注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
バッチデプロイメントの設定
バッチデプロイメントは、モデルを通じてデータを実行し、結果をFoundryデータセットに出力する特別なパイプラインを、モデリング目的の中に設定することができます。これらの出力データセットは、ビルドスケジュールで管理することができます。
前提条件
新しいバッチデプロイメントを作成する前に、以下の2つの前提条件があります。
-
ステージングまたはプロダクションの環境タグが対応する既存のリリースが、目的の中に存在している必要があります。
-
モデルを実行するための入力データセットを選択します。このデータセットは、注意深く管理され、定期的に更新されるべきです。これは、解決しようとしている問題の新しい情報を表します。
デプロイメントの作成
新しいバッチデプロイメントを作成するには、モデリング目的のホームページの下部にあるDeploymentsセクションに移動し、右上の**+ Create deployment**を選択します。
プロンプト内の詳細と関連情報を入力します。要件#1に基づいてデプロイメント環境を選択し、要件#2で決定した入力データセットを選択し、出力データセットの場所と名前を選択します。また、新しい出力データセットを作成する代わりに、既存のデータセットを出力データセットとして選択することもできます。
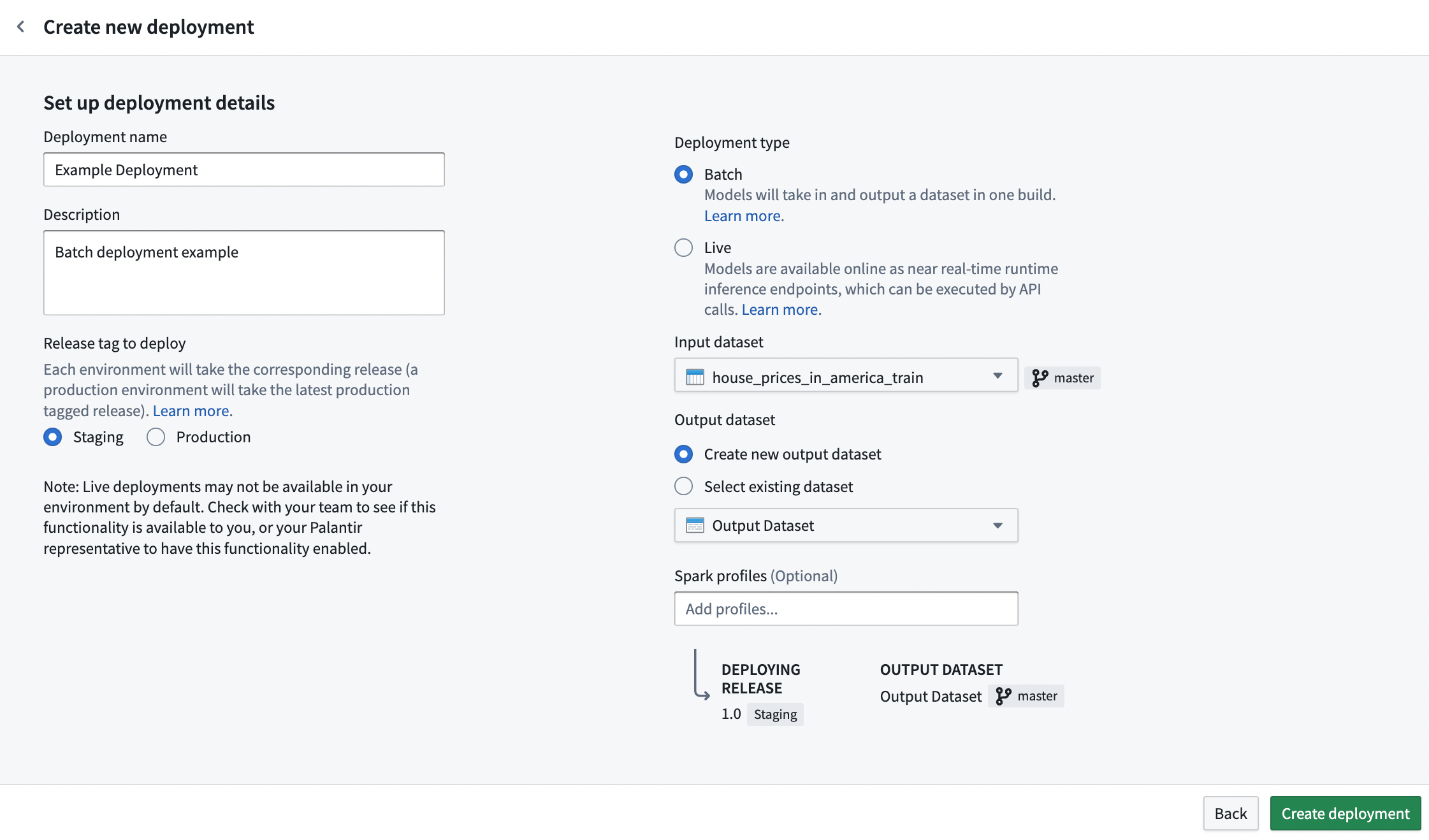
リソース設定
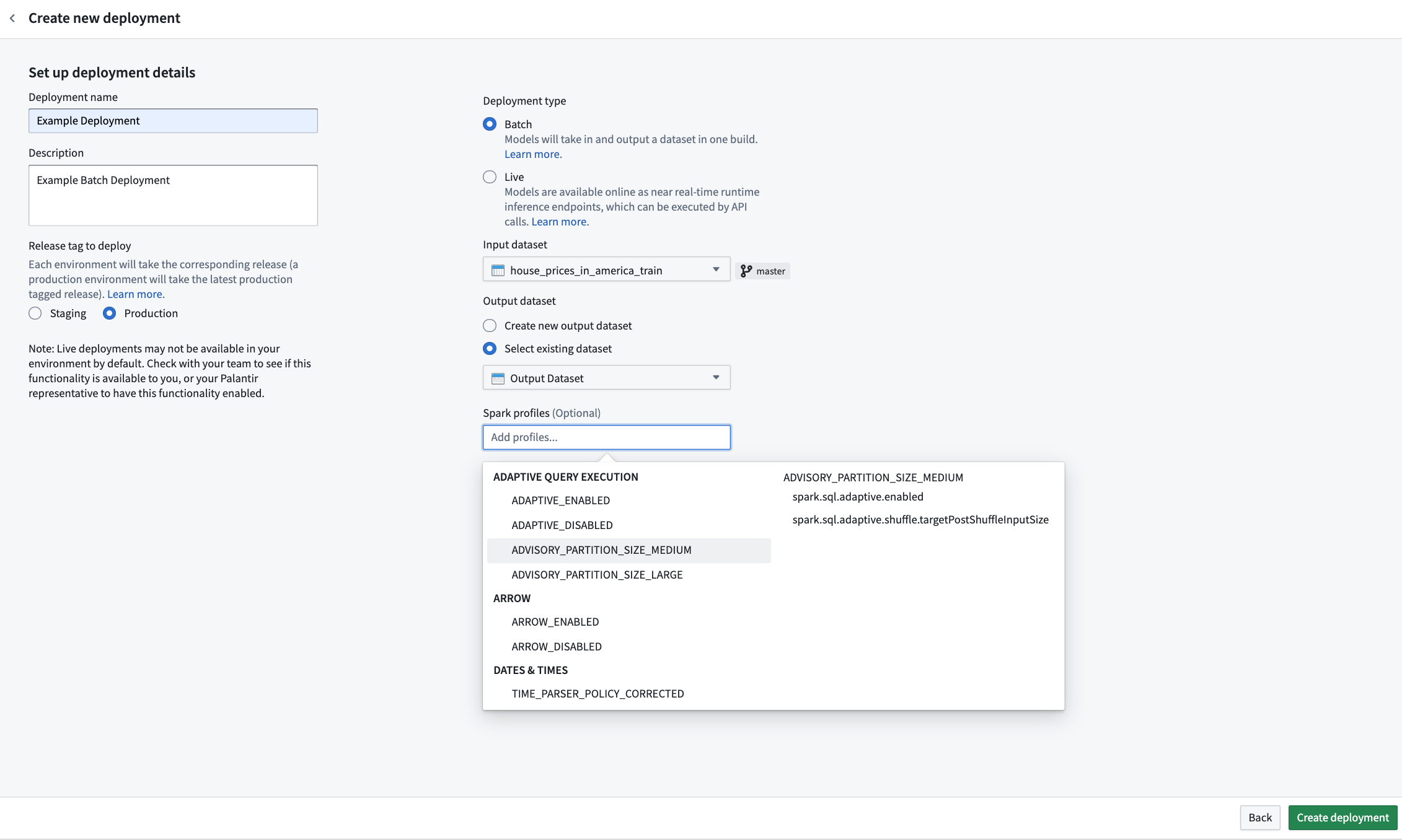
新しいバッチデプロイメントを作成する際に、その個別のデプロイメントに必要なリソースを設定することができます。リソースは、Sparkプロファイルを介して設定され、推論中にSpark環境に適用されます。
新しいバッチデプロイメントを作成する場合、初期デプロイメント設定時にSparkプロファイルセレクタが表示されます。この動作はPythonトランスフォームと同じです。省略された場合、デプロイメントにSparkプロファイルが設定されず、デフォルトのリソースプロファイルが使用されます。
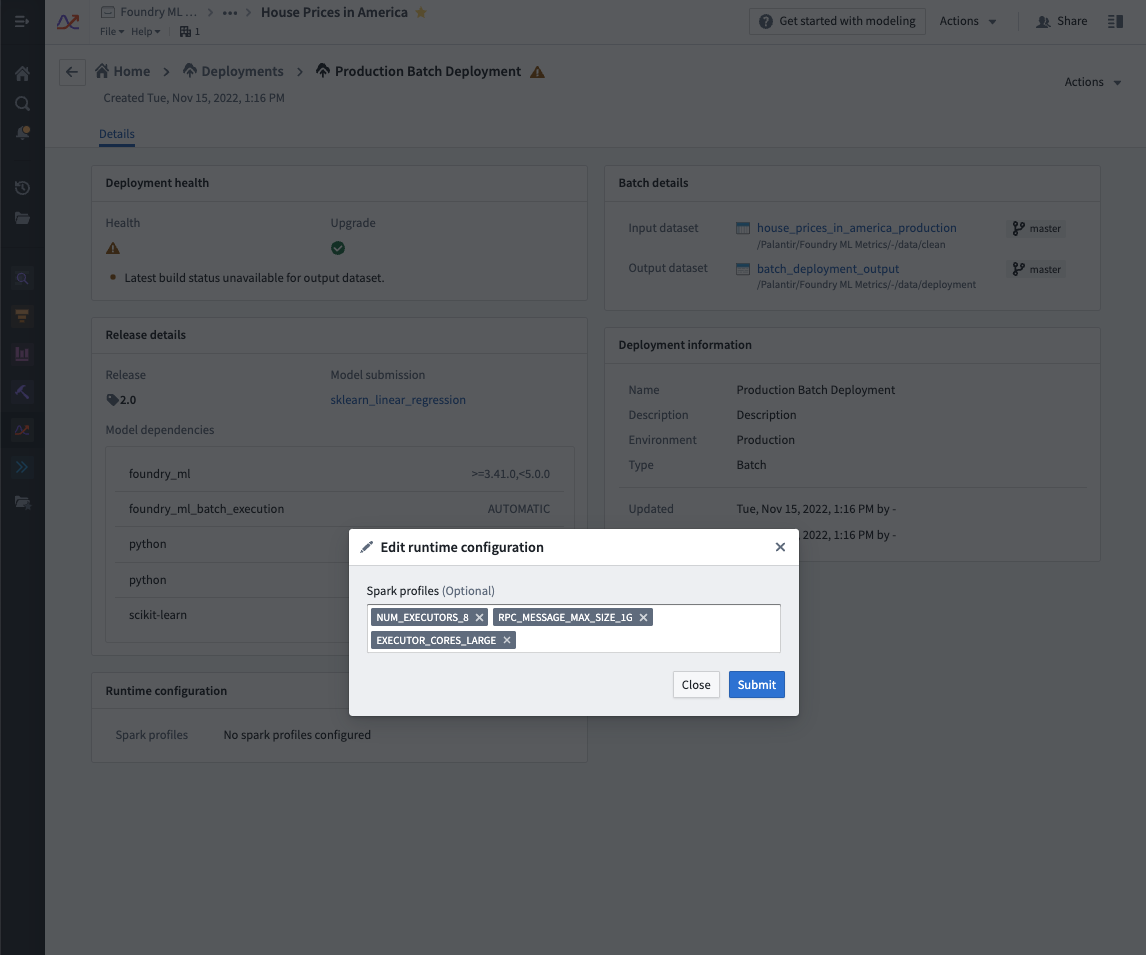
既存のバッチデプロイメントで設定されたSparkプロファイルを編集するには、モデリング目的のDeploymentsセクションに移動し、リストされたデプロイメントからデプロイメントを選択し、Runtime configurationの下の編集ボタンを選択してSparkプロファイルを編集します。これにより、デプロイメントが自動的に更新されます。
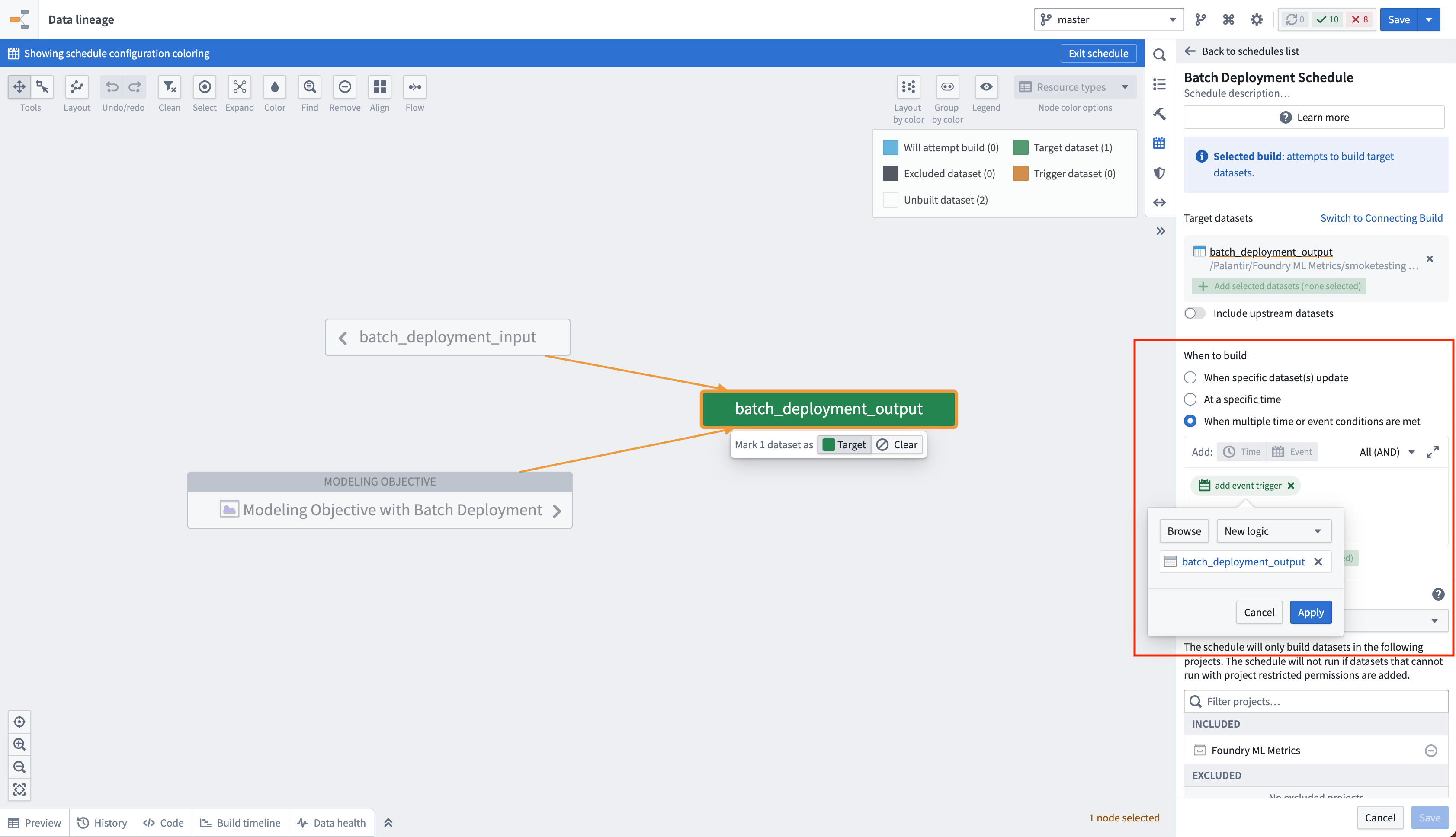
デプロイメント出力の自動ビルド
デプロイメントビューに移動するには、新しいデプロイメントを選択します。
出力データセットに移動するには、デプロイメント詳細ビューのデータセットリンクを選択します。
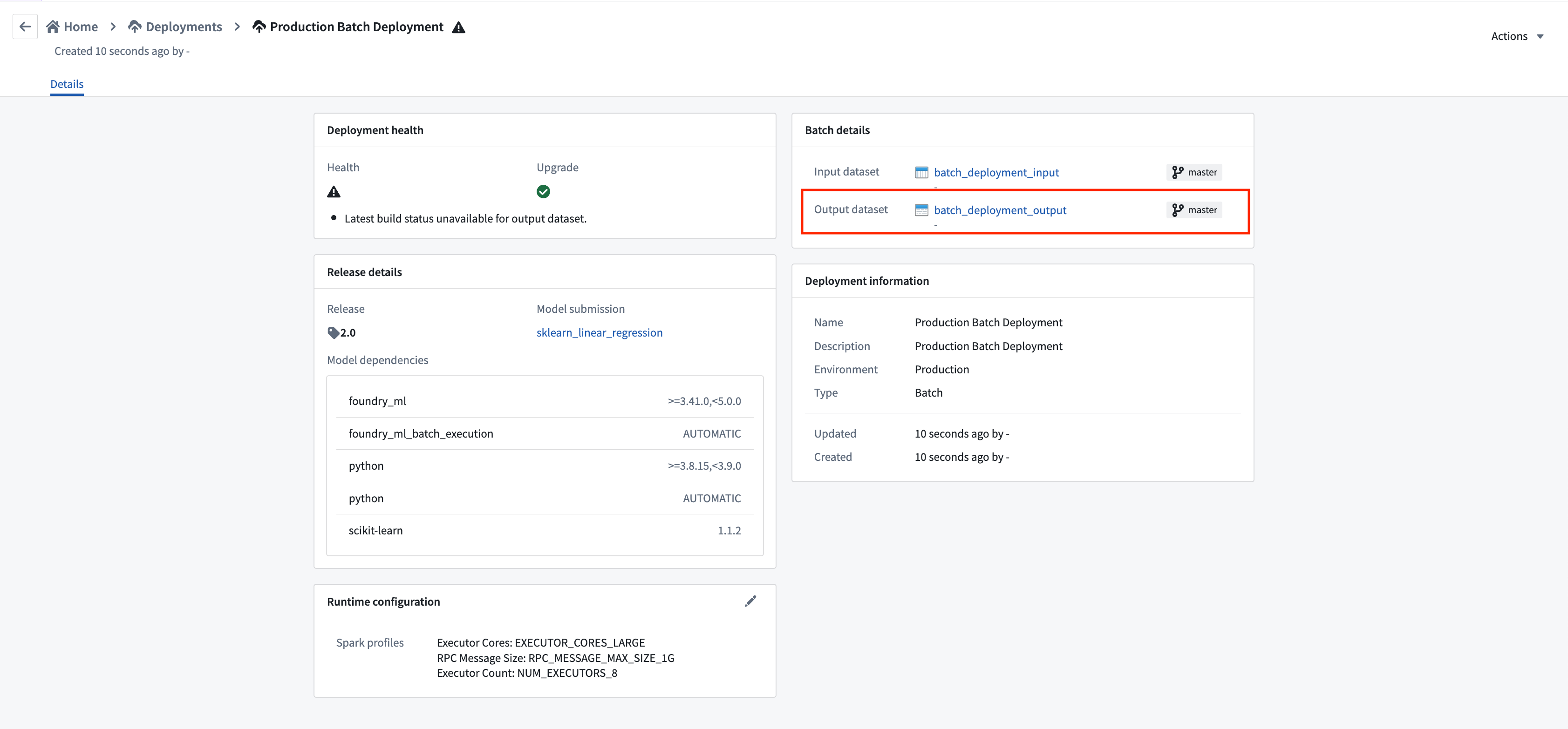
バッチデプロイメントの出力データセットにスケジュールを作成することで、新しいモデルがそのデプロイメント環境にリリースされるたびに自動的に更新されるようにすることができます。これは、データセットのロジックが更新されるたびに出力データセットをビルドする新しいロジックスケジュールを作成することで実現されます。目的で新しいモデルがリリースされると、出力データセットのロジックが更新され、このスケジュールがトリガーされます。