注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
コードでモデルを評価する
Foundry では、モデルを評価するために、そのモデルに対して 1 つ以上の MetricSets を作成することで、コード内で個々のモデルのパフォーマンスを評価できます。このページでは、MetricSet クラスについての知識があることを前提としています。
MetricSet で生成されるメトリックは、評価データセットの特定のトランザクションに関連付けられ、Modeling Objectives アプリケーションでレビューできます。ただし、Modeling Objectives 設定ページ の Only show metrics produced by evaluation configuration をトグルして、これらのメトリックを有効にする必要があります。
メトリックは、入力データセットの特定のトランザクションに関連付けられているため、モデルや入力データセットを更新するたびに、MetricSet を生成するコードを再実行する必要がある場合があります。
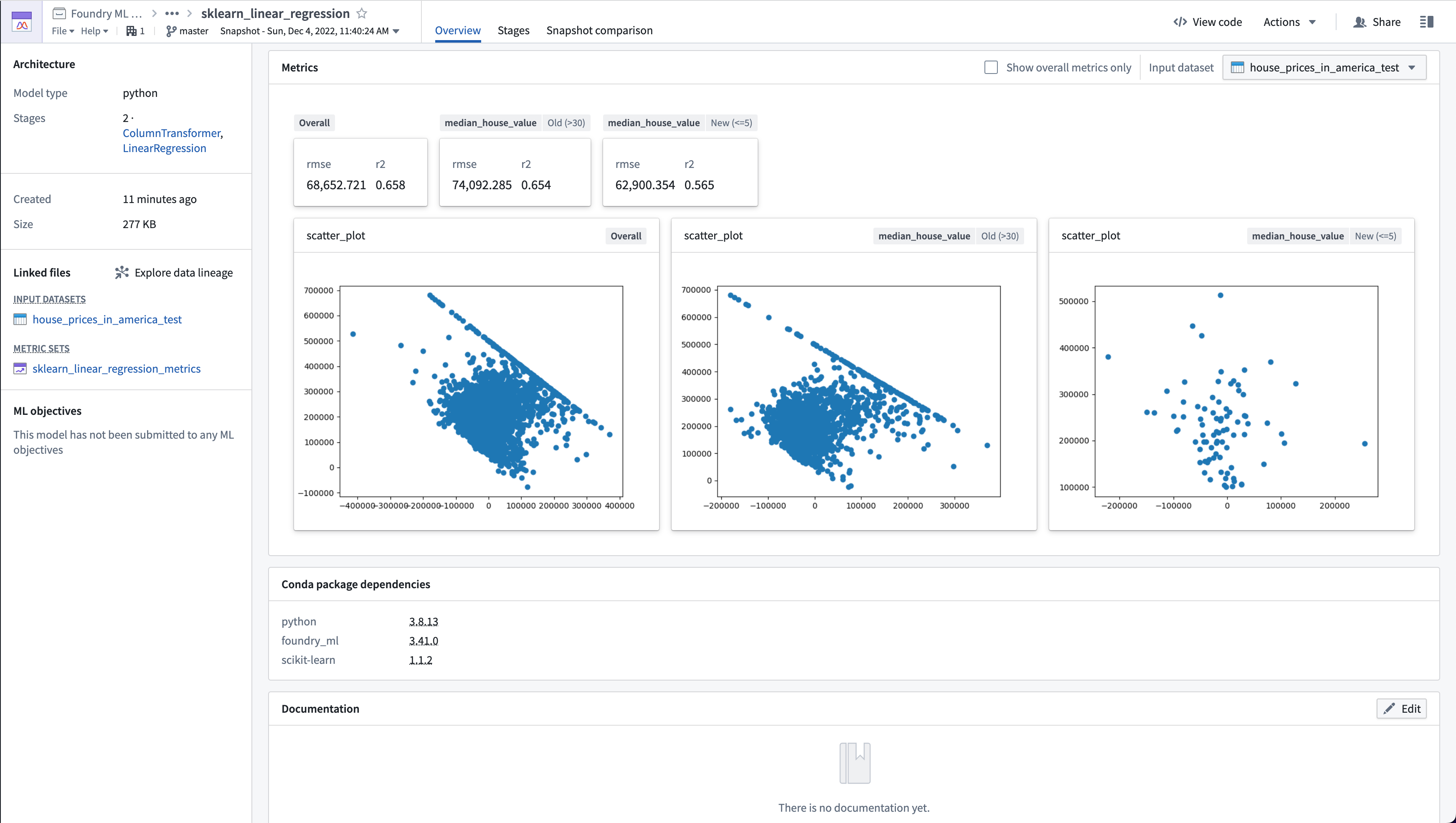
Code Workbook でモデルを評価する
Code Workbook アプリケーションでモデルを評価するには:
- コードワークブックを作成するか、既存のワークブックを開きます。
foundry_mlパッケージを コードワークブックの環境にインポートします。foundry_ml_metricsパッケージはfoundry_mlの一部として利用できます。- モデルと評価データセットをコードワークブックにインポートします。
- Python で
MetricSetオブジェクトを生成する transform を作成し、そのMetricSetの入力としてモデルと評価データセットを関連付けます。 - transform の
MetricSetにメトリックを追加します。 MetricSetを transform の結果として返します。
以下は、回帰モデル lr_model とテストデータセット testing_data の例です。このコードスニペットは、Getting Started チュートリアルで紹介されている住宅データセットに基づくモデルとテストデータセットを使用しています。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77def lr_evaluation_testing(lr_model, testing_data_input): from foundry_ml_metrics import MetricSet # foundry_ml を環境に追加してください model = lr_model # モデルの名前を変更 metric_set = MetricSet( # 個々の指標を追加するための MetricSet を作成 model = lr_model, # 評価している Foundry ML モデル input_data=testing_data_input # パフォーマンスを評価しているデータセットの TransformInput ) testing_data_df = testing_data_input.dataframe().toPandas() # TransformInput から pandas のデータフレームを取得 y_true_column = 'median_house_value' # モデルが予測している評価データセットの列 y_prediction_column = 'prediction' # モデルがデータセットを変換するときに生成される列 scored_df = get_model_scores(model, testing_data_df) # 入力データセット全体の指標を追加 add_numeric_metrics_to_metric_set(metric_set, scored_df, y_true_column, y_prediction_column) add_residuals_scatter_plot_to_metric_set(metric_set, scored_df, y_true_column, y_prediction_column) # housing_median_age 列が 30 より大きい場合の指標を追加 old_homes_subset = {'median_house_value': 'Old (>30)'} old_houses_scored_df = scored_df[scored_df['housing_median_age'] > 30] add_numeric_metrics_to_metric_set(metric_set, old_houses_scored_df, y_true_column, y_prediction_column, old_homes_subset) add_residuals_scatter_plot_to_metric_set(metric_set, old_houses_scored_df, y_true_column, y_prediction_column, old_homes_subset) # housing_median_age 列が 5 以下の場合の指標を追加 new_homes_subset = {'median_house_value': 'New (<=5)'} new_houses_scored_df = scored_df[scored_df['housing_median_age'] <= 5] add_numeric_metrics_to_metric_set(metric_set, new_houses_scored_df, y_true_column, y_prediction_column, new_homes_subset) add_residuals_scatter_plot_to_metric_set(metric_set, new_houses_scored_df, y_true_column, y_prediction_column, new_homes_subset) return metric_set # Code Workbooks はこれを Foundry の MetricSet として保存します def get_model_scores(model, df): return model.transform(df) # モデルに基づいた予測を作成 def add_numeric_metrics_to_metric_set( metric_set, scored_df, y_true_column, y_prediction_column, subset=None ): import numpy as np from sklearn.metrics import mean_squared_error, r2_score y_true = scored_df[y_true_column] y_pred = scored_df[y_prediction_column] # 指標を計算 mse = mean_squared_error(y_true, y_pred) rmse = np.sqrt(mse) r2 = r2_score(y_true, y_pred) metric_set.add(name='rmse', value=rmse, subset=subset) # rmse は float 型 metric_set.add(name='r2', value=r2, subset=subset) # r2 は float 型 def add_residuals_scatter_plot_to_metric_set( metric_set, scored_df, y_true_column, y_prediction_column, subset=None ): import matplotlib.pyplot as plt y_true = scored_df[y_true_column] y_pred = scored_df[y_prediction_column] scatter_plot = plt.scatter((y_true - y_pred), y_pred) # 散布図を作成 figure = plt.gcf() # 現在の pyplot 図を取得 metric_set.add(name='scatter_plot', value=figure, subset=subset) # figure は pyplot 画像 plt.close() # pyplot 図を閉じる
Code Repositories でのモデルの評価
Code Repositories アプリケーションでモデルを評価するには:
- コードリポジトリを作成するか、既存のリポジトリを開く。
foundry_mlパッケージをユーザーのコードリポジトリの環境にインポートする。foundry_ml_metricsパッケージはfoundry_mlの一部として利用できるようになります。- Pythonで
MetricSetオブジェクトを生成する変換を作成し、そのMetricSetの入力としてモデルと評価データセットを関連付ける。MetricSetを返す代わりに、metric_set.save(metrics_output)で metric_set を保存する。- モデルと評価データセットの変換入力タイプはどちらも
TransformInputになります。
- 変換内の
MetricSetにメトリックスを追加する。 MetricSetを変換の結果として返す。
以下は、回帰モデル lr_model とテストデータセット testing_data の例です。このコードスニペットでは、Getting Started チュートリアルで紹介されている住宅データセットをベースにしたモデルとテストデータセットを使用しています。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89from transforms.api import transform, Input, Output # transforms-python/conda_recipe/meta.yamlにfoundry_mlがrun requirementsに追加されていることを確認してください from foundry_ml import Model from foundry_ml_metrics import MetricSet @transform( # @transformを使用しているので、入力はTransformInputになります # メトリクスを保存する出力位置にOutput Pathを更新する必要があります metrics_output=Output("/Path/to/metrics_dataset/sklearn_linear_regression_metrics"), # モデルと評価データセットのパスをInput Pathに更新する必要があります model_input=Input("/Path/to/model/sklearn_linear_regression"), testing_data_input=Input("/Path/to/evaluation_dataset/house_prices_in_america_test") ) def compute(metrics_output, model_input, testing_data_input): model = Model.load(model_input) # TransformInputからFoundry ML Modelを読み込みます metric_set = MetricSet( # 個々のメトリクスを追加するためのMetricSetを作成します model=model, # 評価するFoundry ML Model input_data=testing_data_input # パフォーマンスを評価するデータセットのTransformInput ) testing_data_df = testing_data_input.dataframe().toPandas() # TransformInputからpandasのデータフレームを取得します y_true_column = 'median_house_value' # モデルが予測する評価データセット内の列です y_prediction_column = 'prediction' # モデルがデータセットを変換するときに生成する列です scored_df = get_model_scores(model, testing_data_df) # 入力データセット全体に対するメトリクスを追加します add_numeric_metrics_to_metric_set(metric_set, scored_df, y_true_column, y_prediction_column) add_residuals_scatter_plot_to_metric_set(metric_set, scored_df, y_true_column, y_prediction_column) # housing_median_age列が30より大きい場合のメトリクスを追加します old_homes_subset = {'median_house_value': 'Old (>30)'} old_houses_scored_df = scored_df[scored_df['housing_median_age'] > 30] add_numeric_metrics_to_metric_set(metric_set, old_houses_scored_df, y_true_column, y_prediction_column, old_homes_subset) add_residuals_scatter_plot_to_metric_set(metric_set, old_houses_scored_df, y_true_column, y_prediction_column, old_homes_subset) # housing_median_age列が5以下の場合のメトリクスを追加します new_homes_subset = {'median_house_value': 'New (<=5)'} new_houses_scored_df = scored_df[scored_df['housing_median_age'] <= 5] add_numeric_metrics_to_metric_set(metric_set, new_houses_scored_df, y_true_column, y_prediction_column, new_homes_subset) add_residuals_scatter_plot_to_metric_set(metric_set, new_houses_scored_df, y_true_column, y_prediction_column, new_homes_subset) metric_set.save(metrics_output) # このMetricSetをTransformsOutputに保存します def get_model_scores(model, df): return model.transform(df) # モデルに基づいて予測を作成します def add_numeric_metrics_to_metric_set( metric_set, scored_df, y_true_column, y_prediction_column, subset=None ): import numpy as np from sklearn.metrics import mean_squared_error, r2_score y_true = scored_df[y_true_column] y_pred = scored_df[y_prediction_column] # メトリクスを計算します mse = mean_squared_error(y_true, y_pred) rmse = np.sqrt(mse) r2 = r2_score(y_true, y_pred) metric_set.add(name='rmse', value=rmse, subset=subset) # rmseは浮動小数点数です metric_set.add(name='r2', value=r2, subset=subset) # r2は浮動小数点数です def add_residuals_scatter_plot_to_metric_set( metric_set, scored_df, y_true_column, y_prediction_column, subset=None ): import matplotlib.pyplot as plt y_true = scored_df[y_true_column] y_pred = scored_df[y_prediction_column] scatter_plot = plt.scatter((y_true - y_pred), y_pred) # 散布図を作成します figure = plt.gcf() # 現在のpyplot図を取得します metric_set.add(name='scatter_plot', value=figure, subset=subset) # figureはpyplotのイメージです plt.close() # pyplotの図を閉じます
メトリクスの更新
上記のコードスニペットは変換を作成するため、MetricSetsはFoundry Buildsを通じて作成および計算されます。モデルが更新されたり、新しい入力データバージョンが利用可能になったりすると、そのモデルに関連付けられているメトリクスを更新するためにMetricSetを再構築することが重要です。