Bring your own model to AIP
Bring-your-own-model (BYOM), also known as "registered models" in the Palantir platform, is a capability that provides first-class support for customers who want to connect their own LLMs or accounts to use in AIP with all Palantir developer products. These products include AIP Logic, Pipeline Builder, Agent Studio, Workshop, and more.
When to use
Based on LLM support and viability, we generally recommend using Palantir-provided models from model providers (for example: OpenAI, Azure OpenAI, AWS Bedrock, xAI, GCP Vertex), or self-hosted open-source models by Palantir (such as Llama models).
However, you may prefer to bring your own models to AIP. We recommend using these registered models only when you cannot use Palantir-provided models for legal and compliance reasons, or when you have your own fine-tuned or otherwise unique LLM that you would like to leverage in AIP.
Support for registered models in the Palantir platform
The following table demonstrates which platform applications support registered models and their specific capabilities.
| Application | Supported | Caveats | Functional interfaces supported |
|---|---|---|---|
| AIP Logic | Yes | ChatCompletion, ChatCompletionWithVision | |
| Pipeline Builder | Yes | Provider must have REST endpoint, as function must be implemented with no webhooks. | ChatCompletion, ChatCompletionWithVision |
| Agent Studio/Threads | Yes | Streaming [Beta] | ChatCompletion, StreamedChatCompletion |
| Workshop AIP Interactive widget | Yes | Supported through Agents and AIP Logic, not for directly calling registered model. | Not applicable |
The following table details the capabilities available when using a registered model:
| Capabilities | Supported | Description | Notes |
|---|---|---|---|
| ChatCompletion | Yes | Text-only chat completion registered model function. | |
| StreamedChatCompletion | Yes | Text-only chat completion registered model function that streams back response. | |
| ChatCompletionWithVision | Yes | Support for images (base64 or media reference) as well as text in a chat completion BYOM function | Not streamed |
Considerations
Before you register your model for use with AIP, take note of the following important considerations:
- AIP features that are not listed in the tables above may not be compatible with registered models.
- Certain features are currently unsupported through registered models, but we anticipate adding more functionality. This includes specific LLM capabilities, such as embeddings, and AIP solutions like Python transforms and AIP Evaluation suite.
- There is no support planned for using the following features with registered models: all native assistant features such as AIP Assist, Code Assist, and Pipeline Builder's Generate and Explain assistant features.
Register and use your own model
To access an externally-hosted model, register an LLM using function interfaces first. You can then use your model in AIP Logic and Pipeline Builder.
Use model without configuring webhooks
The registered model workflow in Pipeline Builder does not yet support webhooks. However, you can instead make calls to external systems using direct source egress. To do this, you must have a REST source configured for your external system. Register an LLM using function interfaces first, then skip the section on configuring a webhook for your source.
Once you have a REST source, you can write a TypeScript function using the ChatCompletion functional interface. This step loosely mirrors the steps in the second part of the documentation on registering an LLM with a TypeScript function, but the repository imports and code will look a bit different without a webhook.
First, import your source and open the ChatCompletion functional interface in the sidebar:
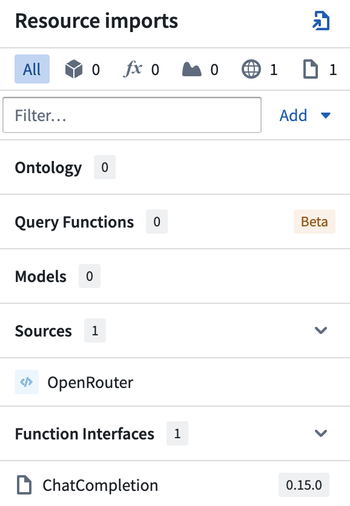
Then, your function signature should implement the @ChatCompletion and @ExternalSystems decorators:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13import { ExternalSystems } from "@foundry/functions-api"; import { MySourceApiName} from "@foundry/external-systems/sources"; import { ChatCompletion } from "@palantir/languagemodelservice/contracts"; import { FunctionsGenericChatCompletionRequestMessages, GenericChatMessage, ChatMessageRole, GenericCompletionParams, FunctionsGenericChatCompletionResponse } from "@palantir/languagemodelservice/api"; @ExternalSystems({sources: [MySourceApiName]}) @ChatCompletion() public async myFunction( messages: FunctionsGenericChatCompletionRequestMessages, params: GenericCompletionParams ): Promise<FunctionsGenericChatCompletionResponse> { // todo: implement function logic here }
Finally, implement your function logic to reach out to your externally-hosted model:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37import { ExternalSystems } from "@foundry/functions-api"; import { MySourceApiName} from "@foundry/external-systems/sources"; import { ChatCompletion } from "@palantir/languagemodelservice/contracts"; import { FunctionsGenericChatCompletionRequestMessages, GenericChatMessage, ChatMessageRole, GenericCompletionParams, FunctionsGenericChatCompletionResponse } from "@palantir/languagemodelservice/api"; @ExternalSystems({sources: [MySourceApiName]}) @ChatCompletion() public async myFunction( messages: FunctionsGenericChatCompletionRequestMessages, params: GenericCompletionParams ): Promise<FunctionsGenericChatCompletionResponse> { // You can access the source's URL const url = MySourceApiName.getHttpsConnection().url; // And the decrypted secret values stored on the source const token = MySourceApiName.getSecret("additionalSecretMySecretApiName"); // Make the external request with the fetch method to process the input messages. // You can also include any secrets required for auth here. const response = await MySourceApiName.fetch( url + '/api/path/to/external/endpoint', { method: 'GET', headers: {"Authorization": "Bearer ${token}"} }); const responseJson = await response.json(); if (isErr(responseJson)) { throw new UserFacingError("Error from external system."); } // Depending on the format of response returned by your external system, you may have to adjust how you extract this information from the response. return { completion: responseJson.value.output.choices[0].message.content ?? "No response from AI.", tokenUsage: { promptTokens: responseJson.value.output.usage.prompt_tokens, maxTokens: responseJson.value.output.usage.total_tokens, completionTokens: responseJson.value.output.usage.completion_tokens, } } }
With the decorators above implemented, you can start testing your function and proceed with the following steps:
- Tag and release a version.
- Create a pipeline in Pipeline Builder.
- Select your function-backed model from the user-provided models tab of the Use LLM model picker.