注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
12 - パイプラインの文書化と更新
learn.palantir.com でも以下の内容をご覧いただけますが、アクセシビリティの観点から、ここに掲載しています。
📖 タスクの概要
なぜ、手付かずのデータセットの clean バージョンをオントロジーの入力として使用しなかったのか?
Clean データセットは、Foundry での多くの活動の起点となることがよくあります。これには、分析、モデリング、および他のデータパイプラインが含まれます。通常、それらは raw データに密接に似ており、オントロジーオブジェクトやリンクタイプに必要なものよりもはるかに多くの行を含むことがありますが、それでも他のワークフローにとって価値のあるものです。また、オントロジーを利用した元データセットに新しい派生行を追加することになるかもしれませんし、それらの変更を clean バージョンに影響を与えずに行いたいかもしれません。この中間変換ステップ( clean → ontology )は、最初に形式ばったりであるように感じる場合でも、常に推奨されます。
このトレーニングのルートで学んだ方法に従って、パイプラインに追加した変換ステップを文書化し、スケジュールし、監視する必要があります。これらの要約的な推奨事項に従って、知識をテストしてください。
🔨 タスクの説明
-
パイプラインがデプロイされたら、Pipeline Builder の Pipeline outputs パネルの上部にある View Lineage ボタンをクリックします。
-
データセットを展開してすべての祖先ノードを表示し、それらを論理的に配置します(ヒント:すべてのノードを選択して ctrl+l をクリックしてみてください)。
-
このデータフローのグラフを
/Ontology Project: Flight Alerts/documentation/に "Flight Alerts Pipeline (Full)" として保存します。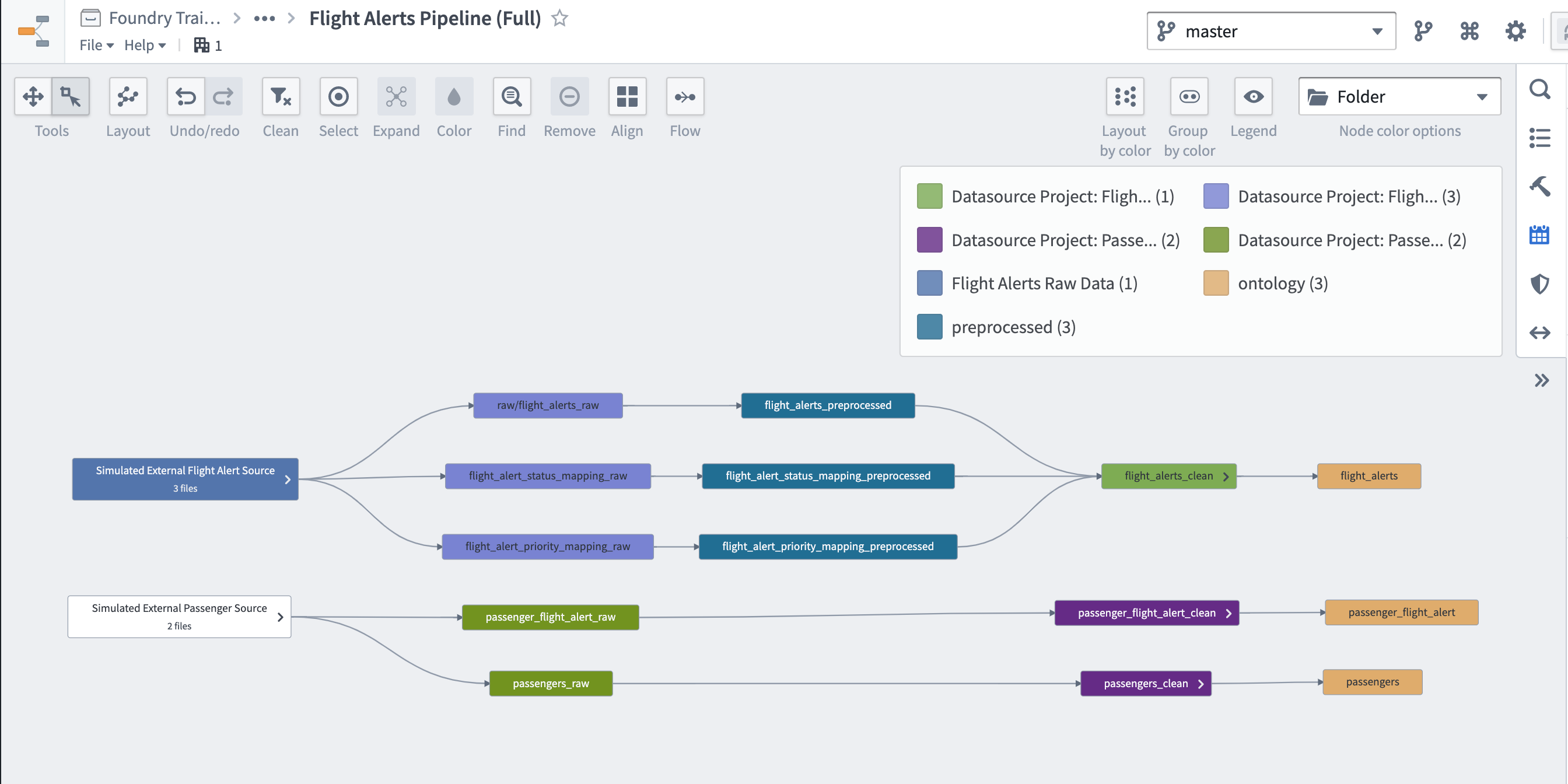
-
/documentationフォルダーに、他のリポジトリ用に作成したものと同じ構造の Notepad ドキュメントを追加します。所有者情報や説明を追加することを検討してください。説明は、前のチュートリアル「プロジェクト出力の作成」の「書面でのパイプライン文書の追加」の タスクの概要 から引用してもよいでしょう。 -
データフローのグラフで、Schedules ヘルパーを開き、Flight Alerts と Passengers のスケジュールを編集して、ターゲットが新しい ontology データセットになるようにします(以前に設定された clean データセットではない)。
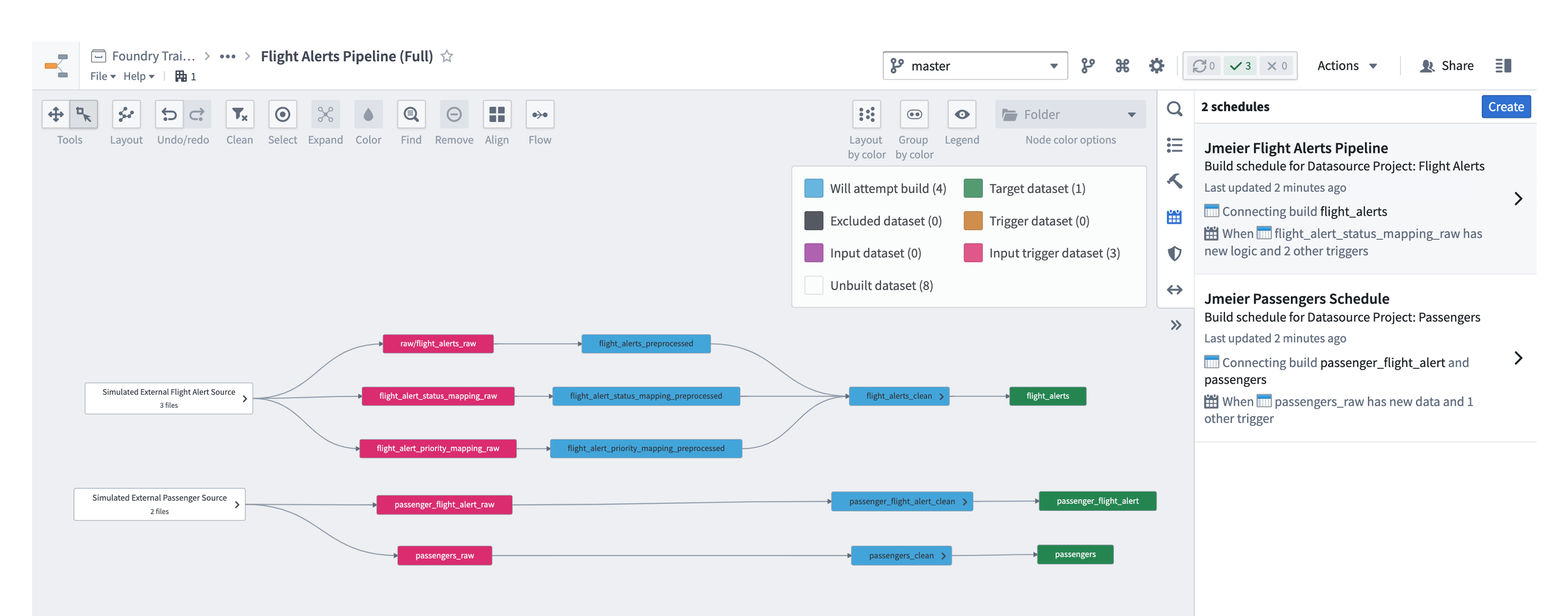
-
以下のヘルスチェックをそれぞれの新しいオントロジーデータセットに適用し、関連するチェックグループに追加します。
- Schema Check (
COLUMN_ADDITIONS_ALLOWED_ STRICT)。 - Primary Key (severity = critical)。
flight_alerts_passengerについては、チェックをalert_display_nameとpassenger_idの組み合わせを確認するように設定します。 - Time Since Last Updated (1 deviation > the median)
- Schema Check (
オントロジーでオブジェクトとリンクタイプを設定した後、最後のチェックを追加します。これらの新しいデータセットはすべて、既存の Schedule Status と Schedule Duration チェックに自動的に追加されます。