- Capabilities
- Getting started
- Architecture center
- Platform updates
Announcements
Python version deprecation
Date published: 2023-07-27
Python 3.6 and 3.7 are being deprecated in Foundry, following the open-source python EOL timelines. Automatic upgrades will be attempted in code repositories, manual action is needed on code workbooks and with older foundry_ml models. Starting from Python 3.8, upstream EOL deprecation timelines will be followed tightly.
Review the Python versions section in the documentation to see which versions are supported and their respective deprecation timeline. We suggest you always maintain your resources on the latest supported version.
Why are Python 3.6 and 3.7 being deprecated?
Open source Python marks old Python versions as End-of-Life (EOL) every year ↗ and drops official support. Python 3.6 and 3.7 are already past their EOL and continued use of EOL Python versions exposes security risks, with the additional following considerations:
- Core packages such as PySpark are hard deprecating older python versions (for example, Python 3.6 and 3.7 deprecation in Spark) and we are not able to deliver runtime improvements nor bug fixes to Python jobs using deprecated Python versions.
- Open source libraries continue to create new releases which are no longer compatible with these deprecated Python releases and causes failing checks and jobs.
What does deprecation mean for me as a user?
If you own resources using a deprecated Python version, you will not be able to develop on those according to the timeline below:
- January 31, 2024
- If any of your workflow is depending on deprecated Python versions, some workflows will not be supported anymore and you will receive no support in case of failures. A limited set of resources can be allowlisted for extended support if agreed with Palantir in advance
- April 1, 2024
- All workflows relying on Python 3.6 and 3.7 will not be supported anymore and will start failing.
Foundry resource migration to supported Python versions
Foundry resource migration will follow the patterns below:
- Code repositories: An automatic upgrade will be attempted in the form of an automatic patch PR.
- Other resources: Informational banners containing instructions and links to support you in moving away from the deprecated Python versions will be displayed. Review the troubleshooting guide for more information.
Currently, the latest version supported in platform is Python 3.10.. Python 3.8. and 3.9.* are also accepted, though they will be deprecated sooner than 3.10.*
Future Python version deprecation
Starting from Python 3.8, Foundry will tightly follow the upstream end-of-life timelines and will deprecate Python versions in Foundry as soon as they reach upstream end-of-life. For more information, see Python versions in the documentation.
Introducing Python support available in Ontology SDK [Beta]
Date published: 2023-07-27
Foundry support for Python in the Ontology SDK and Developer Console is now in beta. This release enables developers to generate Python packages with the desired object types, action types and links, install the package using either conda or pip, and analyze the results in Jupyter® notebooks or any other IDE.
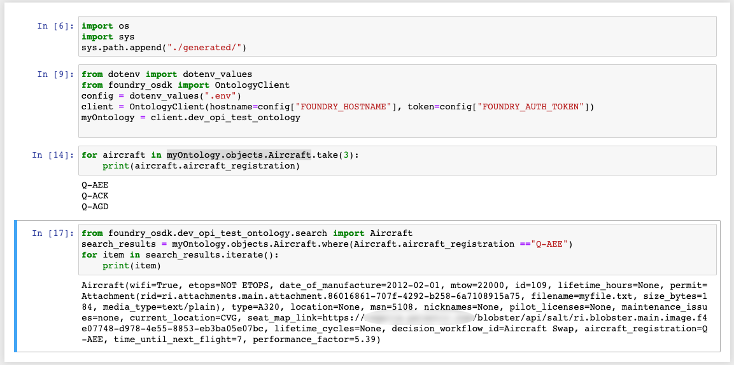
Once the command line package is installed, you can use it to generate the SDK, import the SDK to your Python environment, and begin iterating through objects, searching for specific objects, and applying actions to edit your objects.
How can I try this out?
Each application in Developer Console contains a toggle between the different package managers supported. Use the Install SDK tab on the Application SDK page to toggle between npm installation instructions for TypeScript, or pip and Conda installation instructions for Python.
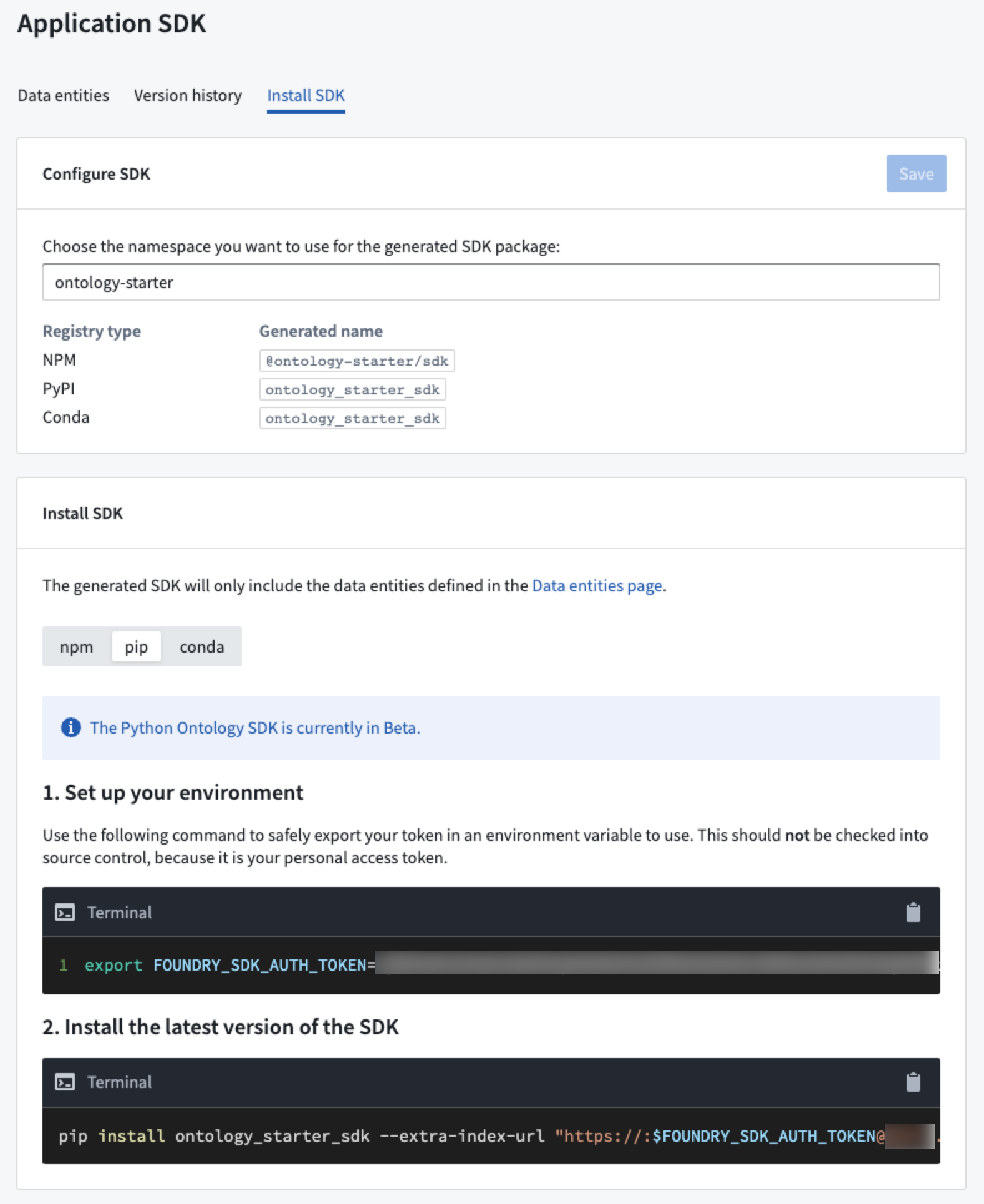
Once installed, start your Python IDE (such as Jupyter®) and import the generated package to begin working with Ontology object types and action types.
For more information, review the Use Jupyter® with OSDK documentation.
What if I need to generate the Python package myself?
In case the platform cannot generate the package for you, you will be presented with instructions on how to generate the package using the command line interface (CLI) tool.
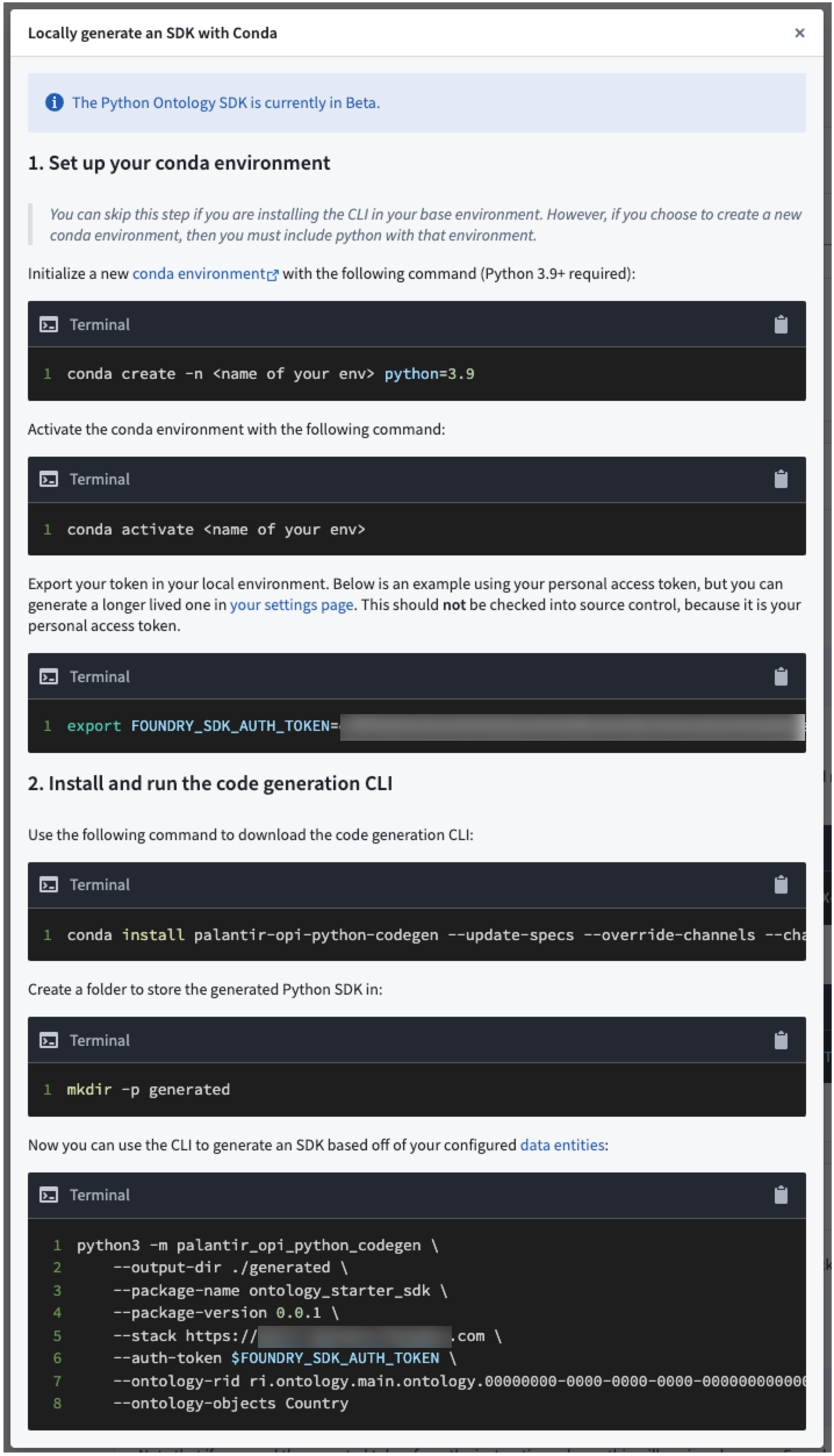
Jupyter® is a registered trademark of NumFOCUS.
Introducing Timeline in Vertex and Map [GA]
Date published: 2023-07-27
Timeline, a feature in Vertex and Map that enables users to inspect the time properties of selected objects and filter to specific events in a given time range is now generally available. Use the Timeline button located next to the zoom selectors to open a Timeline panel that shows object events on the current Vertex graph or map.
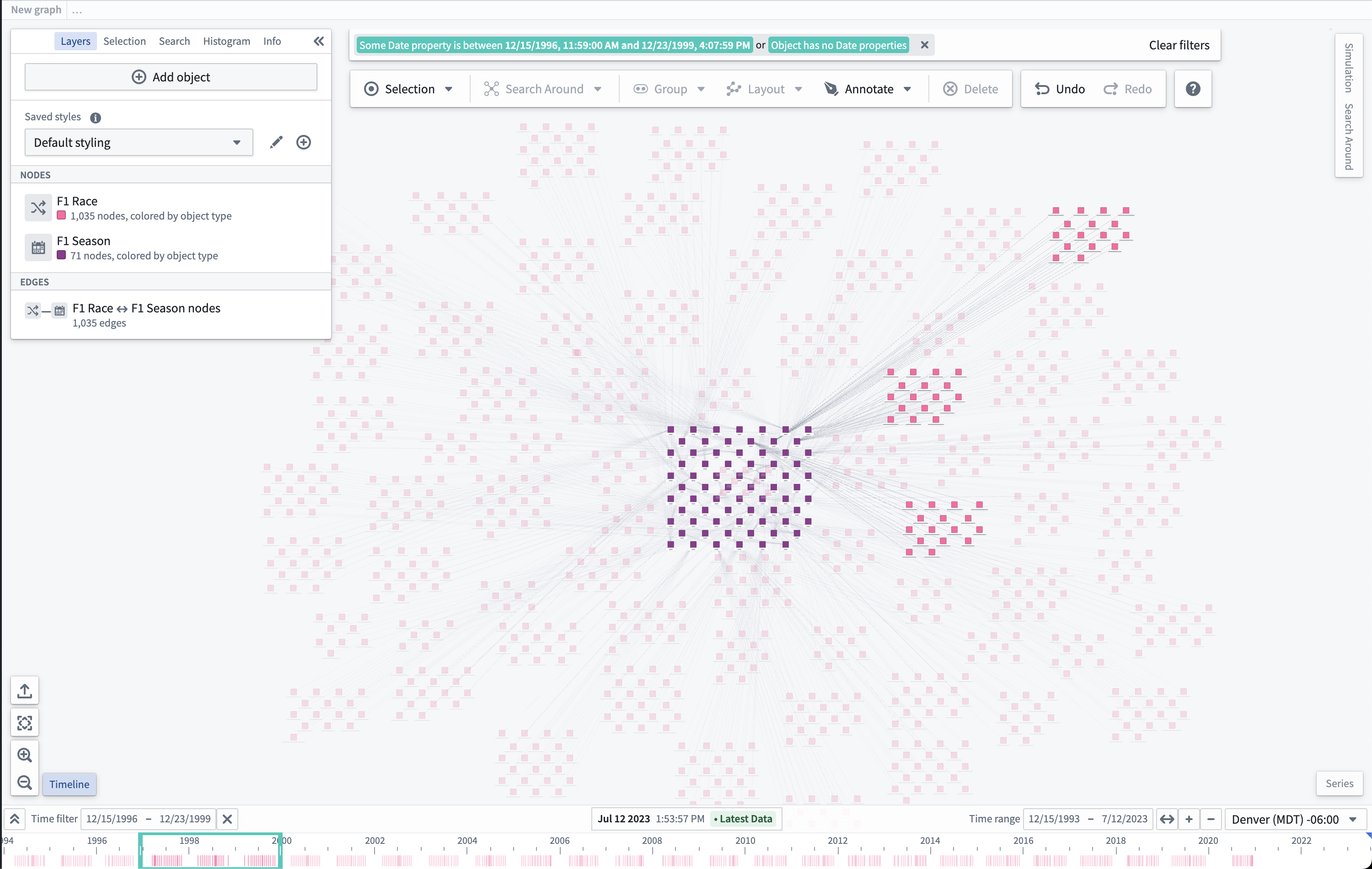
Enable Timeline in Workshop
If you would like the timeline to show up in your Workshop Graph or Map widget, navigate to the Interface section of the configuration for either widgets and toggle Enable Timeline.
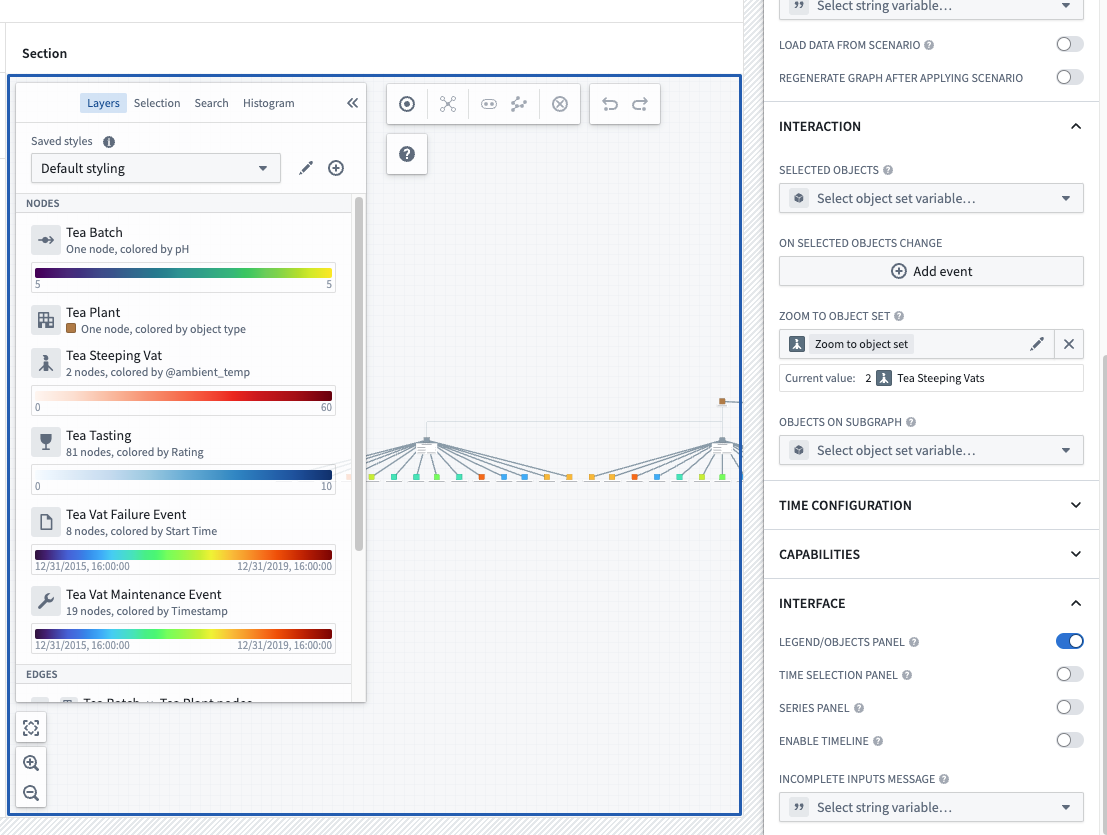
If you were previously using the beta version of Timeline, this option defaults to off and is required to be enabled in each module that you would like the timeline to be available for use.
Deprecation slated for Time selection Panel
As Timeline is now GA, Foundry Map's existing time selection panel functionality is slated for deprecation by Monday, August 21, 2023.
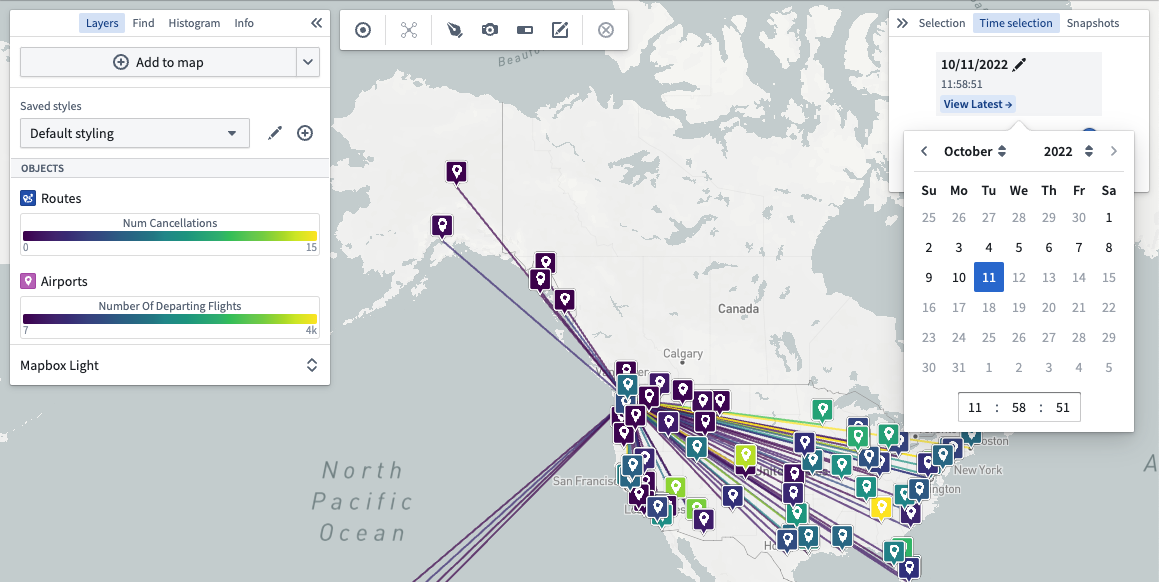
While there is no change to current functionality to prevent disruption to existing time workflows, we do ask that all instances switch over to the Timeline functionality prior to that date. Contact Palantir support if you have any questions or concerns about this update.
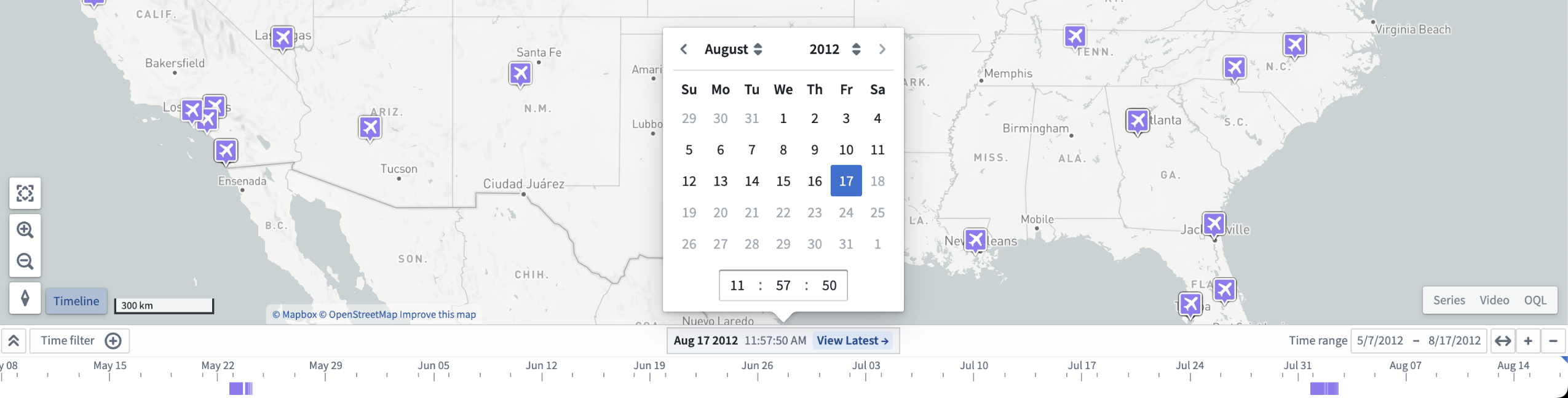
Note that this feature will remain available in Vertex while additional time comparison and modeling features are in development for Timeline.
What's on the development roadmap?
We are planning to enable the ability to collapse or expand the timeline by default on load.
For more information on Timeline and how it can be used, review the documentation for Vertex Timeline or Map Timeline.
Introducing Foundry models in Functions on objects [GA]
Date published: 2023-07-20
You now have the ability to invoke models (served via FoundryML live deployments) from within Functions on objects, increasing the surface area of how models can be executed in the context of the Ontology, used in Workshop and elsewhere in Palantir Foundry. Functions on models can be consumed wherever normal functions are used.
What you can now do
- Complex Ontology mapping: With the power of functions, users can now set links, create objects, and even relax the 1:1 constraint of model inputs to outputs that exists in the Objective binding UI.
- Models as Actions: Actions that are backed by an 'OntologyEditFunction' can now call into models. Those Actions can either be applied to the master Ontology directly or be applied on a Scenario and then be merged back.
- Models as basic functions: Models that do not affect the Ontology, but rather drive visualizations directly, can now be easily integrated into Functions on objects that return Workshop-specific datatypes. This capability speeds up performance and avoids unnecessary setup involving Scenarios.
- Last minute feature engineering: Functions can perform object searches and aggregations that allows feature crafting prior to reaching the model.
Requirements
To enable this workflow, you must first configure an API name for your FoundryML live deployment from its configuration page and meet the following requirements:
-
Minimum Apollo product versions:
- functions-typescript-asset-bundle: >= 0.442.0
- functions-parent-template-bundle: >= 3.5.0
-
Minimum gradle.properties versions:
- functionsTypescriptVersion >= 0.442.0
- functionsVersion: >= 3.5.0
How Functions on models work
The workflow begins with a model saved in Foundry. The user will submit it to a modeling objective, and deploy it via Foundry ML Live.
Function repositories have a new option to import Foundry ML Live deployments, similar to the Ontology import dialog. This registers the model deployment and allows Code Assist to auto-generate typescript bindings for the imported Foundry ML Live deployments, which can be imported using the deployment's API name.
The interface provided in code contains a transform() method that calls into Foundry ML Live. Modeling functions can leverage the new Model Asset primitive to provide a typed transform() reflecting the model input and output. See below for the intended import workflow and example code:
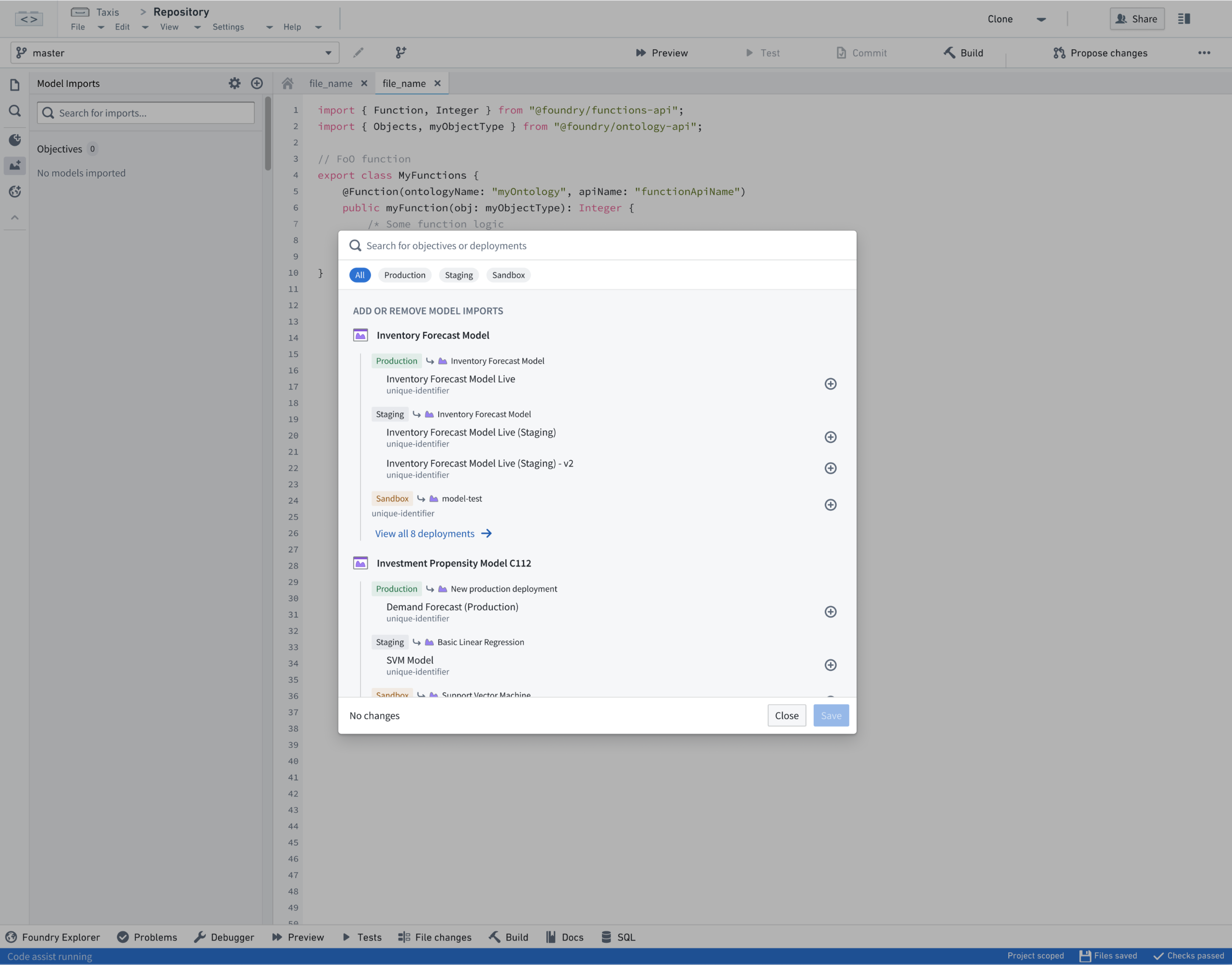
Import dialog for FoundryML live deployments
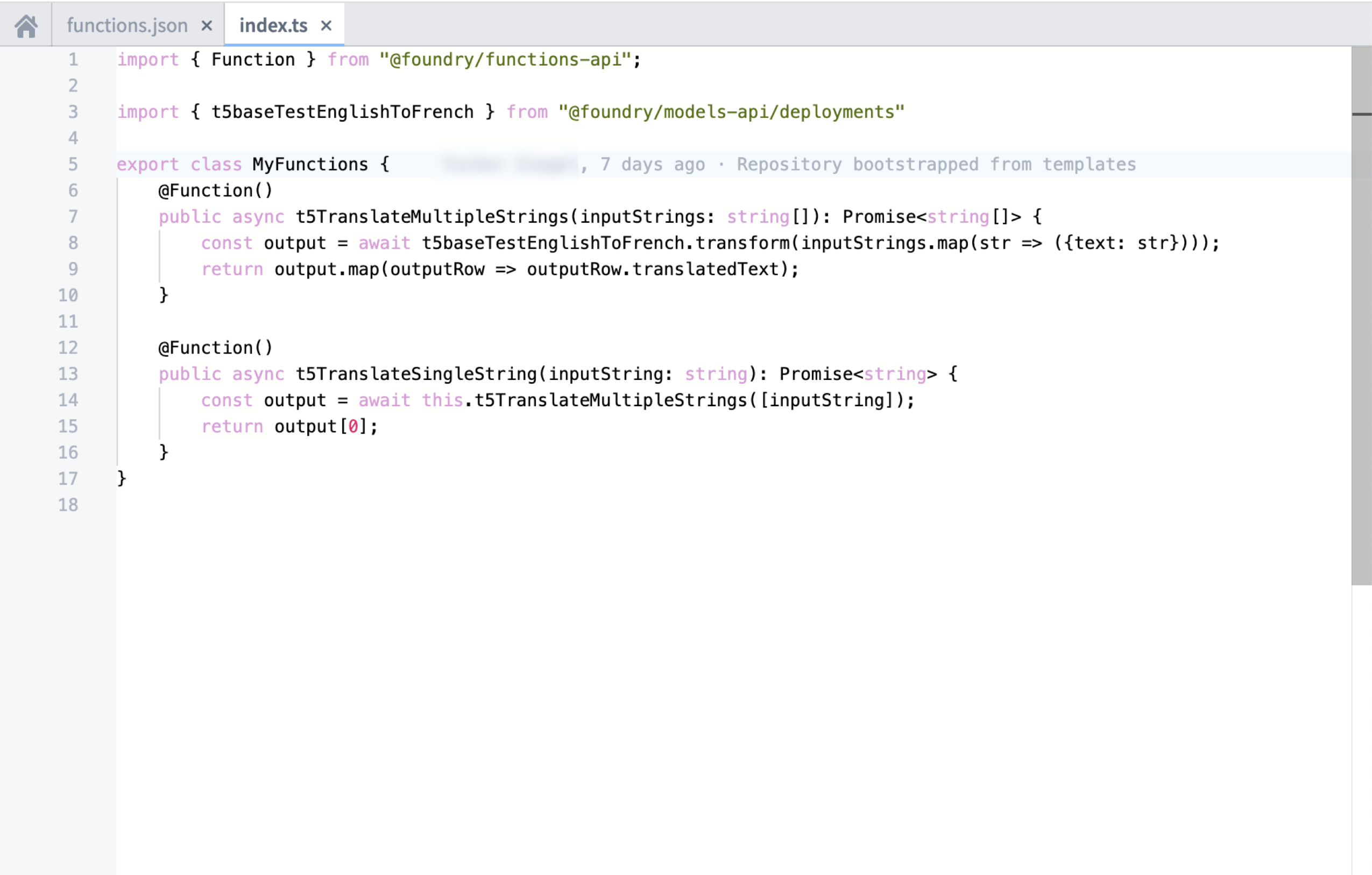
Functions on models example code
What if I am already using Functions on models?
For those already using Functions on models, this GA contains breaking changes, should you choose to upgrade your repository. We encourage all users to migrate old repositories, which is a fairly simple process:
- Define an API name for your ML Live deployment
- Create a new branch in your Functions repository
- Upgrade
functionsVersionandfunctionsTypescriptVersionto the versions listed above - Set
useDeploymentApiNamesto true infunctions.json - Modify all imports from
import { riSanitizedRid } from "@foundry/models-api"toimport { MyDeploymentApiName} from "@foundry/models-api/deployments" - Verify codegen works in the new branch, then submit a pull request to merge back into the main branch
Learn more about Functions on models in the documentation.
Introducing Resource Management data export feature
Date published: 2023-07-20
Resource Management administrators can now export resource management data to a Foundry dataset from Control Panel, enabling the custom investigation and analysis of usage data in Foundry tools such as Contour.
To export your data from Control Panel, navigate to Internal dataset export and export your granular usage data to a new dataset. Once this dataset has been exported, it will remain up to date with the upstream datasource. As with audit logs, once the sensitive dataset has been exported, ensure that you appropriately permission the respective dataset.
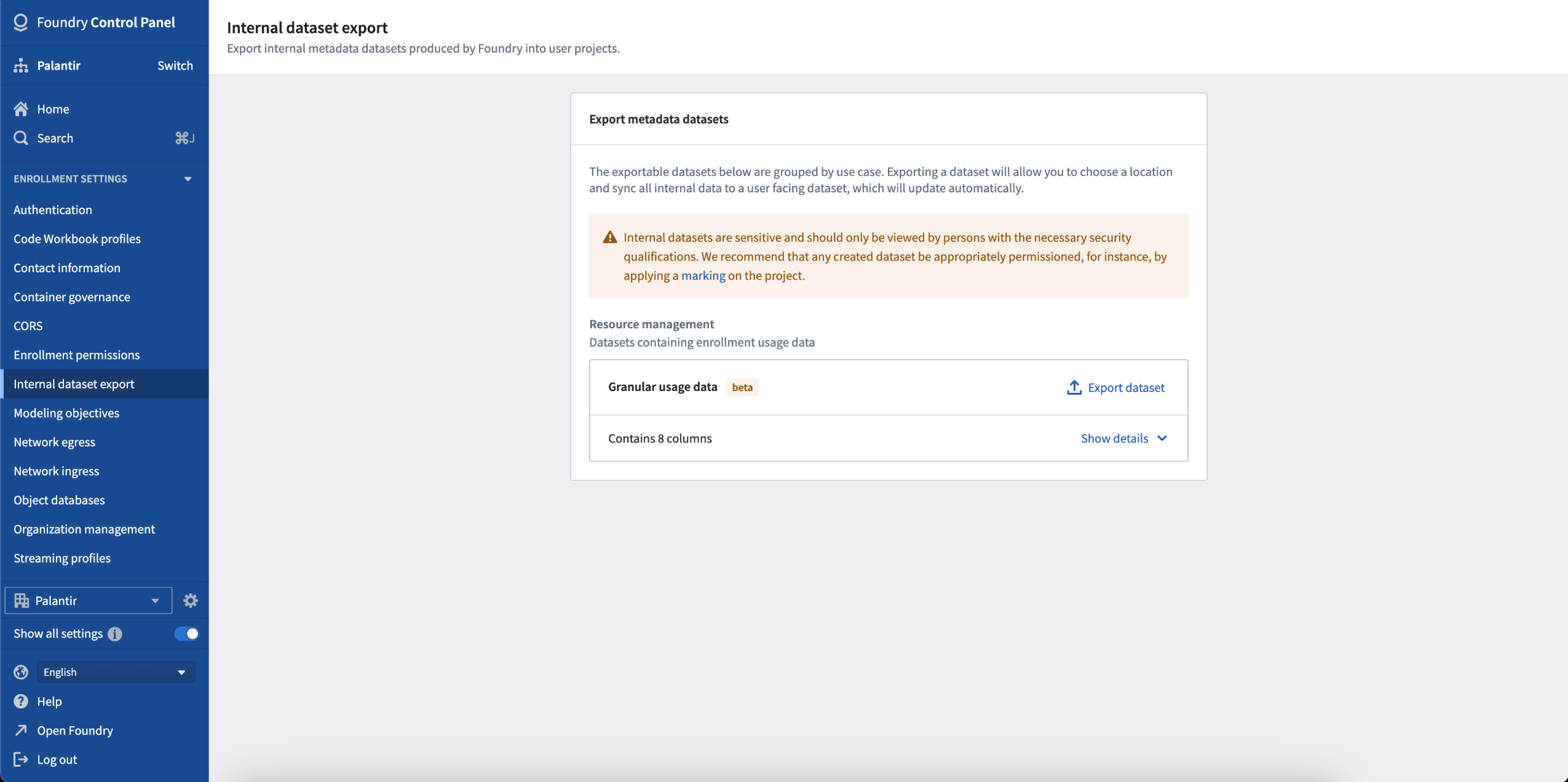
Navigate to Internal dataset export to export resource management data from Control Panel.
The schema of the RMA data is as follows:
enrollment: The enrollment from which the usage data is being exported. This column will contain a single enrollment RID.invoiced_dimension: The invoiced dimension that this row of usage belongs to as set out in the enrollment’s contract.source: The source to which a specific row of usage belongs.summary_resource_rid: The parent of the granular usage. For datasets, this is the Project where the dataset is saved; for Ontology objects, this is the Ontology RID.granular_resource_rid: The resource to which this usage belongs.date: The date on which this usage was consumed.usage: The amount of usage consumed.usage_unit: The unit of usage. For storage, this is GB-months. For compute, this is compute-seconds.
For more information, see the Internal dataset export documentation.
Introducing container-backed models [GA]
Date published: 2023-07-18
The introduction of container-backed models allows you to configure models backed by container images, significantly expanding the range of models that can be used for batch or real-time inference within Foundry. You now have the ability to package arbitrary execution logic into a container image and use that model in Foundry for evaluation, inference, and integration with operational applications. Container-backed Model Assets are particularly useful for large, pre-trained models, models written in languages not natively supported by Foundry Models (such as R), or models that are already containerized for other purposes.
Key features of container-backed models
- Flexibility: Containers can be configured to support a wide range of machine learning frameworks, custom code, and languages.
- Modeling Versioning: Container-backed models can be packaged into Model Versions allowing independent evaluation, review, and release of models in Foundry.
- GPU Support: Container-backed models can be configured to execute with access to a range of GPUs in Foundry for inference and execution.
- Media: Container-backed models have access to tabular and media data, providing the ability to configure computer vision, audio and video workflows natively in Foundry.
How to configure a container-backed model
- Enable container workflows in Control Panel.
- Create a Model Asset and push your container images to it.
- Author a model adapter to interact with your container.
- Configure the model version with the container images and model adapter.
- Deploy your container-backed model and integrate it with operational applications.
For more information on container-backed models, including detailed instructions on how to create, deploy, and manage them, refer to our documentation.
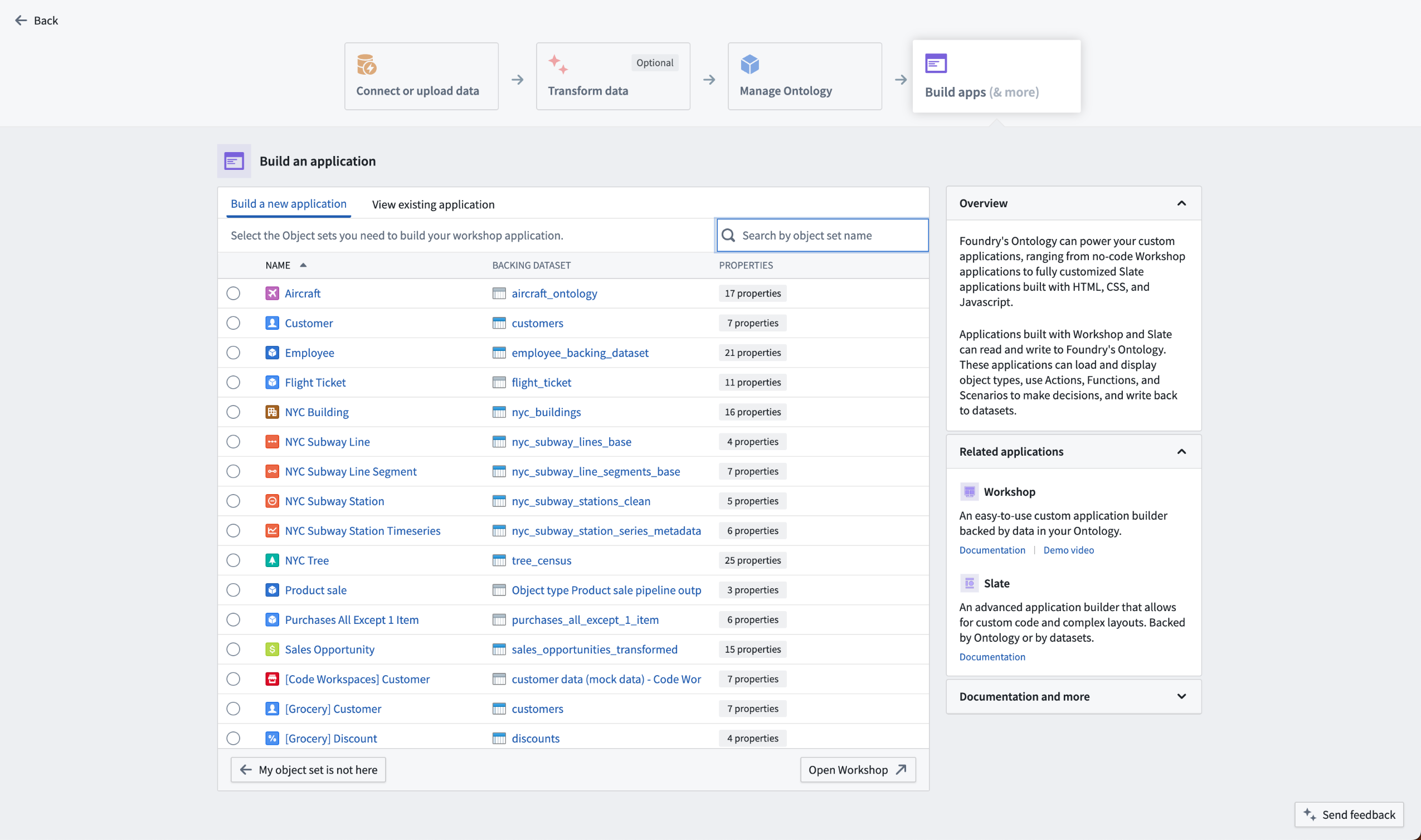
Introducing Home app [GA]
Date published: 2023-07-18
The Home app is a new default Foundry workspace home page designed specifically for new application builders that features a guided experience to facilitate familiarization with completing core workflows and streamline the onboarding process.
Home app's functionalities help you:
- Showcase the variety of workflows users can accomplish within Foundry
- Provide a single access point to resources, apps, and documentation needed for core workflows, making it easier for new developers to become productive
- Enable users to select a workflow goal, allowing for a tailored and goal-oriented initial Foundry experience
- Recommend efficient starting points based on the user's stack and the available Foundry applications and resources
- Offer users a clear understanding of how the Ontology, datasets, and various Foundry applications fit within the ecosystem
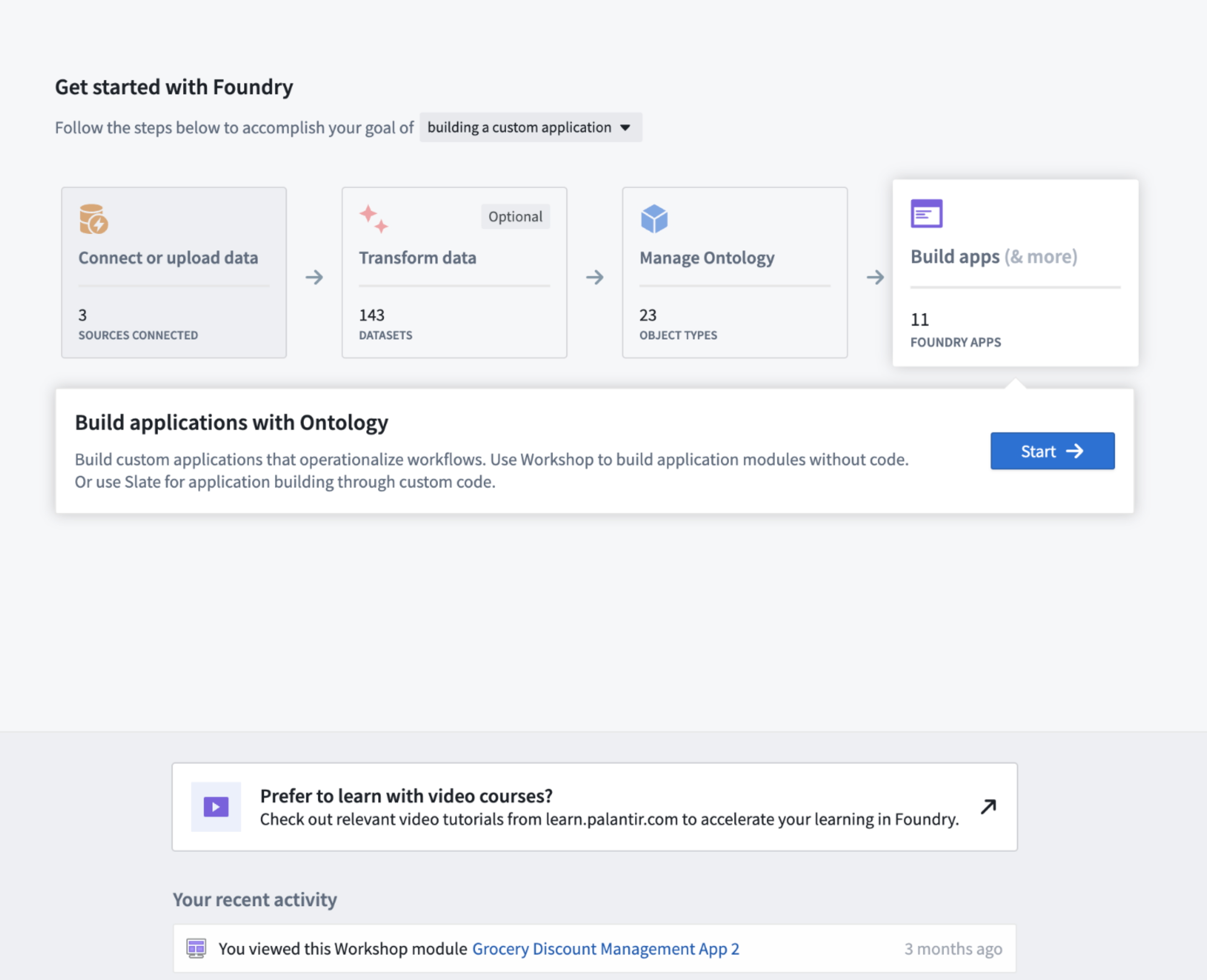
Set Home app as your default home page
Home app is automatically installed on all instances and will be implemented in both existing and new accounts. To set Home app as your stack's default home page, access the home URL setting in Control Panel and select /narrative as the home page for all users or specific user groups. To view Home app on your stack, visit /workspace/narrative.
Learn more in the platform experience settings documentation.
Foundry Quicksearch enabled by default
Date published: 2023-07-18
Foundry Quicksearch is now enabled by default for all users, providing a faster and more intuitive search experience. Users can temporarily switch back to the legacy Foundry Search using the "turn off" button in the UI until the end of July, after which Quicksearch will become the only option and the legacy search button will be removed. Review the Quicksearch documentation and the Quicksearch GA announcement for more details.
Introducing updated workflows and UI for time series
Date published: 2023-07-18
The time series setup workflow in Foundry spans multiple stages to transform data into the correct shape, build a robust Ontology to enrich analysis, and create analytics and operational applications to make business-critical decisions. The time series setup process now has walkthroughs and updated user interfaces to make it more accessible to new and existing users in Foundry.
Walkthroughs for the exploration of time series workflows
New walkthroughs are now available in Dataset Preview, Ontology Manager, and Pipeline Builder. These useful guides introduce concepts and workflows that you can review to learn more about using time series data in Foundry.
In Dataset Preview, you can choose to Analyze data from a stream or batch dataset and open a walkthrough to learn about key concepts and setup requirements for the time series workflow.
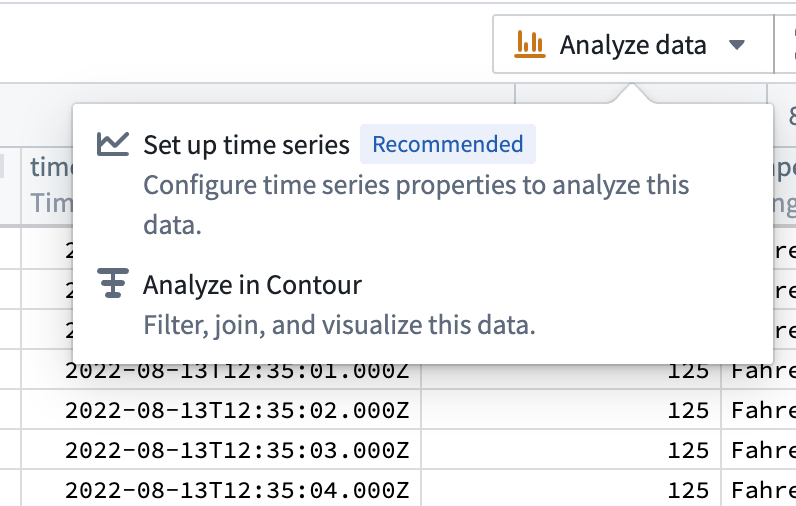
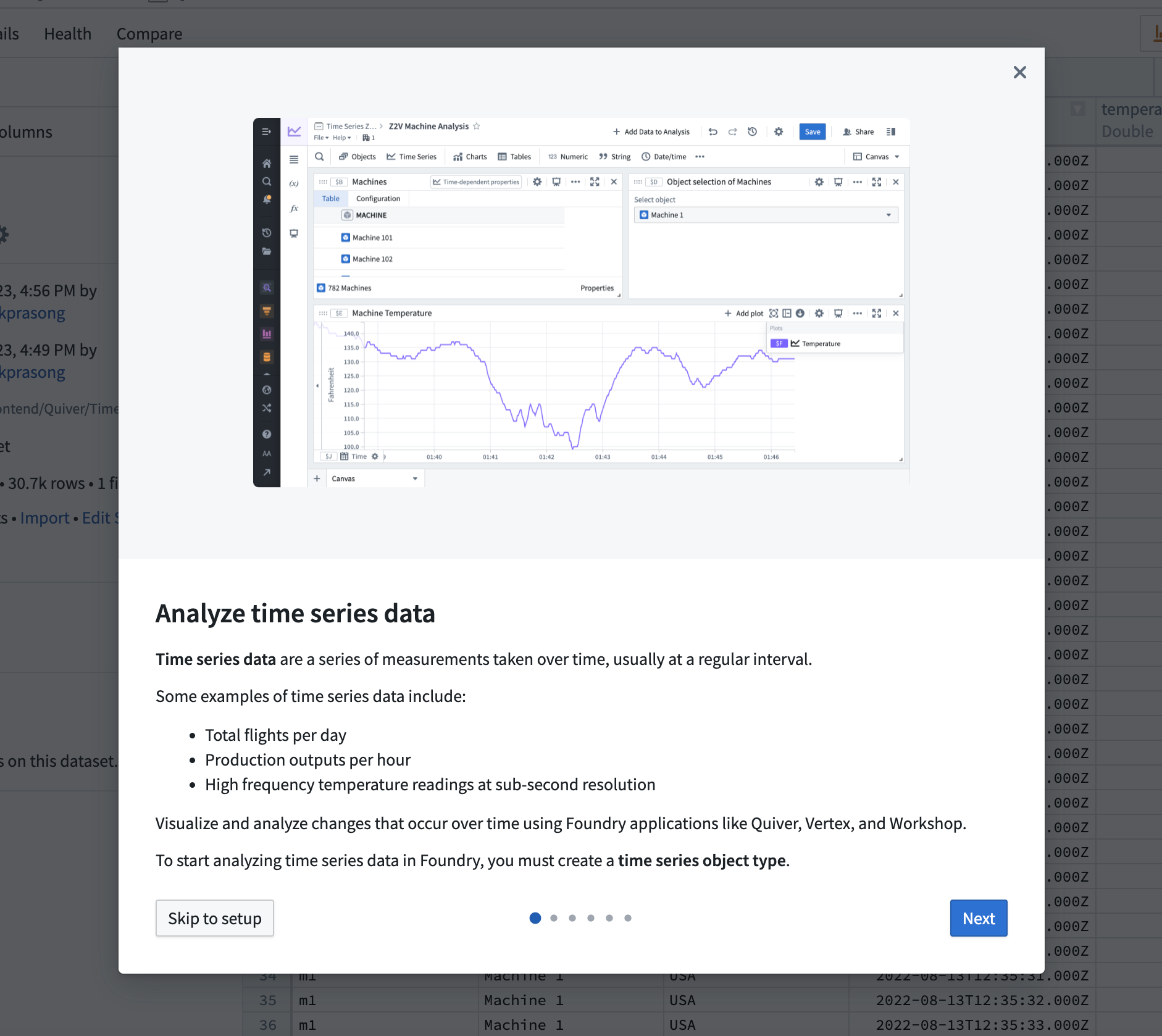
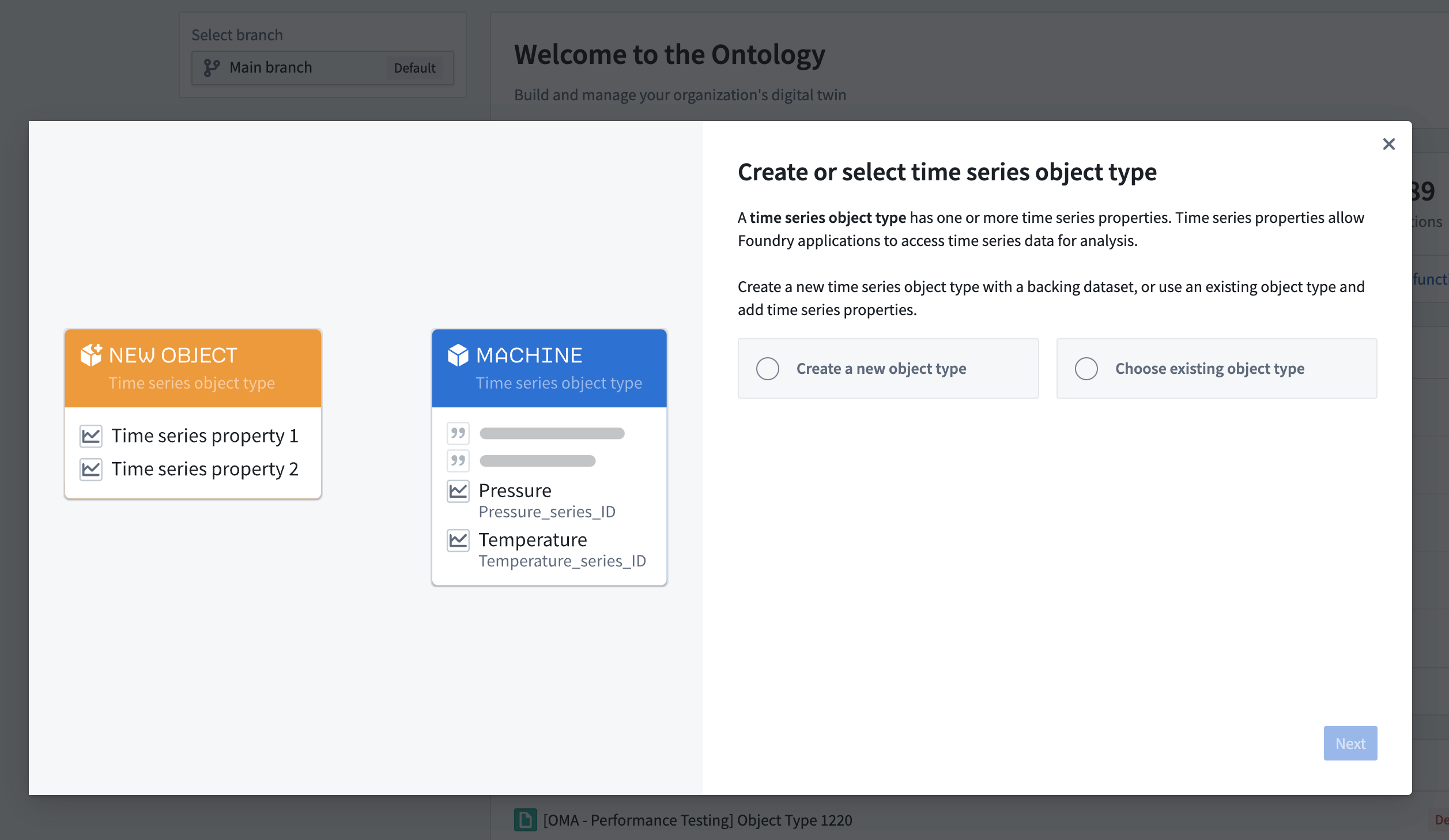
In Ontology Manager, new walkthroughs help you create or select a time series object type and complete the setup of time series properties. These walkthroughs include visual examples representing the architecture and usage of time series data in Foundry.
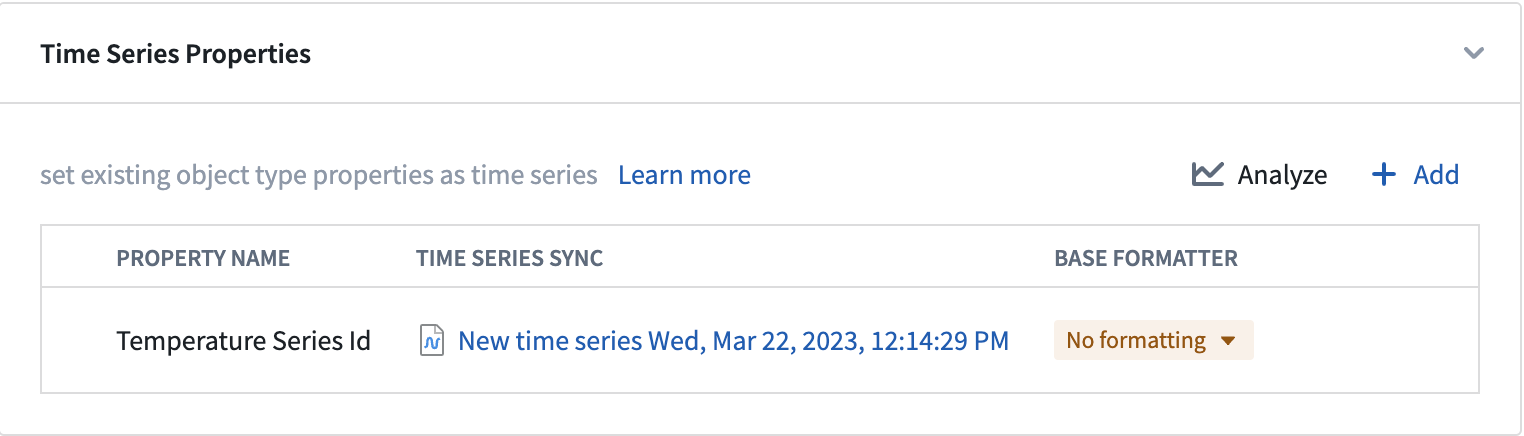
Improved interfaces for time series management
An updated user interface in Ontology Manager allows you to create and manage time series properties directly from the Capabilities tab. From here, you can link time series syncs from existing pipelines or build new pipelines to create time series syncs.
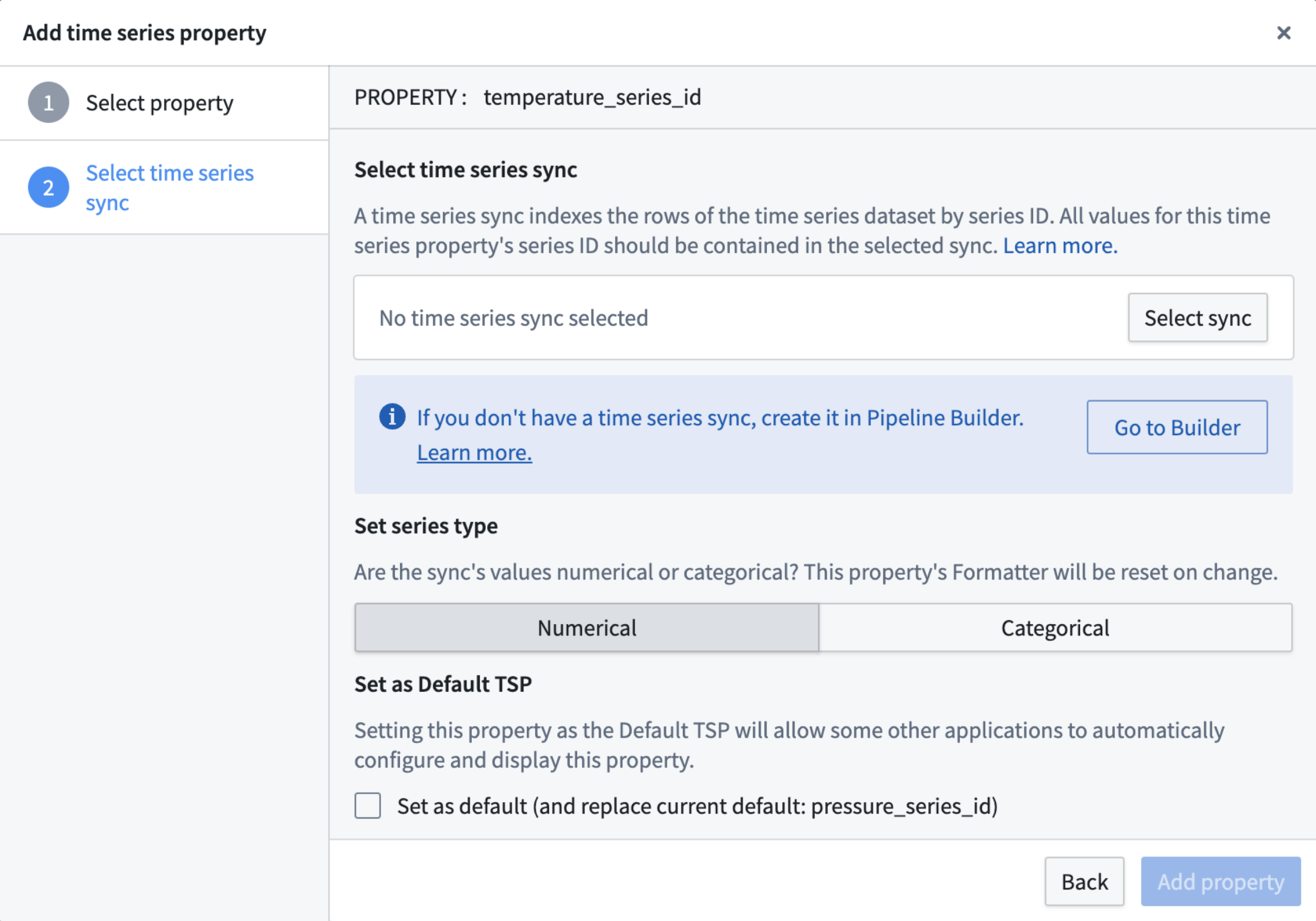
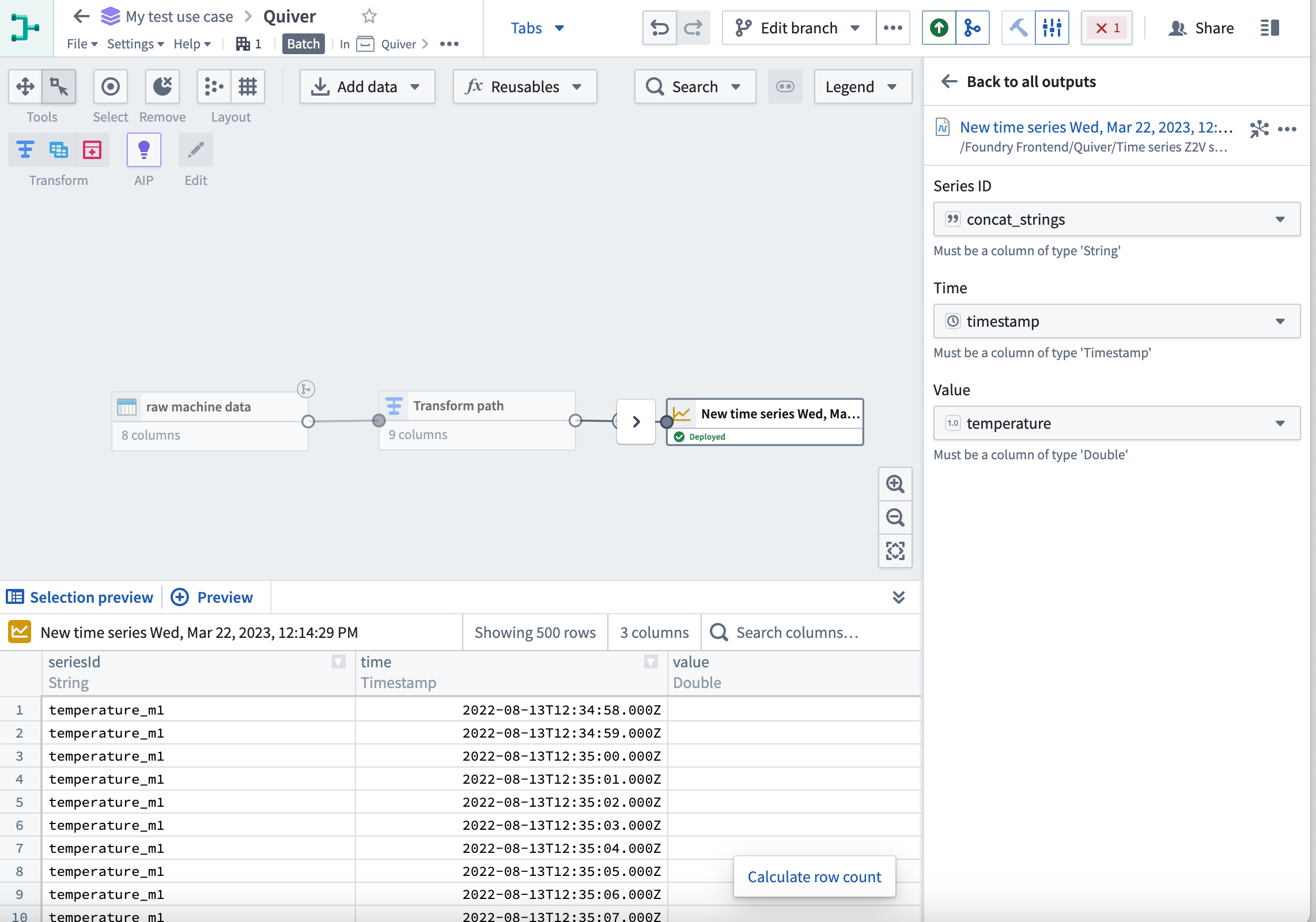
Additionally, Pipeline Builder now fully supports creating time series outputs from streaming or batch time series data. Learn more about Pipeline Builder outputs.
Learn more about the updated workflows and new features by navigating to the time series documentation. Updates have been made to key concepts and the end-to-end setup process, from data to analysis.
What's on the development roadmap?
As part of our goal to make Palantir’s time series product an industry leader in manufacturing, automation, and process management, we continue to invest in key areas that make the journey intuitive and effortless. The following features are currently in development:
- Enhance time series workflows with derived and categorical time series: Authored and maintained in platform.
- Generate derived series: Use Quiver's visual functions UI to create derived time series. Interact with derived and non-derived time series in the same way – from applications like Quiver, Workshop, and Vertex.
- Create categorical time series: Visualize categorical time series properties across platform in Workshop, Object Explorer, and Quiver with an immediate focus on adding support in Workshop for categorical time series in metric cards and object tables.
- Measures concepts revamp: The measures concepts will only be an Ontology setup distinction, by delivering a unified experience for end-users accessing time series properties regardless of whether they are directly on the root object type or on linked sensor objects (for example, via Measures) in analytical and operational applications.
Introducing object-backed map layers [Beta]
Date published: 2023-07-12
The Map layer editor now allows you to configure a map layer by selecting an object type. These object layers can handle extremely high-scale object data by leveraging new backend capabilities to generate tiles directly from data stored in the Ontology.
Previously, accomplishing similar workflows required significant manual configuration to ensure the Ontology remained in sync with an additional, separate service. The new object layers dramatically reduce the effort required to create and style layers backed by data in the Ontology.
This following image demonstrates the complete process to create a layer that can visualize over 1 million objects in realtime:
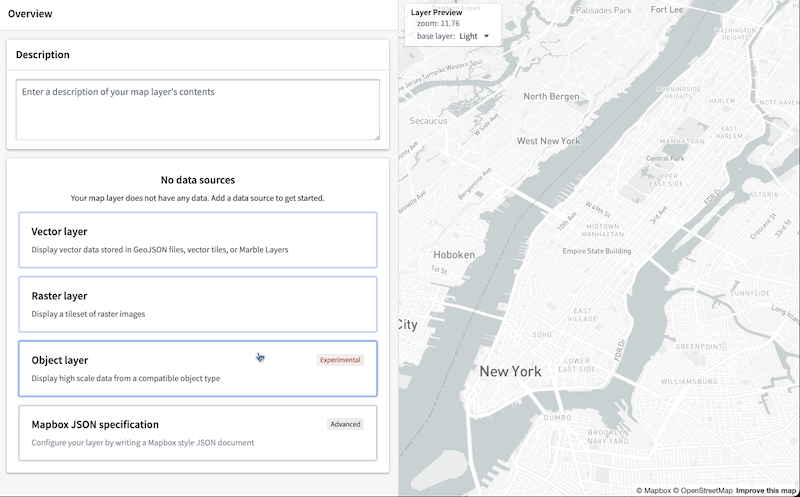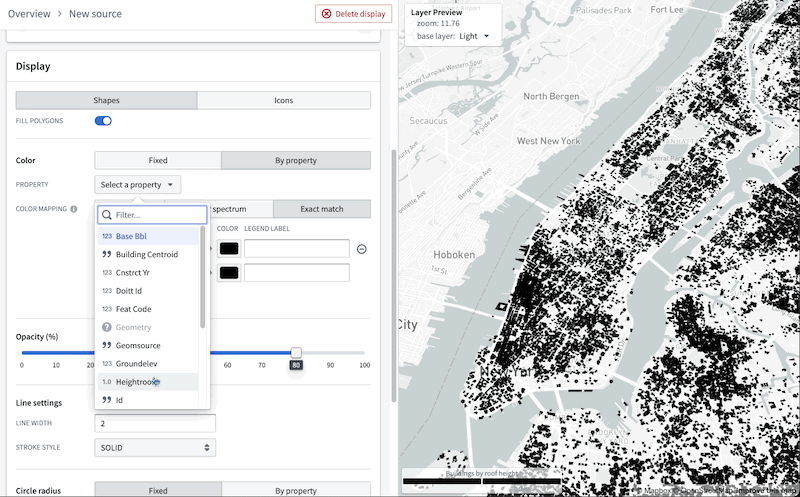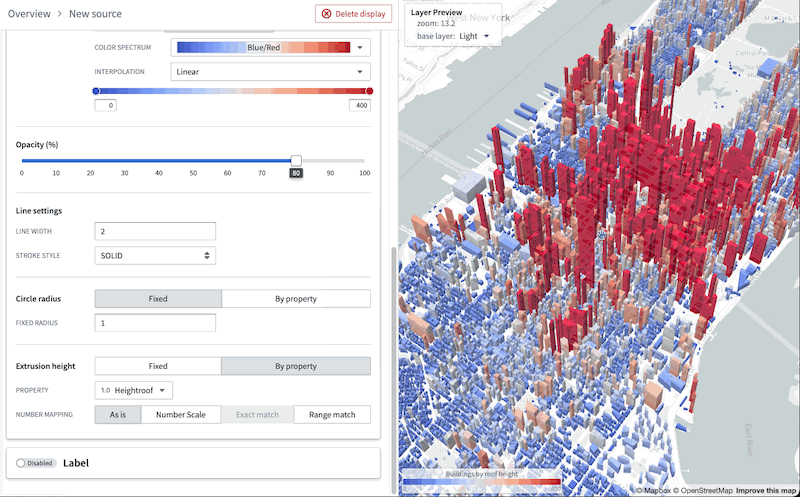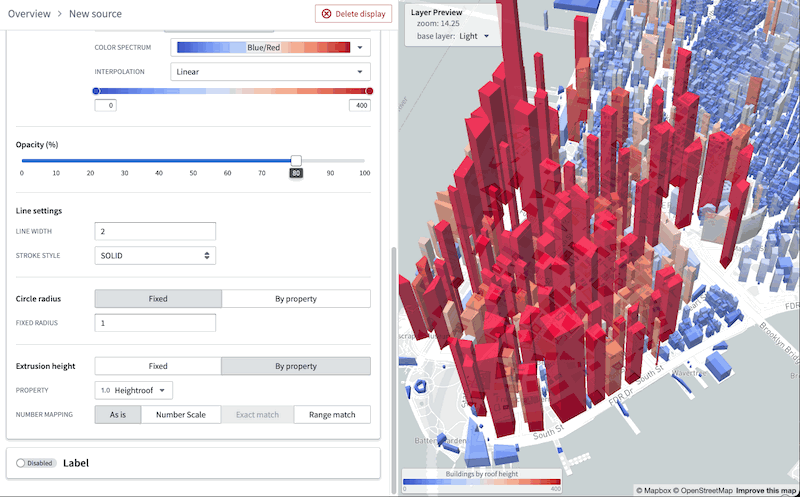
Additionally, you can benefit from the map layer editor's enhanced user interface to easily validate the type of each column in the object-backed layer and configure the appearance, bypassing the burden of manually writing a JSON style specification.
Note that this new capability requires OQL, which is not available on all instances. Contact your Palantir representative for more information.
Announcing new visual depth style features in Workshop
Date published: 2023-07-12
Workshop now offers more control over various style formatting settings to give application builders additional customizability to the design and feel of a module. Configuration options include header formatting, background colors, border styles, and more, available at the page, section and widget levels.
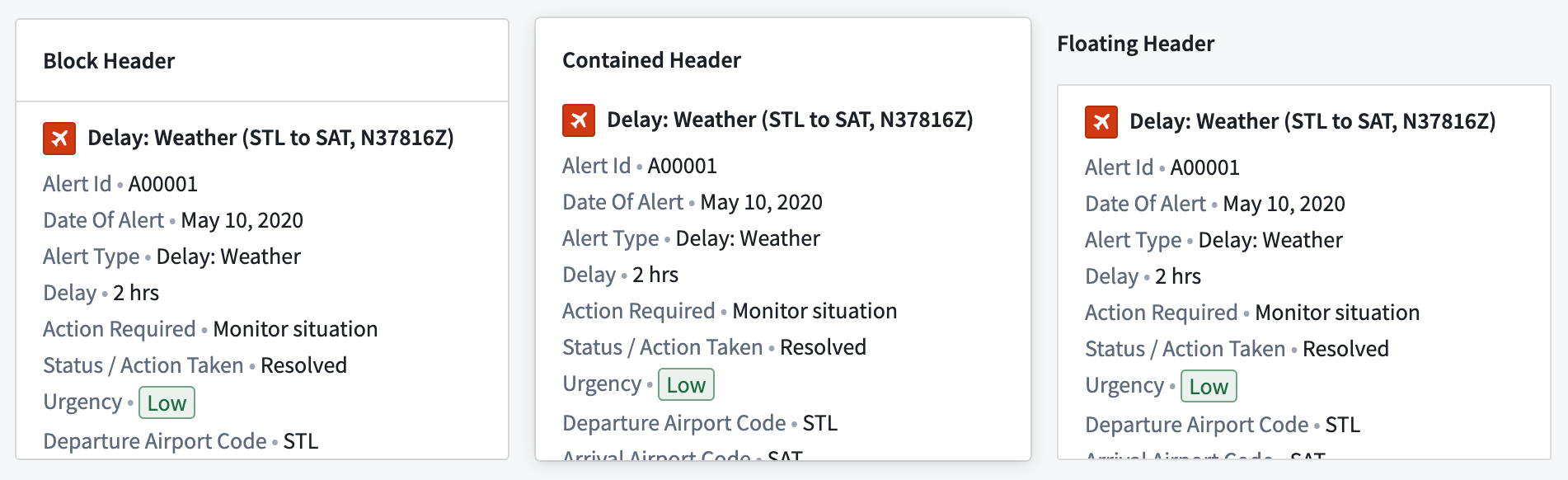
Header formatting
Header formatting options can be added when the header is enabled on a section.
Background colors
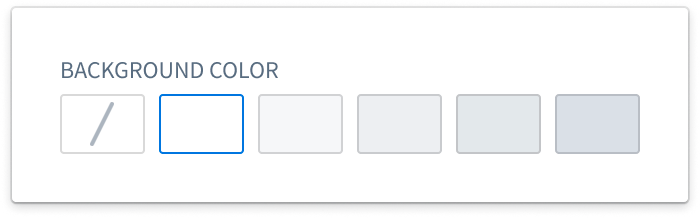
Background colors can be added to pages, sections, and widgets to help visually segment parts of a module. There are five shades available for both light mode and dark mode, and a transparent option.
Border styles
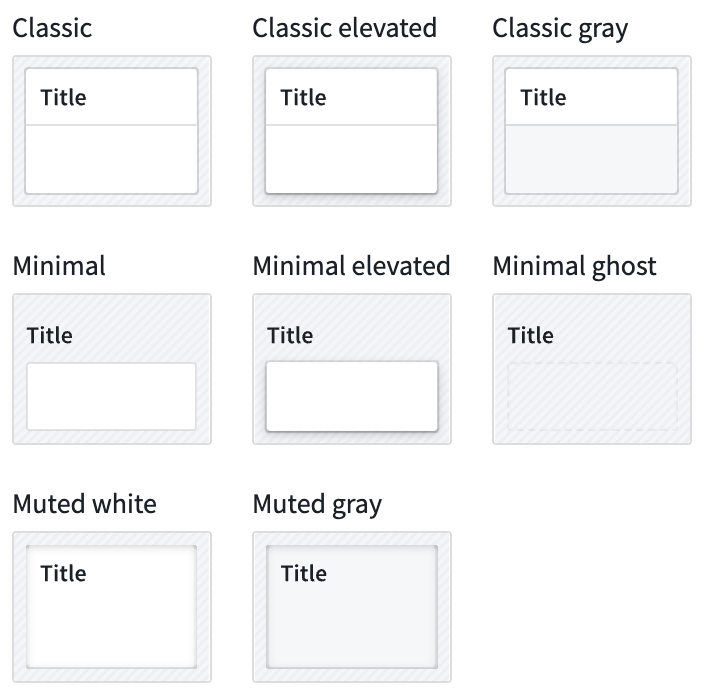
Border styles can be configured on sections and widgets, giving the appearance of different elevation levels within a module.

Padding controls
Padding can be configured for pages and sections to set a consistent amount of padding or space around all child components within. Padding adds space between components to provide separation and breathability to the module.
To learn how to apply these styles, see Layouts in the documentation for more information.
Export Contour logic to Pipeline Builder
Date published: 2023-07-12
In Contour, you can now export most Contour analyses to Pipeline Builder directly and take advantage of its comprehensive features for building end-to-end pipelines to feed production applications.
Direct access to Pipeline Builder from Contour analyses means Foundry users gain the flexibility and power of the Ontology through a user-friendly interface. Once the pipeline is converted for use in Pipeline Builder, you can continue building on your workflow's foundations using the application's robust support for streamlined data integration, custom compute profiles, collaboration, type-safety, and incremental mode, just to name a few. In addition, on instances where AIP is enabled, you can take advantage of additional features driven by natural language prompts.
To start, open an existing Contour analysis and simply select Convert to Pipeline Builder to create an equivalent pipeline in Pipeline Builder.

Simply follow the prompt to select a destination folder for your exported pipeline, and it becomes available to open in Pipeline Builder.

To understand more, see exporting Contour logic to Pipeline Builder in the documentation.
Introducing Ontology Proposals [GA]
Date published: 2023-07-06
Ontology branches allow you to suggest changes to the Ontology using a version control system with a built-in proposal and approval workflow, facilitating easier collaboration with peers and more transparency when changes are made to the Ontology.
With Ontology proposals, you can benefit from the following features:
- Branch creation: You can now create a branch with your changes to the Ontology either by selecting Save after having made the desired changes, or prior to making any changes by selecting Create branch.
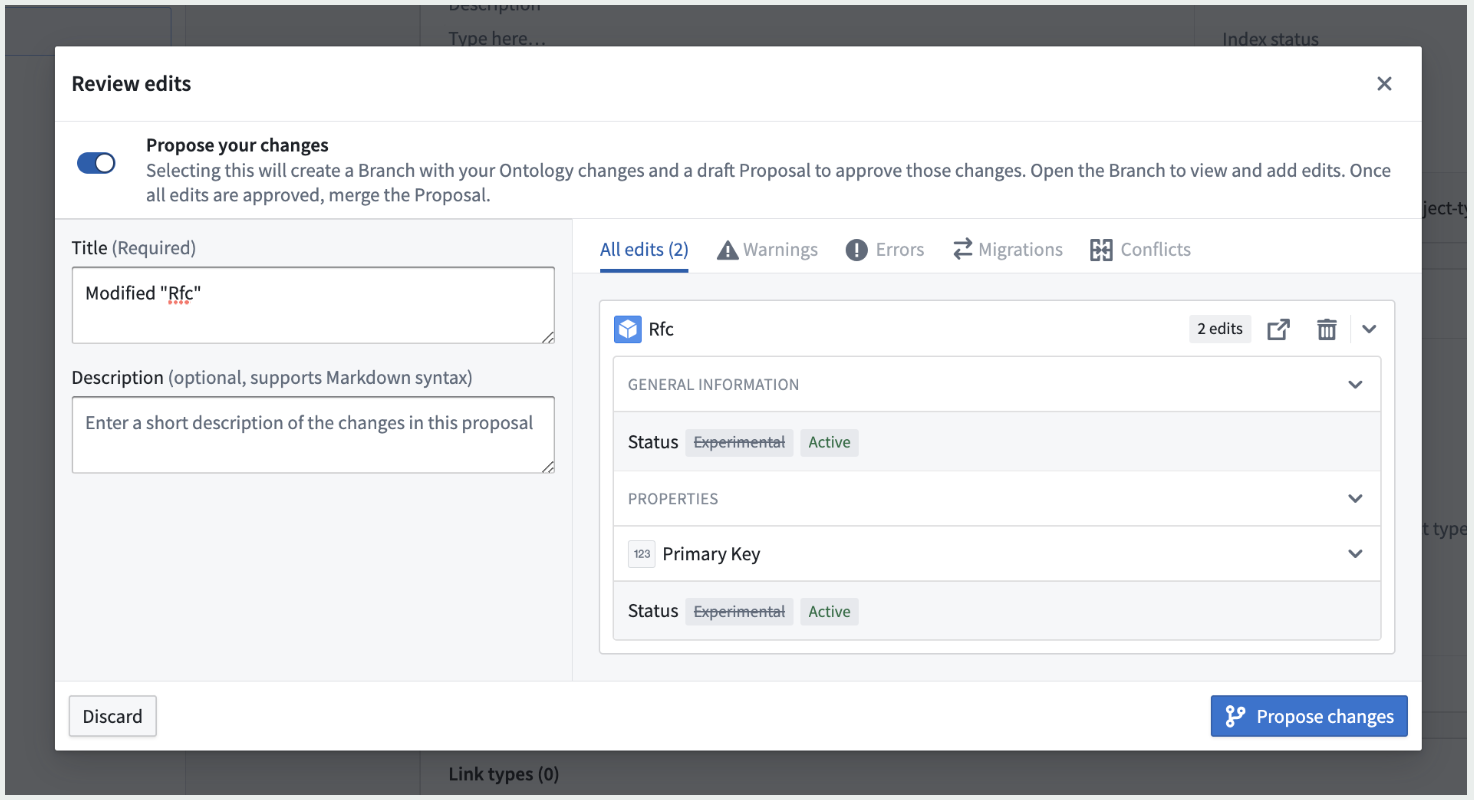
- Proposal Overview: The Proposal overview page centralizes high-level information about a proposal such as description, stage, reviewers, and tasks related to Ontology changes. The Overview is also the starting point for editing the proposal, adding reviewers, reviewing pending tasks, and moving the proposal to the subsequent stage.
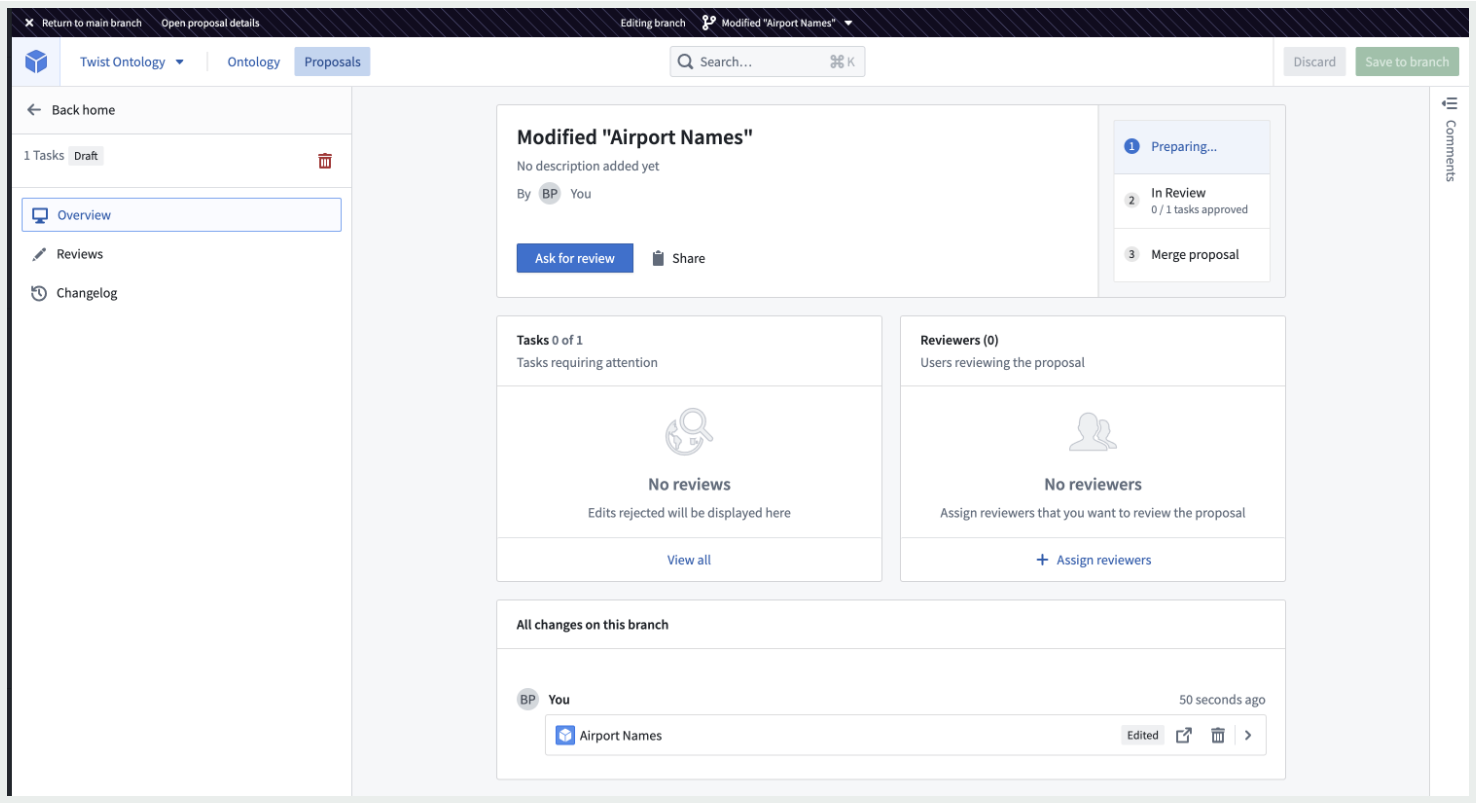
- Reviewing a proposal: Reviewers have the option to either approve or reject changes, and add comments to support their review.
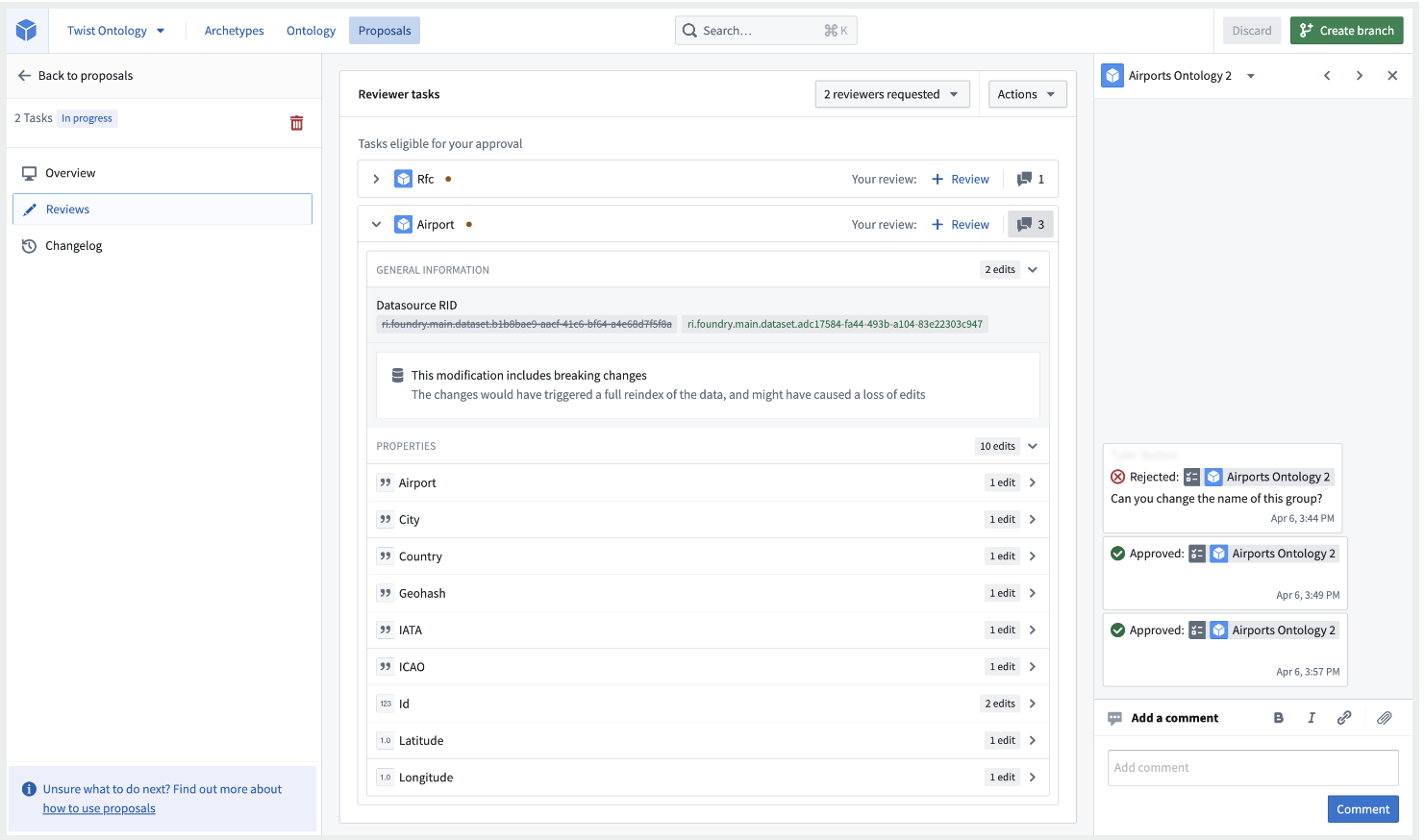
- Releasing a proposal: When all changes have been reviewed and approved, you or your collaborators can choose to save your changes to the Ontology.
Enable Ontology proposals from Control Panel
Proposals can be enabled for all private Ontologies as well as all default Ontologies that do not have collaboration between multiple organizations. To enable Ontology proposals, visit the Ontology settings tab in Control Panel, and toggle on Ontology proposals for your organization.
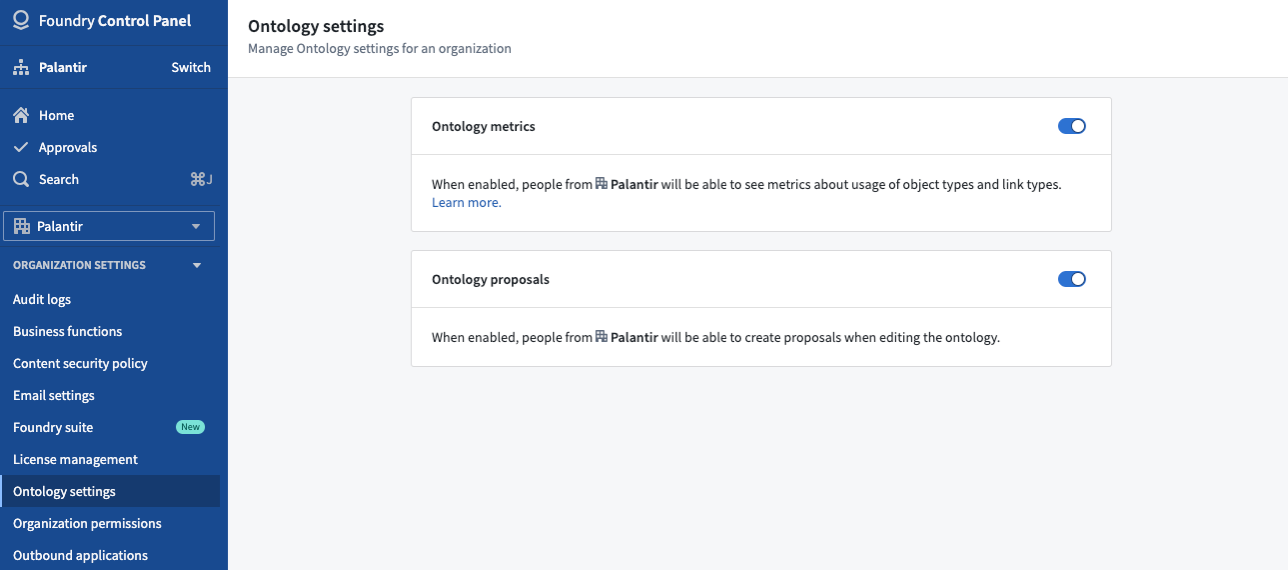
For more information and usage guide, see Ontology branches in the public documentation.
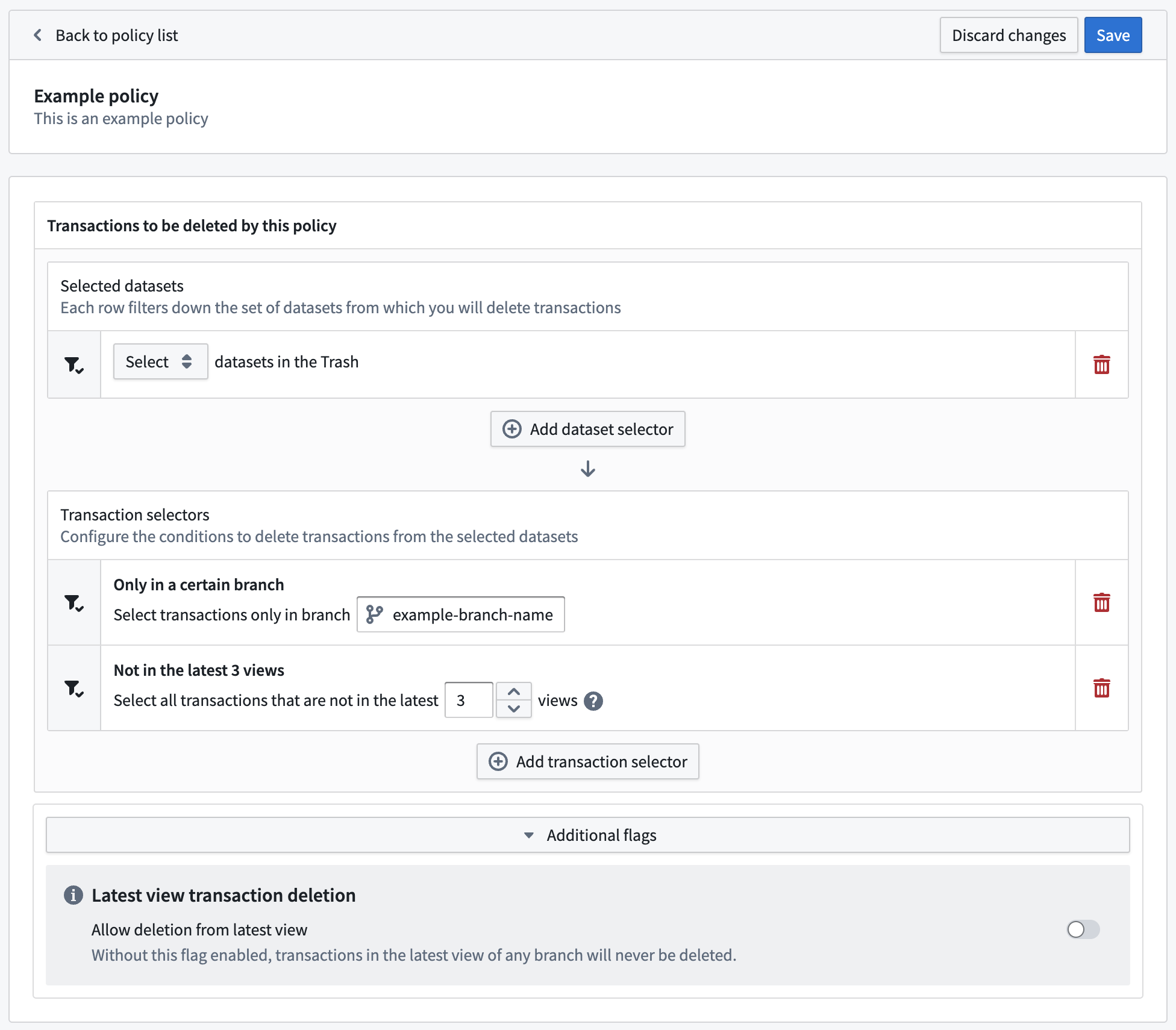
Introducing the Retention Policies application [Beta]
Date published: 2023-07-06
The new Retention Policies application in Palantir Foundry allows you to determine how historical versions of data are deleted from datasets in one self-service interface. Administrators can now easily configure policies that apply to chosen datasets, and Foundry users can view and filter the retention policies that apply to a specific dataset with the Retention policies tab located in the Dataset details view.
The Retention Policies application makes the deletion process more intuitive for administrators while improving transparency for regular Foundry users through its corresponding tab in the Dataset details page.
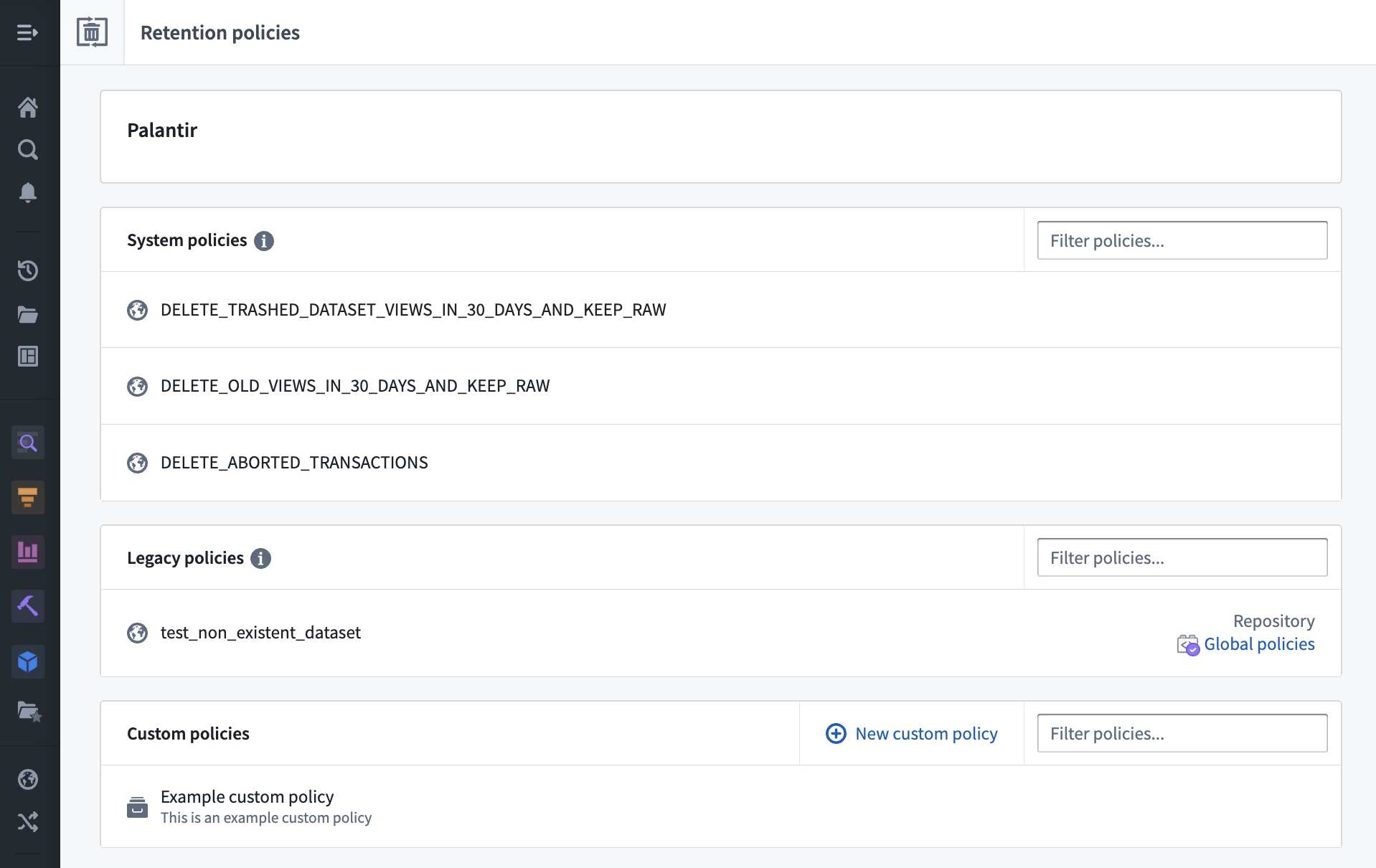
With the Retention Policies application, you can take advantage of the following features:
Retention Policies application (Foundry administrator configuration)
- View all retention policies that apply to a given namespace
- Migrate legacy policies defined in Code Repositories in one click
- Edit mode with validations to alert when the configured policy can be potentially dangerous
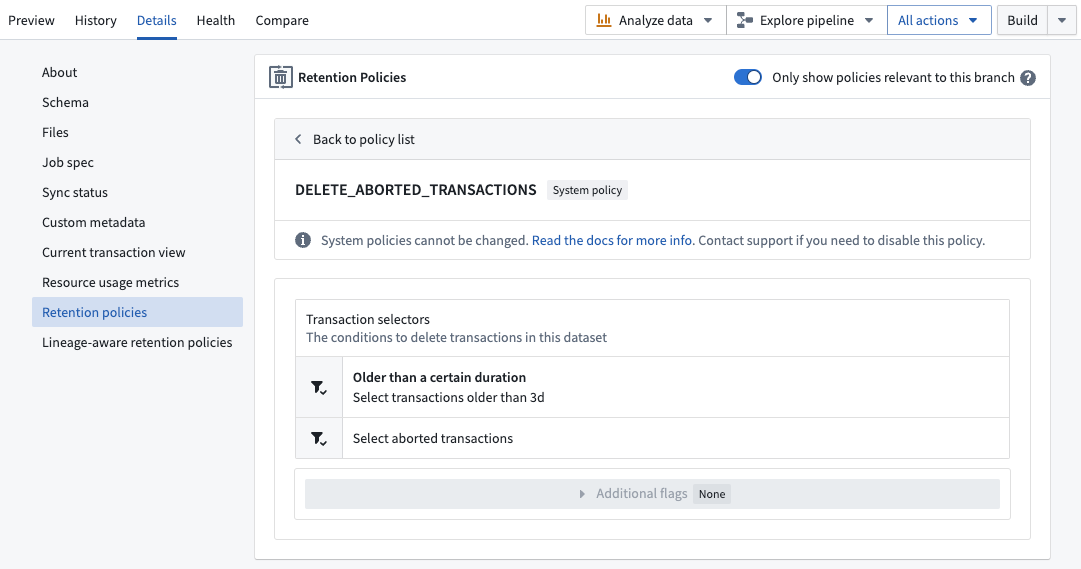
Retention policies tab in Dataset details view (Foundry user view)
- View all retention policies that apply to the given dataset
- Optional toggle to filter only the policies affecting the selected branch of the dataset
Refer to the Retention policies documentation for further details.
What's on the development roadmap?
Better integration with lineage-aware retention policies: When customers have regulatory requirements to delete data after a period of time, it can be difficult to configure the above retention policies to operate on a whole pipeline at once. Support for a new type of policy that can start deleting from one dataset and move downstream of the deleted data is in development.
Introducing AIP in Quiver [Beta]
Date published: 2023-07-06
AIP is now available in Quiver, allowing new and existing application builders, data analysts, and subject-matter experts of all experiences to explore data with ease via natural language prompts. AIP is integrated with Quiver's functionalities and can infer cards and their configuration to construct meaningful graphs.
AIP in Quiver can help:
- Answer business and analytical question by generating the analysis that backs the answers
- Configure output visualizations (layouts, colors, orientation, titles, etc.) Learn how to use the Quiver application with its extensive and powerful suite of data transformation, visualization, and dashboarding capabilities
You can review AIP's suggestions, review their underlying rationales, then accept or reject them. With a click of a button, you can transform your analysis with flexibility and ease.
Generate analyses and get insights more quickly
Answering business and analytical questions in Quiver is now faster than ever using AIP. Users can generate an analysis by simply asking Quiver natural language questions such as:
- Who are the top retailers by revenue in Atlanta and Texas during 2020-2022?
- What was the marketing spend in 2022 for Company A and Company B combined? And what was it for each?
- What was the sum of marketing spend in each advertising channel for each retailer?
(Demonstration screenshots below depict notional data)
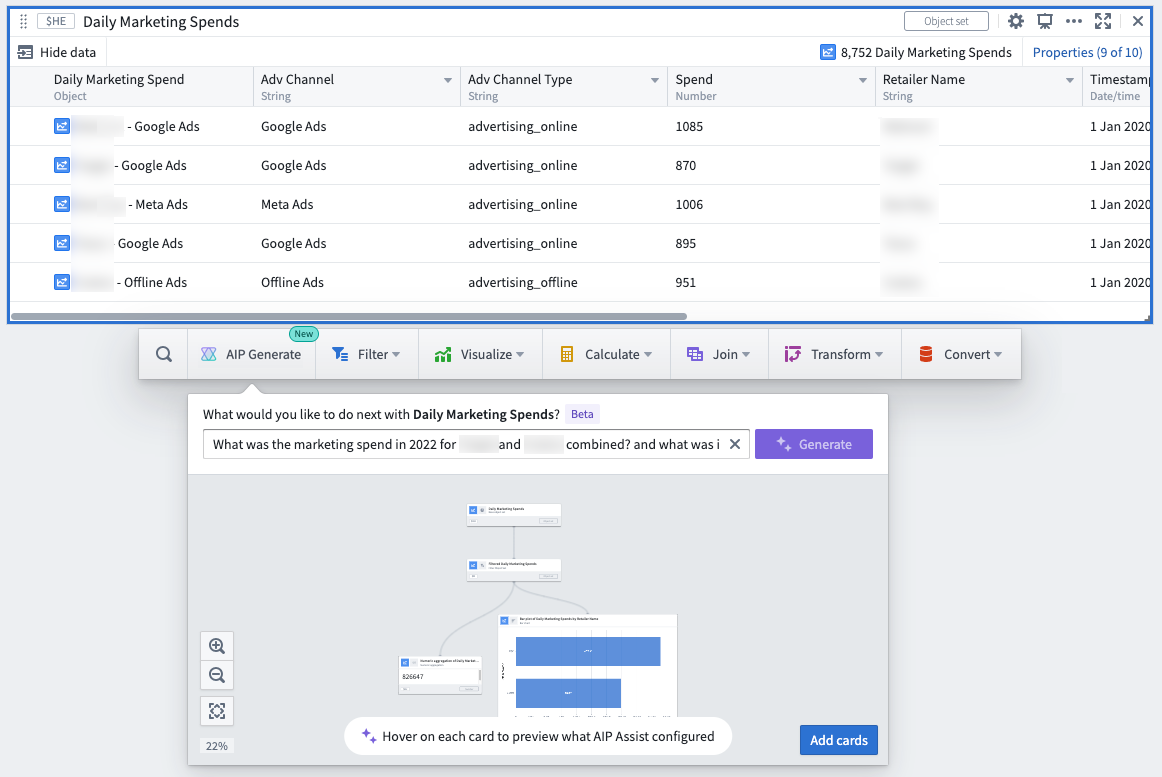
Using a large language model (LLM), AIP parses a user’s question to then construct a resulting Quiver graph, along with a helpful explanation of why specific cards were chosen and how the cards were configured in relation to the respective prompt.
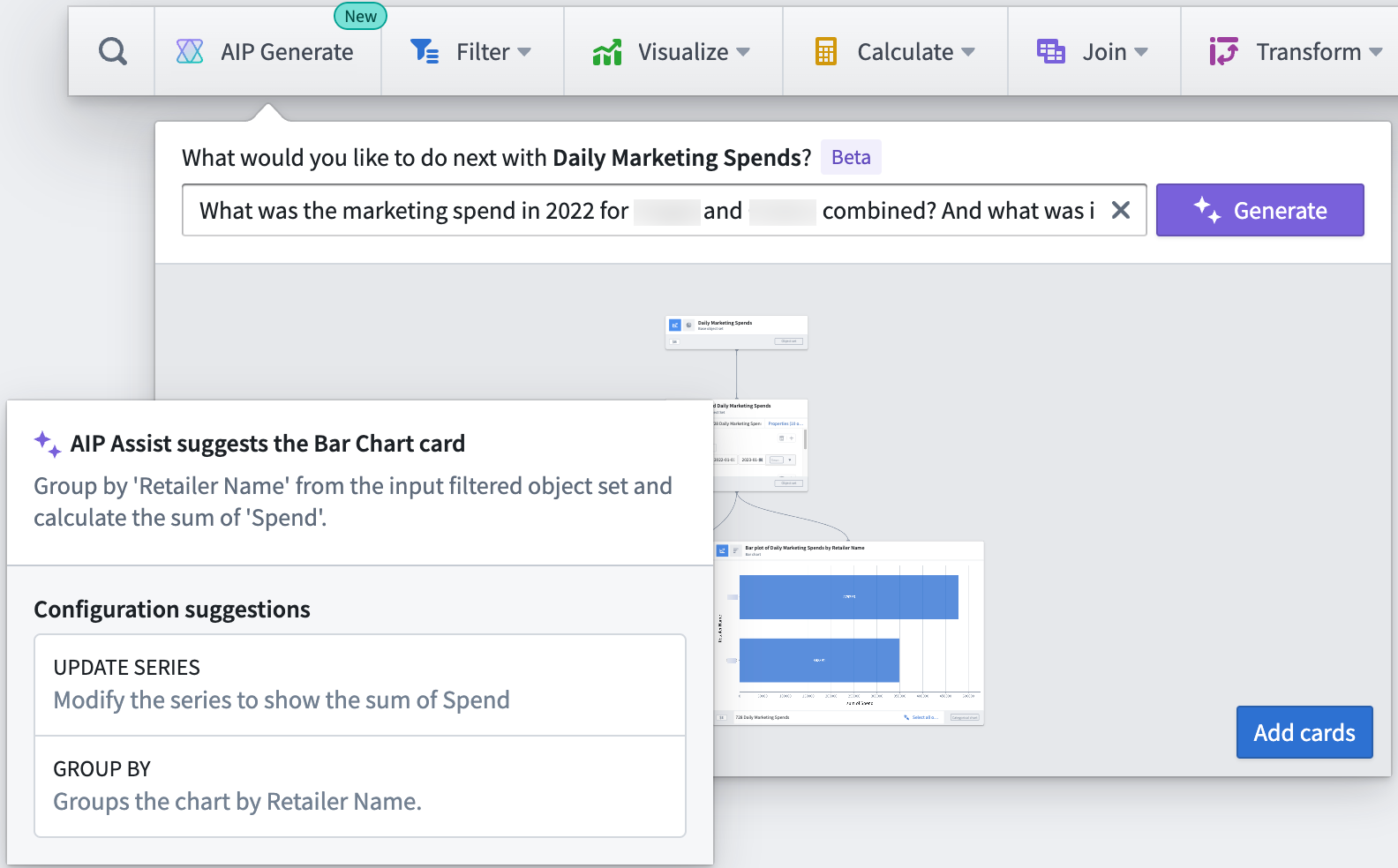
Quiver users can then add the resulting graph to the analysis canvas all at once, to further modify or finalize each card configuration or visualization.
Configure visualizations by describing the desired output
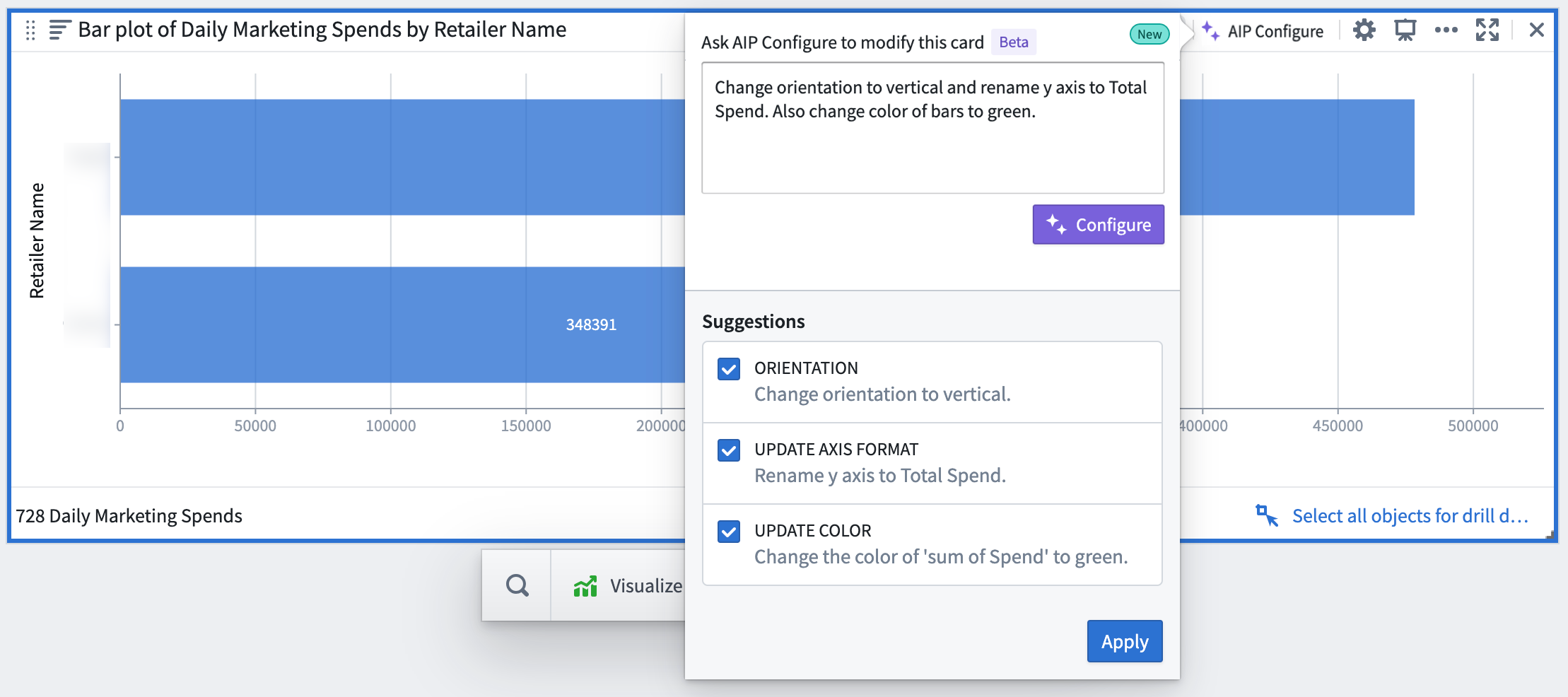
Quiver users can now obtain a picture-perfect visualization without having to know the visualization settings offered by each Quiver card. AIP makes updating card configuration a breeze since users can describe a configuration to AIP such as:
- “Move the legend to the bottom and change the style to grouped”.
- “Change the metric to sum of sales and update the y axis title to
Total Sales".
For each command, AIP returns with card configuration suggestions - accompanied by explanations of why each suggestion was made - which can be accepted or rejected by the user.
Currently, AIP in Quiver includes support for object set and object cards only. Supported cards are labeled with an "AIP Support" label.
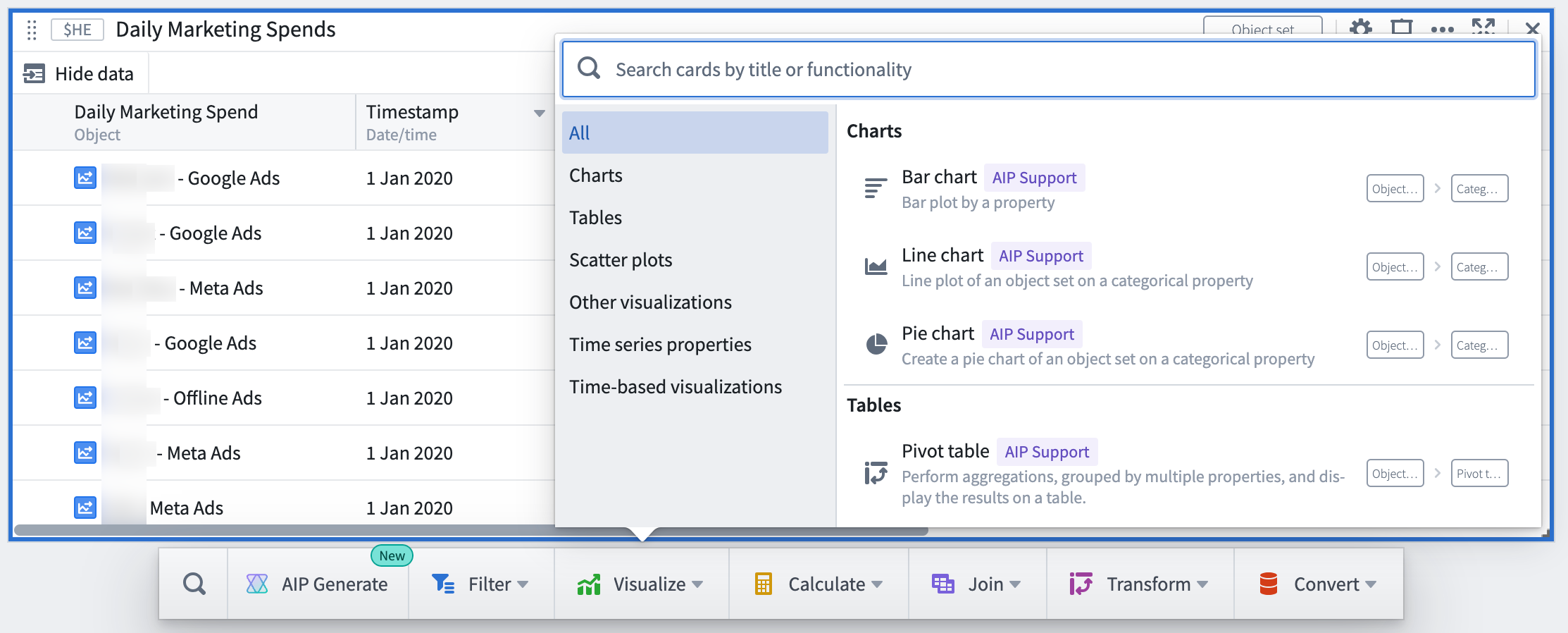
Shortening the time-to-value for new and existing Quiver users, AIP brings Quiver’s full range of advanced functionality to the forefront with just one user command. These new features represent the beginning of exciting ways in which AIP can augment Quiver analyses, with further functionality to come.
See the documentation for more information on Quiver’s AIP features.
Additional highlights
Security | Projects
Surfacing additional data requirements in the Check access panel | The Check access panel in the workspace sidebar now surfaces additional data requirements for certain files such as Markings inherited through lineage for datasets, and Ontology dependencies for Workshop modules & Slate applications.
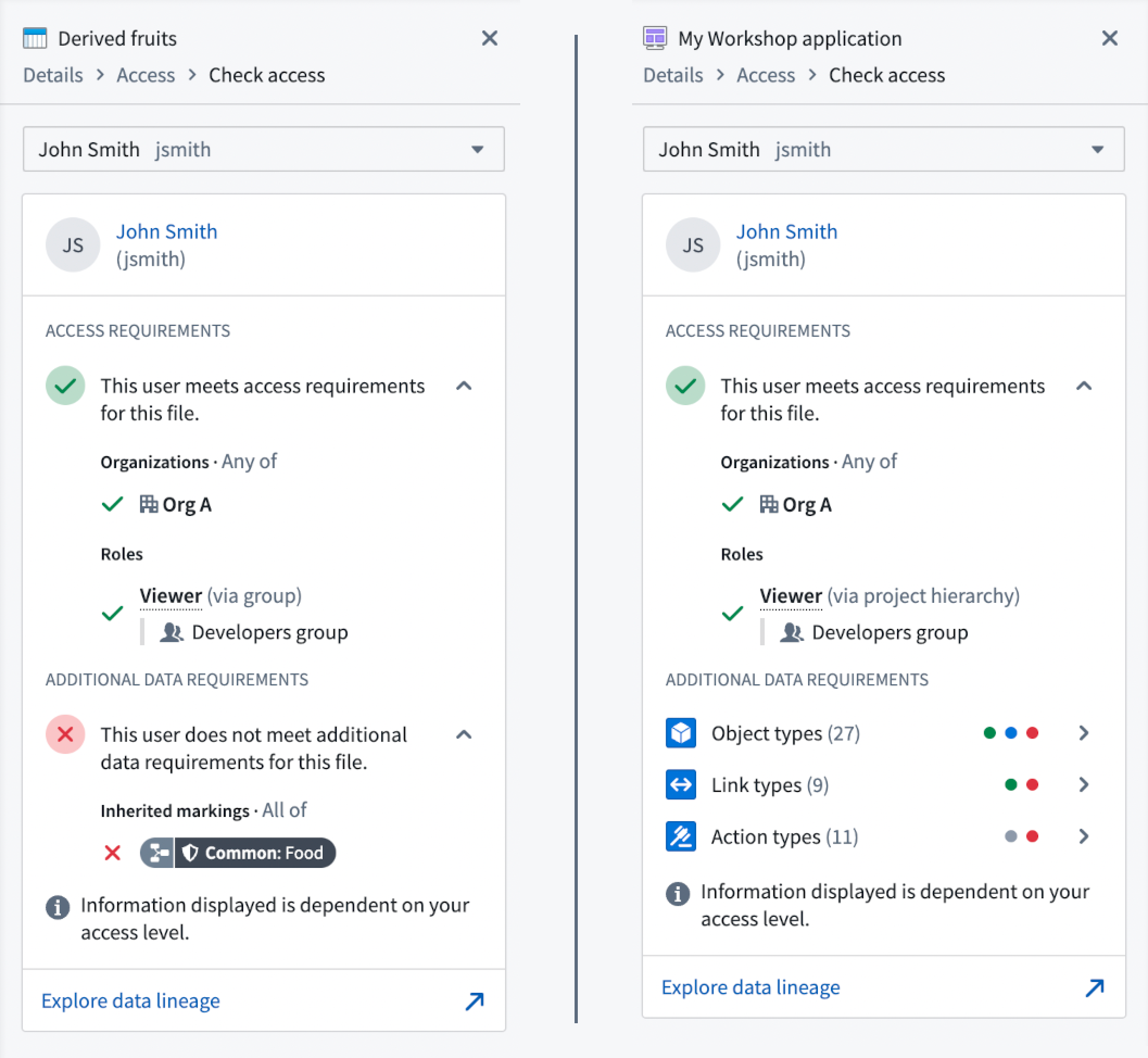 Additional data requirements for dataset and Workshop modules
Additional data requirements for dataset and Workshop modules
Data Integration | Code Repositories
New Code Repositories default to deleting source branches when PRs merge | All new code repositories will default to deleting source branches when its respective pull request has been merged. Existing repositories will be unaffected, and new repositories can be opted-out on a per-repository basis. This change will improve performance and stability by slowing the proliferation of branches, thereby minimizing pressure on downstream services.
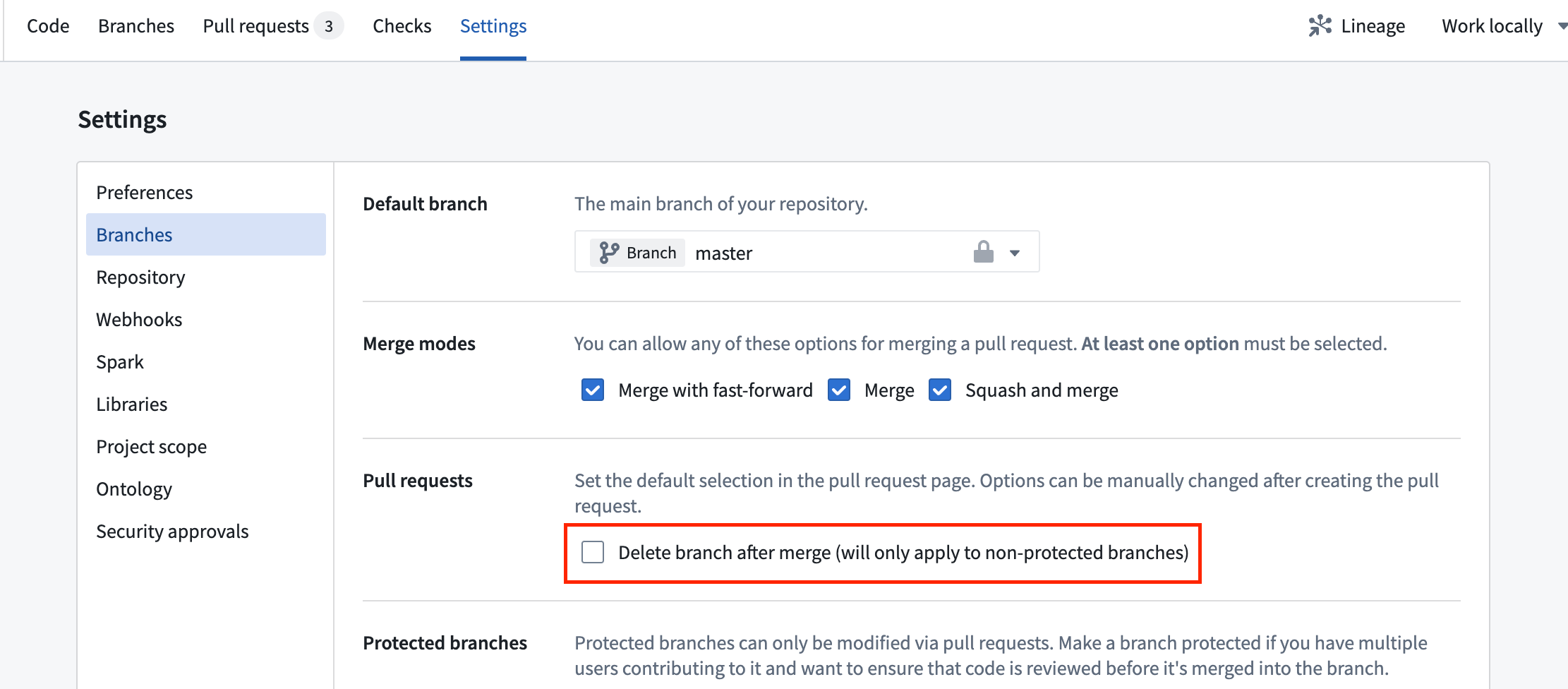 Settings for branch deletion
Settings for branch deletion
Data Integration | Data Connection
Export support in Data Connection | Data Connection exports are now supported. Exports are intended to replace export tasks and provide a user-friendly interface for configuring data flows from Foundry out to other systems. With exports, you can use the same connection to both sync data to Foundry and export data from Foundry. For supported sources, you will now see a table of exports on the source overview page as well as an option to create a new export. Exports are available for S3 and Kafka sources in this release. Support for more source types will be coming soon.
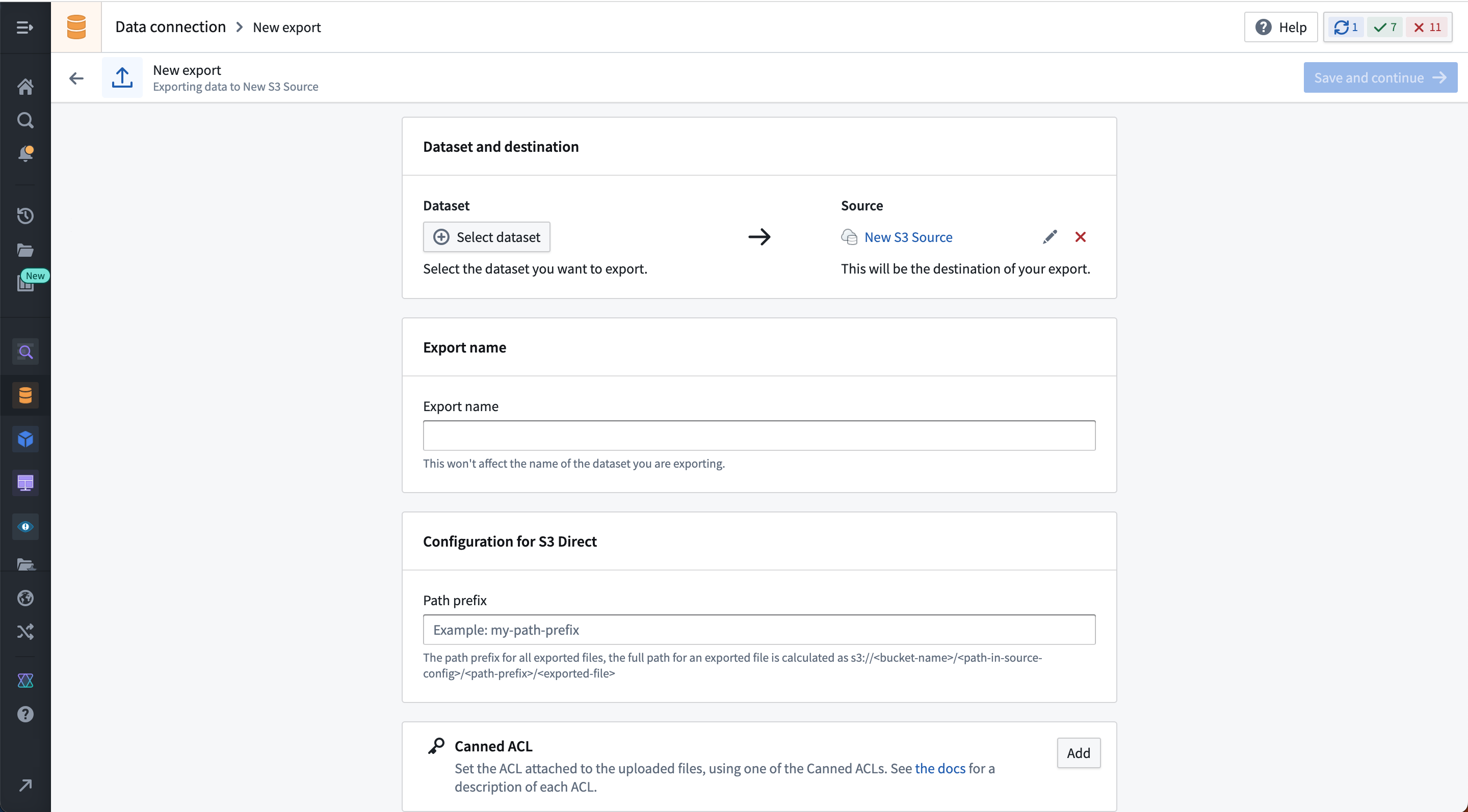 New S3 export page in data connection
New S3 export page in data connection
Foundry | Cipher
Cipher License to Builder Pipeline | Cipher users can now create Builder pipelines from the Cipher App to kick-start encryption on their most sensitive data. This is available for Admin and Data Manager Licenses that allow Encryption. To do so, users will need to select a dataset and a specific column for encryption. Cipher will then automatically generate a pipeline for users to build upon with the pre-selected column already encrypted.
App Building | Workshop
Object List Widget: card-styling and increased media support | The Object List widget now supports a per-object card styling and also provides more options for displaying images, audio, and other media attachments inline. See an example of the new card styling with a prominent inline image displayed for each object.
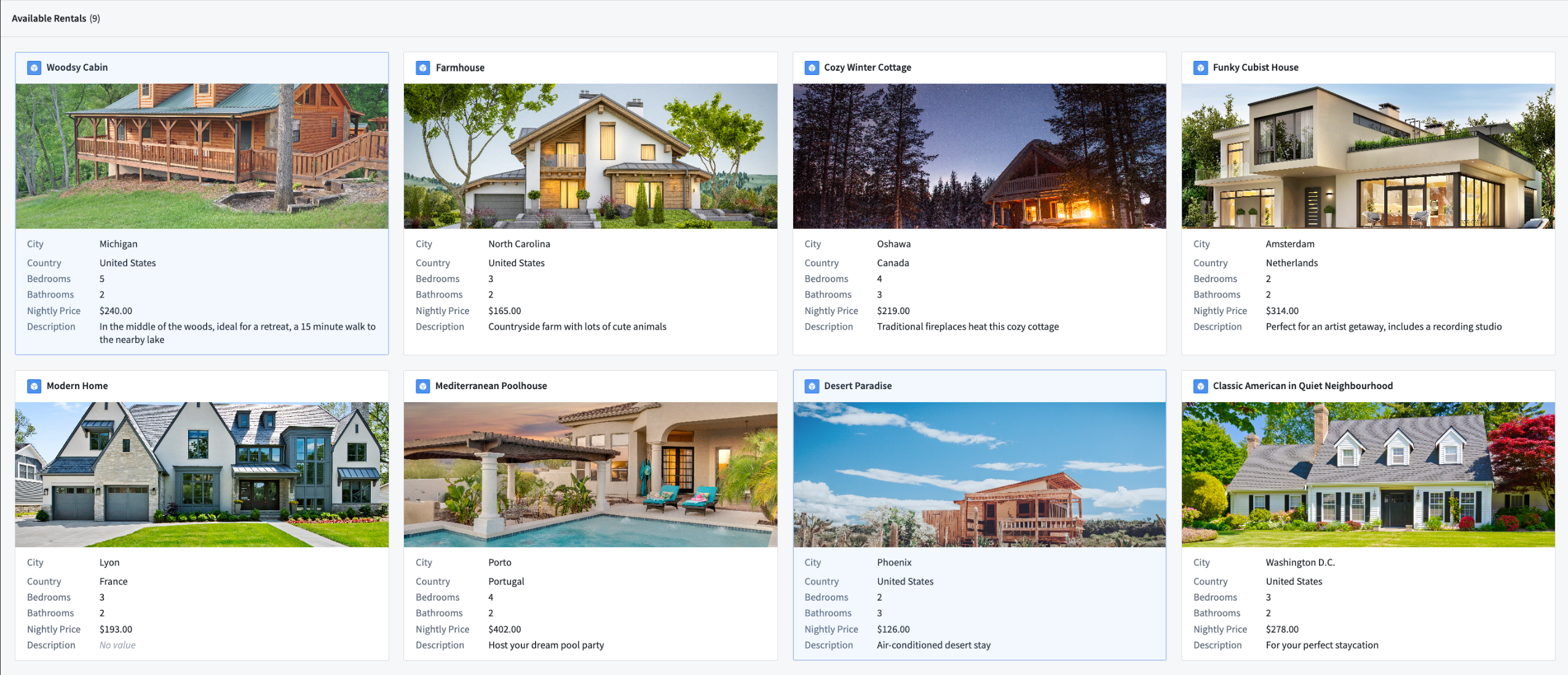
App Building | Workshop
Variable Transforms: Array Operations | Array operations are now supported within Workshop’s front-end variable transformation system. Transforms can be used to compose new arrays, calculate the intersection between arrays, and run boolean checks for the presence/absence of a value within an array.
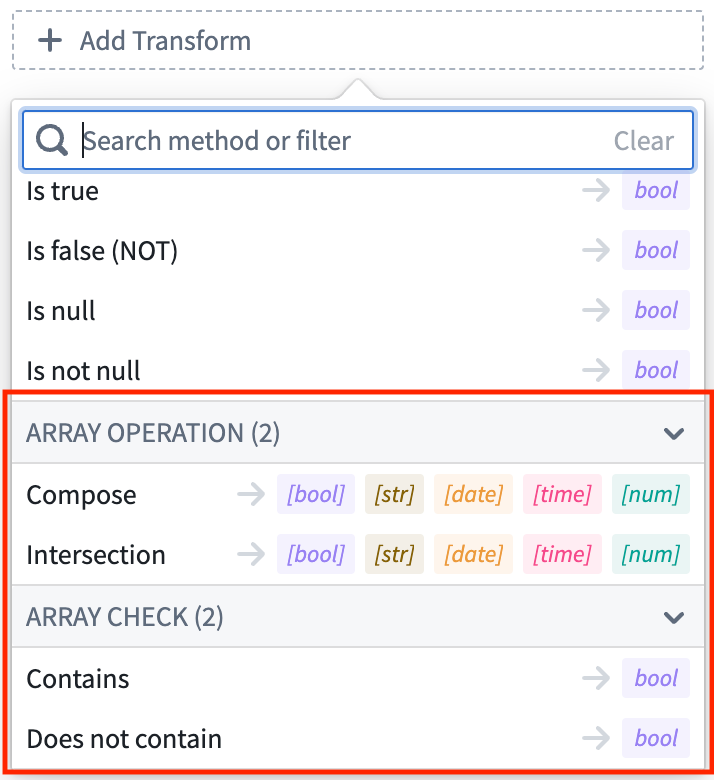
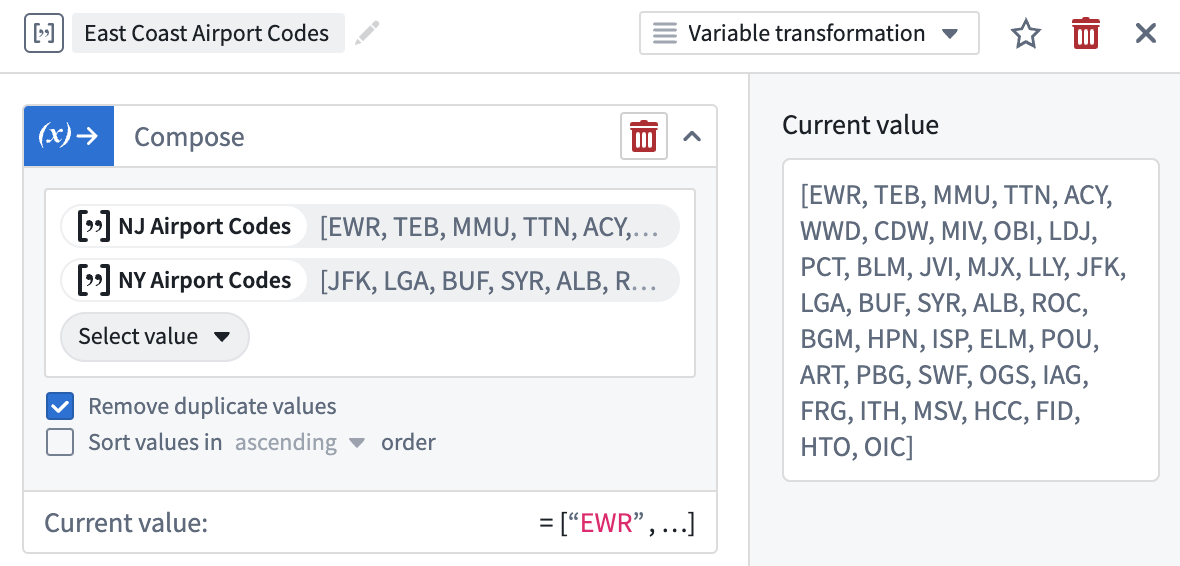
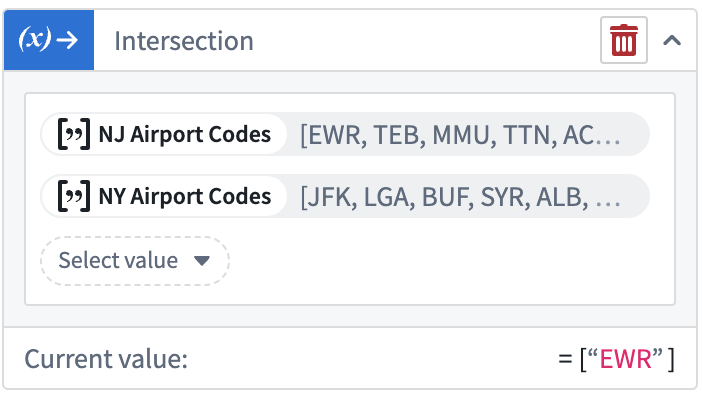
App Building | Workshop
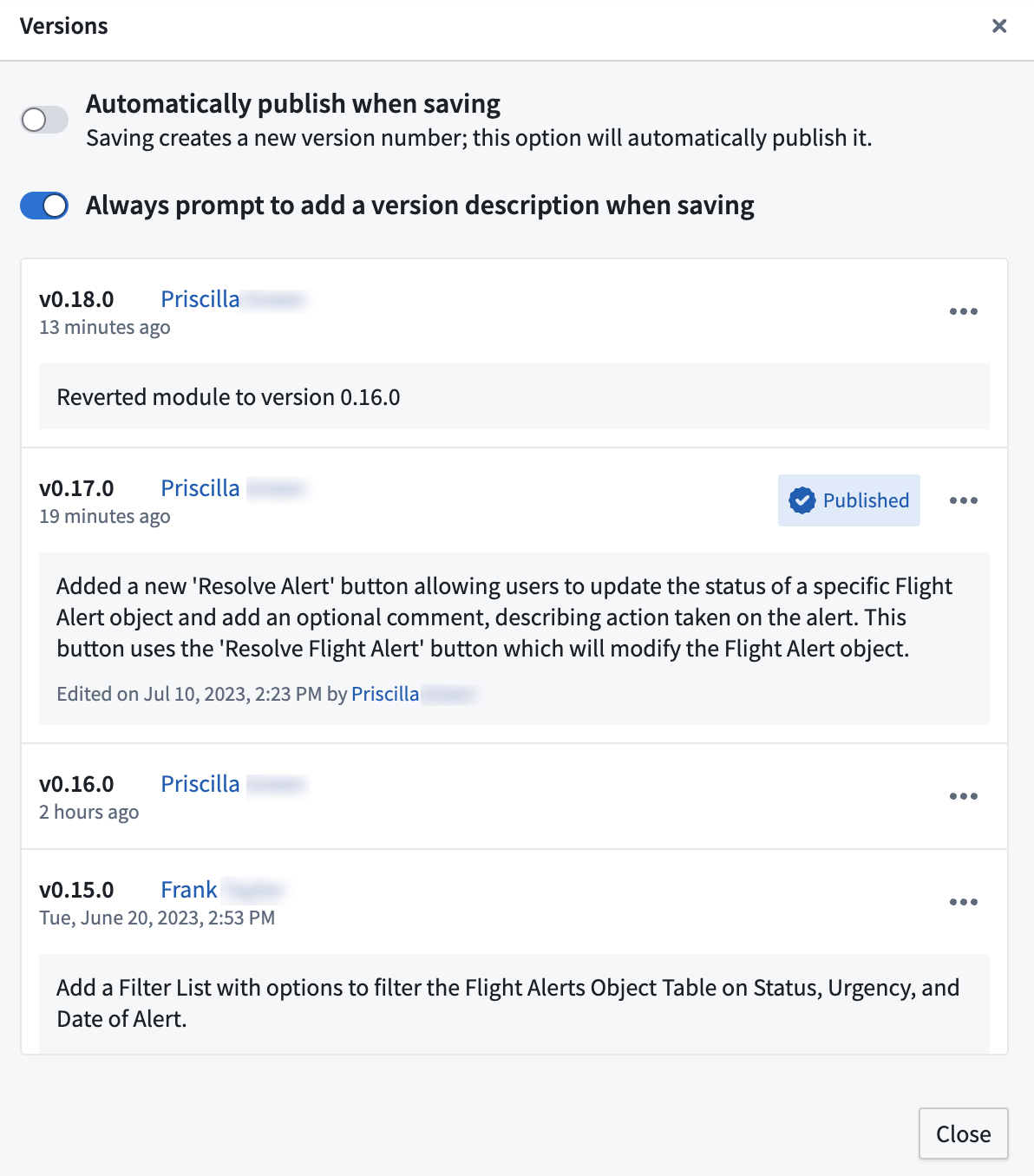
Descriptions on Module Versions | Application builders can now add an optional description when saving a new module version. This helps document the evolution of changes made to production modules and allows builders to main a richer record of a module’s history. Descriptions can be viewed, added, and edited in the module’s versions dialog. Retroactively added or edited descriptions will be marked as edited with accurate timestamp and editor details. Reverting to a previous version of the module will automatically generate a description, logging the taken revert action.
Security | Projects
Require checkpoints for actions taken via asynchronous requests | Justifications are now required for asynchronous requests if checkpoints have been configured for certain synchronous actions, such as adding a reference to a project. The corresponding tasks will display whether checkpoints have already been completed or not.
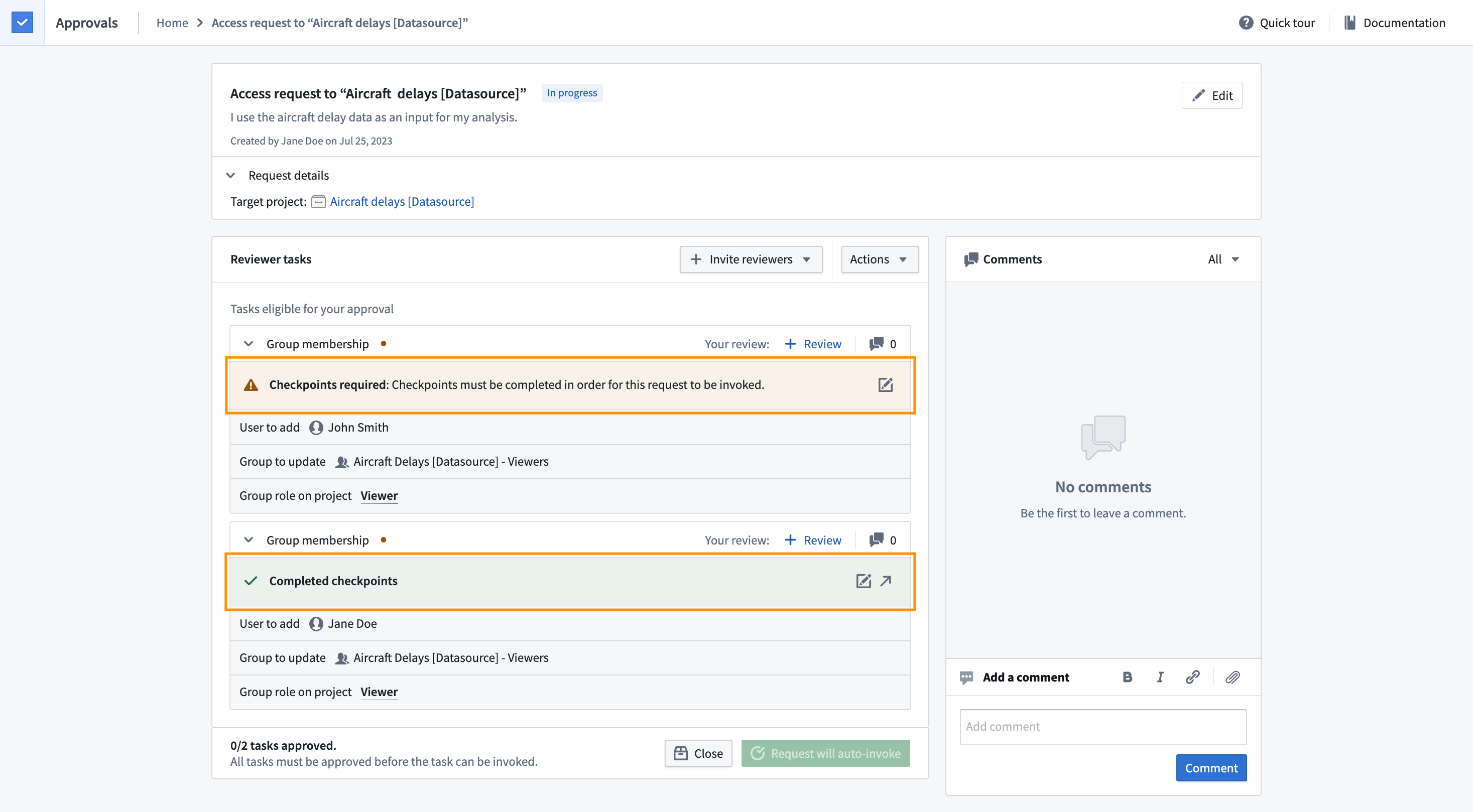
Analytics | Quiver
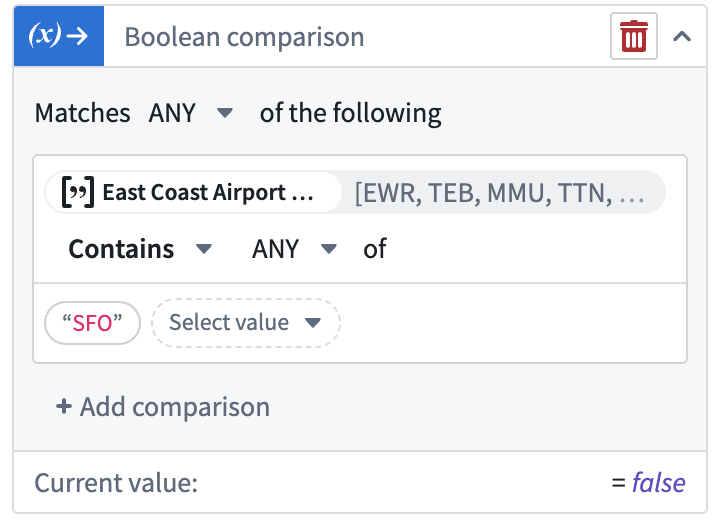
Add Boolean filter transforms | Added is and is not comparison transforms for filtering transform table rows by Boolean columns. These new transforms enhance filtering capabilities, allowing users to filter by Boolean columns and other column types such as date and string. The comparison transforms can also be used separately outside of transform tables.
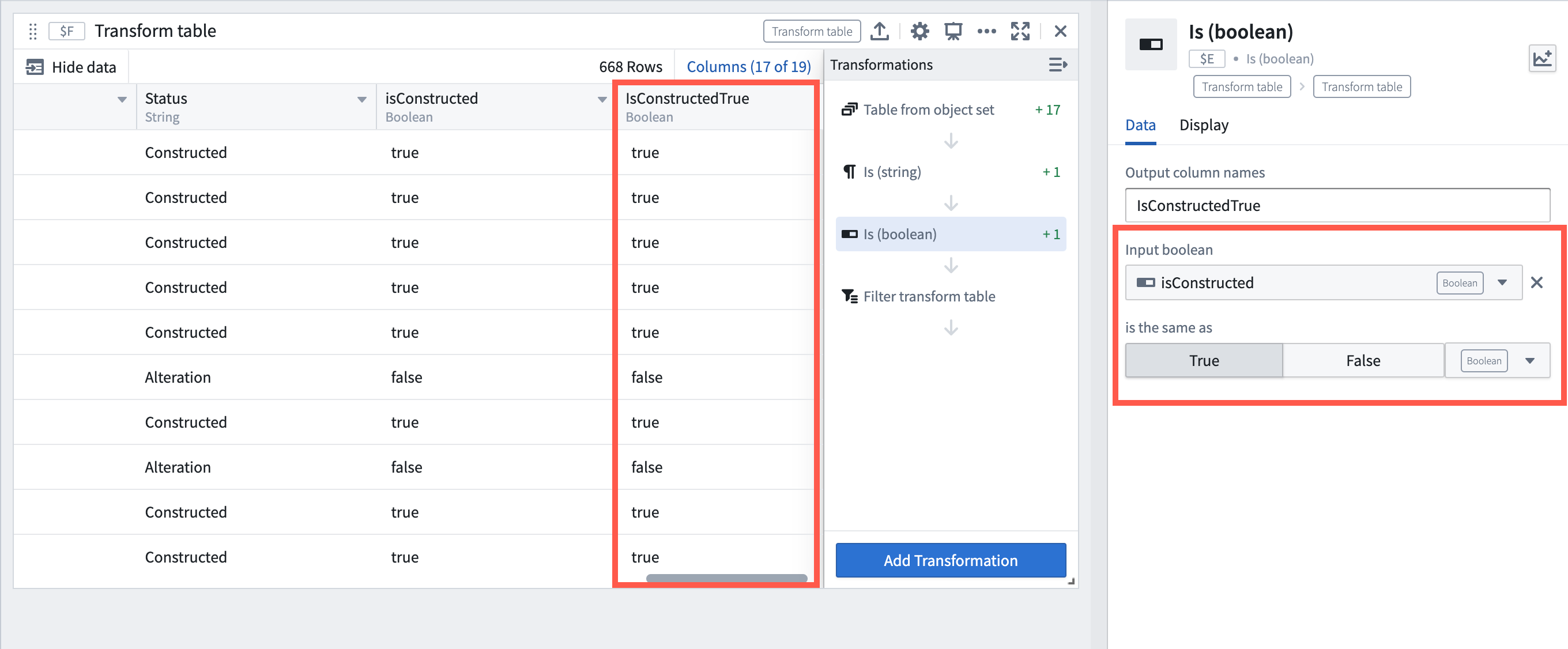
Example of using the new Boolean comparison transform to check if a Boolean column is True.
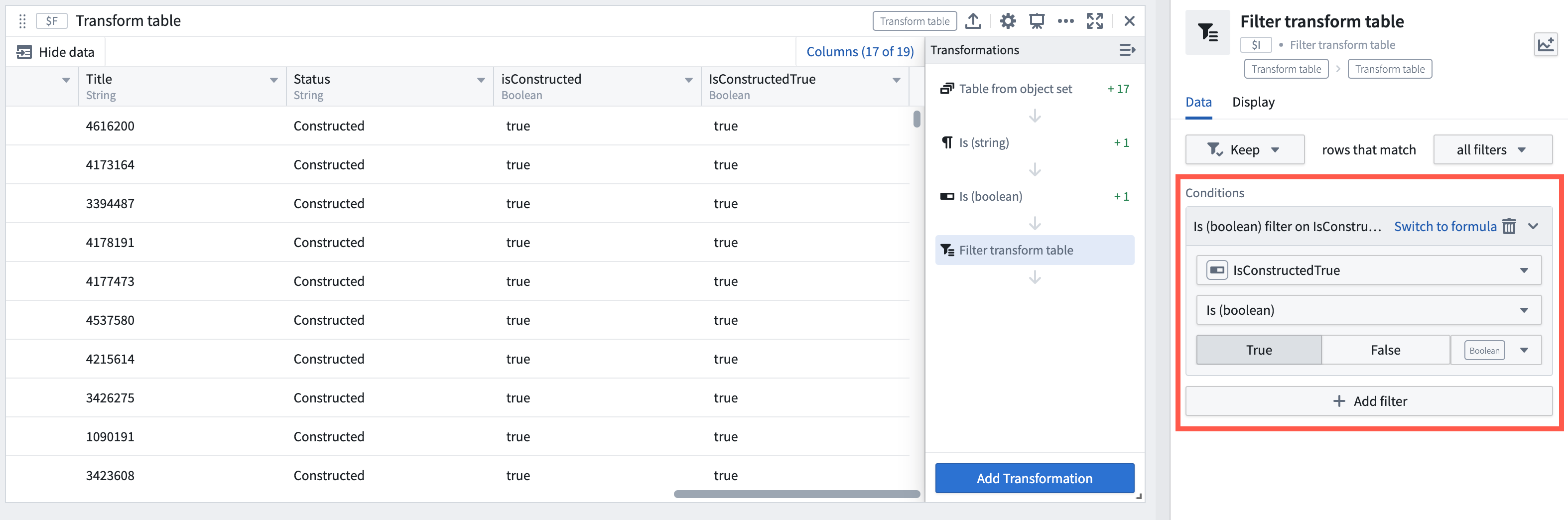
Example of a transform table filtering rows via a Boolean comparison transform output.
Ontology | Ontology Management
Supporting OSv1 -> OSv2 migration for object types with user edits | User-edited object types and many-to-many link types can now be migrated to OSv2 in the Ontology Manager. Previously, the migration framework did not allow migration of object types and many-to-many link types with existing user edits. Edited object types can now benefit from the new features and capabilities of OSv2.
Analytics | Quiver
Replace Number group aggregation with Number array aggregation transform | "Number array aggregation" is a new transform that performs the following functions: First, last, sum, average, standard deviation, maximum, minimum, difference, product, and count. Replacing the existing "Number group aggregation" transform that only works within a transform table, this new transform works both within and separate from transform tables.
Analytics | Quiver
Add Number to Date Transform | Released a new "Number to Date" transform that converts between a numeric representation of a date (either Unix seconds or milliseconds, representing a timestamp in UTC) to a date type. This transform is useful, for example, to convert the returned value of a numeric aggregation on a Date property type which is a Number type back to a Date type to be used as input for other transforms or cards.
Data Integration | Pipeline Builder
Ability to create job groups in Pipeline Builder | Each successful deployment in Pipeline Builder will initiate a single build. In batch pipelines, by default, each output is built as its own job, so output jobs succeed or fail independently. In streaming pipelines, by default, all outputs are bundled into a single job running on a single Flink cluster, so output streams either all succeed or all fail together.
Job grouping enables you to bundle multiple outputs together into one job in batch pipelines, or split each output into its own job in streaming pipelines. You can also specify compute profiles for each grouping, providing granular control over how your outputs are built.
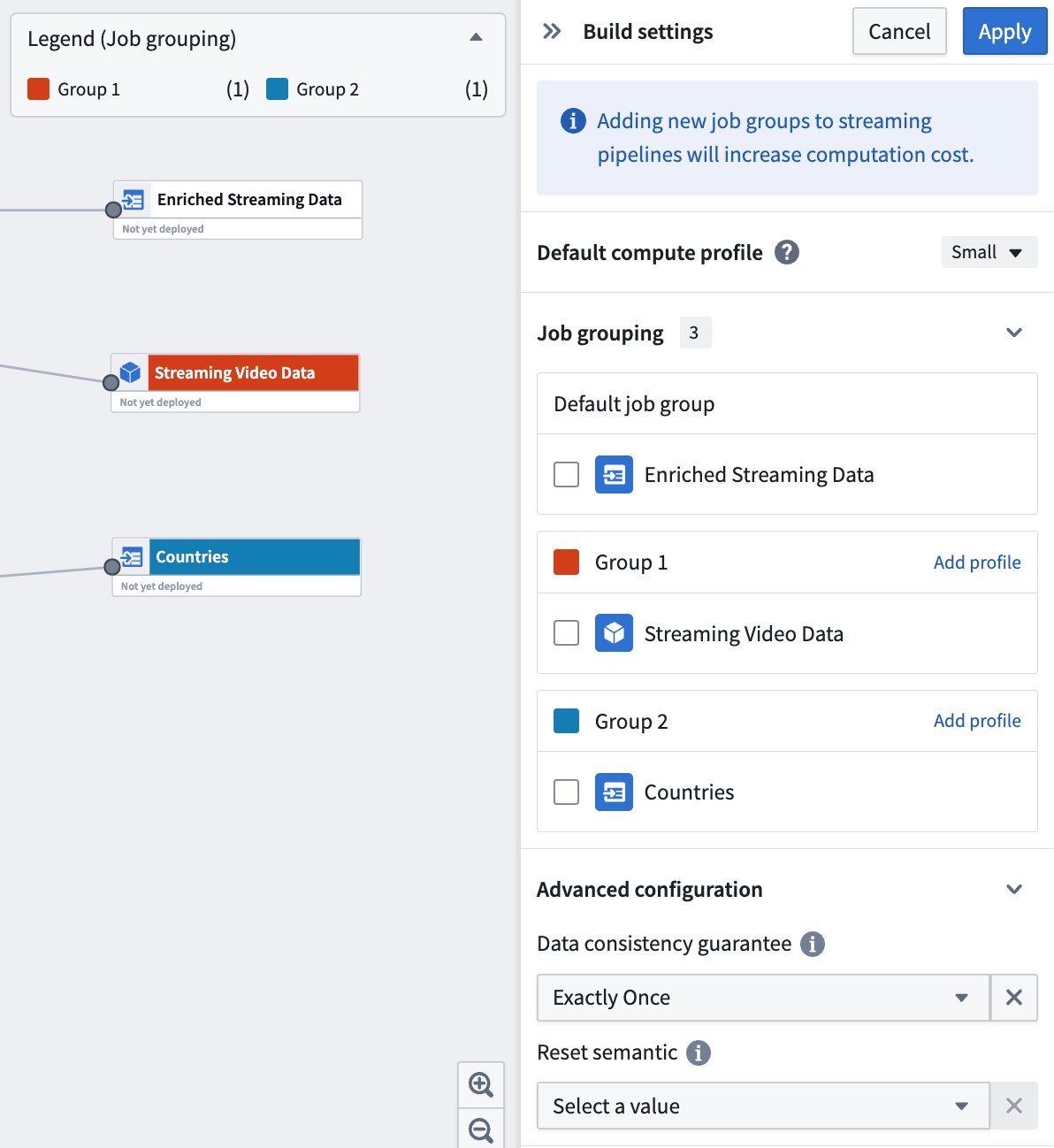
Data Integration | Pipeline Builder
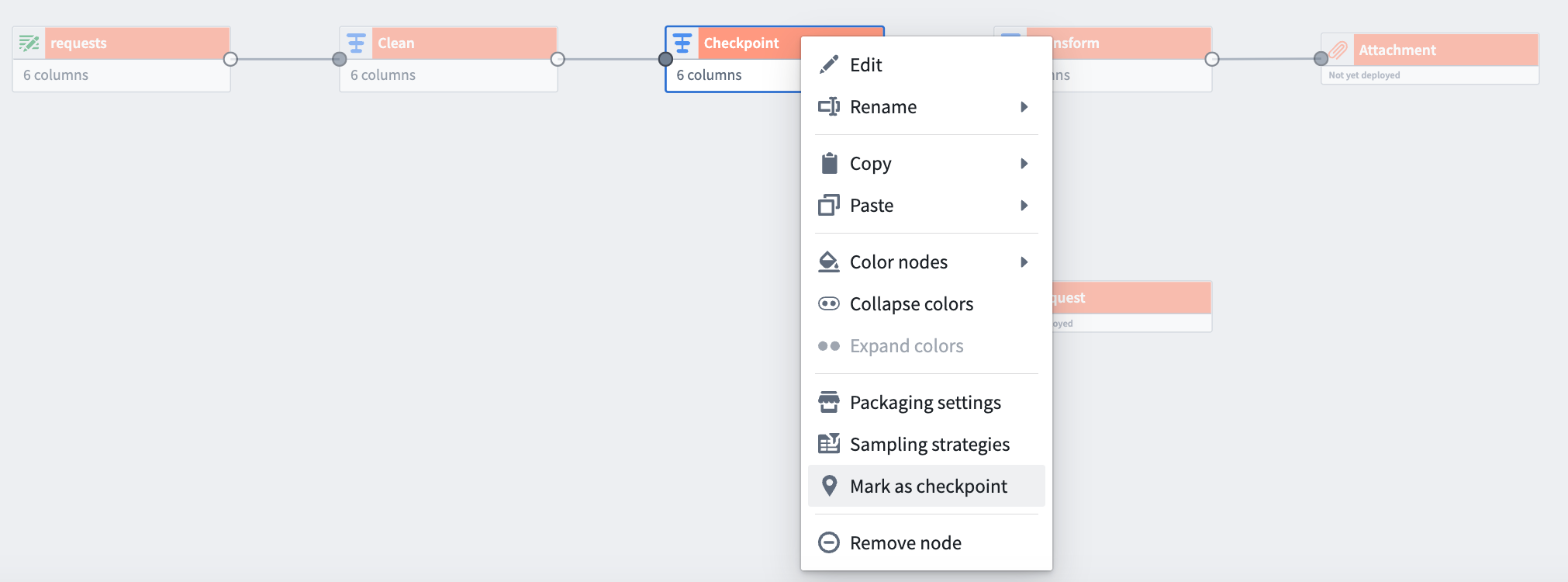
Checkpointing now available in batch pipelines | While building pipelines, you will oftentimes use shared transform nodes between multiple outputs. This logic is normally recomputed once for each output. With checkpointing, you can mark transform nodes as “checkpoints” to save intermediate results during your next build. The logic up to that checkpoint node will only be computed once for all of its shared outputs. This can save compute resources and shorten build times.
Ontology | Foundry Rules
You can now access Foundry Rules configuration via the sidebar | The Foundry Rules deployment and configuration UI is now accessible via a more prominent sidebar icon. See Deploy workflow template in the documentation for more detail.
![]()
Ontology | Ontology Management
Performance improvement in OMA: Rendering speed | The Ontology Manager now renders faster as it only loads updated elements instead of the entire app. Ontology Manager users will benefit from a more responsive experience when clicking between pages or making edits.
Data Integration | Scheduler
Add build duration monitor | You can now create a monitor for build duration in Monitoring views in the Data Health app.