注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
API: Language model adapters
各ノーコード言語モデルに対して、FoundryはデフォルトのModel Adapterを提供します。このデフォルトのModel Adapterは、言語モデルと対話するための合理的なデフォルトパラメーターと構造を提供します。以下にリストされているデフォルトの言語モデルアダプターは、デプロイメントインフラストラクチャでの利用可能性に応じて、CPUおよびGPUデバイスに正しくルーティングされます。
使用中のModel Adapterは、Modeling Objectivesアプリケーションのモデル提出ページで確認できます。
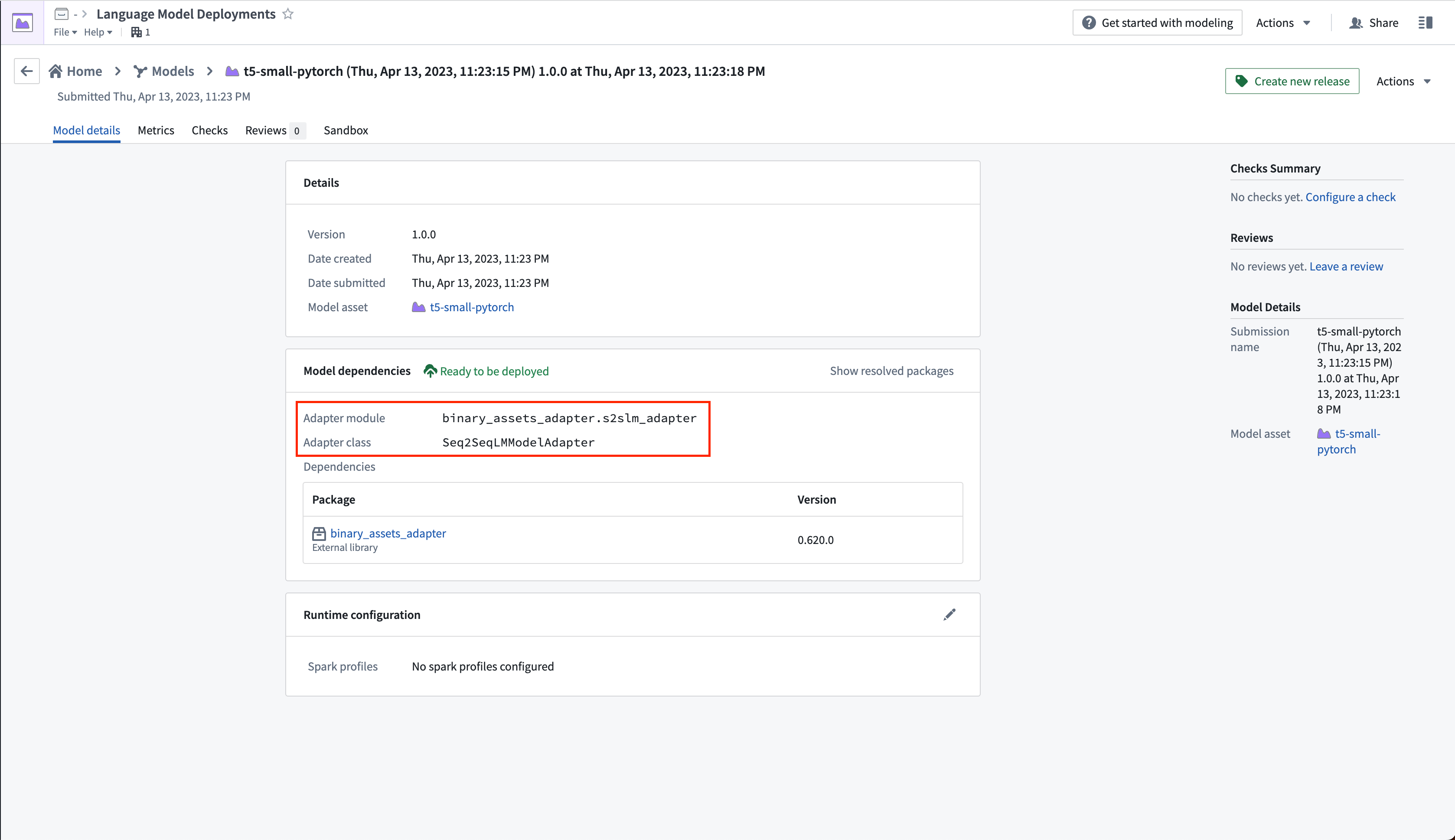
Seq2SeqLMModelAdapter
使用方法
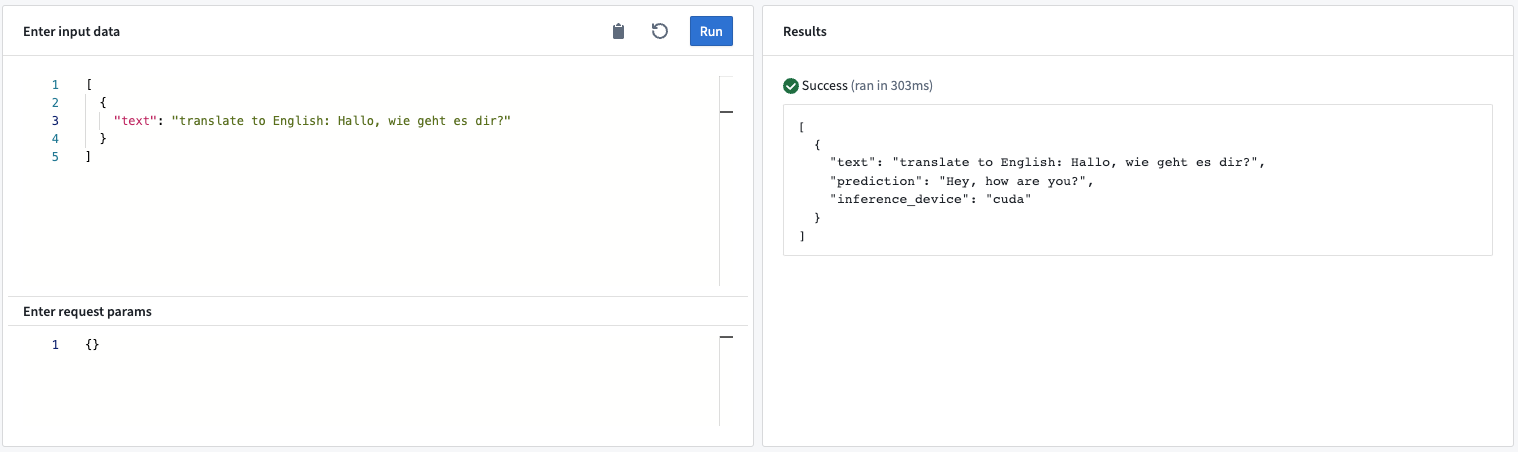
このModel Adapterは、シーケンスツーシーケンス言語モデル ↗をサポートします。このadapterは、提供された入力テキストに基づいてテキストを生成します。
例: 期待される入力テキストとその構造は、選択されたモデルによって異なります。正しいプロンプトエンジニアリングを確実にするために、モデルの詳細を読むことを強くお勧めします。たとえば、flan-t5-large ↗モデルは、翻訳から要約、質問応答まで幅広いプロンプトを実行できます。
モデルAPI
- Input “text”: 言語モデルが出力予測を生成するためのテキスト入力。
- Output “prediction”: モデルが生成したテキスト。
NerAdapter
使用方法
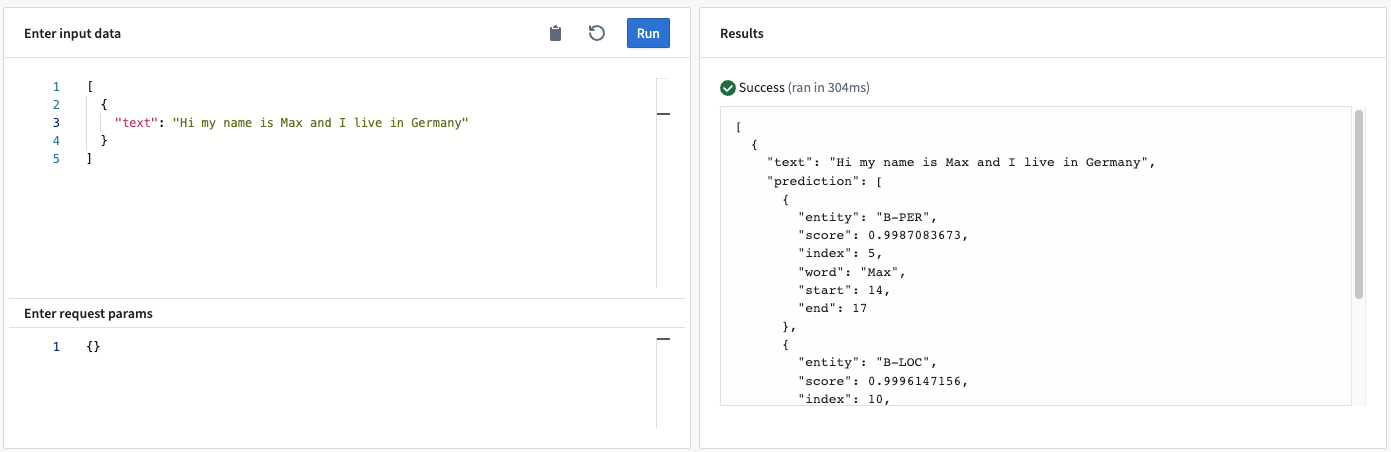
このModel Adapterは、固有表現抽出パイプライン ↗をサポートします。このModel Adapterはテキスト内のエンティティを抽出し、それらをリストで返します。
例: テキスト「My name is Max and I live in Germany」をサンドボックスまたはライブデプロイメントを通じてモデルに送信すると、モデルは2個のエンティティ、MaxとGermanyを認識します。
モデルAPI
- Input “text”: 言語モデルが出力予測を生成するためのテキスト。
- Output<list> “prediction”: モデルの出力は、抽出されたエンティティに関する詳細情報を提供する辞書のリストです。特に、辞書には以下が含まれます:
- entity: 認識されたエンティティの種類。
- score: 特定のエンティティの数値スコア。
- index: エンティティのトークンのインデックス(たとえば、インデックスが
5の場合、認識されたエンティティは入力テキストの5番目のトークンです)。 - word: 認識されたエンティティの文字列表現。
- start: 入力文字列における認識されたエンティティの開始インデックス。
- end: 入力文字列における認識されたエンティティの終了インデックス。
EmbeddingAdapter
使用方法
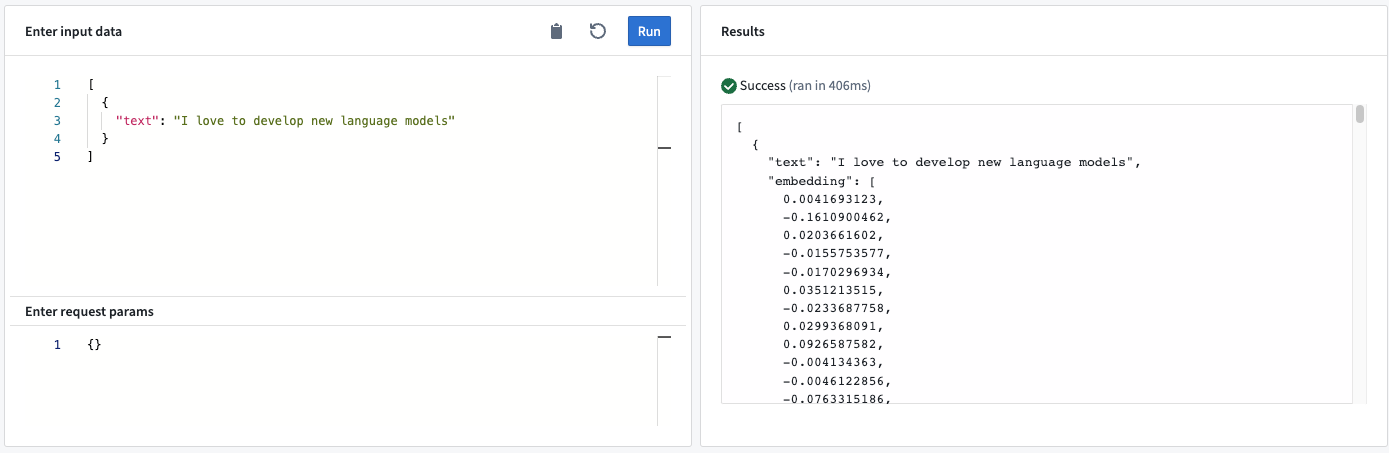
このModel Adapterは、モデルのアテンションマスク ↗に基づいて与えられたテキストの埋め込みを計算します。このadapterは"平均プーリング"と正規化を行い、sentenced-transformers ↗のデフォルトに一致します。
例:
モデルAPI
- Input “text”: 埋め込みモデルの入力テキスト。
- Output<list> “embedding”: 入力テキストを表すn次元ベクトル。
TextClassificationAdapter
使用方法
このModel Adapterは、あらかじめ定義されたクラスのセットに対して入力テキストを分類します。テキスト分類の一般的な例として、感情分析や言語検出があります。
例:
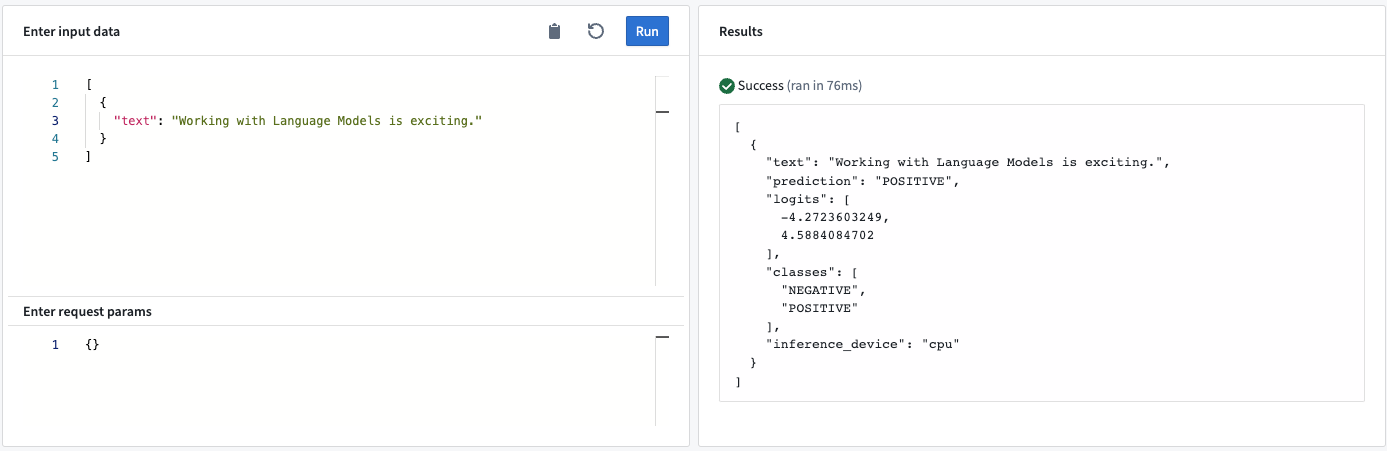
モデルAPI
- Input “text”: 言語モデルが出力予測を生成するための入力テキスト。
- Output “prediction”: 最も可能性の高いクラス。
- Output<list> “logits”: 各クラスのロジット値。
- Output<list> “classes”: モデルが予測できるクラス。順序はロジットの順序と同じです(たとえば、最初のロジットエントリはクラスリストの最初のエントリに対応します)。
ZeroShotClassificationAdapter
使用方法
このModel Adapterは、予測時に提供されるクラスリストに基づいて入力テキストを分類します。この動作により、特定のユースケースに言語モデルを微調整する必要なく、テキストを分類できます。
例: テキスト「I love to develop new language models」と候補ラベル「Travel」、「Sports」、「Work」、「Entertainment」を送信すると、モデルはラベルをスコアリングし、「Work」を最も可能性の高い分類としてランク付けします。
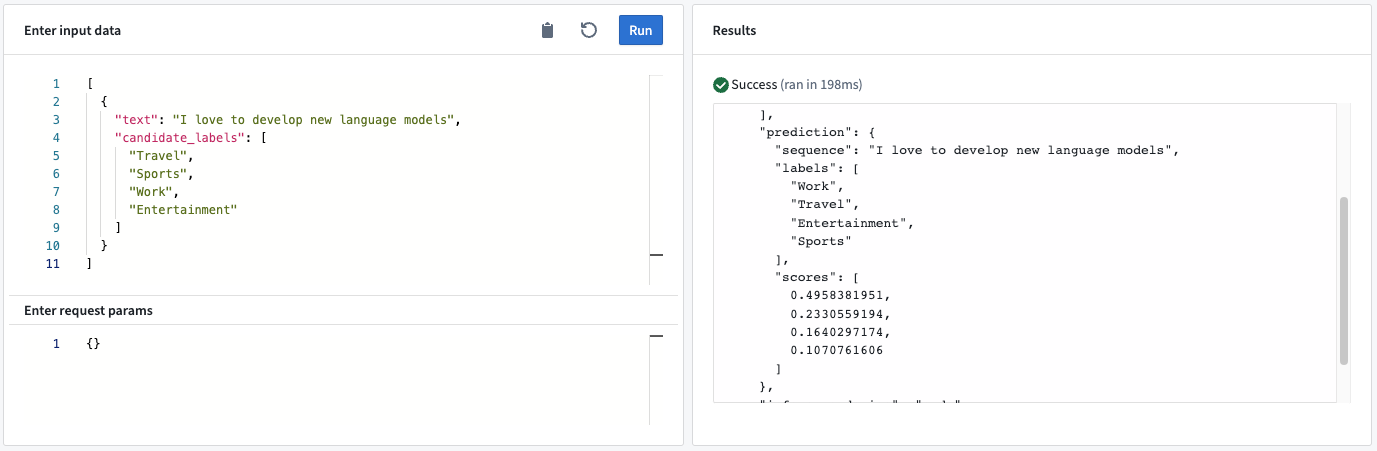
モデルAPI
- Input “text”: 言語モデルが出力予測を生成するための入力テキスト。
- Input<list> “candidate_labels”: モデルがスコアリングする入力テキストの候補ラベルリスト。
- Output “prediction”:
- sequence: ゼロショット分類に使用されたテキスト。
- labels: モデルのスコアに基づいて降順に並べられた候補ラベル。
- scores: 候補ラベルの分類スコアを表す浮動小数点数。スコアの順序はラベルの順序と一致します。