注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
Copied!1 2 3 4 5{ "inference_data": [{ // 推論データ "text": "<Text goes here>" // ここにテキストが入ります }] }
モデルは output_data という名前のデータセットを返し、それには prediction 列が含まれています。これは次のような応答に変換されます:
Copied!1 2 3 4 5{ "output_data": [{ // "output_data"は出力データを表す "prediction": "<Model prediction here>" // "prediction"はモデルの予測結果を表す }] }
例: curl
Copied!1 2 3 4 5 6# HTTP/2 を使用してリクエストを送信します # "Content-Type: application/json" と "Authorization: <BEARER_TOKEN>" というヘッダーを付けています # データとして JSON を送信します。ここでは "inference_data" というキーの値としてテキストのリストを送ります # このリクエストは POST で行います # 送信先の URL は <ENVIRONMENT_URL>/foundry-ml-live/api/inference/transform/ri.foundry-ml-live.<LIVE_DEPLOYMENT_RID> です curl --http2 -H "Content-Type: application/json" -H "Authorization: <BEARER_TOKEN>" -d '{ "inference_data": [ { "text": "Hello, how are you?" } ] }' --request POST <ENVIRONMENT_URL>/foundry-ml-live/api/inference/transform/ri.foundry-ml-live.<LIVE_DEPLOYMENT_RID>
例:Python
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18import requests # 環境URLを指定します url = '<ENVIRONMENT_URL>/foundry-ml-live/api/inference/transform/ri.foundry-ml-live.<LIVE_DEPLOYMENT_RID>/v2' # 推論リクエストのデータを作成します inference_request = { 'inference_data': [ { 'text': 'Hello, how are you?' } ] } # POSTリクエストを送信します。ヘッダーにはContent-TypeとAuthorizationを指定します response = requests.post(url, json = inference_request, headers = { 'Content-Type': 'application/json', 'Authorization': 'Bearer <BEARER_TOKEN>' }) # レスポンスが正常であれば、モデルの結果を表示します if response.ok: modelResult = response.json() print(modelResult) # レスポンスが異常であれば、エラーメッセージを表示します else: print("エラーが発生しました")
例:JavaScript(Node.js 18を使用)
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28// リクエストの構築 const inferenceRequest = { "inference_data": [{ "text": "Hello, how are you?" }] }; // リクエストを送信 const response = await fetch( "<ENVIRONMENT_URL>/foundry-ml-live/api/inference/transform/ri.foundry-ml-live.<RID>/v2", { method: "POST", // POSTメソッドを使用 headers: { "Content-Type": "application/json", // コンテンツタイプはJSON Authorization: // 認証 "Bearer <BEARER_TOKEN>", }, body: JSON.stringify(inferenceRequest), // リクエストボディをJSON形式に変換 } ); if (!response.ok) { // レスポンスがOKでなければエラーを投げる throw Error(`${response.status}: ${response.statusText}`); } const result = await response.json(); // レスポンスをJSONとして解析 console.log(result); // 結果をコンソールに出力
例:マルチ I/O モデル
マルチ I/O モデルは、複数の入力を受け取り、複数の出力を返すことができます。以下の画像は、複数の入力と出力を持つモデルの例を示しています:
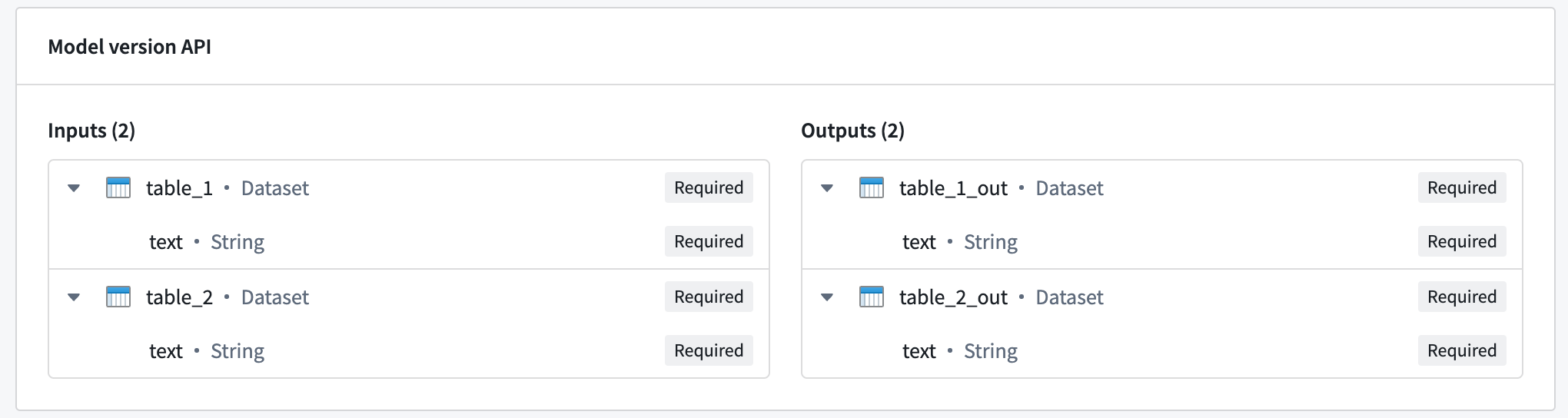
マルチ I/O をクエリするには、前の例で示したのと同じリクエスト形式を使用し、inference_request には各入力の名前付きフィールドを含めます:
Copied!1 2 3 4{ "table_1": [{ "text": "Text for table one" }], // "table_1": [{"text": "テーブル1のためのテキスト"}] "table_2": [{ "text": "Text for table two" }] // "table_2": [{"text": "テーブル2のためのテキスト"}] }
モデルは、各出力に対応する名前付きフィールドを含むオブジェクトを返答します:
Copied!1 2 3 4{ "table_1_out": [{ "text": "Result for table one" }], // "table_1_out"は、"table oneの結果"を表すテキストです "table_2_out": [{ "text": "Result for table two" }], // "table_2_out"は、"table twoの結果"を表すテキストです }
シングル I/O エンドポイント
シングル I/O エンドポイントは、マルチ I/O モデルをサポートしていません。
foundry_mlでパッケージ化されたすべてのモデルは、シングル I/O エンドポイントを使用する必要があります。
- URL:
<ENVIRONMENT_URL>/foundry-ml-live/api/inference/transform/ri.foundry-ml-live.<LIVE_DEPLOYMENT_RID> <ENVIRONMENT_URL>: 詳細については、下記のセクションを参照してください。- HTTP メソッド:
POST - 認証タイプ: ベアラートークン
- 必要な HTTP ヘッダー:
Content-Type:"application/json"である必要があります。Authorization:"Bearer <BEARER_TOKEN>"である必要があります。ここで、<BEARER_TOKEN>はユーザーの認証トークンです。
- リクエストボディ: 以下のフィールドを含む JSON オブジェクト:
requestData: モデルに送信する情報を含む配列。これの期待される形状は、デプロイされたモデルの API に依存します。requestParams: モデルに送信するリクエストパラメーターを含むオブジェクト。これはfoundry_mlでパッケージ化されたモデルにのみ使用され、これの期待される形状もデプロイされたモデルの API に依存します。
- レスポンス: 成功したレスポンスは、ステータスコード
200と以下のフィールドを含む JSON オブジェクトを返します:modelUuid: モデルを識別する文字列。responseData: 各オブジェクトがモデルの推論レスポンスを表すオブジェクトの配列。これらのオブジェクトの形状は、デプロイされたモデルの API に依存します。
例: シングル I/O エンドポイントを使用してライブデプロイメントをクエリする
以下の例では、シングルの入力と出力のシンプルな API を持つモデルを使用します。
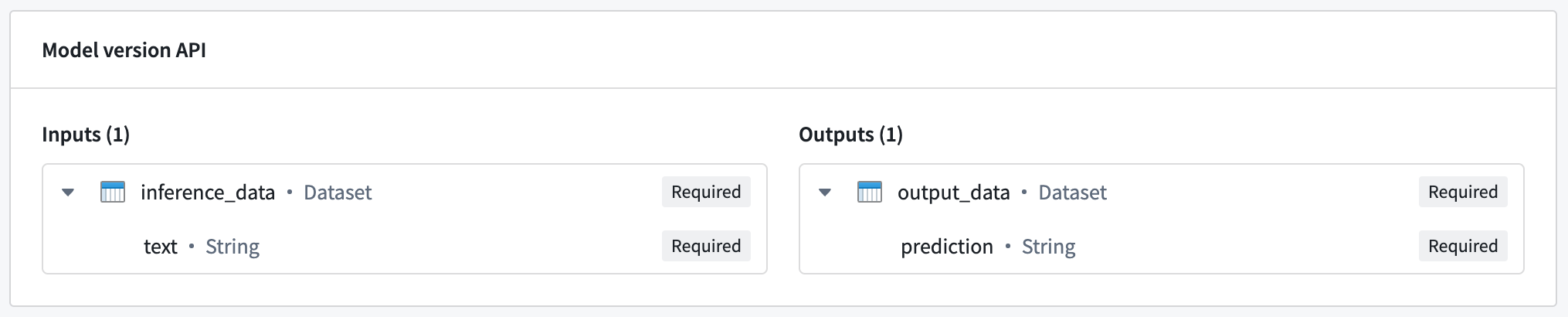
この例のホストされたモデルは、text列を含むデータセットである inference_dataという名前のシングル入力を期待します。この場合、期待されるリクエスト形式は以下の通りです:
Copied!1 2 3 4{ "requestData": [{ "text": "<Text goes here>" }], // "requestData"はリクエストデータを含む配列です。"text"は送信するテキストを表します。 "requestParams": {}, // "requestParams"はリクエストパラメータを含むオブジェクトです。現在は空ですが、必要に応じてパラメータを追加できます。 }
Copied!1 2 3 4 5 6{ "modelUuid": "000-000-000", // モデルのUUID(一意識別子) "responseData": [{ "prediction": "<Model prediction here>" // モデルの予測結果 }] }
Copied!1 2 3 4 5 6 7 8 9 10 11 12# cURLコマンドを使用してHTTPリクエストを送信します。このリクエストはHTTP/2を使用します。 # "Content-Type: application/json"というヘッダーは、送信するデータがJSON形式であることを示しています。 # "Authorization: <BEARER_TOKEN>"というヘッダーは、認証トークンを使用してリクエストを認証します。 curl --http2 -H "Content-Type: application/json" -H "Authorization: <BEARER_TOKEN>" -d '{ # requestDataは送信するデータを含む配列で、テキストメッセージが含まれています。 "requestData":[ { "text": "Hello, how are you?" } ], # requestParamsは追加のパラメータを指定するためのオブジェクトです。ここでは空です。 "requestParams":{} }' --request POST <ENVIRONMENT_URL>/foundry-ml-live/api/inference/transform/ri.foundry-ml-live.<RID> # リクエストメソッドはPOSTで、送信先URLは<ENVIRONMENT_URL>/foundry-ml-live/api/inference/transform/ri.foundry-ml-live.<RID>です。 # <ENVIRONMENT_URL>は環境のURLを、<RID>はリソースIDを表します。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21import requests # 推論のためのAPIエンドポイント url = '<ENVIRONMENT_URL>/foundry-ml-live/api/inference/transform/ri.foundry-ml-live.<RID>' # 推論リクエストを作成 inference_request = { 'requestData': [{ 'text': 'Hello, how are you?' }], # 推論に使用するテキストデータ 'requestParams': {}, # リクエストパラメータ(ここでは使用していない) } # APIにリクエストを送信し、レスポンスを受け取る response = requests.post(url, json = inference_request, headers = { 'Content-Type': 'application/json', 'Authorization': 'Bearer <BEARER_TOKEN>' }) # レスポンスが正常な場合、モデルの結果を表示 if response.ok: modelResult = response.json()['responseData'] print(modelResult) else: # エラーが発生した場合、エラーメッセージを表示 print("An error occurred")
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30// リクエストを構成します const inferenceRequest = { requestData: [{ text: "こんにちは、お元気ですか?" }], requestParams: {}, }; // リクエストを送信します const response = await fetch( "<ENVIRONMENT_URL>/foundry-ml-live/api/inference/transform/ri.foundry-ml-live.<RID>", { method: "POST", // POSTメソッドを使用 headers: { "Content-Type": "application/json", // コンテンツタイプはJSON Authorization: // 認証トークンを含む "Bearer <BEARER_TOKEN>", }, body: JSON.stringify(inferenceRequest), // リクエストボディに構成したリクエストをJSON形式で送信 } ); // レスポンスがOKでない場合、エラーを投げます if (!response.ok) { throw Error(`${response.status}: ${response.statusText}`); } // レスポンスをJSON形式で取得します const result = await response.json(); // レスポンスデータをコンソールに表示します console.log(result.responseData);
環境URL
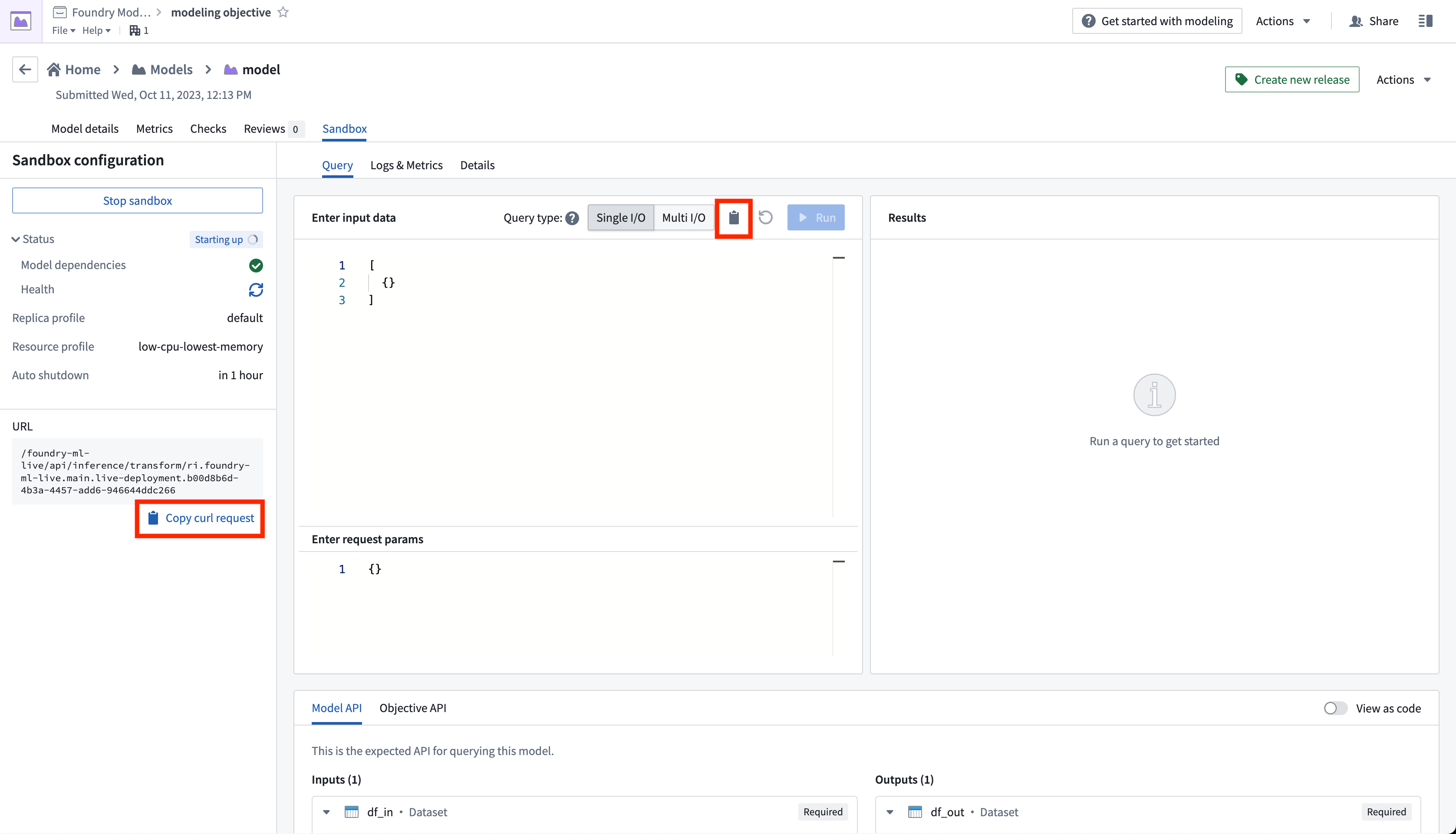
上記の例では、<ENVIRONMENT_URL>プレースホルダーはユーザーの環境のURLを表します。環境URLを取得するには、デプロイメントサンドボックスのクエリタブからcurlリクエストをコピーし、URLを抽出します。
エラーハンドリング
最も一般的なHTTPエラーコードは以下の通りです:
- 400: 通常はモデル推論中に発生した例外によるものです。
- 422: リクエストが適切にフォーマットされていないことによるものです。リクエストのJSONが有効であり、モデルAPIに準拠していることを確認します。
- 429: リクエストが多すぎることによるものです。バックオフを伴って再試行します。レート制限はユーザーの環境に依存します。
- 500: 内部サーバーまたはデプロイメントエラーによるものです。これは、デプロイメントが不健康で自動的に再起動を試みるときに発生することがあります。手動での介入が必要な場合があります。
- 503: サービスが利用できません。バックオフを伴って再試行します。手動での介入が必要な場合があります。