注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
7 - データの前処理、パート 1
この内容は learn.palantir.com ↗ でもご覧いただけますが、アクセシビリティの観点から、ここに掲載しています。
📖 タスクの概要
ユーザーの Datasource Project: Flight Alerts プロジェクトのデータセットと同様に、乗客と乗客フライトアラート(乗客とフライトアラートをマッピング)データセットにも前処理ステップが必要になります。想像できるように、最初のステップはデータセットファイルを読み込み、Spark DataFrame にパースして、最適化された Parquet 形式に書き出すことです。
Parquet では、列名に特殊文字やスペースを許可しないため、前処理ステップでは列名のサニタイズも必要になります。Foundry が提供する API やパッケージの中には、transforms.verbs.dataframes パッケージの sanitize_schema_for_parquet のように、コードベースのトランスフォームを効率化するものがあります。これは、DataFrame の列名から Parquet ファイルとして保存できない文字をすべて削除し、データセットのビルドが成功するようにします。
🔨 タスクの説明
-
最初に、
Masterから新しいブランチを作成し、yourName/feature/tutorial_preprocessed_filesと名前を付けます。 -
コードリポジトリの Files セクションにある
/datasetsフォルダーを右クリックし、新しいフォルダー/preprocessedを作成します。 -
/preprocessedフォルダーに新しい Python ファイルpassenger_flight_alerts_preprocessed.pyを作成します。 -
passenger_flight_alerts_preprocessed.pyファイルを開き、下記のコードブロックでデフォルトの内容を置き換えます。from transforms.api import transform, Input, Output from transforms.verbs.dataframes import sanitize_schema_for_parquet @transform( parsed_output=Output("/${space}/Temporary Training Artifacts/${yourName}/Data Engineering Tutorials/Datasource Project: Passengers/datasets/preprocessed/passenger_flight_alerts_preprocessed"), raw_file_input=Input("${passenger_flight_alerts_csv_raw_RID}"), ) def read_csv(ctx, parsed_output, raw_file_input): # Create a variable for the filesystem of the input datasets filesystem = raw_file_input.filesystem() # Create a variable for the hadoop path of the files in the input dataset hadoop_path = filesystem.hadoop_path # Create an array of the absolute path of each file in the input dataset paths = [f"{hadoop_path}/{f.path}" for f in filesystem.ls()] # Create a Spark dataframe from all of the CSV files in the input dataset df = ( ctx .spark_session .read .option("encoding", "UTF-8") # UTF-8 is the default .option("header", True) .option("inferSchema", True) .csv(paths) ) """ Write the dataframe to the output dataset using the sanitize_schema_for_parquet function to make sure that the column names don't contain any special characters that would break the output parquet file """ parsed_output.write_dataframe(sanitize_schema_for_parquet(df)) -
以下の項目を置き換えます。
- 6 行目の
${space}をユーザーの space に置き換えます。 - 6 行目の
${yourName}をユーザーの Tutorial Practice Artifacts フォルダー名に置き換えます。 - 7 行目の
${passenger_flight_alerts_raw_RID}をpassenger_flight_alerts_csv_rawデータセットの RID に置き換えます。これはpassenger_flight_alerts_raw.pyで定義された出力です。前のタスクでパスを RID に置き換えた場合は、そのファイルから RID をコピーしてこのファイルに貼り付けることができます。 - その他、RID は以下に示すワークフローを使用して Foundry Explorer ヘルパーから取得できます。
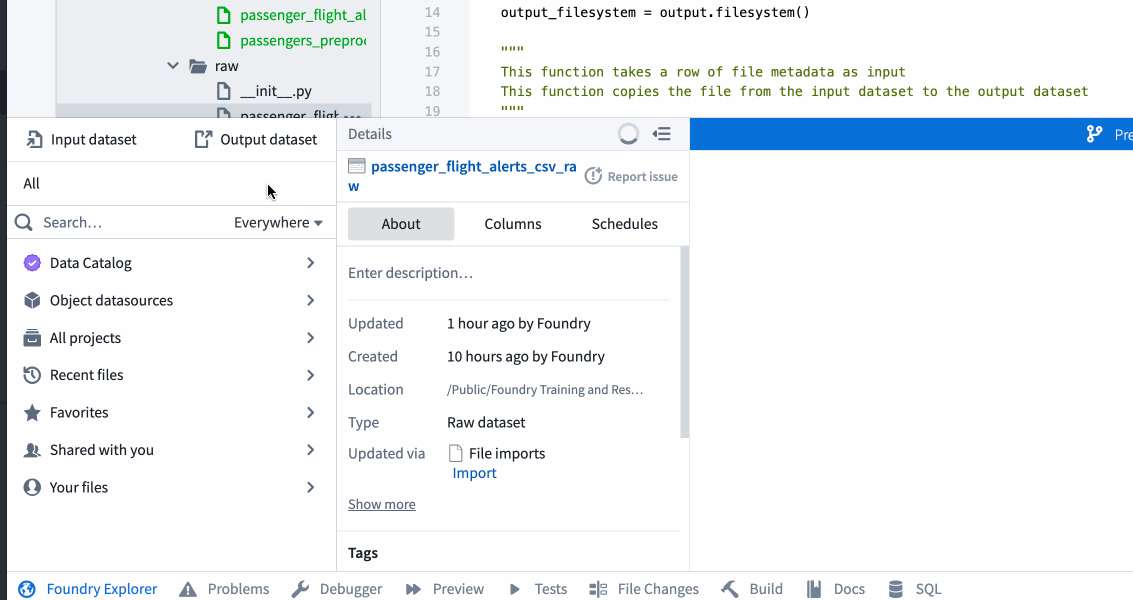
- 6 行目の
-
右上の Preview ボタンを使用して、コードをテストし、出力が raw ファイルではなくデータセットとして表示されることを確認します。プレビューウィンドウで Configure input files を求められた場合は、
Configure...をクリックし、次の画面でpassenger_flight_alerts.csvの隣のボックスにチェックを入れます。 -
テストが期待通りに動作した場合は、コードを「feature: add passenger_flight_alerts_preprocessed」など、意味のあるメッセージを付けてコミットします。
-
フィーチャーブランチで
passenger_flight_alerts_preprocessed.pyコードをビルドし、出力データセットが乗客とフライトアラートの二列マッピングを含むことを確認します。