- Capabilities
- Getting started
- Architecture center
- Platform updates
Announcements
REMINDER: Sign up for the Foundry Newsletter to receive a summary of new products, features, and improvements across the platform directly to your inbox. For more information on how to subscribe, see the Foundry Newsletter and Product Feedback channels announcement.
Share your thoughts about these announcements in our Developer Community Forum ↗.
Introducing community.palantir.com, our official Palantir Developer Community
Date published: 2024-06-25
We are proud to introduce the Palantir Developer Community, a collaborative space dedicated to the exchange of ideas and expertise among Foundry and AIP users and partners. Through this community, Palantir developers, application builders, and power users can connect with one another to ask and answer questions, provide product feedback and stay up-to-date with the latest product initiatives and developer events.
Palantir Developer Community, a home for developers and power users of the Palantir platforms.
To get started, navigate to community.palantir.com to create a free account and join the conversation.
Note: The Palantir Developer Community is public. Please refrain from posting confidential or sensitive data, and adhere to the relevant policies of your organization when posting in the Palantir Developer Community. Participation is voluntary, and responses are not guaranteed. Palantir customers with support contracts should submit requests that require a response, non-public inquiries, bug reports, or feature requests through standard support channels.
Table exports for JDBC systems are now available
Date published: 2024-06-25
Datasets can now be exported to external JDBC systems using table exports in Data Connection. Table exports introduce a new user experience for configuring exports of tabular data through an intuitive interface, a rich export mode selection, and the ability to explore the target system to configure the export. Table exports will work with custom JDBC systems configured with both direct connection and agent runtimes.
Export modes
Table exports support six distinct export modes to accommodate your unique requirements:
- Efficiently mirror dataset to external table (recommended): The external table will always match what you see in the Foundry dataset.
- Full dataset without truncation: Always export a snapshot of the entire view of the Foundry dataset, without truncating the external table first.
- Full dataset with truncation: Truncate (drop) the target table, then export a snapshot of the full current dataset view.
- Export incrementally: Exports only unexported transactions from the current view without truncating the target table.
- Export incrementally with truncation: Truncate (drop) the target table, then export only transactions from the current view that have not previously been exported.
- Export incrementally and fail if not
APPEND: Exports only unexported transactions from the current view, failing if there is aSNAPSHOT,UPDATE, orDELETEtransaction (after the first run).
Learn more about the details of each export mode in our documentation.
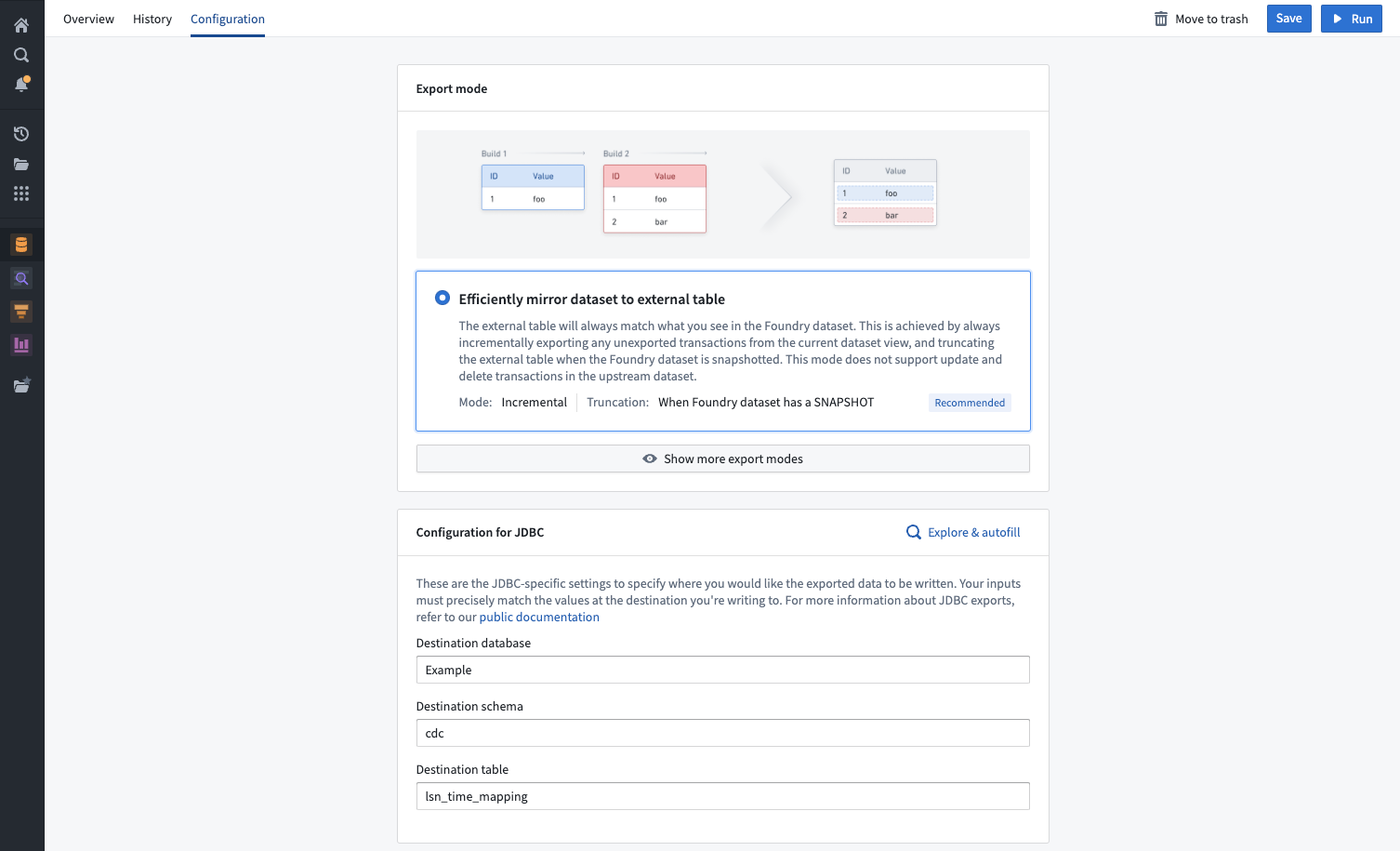
Example of an export mode selection in Data Connection.
Explore target systems
For a dataset to be exported, its schema must match the schema of a table on the target system. To help you configure the correct table, a source explorer is available to navigate all schemas and tables available on the target source.
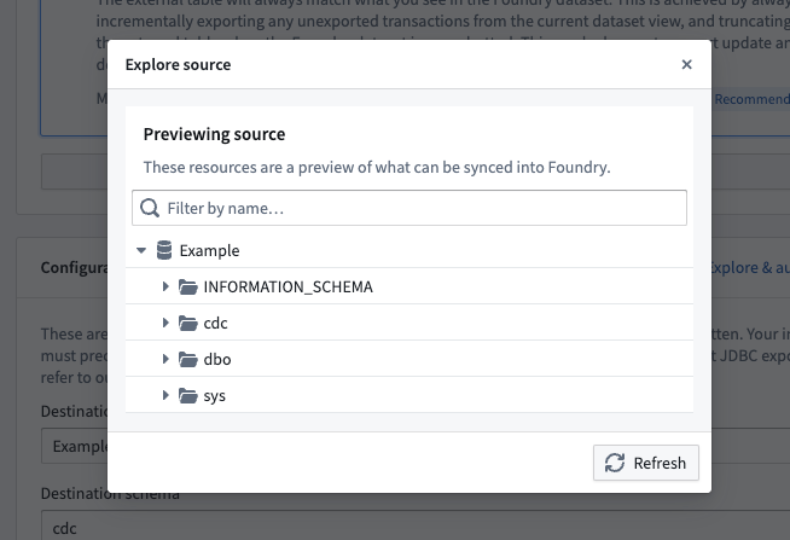
Example of a source exploration dialog.
Migrate from export tasks
The addition of table exports is intended to replace the usage of the now sunsetted export tasks to export tabular data, and every user of export tasks is encouraged to migrate to table exports. Learn more about the differences between Data Connection exports and export tasks, and learn how to migrate your workflows.
What's next on the development roadmap?
Currently, table exports are only available for custom JDBC sources. We plan to expand support for more connector types in the near future.
Estimate compute usage with token counts in Pipeline Builder
Date published: 2024-06-25
Token count metrics are now available for Pipeline Builder previews and trial runs that use OpenAI models. This feature provides more visibility into compute usage before deploying pipelines, giving users more control over compute usage and costs.
Use LLM node previews and downstream transforms now feature a total estimated token count when using OpenAI models. Trial runs also display the total estimated token count for the number of rows run.
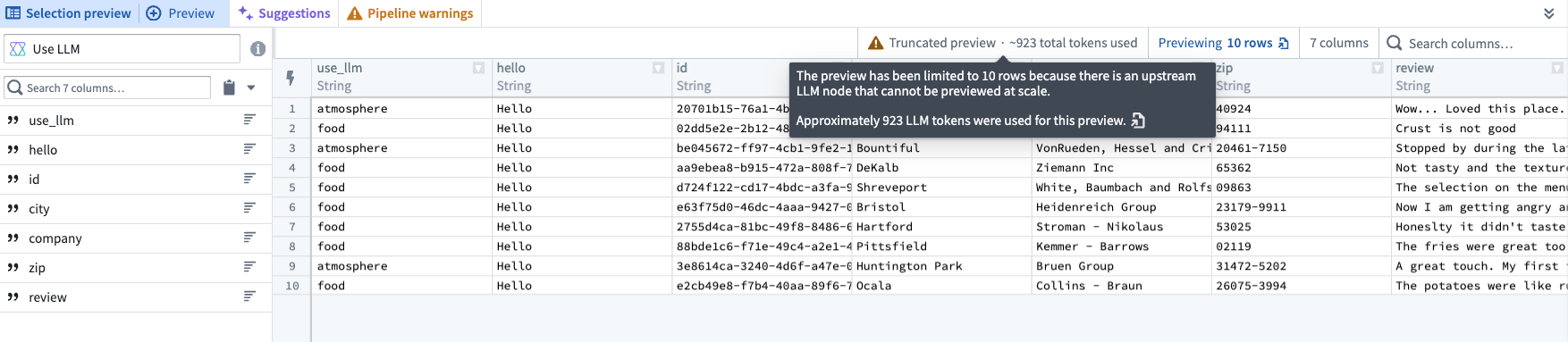
The approximate token count for rows in a Use LLM node preview.

The approximate token count displayed in a trial run.
Note that token counts are not provided for cached results, since no additional tokens are used.
Learn more about Pipeline Builder previews and trial runs.
Introducing a customizable landing page in Ontology Manager
Date published: 2024-06-25
Ontology Manager now makes it easier for you to resume your work, or navigate to the object types that are most important to you upon launch.
Tailor your landing page experience
The new Discover page can be customized to display object types in groups of key interest, giving you quick access to your favorites and recently viewed object types.
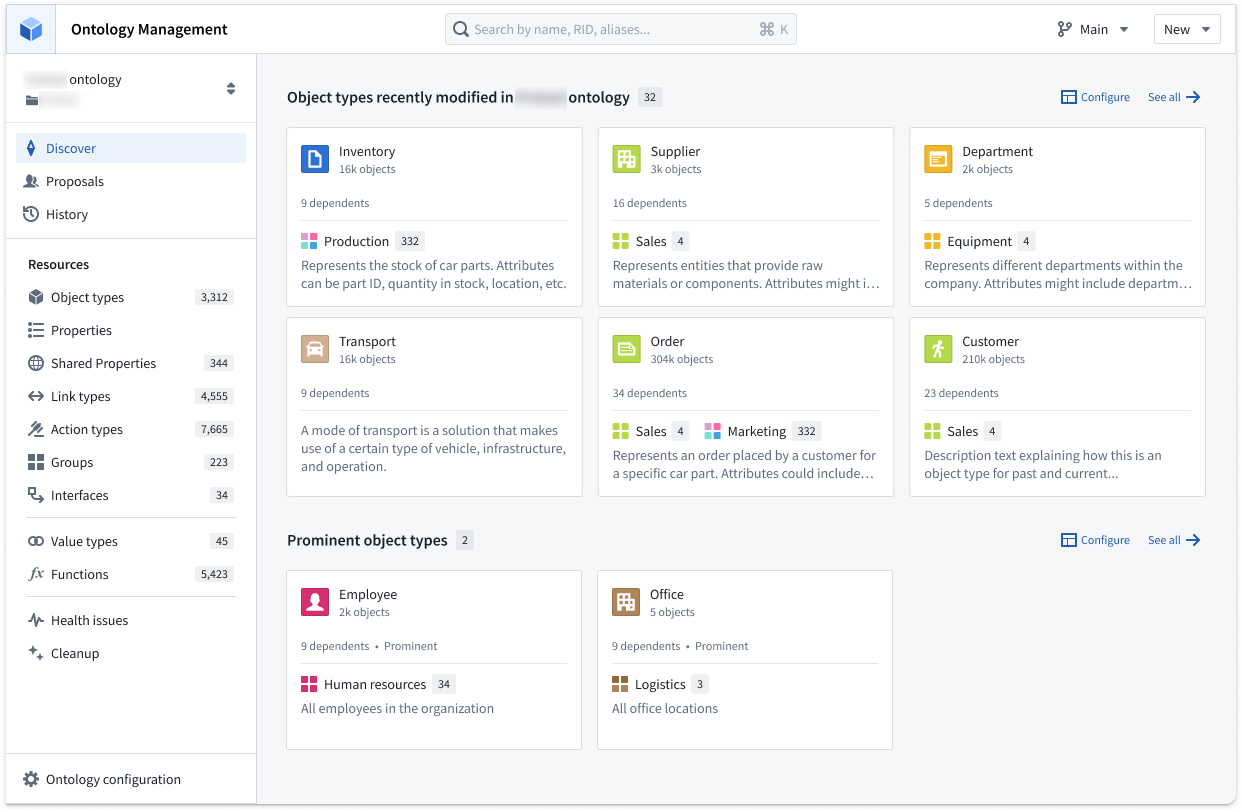
Review your recently-viewed object types, favorite object types, or favorite groups from Discover.
Customize sections to your preference
Choose what sections are available, and order them on your customizable homepage through the Configure option. Use the Add section option to choose from favorite groups, object types, or recently viewed, or choose a specific type group.
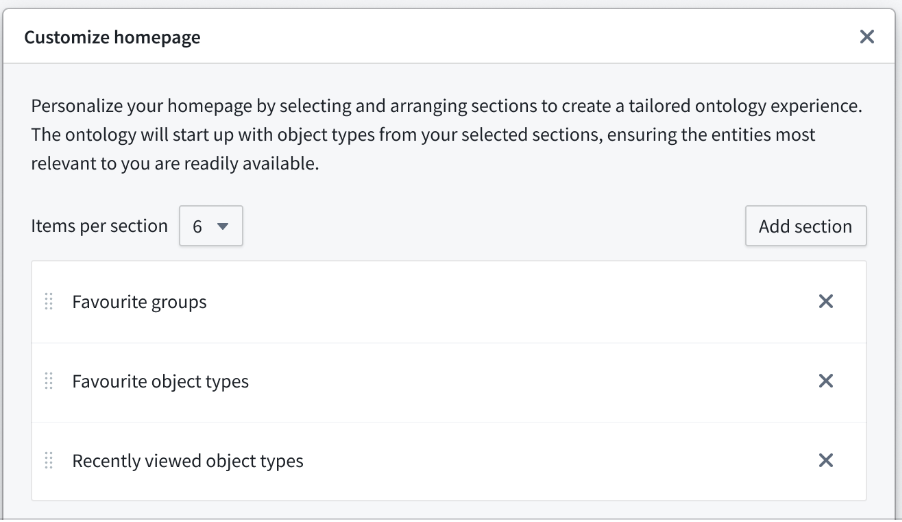
Add sections and rank them using the Customize homepage window.
To help reduce Ontology load times and allow you to resume your workflows swiftly, object types in the sections you choose are loaded first.
Object types at a glance
The Discover page includes a new compact preview of object types to help you better understand how resources can be used. This view is optimized for legibility at a glance by surfacing object count, number of dependents, visibility, and group memberships.
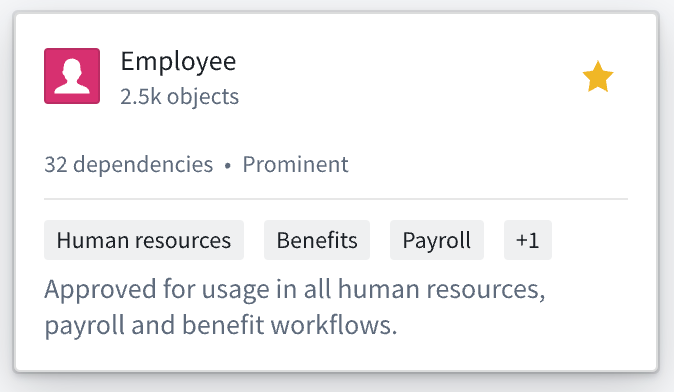
Compact preview of Employee object type.
Learn more about Ontology Manager.
Foundry Connector 2.0 for SAP Applications v2.31.0 (SP31) is now available
Date published: 2024-06-20
Version 2.31.0 (SP31) of the Foundry Connector 2.0 for SAP Applications add-on, used to connect Foundry to SAP systems, is now available for download from within the Palantir platform.
This latest release features bug fixes and minor enhancements, including:
- Performance improvements of metadata retrieval for SAP Landscape Transformation Replication Server (SLT).
- An extended functionality to split
STXLline format on a character. - An enhanced incremental resolution method for incremental syncs leveraging CDPOS.
We recommend sharing this notice with your organization's SAP Basis team.
For more on downloading the latest add-on version, consult Download the Palantir Foundry Connector 2.0 for SAP Applications add-on in documentation.
Introducing Build with AIP for Ontology SDK
Date published: 2024-06-20
A new Build with AIP package is now available for the Ontology Software Development Kit (OSDK). The Ontology SDK allows you to access the full power of the Ontology directly from your development environment and treat Palantir as the backend to develop custom applications. With the Build with AIP package, you can follow an in-platform tutorial to create your own "To Do" application in the Developer Console that is customized to your organization's Ontology resources, allowing you to connect object types, action types, links, and more that are specific to the use cases you care about. Using the Build with AIP package offers builders the ability to seamlessly read from and write to the Ontology, limiting the need to navigate across other Foundry applications to update or load data.
This comprehensive in-platform guide will teach you everything from setting up your development environment in React or Jupyter®, to deploying your final product. For example, you could build a React application backed by data and Ontology action types, or use Jupyter® to perform analysis on your unique Ontology data.
To get started with the Build with AIP package in Ontology SDK, first search for the Build with AIP portal in your platform applications. Then, search for "OSDK" to find the Getting Started with Ontology SDK (OSDK) package. Choose to install it, then designate a location in which to save it.
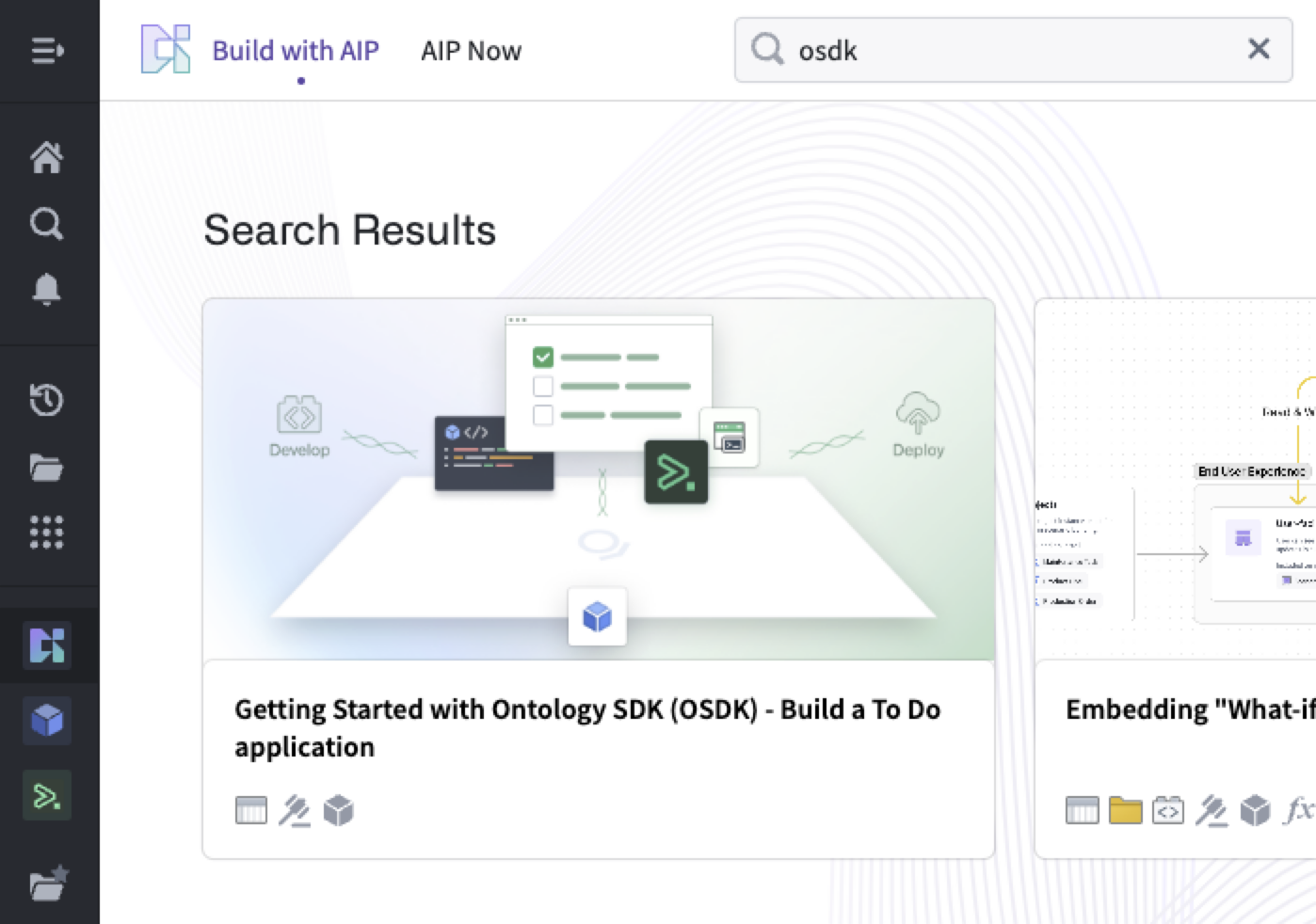
Search for "OSDK" in Build with AIP.
Once installation is complete, select Open Example to follow the guide.
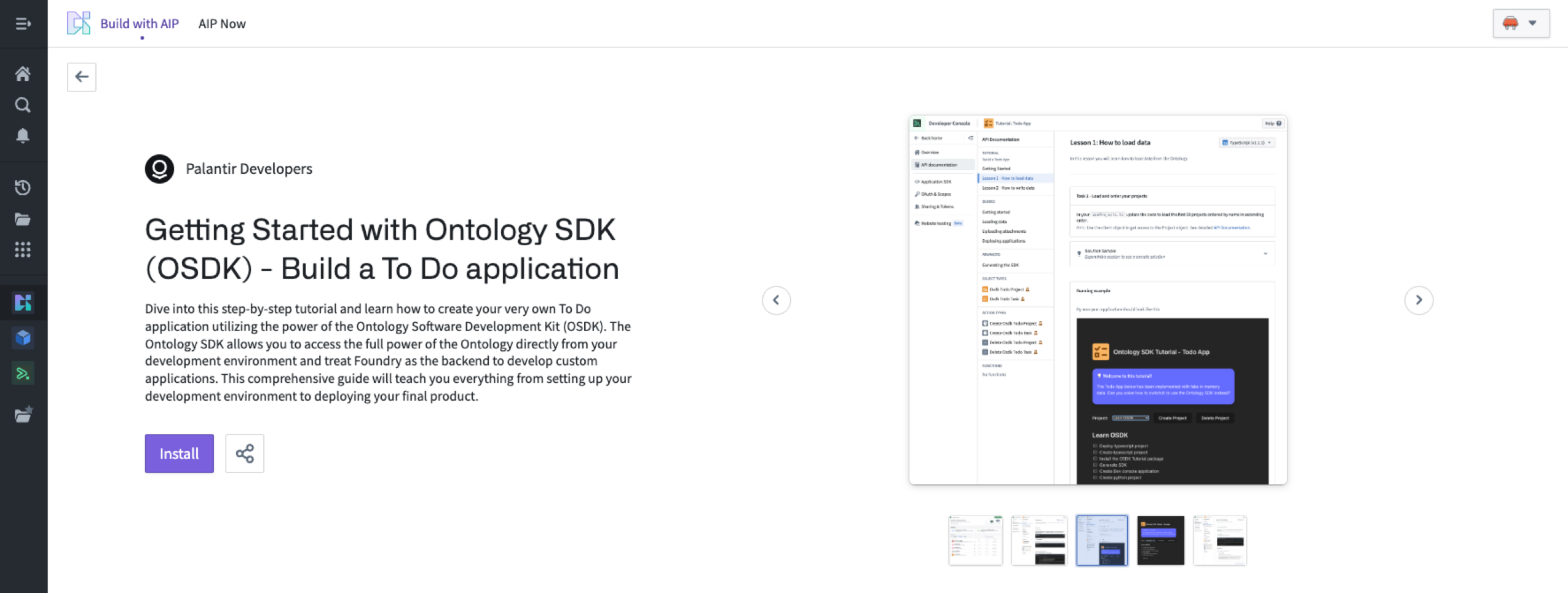
Install the sample To-Do application.
Have you tried this feature?
Share your thoughts in our Developer Community.
What's next on the development roadmap?
We are working to publish more Build with AIP packages, including ones that demonstrate how to use LLMs and leverage AIP Logic from your Ontology SDK application.
Jupyter®, JupyterLab®, and the Jupyter® logos are trademarks or registered trademarks of NumFOCUS.
All third-party trademarks (including logos and icons) referenced remain the property of their respective owners. No affiliation or endorsement is implied.
AIP Assist can now direct users to the Palantir Developer Community forum
Date published: 2024-06-20
As of the week of July 7, AIP Assist will start to redirect user inquiries to Community.palantir.com, our Palantir Developer Community, when unable to provide suitable answers.
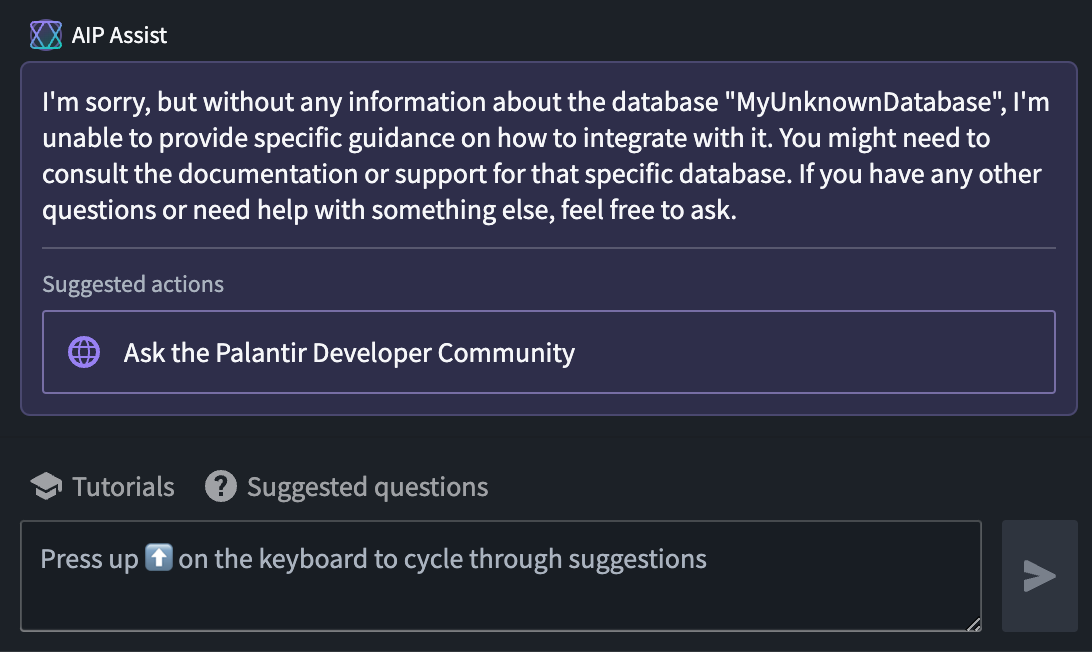
Sample user interaction leading to a suggestion of asking the Palantir Developer Community.
To provide more control over the user experience, enrollment administrators may disable this feature by navigating to Control Panel > AIP Assist > Suggested actions as of today.
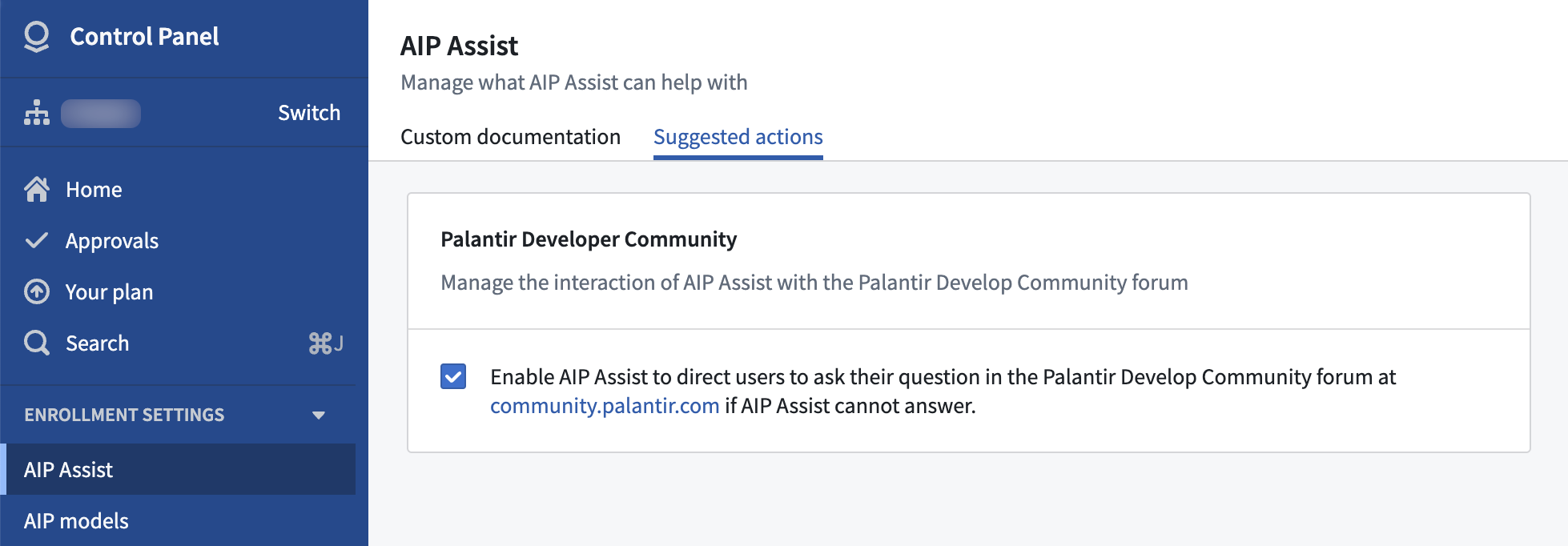
Enable or disable redirection to community.palantir.com in AIP Assist.
Learn about enabling and disabling the feature in AIP Assist documentation.
Over 150 new sources are now available in Data Connection
Date published: 2024-06-20
Our available source connections in the Data Connection application now include over 150 new supported source types. These new sources allow organizations to access data in even more locations using Palantir-provided JDBC drivers. New source types include DynamoDB, Dataverse, CosmosDB, LDAP, and many others.
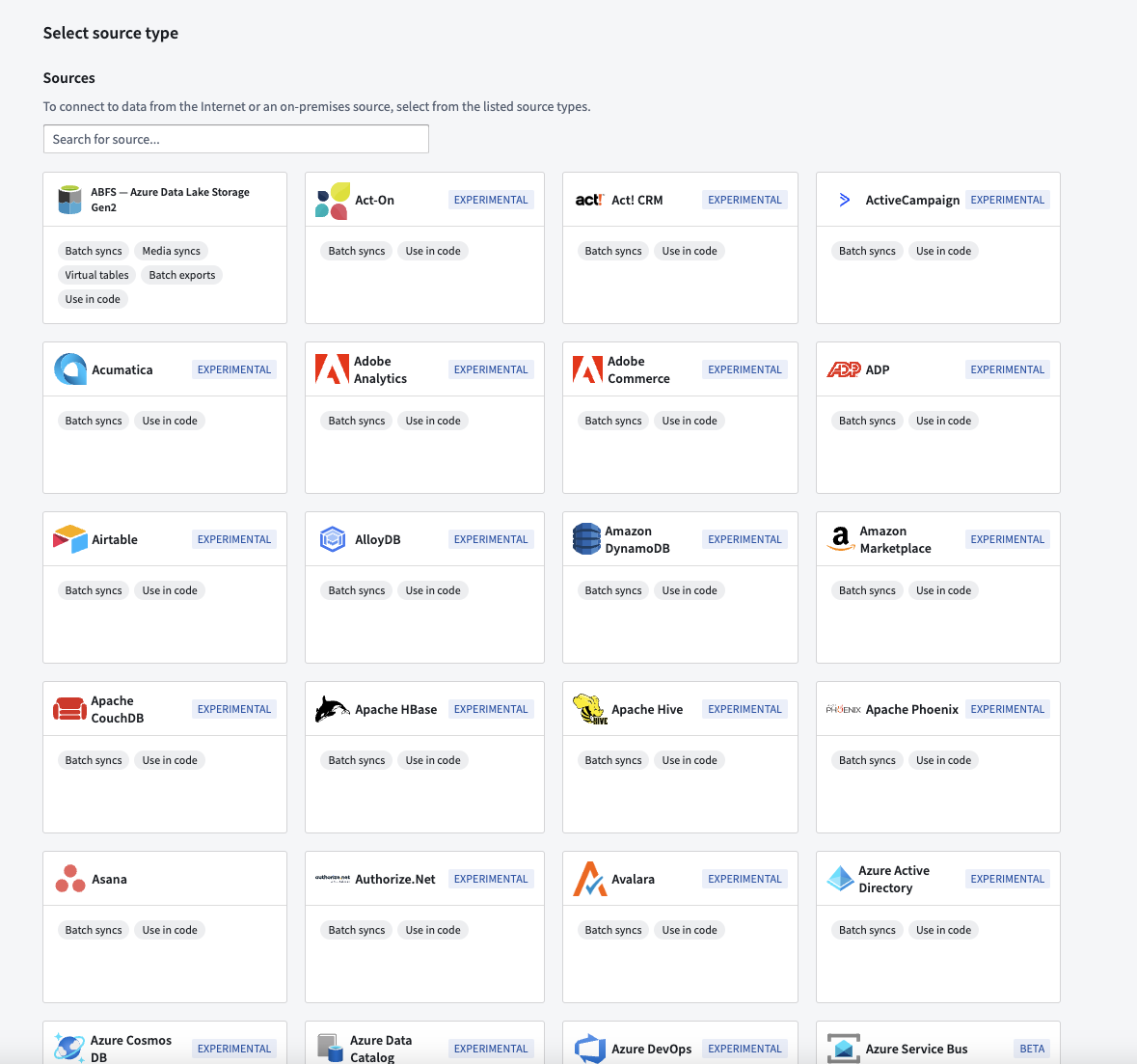
Updated Data Connection landing page showing new connectors.
The new sources have been released in the Experimental stage of Palantir's development lifecycle and are labeled as such. Each source will independently follow the stages of the development lifecycle as usage and support expand.
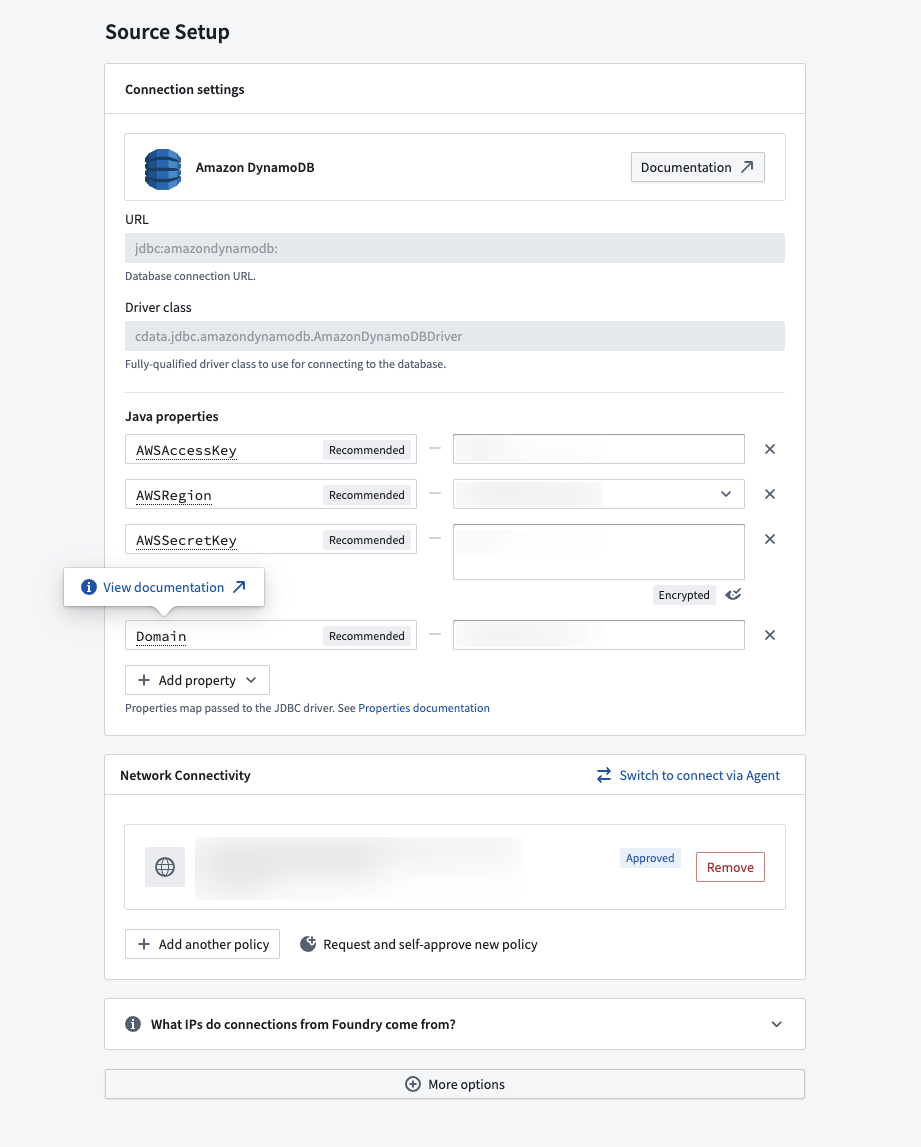
Example source configuration with inline documentation.
Learn more about connecting with Palantir-provided drivers, and explore the list of new available sources in our documentation.
All third-party trademarks (including logos and icons) referenced remain the property of their respective owners. No affiliation or endorsement is implied.
Faster previews in Pipeline Builder
Date published: 2024-06-17
Pipeline Builder previews are now significantly faster due to caching enhancements. Internal tests show a reduction in computation times from 40 seconds to 1 second, speeding up resource intensive previews by 40x. This feature is now generally available on all enrollments.
Faster previews powered by caching improvements
Caching improvements now allow nodes in Pipeline Builder to use cached, or "stored" results from upstream nodes that have already been previewed. This allows downstream nodes to skip recomputes and swiftly display your data previews.
Pipeline Builder's improved caching features include:
- Decreased redundant computations: Previews in Pipeline Builder now only compute additional nodes when previewing downstream of cached nodes.
- Efficient caching: Computationally expensive nodes such as joins and
use LLMare now proactively cached, allowing downstream nodes to avoid repetitive and time-consuming computations.
Users will benefit from snappy previews and decreased processing costs, saving time and resources when working downstream of expensive nodes. A lightning bolt icon will appear on previews that use cached upstream preview results, as shown below:

Improved node caching
Before this change, if you previewed a node twice without any logic changes, it would cache the results from the first preview and reuse them for the second preview. If you then previewed a downstream node, it would not have access to other cached node results. Upstream nodes needed to be recomputed from scratch.
Now, all node previews in Pipeline Builder can make use of cached results, so only additional downstream nodes need to be computed.
Take the following example dataset:

If you preview C, nodes Dataset → A → B → C are computed. Before this change, if you then preview D:
- Nodes
Dataset → A → B → Care recomputed, in addition toD.
After this change, if you preview D after C:
- Only nodes
C → Dare computed, because nodeDcan now use cached results from nodeC.
Note that all node previews compute up to 500 rows. Operations that will not benefit from this feature include operations that change row counts, joins, aggregations, or changes in logic.
Learn more about Pipeline Builder previews.
Support for Llama 3's 70B Instruct and 8B Instruct LLMs now available
Date published: 2024-06-17
Llama 3's 70B Instruct and 8B Instruct LLMs are now generally available and can be enabled for all commercial enrollments. These new flagship models from Meta have performance comparable to other top models in the industry. If your enrollment's agreement with Palantir does not cover usage of these models, enrollment admins must first accept an additional contract addendum through the AIP Settings Control Panel extension before these models can be enabled.
This model should be usable in all AIP features such as Functions, Transforms, Logic, and Pipeline Builder.
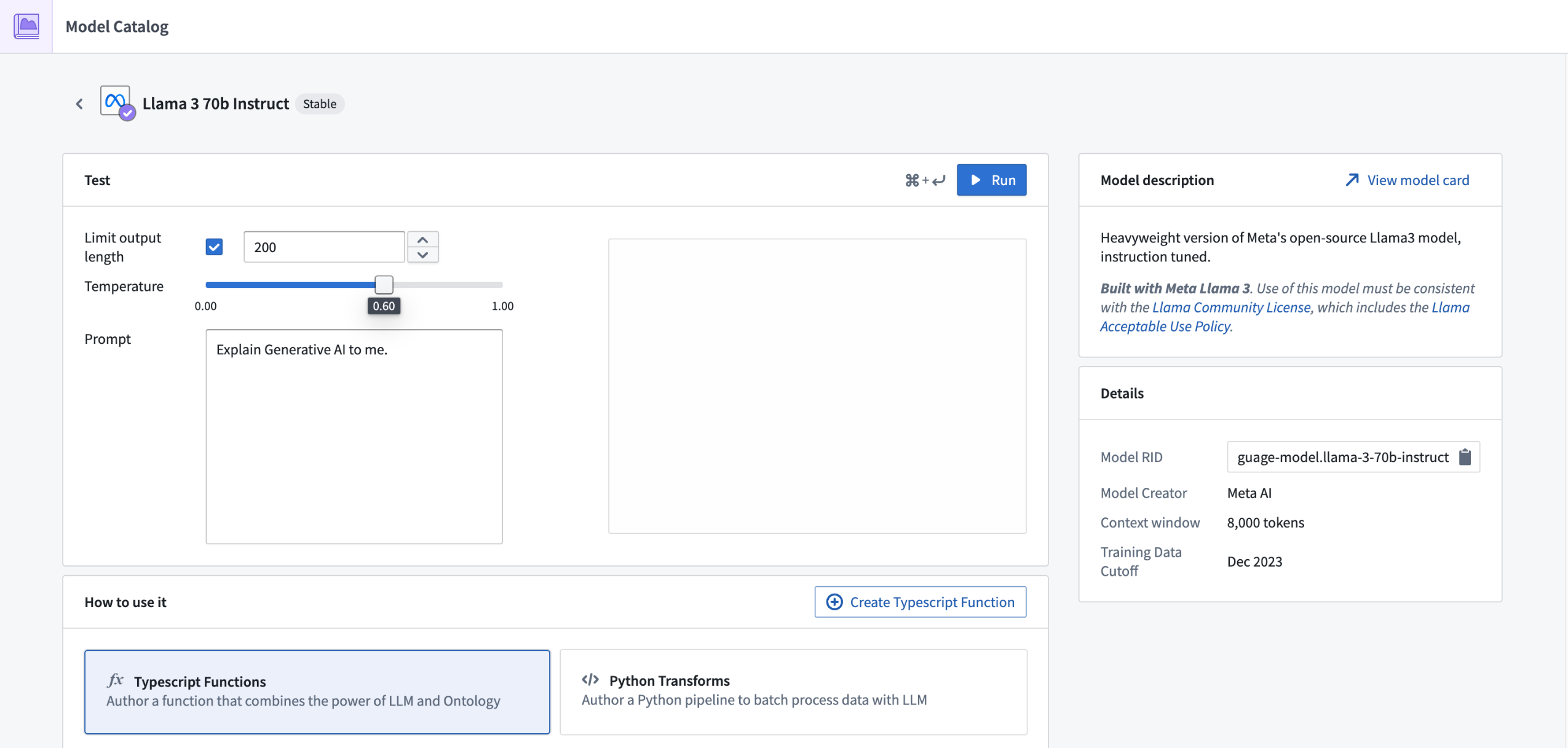
Review a list of LLMs supported in Palantir.
Support for GPT-4o LLM now available
Date published: 2024-06-17
GPT-4o through Azure OpenAI is now generally available on all enrollments that are either not geographically-restricted, or are geographically restricted to the United States or European Union.
To use GPT-4o, you will need to have Azure OpenAI models enabled through the AIP Settings Control Panel extension.
GPT-4o is targeted to be the new flagship model provided by OpenAI. Existing workflows which use GPT-4 are recommended to use GPT-4o as it is cheaper, faster, with more capacity available than existing models provided by Azure OpenAI, and supports multi-modal input such as image and text.
The expansion of supported regions is in development.
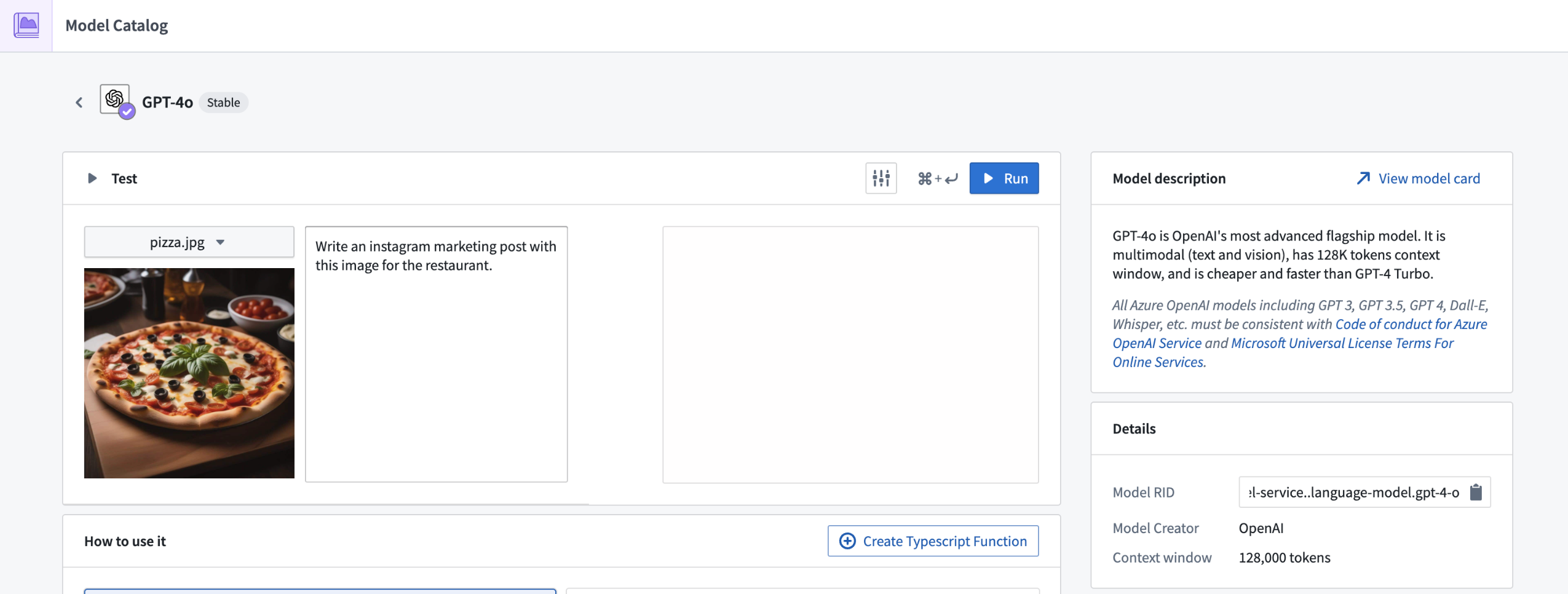
Review a list of LLMs supported in Palantir.
Support for Claude 3 Sonnet LLM through AWS Bedrock now available
Date published: 2024-06-17
Claude 3 Sonnet through AWS Bedrock is now generally available for all non-geographically-restricted enrollments, and geographically-restricted enrollments in the United States, European Union, and Australia. This new flagship model from Anthropic has performance comparable to other top models within the industry, and supports multi-modal workflows, including vision. If your enrollment agreement does not cover Claude 3 Sonnet usage, enrollment admins must first accept an additional contract addendum through the AIP Settings Control Panel extension before the LLM can be enabled.
This model should be usable in all AIP features such as Functions, Transforms, Logic, and Pipeline Builder.
Support for geographically-restricted enrollments in other regions is under active development.
Review a list of LLMs supported in Palantir.
Introducing Python functions for Pipeline Builder, Workshop, and more [Beta]
Date published: 2024-06-13
Python functions are now supported in Pipeline Builder, Workshop, and other Ontology-based applications. Python is a familiar, easy to learn, and well-documented language ↗ with an extensive list of libraries for everything from data science to image processing that you can now leverage in the Palantir platform.
Since user-defined Python functions in the Palantir platform are intentionally reusable across applications, you can easily pre-compute values in Pipeline Builder or calculate them in real time in Workshop modules when users add inputs. This same function can also be used in other Ontology-based applications to empower decision-making processes for your organization.
The following benefits can be found across the platform when using user-defined Python functions:
-
Leverage external libraries: Python has a huge number of libraries that can make development simpler, faster, and more performant.
-
Iterate rapidly: Preview your code in Code Repositories as you develop to monitor your results.
Use Python functions in Pipeline Builder
Python functions in Pipeline Builder offer efficiency and flexibility for your pipelines:
-
Release with ease: When you are satisfied with your changes, simply tag and release your code to make it available in Pipeline Builder.
-
Improve execution time: Reduce your build time by setting your batch size between 100 and 1000, specifying the number of rows to process in parallel.
Add a custom function to your Pipeline Builder pipeline by selecting Reusables in the upper right of your graph. Then, choose User-defined functions > + Import UDF. Here, you can choose the Python function you want to add to your pipeline. Your function will take in a single row, transform it using your logic, and output a single row for all batch and streaming pipelines.
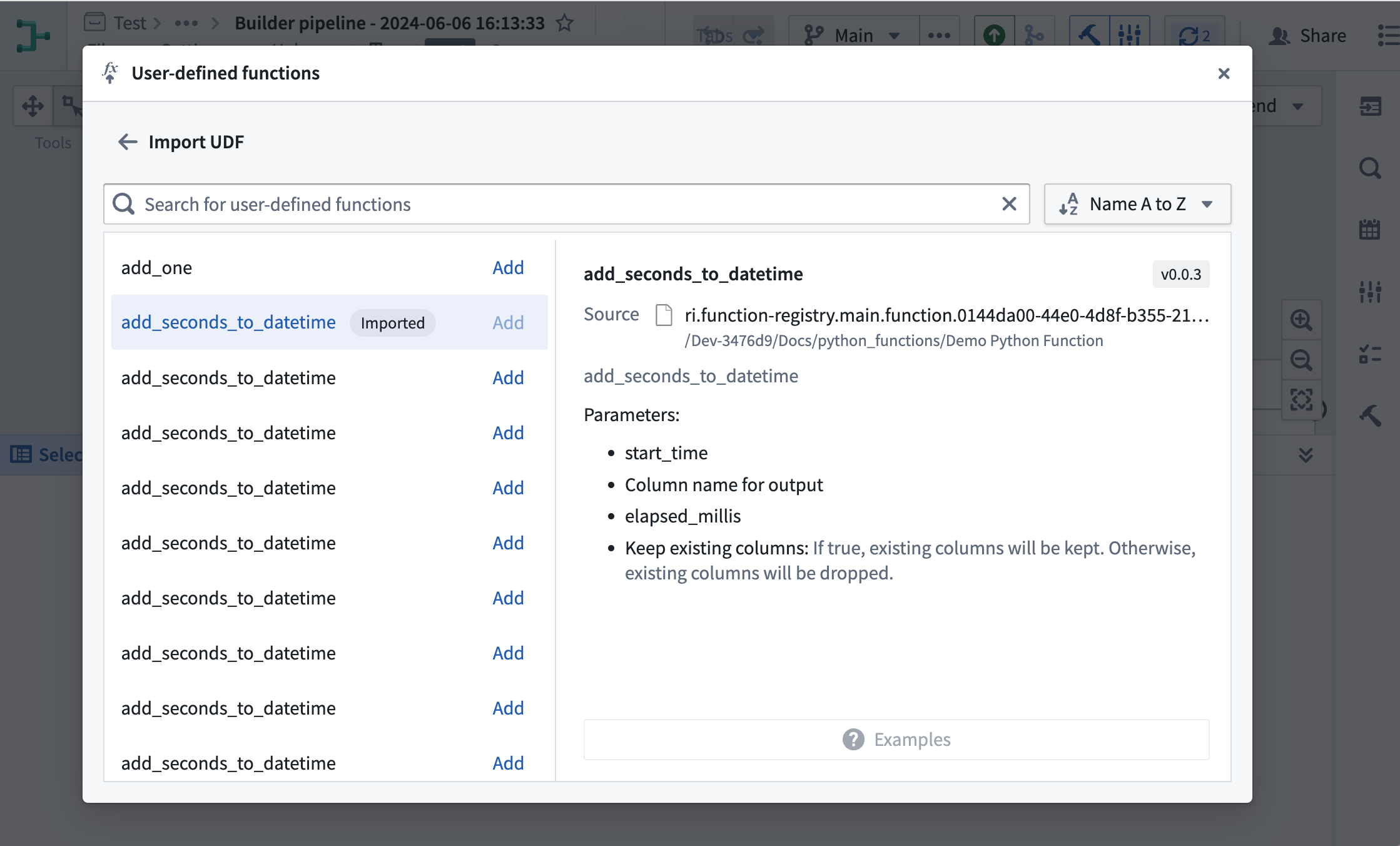
Importing Python functions into Pipeline Builder.
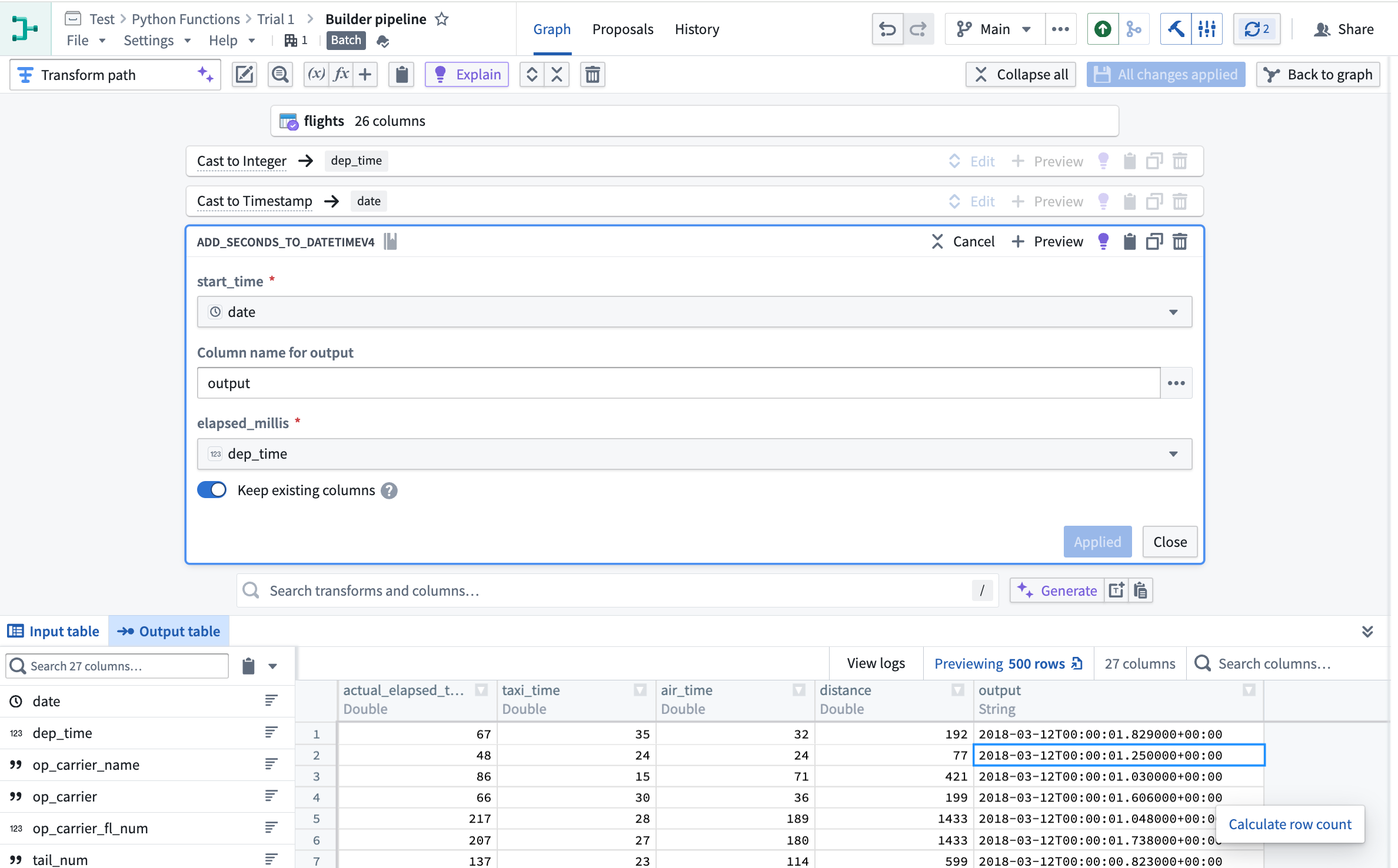
Adding Python functions to the Pipeline Builder pipeline.
Use Python Functions in Workshop and Ontology-based applications
In Workshop, your function will be "deployed", allowing it to dynamically adapt to the number of incoming requests. During periods of high usage, your deployed function will dynamically scale to support new user inputs.
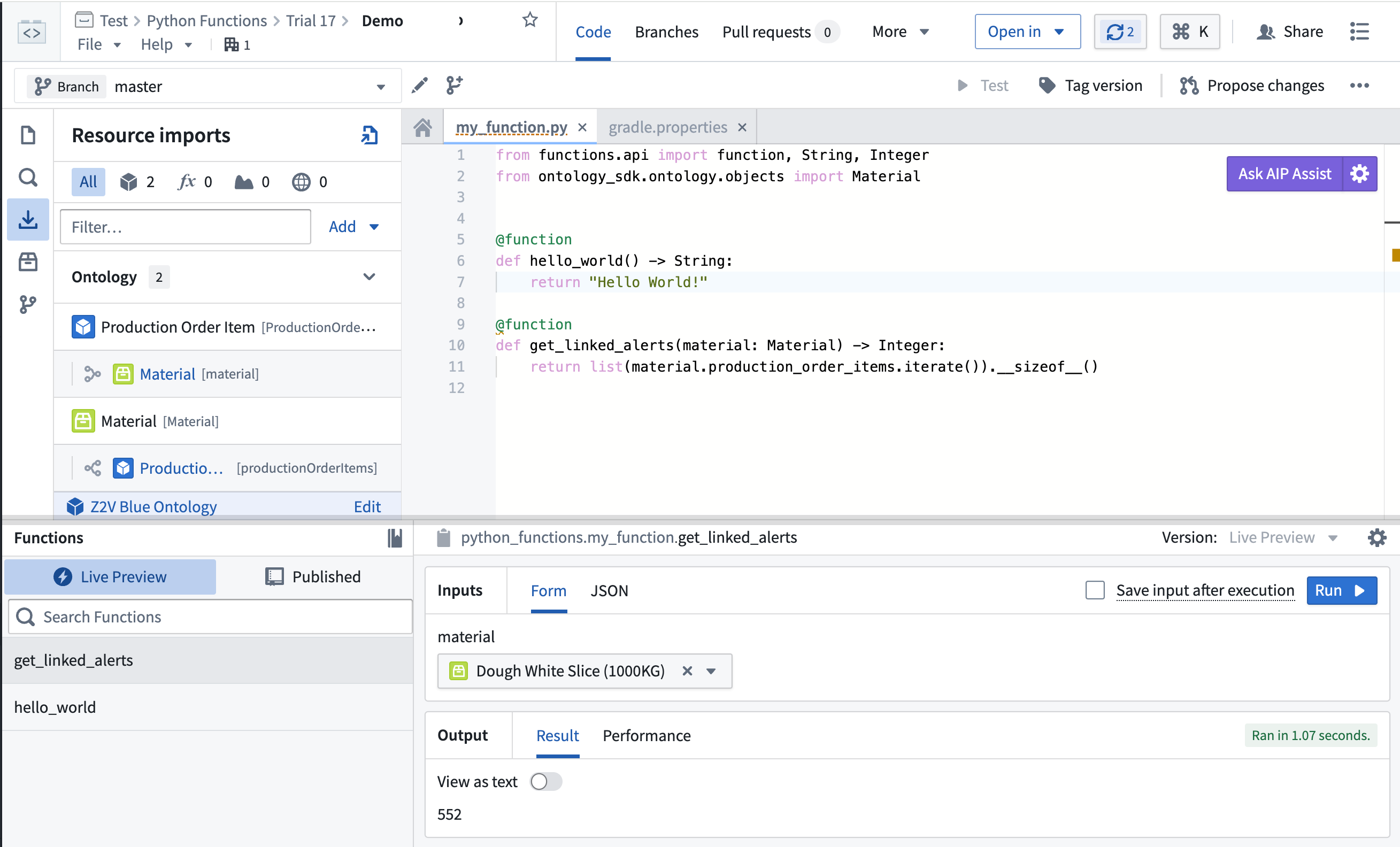
Preview your function in Code Repositories.
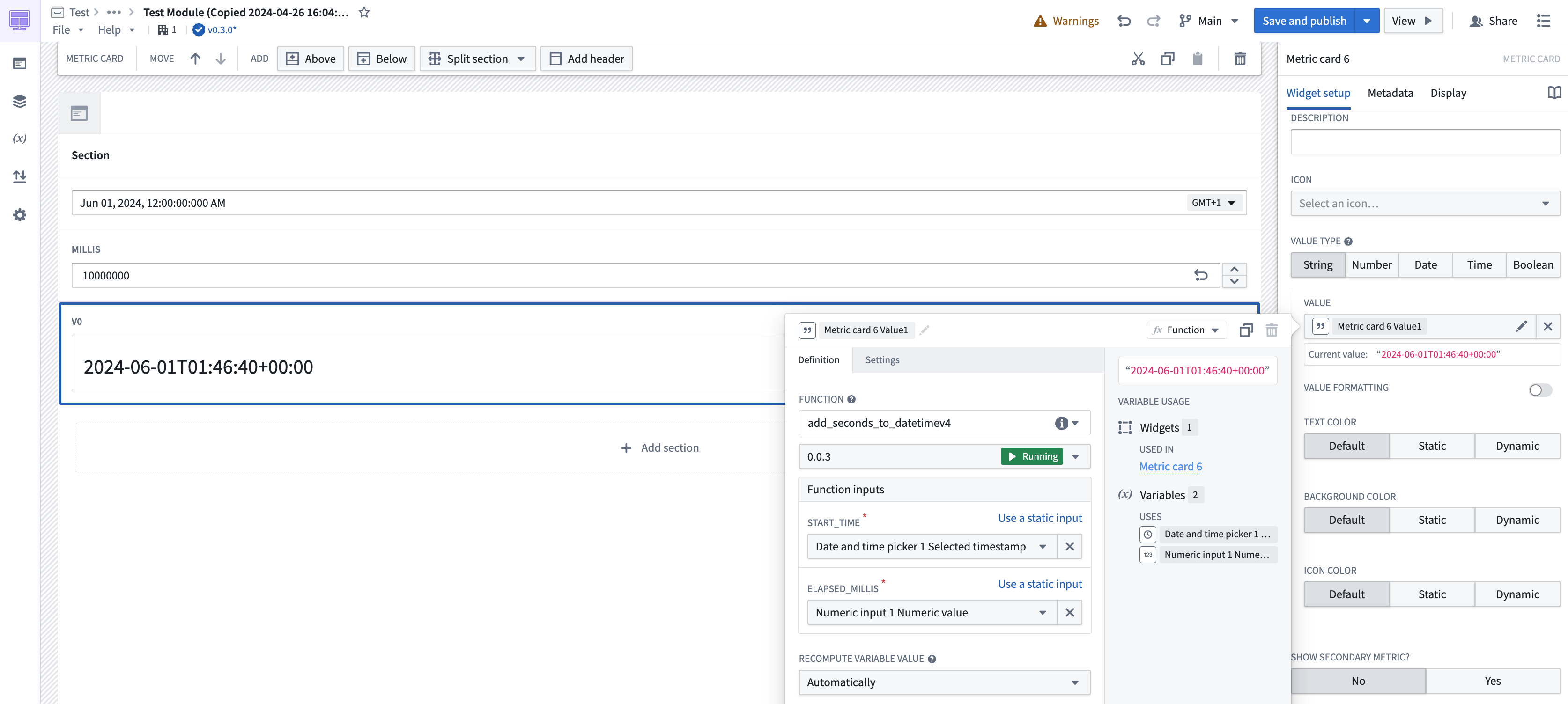
Deployed functions in a Workshop module.
Learn more about Python functions and write your first user-defined Python function with our documentation.
What's next on the development roadmap?
-
A cheaper, faster backend: We are actively working on improving backend performance for Python functions used in Workshop and other applications to match the high-level performance of TypeScript functions.
-
Bridging gaps between TypeScript and Python functions: We continue to work to provide the same level of support to Python functions as we do with TypeScript functions. Currently, our highest priority is to provide support for Ontology edits through Python functions.
-
Marketplace compatibility: Python functions will soon be available in Marketplace so you can share easily share your functions with other users.
Code Repositories now supports Python 3.11
Date published: 2024-06-10
Code Repositories now supports Python 3.11 ↗ for all enrollments. Python 3.11 provides significant performance enhancements such as being "between 10-60% faster than Python 3.10" according to Python documentation ↗.
To access these benefits, you must upgrade your code repositories. We strongly advise keeping your repositories up to date to leverage the latest performance improvements and critical security patches.
Python 3.11 support with boosted performance, TOML parsing, and enhanced typing
Users will now be able to use this version in Python environments, both during Preview and also when the Python transform is running.
Highlights from Python 3.11 include:
- Significant performance improvements
- Support for parsing TOML ↗
- Improved exception information and typing support
To use Python 3.11, users must upgrade repositories and can set the Python environment to use either the recommended version of Python or explicitly select a Python 3.11 release.
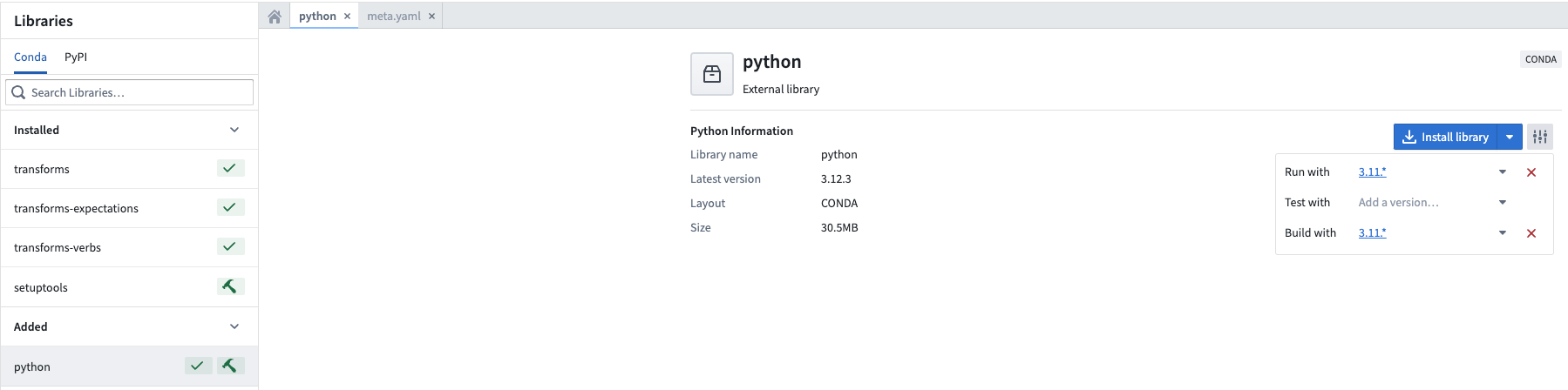
Setting the Python environment to a desired version.
Learn more about Code Repositories.
Introducing Hawk for Python package management in Code Repositories
Date published: 2024-06-10
We are excited to announce Hawk, a new package manager for Python environments. Hawk will be available in Code Repositories on Foundry enrollments in mid-June 2024. It replaces Mamba ↗, which underwent major breaking changes in September 2023, as the default Python package manager in Code Repositories.
Hawk offers enhanced performance and maintainability, ensuring a more efficient and reliable Python environment management experience. Initial tests of Hawk have shown performance improvements of ~25% in checks execution time relative to Mamba when resolving and installing new packages. Additionally, Hawk is built on top of actively maintained libraries, ensuring that the core infrastructure remains up-to-date and secure.
New Python code repositories will begin using Hawk automatically. For existing repositories, you can upgrade the repository by selecting ... and then selecting Upgrade.
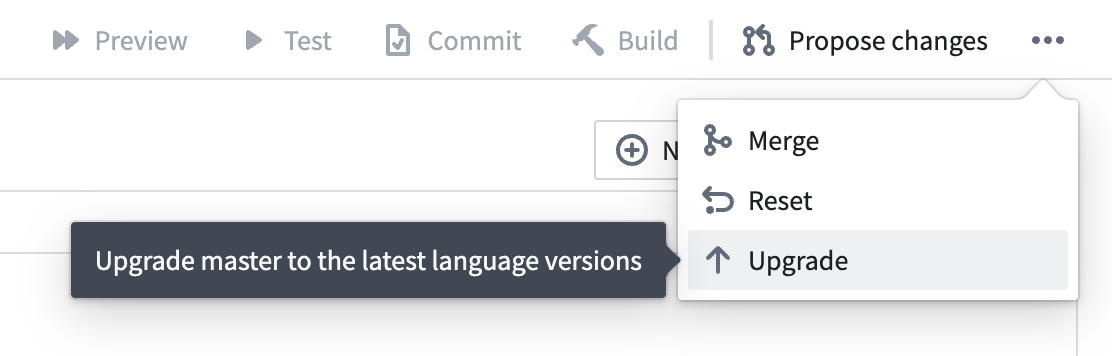
Upgrade your Python repositories to the new Hawk environment management system.
In Python repositories using Hawk, you can view log lines in the Checks tab that indicate certain tasks are being executed by Hawk instead of Mamba. For example, you can view the log line Executing task 'runVersions' with 'HAWK'.
Hawk is built on top of the open-source library Rattler ↗.
Introducing OSDK in Slate [Beta]
Date published: 2024-06-05
The Ontology Software Development Kit (OSDK) allows you to access the full power of the Ontology directly from your development environment. On all enrollments, OSDK is now available in Slate and you can interact with the Ontology by writing functions in Slate to transform Ontology data.
With the OSDK, benefit from a tighter integration between Slate and the Ontology. For example, builders can access object types, link types, and actions from a dedicated interface where the OSDK package can be generated and updated whenever the Ontology is changed.
Fully interact with the richness of the Ontology in code by building applications that can traverse object types with ease, and use actions for a rich and customized application for your organization's most important workflows.
Slate allows for using Foundry Functions in the Platform tab as well as working with non-Ontology data sources to provide a highly-flexible environment for application builders.
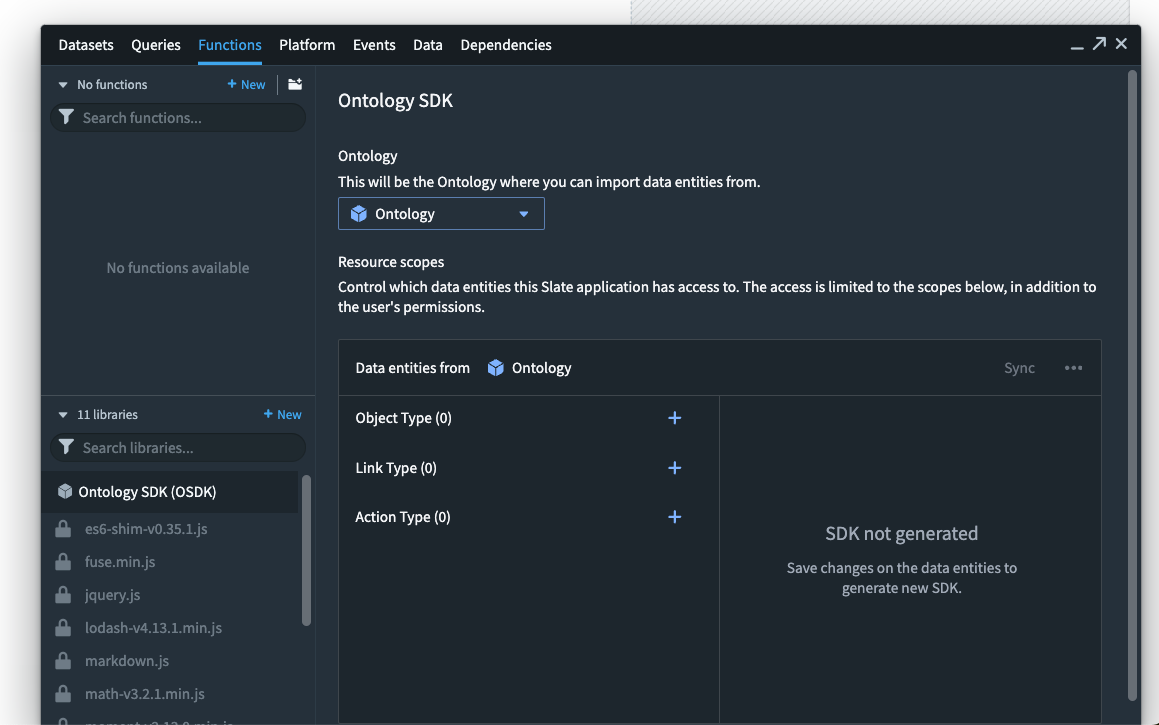
Application builders can now use OSDK functionalities in Slate to enable products that interact with the Ontology.
Learn more about Using the Ontology SDK (OSDK) in Slate.
Additional highlights
Administration | Control Panel
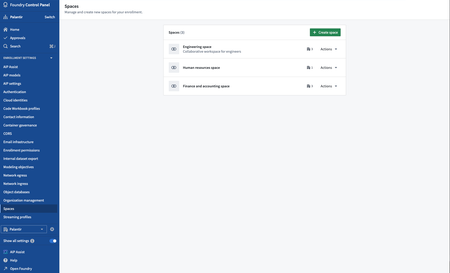
Spaces are now managed in Control Panel | In an effort to consolidate and simplify administrative settings in Foundry, spaces (previously referred to as namespaces) are now managed in Control Panel under enrollment settings.
Although the Spaces tab is visible to everyone, permissions required to manage individual spaces remain unchanged. To configure, it is necessary to meet the access requirements and be granted a role on the relevant space. For more details, review our spaces documentation.
Analytics | Notepad
Enhanced Document Creation from Notepad Templates | The Notepad application now includes an enhanced feature allowing users to instantly generate documents from the latest versions of published Notepad templates. This new functionality is conveniently accessible either from the application's home page or directly through the file menu in the application header.
Analytics | Quiver
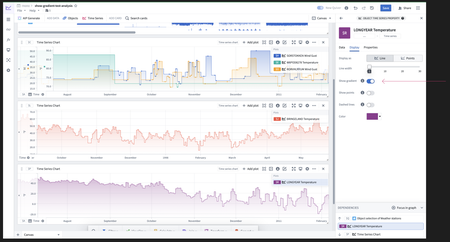
Refined Gradient Display for Time Series Insights | Quiver now features a gradient display option configuring a color fill for time series charts. This improves legibility when plots overlap in the same chart and helps in identifying relative changes in magnitude over time.
App Building | Slate
Enhanced Sidebar Experience in Slate | The redesigned sidebar in Slate introduces a more cohesive user interface. This update centralizes essential tools for application layout, data management, logic operations, and debugging into a singular, accessible panel, enhancing the user journey and facilitating a smoother introduction for new users.
Enhanced JSON Export for Slate Documents in Version History | The Versions dialog now supports exporting the JSON of a Slate document for any selected version. This enhancement ensures editors can easily access and export document JSON for any existing version.
App Building | Workshop
New sorting options | The Object List widget now supports sorting on multiple properties along with sorting on function-backed properties.
Virtualized Object List in Workshop | Object List widgets now leverage virtualization technology to dramatically boost performance, especially for lists containing numerous elements.
Enhanced Widget Configuration in Workshop | The Workshop Action widget now supports a tabular data entry configuration with support for creating multiple rows of new data simultaneously or uploading a spreadsheet of rows to populate the input table. This feature unlocks workflows that require high volume manual data entry.
Enhanced Branch-to-Main Module Comparison | The changelog panel now supports selecting the latest main version for comparison while working within a branch, streamlining the module diffing process. This update is especially advantageous for users engaged in branching workflows.
Data Integration | Data Connection
Enhanced Webhook Access in Data Connection | Users can now directly view and manage the webhooks associated with a source by navigating to that source. The previously available page listing all webhooks has been deprecated.
Ontology | Ontology Management
Refined Primary Key Handling in Ontology Manager Uploads | Enhancements to the tabular entry mode for Actions now ensure a more intuitive handling of primary keys during file uploads. Valid primary keys are automatically associated with their respective objects for object reference form parameters. Those that cannot be resolved are promptly highlighted for direct editing within the upload interface. This update simplifies the data correction process when populating a tabular action with a CSV upload.
Ontology | Vertex
Refined Icon Personalization in Vertex Graph Layers | Vertex introduces refined icon personalization capabilities for graph layers, enabling users to tailor icons according to object attributes or choose from an expanded selection of static icons. This improvement offers a tailored approach to node visualization in graph representations, meeting the varied needs of different workflows.
Security | Approvals
Improved Approvals actions and statuses | Access requests in Approvals have been streamlined; available actions are now present at the request level, rather than at the task level. Approvers can now apply actions to multiple tasks. This improves the discoverability and explainability of all available actions and simplifies request processing. New access request statuses such as Pending approval, Closed, Action required, and Completed have been introduced to better communicate the state of a request.
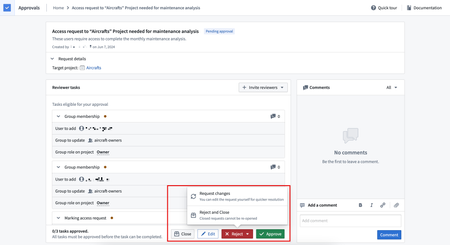
Improved Approvals inbox search | The Approvals inbox now allows users to filter requests based on included Projects, users, or groups, in addition to existing filters. These new filters only apply to access requests and significantly improve user experience by making access request reviews more efficient. Filters that were previously displayed in the table header are now in the left sidebar.