注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
カスタム評価ライブラリ
評価ライブラリは、Foundryで公開されたPythonパッケージで、モデル評価器を生成します。評価ライブラリは、モデルのパフォーマンス、モデルの公平性、モデルの堅牢性、および他のメトリックを、異なるModeling Objectives間で再利用可能な方法で測定するために使用されます。
Foundryのデフォルトのモデル評価器である二値分類モデルと回帰モデルに加えて、Foundryはモデリング目的でネイティブに使用できるカスタムモデル評価器を作成することもできます。
モデリング目的の中のカスタム評価器
カスタム評価器、その設定オプション、および生成されたメトリックは、Modeling Objectivesアプリケーションに、評価器の実装の上部にあるドックストリングで指定された名前と説明とともに表示されます。
カスタム評価器が公開されると、公開されたライブラリへの表示アクセス権を持つユーザーがModeling Objectiveアプリケーションで使用できるようになります。これにより、組織全体で標準化されたメトリックを計算するための再利用可能なロジックを作成できます。
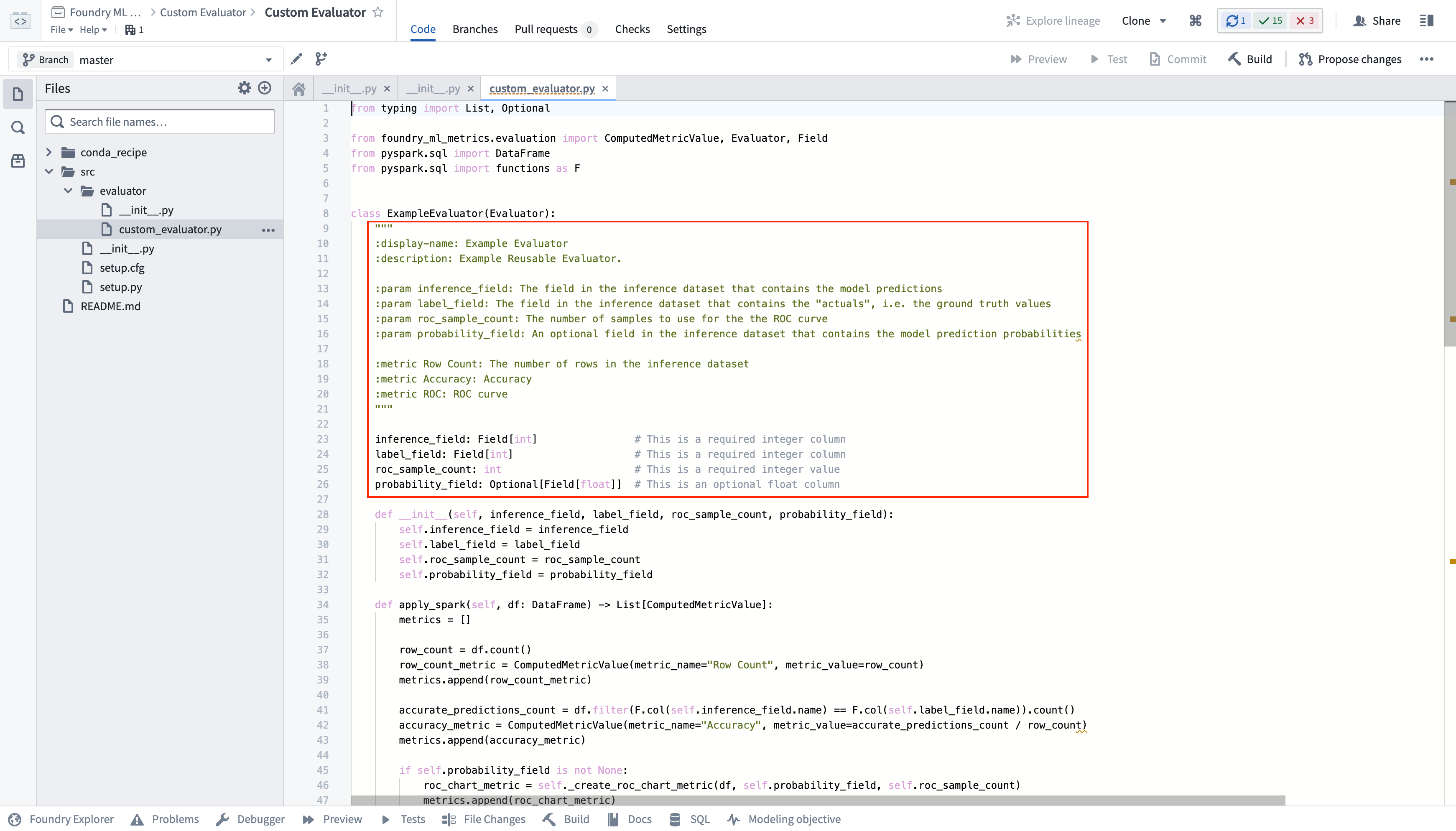
カスタム評価器は、モデリング目的の評価ライブラリ設定内で選択可能であり、そのライブラリは評価器によって定義されたパラメーターに基づいて設定可能です。
カスタム評価器の作成
カスタム評価器を作成するには:
Model Evaluator Template Libraryからコードリポジトリを作成します。- カスタム評価器を実装します。
- カスタム評価器にパラメーターを追加します。
- 変更をコミットして、新しいタグを公開します。
コードリポジトリの作成
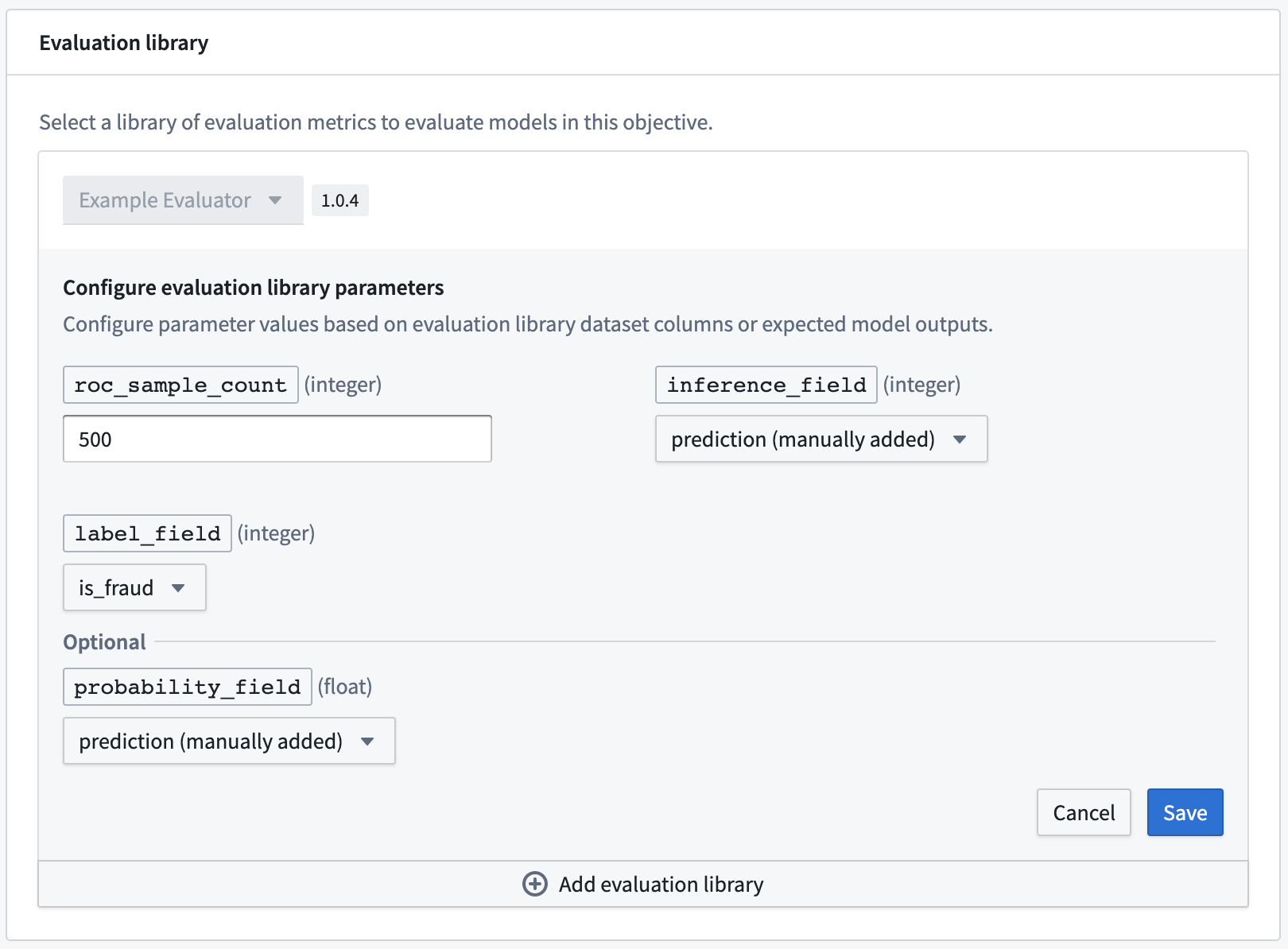
Code Repositoriesアプリケーションには多くのテンプレート実装があります。ここでは、Model Evaluator Template Libraryを使用します。Foundryプロジェクトに移動し、+ New > リポジトリタイプ > モデルインテグレーション > 言語テンプレートを選択し、Model Evaluator Template Libraryを選択して、最後にリポジトリの初期化を選択します。
評価器テンプレートの構造
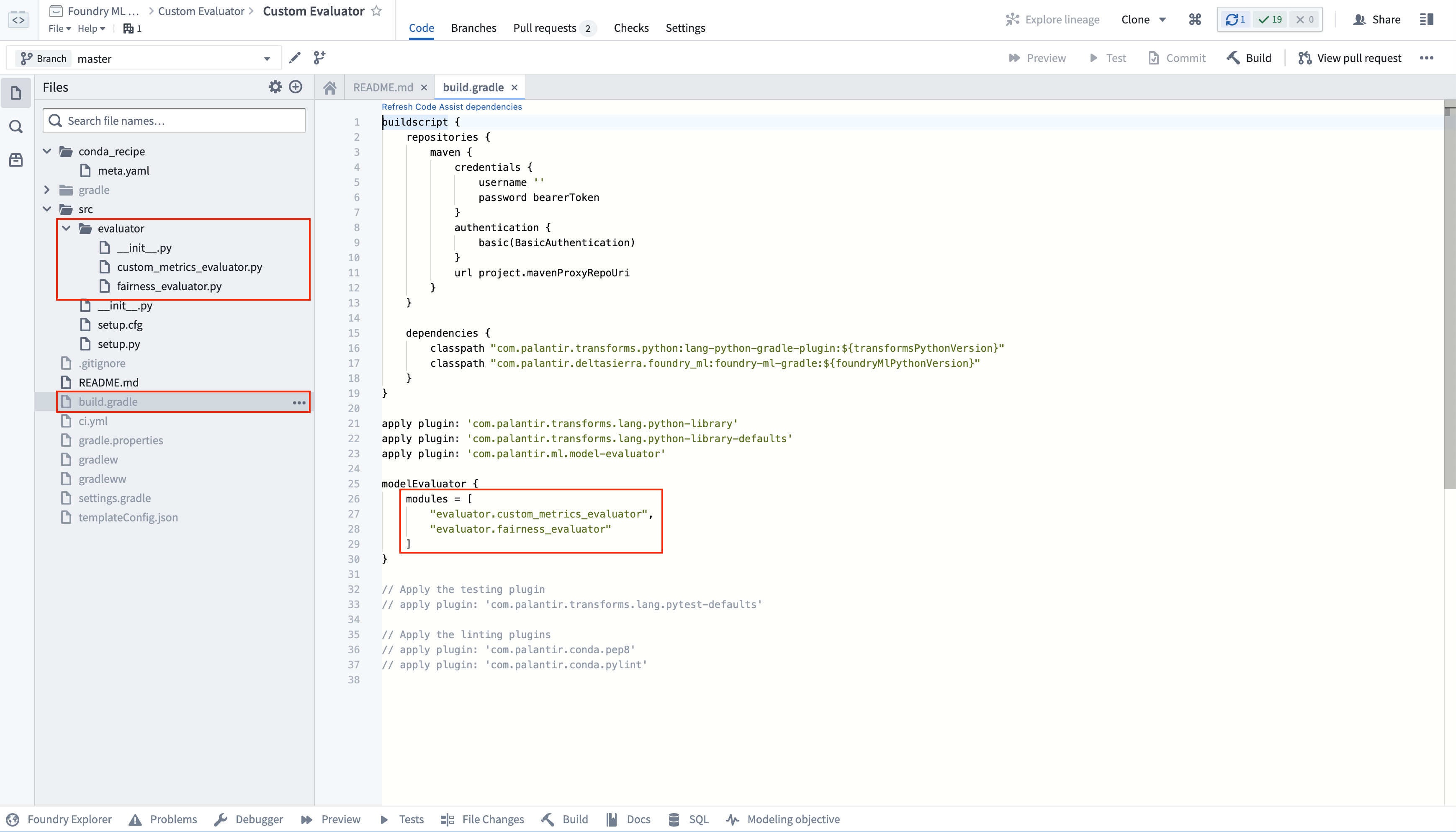
Model Evaluator Template Libraryには、ファイルsrc/evaluator/custom_evaluator.pyに例示実装があります。Evaluator Python インターフェースの実装は、新しいリポジトリバージョンタグでそのリポジトリの新しいバージョンを公開すると、自動的に登録され、利用可能になります。
カスタム評価器ロジックを含むリポジトリは、複数の評価器を公開できます。評価器テンプレートのbuild.gradleにあるモデル評価器モジュールのリストに、追加の評価器実装ファイルを参照として追加する必要があります。
カスタム評価器の実装
カスタム評価器を実装するには、Evaluatorインターフェースの実装を作成し、必要に応じてModeling Objectivesアプリケーションが解釈するための設定フィールドを提供する必要があります。
評価器テンプレートライブラリで、ファイルsrc/evaluator/custom_evaluator.pyに評価器を追加します。
評価器インターフェース
評価器のインターフェースは以下のように定義されます。
Copied!1 2 3 4 5 6 7 8 9 10 11class Evaluator(): def apply_spark(self, df: DataFrame) -> List[ComputedMetricValue]: """ この評価者を適用して、PySparkデータフレームで指標を計算します。 :param df: 指標を計算するPySpark DataFrame :return: 計算された指標値のリスト """ pass
新しく設定されたカスタム評価器を Modeling Objectives アプリケーションで使用するには、まずリポジトリの新しいバージョンを公開し、新しいリポジトリバージョンタグを付ける必要があります。
評価器のドキュメント
カスタム評価器とその設定オプション、生成されるメトリクスは、実装の先頭にあるドックストリングに指定された名前と説明で Modeling Objectives アプリケーションに表示されます。
必要な値は以下の通りです。
display-name:評価器の表示名description:評価器の説明
オプションで以下のものを追加できます。
param:カスタム評価器の設定パラメーターmetric:評価器によって生成されるメトリクス
例:評価器の実装
これは、入力データセットの行数を計算する例の評価器です。
この例の評価器は、Modeling Objectives アプリケーションで以下のように表示されます。
- タイトル
Row Count Evaluator。 - 説明
この評価器は、入力 DataFrame の行数を計算します。 - 生成されるメトリクス
Row Countで、説明は行数。 - 設定パラメーターはゼロ。
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24from pyspark.sql import DataFrame from pyspark.sql import functions as F from foundry_ml_metrics.evaluation import ComputedMetricValue, Evaluator class CustomEvaluator(Evaluator): """ :display-name: 行数評価器 :description: この評価器は、入力DataFrameの行数を計算します。 :metric 行数: 行数 """ def apply_spark(self, df: DataFrame) -> List[ComputedMetricValue]: # DataFrameの行数を計算します row_count = df.count() return [ ComputedMetricValue( # メトリック名は 'Row Count' metric_name='Row Count', # メトリックの値は計算した行数 metric_value=row_count ) ]
評価器のパラメータ化
評価器は、設定パラメーターを提供することで、Modeling Objectives アプリケーションで設定可能にすることができます。 設定パラメーターは、実行時にユーザーが入力した値で Modeling Objectives アプリケーションによって入力されます。 この評価器のユーザーは、モデリング目的で自動評価を設定する際に、パラメーターの値を設定する機会を持つことができます。
許可される設定フィールドは以下の通りです:
int:整数float:浮動小数点数bool:ブーリアン値(True または False)str:文字列の値Field[float]:入力 DataFrame の浮動小数点の行Field[int]:入力 DataFrame の整数の行Field[str]:入力 DataFrame の文字列の行
パラメーターは、Optional(組み込みの typing パッケージから)でラップすることでオプションにすることができます。
例えば:
- オプションの
strはOptional[str]になります。 - オプションの
Field[str]はOptional[Field[str]]になります。
設定フィールドを持つ評価器の例
これは、入力データセットの行数と、入力行 column が値 value を持つようにフィルター処理された入力データフレームの行数を計算する評価器の例です。
この例の評価器は Modeling Objectives アプリケーションに以下のように表示されます:
- タイトルは
Configurable Row Count Evaluator。 - 説明は
This evaluator calculates the row count of the input DataFrame, filtered to the specified value.です。 - 生成されたメトリック
Row CountはThe unfiltered row countという説明があります。 - 生成されたメトリック
Filtered Row CountはThe filtered row countという説明があります。 - 2つの設定パラメーター:
- 評価データセットの行で、名前が
columnで説明がFiltered columnの整数でなければならない。 - 名前が
valueで説明がFiltered valueの整数値。
- 評価データセットの行で、名前が
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45from pyspark.sql import DataFrame from pyspark.sql import functions as F from foundry_ml_metrics.evaluation import ComputedMetricValue, Evaluator, Field class CustomEvaluator(Evaluator): """ :display-name: 設定可能な行数評価器 :description: この評価器は、指定された値にフィルタリングされた入力DataFrameの行数を計算します。 :param column: フィルタリングされた列 :param value: フィルタリングされた値 :metric Row Count: フィルタリングされていない行数 :metric Filtered Row Count: フィルタリングされた行数 """ column: Field[int] value: int def __init__(self, column: Field[int], value: int): self.column = column self.value = value def apply_spark(self, df: DataFrame) -> List[ComputedMetricValue]: column_name = self.column.name column_value = self.value # 行数を取得 row_count = df.count() # フィルタリングされた行数を取得 filtered_row_count = df.filter( F.col(column_name) == column_value ).count() return [ ComputedMetricValue( metric_name='Row Count', metric_value=row_count ), ComputedMetricValue( metric_name='Filtered Row Count', metric_value=filtered_row_count ) ]
参照クラス
以下のクラスは参照として提供されています。
Field
Field は、ユーザーの評価用ライブラリに対して、どのプロパティが実装される必要があるかを示す設定パラメーターとして使用されます。
Field は、以下のインターフェースを持っています。
Copied!1 2class Field(): name: str # 名前という名前の文字列型の属性
ComputedMetricValue
ComputedMetricValue は、Foundry モデルにアタッチするメトリックに関する情報を保存します。
Copied!1 2 3 4 5 6 7 8 9 10class ComputedMetricValue(): """ 評価者の一人によって計算されたメトリック。メトリック名、値、サブセット情報を含む。 """ metric_name: str # メトリックの名前 metric_value: MetricValue # メトリックの値 def __init__(self, metric_name, metric_value): self.metric_name = metric_name # メトリックの名前を初期化 self.metric_value = metric_value # メトリックの値を初期化
MetricValue
MetricValueは以下のいずれかになります。
- 次の型の数値:
- int
- np.int8
- np.int16
- np.int32
- np.int64
- np.uint8
- np.uint16
- np.uint32
- np.uint64
- float
- np.float32
- np.float64
- 次の型の図:
- matplotlib.Figure
- matplotlib.pyplot.Figure
- 以下のメソッドのうちちょうど1つを実装するクラス:
get_figure(self) -> Figure:多くの seaborn プロットがこの関数を実装していることに注意してください。save(self, path: str):多くの seaborn プロットがこの関数を実装していることに注意してください。savefig(self, path: str)
- BarChart
- LineChart