注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
3 - ユーザーのpassengerデータソースプロジェクトを作成してハイドレートする, パート 2
learn.palantir.com でも以下の内容をご覧いただけますが、アクセシビリティの観点から、ここに掲載しています。
📖 タスクの概要
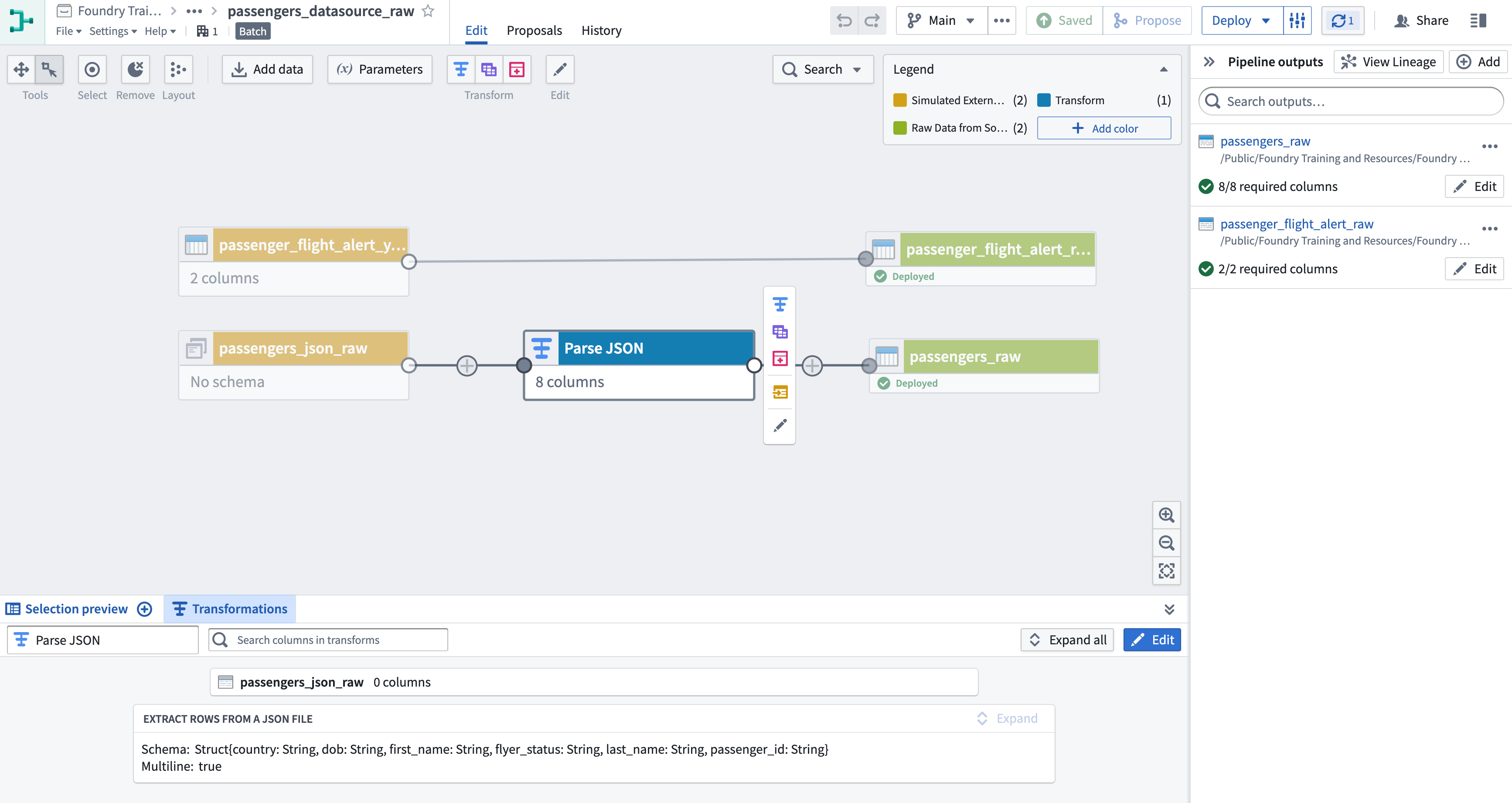
Pipeline Builder グラフで見られるように、passengers_raw_json にはスキーマがありません。これはファイルがJSONで書かれているため、まずSparkが扱える形式に変換する必要があるからです。このタスクでは、Pipeline Builder が JSON や XML を Foundry データセットに解析する方法を示します。
🔨 タスクの説明
-
Extract Rows from a JSON File ボードを使用して
passengers_json_rawデータセットにトランスフォームを追加します。 -
トランスフォーム画面の左上隅でトランスフォームに「Parse JSON」と名前を付けます。
-
Example data テキストエリアに、以下のJSONオブジェクトを入力します。これは生データから取得したものです。Pipeline Builder はこの単一オブジェクトからスキーマを推測できます。
{ "passenger_id": "0f7a3494b080426ca95bb6d155c33e42", "first_name": "Benjamin", "last_name": "Payne", "dob": "7/16/73", "country": "Mexico", "flyer_status": "None" } -
Generate Schema ボタンをクリックし、次に Apply をクリックします。
-
グラフに戻り、新しいトランスフォームから
passengers_rawという新しい出力を作成します。 -
以下に示すように、インポートと出力にノードカラーを追加することを検討してください。
-
パイプラインを保存してデプロイします。