- Capabilities
- Getting started
- Architecture center
- Platform updates
Datasets and object sets
Datasets
In Contour and Code Workbook, users can choose to output datasets (tabular data) to capture analysis results. These datasets can be used in applications like Contour, Code Workbook, and Fusion, and can be shared with other users.
Contour and Code Workbook are not optimized for creating production pipelines. If you are building or maintaining production pipelines, use the Code Repositories application, which includes version history, branching and pull requests, and other functionality essential for robust pipelines. More information can be found in this comparison of Foundry’s tools for writing code-based transformations.
Contour
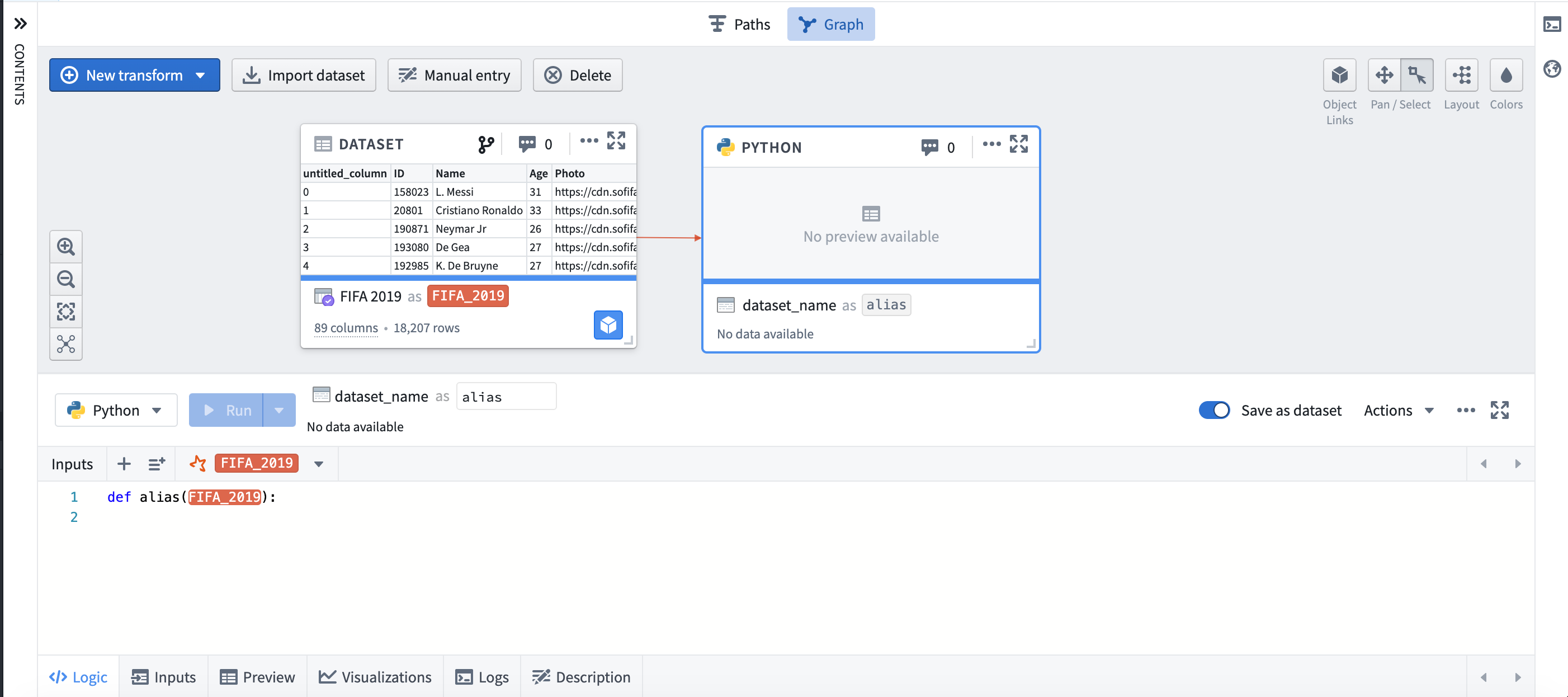
You can save the results of a Contour path by selecting Save as dataset at the bottom of the path. After naming the dataset and choosing its save location, the dataset will build with the results of the analysis. Learn more about saving a dataset from Contour.

Code Workbook
You can choose to save the results of Code Workbook transformations as a dataset by selecting Save as dataset. By default, new transforms are not saved as datasets. Learn more about saving a dataset from Code Workbook.
When are Code Repositories a better fit?
We recommend using the Code Repositories application to create robust production pipelines and support workflows that require an additional layer of governance and monitoring. With Code Repositories, data engineers can create efficient pipelines in bulk.
Example workflows that are a good fit for Code Repositories include:
- A daily pipeline at high data scale which requires incremental compute.
- A high-visibility pipeline with strict governance requiring the ability to revert to previous versions of historical code, or to gate code changes on successful unit tests.
Example workflows that are a good fit for saving a dataset in Contour or Code Workbook are:
- One-time capture of data that is then used in another analytical application.
While you can set build schedules on datasets created in Contour and Code Workbook, pipelining workflows generally belong in Code Repositories.
Object sets
Object sets are lists of real-world entities that are saved for future reference and use across Foundry applications that support objects. Object sets are saved as resources for easy sharing with collaborators.
There are two types of object sets:
- Static object sets: Static object sets are saved as a list of primary keys, and will stay the same regardless of any changes to the input data.
- Dynamic object sets: Dynamic object sets are saved as a representation of the filters applied to create the object set. When new data matches the filters, the object set will be updated.
Object sets created in a Quiver analysis can be saved in Foundry. Once saved, such object sets can be imported in a new Quiver analysis or opened in another Foundry application, such as Object Explorer.
To export an object set, open the editor of the object set card by clicking the  icon in the upper-right corner of the card, and navigate to the Export tab.
icon in the upper-right corner of the card, and navigate to the Export tab.
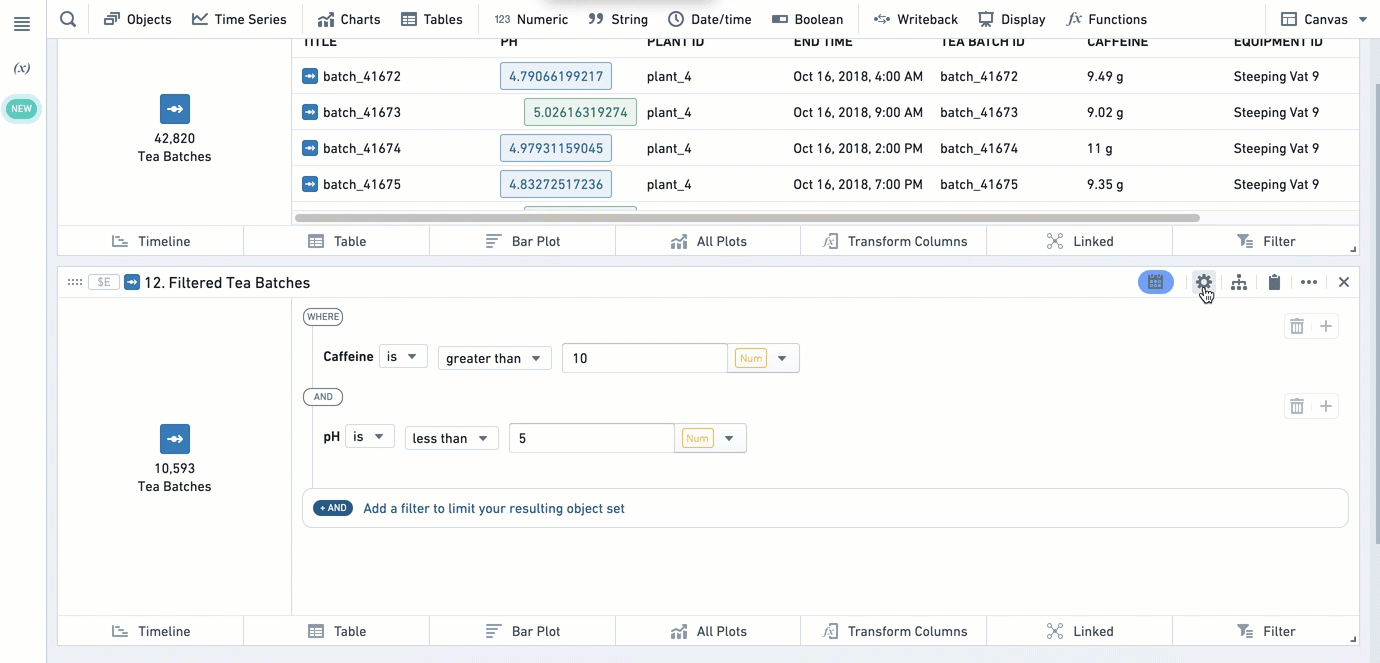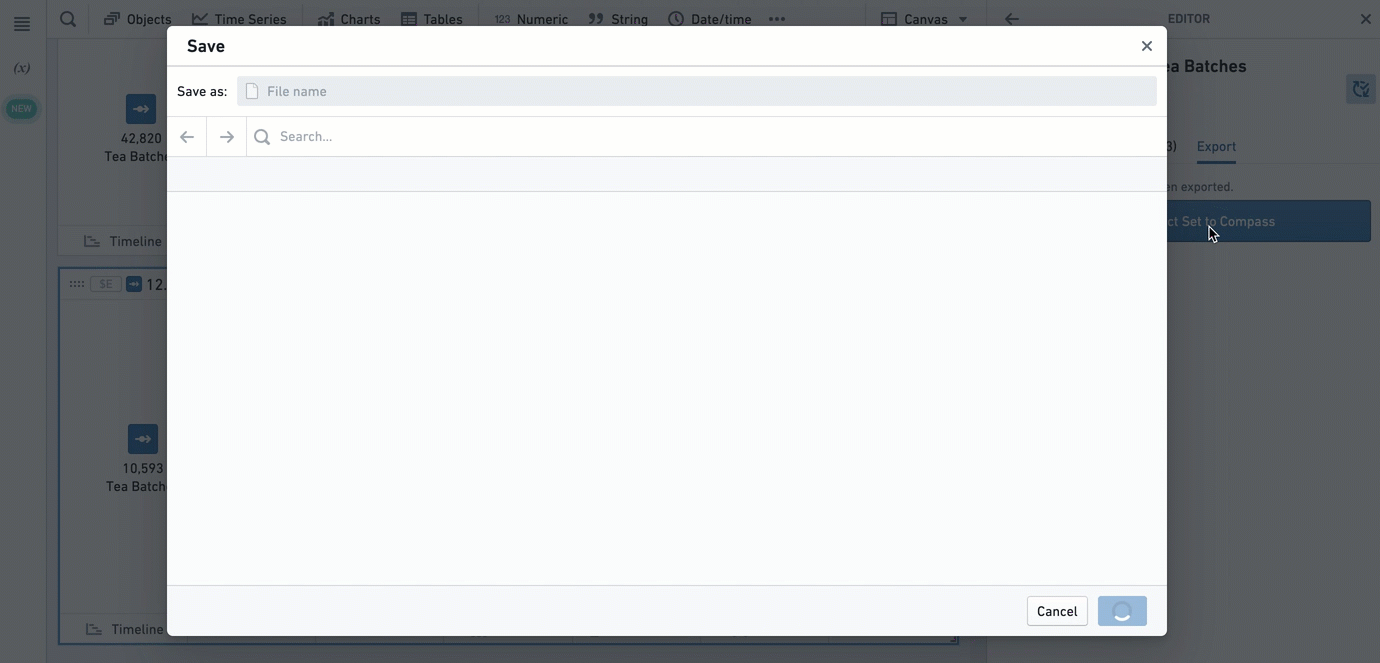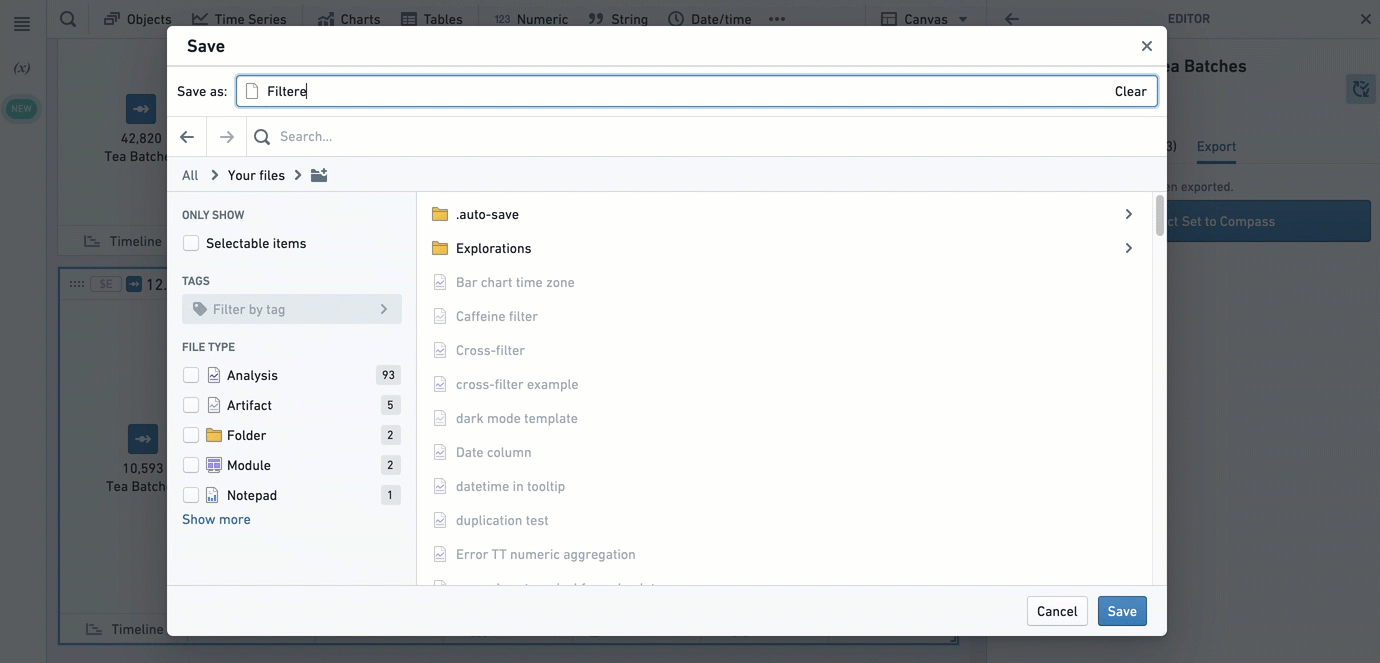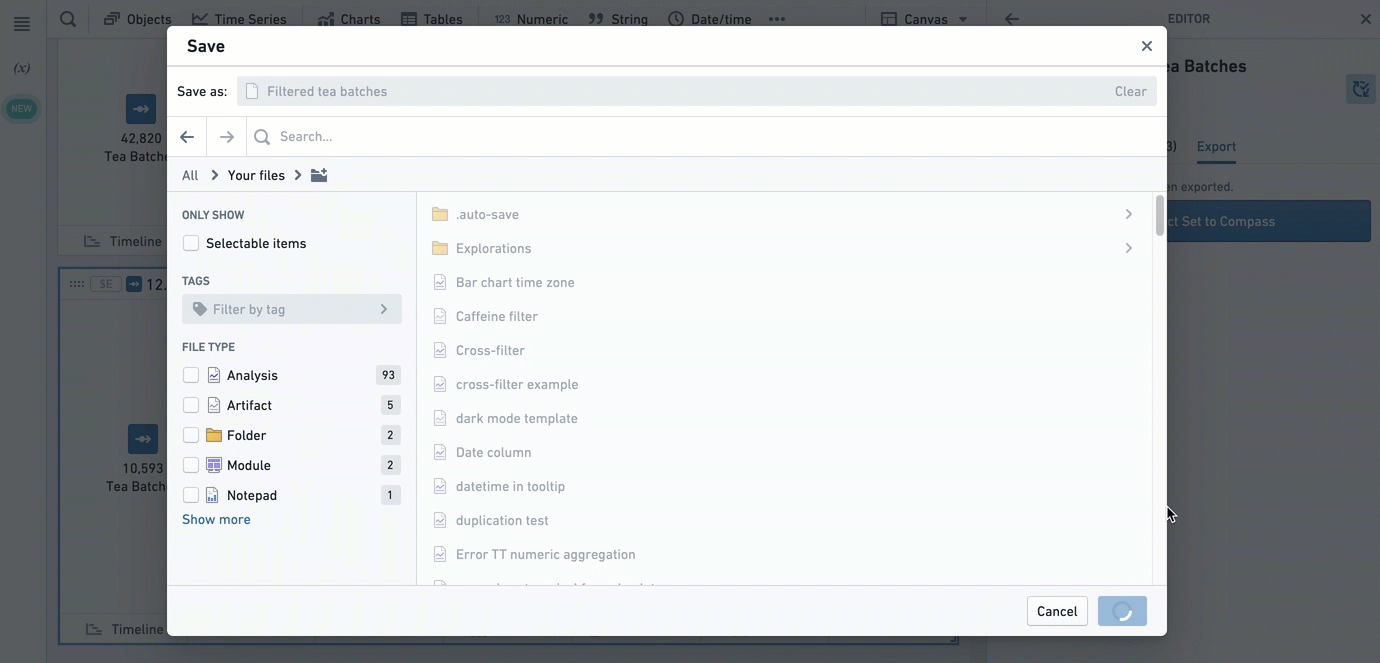
To import an object set, use the Import saved object reference card.
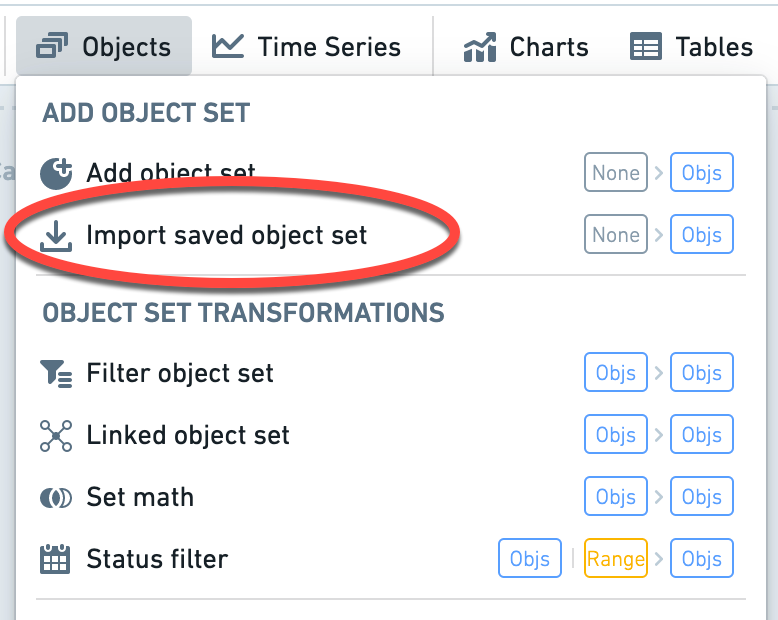
Read more on how to import and export object sets in Quiver.
Object sets can also be saved, updated, and compared in Object Explorer. Read more on how to save object sets in Object Explorer.