注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
5 - 乗客パイプラインのドキュメント化
learn.palantir.com ↗ でも以下の内容をご覧いただけますが、アクセシビリティの観点から、ここに掲載しています。
📖 タスクの概要
前のチュートリアルと同じパターンを使用して、Notepad ドキュメントを .../Datasource Project: Passengers/documentation/ フォルダーに「README」ファイルとして追加します。
🔨 タスクの説明
-
.../Datasource Project: Passengers/documentation/フォルダーを開きます。 -
Passengers Datasource Project Pipeline Documentationという名前の新しい Notepad ドキュメントを追加します。 -
ドキュメントに以下のテキストを追加し、アプリケーション画面の左上のオプションを使用して、見出しやサブ見出しのサイズを調整し、箇条書きや番号付けを追加し、必要に応じてその他のスタイリングを行います。
**Passengers Pipeline** Ownership * **Project team: Aviation Data Development** * **Project owner: [yourName@yourOrganization.com](mailto:yourName@yourOrganization.com)** Overview This pipeline takes raw data ingested from the Passengers datasource and: 1. Parses raw and JSONs into a dataset 2. Normalizes column names and data types across all raw datasets -
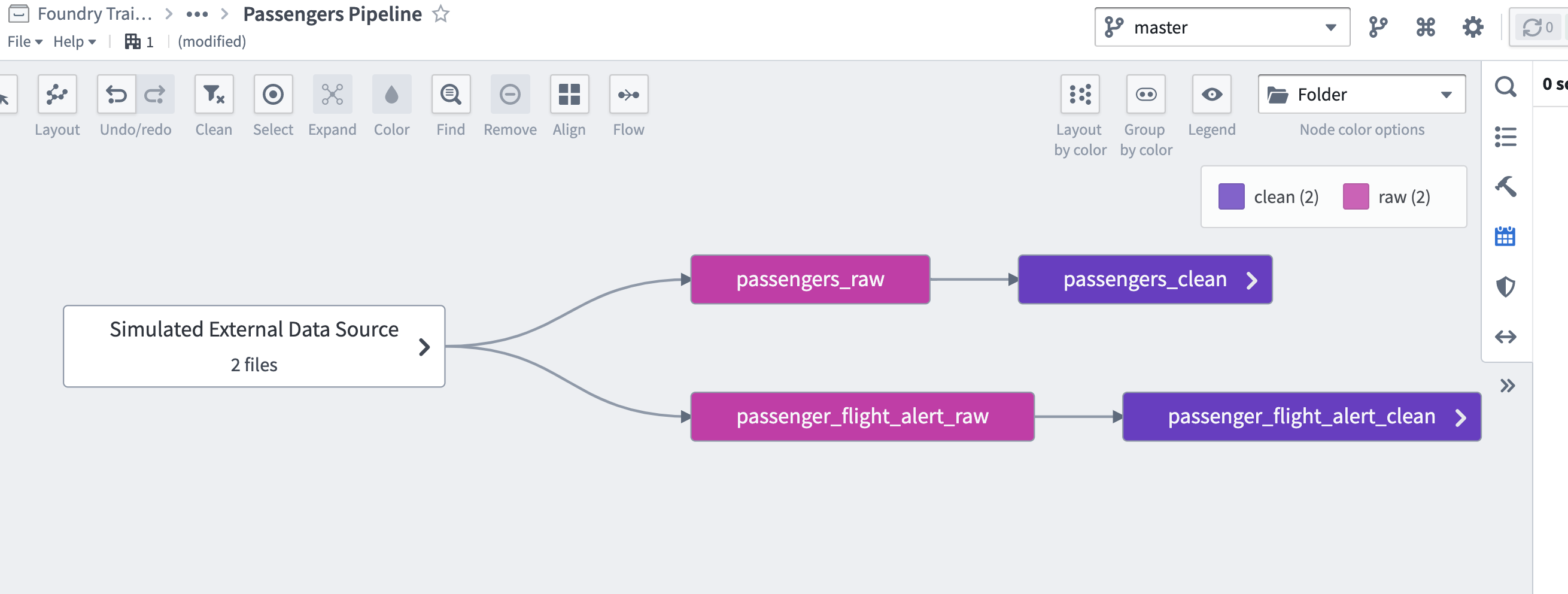
passengers_datasource_cleanPipeline Builder 製作物を開きます。 -
Ctrl+クリックして、Pipeline Builder の Pipeline outputs ウィンドウの上部にある View Lineage ボタンをクリックします。
-
すべての上流の祖先ノードを展開します。
-
shift を押しながら、グラフの最も左側の「raw」ノードの周りに選択ボックスをドラッグします。
-
選択を右クリックし、Group nodes... を選択します。
-
グループに「Simulated External Data Source」と名前を付けます。
-
グラフを
Passengers Pipelineとして.../Datasource Project: Passengers/documentation/フォルダーに保存します。