注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
Jupyter®ノートブックでモデルをトレーニングする
モデルアセットは現在、SparkMLライブラリをサポートしていません。PyTorch、TensorFlow、XGBoost、LightGBM、またはscikit-learnのようなシングルノードの機械学習フレームワークへの切り替えをお勧めします。
モデルは、Code Workspaces内のJupyter®ノートブックでトレーニングできます。モデルをトレーニングするには、以下の手順を完了してください。
- Jupyter®コードワークスペースを作成する
- データをインポートしてモデルトレーニングコードを書く
- モデル出力を追加し、モデルadapterを実装する
- モデルをFoundryに公開する
- モデルを消費する
Jupyter®コードワークスペースでのモデルトレーニングに関する追加の指示は、教師ありモデルトレーニングチュートリアルを参照してください。
Jupyter®コードワークスペースを作成する
- モデルトレーニング用の新しいJupyter®コードワークスペースを作成するには、プロジェクトフォルダーに移動し、+ New > Jupyter® Code Workspaceを選択するか、Code Workspacesアプリケーションで**+ New code workspace**を選択します。
- Code Workspacesで、ワークスペースタイプとしてJupyterLab®を選択し、右下のContinueを選択します。
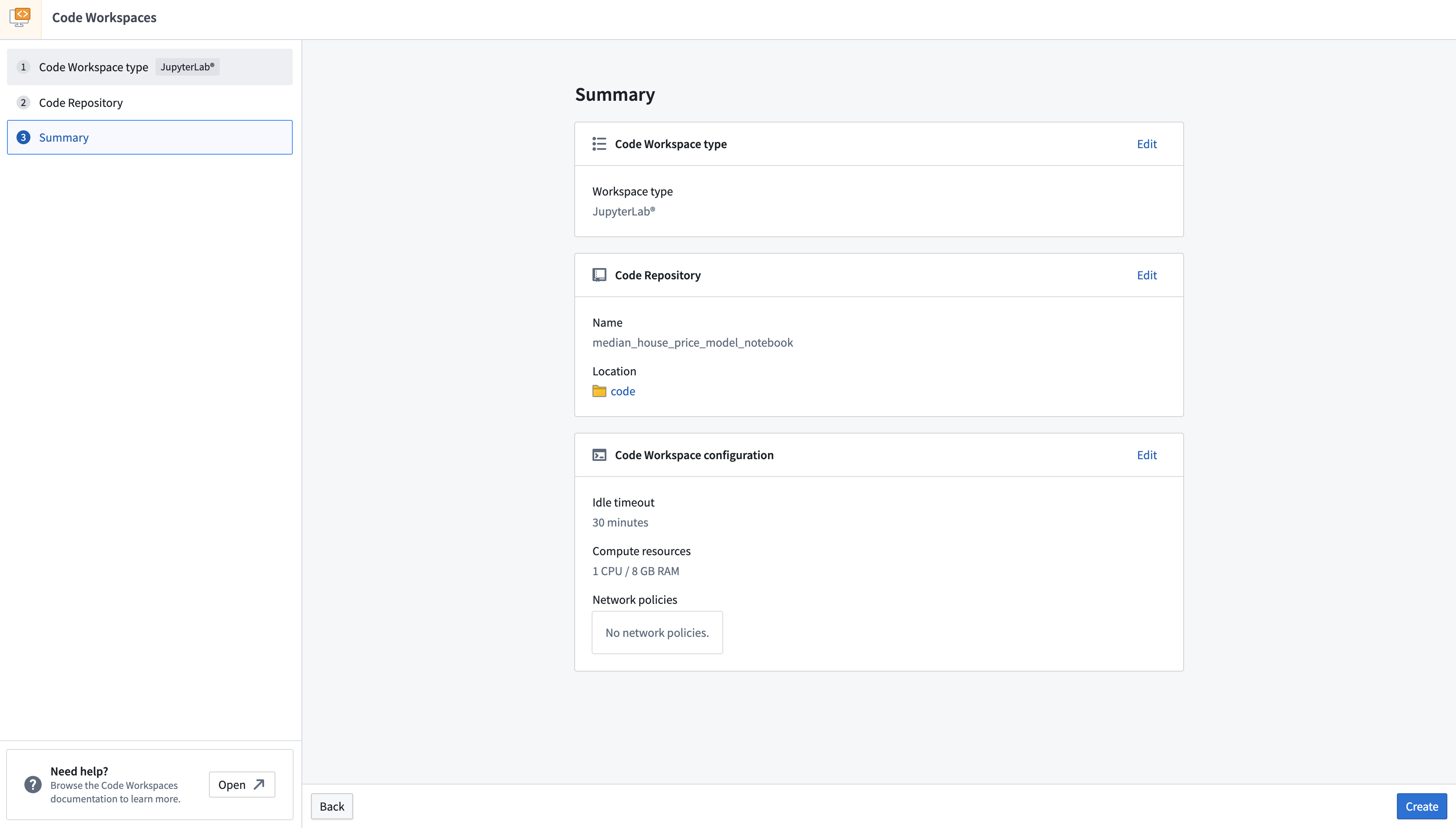
- トレーニングしているモデルに関連してワークスペースに名前を付けます。ワークスペースの計算リソースやネットワークポリシーなどの追加設定をAdvancedを選択して構成することもできます。ノートブックに名前を付けたら、Continueを選択します。
- 最後に、Createを選択してワークスペースを作成し、起動します。
データをインポートしてモデルトレーニングコードを書く
ワークスペースを確立した後、新しいノートブックを作成してデータをインポートし、モデルトレーニングコードを書き始めることができます。
Code Workspacesは、Code Repositoriesなどの他のFoundryコード作成環境で利用可能なパッケージへのアクセスを提供します。新しいパッケージを追加するには、ワークスペースの左サイドバーにあるPackagesタブを開き、必要なパッケージを検索して選択し、Latestまたは他の利用可能なバージョンをクリックして、対応するインストールコマンドを実行するためのターミナルを開きます。
ワークスペースへのデータインポート
Code Workspacesアプリケーションは、ユーザーがトレーニングデータとして利用するために既存のFoundryデータセットをインポートすることを可能にします。Code Workspacesで使用されるトレーニングデータには、リソース識別子として人間が読めるエイリアスが必要です。
- データセットをインポートするには、左サイドバー上部のDataタブを開き、Add dataset > Read existing datasetsを選択します。
- ワークスペースにインポートしたいデータセットを選択し、データセットエイリアスを入力して、+ Add datasetを選択してステップ1を完了します。
- Code Workspacesはステップ2でコードスニペットを生成します。データセットのフォーマットとして
pandas DataFrameなどを選択できます。生成されたコードスニペットをノートブックにコピーするには、コードスニペットの右上にあるクリップボードアイコンを選択し、Doneを選択します。以下は、Code Workspacesが生成したコードスニペットの例です。
Copied!1 2 3 4from foundry.transforms import Dataset # データセットを取得し、Pandas形式のテーブルとして読み込む training_data = Dataset.get("my-alias").read_table(format="pandas")
- コードスニペットをクリップボードにコピーしたら、
Launcherパネルから Python [user-default] を選択して Notebook を起動し、最初のセルにコードスニペットを貼り付けます。 - アクションツールバーの「再生」アイコンを選択するか、メニューバーの Run > Run Selected Cells を選択して、データセットをインポートするためにコードを実行します。
モデルのトレーニングコードを書く
Code Workspaces で利用可能なオープンソースツールを使用すると、回帰や分類など、さまざまな分析ユースケースに対してモデルをトレーニングできます。以下は、scikit-learn を使用して世帯の中央値収入を予測するサンプルの線形回帰モデルです。
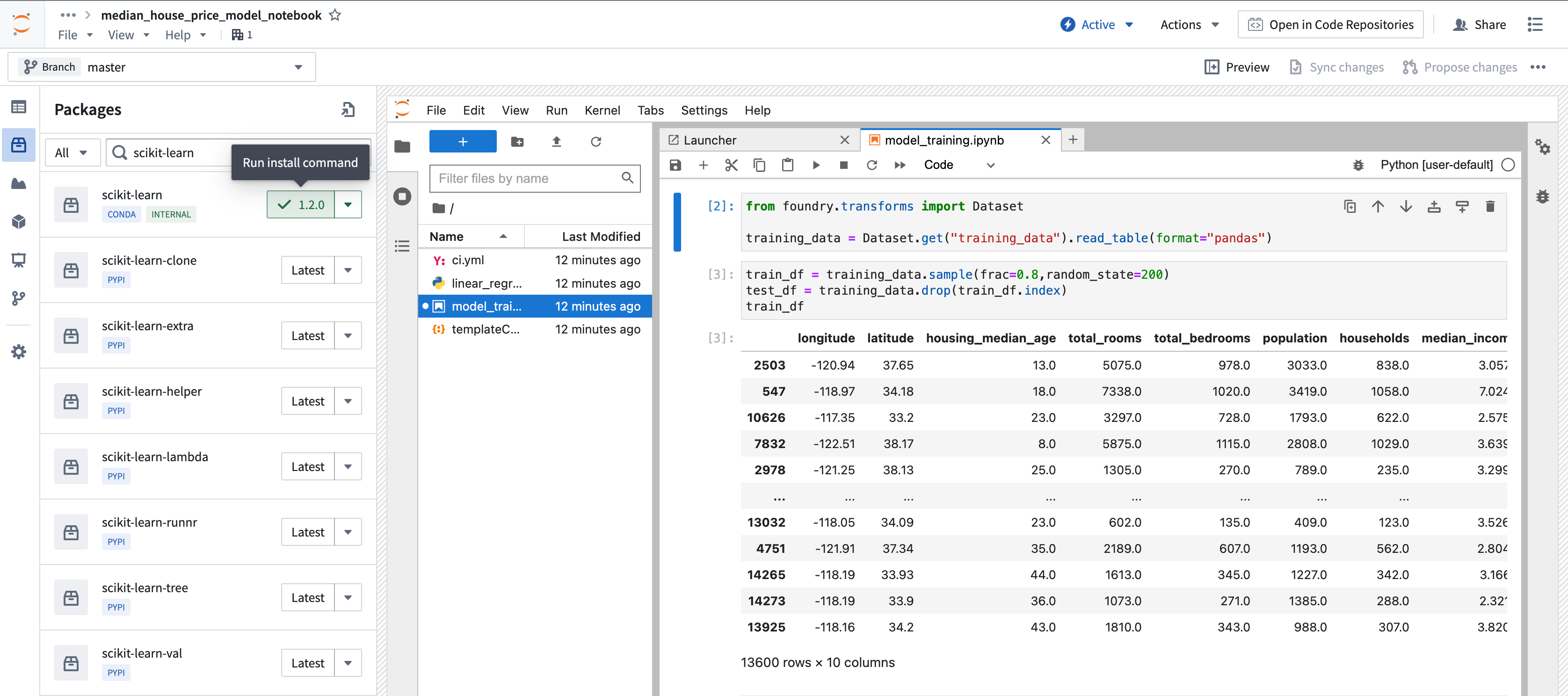
- 左サイドバーの Data の下にある Packages アイコンを選択して、ワークスペースに
scikit-learnをインストールします。 - 検索バーの左側のドロップダウンで
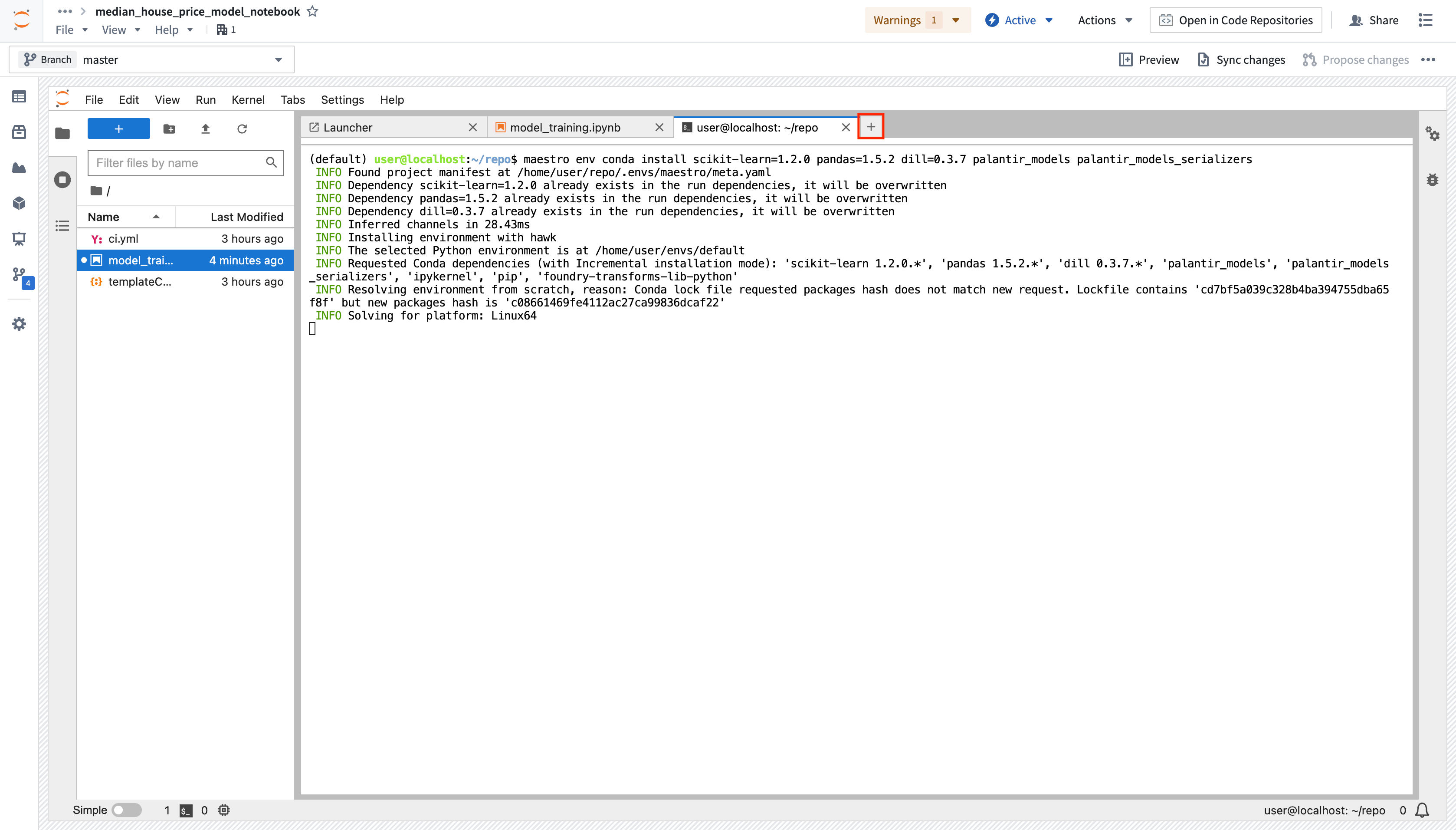
CondaまたはPyPiマネージャーを選択し、scikit-learnを検索します。 - ターミナルでインストールコマンドを実行するには、ドロップダウンでパッケージバージョンを選択し、バージョンボタンを選択します。または、ターミナルを使用して
maestro env conda installまたはmaestro env pip installコマンドを使用して、一度に複数のパッケージをユーザーの管理された環境にインストールすることもできます。
サイドバーを使用したパッケージのインストール:
ターミナルからのパッケージのインストール:
Code Workspaces でモデルを作成し実行した後、他のアプリケーションと統合するために Foundry に公開できます。以下はモデルトレーニングコードの例です。
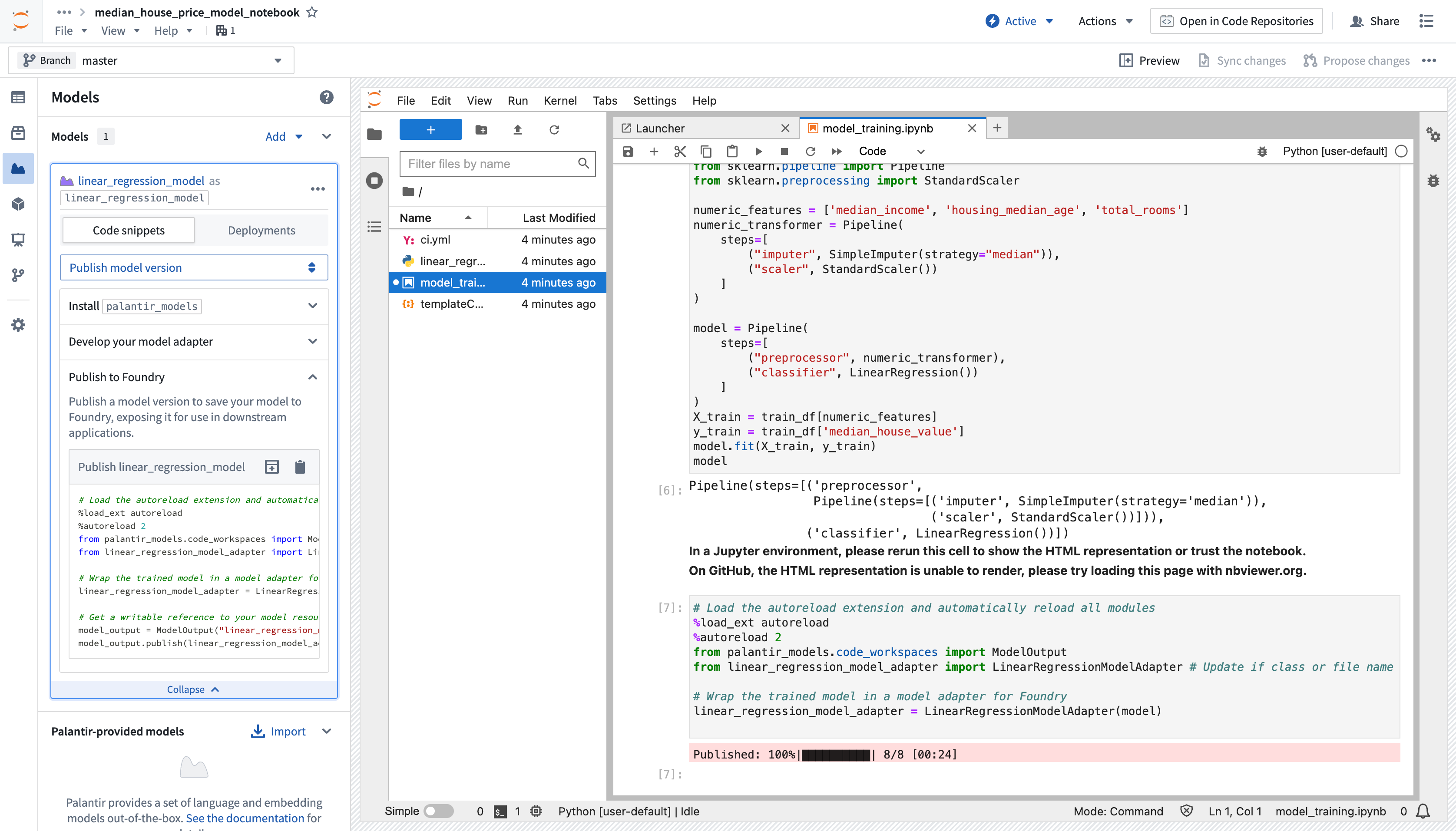
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34from sklearn.impute import SimpleImputer from sklearn.linear_model import LinearRegression from sklearn.pipeline import Pipeline from sklearn.preprocessing import StandardScaler # 数値特徴量を指定 numeric_features = ['median_income', 'housing_median_age', 'total_rooms'] # 数値データの前処理パイプラインを構築 numeric_transformer = Pipeline( steps=[ # 欠損値を中央値で補完 ("imputer", SimpleImputer(strategy="median")), # 標準化を行う ("scaler", StandardScaler()) ] ) # モデルのパイプラインを構築 model = Pipeline( steps=[ # 前処理を適用 ("preprocessor", numeric_transformer), # 線形回帰モデルを適用 ("classifier", LinearRegression()) ] ) # 訓練データから特徴量とターゲットを取得 X_train = training_dataframe[numeric_features] y_train = training_dataframe['median_house_value'] # モデルを訓練データにフィット model.fit(X_train, y_train)
モデル出力を追加してモデル adapter を実装する
モデルを Code Workspaces の外で利用できるようにするには、ワークスペースに新しいモデル出力を追加する必要があります。Code Workspaces は、新しいモデル出力を作成した後、既存のワークスペースに新しい .py ファイルを自動的に作成して保存します。このファイルを使用してモデル adapter を実装できます。モデル adapter は、Foundry 内のすべてのモデルに標準的なインターフェースを提供し、プラットフォームの本番アプリケーションがモデル作成直後に消費できるようにします。Foundry のインフラストラクチャは、モデルをロードし、その Python 依存関係を構成し、API を公開し、モデルインターフェースを有効にします。
- 出力を追加するには、左のサイドバーの Packages の下にある Models タブを開き、Add model > Create new model を選択します。モデルに名前を付け、任意の場所に保存します。
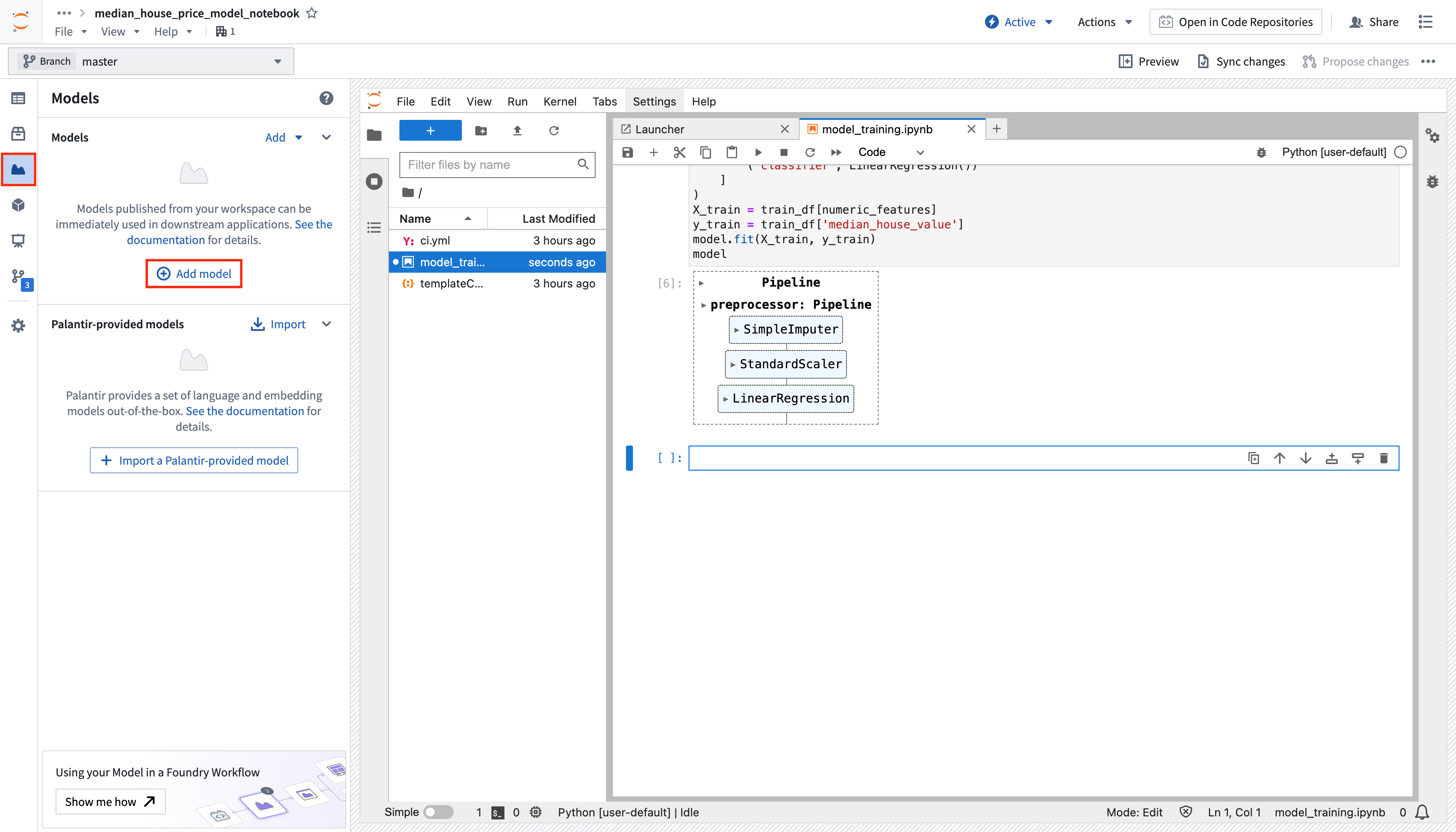
-
モデルに名前を付けて保存した後、ワークスペースの左パネルで Publish a new model を求められます。ステップ 1:
palantir_modelsをインストールする を完了するために、コードスニペットをクリップボードにコピーし、元の.ipynbノートブックファイルで実行します。 -
palantir_modelsを正常にインストールした後、ステップ 2: モデル adapter を開発する でモデル adapter を作成して開発します。モデル adapter は次のメソッドを実装する必要があります:saveおよびload: モデルを再利用するためには、モデルをどのように保存しロードするかを定義する必要があります。Palantir はシリアル化(保存)のデフォルトメソッドを提供しており、より複雑な場合にはカスタムシリアル化ロジックを実装できます。api: モデルの API を定義し、Foundry にモデルが必要とする入力データのタイプを伝えます。predict: Foundry がモデルにデータを提供するために呼び出します。ここで、入力データをモデルに渡して推論(予測)を生成します。
詳細については、モデル adapter API リファレンスを参照してください。
以下のコードサンプルは、scikit-learn を使用して線形回帰モデルの adapter を開発するために上記の関数を実装しています。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30import palantir_models as pm from palantir_models_serializers import DillSerializer class LinearRegressionModelAdapter(pm.ModelAdapter): # モデルを自動的にシリアライズするためのデコレーターを使用 @pm.auto_serialize( model=DillSerializer() # DillSerializerを使用してモデルをシリアライズ ) def __init__(self, model): self.model = model # モデルを初期化 @classmethod def api(cls): # 入力データフレームの列定義 columns = [ ('median_income', float), # 中央所得 ('housing_median_age', float), # 住宅の中央値の年齢 ('total_rooms', float), # 総部屋数 ] # 入力と出力データフレームの仕様を定義 return {"df_in": pm.Pandas(columns)}, \ {"df_out": pm.Pandas(columns + [('prediction', float)])} # 予測結果を含む出力 def predict(self, df_in): # モデルを使用して予測を行い、結果をデータフレームに追加 df_in['prediction'] = self.model.predict( df_in[['median_income', 'housing_median_age', 'total_rooms']] ) return df_in # 予測結果を含むデータフレームを返す
モデル adapter ドキュメント を参照してさらに詳しいガイダンスを確認してください。
モデルを Foundry に公開する
モデルを Foundry に公開するには、ステップ 3: モデルを公開するの下の左サイドバーにある公開したいモデルのスニペットをコピーし、ノートブックに貼り付けてセルを実行します。以下は、上記の LinearRegressionModelAdapter を使用して線形回帰モデルを公開するためのスニペット例です。
Copied!1 2 3 4 5 6 7 8 9 10 11from palantir_models.code_workspaces import ModelOutput # モデルアダプタはlinear_regression_model_adapter.pyで定義されています from linear_regression_model_adapter import LinearRegressionModelAdapter # sklearn_modelは別のセルで訓練されたモデルです linear_regression_model_adapter = LinearRegressionModelAdapter(sklearn_model) # "linear_regression_model"はこの例のモデルのエイリアスです model_output = ModelOutput("linear_regression_model") model_output.publish(linear_regression_model_adapter)
スニペットはそのまま動作するはずですが、トレーニングしたモデルをadapterの初期化に適切に渡す必要があります。コードが準備できたら、セルを実行してモデルをFoundryに公開できます。
モデルの利用
モデルはモデリングの目的への提出を通じて利用できます。モデルは以下の目的でモデリングの目的に提出できます:
モデルは、モデリングの目的を超えた代替のモデルホスティングシステムを表すモデルデプロイメントを使用して利用することもできます。
Jupyter®およびJupyterLab®は、NumFOCUSの商標または登録商標です。
参照されたすべてのサードパーティの商標は、それぞれの所有者の財産です。提携や承認は示唆されていません。