注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
Code Repositoriesでモデルを学習する
現在、モデル資産はSparkMLライブラリをサポートしていません。単一ノードの機械学習フレームワークであるPyTorch、TensorFlow、XGBoost、LightGBM、またはscikit-learnへの切り替えをお勧めします。SparkMLが必要な場合は、モデルを学習するためにdataset-backed modelsを使用できます。
モデルは、Model Training Templateを使用してCode Repositoriesアプリケーションで学習することができます。
モデルを学習するには、以下の手順を完了します:
1. モデルアダプターを作成する
モデルは、Foundryがモデルを正しく初期化、シリアル化、デシリアル化、および推論を行うことを確認するためにモデルアダプターを使用します。Code Repositoriesで、Model Adapter Library テンプレートまたはModel Training テンプレートのどちらかを使用してモデルアダプターを作成できます。
モデルアダプターはPythonトランスフォームリポジトリで直接作成することはできません。既存のリポジトリからモデルを作成するには、Model Adapter Libraryを使用してトランスフォームリポジトリにライブラリをインポートするか、Model Trainingテンプレートに移行します。
それぞれのモデルアダプターリポジトリの使用場合と作成方法については、モデルアダプターの作成のドキュメンテーションを参照してください。以下の手順は、Model Trainingテンプレートの使用を前提としています。
モデルアダプターの実装
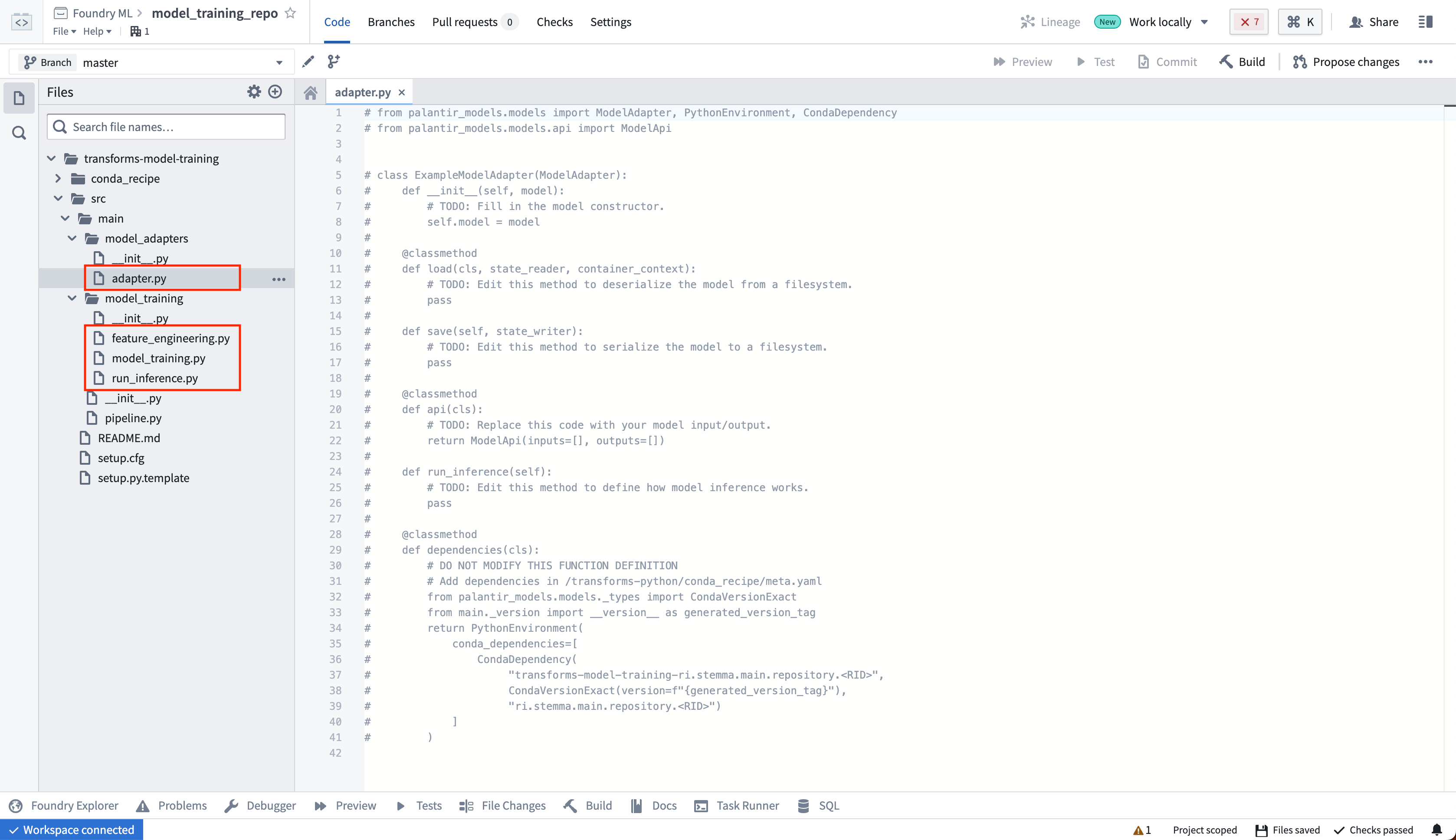
モデルアダプターとモデル学習コードは、学習済みモデルが下流のトランスフォームで使用できるように、別々のPythonモジュールにする必要があります。テンプレートでは、この目的のために model_adaptersと model_trainingモジュールが別々になっています。adapter.pyファイルでモデルアダプターを作成します。
モデルアダプターの定義は、学習するモデルに依存します。詳細については、ModelAdapter API リファレンスを参照するか、例のsklearnモデルアダプターを確認するか、監督式機械学習チュートリアルを読むことで詳しく学ぶことができます。
2. モデルを学習するためのPythonトランスフォームを書く
次に、コードリポジトリで新しいPythonファイルを作成し、そこに学習のロジックを記述します。
このロジックは ModelOutput に公開しています。変更をコミットした後、Foundry は指定されたパスで自動的にモデルリソースを作成します。また、 @configureアノテーションを使用して、モデル訓練に必要なリソース(CPU、メモリ、GPUの要件)を設定することもできます。
3. Python トランスフォームのプレビューを行い、ロジックをテストする
Code Repositories アプリケーションでは、フルビルドを行うことなく、トランスフォームのロジックをテストするために プレビュー を選択できます。プレビューは、 @configureアノテーションで設定したリソースプロファイルよりも小さいリソースプロファイルで実行されることに注意してください。
ModelOutput プレビュー
ModelOutput プレビューでは、モデル訓練ロジック、モデルのシリアライズ、デシリアライズ、API実装を検証することができます。
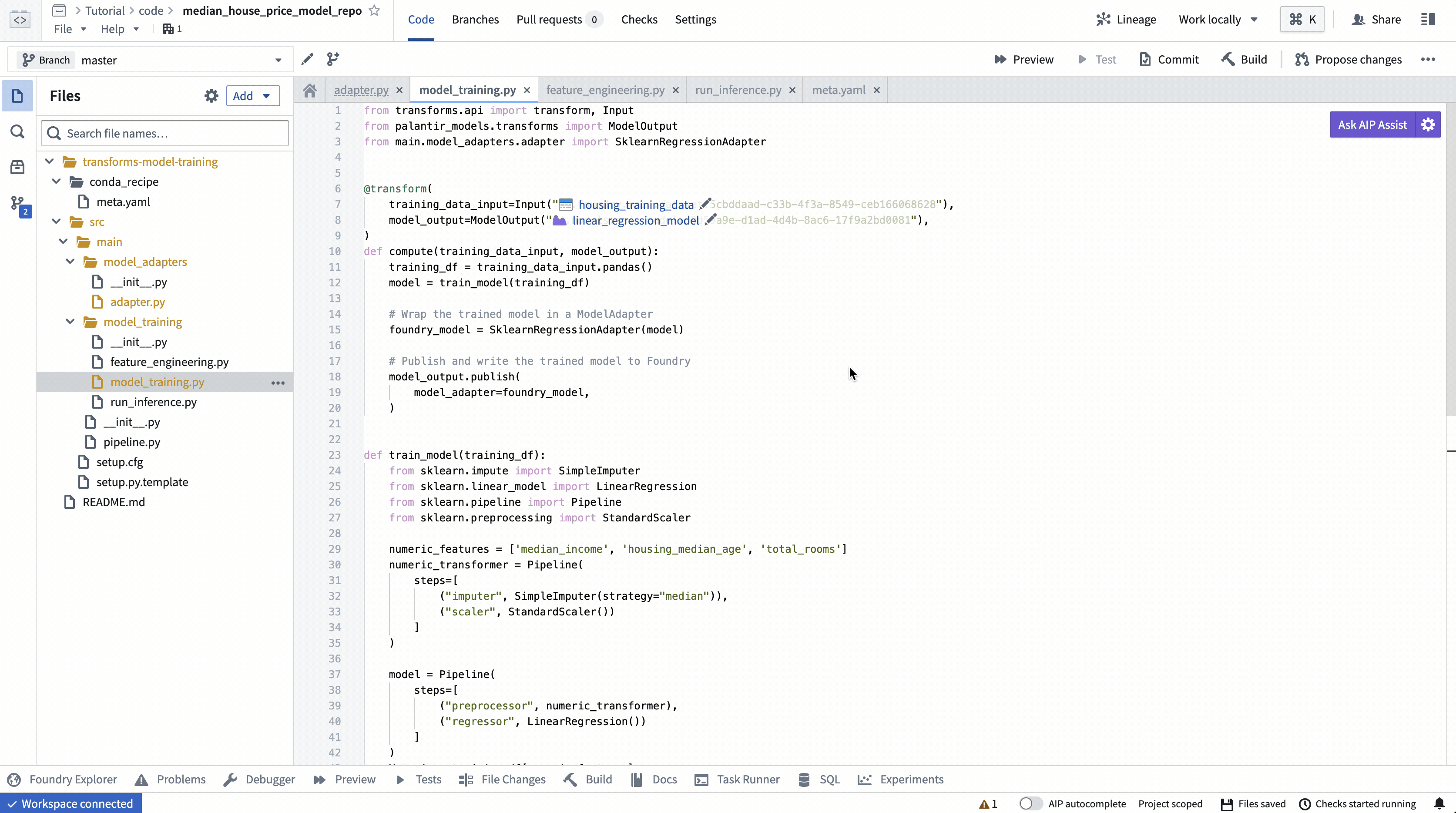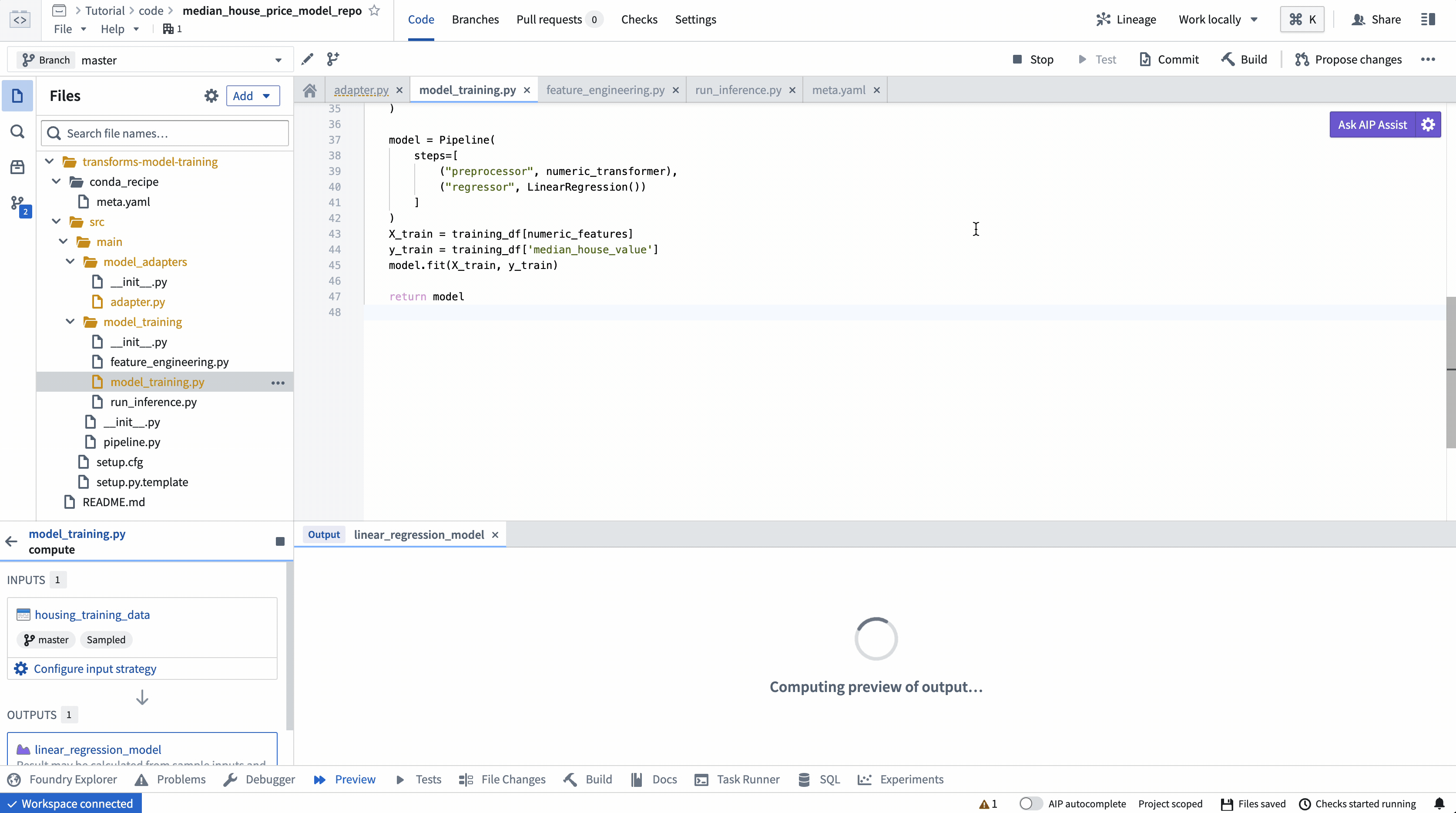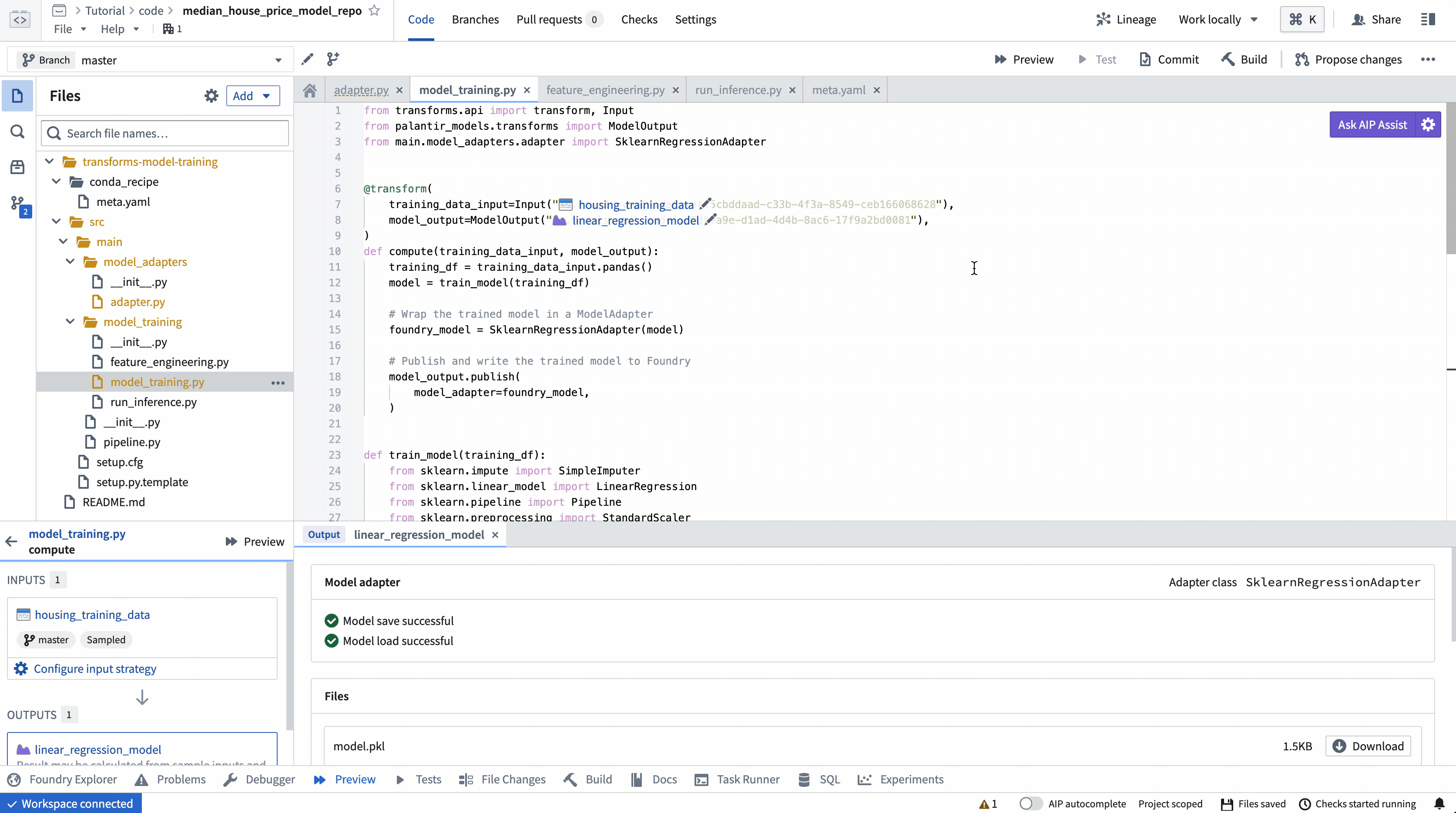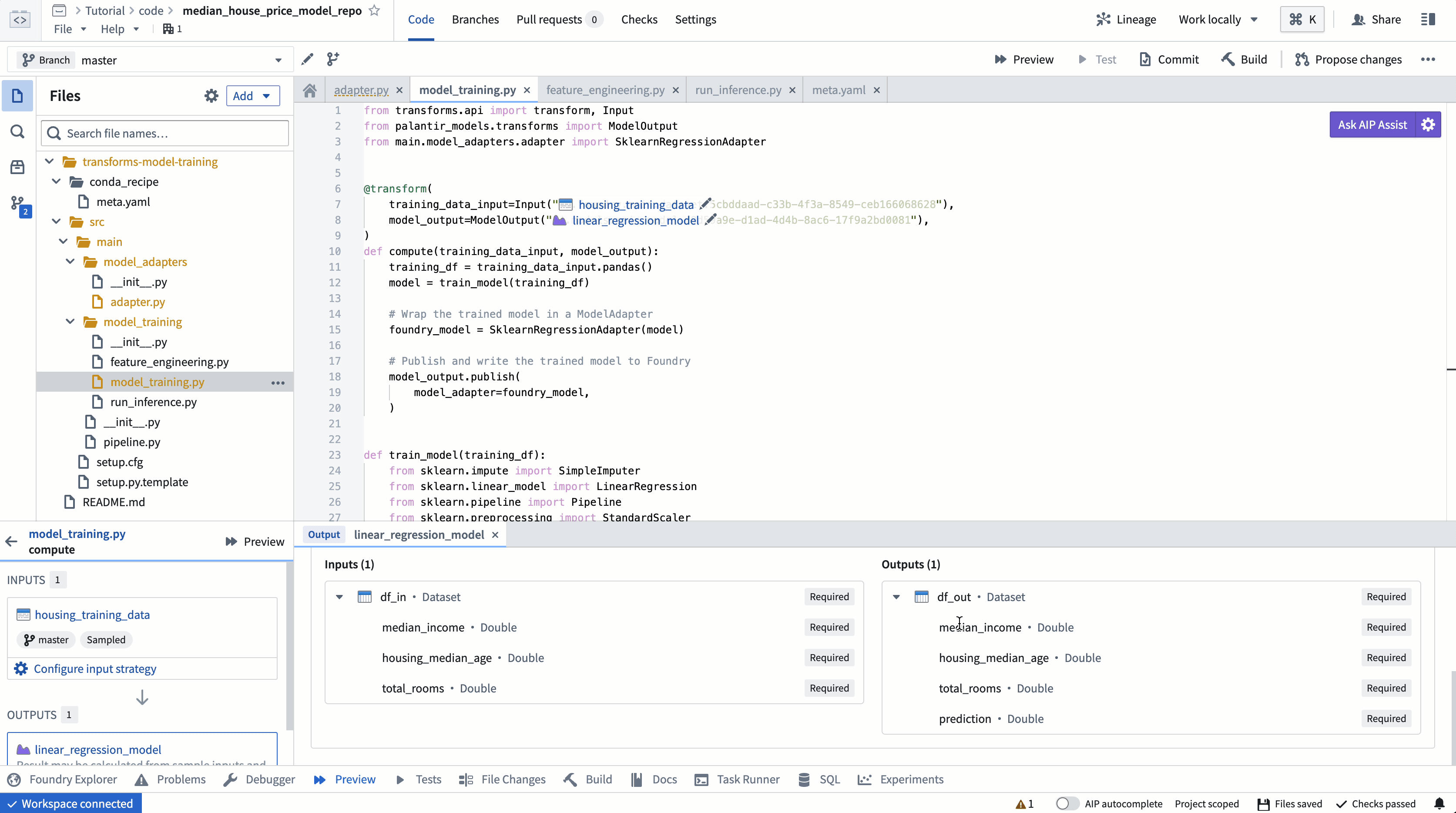
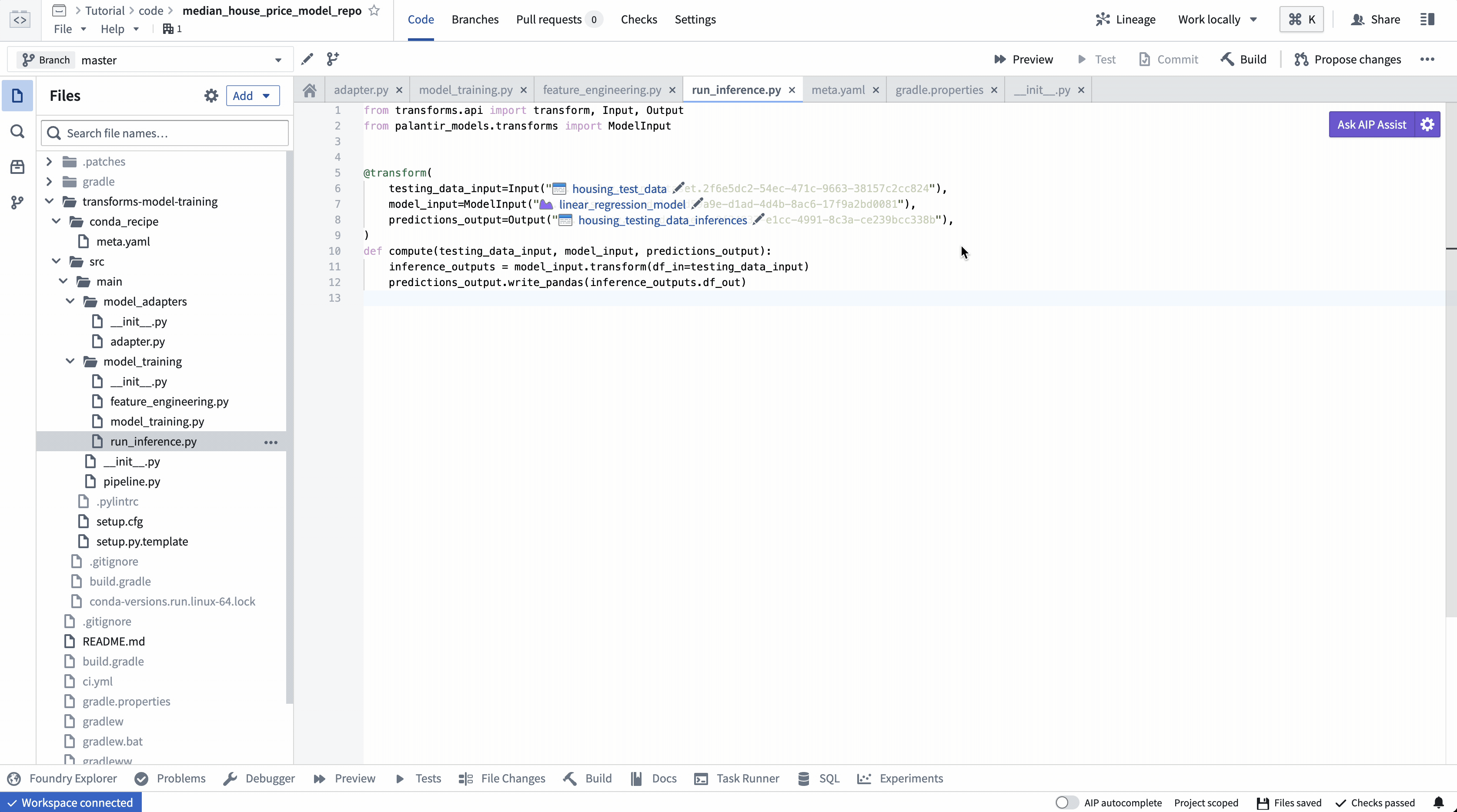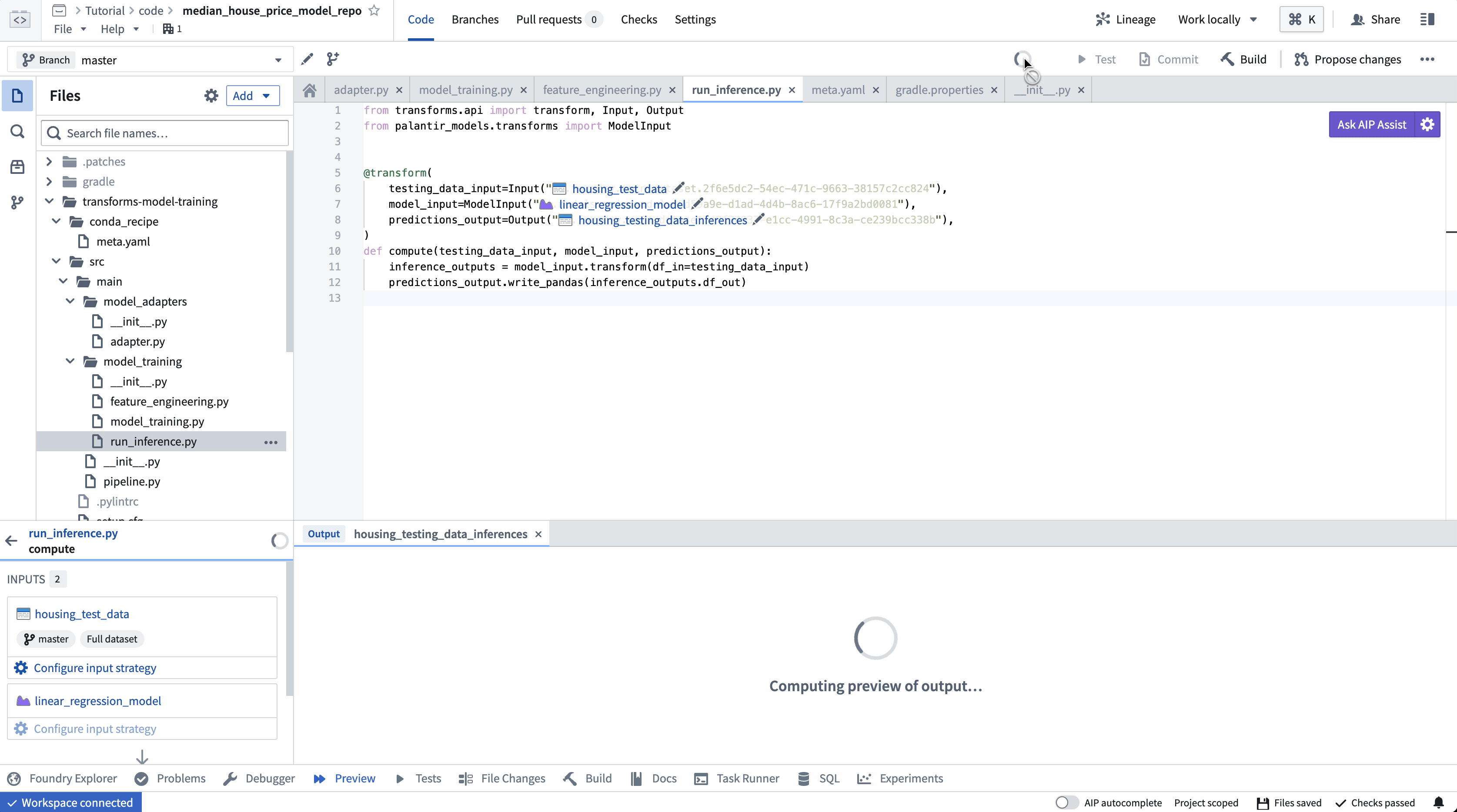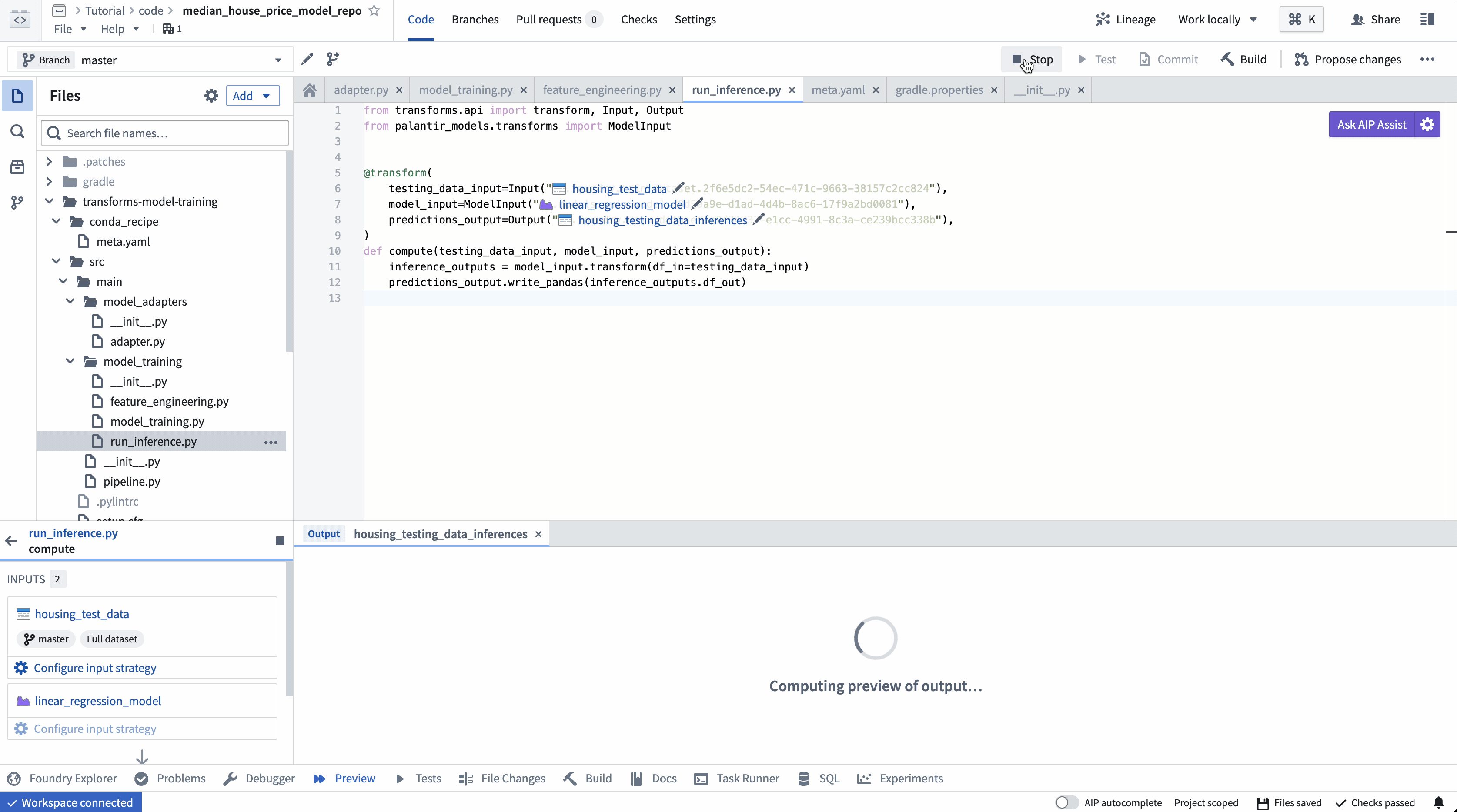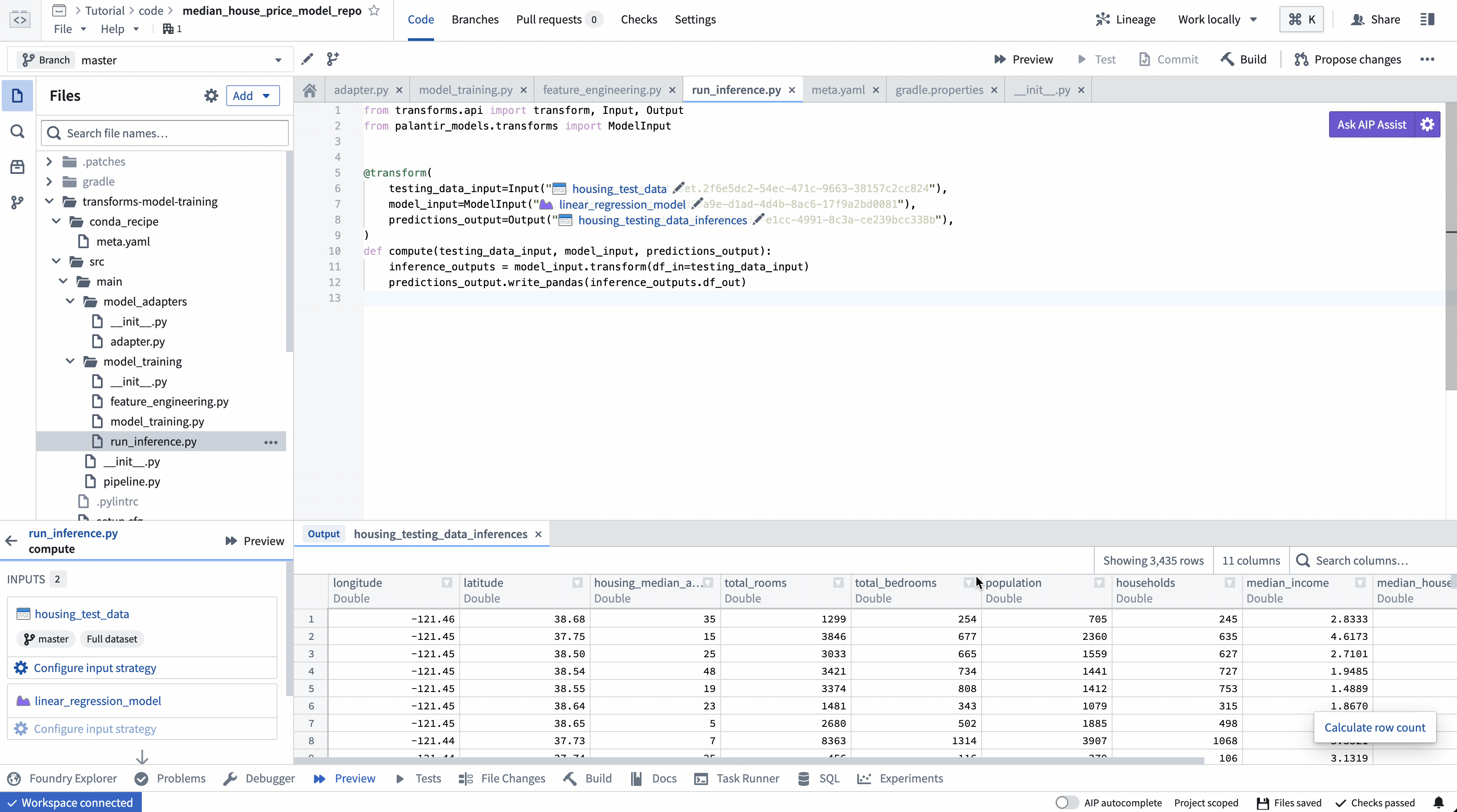
ModelInput プレビュー
ModelInput プレビューでは、既存のモデルに対して推論ロジックを検証することができます。Code Repositoriesでのプレビューでは、各 ModelInput につき5GBのサイズ制限があることに注意してください。
4. Python トランスフォームをビルドし、訓練済みモデルを公開する
コードリポジトリで ビルド を選択して、トランスフォームを実行します。Foundry は、訓練ロジックを実行する前に、Python の依存関係とモデルの依存関係を両方解決します。
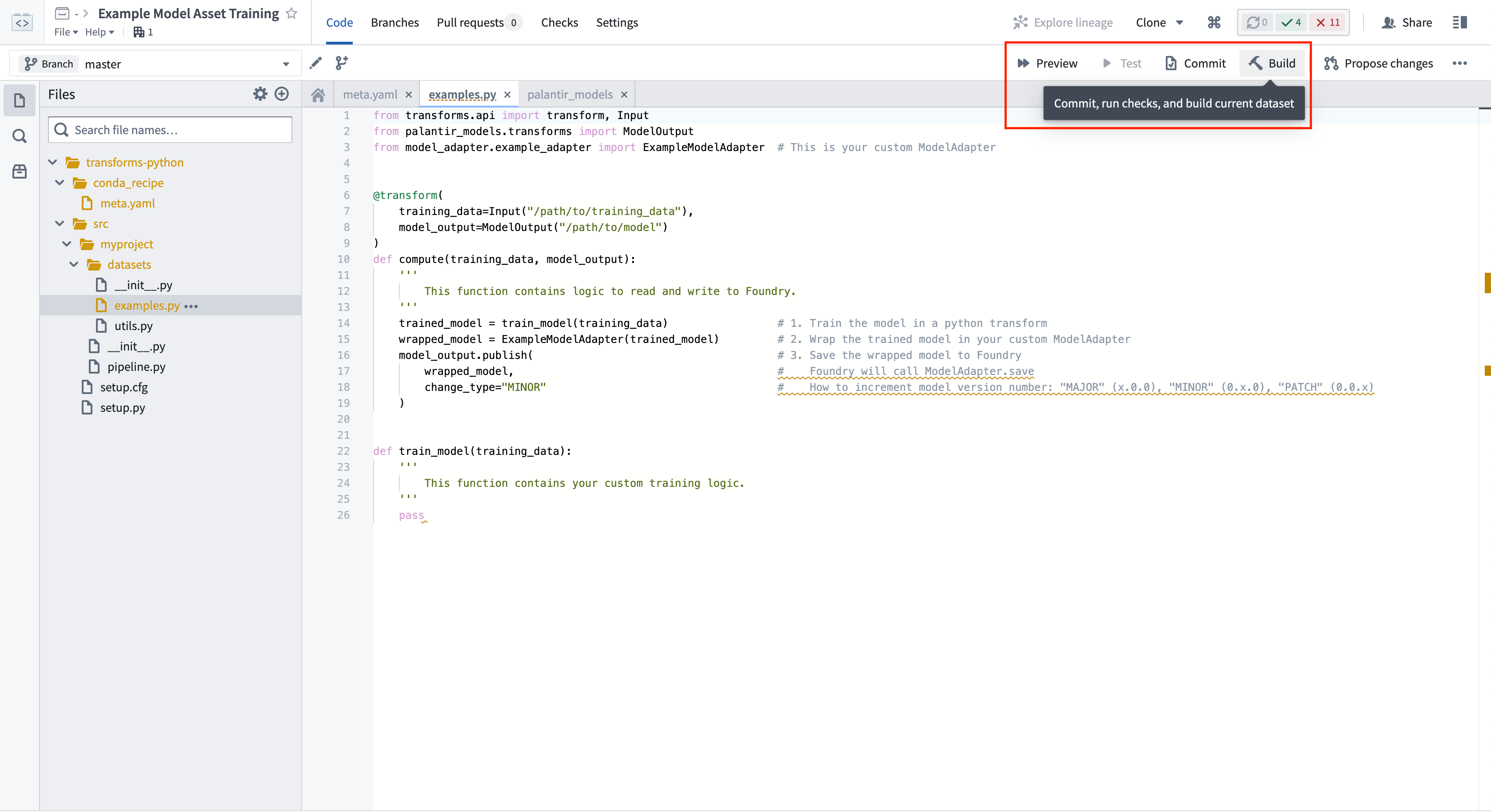
ModelOutput.publish() を呼び出すと、モデルのバージョンが Foundry に公開されます。Foundry は ModelAdapter.save() 関数を呼び出し、ModelAdapter に実行に必要なすべてのフィールドをシリアライズする能力を提供します。
5. モデルの使用
モデリングの目的に送信する
モデルは次の目的でモデリングの目的に公開することができます:
Python トランスフォームで推論を実行する
以下の詳細に従って、パイプラインで Palantir モデルを使用することもできます。
異なる Python トランスフォームリポジトリでモデルを使用している場合、モデルアダプタPythonライブラリを Python 環境の作成に追加する必要があります。これは通常、Palantir のモデルリソースページで見つけることができます。
Copied!1 2 3 4 5 6 7 8 9 10# ModelOutputはpalantir_models.transformsからインポートすることができます。 class ModelOutput: def __init__(self, model_rid_or_path: str): ''' `ModelOutput`は新しいバージョンをモデルに公開するために使用されます。 `ModelOutput`は1つの引数を取ります。それはモデルへのパス(またはモデルRID)です。 アセットがまだ存在しない場合、ユーザーがCommitまたはBuildを選択し、トランスフォームチェック(CI)が実行されたときに、ModelOutputはアセットを作成します。 ''' pass
Copied!1 2 3 4 5 6 7 8 9 10# ModelOutputはpalantir_models.transformsからインポートできます class ModelOutput: def __init__(self, model_rid_or_path: str): ''' `ModelOutput`は新しいバージョンをモデルに公開するために使われます。 `ModelOutput`は一つの引数を受け取ります、それはモデルのパス(またはモデルRID)です。 アセットがまだ存在していない場合、ユーザーがCommitまたはBuildを選択し、トランスフォームのチェック(CI)が実行される時に、ModelOutputはアセットを作成します。 ''' pass