注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
モデルの自動評価
モデリングプロジェクトが成熟し、規模が拡大し、運用に移行するにつれて、現在および新しいモデルの提出を体系的に評価および比較することが重要です。モデルの提出は、明確に定義されたメトリクスに対して適切に管理された代表的なデータを使用して一貫して評価する必要があります。
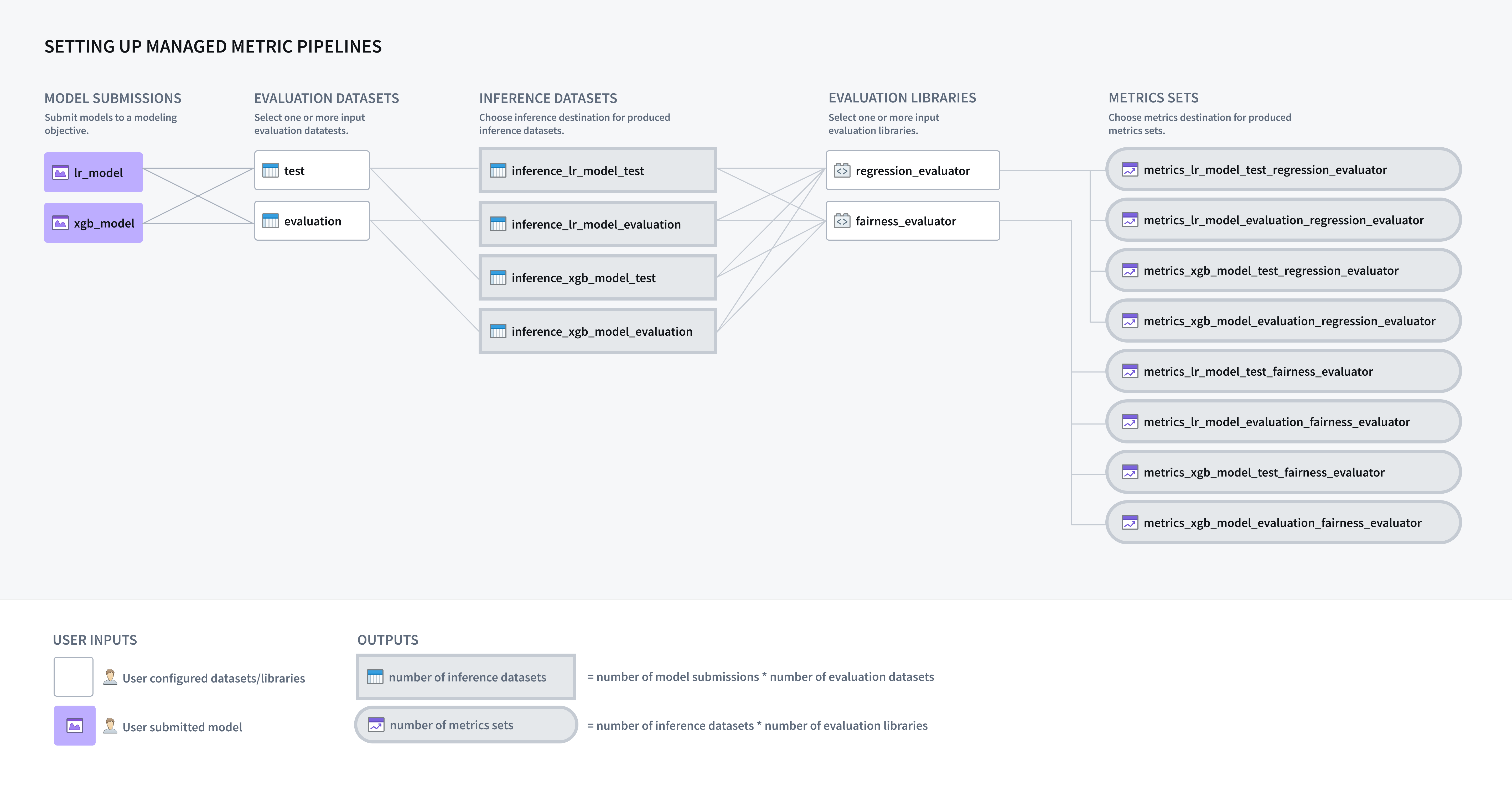
モデリングの目的は、提出されたすべてのモデルに対して推論およびメトリクスのパイプラインを自動的に生成するように設定でき、ソフトウェアで体系的なテストおよび評価 (T&E) 計画を実装できるようにします。
モデル評価の設定
モデルの自動評価を有効にするためには、モデリングの目的に対して提出されたモデルをどのように評価するかを設定する必要があります。
パイプライン管理を有効にする
モデリングの目的においてモデルの自動評価を設定する最初のステップは、推論およびメトリクスの生成を有効にすることです。Modeling Objectivesのホームページから、評価ダッシュボードの設定を選択するか、既にモデル評価を設定している場合は、評価ダッシュボードから評価設定の編集を選択します。
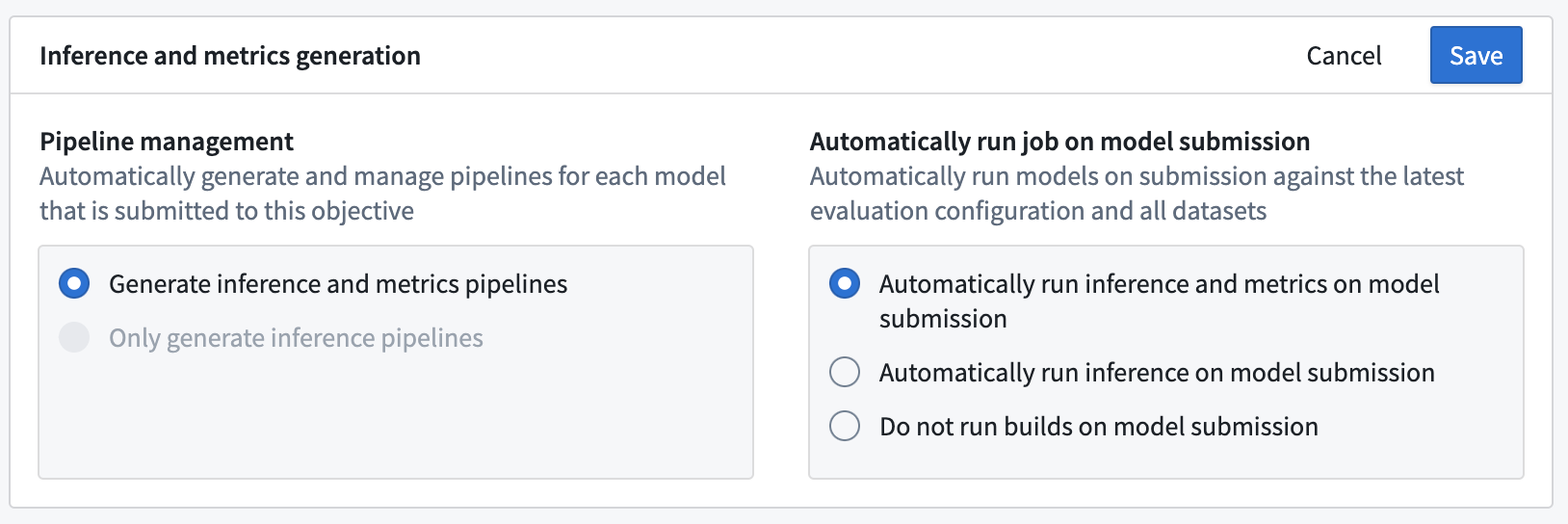
評価ダッシュボードの設定ビューでは、推論およびメトリクスのパイプラインを自動的に生成するか、推論パイプラインのみを生成するかを選択できます。選択に応じて、既存のすべてのモデル提出および新しいモデル提出に対して推論およびメトリクスのデータセットが生成されます。
自動モデル推論または評価の設定
次に、新しいモデルが提出されたときに推論または推論とメトリクスのデータセットを自動的に構築するかどうかを決定できます。推論およびメトリクスのデータセットを自動的に構築することで、モデリングプロジェクトで使用されるすべてのモデルが一貫して評価されるようになります。
推論およびメトリクスのパイプラインは、モデルの提出時にのみ構築されます。既存のモデル提出については、評価ダッシュボードの評価の構築ボタンから手動でビルドを開始する必要があります。
保存をクリックして推論およびメトリクスの生成設定を保存します。
評価データセットの追加
評価データセットは、モデリングの目的内でモデルが評価されるFoundryデータセットです。モデリングの目的が推論パイプラインを自動的に生成するように設定されている場合、モデル提出と評価データセットの組み合わせごとに1つの推論データセットが生成されます。各評価データセットは関連性があり、注意深く管理されている必要があります。これには、精選された検証セットまたはテストセット、運用観察、ユーザーのフィードバックインスタンス、重要なテストケース、または仮想上のシナリオの表現が含まれる場合があります。評価データセットには、モデルが推論を実行するために必要なデータセットフィールドまたはファイルが含まれている必要があります。
評価データセットは異なるサイズ、更新頻度、および権限を持つことができ、これらのデータセットを分離しておくことで、計算されたメトリクスの頻度および権限の管理をより容易にします。
権限はモデリングの目的内で完全に尊重されます。適切なアクセス権を持たないと、ユーザーはモデル、評価データセット、評価ライブラリ、またはメトリクスを閲覧できません。
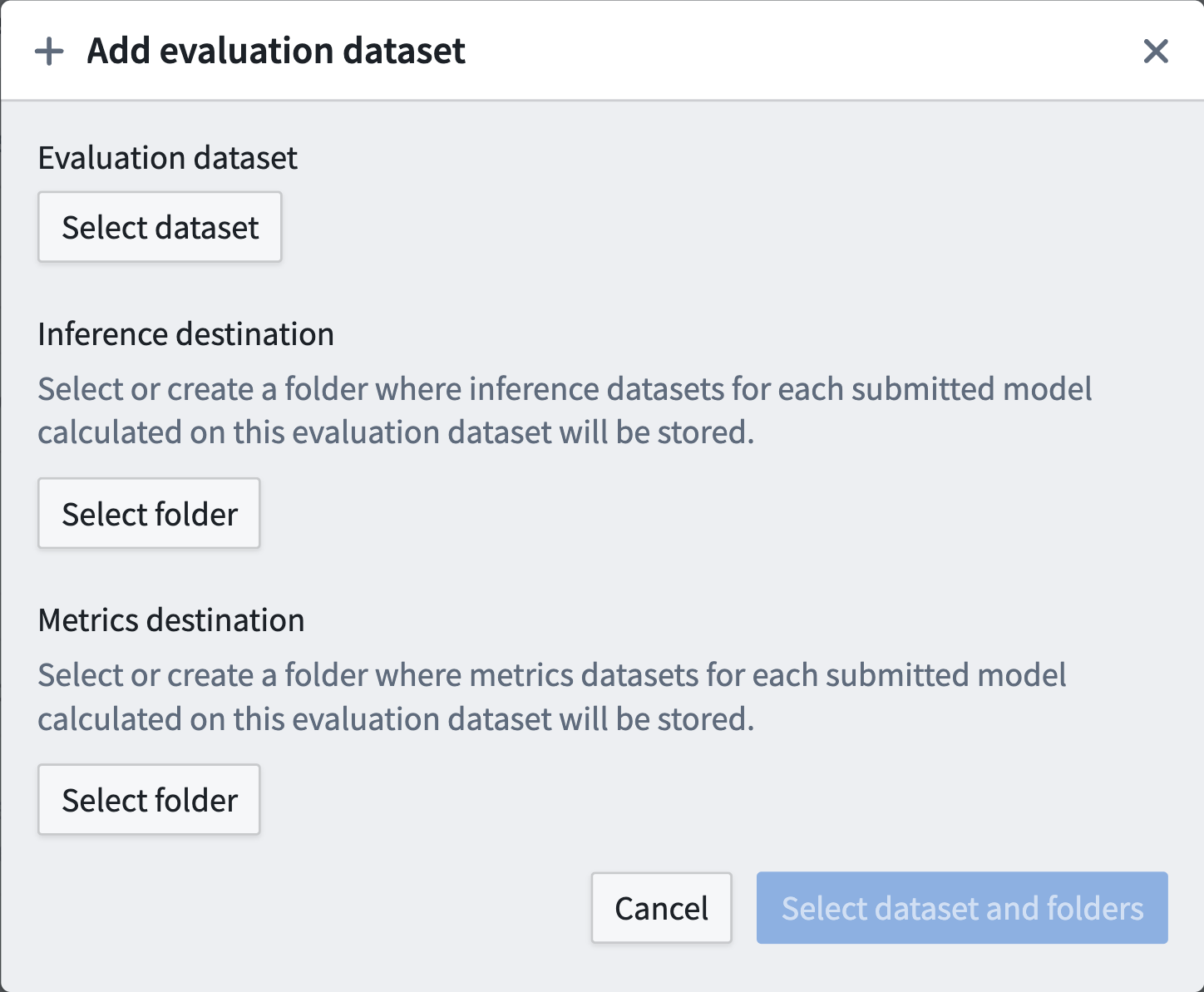
評価データセットを設定するには、評価データセットの追加を選択します。ポップアップが表示され、以下を設定できます:
- 評価データセット。
- 推論データセットが生成されるFoundryフォルダー。
- メトリクスデータセットが生成されるFoundryフォルダー。
Foundryフォルダーは新規または既存のフォルダーであり、評価データセットごとに一意である必要はありません。通常、モデリングの目的ごとに1つの出力フォルダーを推奨しますが、特定のユースケースに合わせて設定できます。
評価データセットおよび目的自体は、推論およびメトリクスの宛先と同じFoundryプロジェクト内にある必要があるか、リファレンスとしてFoundryプロジェクトに追加される必要があります。
Modeling Objectivesでの自動モデル評価は、単一の表形式データセット入力を持つモデルにのみ対応しています。
評価ライブラリの設定
モデリングの目的がメトリクスおよび推論パイプラインを生成するように設定されている場合、次のステップは評価ライブラリを設定することです。評価ライブラリは、モデル評価者を生成するFoundryで公開されたPythonパッケージです。Foundryには、バイナリ分類および回帰のデフォルトのモデル評価者が付属しており、カスタムモデル評価者を構築することもできます。評価ライブラリは、モデルのパフォーマンス、モデルの公平性、モデルのロバスト性、およびその他のメトリクスを測定するために使用されます。
設定されると、評価ライブラリは、設定された推論データセットごとにメトリクスセットを含む1つのデータセットを生成します。
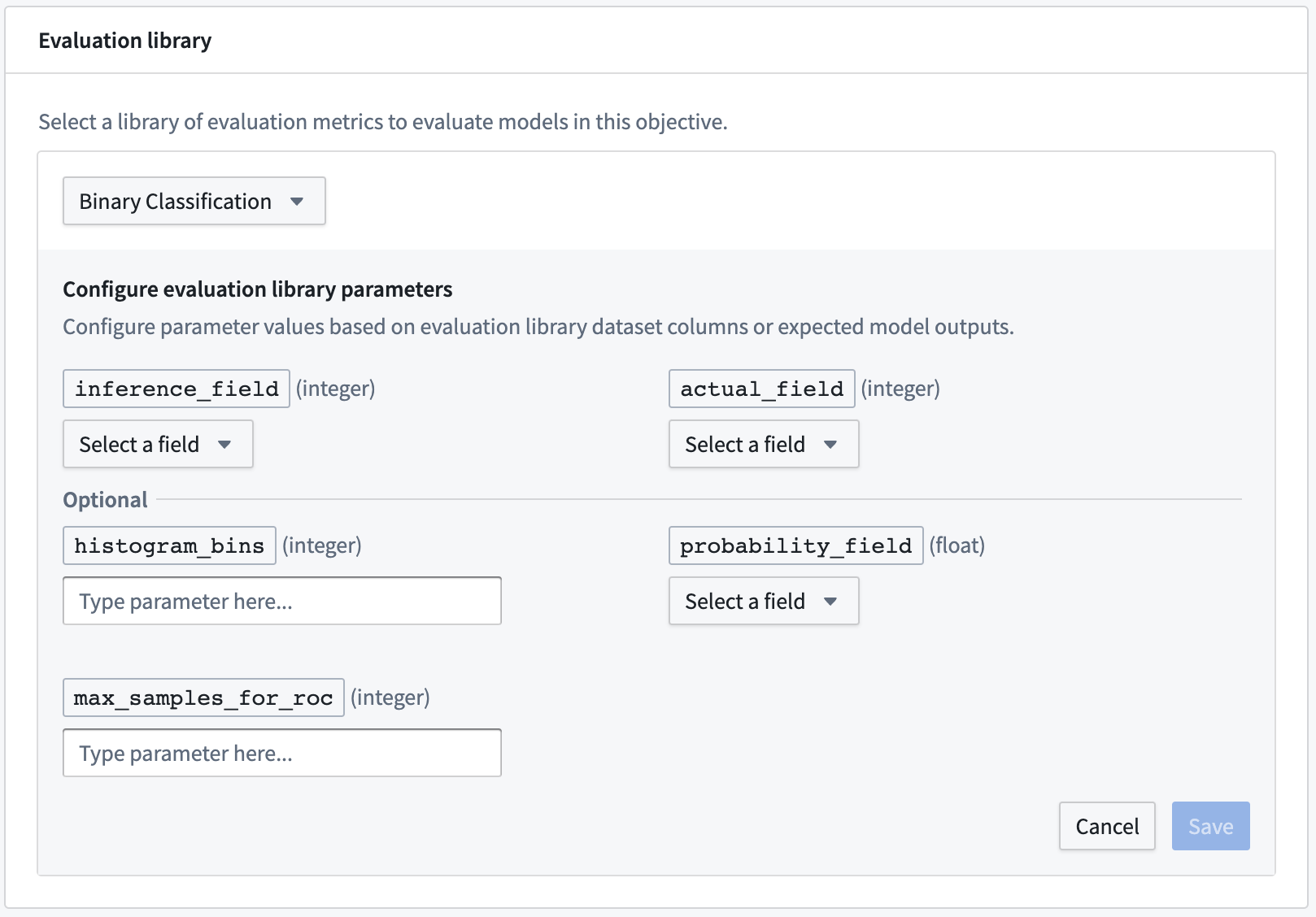
評価ライブラリを設定するには、評価ライブラリの選択をクリックし、評価ライブラリを選択して、そのモデル評価者に期待されるフィールドを設定します。列入力タイプの場合、モデリングの目的は任意の評価データセットで利用可能な列を提案します。さらに、ドロップダウンに表示されない場合やモデルのトランスフォームによって生成されることがわかっている場合は、モデル提出が生成すると期待される列を表す期待されるモデル出力の追加も行えます。
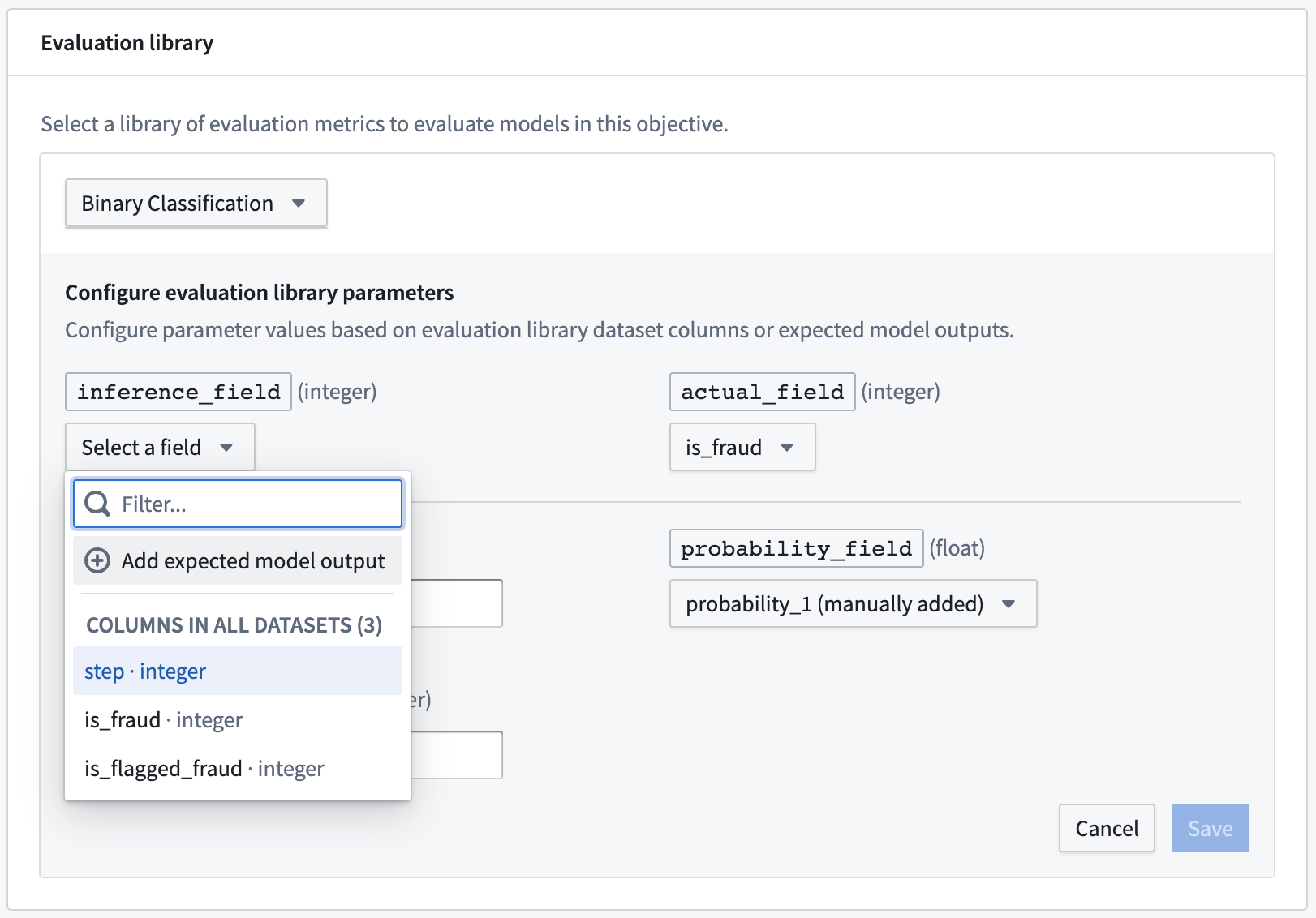
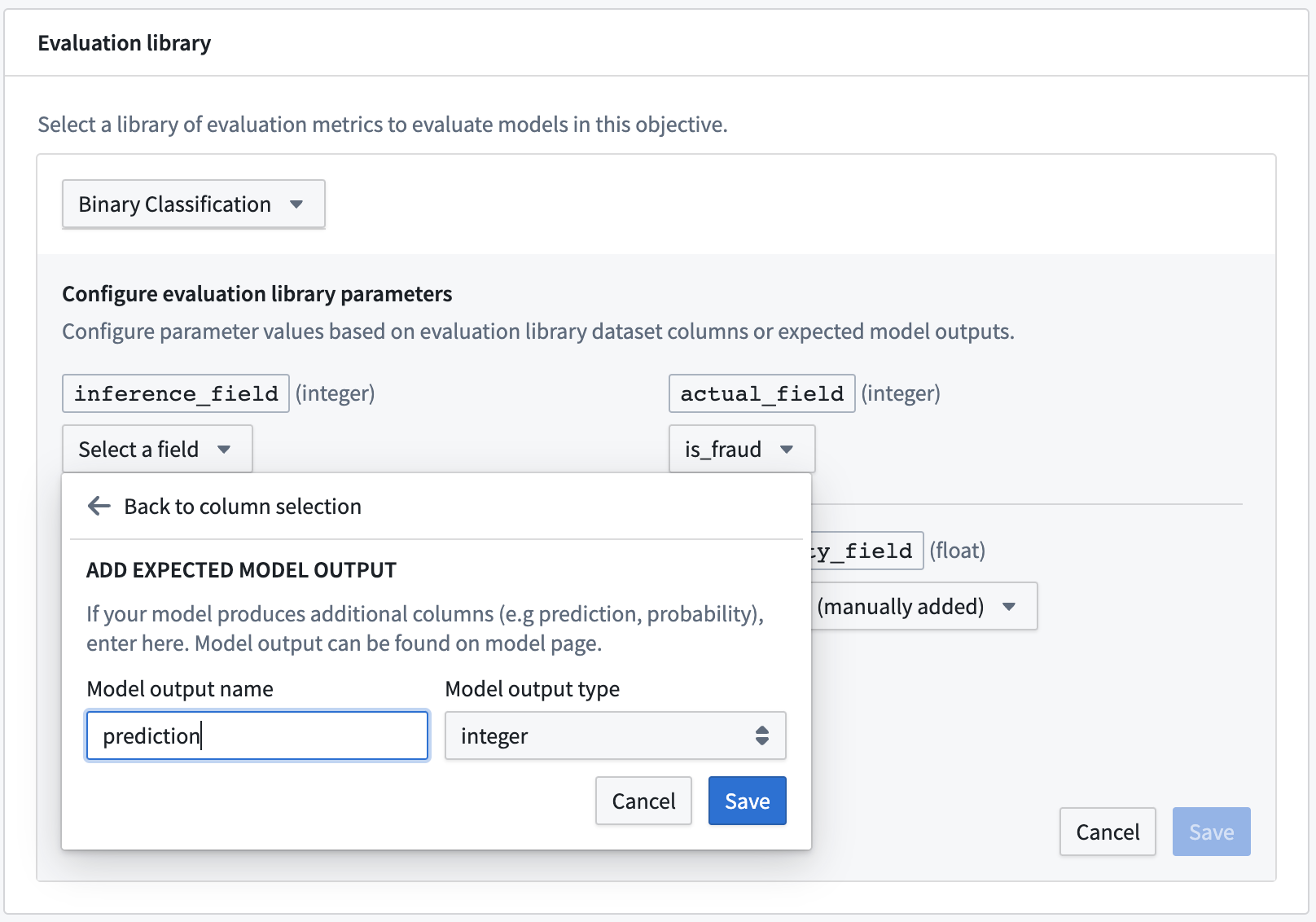
最も一般的な期待されるモデル出力のタイプは、予測出力(しばしばpredictionと名付けられる)、確率出力(しばしばprobability_1と名付けられる)、および信頼スコアです。
評価サブセットの設定
自動モデル評価の設定のオプションのステップは、評価ライブラリに対してメトリクスを生成する評価サブセットを定義することです。評価サブセットは、評価データセット内のデータのサブセットであり、そのサブセットに対してメトリクスが個別に生成されます。評価サブセットのメトリクスは、評価ダッシュボードを通じて個別に分析できます。
評価サブセットは、特定の入力データグループに対するモデルのパフォーマンスを理解するのに役立ち、モデルの解釈性、説明可能性、および潜在的に保護されるクラス全体での公平性を向上させるために使用できます。評価サブセットは、評価データセットの任意の列で生成できるため、モデルの特徴やモデルの予測などのモデル変換の入力または出力で生成される必要はありません。
メトリクスは常に、各評価データセットのすべての行に対して「全体」サブセットで生成されます。自動メトリクス生成のための評価サブセットの設定は任意です。
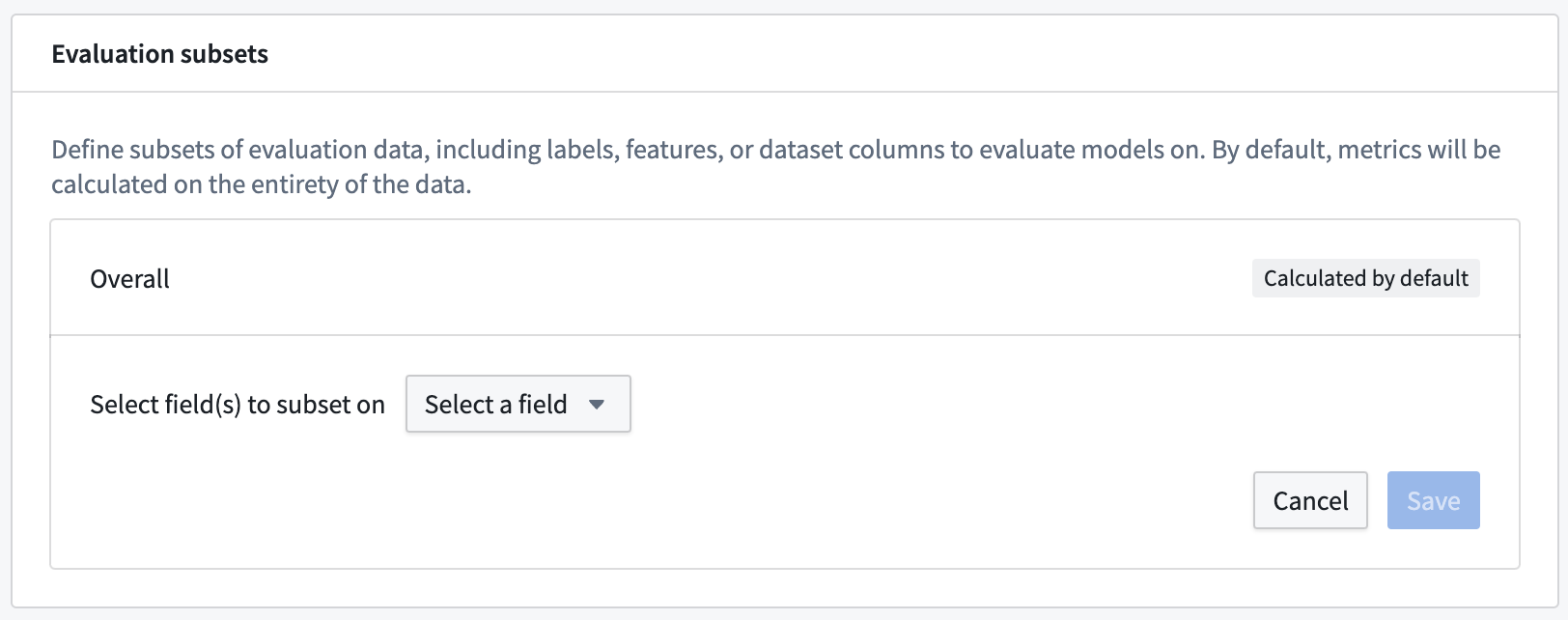
評価サブセットを設定するには、評価サブセットの追加をクリックし、評価データセットの列または期待されるモデル出力を選択してサブセットを作成します。
分類バケット
評価サブセットからstringタイプのフィールドを選択すると、評価パイプラインが構築される時点で評価ライブラリ内の各ユニークな文字列値に対してユニークなサブセットが生成されます。
定量バケット
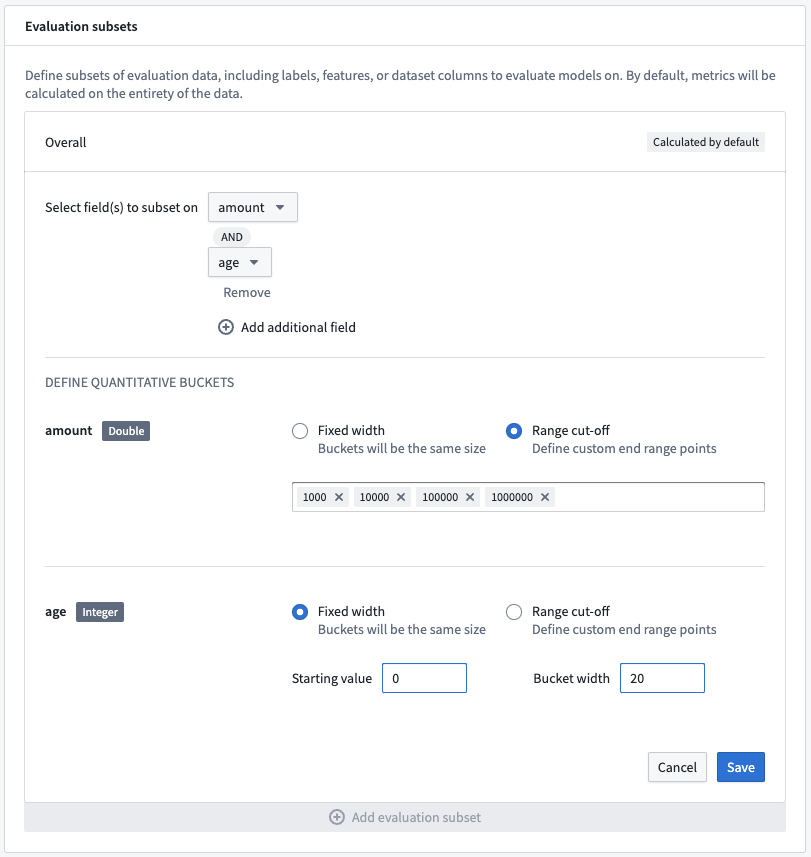
評価サブセットから数値タイプのフィールドを選択すると、サブセットを生成するために使用される定量的なバケッティング戦略を選択できます。バケットは固定幅または特定の範囲カットオフで定義できます。両方のバケッティング戦略は、以下のように定義されたバケットを作成します:
- 下限を含む範囲から、
- 上限を含む範囲まで。
固定幅のバケットの場合、開始値とバケット幅の両方を指定する必要があります。選択したフィールドの範囲のエンティティに対して、正および負の両方でバケット幅ごとにユニークなサブセットが生成されます。
範囲カットオフは、指定したすべての値の範囲にわたるサブセットを生成します。選択したフィールドの全範囲をカバーしない場合、列の最小値から最小カットオフまで、および最大カットオフから列の最大値までの2つの追加バケットが生成される場合があります。
すべてのユニークなサブセットは、すべての評価データセットおよびライブラリで評価されます。その結果、多数のサブセットを生成すると、モデル評価のビルド時間が大幅に増加する可能性があります。
複数フィールドのサブセット
複数のフィールドの組み合わせを表すサブセットを生成することが可能です。複数のフィールドで追加のフィールドを追加をクリックして、複数の列または期待されるモデル出力を選択し、単一のサブセットに結合します。これにより、フィールド間のバケットの組み合わせごとにサブセットが作成されます。
定量バケッティング戦略は、各サブセットフィールドに対して一意に定義できます。
評価サブセットプレビューの確認
評価サブセットを設定すると、ページの右側に評価データセットのプレビューが表示されます。このプレビューは、設定したすべての評価データセットに対して利用でき、評価設定によって生成される評価サブセットの数を確認するために使用できます。
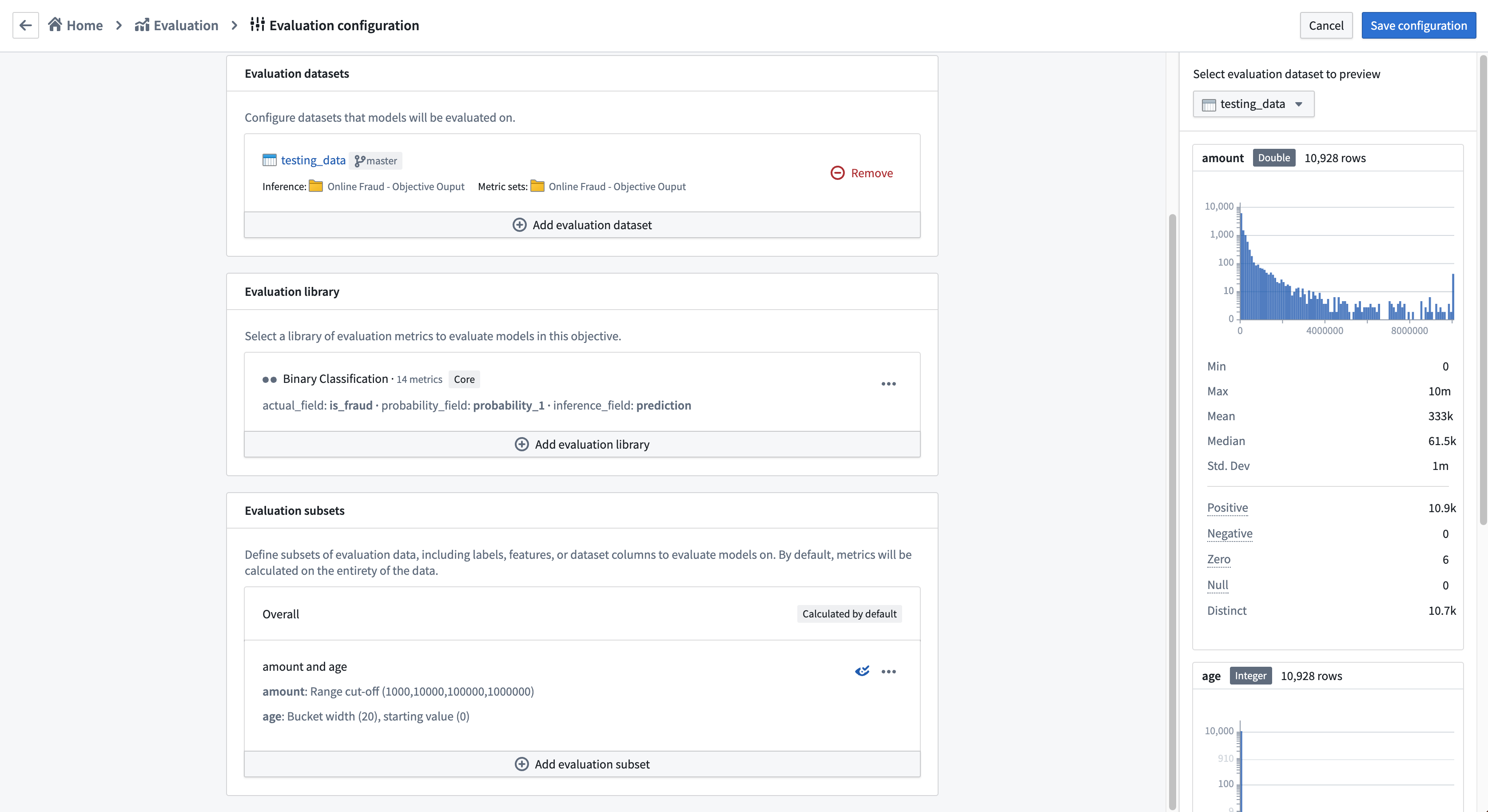
評価設定の保存
ページの右上隅にある設定の保存をクリックして評価設定を保存し、評価ダッシュボードに戻ります。