- Capabilities
- Getting started
- Architecture center
- Platform updates
Announcements
REMINDER: You can now sign up for the Foundry Newsletter to receive a summary of new products, features, and improvements across the platform directly to your inbox. For more information on how to subscribe, see the Foundry Newsletter and Product Feedback channels announcement.
Introducing AIP Logic [GA]
Date published: 2023-12-14
AIP Logic is a no-code development environment for building, testing, and releasing functions powered by large language models. With AIP Logic, you can build feature-rich AI-powered functions that leverage the Ontology without the complexity typically introduced by development environments and API calls. Using Logic’s intuitive interface, application builders can engineer prompts, test, evaluate and monitor, set up automation, and more.
You can use AIP Logic to automate and support your critical tasks, whether that’s connecting key information from unstructured inputs to your Ontology, resolving scheduling conflicts, optimizing asset performance by finding the best allocation, or reacting to disruptions in your supply chain.
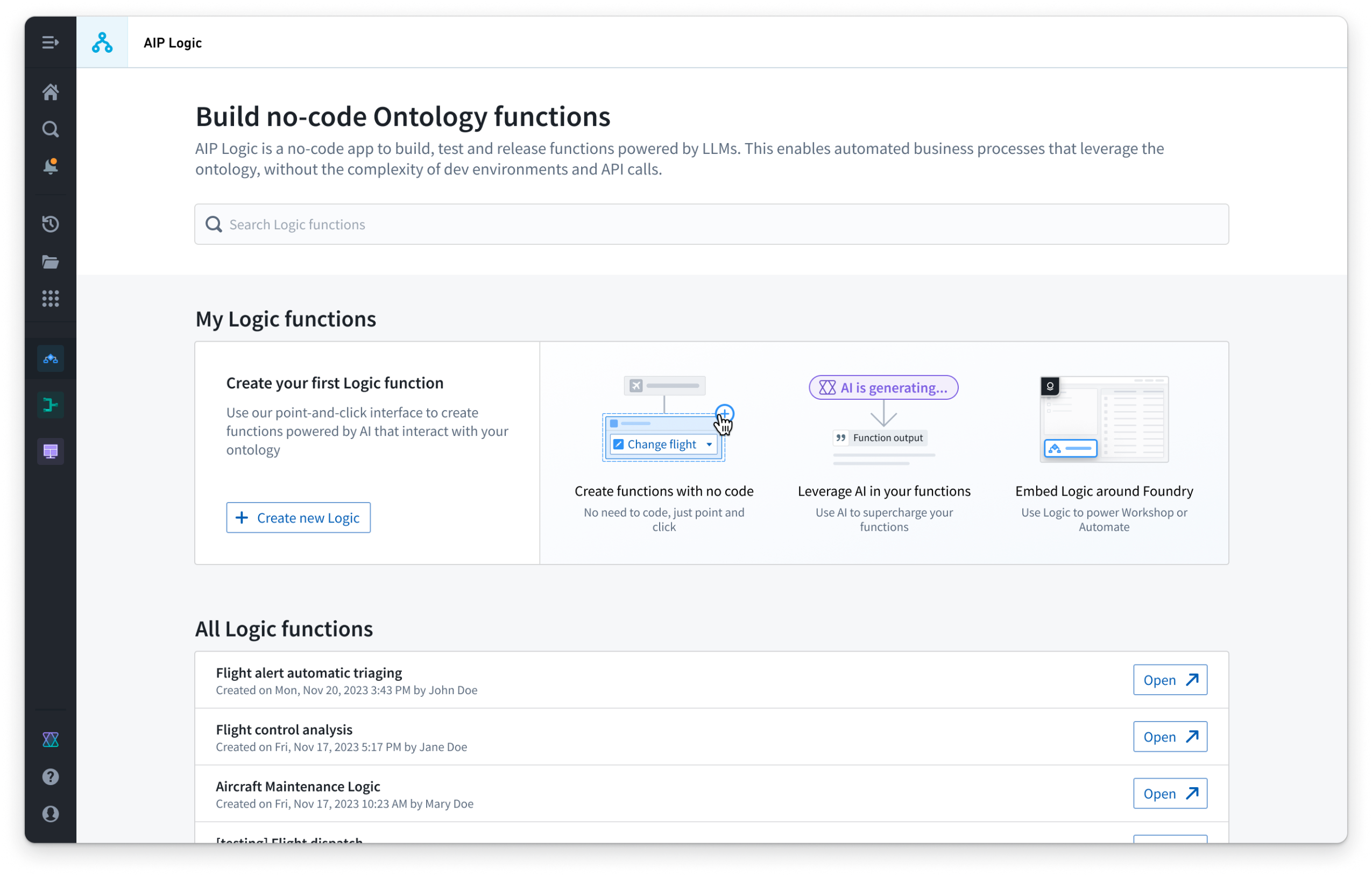
AIP Logic's landing page.
Access AIP Logic
AIP Logic can be accessed from the platform’s workspace navigation bar or by using the quick search shortcuts CMD + J (macOS) or CTRL + J (Windows). Alternatively, you can create a new logic function from your Files by selecting +New and then choosing AIP Logic, as shown below.
+ New dropdown menu.
What's on the development roadmap?
The following features for AIP Logic are currently in development:
- Logic Assistant: Obtain AI-assisted help in writing your prompts and check for missing tools and data. Build more reliable Logic functions and benefit from faster iteration on prompts and reduced error rates.
- Versioning and Branching: Create, manage, and merge different versions and branches of your AIP Logic functions.
- Evaluations: Set up an evaluation and testing framework with your Ontology definition to measure the efficacy of your Logic functions.
Get Started with AIP Logic
To get started, visit Getting started or learn more about Core concepts.
Introducing Derived Series [Beta]
Date published: 2023-12-14
Derived series, now available as a beta feature on request, provides a new way for time series users to save and replicate calculations performed on time series data within their Quiver analysis. Storing derived series as Foundry resources allows the logic to be shareable and linked to the Ontology, enabling derived series to act like raw time series, calculated on demand without needing additional storage or repeated calculations.
Contact your Palantir representative for enablement.
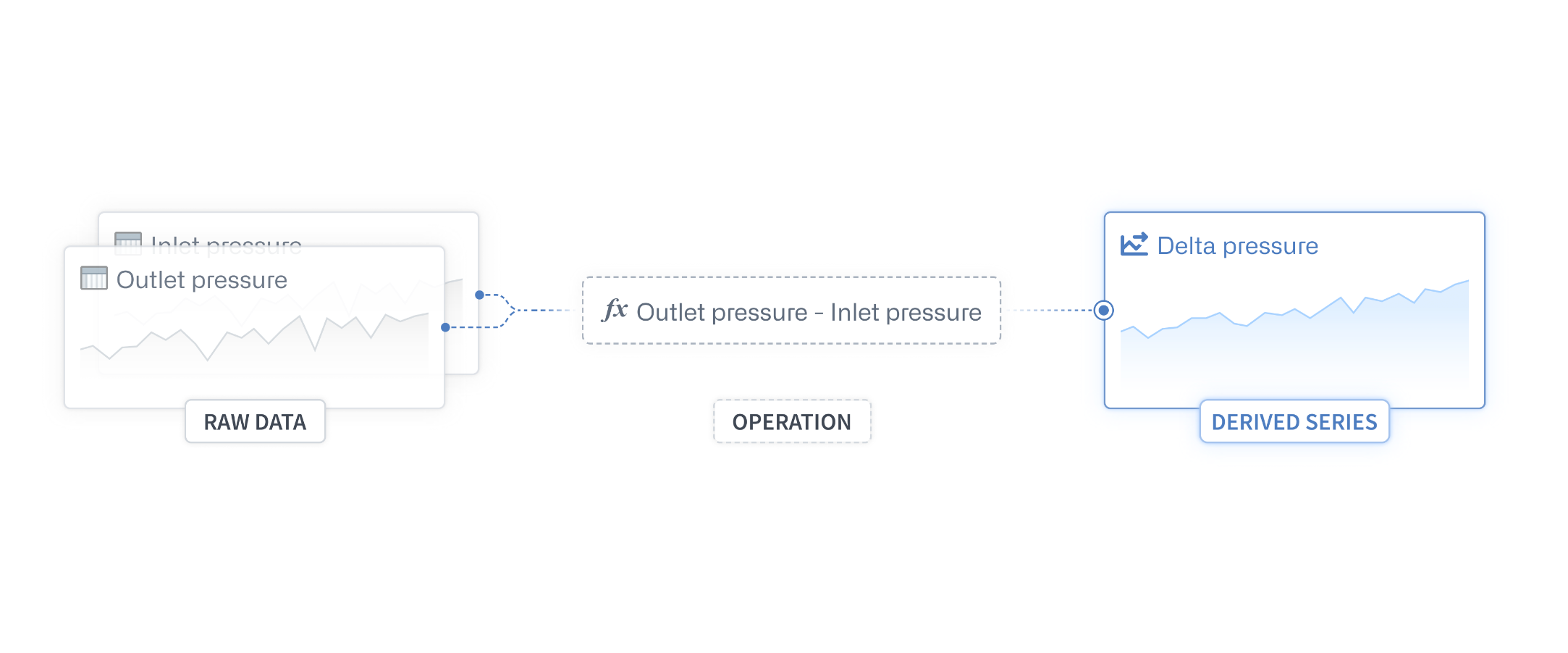
A derived series is the combination of transformations and/or calculations on raw time series data, saved as a Foundry resource to be reused in a variety of workflows.
Derived series creation
Users can now save transformations on time series data from their Quiver analysis as derived series. Time series cards such as time series formula, rolling aggregate, et cetera now have a Save derived series option that converts the entire logic tree in a Quiver analysis to a codex template that can be executed at runtime.
Learn more about creating derived series.
Saving derived series after details and object type select configuration.
Derived series management
Furthermore, you can access the derived series management page to manage both the derived series resource as well as codex template. View relevant information about the derived series as well as modify the logic, metadata and republish a new version of the derived series template.
Learn more about managing derived series.
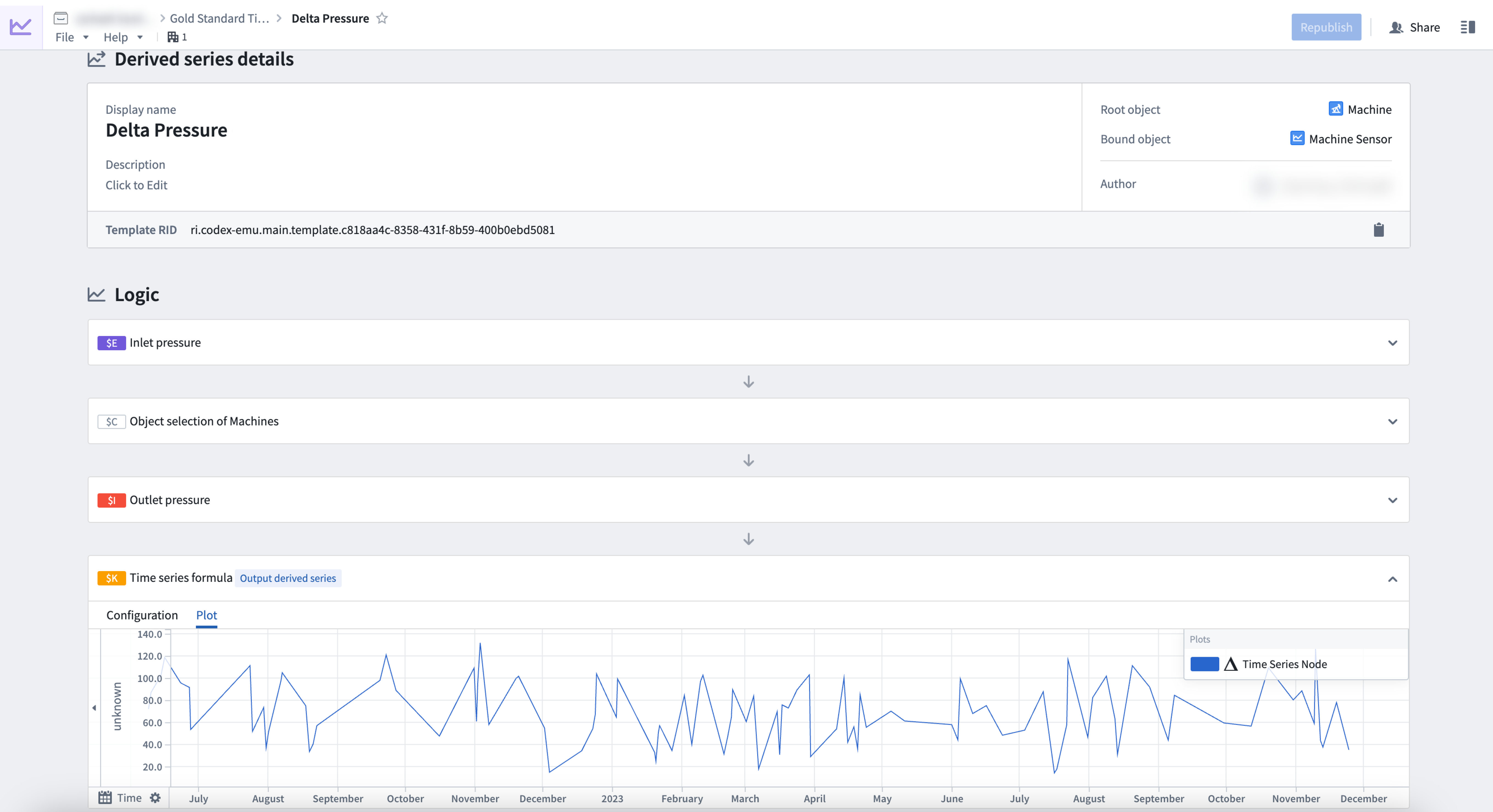
Derived series details in one view.
What's on the development roadmap?
The step to save derived series to the Ontology currently necessitates users to manually build and maintain pipelines that link the series to root or sensor object types in order to facilitate the broader use of derived series in analytical or operational applications, comparable to raw time series. We are actively developing full automation in building derived series workflows to ensure a seamless user experience by eliminating the need to manually manage Ontology pipelines.
Get started with derived series
For more information, review the following related documentation:
Introducing HyperAuto V2 automatic sync creation [GA]
Date published: 2023-12-12
The automatic sync creation feature for HyperAuto V2 pipelines is now generally available, allowing you to select any visible table within your source when configuring a HyperAuto pipeline. In the case where a sync does not already exist, HyperAuto will intelligently create one for you to configure as you wish.
Use tables without data connections syncs as inputs
You can now choose tables that do not have data connection syncs as inputs in the Input configuration step. If syncs exist for a chosen input, HyperAuto will default to using the most recently run sync. You can re-configure a selected input via the Configure input table option via the pencil icon and can choose either a different existing sync to use or for a new sync to be created.
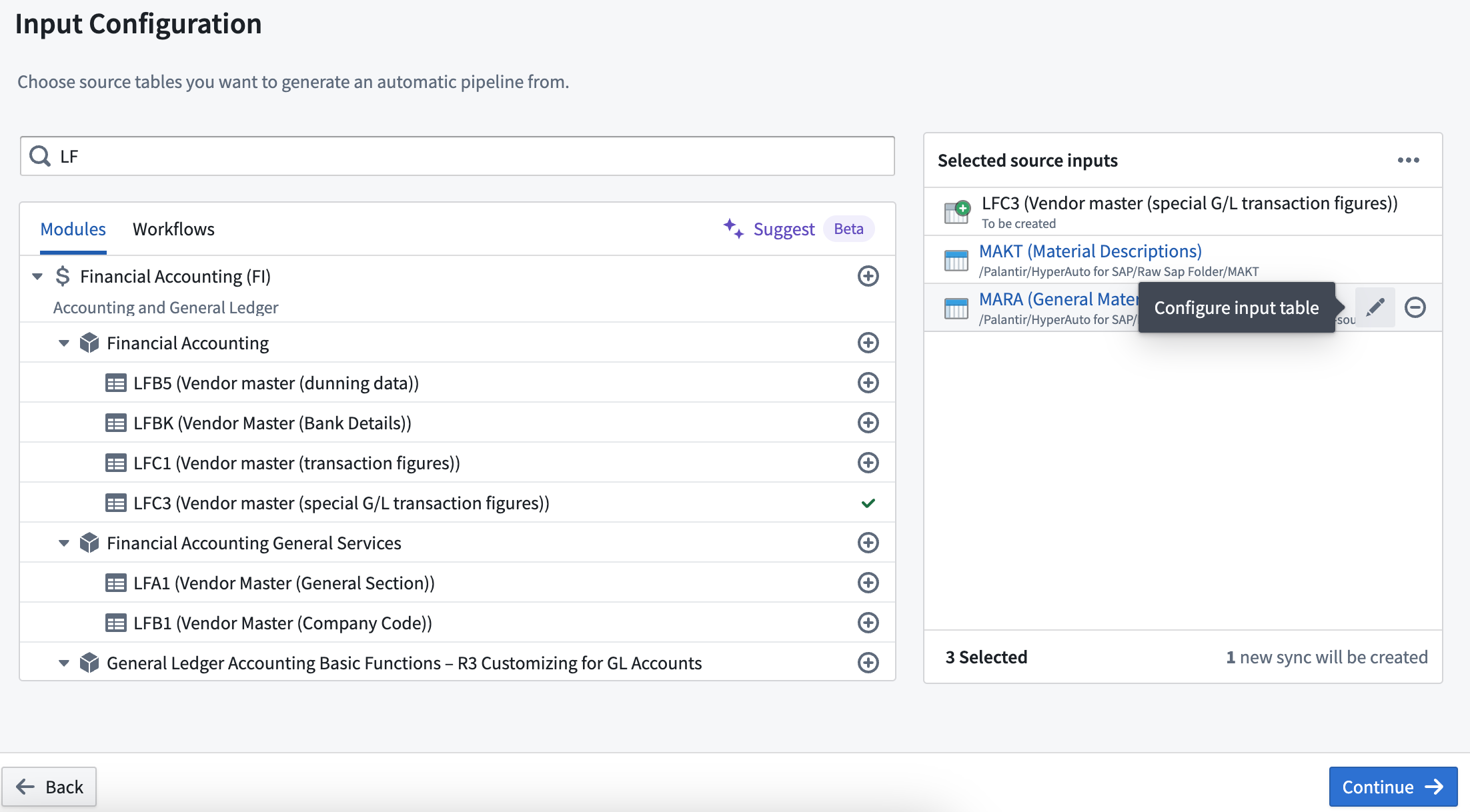
Input configuration window now allows tables without data connection syncs as inputs.
From the Input table settings panel, select Create a new sync from your SAP Source for this table, then Save.
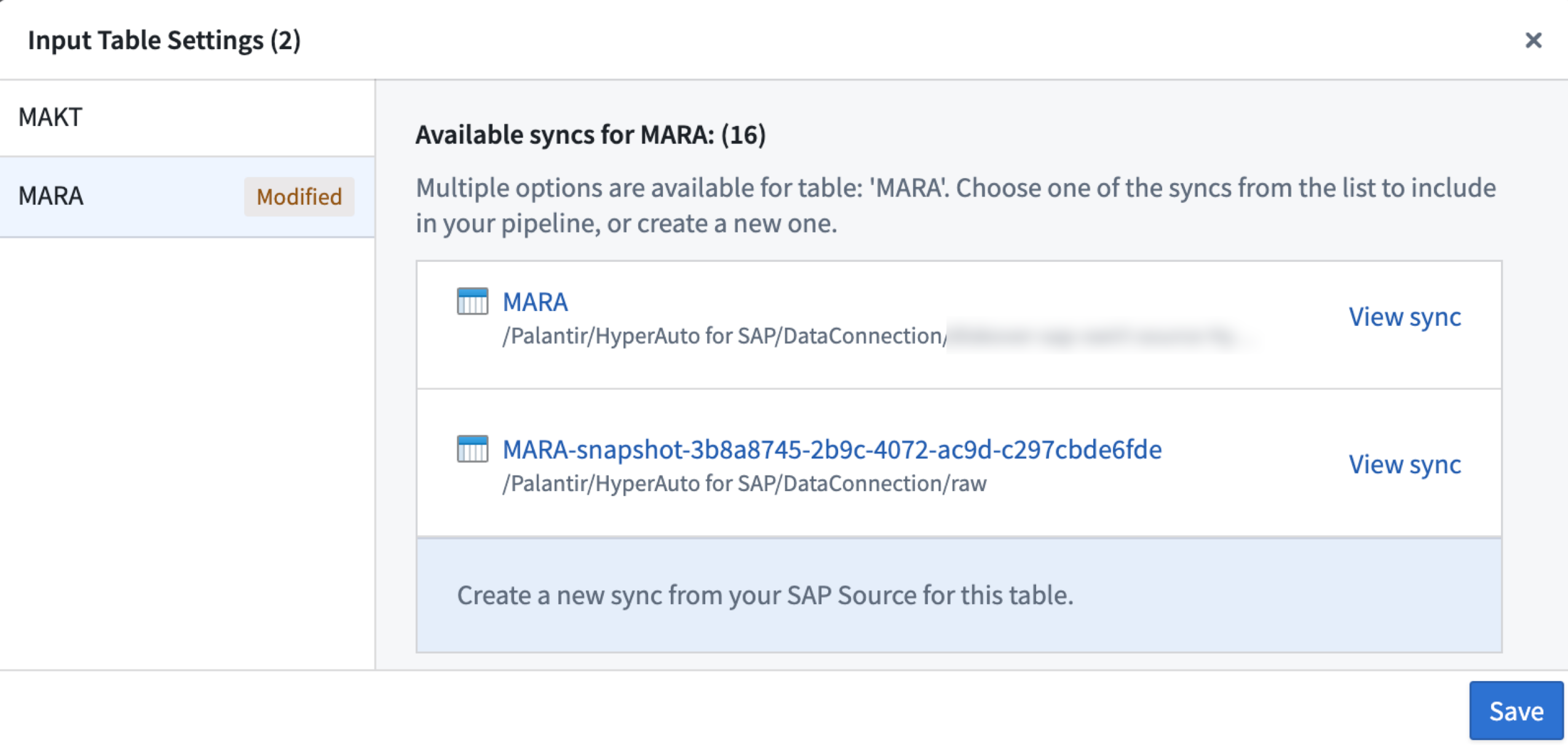
Create a new sync option available from the Input table settings panel.
Once the HyperAuto pipeline has been created, you can see how many syncs are being set up (also known as “initialized” in the interface) from the Overview page.
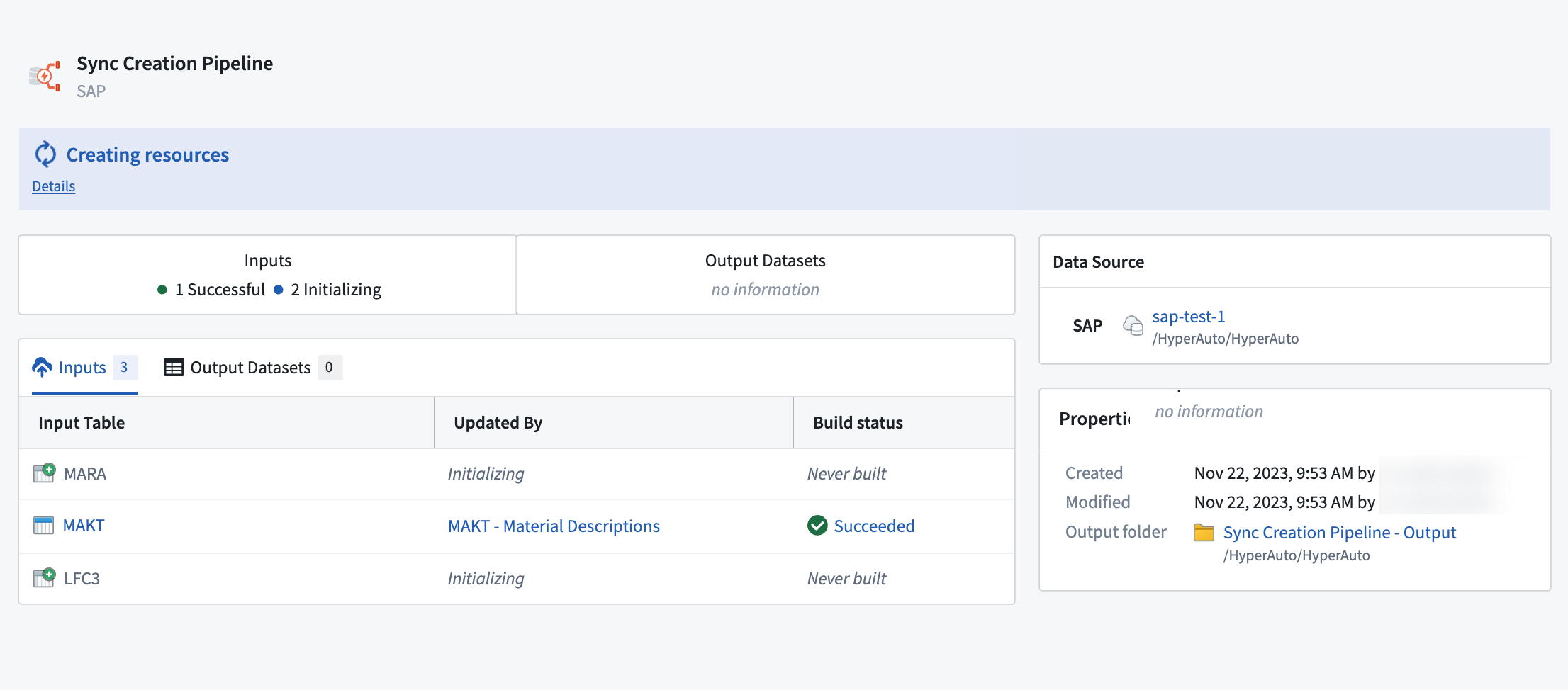
Overview page showing syncs being automatically generated.
HyperAuto will create and run the syncs shown on the Overview page before deploying the pipeline logic.
Learn more from Getting started with HyperAuto.
Introducing the Free-form Analysis widget
Date published: 2023-12-12
The Free-form Analysis Workshop widget enables users to independently investigate object data with flexibility within the framework of a Workshop application. Now generally available, the widget allows users to benefit from simple path-based analysis interface driven by Quiver's robust suite of features.
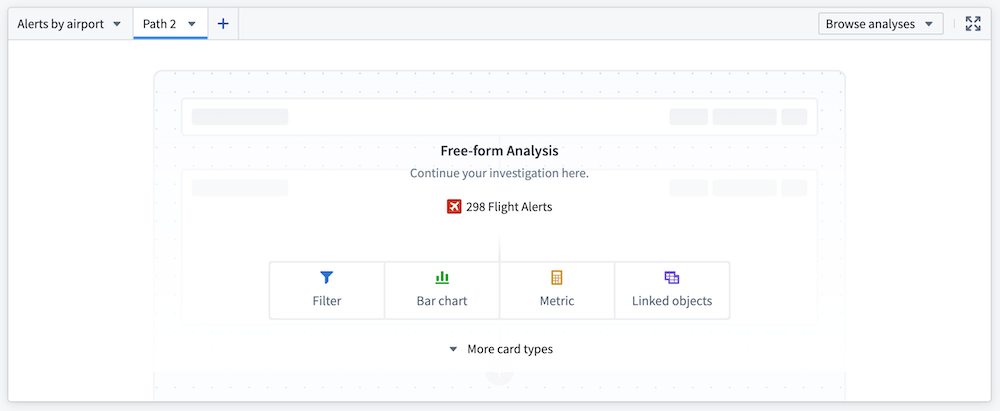
Investigate data directly within Workshop applications with the Free-form Analysis widget.
Seamless data exploration within Workshop applications
With the Free-form Analysis widget, users can explore the object data within the Workshop application, and share their investigation with others to reduce duplicative work and enhance their workflow. Previously, when users wanted to dig into data in a Workshop application, they were required to use Contour or Quiver to support their investigation.
Now, with the Free-form Analysis widget, the following use cases will benefit:
- Data exploration: Explore data and create bespoke investigations within an existing Workshop application.
- Root cause investigation: Given an alert, users can build upon a pre-defined set of visualizations and drill into the data in whichever direction is most relevant for their investigation — including exploring linked object types.
- Application prototyping: Builders can review saved analyses to understand common off-roading patterns, then incorporate these into the production workflow.
- Cohort creation: Users can drill down to create custom cohorts, which can be saved as a group for use elsewhere in the application.
Get started with Free-form Analysis widgets
To begin using the Free-form Analysis widget, simply search for the widget in the Workshop widget homepage. Then, to configure:
- Provide an Input object set to serve as the base input to the analysis.
- Define how the widget should be configured when there are no cards in a path by setting the Empty state header and the Empty state description.
- Determine the Output object set, which saves the output object set for reference elsewhere within Workshop.
- Optionally, toggle on Enable path saving which will copy individual cards in a path to be added to a Notepad document. Users should note that cards can only be copied if they are in a saved analysis path.
Analysis paths can be saved as either public or private for future reference and can also be opened in Quiver, or copied to Notepad documents.
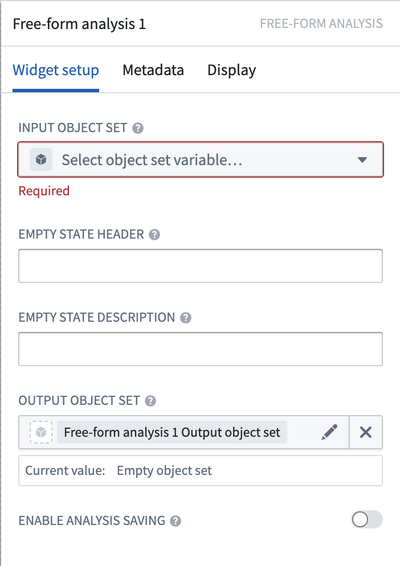
Free-form Analysis widget configuration
To learn more, see the Free-form Analysis widget documentation.
Introducing expanded LLM integration for AIP developer capabilities
Date published: 2023-12-07
We are excited to announce expanded support for large language model (LLM) usage in AIP developer capabilities, including:
- AIP developer capabilities permission management in Control Panel
- Language models in Python transforms
- Language models in Functions on Objects
- Text to Embeddings board in Pipeline Builder
AIP developer capabilities permission management in Control Panel
Administrators of AIP-enabled stacks can now take advantage of a new AIP Settings page in Control Panel to manage access to LLMs within AIP developer workflows. From the page, administrators can enable, disable, and choose which users groups are able to build workflows on top of custom and Palantir-provided LLMs.
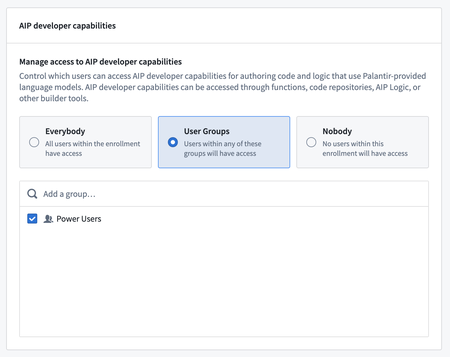
AIP developer capabilities permission management in Control Panel
Use language models in Python transforms
Pipeline authors using Python transforms can now seamlessly build data pipelines that make use of Palantir-provided LLMs and embedding models. Simply take advantage of the Python SDK included in the palantir_models Python package.

Incorporate LLM in your data pipelines with the palantir_models Python package
Example setup
The code snippet below demonstrates how a pipeline developer can implement transforms with OpenAI's GPT-4 ↗ in their logic, effortlessly tapping into the potential of LLMs for any data pipeline existing on the platform.
Copied!1 2 3 4 5 6 7 8 9 10 11from transforms.api import transform, Input, Output from palantir_models.transforms import OpenAiGptChatLanguageModelInput from palantir_models.models import OpenAiGptChatLanguageModel @transform( source_df=Input("/path/to/input/dataset") gpt_4=OpenAiGptChatLanguageModelInput("ri.language-model-service..language-model.gpt-4_azure"), output=Output("/path/to/output/dataset"), ) def compute(ctx, source_df, gpt_4: OpenAiGptChatLanguageModel, output): ...
For more information on LLMs available in-platform and usage, consult Palantir-provided models within transforms in the documentation.
Interact with language models in Functions on Objects
Users can now create custom logic using Palantir-provided language models with Typescript functions, facilitating workflows like summarization, Q&A, semantic search, and more. The updated model import panel supports both Palantir-provided and custom-authored models. Typescript classes will be generated for all imported LLMs, providing an intuitive interface for using LLMs within user-authored functions.
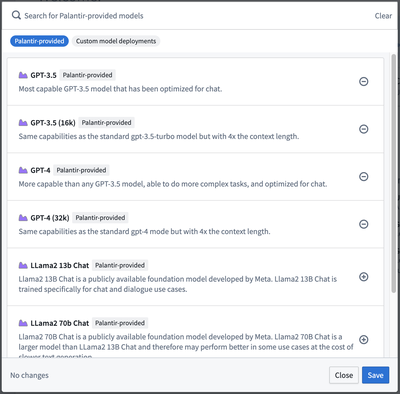
A sample of Palantir-provided LLMs - availability may differ between stacks
Example usage
For example, the following code demonstrates writing a custom Typescript function using the GPT_4 model to run a simple sentiment analysis on the provided text.
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13import { GPT_4 } from "@foundry/models-api/language-models"; @Function() public async sentimentAnalysis(userPrompt: string): Promise<string> { const systemPrompt = "Provide an estimation of the sentiment the text the user has provided. \ You may respond with either Good, Bad, or Uncertain. Only choose Good or Bad if you are overwhelmingly \ sure that the text is either good or bad. If the text is neutral, or you are unable to determine, choose Uncertain." const systemMessage = { role: "SYSTEM", content: systemPrompt }; const userMessage = { role: "USER", content: userPrompt }; const gptResponse = await GPT_4.createChatCompletion({messages: [systemMessage, userMessage], params: { temperature: 0.7 } }); return gptResponse.choices[0].message.content ?? "Uncertain"; }
For more information on usage and examples, review the documentation on Language models within Functions.
Text to Embeddings board in Pipeline Builder
Pipeline Builder now includes a powerful new Text to Embeddings board. Embeddings are dense vector representations of text designed to capture the semantic meaning of words or phrases from the text to be processed by LLMs. Embeddings convert text into a numerical form that can be processed by LLMs.
The numerical representation (embedding) allows for the comparison of textual data based on contextual similarity rather than just syntactic similarity. For instance, when comparing the words "cat," "dog," and "balloon," embeddings can help determine that "cat" and "dog" are more closely related in meaning than "cat" and "balloon", and use that understanding to drive advanced text analysis and operations.
Using embeddings in Pipeline Builder is particularly beneficial for workflows that involve semantic search as it allows LLMs to perform more effective, nuanced, and accurate searches by evaluating the vectors for similarity.
Example usage
This board takes a string column as input and will use the Palantir-provided text-embedding-ada-002 model to create an embedding vector.
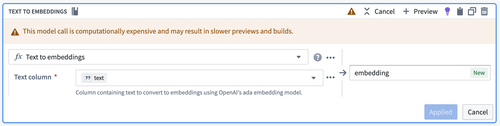
Text to Embeddings board configuration
These embeddings can then be added to the Ontology as an Embedded vector property and used downstream in LLM-powered workflows.
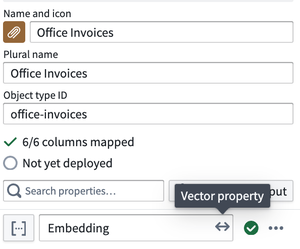
Using an embedding as part of your workflow
Learn more
To learn more about the features described above, review the following documentation:
- Manage AIP settings with Control Panel
- Learn how to use Language models within Python Transforms
- Learn how to use Language models within Functions
- Embeddings in Pipeline Builder
Additional highlights
Foundry Developer Console
Date published: 2023-12-12
Export OpenAPI Specifications in Developer Console | Users can now generate and export OpenAPI specifications for their Developer Console applications as YAML files. This feature can be accessed through the renamed SDK Generation tab, previously known as Version history.
Marketplace
Date published: 2023-12-12
Improved Product Image Alignment and Layout in Marketplace | The Marketplace product page now features improved alignment of product images and an enhanced layout.
App Building | Workshop
Date published: 2023-12-12
Faster Embedded Module Loading for Large Modules | This update significantly improves the load time of very large embedded modules in Workshop. Users working with large modules will experience load times up to 5 times faster.
Data Integration | Code Repositories
Date published: 2023-12-12
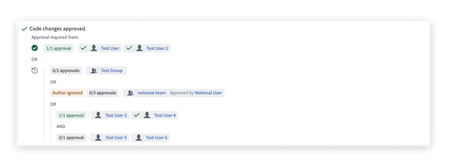
Advanced pull request approval policies | Introducing a granular, rule-based system for configuring pull request approvals. With advanced PR approval policies, it is now possible to specify which users or groups should approve a PR based on the files modified. The policy can be edited both in YAML and using the interactive approval policy editor.
Policies are then applied to newly created pull requests. Required approvers are displayed in a new user interface, showing which rules have been satisfied and how many approvals are still required.
To get started using this feature, create a protected branch and then edit the policy from the Branches tab of the settings pane in your Code Repository.
Marketplace
Date published: 2023-12-12
Marketplace Modeling Integration Now Generally Available | The Marketplace modeling integration is now generally available, enabling users to package containerized executables that encapsulate various functional logic, such as machine learning, forecasting, optimization, physical models, and business rules.
Administration | Control Panel
Date published: 2023-12-12
Enhanced Egress Policies for AWS Hosted Stacks | Users on AWS hosted stacks can now create egress policies to S3 buckets they own in the same region, providing more control over data access. Note that a future update will improve the user experience by providing clear feedback on policy eligibility based on the bucket's region.
Object Monitoring
Date published: 2023-12-12
Enhanced Automation View and Edit Modes | The Object Monitoring application now features an improved view mode selector in the automation header, providing users with more options to switch between automation edit and view modes. The execution mode selection has been made more visible, and automation condition icons have been consolidated for a better user experience.
Data Integration | Code Repositories
Date published: 2023-12-12
Spark Module Runtimes Upgrade to Spark 3.4 | Foundry's Spark module runtimes have been upgraded to Spark 3.4, providing users with the latest performance and security enhancements. This upgrade applies to all modules greater than the following versions: Python 1.975.0, Java 1.997.0, and SQL 1.861.0. No action is required from users, as modules will be upgraded automatically.
Foundry Developer Console
Date published: 2023-12-12
API Token Creation in Developer Console | Users can now generate long-lived API tokens with restricted capabilities in Developer Console for personal use and CI/CD workflows. The initial capability allows installing SDKs with a scope of artifacts on both the SDK artifacts repository and the Foundry SDK asset bundle. Access the Create API Token dialog in the Application SDK settings pages or through the getting started instructions.
Object Monitoring
Date published: 2023-12-12
Enhanced Object Monitoring Features | This update brings several enhancements to the Object Monitoring application. Users can now view failure events from the last 28 days on the landing page, providing better visibility into recent issues. Additionally, more options for deleting automations have been added, making it easier to manage and maintain your workflows. The Actions menu has been reorganized, moving automation options to a separate menu for easier access. Lastly, evaluation latency information has been improved, with clearer wording and added hints for time condition combinations on objects added and removed.
Security | Projects
Date published: 2023-12-05
Enhanced Project Contact Selection | Users and groups without contact details can now be added as project contacts, improving flexibility in project management. The updated interface displays the appropriate UI for users without an email address and groups without contact details.
App Building | Workshop
Date published: 2023-12-05
New PDF Viewer Widget with Keyword Search | Workshop's PDF Viewer widget is now generally available, featuring keyword search capabilities with text highlighting and auto-scroll on match. This enhancement improves PDF workflows through manual or variable-based inputs.
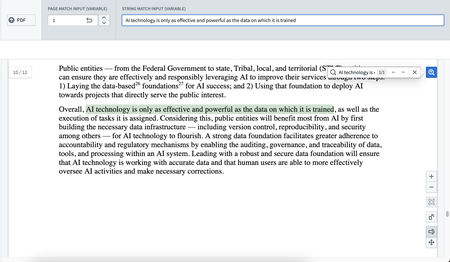
Administration | Control Panel
Date published: 2023-12-05
Expose Cloud Runtime Egress IPs in Control Panel | Users can now access cloud runtime egress IP addresses directly in the Control Panel, making it easier to set up ingress filtering for APIs and cloud sources. This update provides a more contextual and convenient way for users to obtain the necessary IP addresses for their cloud runtimes.
Security | Projects
Date published: 2023-12-05
Support for Vertex and Vortex Ontological Dependencies | Projects now support Vertex and Vortex Ontological dependencies, enhancing the Ontology access checker capabilities for more efficient and accurate Ontology management.
Data Integration | Code Repositories
Date published: 2023-12-05
Attachments as Function Inputs in Code Repositories | Users can now upload attachments for use as function inputs in Code Repositories, providing a more seamless workflow for using attachments in both Live Preview and published functions. To get started, add a function with an Attachment or Attachment[] input type and open the Live Preview tab to upload your attachments. You can review the documentation on input and output types available when using functions.
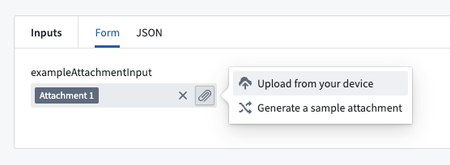
Ontology | Ontology Management
Date published: 2023-12-05
Action Log Requiredness Toggle for Ontology Management | Introducing a new Requires action log toggle in Ontology Manager. When enabled, any action that edits the specified object type will require an action log rule, ensuring that all edits to objects of that type are logged for greater visibility and traceability.