注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
29 - 加算の元データセットの変更:パート 1
このコンテンツは learn.palantir.com でも以下の内容をご覧いただけますが、アクセシビリティの観点から、ここに掲載しています。
📖 タスクの概要
この演習では、元データセットとオントロジーの設定の変更に関連する2つの主要なシナリオに対応する方法を学びます。
- ユーザーの元データセットへの加算変更。
- ユーザーの元データセットへの破壊的な変更。
乗客オブジェクトタイプのタイトルキーは、単純に乗客の姓です。元データセットに full_name という新しい行を作成し、それをタイトルキーと交換しましょう。そうすることで、元データセットが新しい行を受け取ったときにオントロジーの同期プロセスで何が起こるかを確認します。
🔨 タスクの説明
-
ユーザーの
ontology_flight_alerts_logicパイプライン作成物を開きます。- ⚠️ このような変更を行うときは通常
Mainからブランチを作成したいところですが、便宜上、ユーザーは直接Mainに変更を加えます。
- ⚠️ このような変更を行うときは通常
-
passengers_cleanにfirst_nameとlast_nameを空白で区切って結合する 文字列の結合 変換を追加し、新しい行をfull_nameと呼びます。- 2つのノードの間に変換を追加することができます。ノード間の
+サインをクリックするか(下の画像参照)、後で各ノード接続の端にある白と灰色の円を通じてノードの入力と出力を変更することによります。
- 2つのノードの間に変換を追加することができます。ノード間の
-
ユーザーの変換ノードに名前を付けることを検討します(例えば、"Concat Names")。
-
変更を適用し、プレビューします。
-
パイプライングラフに戻り、ユーザーの変換ノードに色を付け、下の画像に示すように
passengersの出力が入力スキーマを使用するように変更します。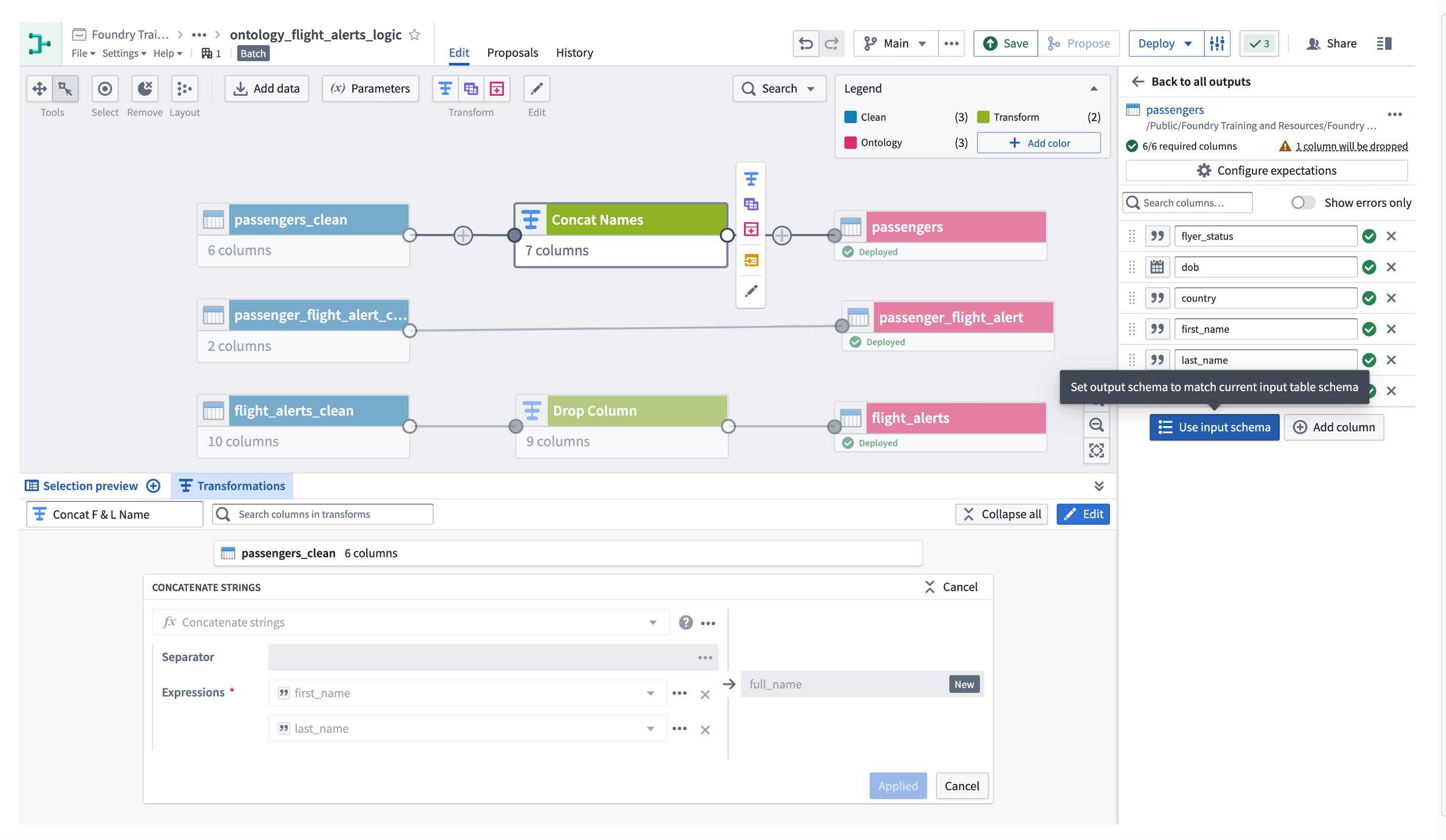
-
パイプラインをデプロイします。
-
データセットのビルドが完了したら、出力
passengersデータセットを開き、下の画像に示すように 詳細 タブの 同期 セクションに進みます。ここでは、スキーマの変更にもかかわらず、データセットとオブジェクトストレージサービス(別名 "Phonograph")間の同期が成功したことが確認できます。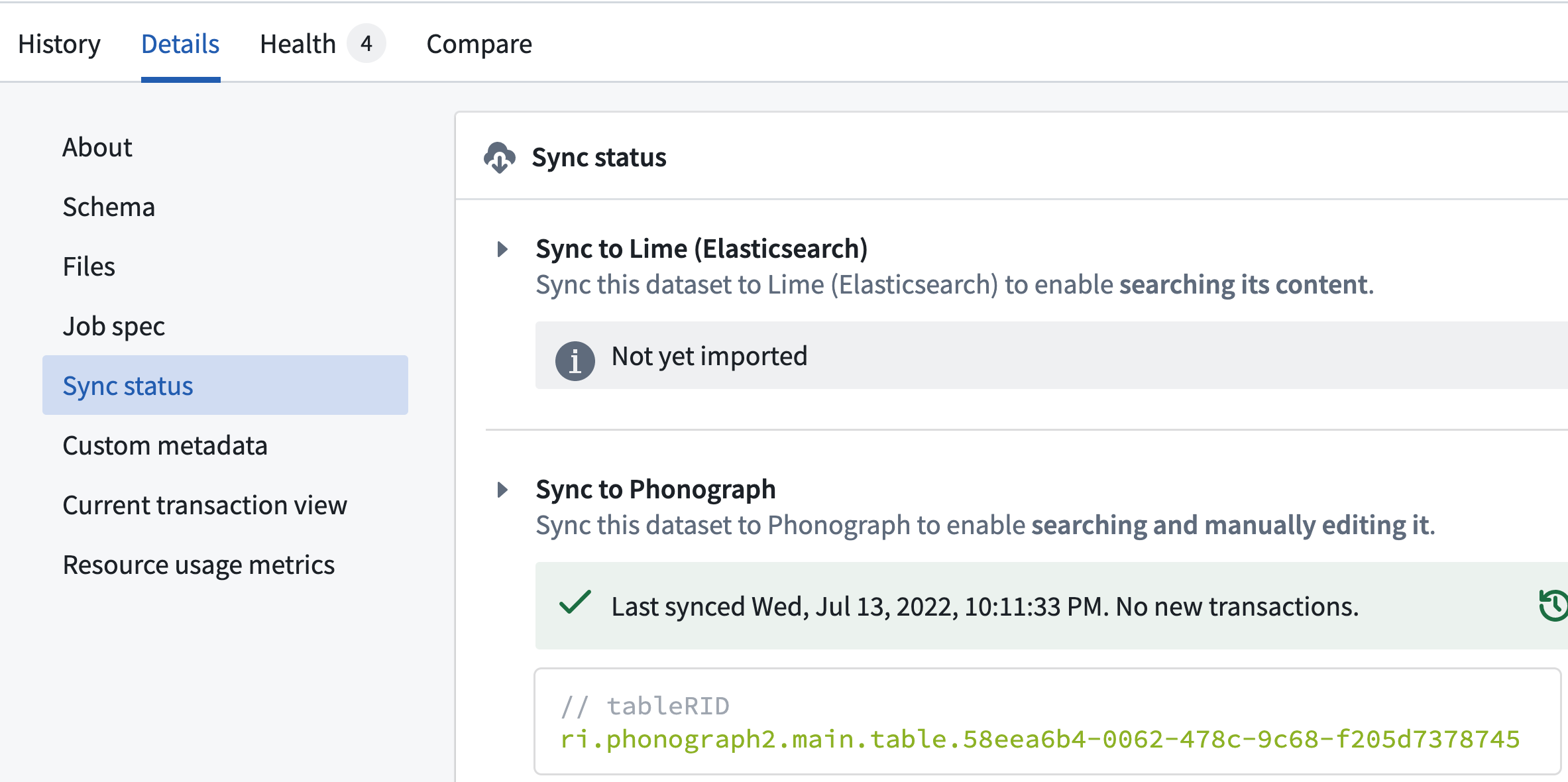
ここにいる間に、Health タブにアクセスして、以前に設定した Schema Check が通過したことも確認できます。チェックを COLUMN_ADDITIONS_ALLOWED_STRICT に設定したため、新しい行が追加されました。