- Capabilities
- Getting started
- Architecture center
- Platform updates
Apply Cipher operations to columns of datasets
Cipher allows you to encrypt, decrypt, and hash full columns of datasets. This is supported in Pipeline Builder, Contour, and Python transforms.
When using Preview in Code Repositories or Preview in Pipeline Builder, users will not be able to see the real output of Cipher operations. Instead, users in Preview will see the placeholder value. It is important to note that data will be encrypted at build time. To see the real output of Cipher operations, users should run a build.
Pipeline Builder
Pipeline Builder is a data integration application that aims to make it easier to perform high-quality data integrations in Foundry. This section demonstrates how to deploy Cipher operations to obfuscate columns of datasets in Pipeline Builder. To run a Cipher operation in Pipeline Builder, users must have access to a Cipher Data Manager License or Admin License.
Encryption
First, select the Cipher encrypt transform. Then, select an Expression (the column to be encrypted). Next, select a Data Manager License with encrypt permission, typically found in the Project folder after previous issuance in the Cipher application. Finally, name the output column.
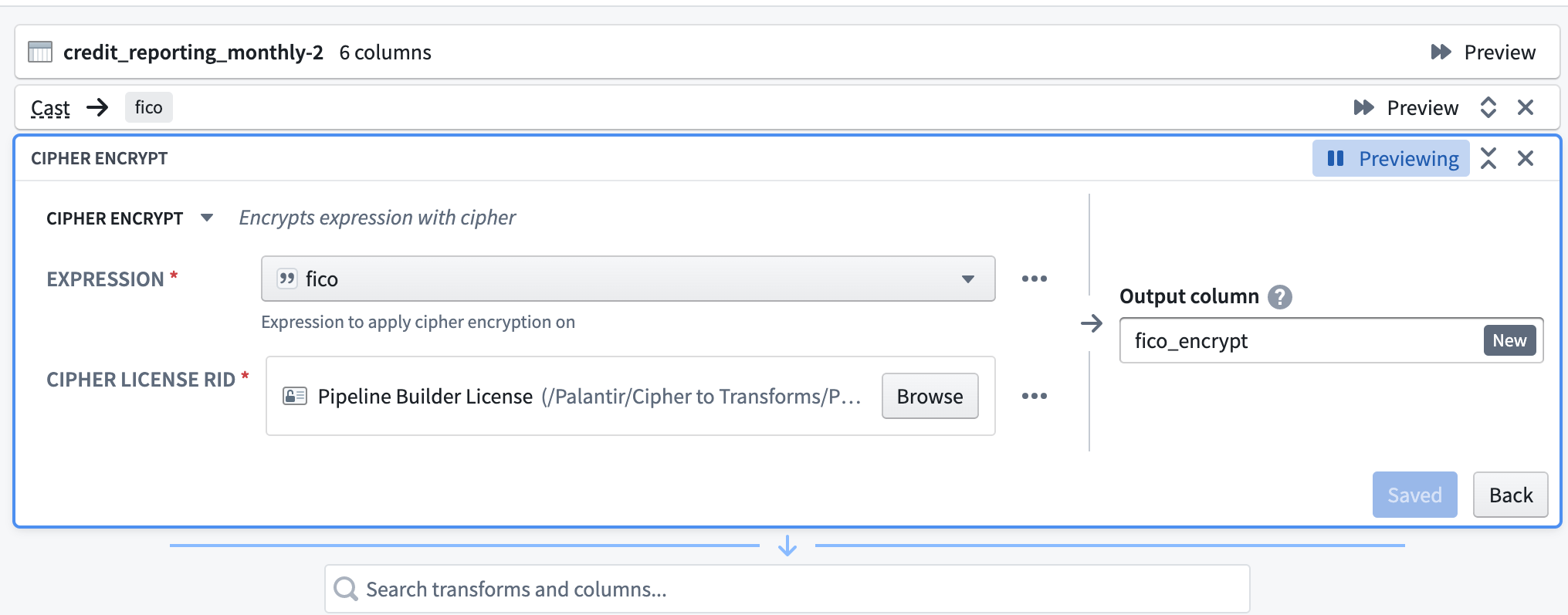
Decryption
First, select the Cipher decrypt transform. When selecting an Expression, specify a column that has already been encrypted via a Cipher transform. For the Cipher License RID, select a Data Manager License with decrypt permission, typically found in the Project folder after previous issuance in the Cipher application. Note that the License must be part of the same Cipher Channel used to encrypt the relevant column. Finally, name the output column.
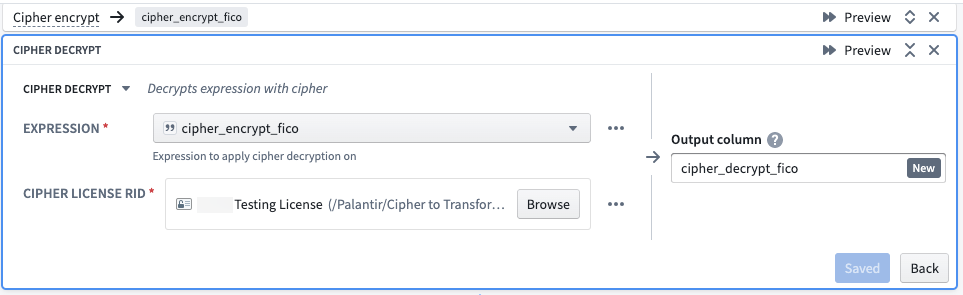
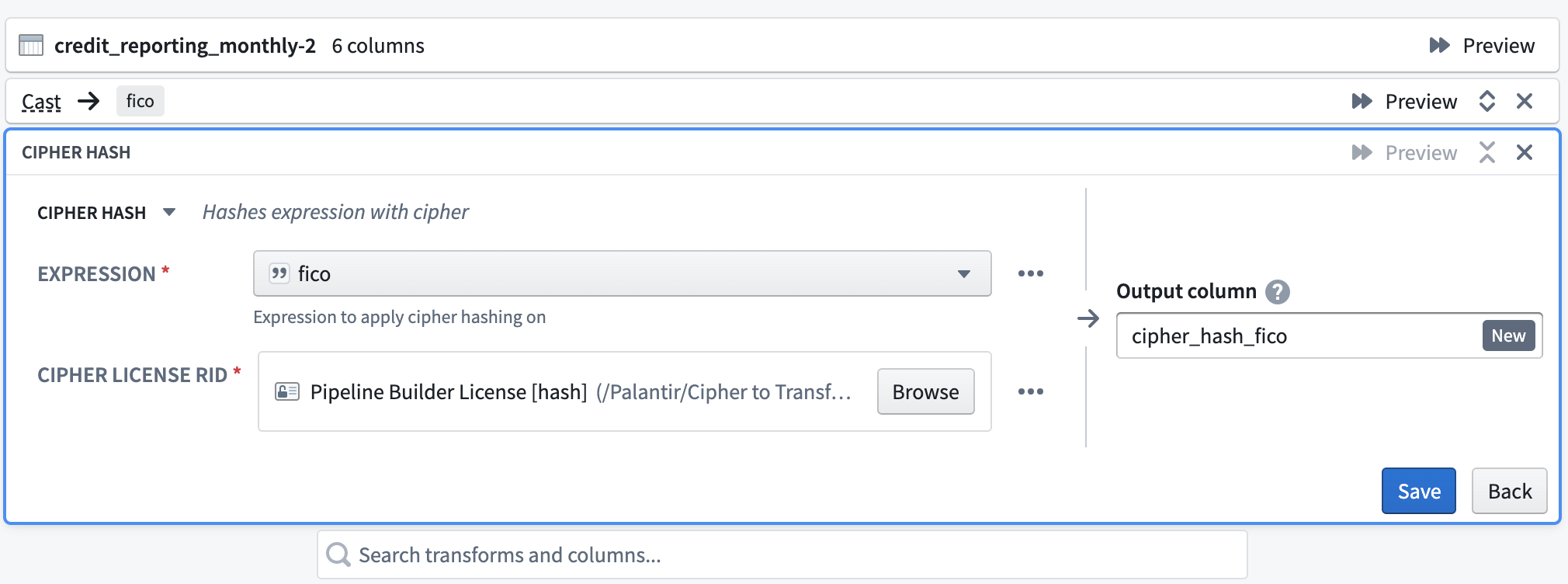
Hashing
Select the Cipher hash transform. For the Expression, specify the column to hash. Next, select a Data Manager License with permission to encrypt from a hash Cipher Channel. The License would have been issued in the Cipher application and then saved in a Project folder. Finally, name the output column.
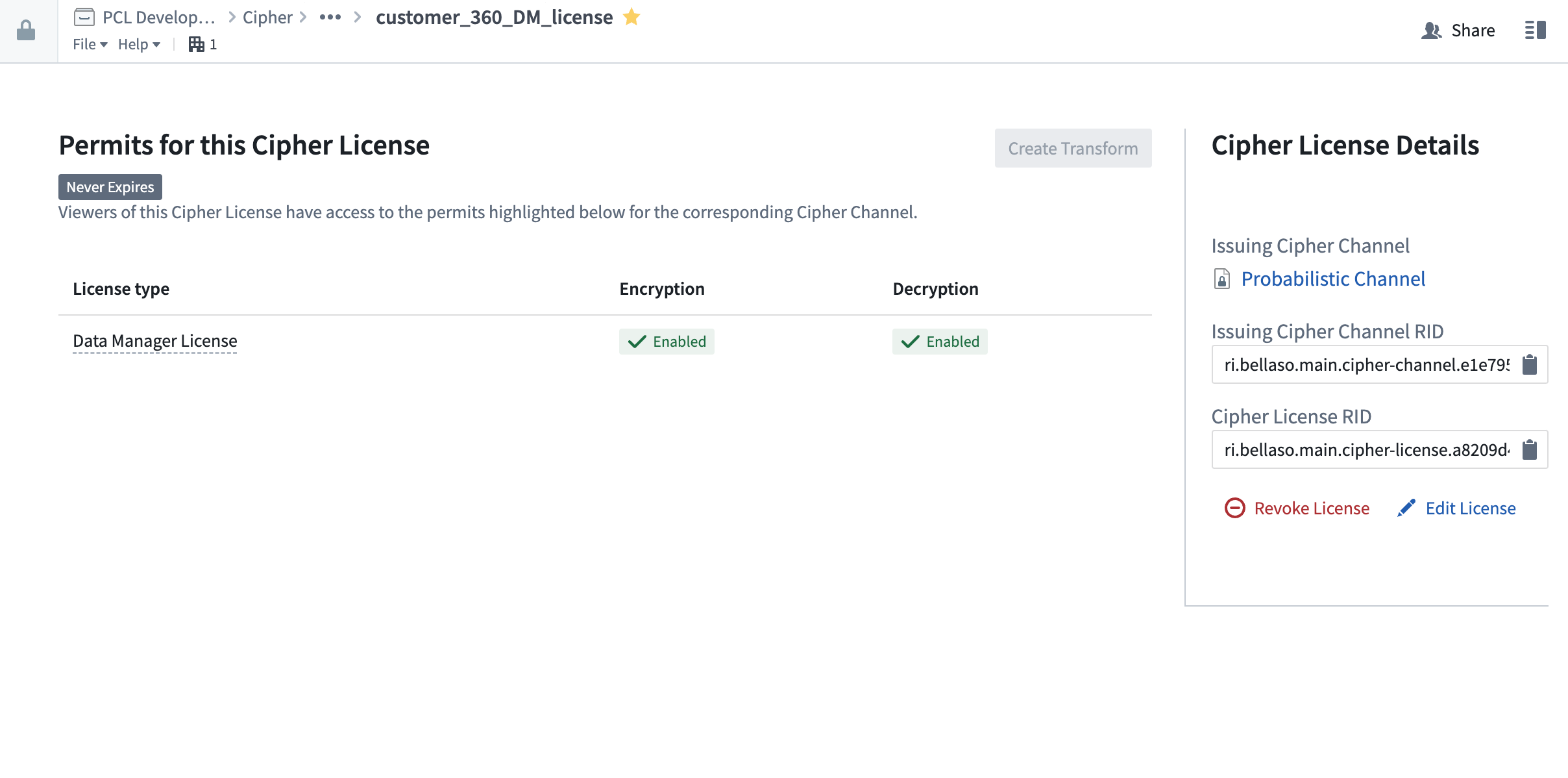
How to encrypt pipelines with Cipher (Admin and Data Manager Licenses only)
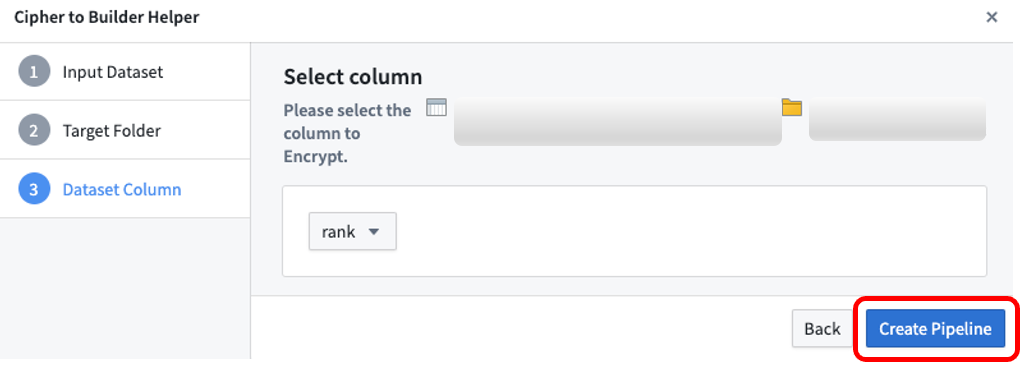
First, open a Cipher License with encrypt permission; licenses are typically found in the Project folder after previous issuance in the Cipher application. Then, select 'Create Pipeline' at the top right.
Select the input dataset to encrypt, then the target folder in which the pipeline will be saved, and then the dataset column you want to encrypt. Note that only String columns are available for encryption; if you need to encrypt another column, first cast it to String. After selecting Create Pipeline, Cipher will automatically generate a new pipeline and encrypt the column you previously selected.
Contour
Contour provides a point-and-click user interface to perform data analysis on tables at scale. This section demonstrates how to use Cipher operations to (de)obfuscate columns of datasets in a Contour Analysis. To run a Cipher operation in Contour, users must have access to a Cipher Data Manager License or Admin License. To begin, use the Contour toolbar search mode to add a Cipher board to an analysis.
Contour's table board and table panel can be used to see the result of the Cipher operation.
A Contour analysis path that uses a Cipher board cannot be saved as a dataset.
Encryption
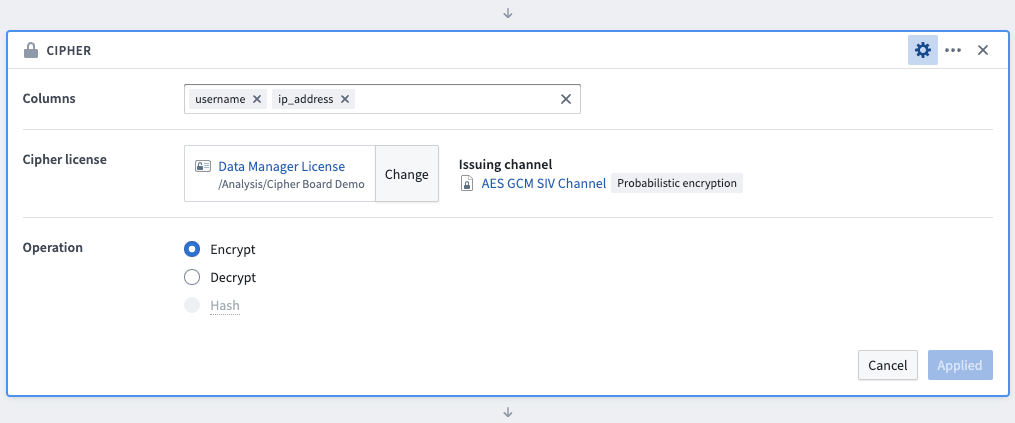
To use the Cipher board to encrypt data, first select the columns to be encrypted (the order in which the columns are selected has no impact on the operation). Next, select a Data Manager License or Admin License with encrypt permission, typically found in the Project folder after previous issuance in the Cipher application. Select the Encrypt operation and save the board. Column values will be updated by this transformation, but column names will remain unmodified.
Decryption
To use the Cipher board to encrypt data, first select the columns to be decrypted (the order in which the columns are selected has no impact on the operation). Next, select a Data Manager License or Admin License with decrypt permission, typically found in the Project folder after previous issuance in the Cipher application. Select the Decrypt operation and save the board. Column values will be updated by this transformation, but column names will remain unmodified.
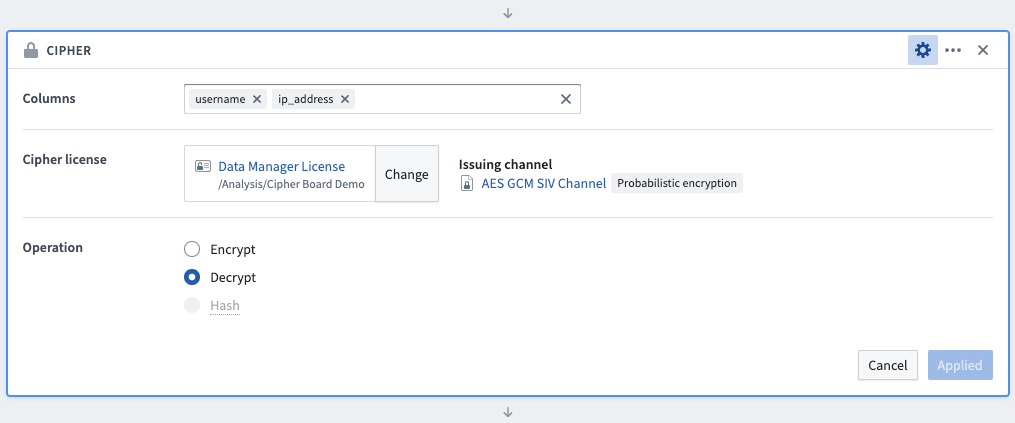
Hashing
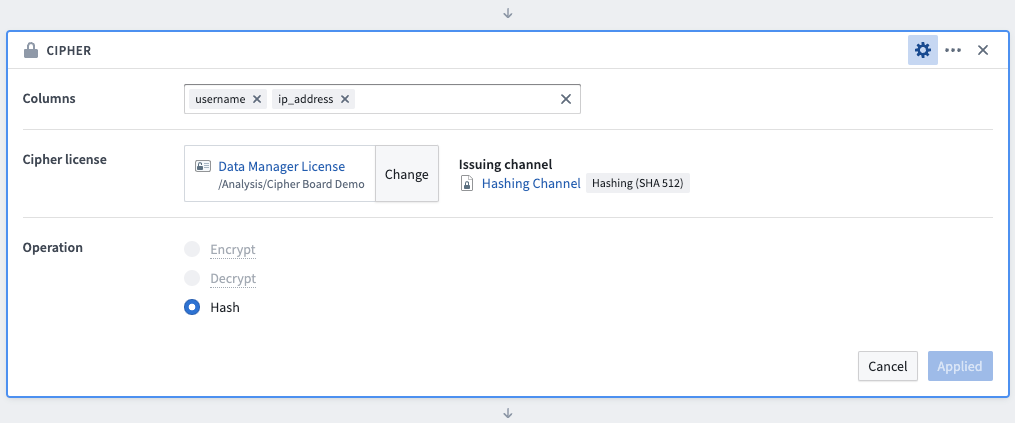
To use the Cipher board to hash data, first select the columns to be hashed (the order in which the columns are selected has no impact on the operation). Next, select a Data Manager License or Admin License with hashing permission, typically found in the Project folder after previous issuance in the Cipher application. Select the Hash operation and save the board. Column values will be updated by this transformation, but column names will remain unmodified.
Python transforms
Set up a repository
Add bellaso-python-lib in the requirements.run block in conda_recipe/meta.yml. You can also do this automatically by adding it in the Libraries panel of your Code Repository environment. Note that an Admin License is necessary to perform Cipher operations in Transforms.
Encryption
To encrypt a column, you will need to define an EncrypterInput in the @transforms block. The EncrypterInput takes either the RID or the filesystem path to the Cipher License. Note that the Cipher License must have encryption permission.
Example:
Copied!1 2 3 4 5 6 7 8 9 10 11 12from transforms.api import transform, Input, Output from pyspark.sql.functions import col from bellaso_python_lib.encryption.encrypter_input import EncrypterInput @transform( encrypter=EncrypterInput("/path/to/cipher/license"), output=Output("/path/to/output/dataset"), input_dataset=Input("/path/to/input/dataset") ) def encrypt_column(ctx, input_dataset, output, encrypter): encrypted_df = input_dataset.dataframe().withColumn("your_column_name", encrypter.dataframe().encrypt(col("your_column_name"), ctx)) output.write_dataframe(encrypted_df)
Decryption
To decrypt a column, you will need to define a DecrypterInput in the @transforms block. The DecrypterInput takes either the RID or the filesystem path to the Cipher License. Note that the Cipher License must have decryption permission.
Example:
Copied!1 2 3 4 5 6 7 8 9 10 11 12from transforms.api import transform, Input, Output from pyspark.sql.functions import col from bellaso_python_lib.decryption.decrypter_input import DecrypterInput @transform( decrypter=DecrypterInput("/path/to/cipher/license"), output=Output("/path/to/output/dataset"), input_dataset=Input("/path/to/input/dataset") ) def decrypt_column(ctx, input_dataset, output, decrypter): decrypted_df = input_dataset.dataframe().withColumn("your_column_name", decrypter.dataframe().decrypt(col("your_column_name"), ctx)) output.write_dataframe(decrypted_df)
Hashing
To hash a column, you will need to define an HasherInput in the @transforms block. The HasherInput takes either the RID or the filesystem path to the Cipher License. Note that the Cipher License must have hashing permission.
Example:
Copied!1 2 3 4 5 6 7 8 9 10 11 12from transforms.api import transform, Input, Output from pyspark.sql.functions import col from bellaso_python_lib.encryption.hasher_input import HasherInput @transform( hasher=HasherInput("/path/to/cipher/license"), output=Output("/path/to/output/dataset"), input_dataset=Input("/path/to/input/dataset") ) def hash_column(ctx, input_dataset, output, hasher): hashed_df = input_dataset.dataframe().withColumn("your_column_name", hasher.dataframe().hash(col("your_column_name"), ctx)) output.write_dataframe(hashed_df)
To encrypt or hash data upon ingestion, you can use Cipher's Python library along with external transforms.
Incremental transforms
To use Cipher in an incremental transform, you must list all encrypters, decrypters, and hashers as snapshot inputs.
Example:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16from transforms.api import transform, incremental, Input, Output from bellaso_python_lib.encryption.encrypter_input import EncrypterInput from pyspark.sql.functions import col @incremental( snapshot_inputs=['encrypter'] ) @transform( encrypter=EncrypterInput("<YOUR_CIPHER_LICENSE_RID>"), output=Output("/path/to/output/dataset") input_dataset=Input("/path/to/input/dataset") ) def encrypt_column(ctx, input_dataset, output, encrypter): encrypted_df = input_dataset.dataframe().withColumn("encrypted_column", encrypter.dataframe().encrypt(col("<YOUR_COLUMN_NAME>"), ctx)) output.write_dataframe(encrypted_df)
Visual Obfuscation
To hash a column, you will need to define an EncrypterInput in the @transforms block. The EncrypterInput takes either the RID or the filesystem path to the Cipher License. Note that the Cipher License must have encryption permission.
Example:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31from transforms.mediasets import MediaSetInput, MediaSetOutput import io from bellaso_python_lib.encryption.encrypter_input import EncrypterInput from bellaso_python_lib.types import Coordinate @transform( mediaset_in=MediaSetInput("</path/to/input/media/set"), mediaset_out=MediaSetOutput("</path/to/output/media/set"), encrypter=EncrypterInput("/path/to/cipher/license"), polygons=Input("/path/to/polygon/dataset"), ) def compute(mediaset_in, mediaset_out, encrypter, polygons, ctx,): media_references = mediaset_in.list_media_items_by_path_with_media_reference( ctx ).collect() # noqa for row in media_references: image_file = mediaset_in.get_media_item(row["mediaItemRid"]) plainview_image = image_file.read() # Encrypt a square in the top left of the image, 100 px by 100 px. polygon = [Coordinate({"x": 0, "y": 0}), Coordinate({"x": 100, "y": 0}), Coordinate({"x": 100, "y": 100}), Coordinate({"x": 0, "y": 100})] polygon_list = [polygon] if plainview_image: encrypted_image = encrypter.encrypt_image(plainview_image, polygon_list, ctx) mediaset_out.put_media_item(io.BytesIO(encrypted_image), row["path"])