注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
1 - このコースについて
learn.palantir.com ↗でも以下の内容をご覧いただけますが、アクセシビリティの観点から、ここに掲載しています。
Foundry のオントロジーは、組織にとって重要なエンティティ、イベント、プロセスの「デジタルツイン」です。このセマンティックオブジェクトレイヤーは、ユーザーとユーザーの同僚が運用的で相互運用可能なアプリケーションを構築するために使用できる一貫した API を提供します。以下の Data Lineage の画像では、Foundry のオントロジーで [Example Data] Flight オブジェクトタイプが少なくとも 2 つの運用アプリケーション(Data Lineage で「モジュール」とラベル付けされている)で使用され、航空機やフライトアラートなどの他のオブジェクトタイプにリンクしていることがわかります。
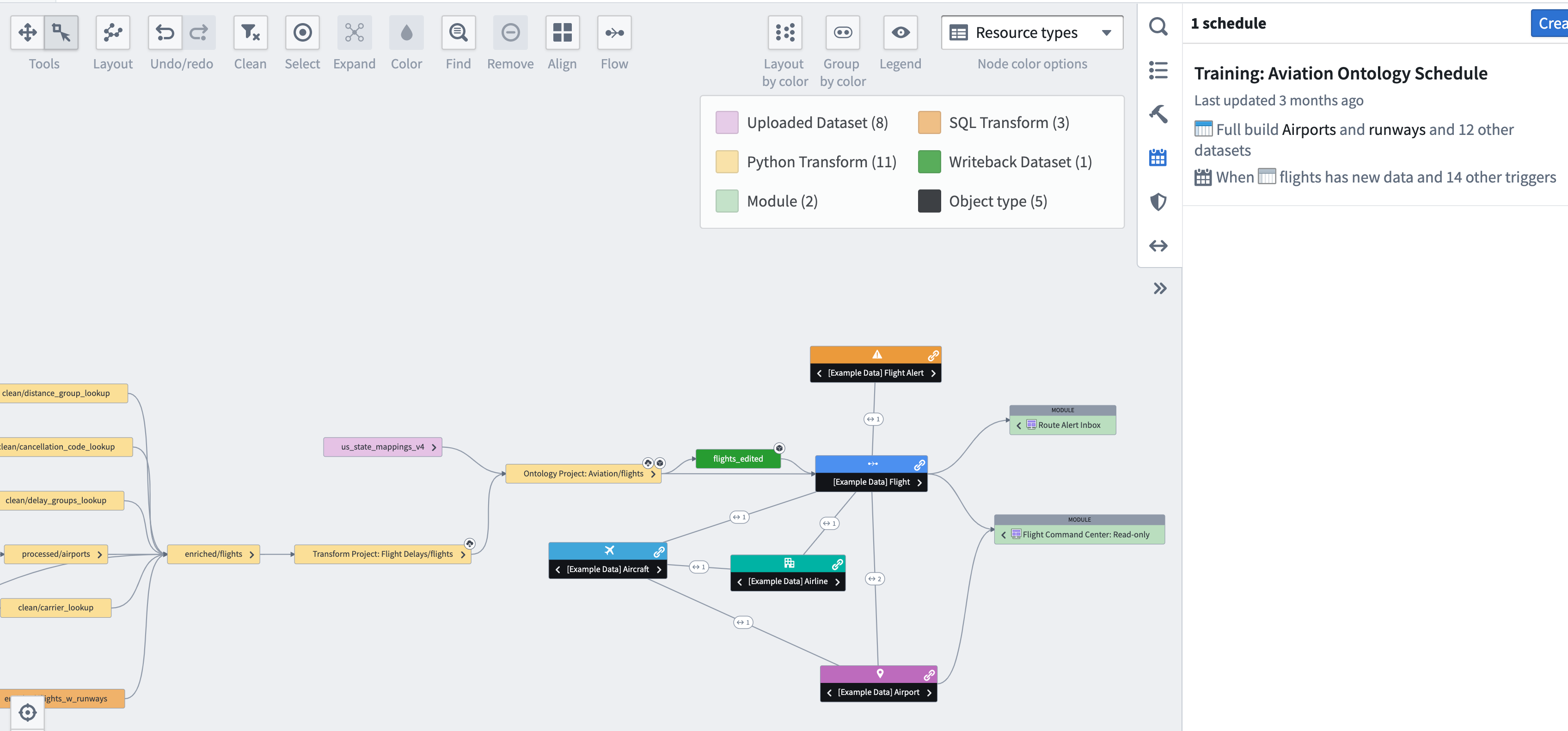
また、このグラフでは [Example Data] Flight オブジェクトタイプがデータセットに「バックアップ」されており、そのデータセットはスケジュールされたビルドの出力です。このフローは、このチュートリアルの中心テーマを示しています: データエンジニアは、アプリケーションビルダーの同僚と密接に協力して、Foundry のオントロジーオブジェクトやリンクの基礎となるパイプラインとデータセットを作成する必要があります。
⚠️ コースの前提条件
- DATAENG 07: データ期待値の設定: このトラックの前のコースをまだ完了していない場合は、今すぐそれを行ってください。
- ユーザーの組織のオントロジーを編集するための必要な権限。承認が必要な場合は、プログラム管理者またはPalantir Supportに連絡してください。
成果
データパイプラインは孤立した作成物ではありません。それらは常に何かの目的のために作成されます。このトレーニングでは、私たちのパイプラインの目的は、リンクしたオントロジーオブジェクトタイプをバックアップするためのデータセットを準備することです。ユーザーは、オントロジーの設定とパイプラインの更新を手掛ける実践を行い、元データセットを最適化し、それらをユーザーのオントロジーの形状を変えるような上流データの変更に対して回復力を持たせます。最後に、一連の演習で一般的なトラブルシューティングのステップを学びます。
学習の目的
- オントロジーの基本的な概念、基本的なユースケース、および設計上の決定を理解する。
- Object Explorerでオブジェクトタイプを検索し、フィルター処理する。
- Ontology Managerで新しいオブジェクトタイプとリンクタイプを作成する方法を知る。
- 元データセットをオントロジーで使用するために、ベストプラクティスに従って最適化する。
- パイプラインにチェックを適用して、オブジェクトタイプが上流データの変更に対して回復力を持つことを確認する。
- オントロジーのストレージと取得アーキテクチャを理解する。
- "書き戻し"とそのデータパイプラインにおける位置づけについて、経験に基づく理解を深める。
- 一般的なオントロジー同期問題のトラブルシューティングを練習する。
💪 Foundry のスキル
- Object Explorer を使用して、オントロジーを検索、フィルター処理し、一般的に理解する。
- Ontology Manager を使用して、オントロジーオブジェクトタイプとリンクタイプを作成および編集する。
- パイプライン変換を更新して、元データセットをオントロジーのバックエンドと同期させるために最適化する。
- "書き戻し"データセットを作成し、それをユーザーのデータパイプラインに配置する。
- オントロジー管理アプリケーションのオブジェクトストレージインターフェースを通じて、スキーマの追加と破壊的な変更を収容する。