注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
10 - Pipeline を Data Lineage Graph でドキュメント化する
learn.palantir.com でも以下の内容をご覧いただけますが、アクセシビリティの観点から、ここに掲載しています。
📖 タスクの概要
チームがこのパイプラインのステージにおけるデータの流れを迅速に理解できるように、Datasource プロジェクトの /documentation フォルダーに Data Lineage グラフを作成して保存します。
🔨 タスクの説明
-
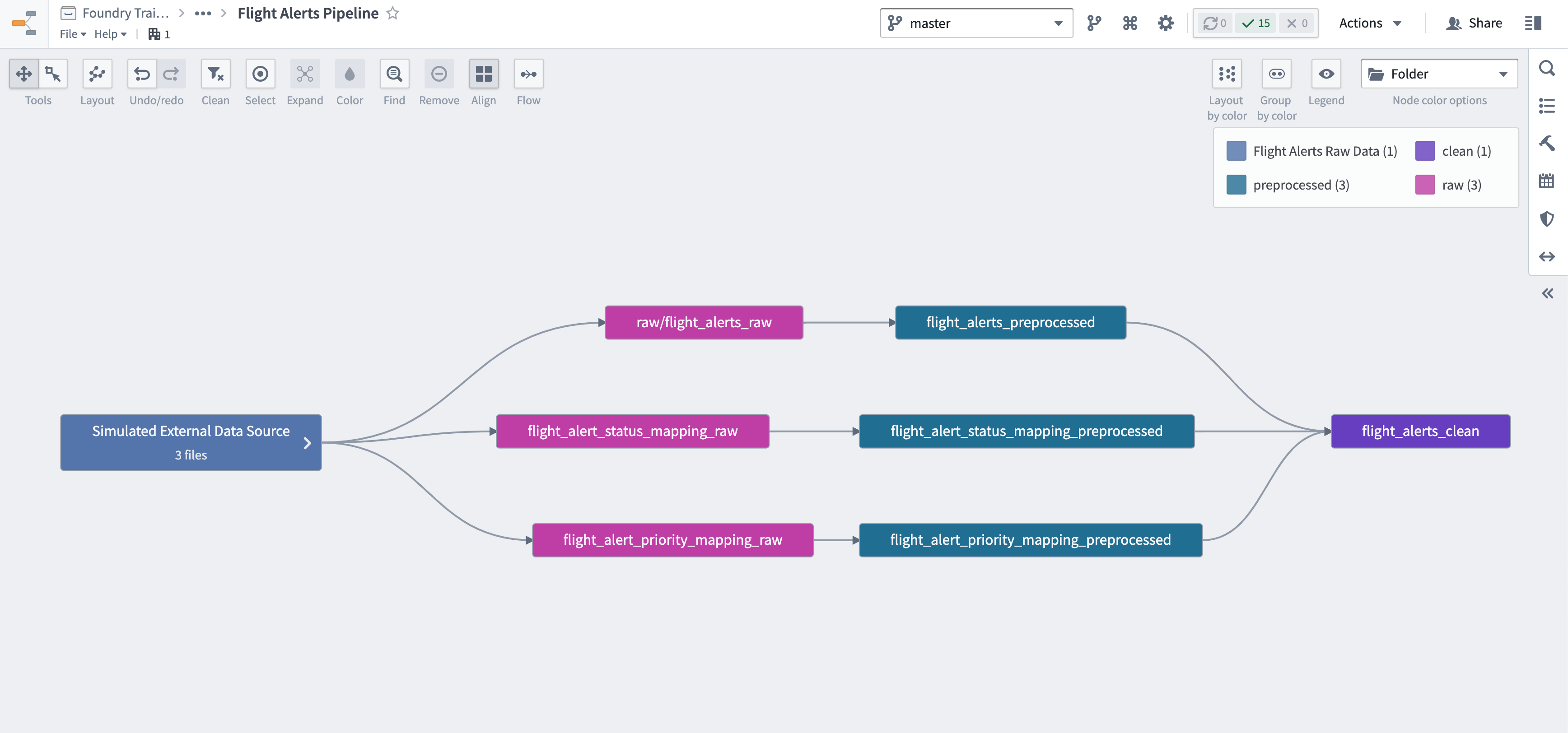
Pipeline outputs ウィンドウの上部にある View Lineage ボタンを Ctrl+クリックします。
-
Data Lineage 画面の左上にある Align アイコンをクリックして、グリッドにスナップする動作を有効にします。
-
右上の「ギア」アイコンをクリックして、まだ有効にしていない場合は Enable curved edges を有効にします。
-
現在のグラフには
flight_alerts_cleanと*_preprocessedデータセットのみが表示されています。前処理済みのノードをハイライトし、データフローを元の生の入力データセットまで拡張します。データフローが表示されたら、必要に応じてノードを再配置します。 -
Node color options を フォルダー に変更して、パイプラインのステージをより明確に識別します。
「raw」データセットは最上流に位置し、外部データソースをシミュレートしているだけであることを忘れないでください。たとえば、raw データセットの接続が
sample-sourceという 1 つの外部 Postgres データベースから来ていた場合、グラフは次のようになります: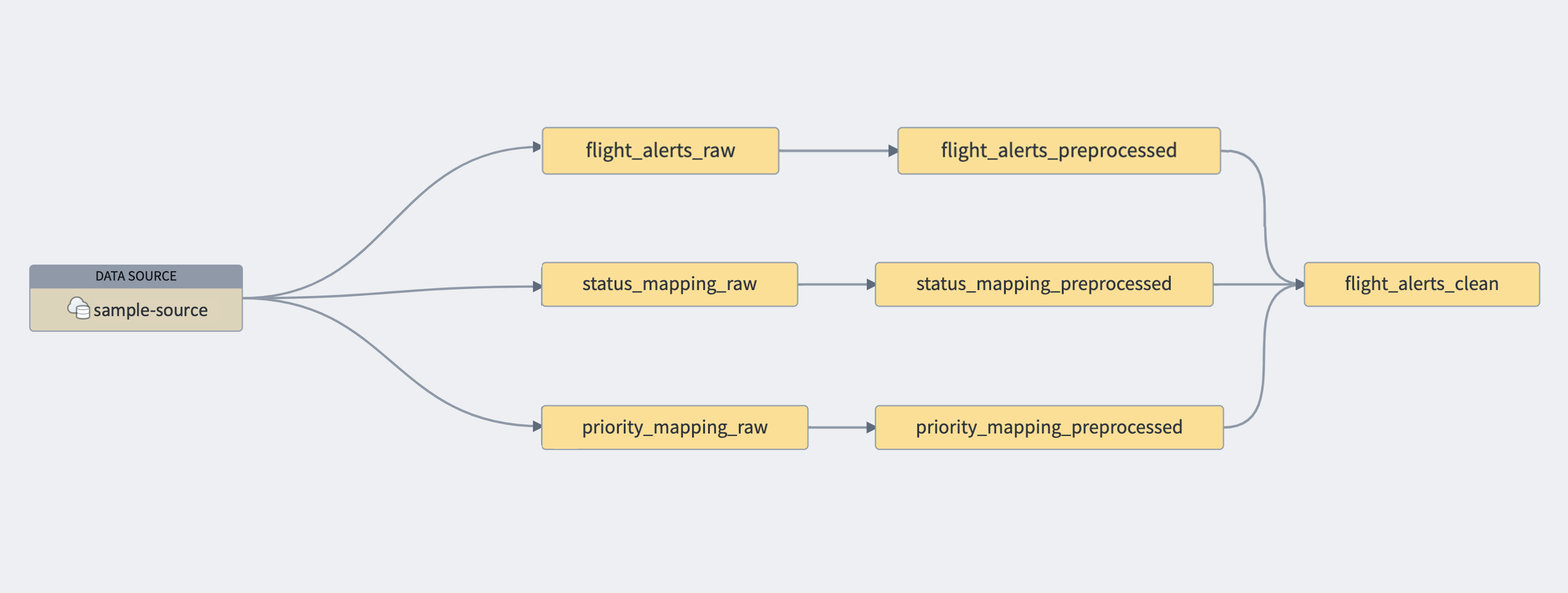
-
この構成をできるだけ近くシミュレートしましょう。shift を押しながら、グラフ上の最も左側にある「Flight Alerts Raw Data」ノードの周りに選択ボックスをドラッグします。
-
選択を右クリックし、Group nodes... を選びます。
-
グループに「Simulated External Data Source」という名前を付けます。
-
Data Lineage アプリケーションの右上にある青い Save ボタンをクリックします。ファイルを Flight Alerts Pipeline として Datasource プロジェクトの
/documentationフォルダーに保存します (たとえば、.../Data Engineering Tutorials/Datasource Project: Flight Alerts/).