注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
リグレッション評価器
モデリング目的におけるデフォルトの評価ライブラリの一つが、リグレッション評価器です。このライブラリは、リグレッションモデルを評価するために一般的に用いられる一連のメトリクスを提供します。
含まれるメトリクス
以下のメトリクスは、評価ダッシュボードで設定されたすべてのサブセットバケットに対して生成されます。
デフォルトのリグレッション評価器は以下の数値メトリクスを生成します:
- 行数: 評価データセット内のレコード数。
- 平均絶対誤差: ラベルデータとモデル予測の間の平均誤差(差異)、誤差の方向に関係なく。この値は常に正で、モデルが評価データセットでより良くパフォーマンスを発揮すると0に近づきます。
- 平方根平均二乗誤差: 平均絶対誤差と同様に、平方根平均二乗誤差もラベルデータとモデル予測の差を表しますが、誤差の方向は無視します。しかし、平方根平均二乗誤差は、ラベルデータから遠い予測により大きな重みを付けます。この値は常に正で、モデルが評価データセットでより良くパフォーマンスを発揮すると0に近づきます。
- R2 スコア: R2(R スクエア)スコアは、モデルによって説明されるラベルデータの分散の割合を表します。この値は常に1以下で、スコアが1に近いほど、モデルは評価データセットに対してより良くパフォーマンスを発揮します。R2 スコアは負の値になることがあります。
- 説明分散: R2 スコアと同様に、これはモデル予測によって説明されるラベルデータの分散の割合を表します。説明分散は平均誤差がゼロでない場合に R2 スコアと異なり、この差はモデルバイアスを示します。この値は常に1以下で、スコアが1に近いほど、モデルは評価データセットに対してより良くパフォーマンスを発揮します。説明分散は負の値になることがあります。
デフォルトのリグレッション評価器は以下のプロットを生成します:
- スコア分布: 評価データセット上のモデル予測の分布を示すチャート。
- 残差: 評価データセット上の残差の分布を示すチャート、ここで残差とは
label_value - predictionです。
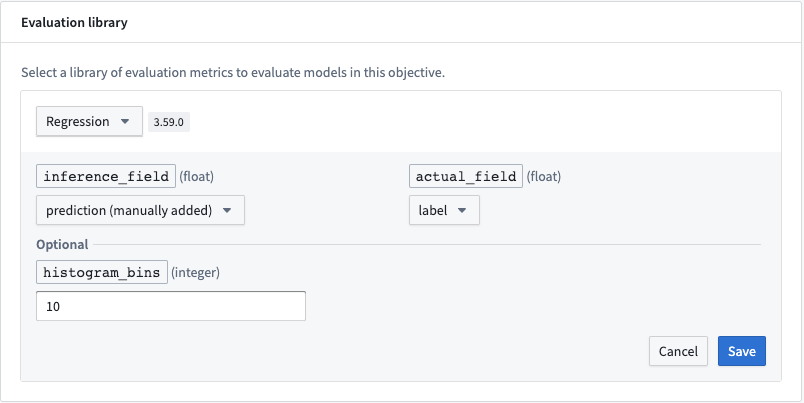
設定
完全な設定手順については、モデル評価ライブラリの設定方法のドキュメンテーションを参照してください。
必須フィールド
リグレッション評価器には以下のフィールドが必要です。これらの行の予想値のタイプは整数です。
- inference_field: モデルの予測を表す行。
- actual_field: モデルの予測が比較されるべき値を含む行。
オプションフィールド
- histogram_bins: スコア分布と残差のプロットのために残差とモデルスコアをグループ化するバケットの数。提供されていない場合、これはデフォルトで
10になります。