- Capabilities
- Getting started
- Architecture center
- Platform updates
Announcements
REMINDER: Sign up for the Foundry Newsletter to receive a summary of new products, features, and improvements across the platform directly to your inbox. For more information on how to subscribe, see the Foundry Newsletter and Product Feedback channels announcement.
Share your thoughts about these announcements in our Developer Community Forum ↗.
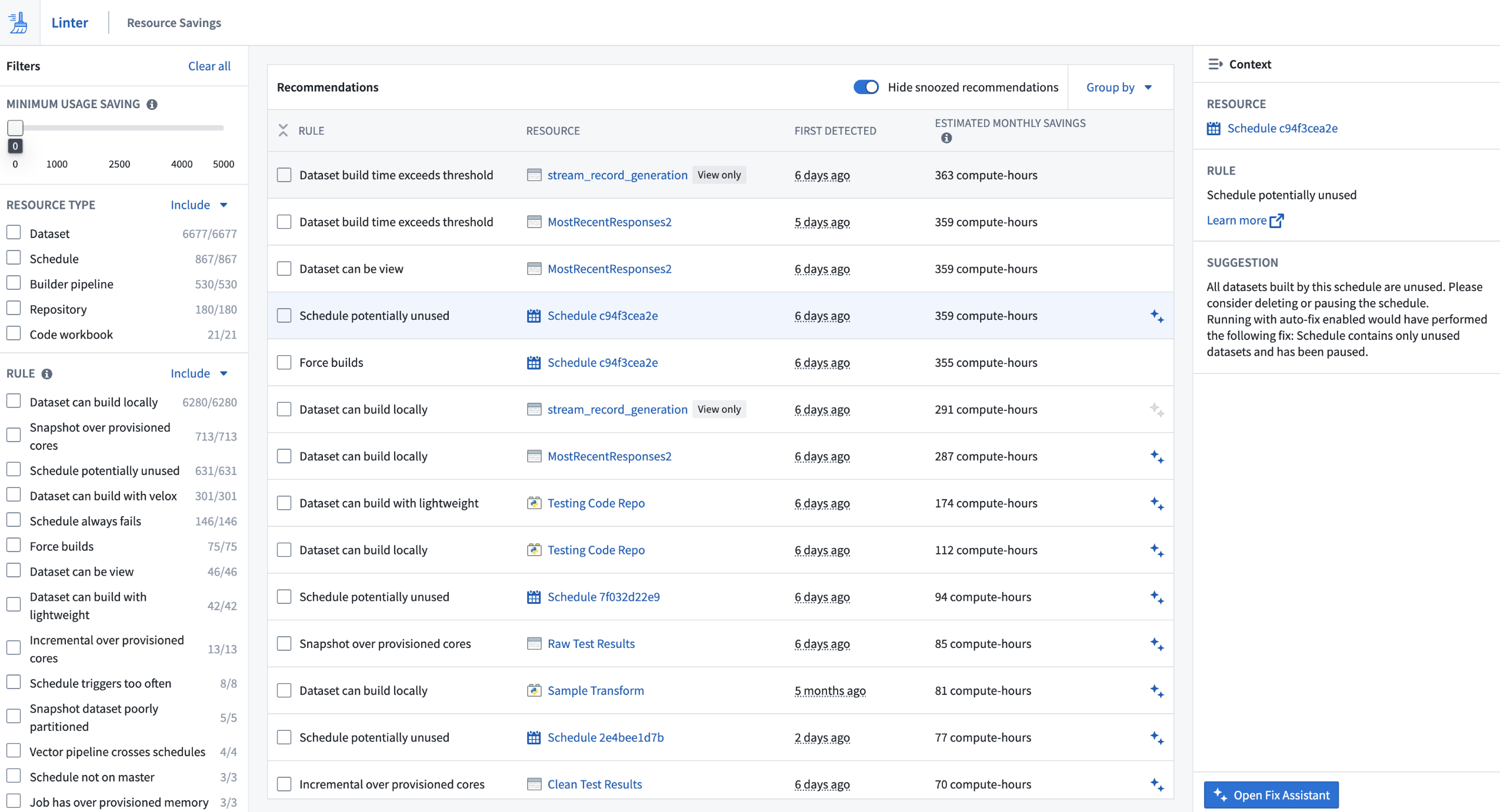
Generate actionable recommendations with Linter, generally available soon [GA]
Date published: 2024-09-24
We are happy to announce that Linter will be generally available for all enrollments the week of October 7. This change includes UI updates, improvements to scalability, visibility features for recommendations, and a fix assistant to help users act on recommendations. Linter generates opinionated, actionable recommendations when workflow designs incur unnecessary costs, do not use the latest Palantir platform features, or do not adhere to best practices. You can use these recommendations to reduce costs, optimize your Ontology, and increase pipeline stability and resilience across your enrollment.
With Linter, you can better understand the wide range of capabilities that the Palantir platform has to offer while monitoring platform updates that could benefit your use case objectives. Linter is enabled by default; if you are a platform administrator, you can configure user group access to Linter by navigating to Control Panel > Application access for the correct Organization, and selecting the Manage option next to Linter.
Why was Linter created?
The Palantir platform is the best place to host workflows, and while application builders aim to design optimized workflows, the reality is that design decisions can prove to be suboptimal in practice. To address this issue, we created Linter to ensure that workflows use available technology and achieve the same results with more efficient use of resources and features.
When should Linter be used?
Linter can be used at any time, whether you are just getting started with the Palantir platform, or you already have complex and extensive workflows in place. Linter will monitor new and existing workflows and provide ongoing recommendations, performing regularly-occurring sweeps to gather an analysis of the state of your enrollment. These sweeps identify a list of resources that match predefined rules and produce a list of recommendations based on sweep results.
Linter's Impact Tracking UI displaying the number of actioned recommendations
Because Palantir platform capabilities are frequently updated, the results of a Linter sweep are dynamic and can change from day to day. To keep up with these changes you can set up a sweep schedule to periodically perform sweeps against Foundry resources in Projects that belong to a space.

A sample sweep schedule, the option to generate a new schedule, the Actions dropdown, and recent sweep statuses
Reduce costs and optimize workflows
Users of Linter in beta investigated and eliminated significant amounts of compute-hours of waste in cloud costs, resulting in quantitative improvements. Impact for customers correlates to their platform usage, but even enrollments with relatively small developer bases have benefited from Linter to meet their cloud cost targets.
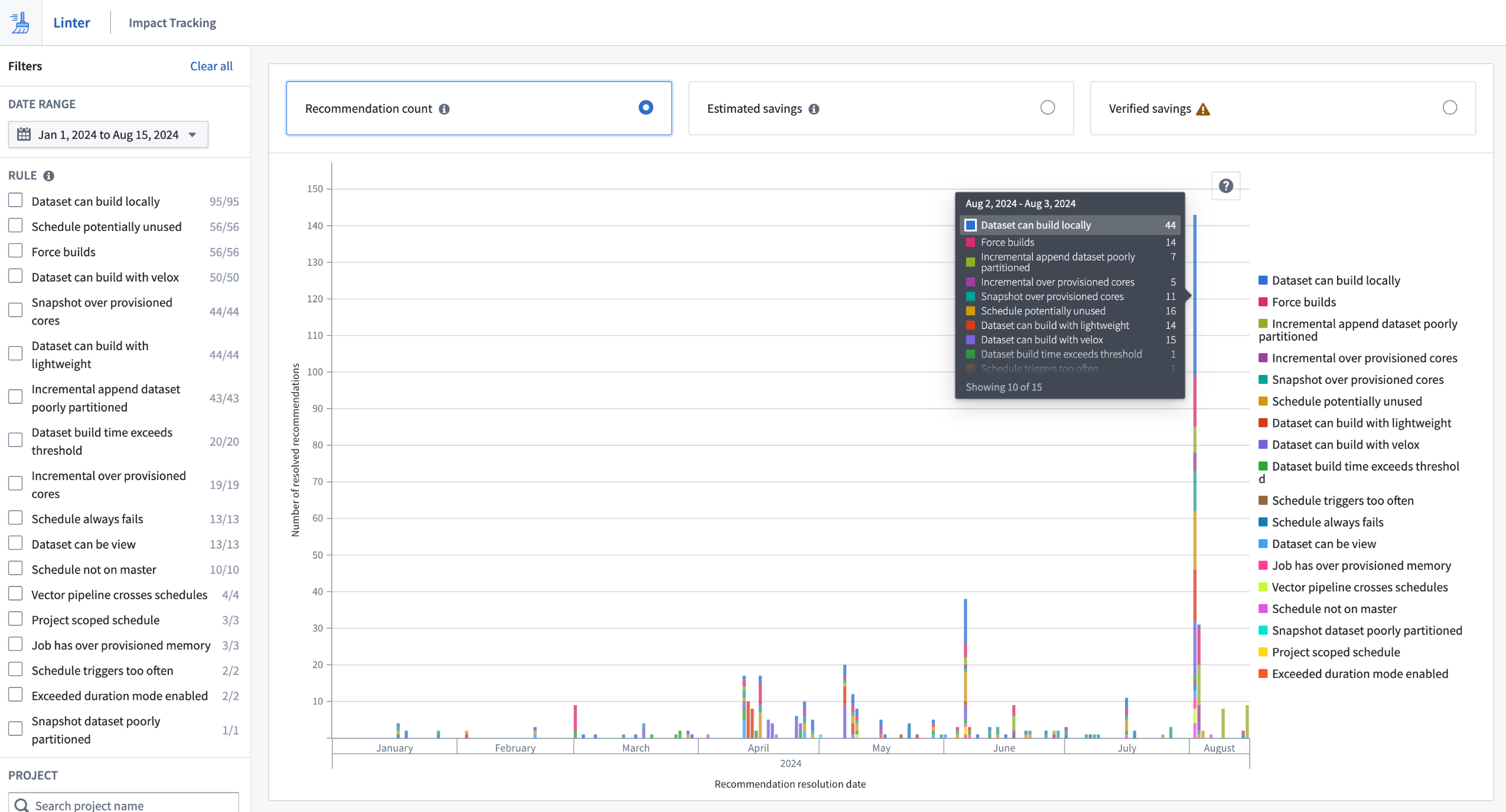
Linter's Impact Tracking UI displaying the number of actioned recommendations
Some customers organized sprints to investigate and act on Linter recommendations, while others spread their focus over longer periods by positioning Linter as a supportive tool for resource usage. Many customers now dedicate time to acting on Linter recommendations as a core part of their Palantir platform engagements.
Aside from cost reductions, Linter has also been used to recommend workflow updates to use newly available features in the Palantir platform. These include opportunities to use lightweight transforms and native Spark acceleration, neither of which existed at the beginning of this year.
Since Linter's beta release, the following features have been added, in addition to scalability improvements:
- Expansion of Linter rules, such as the addition of the dataset can build with lightweight rule.
- Introduction of the fix assistant to streamline fix generation and implementation of actions for recommendations.
- User Interfaces for impact tracking and editing sweep schedules.
Access tailored pathways for success with the Training application [GA]
Date published: 2024-09-19
We are pleased to announce that the in-platform Training application will become generally available in the coming weeks. The Training application offers customized training pathways for roles like data analysts and AI engineers, and provides a collection of courses, documentation, and resources on how to best use the Palantir platform.
Additionally, this application allows administrators to highlight organization-specific documentation or instructions that users should be aware of as they begin their training journey.
Learn how to use the Palantir platform with our Training application.
GPT-4o's vision capabilities are now available in Pipeline Builder
Date published: 2024-09-19
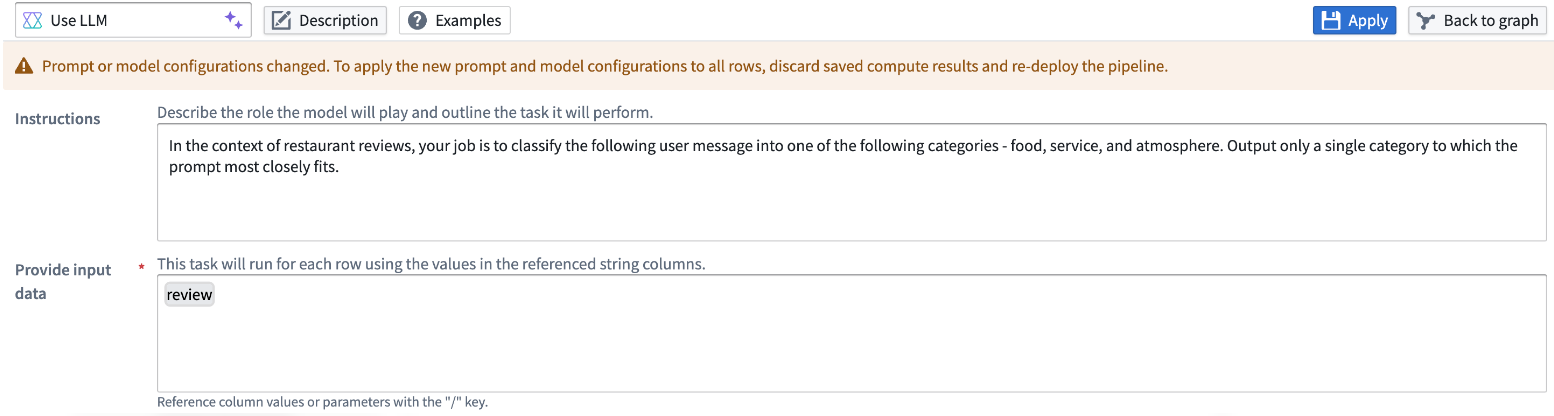
We are excited to announce that Pipeline Builder is now integrated with GPT-4o's vision capabilities, bringing you the power of vision prompts to your workflows. Now, you can transform your image-based workflows with the power of LLMs, allowing you to pass images through the model for analysis and receive answers to questions based on the visual input.
To use vision functionality with LLMs, first add the Use LLM node to a dataset node in your Pipeline Builder pipeline. Choose to add an Empty prompt to open the LLM configuration screen. From here, add the media reference column to the Provide input data section and select GPT-4o as the model.
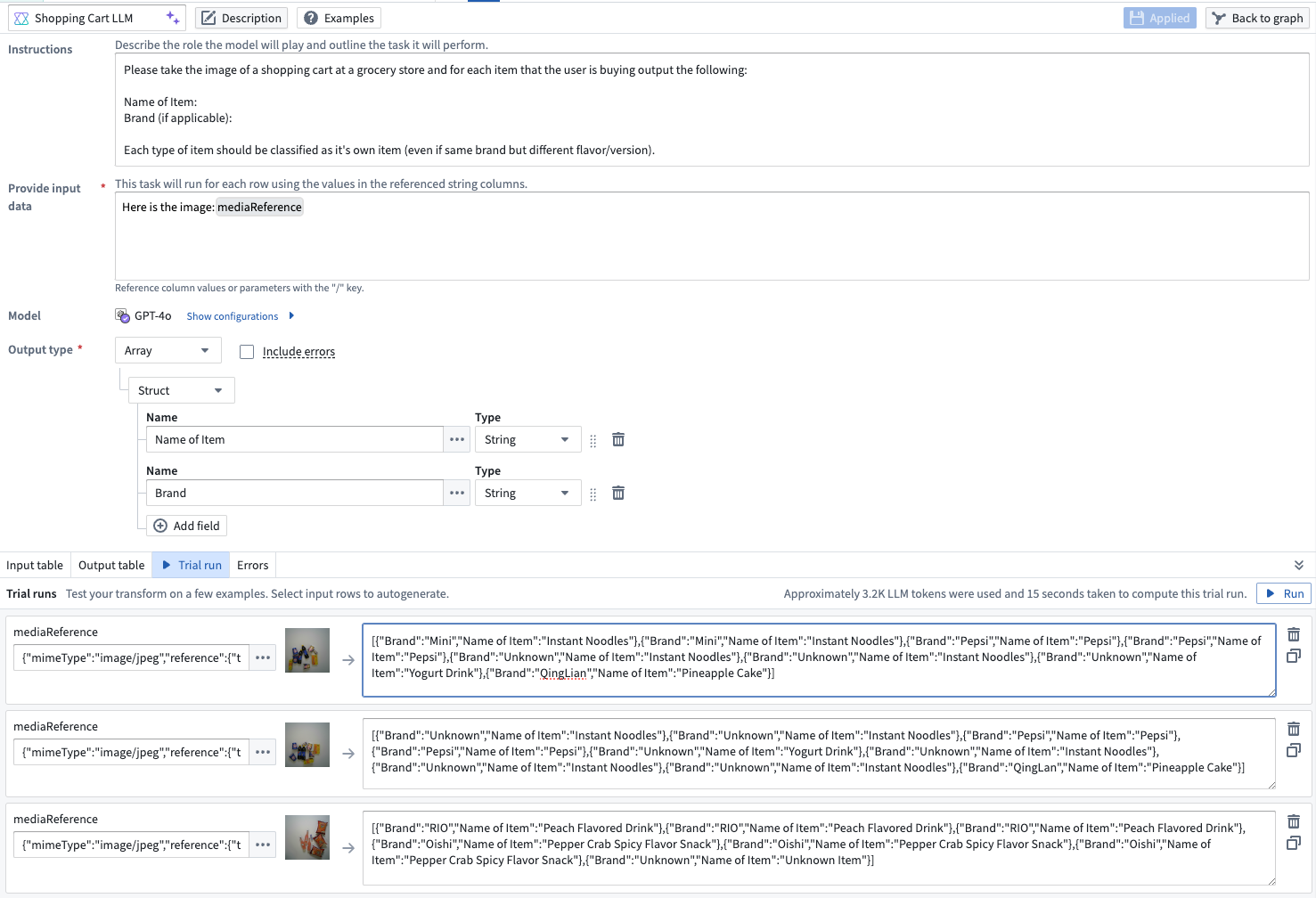
An LLM prompt configured to use GPT-4o to reference images and return names and brands of items in a grocery cart.
If you have an image-based media set you want to use with an LLM prompt, first use the Convert media set to table rows transform to output a table with a media reference column that you can then add to the LLM configuration.

The Convert media set to table rows transform board.
Learn more about vision capabilities in Pipeline Builder and other ways to use LLMs in your pipeline.
Localize your Workshop application with ease using the new Translations feature
Date published: 2024-09-17
Application builders can now provide translations for supported string types used within a Workshop application through the new Translations feature. With Translations, easily localize Workshop applications into various languages manually or with the help of AIP Assist for enabled enrollments.
Viewers will be presented with a translated view of the module in the language set for their account if the Workshop application has been translated to that language using this feature.
For details on what content is translatable using this feature and how to configure this feature as a builder, review the Translations feature documentation.
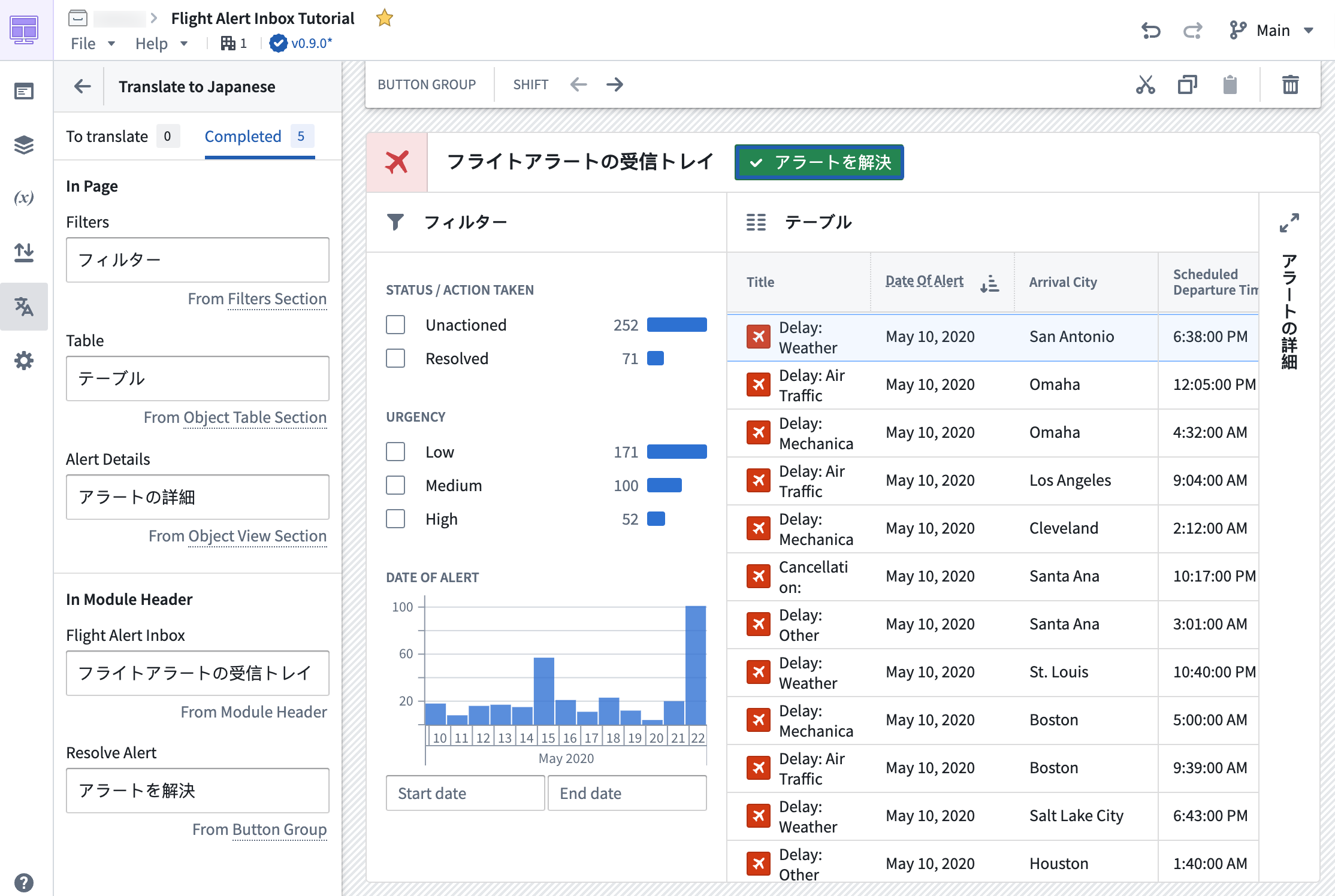
A Workshop application with the Translations panel open, with instant preview in the main section of the screen.
Support for Llama 3.1 70B Instruct and 8B Instruct LLMs now generally available
Date published: 2024-09-17
Llama 3.1 70B Instruct and 8B Instruct LLMs ↗ are now generally available and can be enabled for all enrollments. These new flagship models from Meta have performance comparable to other top models in the industry. If your enrollment's agreement with Palantir does not cover the usage of these models, enrollment admins must first accept an additional contract addendum through the AIP Settings Control Panel extension before these models can be enabled.
This model is usable in all Palantir AIP features such as Functions, Transforms, Logic, and Pipeline Builder.
Support for Claude 3.5 Sonnet and Claude 3 Haiku LLMs through AWS Bedrock now generally available
Date published: 2024-09-17
Claude 3.5 Sonnet and Claude 3 Haiku through AWS Bedrock are now generally available for all non-geographically-restricted enrollments. Additionally, for enrollments that are geographically-restricted, these models are also available in all US regions and some EU regions, with support for other regions under active development. For additional details, review the documentation on georestriction of model availability.
These new flagship models from Anthropic have performance comparable to other top models within the industry, and support multi-modal workflows, including vision. Details for each model follow below.
-
Claude 3.5 Sonnet ↗: Sonnet is Anthropic's most intelligent and advanced model yet, demonstrating exceptional capabilities across a diverse range of tasks and evaluations. Additionally, Sonnet has surpassed Claude 3 Opus on standard vision benchmarks. These step-change improvements are most noticeable for tasks that require visual reasoning, like interpreting charts and graphs. Claude 3.5 Sonnet can also accurately transcribe text from imperfect images—a core capability for retail, logistics, and financial services, where AI may glean more insights from an image, graphic or illustration than from text alone.
-
Claude 3 Haiku ↗: Haiku is Anthropic’s fastest, most compact, and affordable model for near-instant responsiveness. Haiku is the best choice for building seamless AI experiences that mimic human interactions. Enterprises can use Haiku to moderate content, optimize inventory management, produce quick and accurate translations, summarize unstructured data, and more.
If your enrollment agreement does not cover Claude 3.5 Sonnet or Claude 3 Haiku usage, enrollment admins must first accept an additional contract addendum through the AIP Settings Control Panel extension before the LLM can be enabled.
This model should be usable in all AIP features such as Functions, Transforms, Logic, and Pipeline Builder.
Introducing a simplified model deployment workflow with increased stability and speed
Date published: 2024-09-12
Previously, deploying a machine learning model for real-time inference required the effort and time of setting up a live deployment with Modeling Objectives, our tool for managing production-grade modeling workflows. From your model overview page, you can now deploy models with one click on either the Start deployment or Start & run option, without going through the Modeling Objectives application flow. Additionally, we are introducing multiple improvements to our infrastructure that enable faster startup times, cleaner functions Integration, autoscaling through Compute Modules, auto-upgrades, inference type safety, and more.
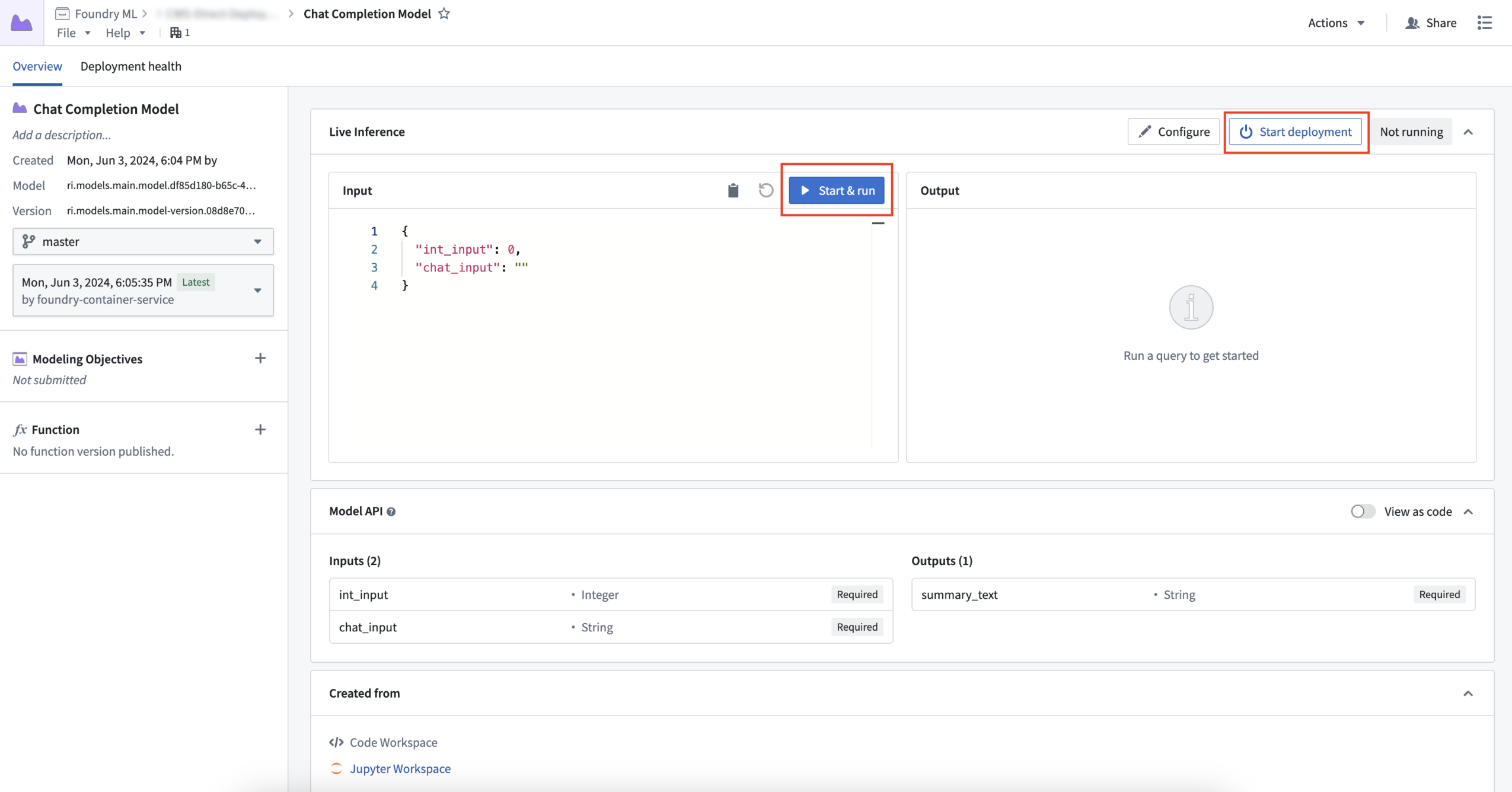
Users can now deploy a model directly from the model's Overview page.
Simplify auto-upgrades and autoscale down to zero for cost savings
Model deployment can now be fully managed from the model's overview page. You can start, stop, update model scaling configuration, and also test inference in the same interface. As deployments are now backed by Compute Modules, you can benefit from its autoscaling capacity which spins up or draws down replicas dynamically in relation to the model's inference traffic and usage.
For example, if your request load only comes at specific times, you can now set the range of replicas to be made available and scalable to actual request volumes. You can even scale replicas down to a minimum of zero to benefit from potential cost-savings if your model deployment is periodically not queried.
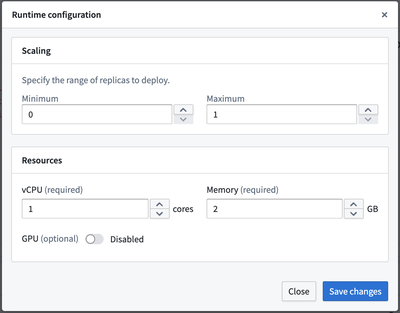
Configuring runtime scaling and resource availability based on model deployment needs.
Model deployments follow a user's branch of the model, making updates seamless. Simply publish a new model version from either Code Repositories or Code Workspaces, and the existing model deployment will be upgraded, ensuring all downstream workflows are always pointing to the latest model.
Functions integration without the need for a TypeScript repository
A model deployment can now easily be registered as a Function and used directly within Workshop, saving you the time and effort from building and using a TypeScript repository. Additionally, benefit from support for tabular inputs and outputs, with more types of models now supported as Functions in the Modeling Objectives application. Specifically, models with pandas APIs (tabular inputs/outputs) can now be directly integrated into Workshop applications, meaning you no longer need to have a translation layer from a pandas dataframe to parameters in TypeScript. Relatedly, models with parameter input and outputs continue to be supported.
For other API shapes, models can be published with an API name so they can still be used in TypeScript repositories where needed, such as when enabling the usage of a Function that cannot be consumed by Workshop directly.
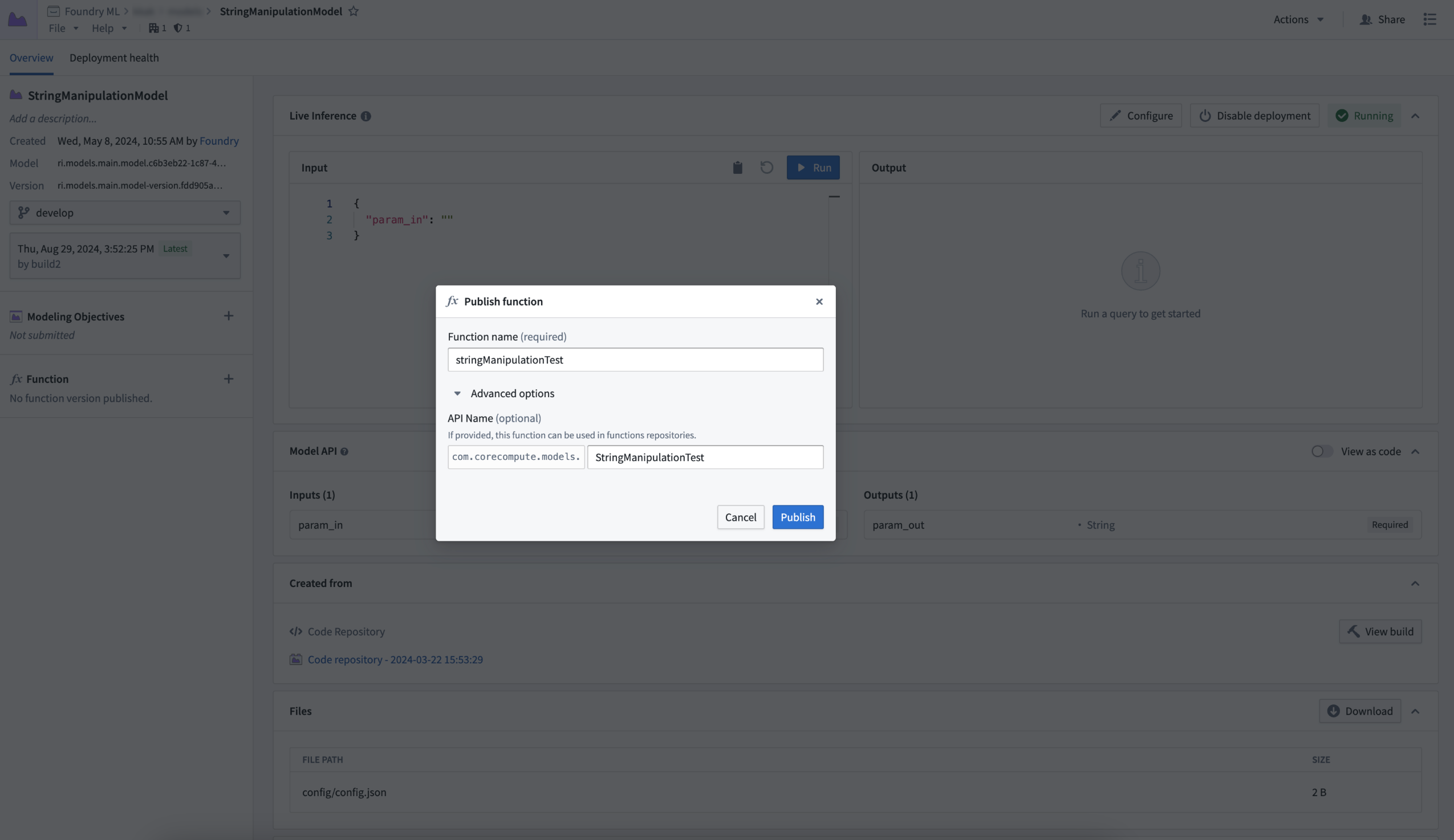
Publishing a function from a model deployment.
Notably improved stability and faster startup times
We have also incorporated the use of fully containerized models, a major change to the modeling infrastructure, meaning that models are now a Docker image with the full model environment, adapter instance, and model weights all patched together, ensuring faster startup times. Additionally, containerized images do not require any connection to the Palantir platform to launch. During internal testing, model deployments became fully ready in just one minute, whereas live deployments took three; compressed startup times become increasingly impactful within large, complex environments.
Guaranteed inference type safety
We are now able to guarantee inference type safety by using Apache Arrow to communicate with the model's container. This ensures that a user’s inference inputs are being passed to their model adapter logic in exactly the method specified within the model adapter’s API. For example, if the model’s API declares an integer parameter to be supplied, the input value will be either cast as an integer, or thrown if the value cannot be cast successfully. Additionally, date-time and timestamp values will now pass safely and accurately.
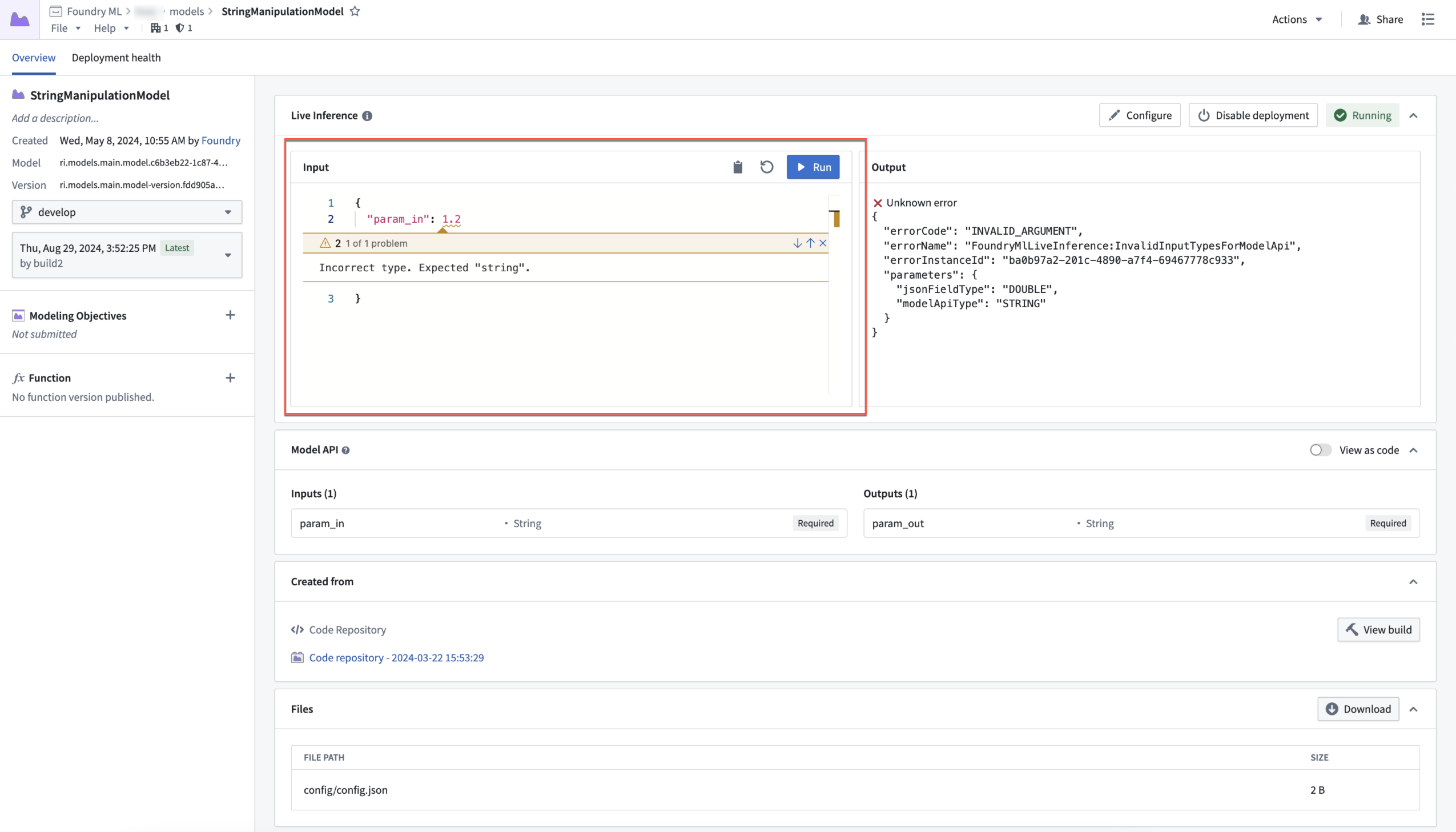
Open model with incorrect type error message.
Debug mode with practical flame graph visualization
Direct model deployments now boast a new debugging feature: the ability to create and view a full flame graph of a model’s inference. This feature empowers you to view how different parts of the model interact. By leveraging this new view, you can now gain insight into exactly what parts of code are slower than expected, allowing you to iteratively optimize model performance more easily than before.
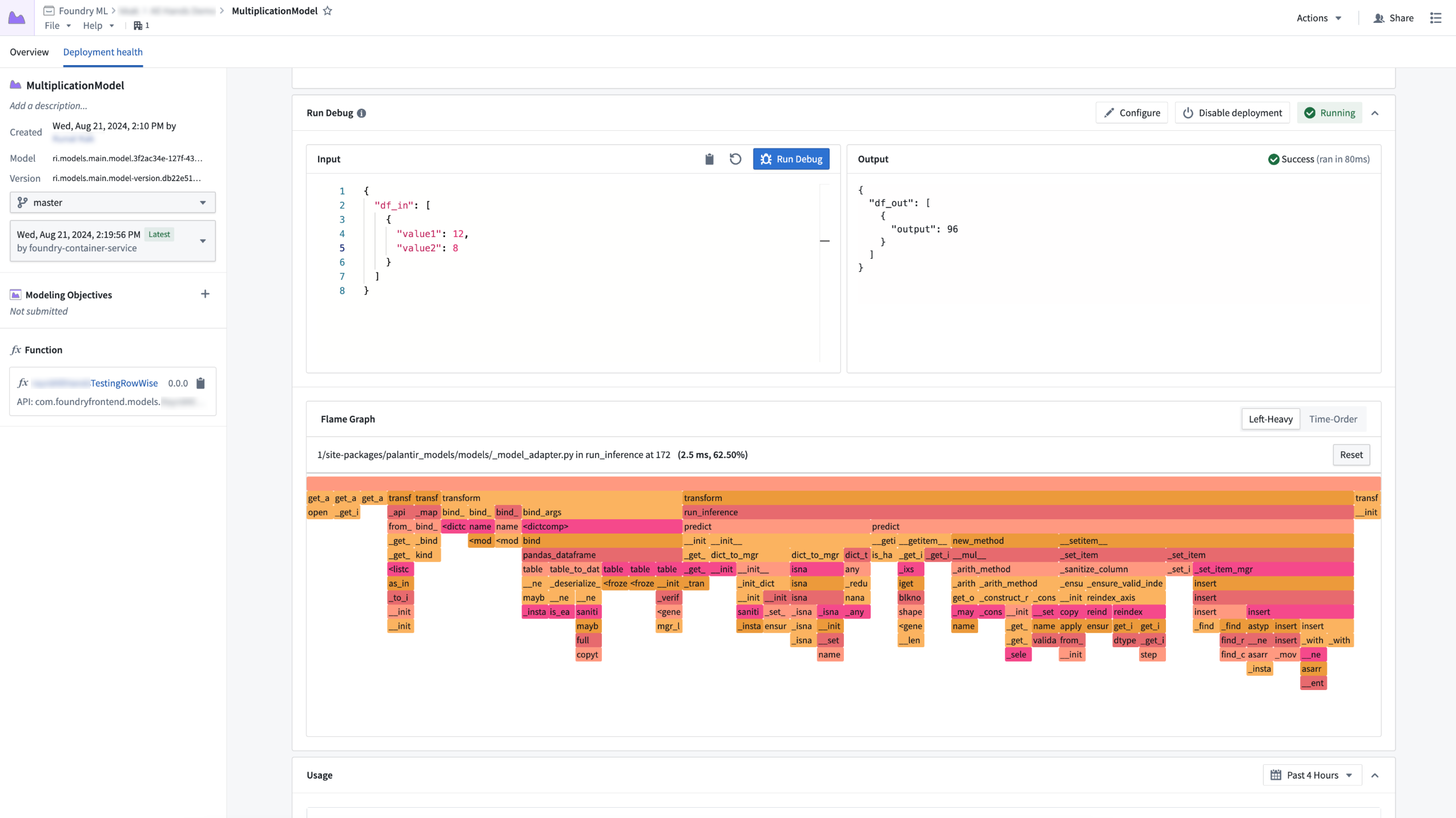
Flame graph view for a model deployment inference query.
Get started with model deployments
To benefit from these features above, make sure to publish a new model version for your model using the latest palantir_models library. Note that the feature set is not yet available for on-premise stacks, and that not all model types are supported by model deployments. External models and SparkML models are currently excluded.
To get started, review our model deployment guide.
Python version 3.8 will be deprecated January 31, 2025
Date published: 2024-09-12
Python 3.8 is being deprecated in the Palantir platform in line with open source Python's End-of-Life (EOL) timeline. As a result, automatic upgrades will be attempted in code repositories; manual action is needed on code workbooks and with older foundry_ml models. Starting from Python 3.9, we will be following Python's EOL deprecation timelines closely. Review the Python versions section in the documentation to see supported versions and respective deprecation timelines. We recommend that resources always be kept on the latest supported Python version.
Why is Python 3.8 being deprecated?
Open-source Python marks old Python versions as End-of-Life (EOL) every year ↗ and drops official support. Python 3.8 is approaching its EOL and continued use of EOL Python versions exposes security risks. Additionally, open-source libraries continue to create new releases which are no longer compatible with these deprecated Python releases, potentially causing failing checks and jobs for unmigrated workflows.
What does deprecation mean for me as a user?
If you own resources using a deprecated Python version, note the following important dates:
- January 31, 2025: Workflows depending on deprecated Python versions will no longer be supported, and you will receive no support in case of failures. A limited set of resources can be allowlisted for extended support if agreed with Palantir in advance.
- April 30, 2025: All workflows relying on Python 3.8 or older will no longer be supported and might experience failures.
Foundry resource migration to supported Python versions
Foundry resource migration will follow the patterns below:
- Code repositories: An automatic upgrade will be attempted in the form of an automatic patch pull request. This will be attempted for all resources on Python 3.8, regardless of priority.
- Other resources: Informational banners containing migration instructions from the deprecated Python versions will be displayed. Review the troubleshooting guide for more information.
Currently, the latest version of Python supported in platform is Python 3.11.
Future Python version deprecation
Starting from Python 3.9, the Palantir platform will closely follow the upstream end-of-life timelines and will deprecate Python versions in-platform as soon as they reach upstream end-of-life. For more information, see Python versions in the documentation.
Optimize Pipeline Builder LLM builds by skipping processed rows
Date published: 2024-09-10
We are pleased to announce that Pipeline Builder can now skip previously processed rows for Use LLM nodes and Text to Embeddings transforms to save costs and improve performance. Previously, each row was re-processed during pipeline builds. Now, however, row results can be cached, meaning that they are stored and reused in subsequent builds. You can save both time and costs by skipping already processed rows; tested use cases have shown build times decreasing from 3 hours to just 20 minutes.
To get started, enable Skip recomputing rows when configuring Use LLM or Text to Embeddings. When this is enabled, rows will be compared with previously processed rows based on the columns and parameters passed into the input prompt. Matching rows with the same column and parameter values will get the cached output value without reprocessing in future deployments.
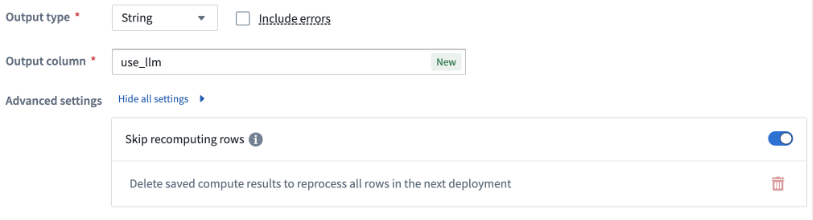
The Skip recomputing rows option.
Users can manually clear the cache if changes to the prompt require all rows to be recomputed. In this case, a warning banner will appear over the LLM view, and users can decide to keep all previously cached values as long as the output type remains the same.
The LLM view with a warning banner informing users that the prompt or model configuration has changed.
Improve workflow efficiency and reduce computational costs by enabling this feature on Use LLM nodes and Text to Embeddings transforms in your pipelines.
Learn more about skipping processed rows.
Introducing the Scheduling Calendar widget
Date published: 2024-09-10
We are excited to introduce the Scheduling Calendar widget in Workshop, a new way to visualize and interact with time-bound objects. The Scheduling Calendar provides a clean and flexible way to display events or tasks.
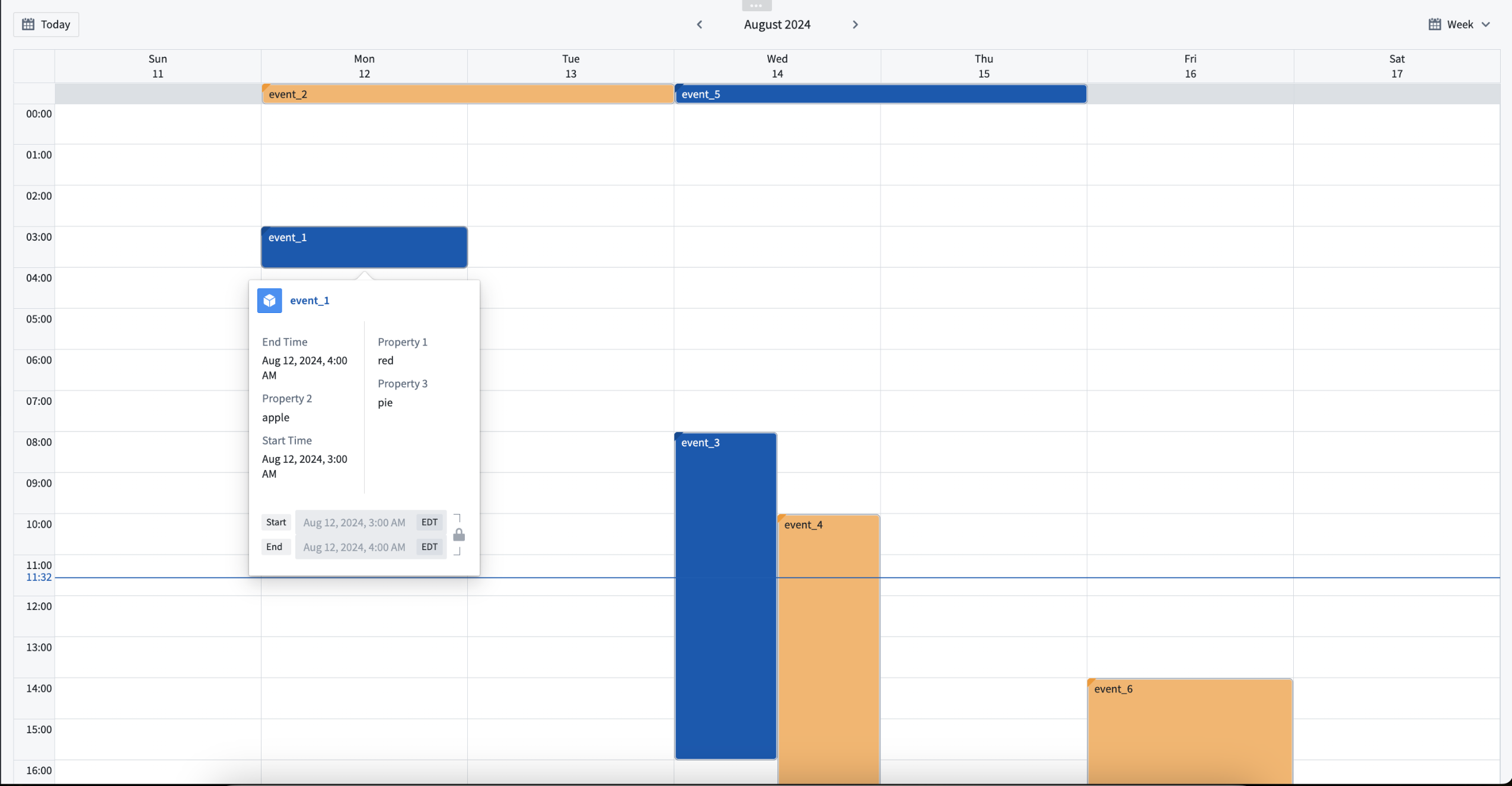 Example of events in the Scheduling Calendar widget.
Example of events in the Scheduling Calendar widget.
Example use cases for the Scheduling Calendar widget:
- Appointment or meeting scheduling
- Tracking task and milestone deadlines
- Viewing employee shift assignments
Key features of the Scheduling Calendar widget:
- Intuitive drag-and-drop functionality, allowing you to easily reschedule events.
- Customizable display options like coloring and object details that provide context to scheduling decisions.
- Native day, week, and month views.
What’s next on the development roadmap?
Our team is actively working on the following features for a future update:
- Trigger Actions and Workshop events directly in the Scheduling Calendar widget.
- Simulate scheduling changes through integration with Scenarios.
For more information, review the Scheduling Calendar widget documentation.
Introducing live logs [GA]
Date published: 2024-09-03
We are excited to announce the live logs feature, now available as part of the Builds application in your Palantir enrollment. Live logs grant users real-time visibility into actively-running jobs, providing powerful and insightful monitoring on how these jobs are progressing across your data resources and the ability to inspect long-running tasks such as streams or compute modules.
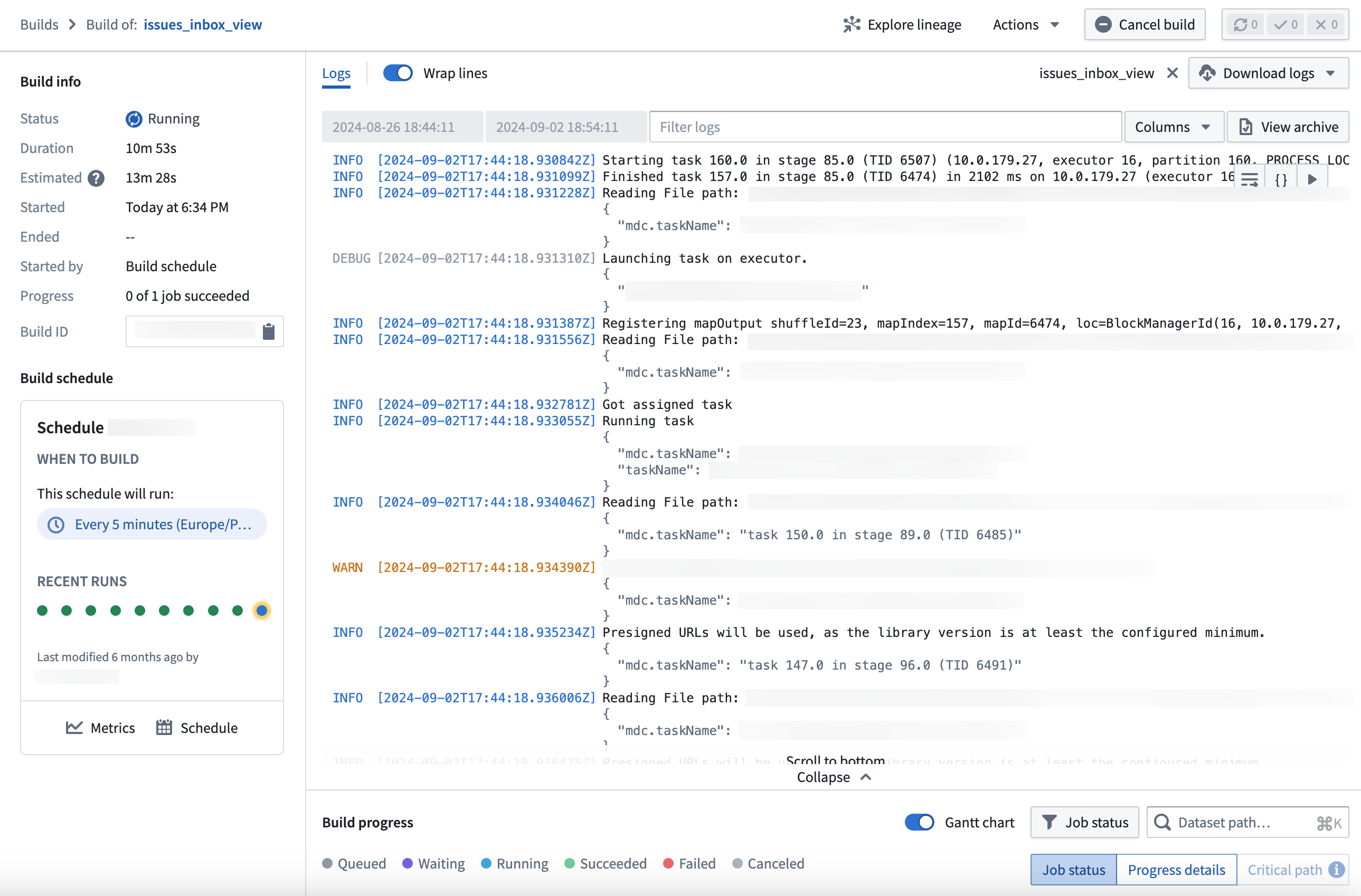
The live logs feature in the Builds application, returning task reports in real-time.
Rooted in user control
Live logs are designed with user control in mind; you can stop the logs at any time using the Pause option in the top right corner of the log view and easily start again from the same location. Additionally, parameters and safe parameters are visible as a structured and readable JSON block for easier consumption and understanding.
The Pause and Format as JSON options from the live log view.
Colorful visibility
A key benefit of using live logs to monitor your jobs is the color-coded identification of issues with the build. Use these colors to quickly identify warnings and errors in your live log feed and prioritize the necessary fixes to complete a successful build.

An example of color coded debugging and warning alerts in a live log feed.
Get started with live logs
To access live logs, navigate to the Builds application and choose to view an active job. Then, select View live from the top right corner of the log viewer.
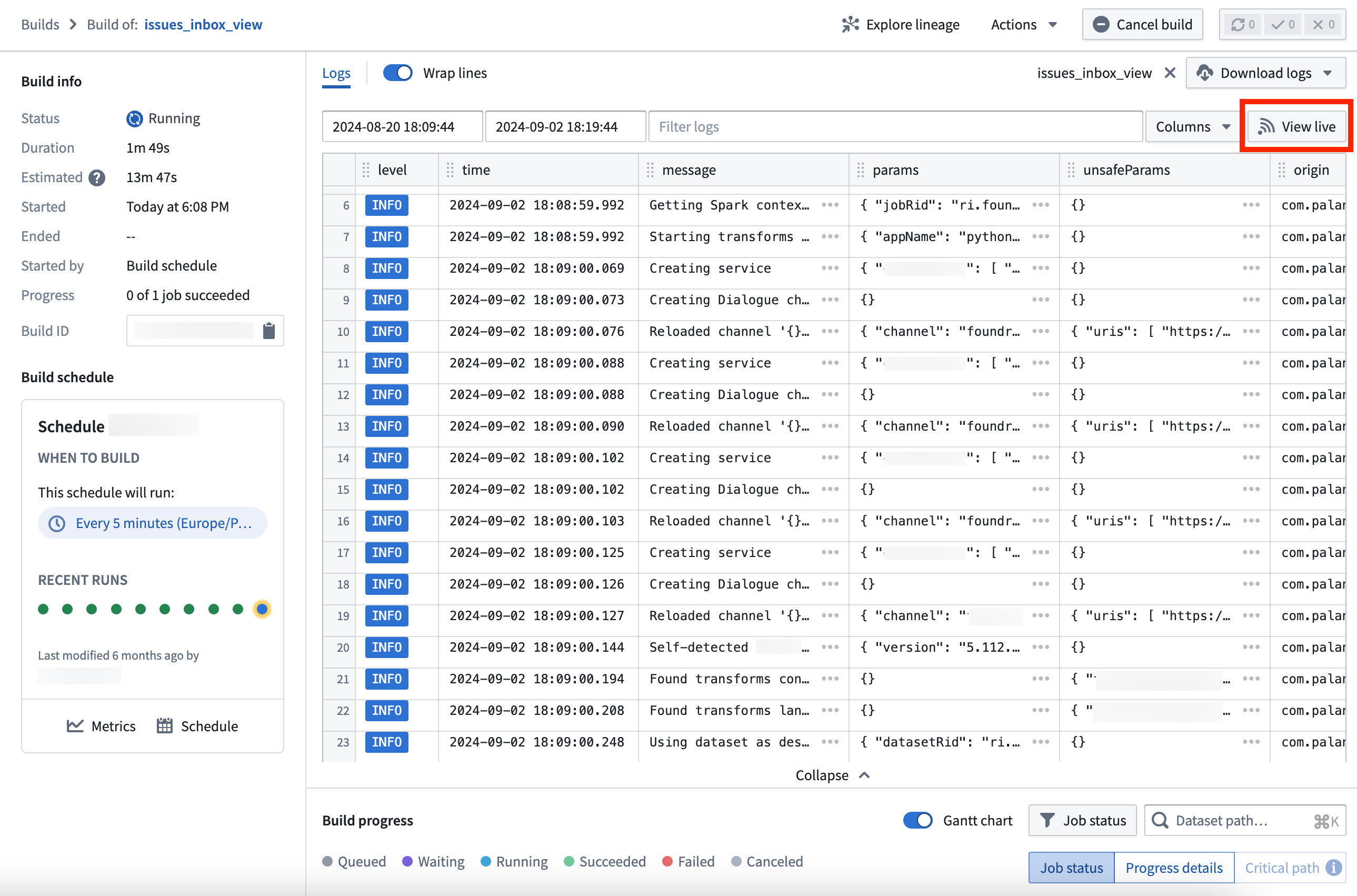
The log view of an active build, with the option to View live in the top right corner.
Learn more about live logs and Builds application in our documentation.
Earn your Foundry and AIP builder foundations badge
Date published: 2024-09-03
We are proud to launch the new Foundry and AIP builder foundations quiz and badge ↗ on the official Palantir training site ↗. Take the ten question quiz and earn a badge that can be shared on LinkedIn as an official LinkedIn credential.

A badge that can be displayed as a credential on your LinkedIn profile.
This quiz complements the Speedrun: Your First End-to-End Workflow ↗ course, which provides an intro to Pipeline Builder, the Ontology, Workshop, and Actions in under 60 minutes. Users who are familiar with Foundry should be able to pass the quiz and earn the badge without completing the Speedrun course. You will also be awarded an official certificate acknowledging completion of the curriculum.

An example of the official certificate you can earn with this quiz.
If you do not have a Palantir Learn account, you can sign up ↗ for free to get started with learning paths and certifications across a range of topics including data engineering, end-to-end workflow building, solution design, and platform administration.
Use multiple protected branches in Pipeline Builder
Date published: 2024-09-03
You can now protect multiple branches in Pipeline Builder to achieve a greater level of governance and defense against unintended changes. A protected branch can only be modified with a pull request and must go through the specified approval process for changes to be merged. By implementing protected branches, you ensure that only authorized modifications are made and increase the security and integrity of your data workflows.
To get started, configure protected branches under Settings > Manage branches in Pipeline Builder:
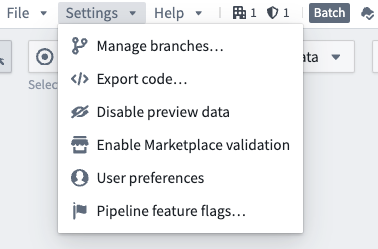
The Manage branches option in the settings dropdown.
Select the Branch protection tab and choose the branches to be protected, along with the desired approval policies. All protected branches will follow the same approval policies.
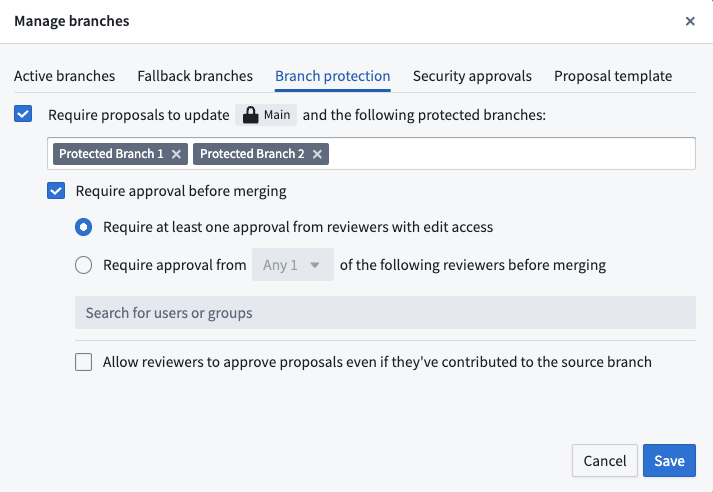
The Branch protection tab with two additional protected branches and approval policy options.
Use multiple protected branches to minimize the risk of unintended changes and create a more controlled development environment for greater peace of mind.
Learn more about protected branches.
Additional highlights
Analytics | Notepad
Template Anchor Link Improvements in Notepad | Previously, generating a new document from a template caused anchor links to point back to the template. With this latest improvement, anchor links in newly generated documents now correctly reference points within the same document, ensuring seamless user navigation.
Notepad Object Media Preview Widget in Marketplace | Object media previews are now supported in templates for Marketplace in Notepad versions. Before this enhancement, users had to create a new notepad document for every template change. This improvement streamlines the workflow significantly because you can now use Notepad object media previews in Marketplace.
App Building | Ontology SDK
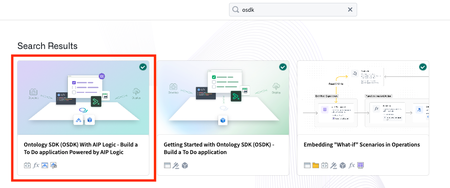
Announcing a new Build with AIP package for Ontology SDK, powered by AIP Logic | We are excited to announce that a new Build with AIP package is now available for Ontology Software Development Kit (OSDK), featuring the power of AIP Logic. This new package expands upon the previously released Getting Started with Ontology SDK Build with AIP package, demonstrating how to use Palantir AIP capabilities from any external application, such as running an AIP Logic function, calling a query that uses LLMs to enrich your data, and building a "To-Do" application with AIP Logic automation. To get started with the new Build with AIP package, first search for the Build with AIP portal in your platform applications. Then, search for "OSDK" to find the Ontology SDK (OSDK) with AIP Logic package. Choose to install it, then designate a location in which to save it. Once installation is complete, select Open Example to follow the guide and start building.
App Building | Workshop
Workshop Resizable Sections | Workshop now supports configuring absolute sized sections to be resizable by users in View mode. Resizable sections feature a minimum and maximum size config, an accessible resize handle, and auto-collapse functionality for collapsible sections with headers.
Horizontal filter list | The Filter List layout now supports a horizontal setup. In this layout, each filter will be displayed within an interactive tag, enabling access to the corresponding filter.
Data Integration | Pipeline Builder
Implement interfaces in Pipeline Builder (Beta) | You can now implement interfaces on objects created in Pipeline Builder. Interfaces offer object type polymorphism, enabling consistent modeling and interaction with object types that share a common structure. They facilitate composability by allowing multiple object types to implement and extend shared properties, link types, and metadata.
Learn more on how to implement an interface on objects created in Pipeline Builder.
DevOps | Marketplace
Improved Marketplace store and product navigation | We are thrilled to introduce a revamped navigation experience in Marketplace. With enhanced store overview, you can now begin your Marketplace journey by viewing all available stores, making it easier to dive into a specific store to explore and search for products. Breadcrumb navigation has been added to help direct you through the store, product, and installation or draft stages. Use improved global search to find products intuitively, right from the search bar accessible from anywhere within the application.
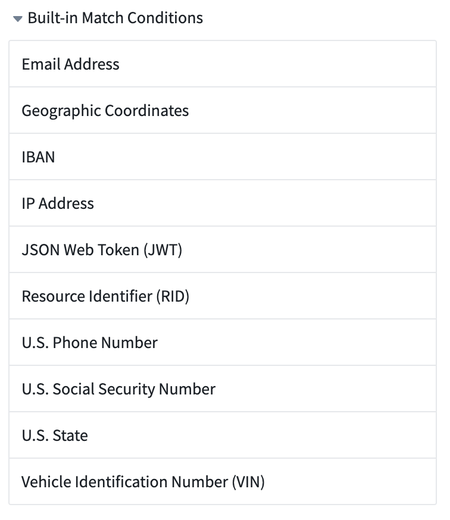
Security | Sensitive Data Scanner
Built-in match conditions now available in Sensitive Data Scanner | Sensitive Data Scanner now includes a variety of built-in match conditions to detect common types of Personally Identifiable Information (PII), such as Social Security numbers, email addresses, and phone numbers. You can access these conditions by expanding the Built-in Match Conditions section in the right sidebar.
You may still create your own custom match conditions for your unique requirements. For more information on how to navigate match conditions, refer to our documentation.