注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
ライブデプロイメントの設定と使用
ライブデプロイメントは、APIエンドポイントを介して対話できる、リリース用の永続的でスケーラブルなデプロイメントです。ライブデプロイメントは、バッチデプロイメントと一緒にモデリング目的で管理でき、自動アップグレード、監視可能性、権限構造のすべてのメリットを受けることができます。
要件
新しいライブデプロイメントを作成する前に、モデリング目的には対応するタグ(Staging または Production)を持つ既存のリリースが含まれている必要があります。
一部の環境では、TypeScript Functions がライブデプロイメントを通じて利用可能なサポートが提供されています。ライブデプロイメントでTypeScript Functionsを使用する方法について詳しく学ぶ。
デプロイメントの作成
新しいライブデプロイメントを作成するには、モデリング目的の下部にあるデプロイメントセクションに移動し、青い**+ デプロイメントを作成**ボタンを選択します。
デプロイメント名、説明、このデプロイメントが現在のステージングまたはプロダクションリリースモデルに基づくべきかどうかを入力します。設定が完了したら、デプロイメントを作成をクリックします。
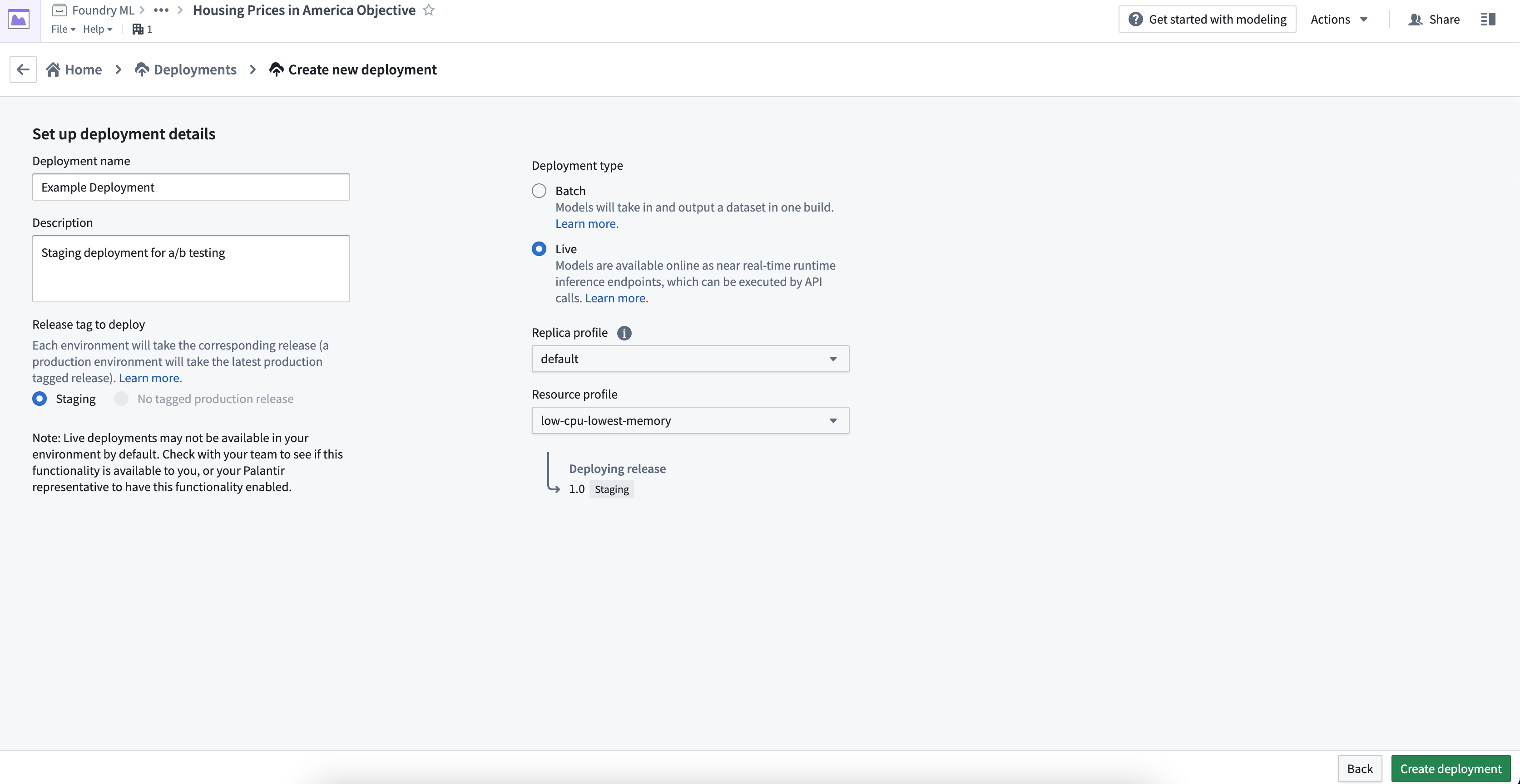
新しく作成されたデプロイメントを選択して詳細を開くと、最新のリリースおよび推論コードが含まれたコンテナイメージがデプロイされていることを示す中間ステータスが表示されます。
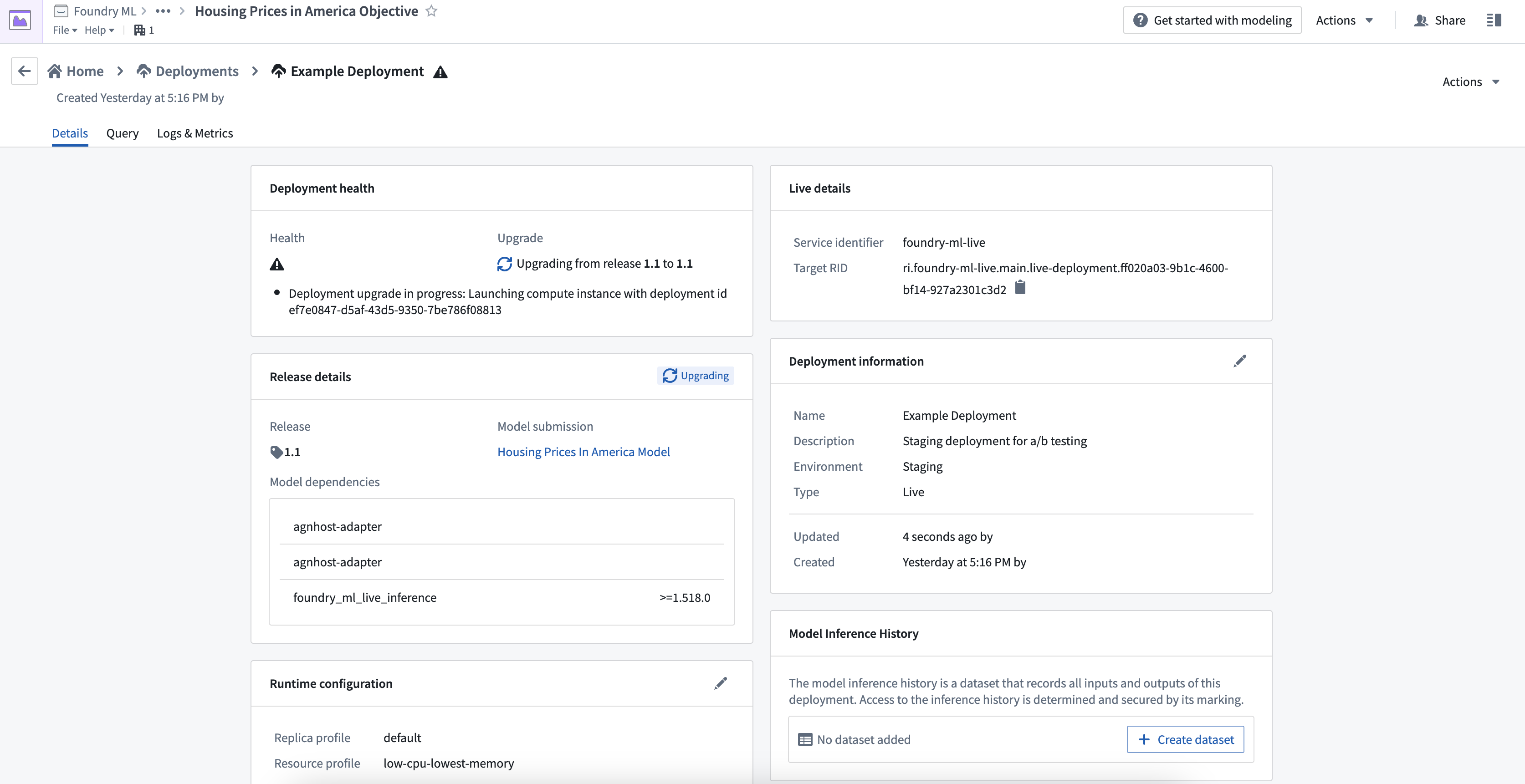
API名
モデル上のFunctionsでモデルを運用化するには、デプロイメントのAPI名を定義する必要があります。API名は、デプロイメントが存在するネームスペース内で一意である必要があります。API名を定義するには、API名の隣にある鉛筆アイコンを選択します。
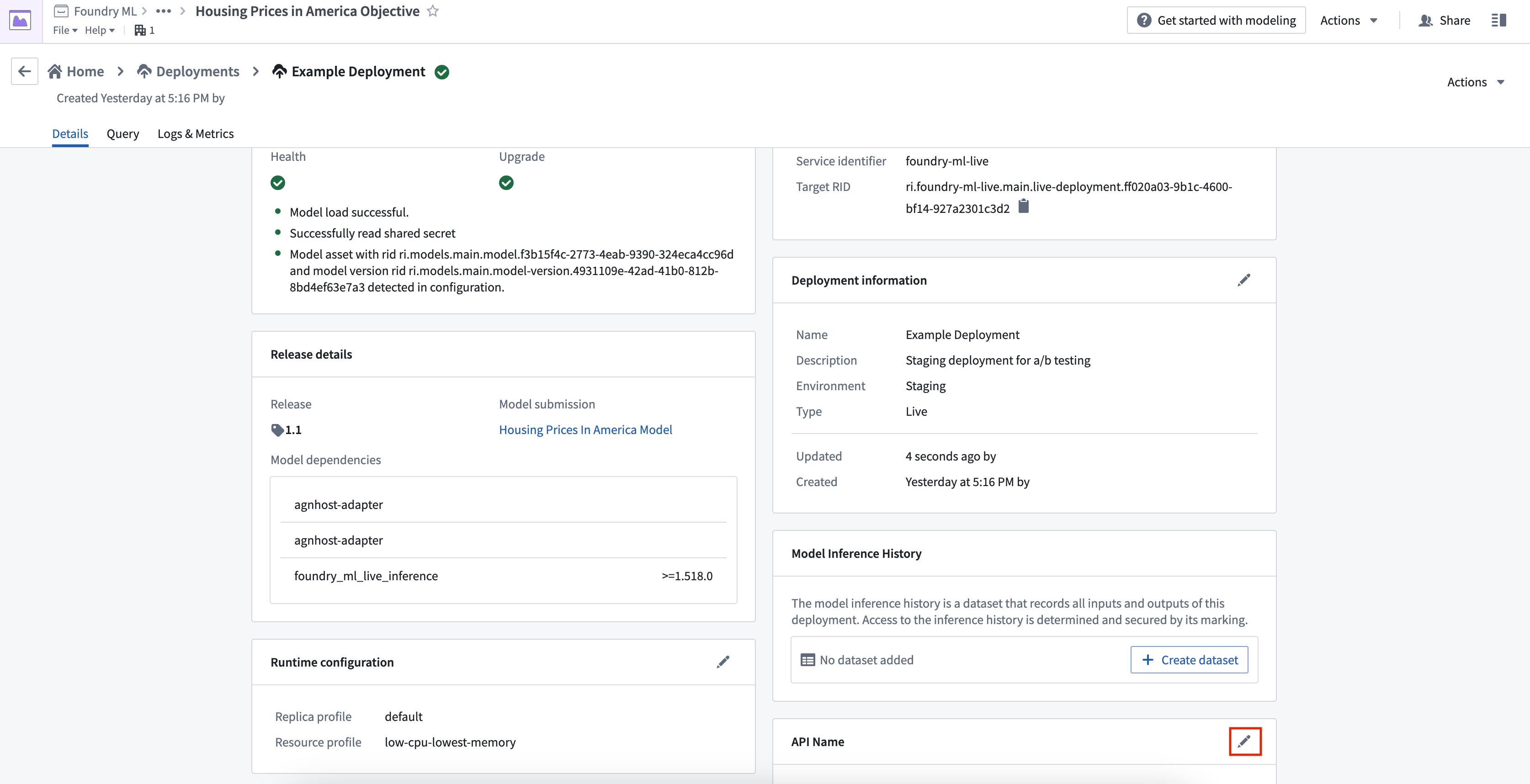
ステータスと健康状態
デプロイメントの更新が完了すると、ステータスと健康状態の両方が緑色のチェックマークとして表示されます。これらは、デプロイメントがクエリの準備ができており、最新のリリースモデルが正常に含まれていることを示しています。

ライブデプロイメントのテスト
デプロイメントの詳細ページのクエリタブに移動して、ライブデプロイメントエンドポイントをテストできます。入力リクエストを作成し、ライブエンドポイントに送信し、モデル出力応答を表示できます。単一 I/O と複数 I/O の2種類のクエリタイプが利用可能です。
単一 I/O クエリは、単一の表形式の入力/出力のみをサポートしています。一方、複数 I/O クエリは、モデルアセットで定義されているModelAdapter APIのみをサポートしています。モデルアセットは、単一 I/O と複数 I/O の両方のクエリタイプをサポートしていますが、データセットを利用したデプロイメントは、単一 I/O クエリのみをサポートしています。
例コマンド
以下は、単一 I/O を使用して curl を介してライブデプロイメントをクエリする方法の例です。変換エンドポイントを使用します。
Copied!1 2 3 4 5 6 7 8 9 10 11# 以下のコマンドは、機械学習モデルによる推論をリクエストするために使用されます。 # -X POST: POSTリクエストを送信します。 # -H: ヘッダーに情報を追加します。 # -d: データを指定します。 curl -X POST https://<URL>/foundry-ml-live/api/inference/transform/ri.foundry-ml-live.main.live-deployment.<RID> -H "Authorization: <BEARER_TOKEN>" # 認証トークンを設定します。 -H "Accept: application/json" # 応答のフォーマットをJSONとして受け入れます。 -H "Content-Type: application/json" # リクエストのデータ形式をJSONとして指定します。 -d # リクエストデータとパラメータを指定します。 '{"requestData":[{"house-location":"New York", "bedrooms":3,"bathrooms":1.5}], "requestParams":{}}'
また、以下の例は、transformV2エンドポイントを使用したマルチI/Oを使用してcurlを使ってライブデプロイメントをクエリする方法を示しています:
Copied!1 2 3 4 5# 以下のコマンドは、APIにリクエストを送信して、住宅価格の予測を取得します。 curl -X POST https://<URL>/foundry-ml-live/api/inference/transform/ri.foundry-ml-live.main.live-deployment.<RID>/v2 -H "Authorization: <BEARER_TOKEN>" -H "Accept: application/json" -H "Content-Type: application/json" -d '{"input_df":[{"house-location":"New York", "bedrooms":3,"bathrooms":1.5},{"house-location":"San Francisco", "bedrooms":2,"bathrooms":1}]}' # 上記のコードでは、入力として2つの家の情報(場所、ベッドルーム数、バスルーム数)を渡しています。
デプロイメントのアクション
管理アクション
実行中のライブデプロイメントに対して行うことができる2つのオプションがあります。
- 無効化 は、デプロイメントを停止させるもので、ターゲット RID をそのまま利用して再度有効化できるようにします。
- 削除 は、デプロイメントを完全に削除するもので、古いターゲット RID はもうクエリできなくなります。
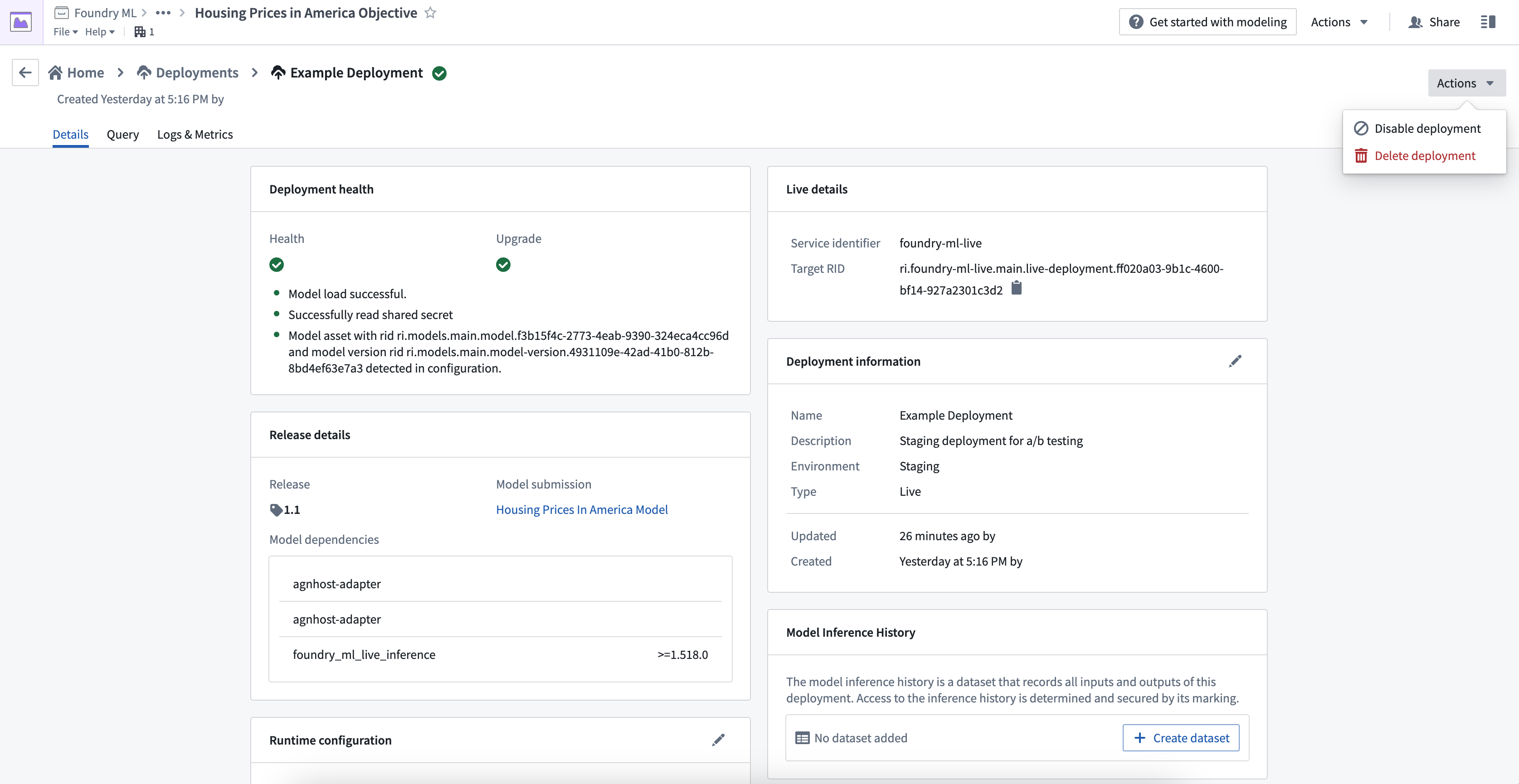
無効化されたライブデプロイメントは、目標のデプロイメントページに表示され続け、再度有効化できる状態になります。

リソースの設定
ライブデプロイメントは、レプリカプロファイルとリソースプロファイルの両方で構成されます。レプリカプロファイル は、使用する同時レプリカの数を指定します。リソースプロファイル は、それぞれのレプリカが作成される際に割り当てられる VCPU/RAM/GPU の量を決定します。
デプロイメントの作成時にプロファイルを設定することも、後から編集することもできます。ランタイム設定を編集すると、自動的にデプロイメントが再実行され、エンドポイントがダウンタイムなしでアップグレードされます。
新しいライブデプロイメントを設定するには、デプロイメントの作成 を選択し、デプロイメントタイプ の下で ライブ を選択し、レプリカプロファイルとリソースプロファイルを選択します。
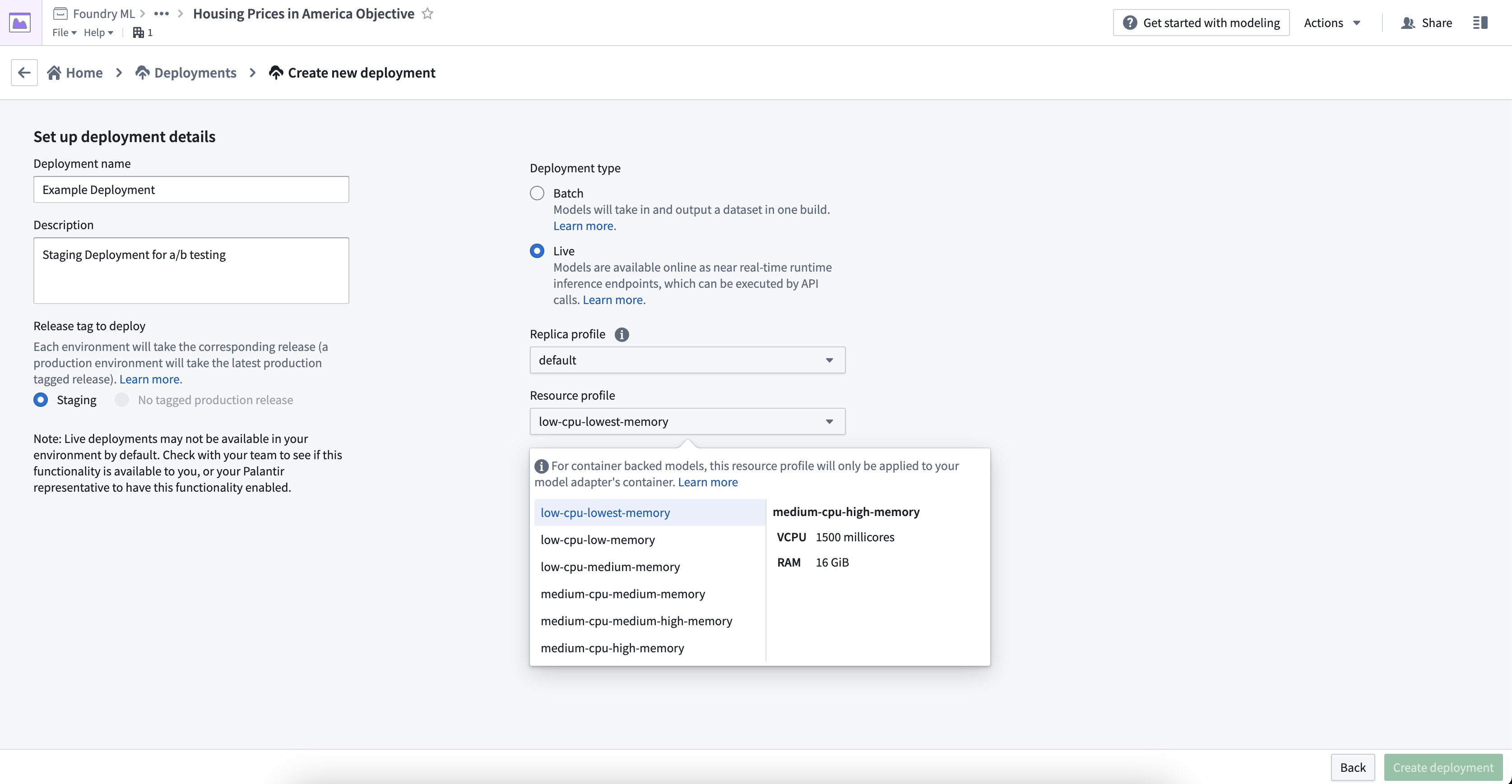
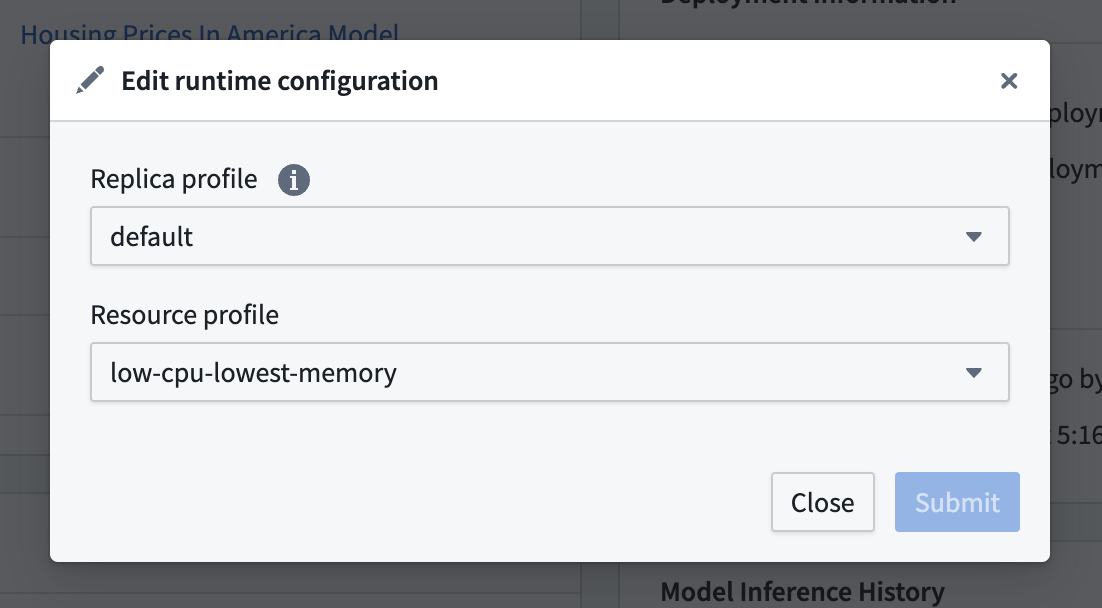
設定されたレプリカプロファイルとリソースプロファイルを編集するには、モデリングプロジェクトの デプロイメント セクションに移動し、リストされたデプロイメントからデプロイメントを選択し、ランタイム設定 の下の編集ボタンを選択してプロファイルを編集します。
デプロイメントサービスログの表示
各ライブデプロイメントからは、デプロイメントの起動進行状況を説明する一連のログが出力されます。これらのログには、デプロイメントがダウンロードしてインストールしようとするリリース環境の Conda パッケージの URI や、モデル自体のダウンロードに関する詳細が含まれます。デプロイメントが正常に起動できなかった場合、何が起こったかを理解するのに役立つ警告やエラーレベルのログがあるかもしれません。
実行中のライブデプロイメントからサービスログを直接表示するには、デプロイメント詳細ページの ログ & メトリクス タブに移動します。検索範囲として時間を指定したり、フィールドごとにログをフィルター処理したり、表示から行を追加したり削除したりすることができます。また、右上のダウンロードボタンを使って、すべてのログをテキストファイルとしてダウンロードすることもできます。
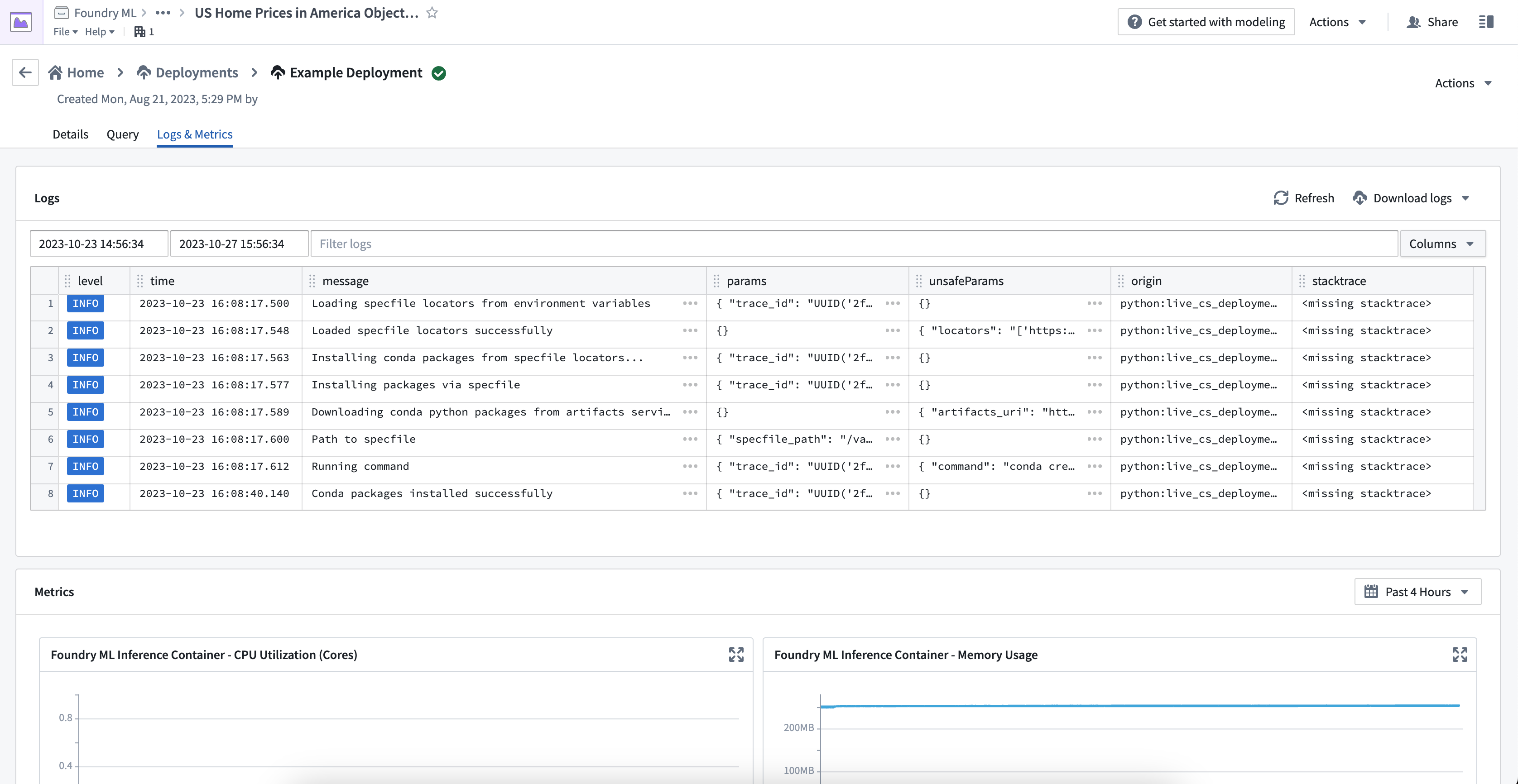
デプロイメントを 複数のレプリカ で実行するように設定している場合、同じようなログが複数表示されることがあります。ただし、それぞれのログには一意の node_id がタグ付けされており、必要に応じてレプリカごとにフィルター処理することができます。以下のような表記を使用してください。
Copied!1tags.node_id:{ここにUUIDを挿入してください}
このコードは、特定のノードIDをタグに関連付けるためのものです。UUID(Universally Unique Identifier)は、ユニバーサルユニーク識別子のことで、全世界で一意の識別子を生成することが可能です。このUUIDを指定することで、特定のノードを一意に識別し、操作することができます。 モデルからログを直接出力するには、標準の python logging モジュールを使用できます。ライブデプロイメントでは、各ログ行を Logs & Metrics タブ内からクエリできるようになります。
Copied!1 2 3 4 5 6 7import logging # 'model-logger'という名前のロガーを作成します。 log = logging.getLogger('model-logger') # モデルから直接情報を出力する。 log.info("Emitting info directly from the model")
コンテナを利用したモデルからログを出力するには、モデルバージョンの設定でテレメトリを有効にしてください。
ユーザーのライブデプロイメントからのログは、7日間保持され、その後は閲覧やダウンロードができなくなります。
デプロイメントメトリクスの表示
ログ & メトリクスタブには、Kubernetes ホストと推論コンテナという2種類のメトリクスがあります。モデルを適切に監視およびデバッグするには、これらのメトリクスタイプの違いを理解してください。
Kubernetes ホストメトリクス
Kubernetes ホストメトリクスは、特定のモデルに関連するプロセスだけでなく、ホスト上で実行されているすべてのプロセスによって使用されるメモリと CPU 使用率の割合を示します。これらのメトリクスは、スケジューリングやリソース制限に関連する問題をデバッグするために重要です。例えば、ユーザーのモデルのパフォーマンスが遅いが、ホストメトリクスが100%になっている場合、モデルはKubernetes ホストによって制限されている可能性があります。
推論コンテナメトリクス
推論コンテナメトリクスは、Python モデルやモデルアダプタロジックのリソース使用状況をデバッグするのに役立ちます。これらのメトリクスは、推論コンテナの正確なメモリ使用量と CPU コア使用量を提供し、Kubernetes ホスト全体とは独立しています。現在、コンテナベースのモデルの使用メトリクスは利用できません。
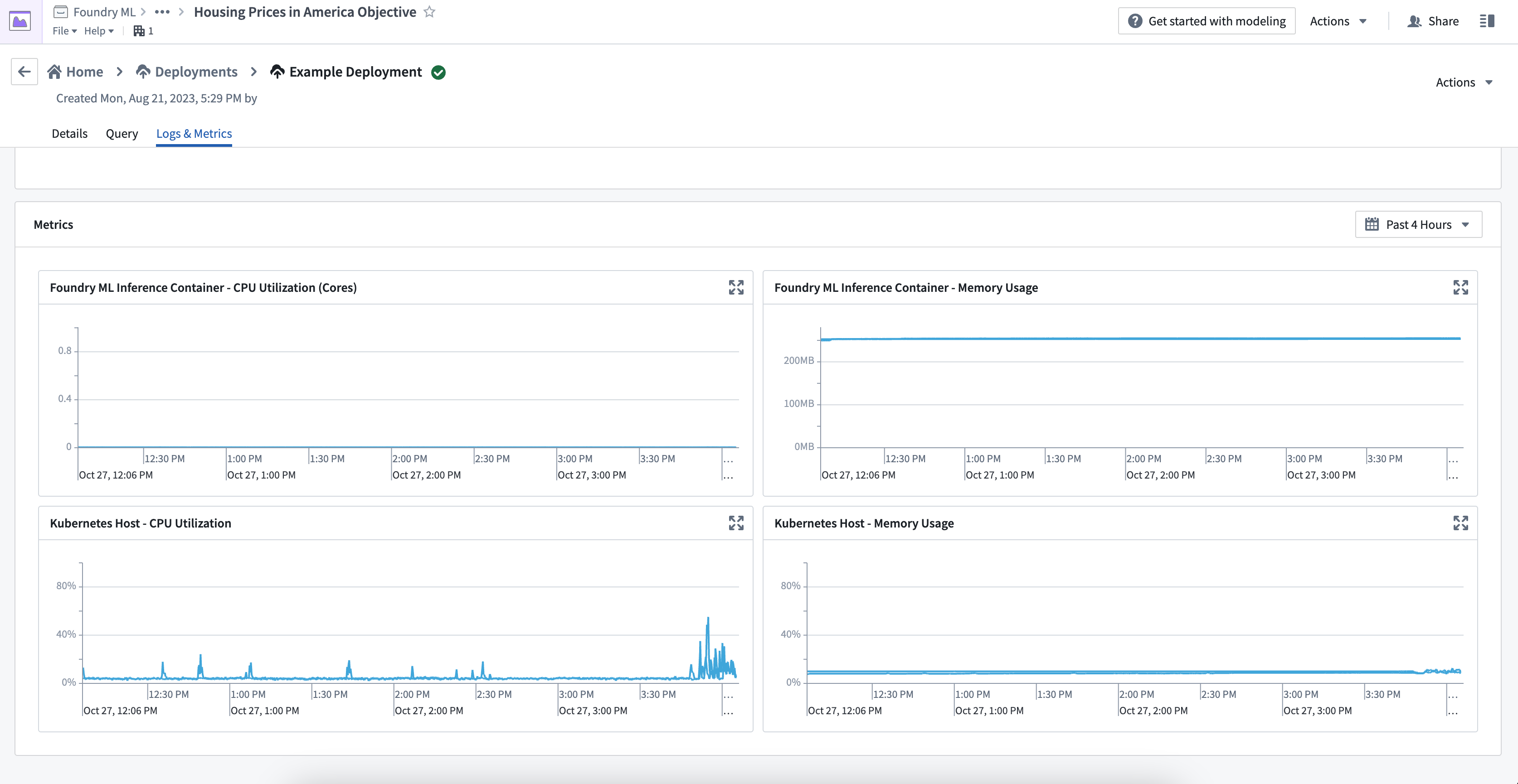
Kubernetes ホストメトリクスのみを表示できて、推論コンテナメトリクスが表示できない場合、ユーザーのコンテナはライブデプロイメントの古いバージョンで実行されている可能性があります。ライブデプロイメントを再起動してバージョンを更新し、すべてのメトリクスを表示してください。
Spark モデルのサポート
サポートされている Spark バージョンは今後のバージョンで変更される可能性があり、後方互換性は保証されません。ユーザーのモデルが現在の Spark バージョンと互換性がない場合、再構築が必要になることがあります。
すべてのライブデプロイメントは、JDK と Spark のディストリビューションがインストールされた状態で初期化されます。これにより、Spark モデルがライブデプロイメントと互換性を持つようになります。このインタラクティブな環境では、ローカル Spark のみがサポートされており、すべての処理は単一の JVM 内で行われます。
ライブデプロイメントでは、入力と出力のタイプが Pandas のデータフレームであることが期待されているため、foundry_ml Python ライブラリは、モデルが標準のサポートされている PySpark モデルである限り、ユーザーの Spark モデルをラップします。データフレームをどちらかの方向に変換する際に、特にカスタム Spark タイプを扱う際に、データタイプの変換の問題が発生する可能性があります。
Spark データフレームを想定したカスタムモデルを開発する際には、事前処理ステージや transform関数内で、手動でこの変換を行う必要があります。これについては、以下の簡単な例があります:
Copied!1 2 3 4 5 6 7 8 9import pandas as pd from pyspark.sql import SparkSession def _transform(model, df): # dfがpandas DataFrameのインスタンスであれば、Spark DataFrameに変換します。 if isinstance(df, pd.DataFrame): df = SparkSession.builder.getOrCreate().createDataFrame(df) # モデルを使用してSpark DataFrameの予測を行います。 return model.predict_spark_df(df)