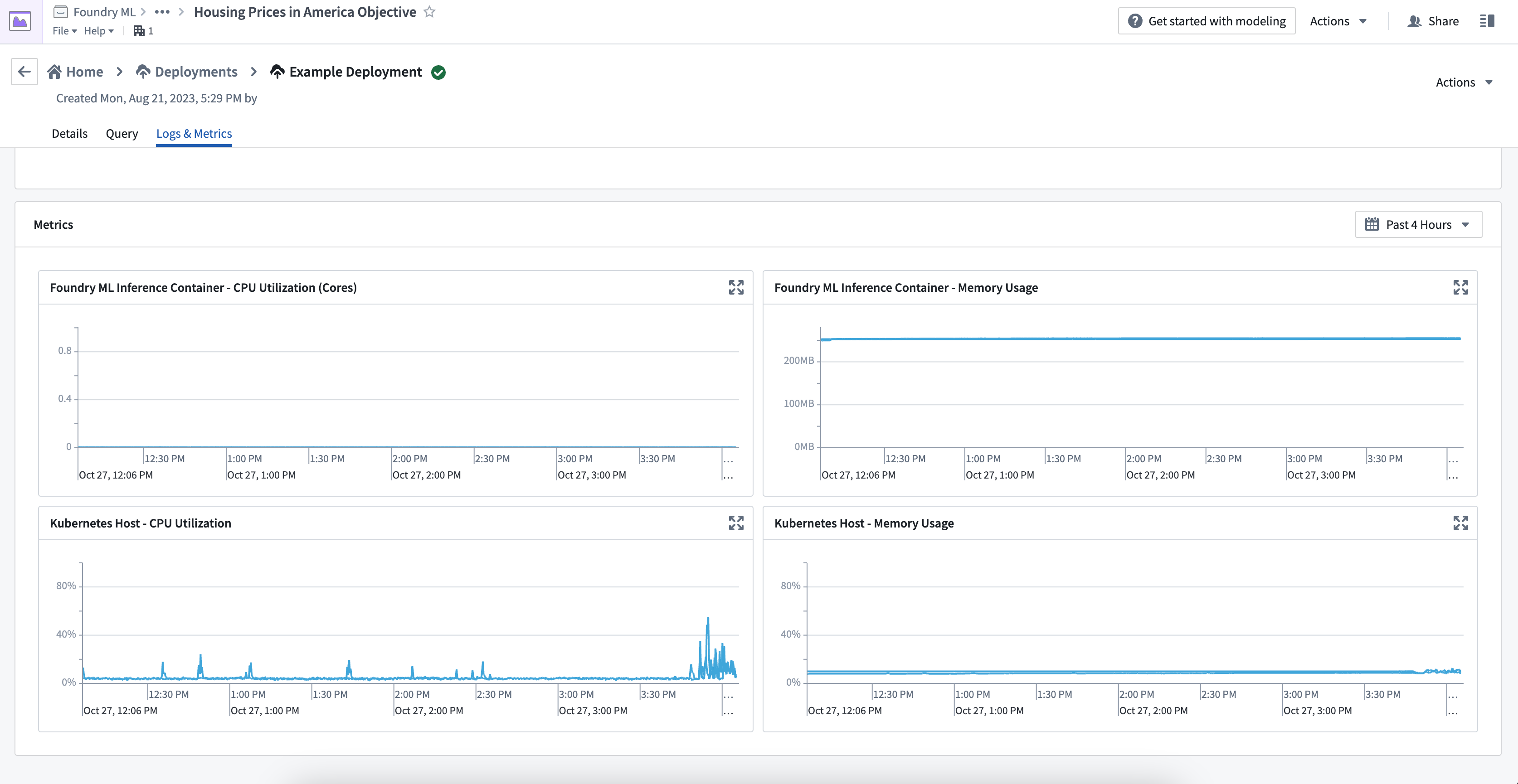
Kubernates ホストメトリクスのみが表示されており、推論コンテナメトリクスが表示されていない場合、コンテナが古いバージョンのライブデプロイメントで実行されている可能性があります。ライブデプロイメントを再起動してバージョンを更新し、すべてのメトリクスを表示してください。
Spark モデルのサポート
サポートされる Spark のバージョンは今後のバージョンで変更される可能性があり、後方互換性は保証されません。モデルが現在の Spark バージョンと互換性がない場合、再構築が必要になる場合があります。
現在、すべてのライブデプロイメントには、JDK と Spark のディストリビューションがインストールされて初期化されます。これにより、Spark モデルがライブデプロイメントと互換性を持つようになります。この対話型環境では、ローカル Spark のみがサポートされており、すべての処理は単一の JVM 内で行われます。
ライブデプロイメントでは、入力と出力のタイプが Pandas のデータフレームであることが期待されているため、foundry_ml Python ライブラリは、モデルが標準的なサポートされている PySpark モデルである限り、ユーザーの Spark モデルをラップします。データフレームをどちらかの方向に変換する際には、特にカスタム Spark タイプを扱う場合、データ型の変換に関する問題が発生する可能性があります。
Spark データフレームを予期しているカスタムモデルを開発する場合、前処理ステージや transform 関数内でこの変換を手動で実行する必要があります。以下に簡単な例を示します。
Copied!1 2 3 4 5 6 7 8 9 10 11import pandas as pd from pyspark.sql import SparkSession # モデルとデータフレームを引数に取る_transform関数を定義します def _transform(model, df): # もしdfがpandasのデータフレームなら if isinstance(df, pd.DataFrame): # SparkSessionを作成し(もしくは既存のものを取得し)、その上でデータフレームを作成します df = SparkSession.builder.getOrCreate().createDataFrame(df) # モデルを使ってSparkデータフレームに対して予測を行い、その結果を返します return model.predict_spark_df(df)